广义不完备多粒度标记决策系统的粒度选择
2018-06-08吴伟志谭安辉徐优红
吴伟志 杨 丽 谭安辉 徐优红
(浙江海洋大学数理与信息学院 浙江舟山 316022) (浙江省海洋大数据挖掘与应用重点实验室(浙江海洋大学) 浙江舟山 316022) (wuwz@zjou.edu.cn)
粒计算(granular computing, GrC)是当前人工智能领域中一个非常活跃的研究方向,是信息处理的一种新的概念和计算范式,它模拟人类思考模式,以粒(granule)为基本计算单位,强调对现实世界问题多视角、多层次的理解和描述,是针对复杂问题求解、海量数据挖掘和不确定性信息处理等问题研究的有力工具.早在1979年,模糊数学的创始人Zadeh[1]就提出了信息粒度(information granularity)的概念.Hobbs[2]于1985年对粒度(granularity)概念作了进一步的阐述,描述了粒计算雏形的一些基本特征,以不同的粒度来概化世界,以粒度之间的交换来处理问题.Zadeh[3]于1997年又进一步提出了信息粒化(information granulation)的概念,并认为人类认知能力可概括为粒化、组织和因果3个主要特征.而“粒计算”这个概念是Lin[4]于1997年首次提出的,后来Lin[5]和Yao[6]分别对粒计算研究的一些基本问题进行了阐述.我国张钹院士和张铃教授[7]提出的商空间(quotient space)理论被公认为粒计算的另一个重要模型,该理论明确指出“在问题求解研究中,人类智能的一个公认特点,就是人们能从极不相同的粒度上观察和分析同一问题”.
迄今为止,已经提出了很多涉及具体应用背景的粒计算模型和方法,而在众多粒计算研究方法中,粗糙集对粒计算研究的推动和发展起着重要的作用[8-19].粗糙集数据分析中的典型数据描述结构称为信息系统(information system)[20],又称为信息表或对象-属性值表,信息表所给出的是数据集的训练样本,原始的Pawlak粗糙集理论利用样本集上的等价类来描述“粒度”,用等价关系所诱导的划分来描述粒度空间.由于Pawlak粗糙集模型所用到的等价关系要求过于严厉且对噪声过于敏感,因此,很多基于非等价关系的粗糙集模型被提出来,并用于各种类型的信息系统和决策表的信息粒度表示和知识获取问题[9-11,16-18].然而,在传统粗糙集数据分析中,信息系统或决策表中的每个对象只能取唯一的属性值,这样的信息系统所描述的是固定尺度下的对象信息,我们称之为单粒度标记信息系统.事实上,单一粒度框架下的知识表示以及数据处理方法已远远不能满足实际应用的需求,因而“多粒度”已经成为粒计算研究方向的热点.将复杂问题转换为多粒度问题并利用多粒度方法进行求解,不仅体现了粒计算中将复杂问题分层、分块处理的基本思想,而且展现出人类的多层次、多视角思维认知能力.在粗糙集数据分析方面,钱宇华等人在文献[21]中首次提出了多粒度粗糙集模型,这是一种推广的Pawlak粗糙集模型,所提出的乐观粗糙集和悲观粗糙集思想有较好的创新性,其主要思想是通过属性的选择进行交运算或并运算进行数据处理,在此基础上针对不同数据背景的多粒度粗糙集方法被相继提出[22-23].在实际应用中人们可能要在不同的粒度标记下对同一对象在同一属性或变量下对系统中的数据进行观察、表示、分析和做出决策,即对于同一个对象和所对应的某个属性,根据实际问题的不同粒度层次的需要,可以取不同层次标记的值.比如,对于地图上我国的某一地方,根据行政区域的不同粒度层次(如乡、县、地级市、省自治区等级别),其所属地分别给予不同的区域标记.针对类似问题,Wu和Leung在文献[24]中首次提出了基于多粒度标记划分的粗糙集数据分析方法,在这种多粒度标记数据模型下,同一批数据可以被标记为不同的粒度层次,人们可以根据需要在不同的粒度标记层面上处理和分析数据.Wu等人[25-29]还进一步研究了在多粒度标记框架下的其他数据类型的信息粒度表示和最优粒度的选择问题,She等人[30]提出了多粒度标记决策系统的局部最优粒度选择和规则提取方法.Gu和Wu[31-32]还给出了协调的和不协调的多粒度标记决策系统中知识获取的算法.由于人们在日常生活中接触和处理的数据很多情形下都有缺省的情况,针对此类情况,Wu等人[33]最近又进一步提出了不完备多粒度标记粗糙集数据分析模型.然而,以上多粒度标记信息系统都有一个共同的假设,即系统中所有的属性都具有相同的粒度标记个数,而实际生活中人们可能面对不同的属性具有不同的粒度标记个数的数据处理问题,针对这种情形,Li和Hu在文献[34]中提出了一种推广的多粒度标记数据分析模型,研究了不同属性具有不同粒度标记层次的多粒度标记决策系统的最优粒度选择问题,给出了2种最优粒度标记选择方法.
本文结合文献[33-34]的思路,提出推广的不完备多粒度标记决策系统的粗糙集知识表示模型,并讨论该模型下粒度标记选择问题.
1 相关的基础知识
设U是非空论域,U的子集全体记为P(U).对于A∈P(U),A在U中的补集记为~A,即~A={x∈U|x∉A}.本节简单介绍一些基本概念与知识.
1.1 不完备信息系统
一个信息系统是一个二元组(U,AT),其中U={x1,x2,…,xn}是一个非空有限对象集,称为论域;AT={a1,a2,…,am}是一个非空有限属性集,对于任意的a∈AT,满足a:U→Va,即a(x)∈Va,x∈U,其中Va={a(x)|x∈U}称为a的值域.
当一个信息系统中的一些属性值是缺省的或者说是未知的,则称该系统为不完备信息系统,我们仍然用二元组(U,AT)来表示.用符号“*”表示未知值或缺省值,即如果a(x)=*,那么就认为x在属性a上的值是未知的.
对于给定的一个不完备信息系统(U,AT),A⊆AT,记:
RA={(x,y)∈U×U|∀a∈A,a(x)=a(y)
或a(x)=*或a(y)=*}.
显然,RA是自反和对称的,即RA是相似关系,但一般是非传递的.记:
SA(x)={y∈U|(x,y)∈RA},x∈U.
SA(x)称为对象x关于RA的相似类,记:
URA={SA(x)|x∈U}.
设(U,AT)是一个不完备信息系统,A⊆AT,X⊆U,X关于RA的下近似和上近似定义如下:
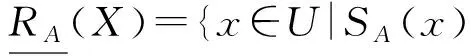
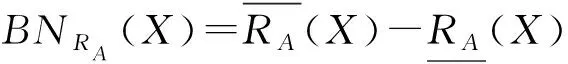
其中,|X|表示集合X的基数.X关于RA的粗糙度为
1.2 信任函数与似然函数
定义1. 信任结构.设U是非空有限论域,集函数m:P(U)→[0,1]称为mass函数(基本概率指派),若它满足2个性质:
1)m(∅)=0;
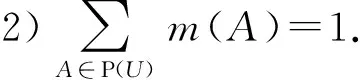
称A∈P(U)是m的焦元,若m(A)>0.记M={A∈P(U)|m(A)>0},则序对(M,m)称为U上的一个信任结构.
定义2. 信任函数与似然函数.设(M,m)是U上的一个信任结构,集函数Bel:P(U)→[0,1]称为U上的信任函数,若
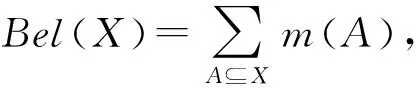
集函数Pl:P(U)→[0,1]称为U上的似然函数,若
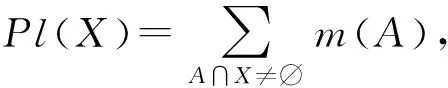
由同一信任结构导出的信任函数与似然函数是对偶的,即∀X∈P(U),
Pl(X)=1-Bel(~X),
且
Bel(X)≤Pl(X).
反之,信任结构中的mass函数可以通过Möbius变换用信任函数来表示,即∀X∈P(U),
信任函数和似然函数还可以等价地用公理定义,即集函数Bel:P(U)→[0,1]是U上的一个信任函数当且仅当它满足3个性质:
1)Bel(∅)=0;
2)Bel(U)=1;
3) 对于任意X1,X2,…,Xl⊆U,有
同样地,Pl:P(U)→[0,1]是U上的一个似然函数当且仅当它满足3个性质:
1)Pl(∅)=0;
2)Pl(U)=1;
3) 对于任意X1,X2,…,Xl⊆U,有:
定理1[35]. 设(U,AT)是一个不完备信息系统,A⊆AT,∀X∈P(U),记:
则BelA,PlA:P(U)→[0,1]是U上一对对偶的信任函数与似然函数,其对应的mass函数为
2 不完备多粒度标记信息系统
在一个(完备)信息系统(U,AT)中,每一个对象xi在属性aj上只取一个确定的值,这是单粒度标记信息系统.若信息系统(U,AT)中每一个对象在同一个属性上,根据不同的粒度标记层面可以取不同的值,则(U,AT)是一个多粒度标记信息系统.Wu和Leung在文献[24]中首次提出了多粒度标记信息系统的概念.
定义3[24]. 多粒度标记信息系统.称(U,AT)是一个多粒度标记信息系统,其中U={x1,x2,…,xn}是一个非空有限对象集,称为论域,AT={a1,a2,…,am}是一个非空有限属性集,且每一个属性都是多粒度属性.假设所有的属性都有I个相同的等级粒度,则一个多粒度标记信息系统可以表示为
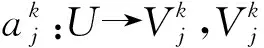
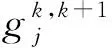
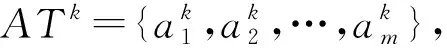
定义3中假设系统中的每一个属性都有相同等级的粒度标记,但在实际生活中,各个属性的粒度等级可能不一样,针对这种情形,Li和Hu在文献[34]中提出了一种基于不同属性取不同等级粒度标记的多粒度标记信息系统,我们称之为广义多粒度标记信息系统.
定义4[34]. 广义多粒度标记信息系统.称(U,AT)是一个广义多粒度标记信息系统,其中U={x1,x2,…,xn}是一个非空有限对象集,称为论域,AT={a1,a2,…,am}是一个非空有限属性集,且每一个属性都是多粒度属性.假设属性aj有Ij个等级粒度标记,则一个多粒度标记信息系统可以表示为
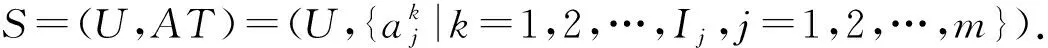
其中,k=1,2,…,Ij-1;j=1,2,…,m;x∈U.
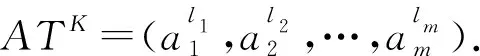
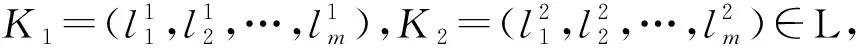
可以验证,(L,⪯)是一个偏序集,即⪯是L上的一个偏序关系(自反、传递和反对称的关系).若进一步定义:
则(L,⪯,∧,∨)是一个有界格,显然它是一个完备格,其中最小元是(1,1,…,1),最大元是(I1,I2,…,Im),并且:
K1⪯K2⟺K1∧K2=K1⟺K1∨K2=K2.
对于A⊆AT和K=(l1,l2,…,lm)∈L,记K在属性子集A上的限制为KA,并记LA={KA|K∈L},即LA是子多粒度标记信息系统(U,A)的粒度标记选择全体.
对于A⊆AT和K=(l1,l2,…,lm)∈L,记:
RAK={(x,y)∈U×U|∀al∈AKA,
al(x)=al(y)或al(x)=*或al(y)=*},
则RAK是不完备多粒度标记信息系统S在粒度标记层面K=(l1,l2,…,lm)上由属性集A导出的一个相似关系,特别地,对于a∈AT,记RaK=R{a}K.记:
SAK(x)={y∈U|(x,y)∈RAK},x∈U.
SAK(x)称为对象x关于AK的相似类.记:
URAK={SAK(x)|x∈U}.
定义6. 设U为非空集,A与B是U的2个覆盖,若对于任意A∈A,存在B∈B使得A⊆B,则称A比B细或B比A粗,记作AB.
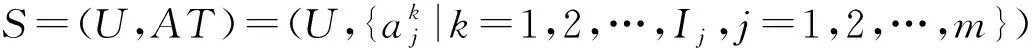
1)K1⪯K2⟹RAK1⊆RAK2;
2)K1⪯K2⟹SAK1(x)⊆SAK2(x),∀x∈U;
3)K1⪯K2⟹URAK1URAK2;
4)A⊆B⊆AT⟹RBK⊆RAK,∀K∈L;
证明. 直接验证即得.
证毕.
对于X⊆U,K∈L,X关于RAK的下近似和上近似定义为
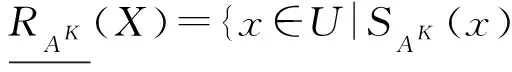
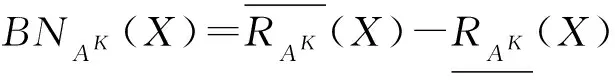
由定理2和上述下近似、上近似的定义容易得到如下:
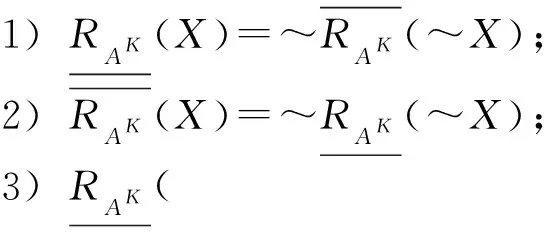
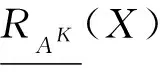
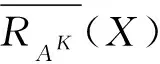
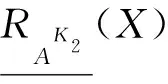
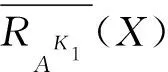
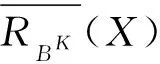
X关于RAK的近似精度定义为
X关于RAK的粗糙度定义为
ρAK(X)=1-αAK(X),
则我们可以得到在不同的粒度标记层面下集合的近似精度与粗糙度的关系:
1)K1⪯K2⟹αAK2(X)≤αAK1(X);
2)K1⪯K2⟹ρAK1(X)≤ρAK2(X).
定理4表明,粒度标记越小(细),集合的近似精度越高而相应的粗糙度越小.
由定理1和定理3可得:
则BelAK,PlAK:P(U)→[0,1]是U上一对对偶的信任函数与似然函数,其对应的mass函数为
并且信任函数与似然函数满足3个性质:
1) 对于K1,K2∈L,若K1⪯K2,则BelAK2(X)≤BelAK1(X)≤P(X);
2) 对于K1,K2∈L,若K1⪯K2,则P(X)≤PlAK1(X)≤PlAK2(X);
3) 若B⊆C⊆AT,则BelBK(X)≤BelCK(X)≤P(X)≤PlCK(X)≤PlBK(X).
3 不完备多粒度标记决策系统与最优粒度选择
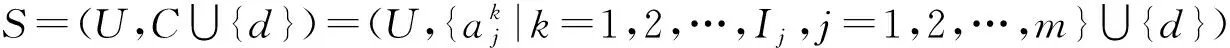
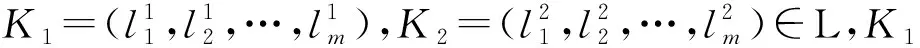
是协调的,即RCK2⊆Rd,则由定理2知,RCK1⊆RCK2⊆Rd,从而:
也是协调的,即在较粗的粒度标记层面下的不完备决策系统是协调的,则在较细的粒度标记层面下的不完备决策必定是协调的.
例1. 表1是一个不完备多粒度标记决策表S=(U,C∪{d}),其中U={x1,x2,…,x8},C={a1,a2,a3},其中“S”,“M”,“L”,“Y”,“N”分别表示“小”、“中等”、“大”、“是”、“否”等.属性a1与a3有3个粒度层面的标记,属性a2只有2个粒度层面的标记.

Table 1 An Incomplete Multi-Granular LabeledDecision System表1 一个不完备多粒度标记决策系统
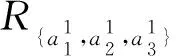
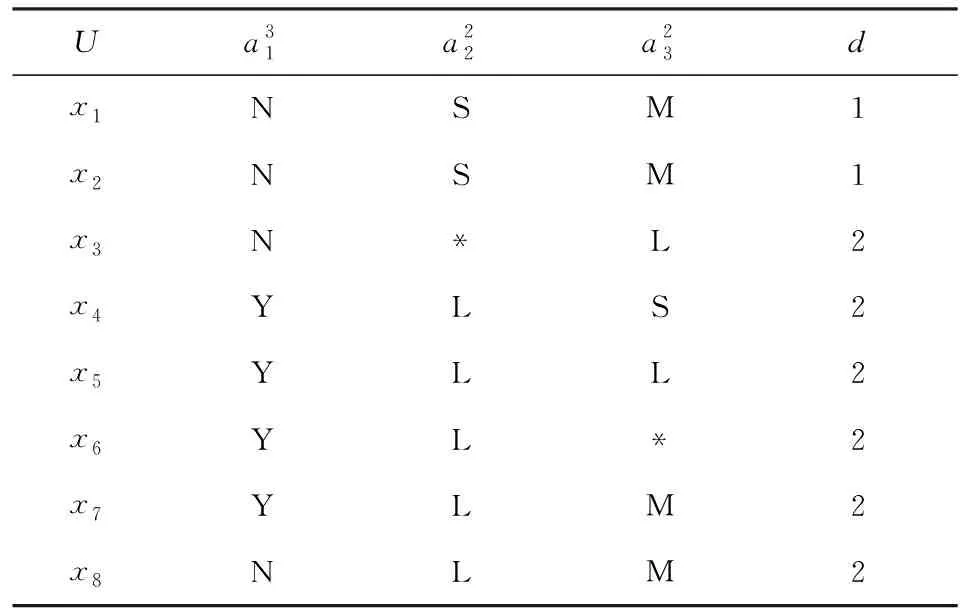
Table 2 The Incomplete Decision Table with the GranularLabel Selection K=(3,2,2)表2 对应于粒度标记选择K=(3,2,2)的不完备决策表
我们下面讨论用证据理论中的信任函数和似然函数来刻画最优粒度标记选择的特征.为了方便起见,不妨设Vd={1,2,…,r},记Dj={x∈U|d(x)=j},j∈{1,2,…,r},URd={Dj|j=1,2,…,r}.
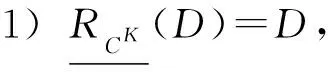
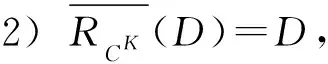
证明. 1) 对于任意D∈URd,由定理3知,⊆D.另一方面,对于任意x∈D,显然[x]d={y∈U|d(y)=d(x)}=D.由于SK=(U,CK∪{d})是协调的,从而SCK(x)⊆[x]d=D,由下近似的定义知于是D⊆因此,
2) 对于任意D∈URd,由定理3知,D⊆另一方面,对于任意由上近似的定义知,SCK(x)∩D≠∅.对于任意y∈SCK(x)∩D,显然[y]d=D,又由于RCK是对称的,从而由y∈SCK(x)可得x∈SCK(y).由于SK=(U,CK∪{d})是协调的,因此SCK(y)⊆[y]d,从而x∈SCK(y)⊆[y]d=D,于是⊆D,故
证毕.
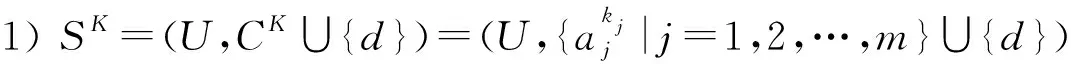
证明. “1)⟹2)”由于SK=(U,CK∪{d})是协调的,由定理6知,对于任意Di∈URd有从而因此,
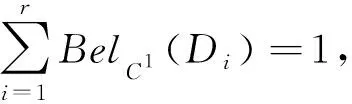
(1)
由定理5知,对于任意Di∈URd有BelCK(Di)≤BelC1(Di),因此由式(1)可得:
于是:
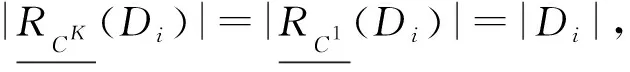
(2)
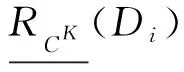
SCK(y)⊆[x]d,
(3)
由于x∈[x]d,在式(3)中取y=x即得SCK(x)⊆[x]d,因此RCK⊆Rd,即SK=(U,CK∪{d})是协调的.
“1)⟹3)”由于SK=(U,CK∪{d})是协调的,由定理6知,对于任意Di∈URd有从而因此,
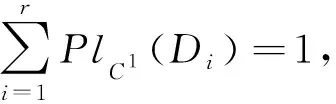
(4)
由定理5对于任意Di∈URd有PlC1(Di)≤PlCK(Di),故由式(4)可得:
因此:
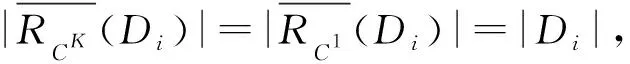
(5)
而由定理3知:
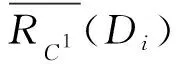
(6)
从而由式(5)和式(6)即得:
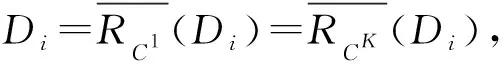
(7)
对于任意x∈U,取D∈URd使得x∈D,显然[x]d=D.对于任意y∈SCK(x),由于RCK是对称的,因此x∈SCK(y),从而SCK(y)∩[x]d≠∅,于是由上近似定义可得故由式(7)知y∈[x]d,这样我们证明了对于任意x∈U有SCK(x)⊆[x]d,即RCK⊆Rd,因此SK=(U,CK∪{d})是协调的.
证毕.
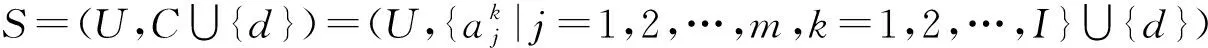
1) 粒度标记选择K是最优的;
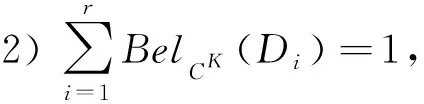
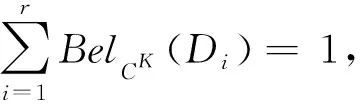
证毕.
例2. (续例1)在表1给出的例中,经计算当K=(3,2,2)∈L时,
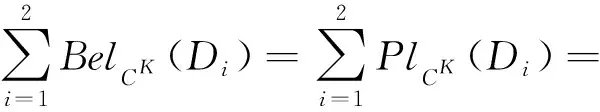
而对于H=(3,2,3)∈L,有:
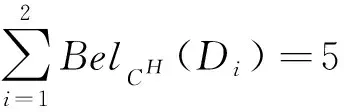
又由于H=(3,2,3)是L中唯一严格粗于K的粒度标记选择,由定理8可知K=(3,2,2)是S的最优粒度标记选择.
4 结束语
本文介绍了广义不完备多粒度标记信息系统的概念,在这种系统中不同属性可以有不同的粒度标记层面个数.给出了在不同粒度标记层面下基本信息粒的表示及其相互关系,同时定义了基于相似关系的集合的下、上近似概念,并讨论了近似算子的性质.引入了广义不完备多粒度标记信息系统中的粒度标记选择和广义不完备多粒度标记决策系统中的最优粒度标记选择的概念.并进一步用证据理论中的信任函数和似然函数刻画了协调的不完备多粒度标记决策系统的最优粒度选择的特征.由于广义不完备多粒度标记决策系统中可能的粒度标记选择的集合组合复杂度比较高,因此,寻求合适的算法求解最优粒度标记是一个值得研究的问题.对于一个不协调的不完备多粒度标记决策系统可以通过引入广义决策函数,并用广义决策函数代替原系统中的决策,可以将不协调的不完备多粒度标记决策系统转化为协调的不完备多粒度标记决策系统,这样就容易得到判别不协调的不完备多粒度标记决策系统中保持广义决策不变的最优粒度选择的特征.未来我们将研究不协调的不完备多粒度标记决策系统在其它各种意义下的最优粒度选择问题和多粒度决策规则提取的方法.
[1]Zadeh L A. Fuzzy sets and information granularity[G]Advances in Fuzzy Set Theory and Applications. Amsterdam: North-Holland, 1979: 3-18
[2]Hobbs J R. Granularity[C]Proc of the 9th Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 1985: 432-435
[3]Zadeh L A. Towards a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic[J]. Fuzzy Sets and Systems, 1997, 90(2): 111-127
[4]Lin Tsau Young. Granular computing: From rough sets and neighborhood systems to information granulation and computing in words[COL]Proc of European Congress on Intelligent Techniques and Soft Computing, 1997 [2017-05-12]. http:xanadu.cs.sjsu.edu~drtylinpublicationspaperList101_34rsnsigcw3.pdf
[5]Lin Tsau Young. Granular computing: Structures, representations, and applications[G]LNAI 2639: Proc of the 9th Int Conf on Rough Sets, Fuzzy Sets, Data Mining, and Granular Computing. Berlin: Springer, 2003: 16-24
[6]Yao Yiyu. Granular computing: Basic issues and possible solutions[C]Proc of the 5th Joint Conf on Computing and Information. Durham: Duke University Press, 2000: 186-189
[7]Zhang Ling, Zhang Bo. Quotient Space Based Problem Solving: A Theoretical Foundation of Granular Computing[M]. Beijing: Tsinghua University Press, 2014 (in Chinese)(张铃, 张钹. 基于商空间的问题求解: 粒度计算的理论基础[M]. 北京: 清华大学出版社, 2014)
[8]Duan Jie, Hu Qinghua, Zhang Lingjun, et al. Feature selection for multi-label classification based on neighborhood rough sets[J]. Journal of Computer Research and Development, 2015, 52(1): 56-65 (in Chinese)(段洁, 胡清华, 张灵均, 等. 基于邻域粗糙集的多标记分类特征选择算法[J]. 计算机研究与发展, 2015, 52(1): 56-65)
[9]Kryszkiewicz M. Rough set approach to incomplete information systems[J]. Information Sciences, 1998, 112(1-4): 39-49
[10]Leung Yee, Wu Weizhi, Zhang Wenxiu. Knowledge acquisition in incomplete information systems: A rough set approach[J]. European Journal of Operational Research, 2006, 168(1): 164-180
[11]Li Deyu, Zhang Bo, Leung Yee. On knowledge reduction in inconsistent decision information systems[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2004, 12(5): 651-672
[12]Lin Tsau Young, Yao Yiyu, Zadeh L A. Data Mining, Rough Sets and Granular Computing[M]. New York: Physica-Verlag, 2002
[13]Miao Duoqian, Wang Guoyin, Liu Qing, et al. Granular Computing: Past, Present and Future[M]. Beijing: Science Press, 2007 (in Chinese)(苗夺谦, 王国胤, 刘清, 等. 粒计算的过去、现在与展望[M]. 北京: 科学出版社, 2007)
[14]Miao Duoqian, Li Deyi, Yao Yiyu, et al. Uncertainty and Granular Computing[M]. Beijing: Science Press, 2011 (in Chinese)(苗夺谦, 李德毅, 姚一豫, 等. 不确定性与粒计算[M]. 北京: 科学出版社, 2011)
[15]Pedrycz W, Skowron A, Kreinovich V. Handbook of Granular Computing[M]. New York: Wiley, 2008
[16]Shao Mingwen, Zhang Wenxiu. Dominance relation and rules in an incomplete ordered information system[J]. International Journal of Intelligent Systems, 2005, 20(1): 13-27
[17]Shi Qianyu, Liang Jiye, Zhao Xingwang. A clustering ensemble algorithm for incomplete mixed data[J]. Journal of Computer Research and Development, 2016, 53(9): 1979-1989 (in Chinese)(史倩玉, 梁吉业, 赵兴旺. 一种不完备混合数据集成聚类算法[J]. 计算机研究与发展, 2016, 53(9): 1979-1989)
[18]Sun Bingzhen, Ma Weimin, Gong Zengtai. Dominance-based rough set theory over interval-valued information systems[J]. Expert Systems, 2014, 31(2): 185-197
[19]Zhang Wei, Miao Duoqian, Gao Can, et al. A neighborhood rough sets-based co-training model for classification[J]. Journal of Computer Research and Development, 2014, 51(8): 1811-1820 (in Chinese)(张维, 苗夺谦, 高灿, 等. 邻域粗糙协同分类模型[J]. 计算机研究与发展, 2014, 51(8): 1811-1820)
[20]Pawlak Z. Rough Sets: Theoretical Aspects of Reasoning about Data[M]. Amsterdam, Netherlands: Kluwer Academic Publishers, 1991
[21]Qian Yuhua, Liang Jiye, Yao Yiyu, et al. MGRS: A multi-granulation rough set[J]. Information Sciences, 2010, 180(6): 949-970
[22]Qian Yuhua, Liang Jiye, Dang Chuangyin. Incomplete multi-granulation rough set[J]. IEEE Trans on Systems, Man and Cybernetics, 2010, 40(2): 420-431
[23]Yang Xibei, Song Xiaoning, Chen Zehua. On multigranula-tion rough sets in incomplete information system[J]. International Journal of Machine Learning and Cybernetics, 2012, 3(3): 223-232
[24]Wu Weizhi, Leung Yee. Theory and applications of granular labeled partitions in multi-scale decision tables[J]. Information Sciences, 2011, 181(18): 3878-3897
[25]Wu Weizhi, Gao Cangjian, Li Tongjun. Ordered granular labeled structures and rough approximations[J]. Journal of Computer Research and Development, 2014, 51(12): 2623-2632 (in Chinese)(吴伟志, 高仓健, 李同军. 序粒度标记结构及其粗糙近似[J]. 计算机研究与发展, 2014, 51(12): 2623-2632)
[26]Dai Zhicong, Wu Weizhi. Rough approximations in incomplete multi-granular ordered information systems[J]. Journal of Nanjing University: Natural Sciences, 2015, 51(2): 361-367 (in Chinese)(戴志聪, 吴伟志. 不完备多粒度序信息系统的粗糙近似[J]. 南京大学学报: 自然科学版, 2015, 51(2): 361-367)
[27]Wu Weizhi, Leung Yee. Optimal scale selection for multi-scale decision tables[J]. International Journal of Appro-ximate Reasoning, 2013, 54(8): 1107-1129
[28]Wu Weizhi, Chen Ying, Xu Youhong, et al. Optimal granularity selections in consistent incomplete multi-granular labeled decision systems[J]. Pattern Recognition and Artificial Intelligence, 2016, 29(2): 108-115 (in Chinese)(吴伟志, 陈颖, 徐优红, 等. 协调的不完备多粒度标记决策系统的最优粒度选择[J]. 模式识别与人工智能, 2016, 29(2): 108-115)
[29]Wu Weizhi, Chen Chaojun, Li Tongjun, et al. A comparative study on optimal granularities in inconsistent multi-granular labeled decision systems[J]. Pattern Recognition and Artificial Intelligence, 2016, 29(12): 1103-1111 (in Chinese)(吴伟志, 陈超君, 李同军, 等. 不协调多粒度标记决策系统最优粒度的对比[J]. 模式识别与人工智能, 2016, 29(12): 1103-1111)
[30]She Yanhong, Li Jinhai, Yang Hailong. A local approach to rule induction in multi-scale decision tables[J]. Knowledge-Based Systems, 2015, 89: 398-410
[31]Gu Shenming, Wu Weizhi. On knowledge acquisition in multi-scale decision systems[J]. International Journal of Machine Learning and Cybernetics, 2013, 4(5): 477-486
[32]Gu Shenming, Wu Weizhi. Knowledge acquisition in inconsistent multi-scale decision systems[G]LNAI 6964: Proc of the 6th Int Conf on Rough Sets and Knowledge Technology. Berlin: Springer, 2011: 669-678
[33]Wu Weizhi, Qian Yuhua, Li Tongjun, et al. On rule acquisition in incomplete multi-scale decision tables[J]. Information Sciences, 2017, 378: 282-302
[34]Li Feng, Hu Baoqing. A new approach of optimal scale selection to multi-scale decision tables[J]. Information Sciences, 2017, 381: 193-208
[35]Wu Weizhi. Attribute reduction based on evidence theory in incomplete decision systems[J]. Information Sciences, 2008, 178(5): 1355-1371
WuWeizhi, born in 1964. Professor and PhD supervisor. Senior member of CCF. His main research interests include rough set theory, granular computing, random set theory, concept lattice, approximate reasoning, etc.

YangLi, born in 1994. Master. Her main research interests include rough set theory and granular computing (1214774932@qq.com).

TanAnhui, born in 1986. PhD. Lecturer. His main research interests include rough set theory, granular computing, artificial intelligence, etc (tananhui86@163.com).

XuYouhong, born in 1969. Associate professor. Her main research interests include rough set theory and granular computing (xyh@zjou.edu.cn).
