基于证据自动机的软件回归验证
2018-11-22贾尚坤
贾尚坤,贺 飞
(清华大学 软件学院, 北京 100084)(*通信作者电子邮箱 hefei@tsinghua.edu.cn)
0 引言
为了保障软件的正确性与鲁棒性,传统的方法是通过一系列功能与性能相关的测试发现软件的问题与缺陷。然而,测试方法只能在整个系统或相关功能实现后进行,无法在软件的需求或设计阶段预见系统潜在的问题。另外,测试方法不可能包含所有情况的测试用例,因此无法证明系统不存在缺陷,也无法证明它满足特定的属性。而验证方法则恰好可以解决上述问题。软件的形式化验证[1]指的是在软件系统的抽象数学模型上应用形式化的证明,验证系统满足或违反相应的规约和属性,以确保软件的正确性。用于建模系统的数学对象包括有限状态机、Petri网、时间自动机等,而形式化的证明方法则在数理逻辑、自动机、图论等数学理论基础之上对系统进行分析与验证。形式化验证主要包含定理证明和模型检测两种途径,其中后者由于轻量级和完全自动化在工业界得到了广泛应用。
多版本迭代是当前软件开发的普遍状况。为了节约软件开发的资金、人力、时间等投入,软件公司需要用尽可能少的版本迭代为软件增加更多的新特性。然而,软件在对自身功能进行扩展的同时,可能会与已有功能产生冲突而引发错误,这一现象被称为“回归”[2]。为了避免回归,文献[3]中首先提出了回归测试的概念,即用一组覆盖面尽可能大的回归测试用例对软件的新版本进行检测,报告任何可能出现的新漏洞。但由于回归测试不可能包含所有的测试用例,因此无法保证所有的新漏洞在软件发布前都能被提前发现而得到解决。因此,为了确保软件的安全性与可靠性,需要在软件的研发进程中引入程序验证方法。考虑到邻近版本之间往往有较多的相似性,如果将这些版本视为不同软件分别进行验证,将会浪费掉大量的共享信息,从而影响验证效率。为了利用邻近版本之间的共享信息,学者又提出了回归模型检测[4]与回归验证[5]的概念。最初回归验证指的是证明相关联程序的等价性,即:程序P1与P2的任意可终止的执行若具有相同的输入,则运行结束后将得到相同的返回值。后来人们用回归验证表示将形式化验证技术应用到连续检测的开发版本中,利用邻近版本之间的共享信息验证程序属性。
而对于证据(witness),最开始更多被用来描述验证工具在系统违反验证属性时生成的错误路径,它们在复现系统的错误中扮演了“见证人”的角色。后来证据的含义得到扩展,指的是软件验证工具在验证完成后生成的一个验证结果辅助文件,用来对验证程序进行再检验,进而确定程序是否如验证结果所说满足或违反其验证属性[6],如图1所示。证据需要有统一的格式,这样不仅方便不同验证工具的交互,也有助于证据文件的可读性与可视化。目前在国际软件验证大赛(Competition on Software Verification, SV-COMP)上采用的证据文件格式为GraphML(一种可扩展标记语言),其中定义了一个非确定有限自动机,即证据自动机。自动机的节点表示一个程序位置(对应程序计数器的一个值),自动机的边表示控制流从边的起点到终点时程序执行的操作(对应一条程序语句),整个证据自动机刻画了程序的大致结构。图2给出了一个证据自动机的示例,自动机每个节点上的编号对应一个程序位置,而每条边除了对应的程序语句之外,还包含起始行号、偏移量等相关的定位信息。

图1 证据文件的生成与检验Fig. 1 Generation and validation of witness files
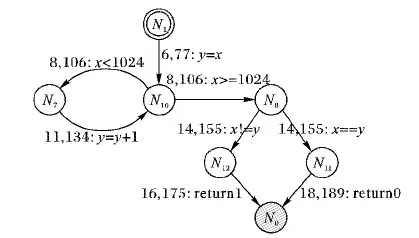
图2 证据自动机示例Fig. 2 Example of witness automata
根据验证结果的不同(不考虑超时等未知验证结果),证据分为正确证据(correctness witness)[7]与违反证据(violation witnesss)[8]两类,分别表示程序满足或违反其验证属性。二者的内涵也有所不同,正确证据包含了程序验证得到的循环不变式,而违反证据记录了程序验证过程中到达错误状态的反例路径信息。由于回归验证的关键在于邻近版本之间的共享信息,因此基于证据自动机的回归验证的主要目标是提取并重用证据文件中的共享信息。对于邻近版本的程序而言,若均满足验证属性,则相同或相近程序位置处成立的不变式很可能相差不大;而若均违反验证属性,前一版本的反例路径在后一版本中未必有效,即使有效也未必导向错误状态。因此,基于证据自动机的回归验证主要指的是提取并重用之前版本正确证据中的循环不变式,对多版本程序进行回归验证。
历届国际软件验证大赛都要求所有参赛工具提供能够复现验证结果的证据文件,从SV-COMP 2015开始规定了反例文件的格式并要求为属性违反提供违反证据[9],从SV-COMP 2017开始规定了正确文件的格式并要求为属性满足提供正确证据[10]。但大多数能生成证据文件的验证工具并不能利用证据文件中的信息,截至SV-COMP 2017只有可配置程序分析检测工具(Configurable Program Analysis checker, CPAchecker)和终极自动机验证工具(Ultimate Automizer, UAutomizer)被选为证据文件的检验工具[10]。由于UAutomizer对证据文件中循环不变式的利用效率偏低[7],因此本文在CPAchecker源代码的基础上实现回归验证功能。CPAchecker是一个应用可配置程序分析(configurable program analysis)框架[11]整合各种软件分析与验证技术的开源工具[12],可以通过命令行或Eclipse插件运行。
1 证据预处理
对于多版本程序而言,即便邻近版本的程序结构也会存在一定的差异,因此上一个版本的证据文件并不能直接应用到下一个版本的验证中。为了利用之前版本证据自动机中的不变式信息,需要对证据文件进行相应的预处理。预处理大致可以分为两个部分:影响域分析与证据文件生成。整个预处理过程如图3所示。证据预处理的相关实现已被整合到CPAchecker源码中。

图3 证据预处理Fig. 3 Witness preprocessing
1.1 影响域分析
影响域分析的目的在于确定版本变动对原证据文件中不变式的影响。不受影响的不变式可以直接重用,而受影响的不变式在新版程序中可能仍然成立,需要进一步检验。影响域分析分为三步:比较新旧程序、生成混合程序、得到影响结果。
比较新旧程序主要用到了Linux系统中的diff命令:
diff -b -B -H -n old.c new.c
其中:-b用于忽视空格字符;-B用于忽视空白行;-H用于提高大文件比较的速度;-n用于修改输出格式。通过调用diff命令比较新旧版本程序的文本差异,并将比较结果重定向到差异文件diff.txt中。diff.txt包含了新版程序相对于旧版程序增加和删除的语句信息,例如对于diff.txt中的以下内容:
a6 1
int c=a+b;
d12 2
其中:a和d分别表示增加和删除。a和d后面的第一个数字表示旧版程序的行号;第二个数字表示增加或删除的代码行数,若为增加还会在后面附加具体的语句。
生成混合程序通过将原证据文件old-witness与差异文件diff.txt的信息综合到旧版程序old.c中,得到用于影响域分析的混合程序mix.c。old-witness的信息主要指证据自动机节点上的循环不变式。由图2可知,自动机节点可以通过其入边与出边在程序中定位,因而可以将节点上的不变式作为布尔表达式插入到相应的程序位置。之后将diff.txt中的新增语句插入混合程序,并且在新增语句和删除语句前加上影响标注:
/*@ impact pragma stmt; */
由混合程序mix.c调用Frama-C的影响域分析插件即可得到版本变动语句对原证据文件中不变式的影响结果。Frama-C是一个面向大规模C程序验证的源码分析平台[13],通过整合相关插件实现各种分析与验证功能。通过图形界面或命令行调用Frama-C的影响域分析插件,可以分析带有影响标注的语句对其他语句的影响。调用该插件的具体命令如下:
frama-c -impact-pragma
-impact-log r:impact.txt -val-initialized-locals mix.c
-impact-pragma后接函数名表示在相应的函数中检测影响标注。由于影响标注在所有函数中都可能出现,因此需要调用CPAchecker的相关接口getAllFunctionNames获取程序所有的函数名。又因为CPAchecker在生成证据自动机时会对程序进行预处理,从混合程序看来自动机节点上不变式中的变量在相应的程序位置处可能尚未初始化,如果直接对这样的程序进行影响域分析将无法得到正确的影响结果,因此需要用-val-initialized-locals选项对所有的局部变量进行初始化。影响域分析的结果保存在文件impact.txt中。
1.2 证据文件生成
得到影响域分析结果之后,未受影响的不变式可以直接重用。而由于受影响的不变式在新版程序中可能仍然成立,需要将其写入用于进一步检验的新证据文件new-witness。生成new-witness的目的是如果之后的版本迭代不改变程序结构,可以直接将new-witness作为验证后面版本的输入,从而省去证据预处理过程。
生成new-witness之前,需要从原证据文件old-witness中提取受影响不变式的相关信息,包括不变式的内容、所属的节点编号、在程序中的作用域以及与所属节点相关联的边。边上的代码行号关系到不变式在新证据自动机中的定位,而由于版本变动,旧版程序的代码行号在新版程序中也会相应变化。因此,需要对行号进行相应的转换,转换方法如算法1所示。
算法1 新旧代码行号转换。
输入 旧版程序代码行数len,新旧版本差异文件diff.txt。
输出 整型数组oldToNew[],数组下标和相应的元素值分别表示旧版程序及其在新版程序中对应的代码行号(均从0开始)。
1)
新建一个大小为len的整型数组oldToNew[],并将其每一项初始化为0
2)
对于diff.txt中的每一行diffline:
3)
解析diffline,得到变动类型type、行号number与行数count
4)
if (type==′d′)
5)
oldToNew[number-1] -=count
6)
else
7)
oldToNew[number]+=count
8)
diff.txt继续向后读取count行
9)
intlastIndex=0
10)
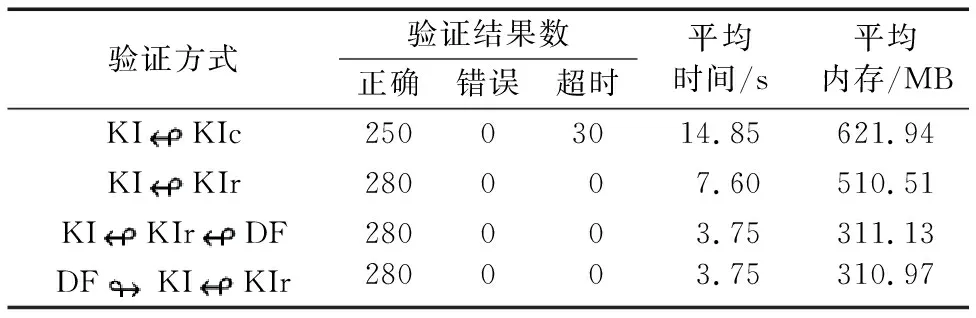
for (inti=1;i 11) oldToNew[i]+=oldToNew[i-1]+1 12) for (inti=len-1;i>=0; --i) 13) if (oldToNew[i]>=0) 14) lastIndex=oldToNew[i] 15) else 16) oldToNew[i]=lastIndex 预处理过程改写了CPAchecker的接口writeProofWitness,在得到不变式相关信息之后,可以由该接口将其写入新证据文件。对于原证据文件中一条与不变式所属节点相关联的边,找出它经过行号转换后在新证据自动机中对应的边,若二者的控制条件一致,则在新证据自动机中的对应节点上附加相应的不变式信息。然后通过合并冗余节点及其不变式,得到最终的新证据自动机,再调用CPAchecker中GraphML构造器GraphMlBuilder的appendTo方法生成新证据文件new-witness。new-witness刻画了新版程序的大致结构,因而可以应用到新版程序的验证中。 对新版程序进行回归验证的关键在于提取并重用原证据文件中的不变式信息。不受版本变动影响的不变式可以直接重用,而受影响的不变式则需要在新证据文件中检验通过后才能重用。检验新证据文件及验证新版程序的回归验证算法基于CPAchecker中用辅助不变式增强的k-归纳(k-induction)算法。 k-induction最初作为有限状态迁移系统基于可满足性判定的一种验证技术,被用于硬件设计与转移关系的验证[14]。后来k-induction技术逐渐应用到软件分析与验证领域,如直接内存访问竞争分析[15]、同步程序分析[16]与嵌入式软件验证[17]等。 对于一个表示程序的状态迁移系统,s和s′为其中的两个状态变量,I(s)表示s为初始状态,T(s,s′)表示存在s到s′的状态转移,P(s)表示程序的安全属性P在s上成立。给定一个任意的正整数k,分两步说明k-induction的验证过程。 为了用k-induction证明程序,首先需要验证P在从初始状态s1出发k步内可达的所有状态s1,s2, …,sk上均成立,也就是式(1)不可满足: (1) 接下来,还需要验证只要P在任意k个连续状态sn,sn+1, …,sn+k-1上成立,P在第k+1个状态sn+k上就一定成立,也就是式(2)不可满足: (2) 由上述两步即可验证程序的正确性。若式(1)可以满足,则程序违反其验证属性;若式(2)可以满足,则在当前k值下无法验证程序(程序可能满足或违反其验证属性)。 k-induction验证是归纳方法在软件验证中的应用,连续k+1个状态可以看作程序循环的k次展开。当k=1时,k-induction退化为标准归纳方法,且随着k的增大,式(2)的归纳假设随之不断增强,从而使证明变得更容易。但若要使用k-induction,程序的安全属性P必须满足相应的可归约性(即式(2)不可满足),否则在当前k值下无法验证程序。 为了将k-induction推广到一般程序,Beyer等[18]提出了用辅助不变式增强的k-induction算法。具体来说,就是用与k-induction算法并行的不变式生成算法为程序生成不断强化的循环不变式,在k-induction的每轮验证中用当前已知的不变式Inv增强式(2)的归纳假设,也就是改为证明式(3)不可满足: (3) CPAchecker总的k-induction验证流程如下:1)首先初始化一个较小的k值,以当前的k值为界,调用有界模型检测(bounded model checking)算法验证式(1)的可满足性,若其可满足,则发现了一条程序的错误路径,结束验证;2)若式(1)不可满足,则在当前已知不变式的辅助下验证式(3)的可满足性,若其不可满足,则程序正确性得证;3)若式(3)可以满足,且在前面的验证过程中并行算法生成了更强的不变式,则在新不变式的辅助下重新验证式(3)的可满足性;4)若式(3)始终可以满足,则说明在当前k值与辅助不变式下无法验证程序的正确性,此时CPAchecker会增大k值进行下一轮验证,直到得出验证结果或超时为止。 CPAchecker通过用不断强化的不变式增强k-induction的归纳假设以验证程序的正确性。但如果k-induction验证的不是程序的安全属性,而是一些不变式的候选(如证据自动机中待检验的不变式),将验证成立的候选作为辅助不变式提供出去,则k-induction本身也可以作为不变式生成算法。 用CPAchecker的原有配置即可并行两个k-induction算法,其中一个k-induction(下称“从KI”)为另一个k-induction(下称“主KI”)提供辅助不变式,而后者负责验证程序的正确性。该配置取程序所有到达错误状态的控制流路径的否定作为从KI的候选不变式[18]。每当从KI成功证明一条候选不变式λ,从KI就将λ加入辅助不变式提供给主KI以增强主KI的归纳假设;同时λ作为从KI的已知不变式,在从KI验证其他候选不变式时也会增强从KI的归纳假设。随着k不断增大,从KI证明的候选不变式不断增多,提供给主KI的辅助不变式也不断增强。 在上述配置的基础上,提取新证据文件中受版本变动影响的不变式加入从KI的候选不变式,用证据预处理得到的不受影响的不变式增强主KI的归纳假设,即可实现基于证据自动机的回归验证,如图4所示。除了原有配置的候选不变式,此过程主要用证据自动机中的不变式信息增强主KI的归纳假设,但证据文件包含的不变式可能不足以辅助程序验证[7]。因此,只用从KI生成辅助不变式的回归验证可能得不到足够强的归纳假设。 图4 基于证据自动机的回归验证Fig. 4 Regression verification based on witness automata 除了k-induction之外,CPAchecker还可用可配置程序分析算法(Configurable Program Analysis Algorithm, CPAAlgorithm)[19]执行数据流分析生成辅助不变式。CPAAlgorithm通过广度优先搜索维护可达抽象状态的集合,动态更新每个状态上的不变式,在每次迭代结束后将所有状态上不变式的析取与当前不变式的合取作为辅助不变式提供给主KI。由于CPAAlgorithm应用了动态精度调整,在迭代过程中会不断增加重要程序变量的数目和表达式的嵌套深度,因此产生的辅助不变式也是经过连续精化的[20]。 既然k-induction和CPAAlgorithm都能生成辅助不变式,可以通过并行主KI、从KI与CPAAlgorithm,在回归验证中将证据自动机中的不变式信息与数据流分析生成的辅助不变式相结合。如图5所示,既可用数据流分析生成的辅助不变式增强从KI的归纳假设,再由从KI将其提供给主KI间接增强主KI的归纳假设(用虚线表示),又可以将数据流分析与从KI生成的两部分辅助不变式合并后直接增强主KI的归纳假设(用点划线表示)。 图5 结合数据流分析的回归验证Fig. 5 Regression verification combined with data flow analysis CPAchecker为用辅助不变式增强的k-induction算法实现了三种不变式生成策略,其中除了不生成不变式的策略DO_NOTHING之外,INDUCTION接受从KI生成的不变式,REACHED_SET接受数据流分析生成的不变式。本文另外实现了新策略KIDF,用来同时接受从KI与数据流分析生成的不变式。 本章主要介绍不使用证据自动机中不变式信息的直接验证与2.2节介绍的三种回归验证之间的对比实验。为了方便表述,下面引入相应的符号记法。 实验的原始测例来自于国际软件验证大赛的验证任务集(https://github.com/sosy-lab/sv-benchmarks)。整个验证任务集包含了使用C语言(遵循GNU C标准)、Java语言、霍恩(Horn)子句的待验证程序,涵盖了可达性、内存安全、并发安全、可终止性、溢出检测等各个方面的验证。验证任务集主要为历届国际软件验证大赛提供统一的、覆盖面尽可能广的测例程序,同时也被许多研究项目用于评估软件验证算法的验证性能。 由于测例程序被用于回归验证实验,选取原始测例时需要考虑与回归验证方法的契合度。由于属性违反时的证据文件不包含不变式信息,而回归验证的核心思想是提取并重用证据文件中的循环不变式,因此选取原始测例时要排除验证任务集中违反验证属性的程序。另外,由于原始测例程序互不相关,为了由原始测例生成体现版本迭代过程的回归测例,还需要考虑原始测例的变异效果。综上,为了在对比实验中更好地体现回归验证的作用,本文从验证任务集C语言分支下与Linux内核相关更适合变异的ldv-linux-3.4-simple文件夹中随机选取了56个满足验证属性的程序作为版本迭代前的原始测例程序。 而为了由原始测例得到回归测例,需要将原始测例中的每个程序看作独立分支下的初始版本,在初始版本的基础上依次进行程序变异得到该分支下的其他版本。进行回归验证时,上一个版本的证据文件作为下一个版本程序验证的输入。由于要验证不变式重用的效果,与选取原始测例时类似,变异程序时同样需要舍弃违反验证属性的版本。 对于每一个原始测例程序P0,用开源C程序变异工具Milu[21]对其进行变异得到P1,若P1满足其验证属性(用CPAchecker和UAutomizer参与国际软件验证大赛的标准配置对P1的验证结果均为true),再在P1的基础上变异得到P2;否则重新由P0变异P1。类似可得P3、P4、P5,从P0到P5代表了一系列版本迭代的完整流程。这样就得到了56组用于回归验证的测例程序,每组回归测例包含6个版本。 本文用独立于验证工具的轻量级开源基准测试(benchmarking)框架BenchExec[22]对所有回归测例进行批量验证,统计其验证结果、时间与内存消耗。BenchExec接受一个XML文件作为输入,XML文件定义了待执行命令、资源使用限制与验证任务集合。在本实验中,BenchExec调用CPAchecker验证所有测例程序,时间限制为200 s,内存限制为4 GB,CPU核心数限制为4。 实验机器的CPU为i5-4590 (3.30 GHz×4),内存为8 GB,操作系统为Ubuntu 16.04 (64位)。实验所用的CPAchecker版本为1.6.1-svn,Frama-C版本为16.0-Sulfur-beta,Milu版本为3.0,BenchExec版本为1.14。 表1 base.properties新增配置项Tab. 1 Additional configuration options in base.properties 表2 对比实验结果Tab. 2 Contrast experiment results BenchExec调用CPAchecker得到的验证结果可能为true、 false或unknown,分别表示属性满足、属性违反或无法确定(原因可能是运行错误、超时或内存不足等)。由于本实验在原始测例选取和版本变异时均确保程序满足其验证属性,因此验证结果为true对应表2的正确计数,验证结果为false对应错误计数,而当验证结果为unknown时,验证时间不足200 s(即由超时以外的原因导致验证结果无法确定)对应错误计数,反之对应超时计数。由表2可知,除了因验证时间限制引起的部分超时(国际软件验证大赛的超时时间一般设置为900 s,而本实验为200 s),所有验证方式得到的验证结果均为true,与CPAchecker和UAutomizer标准参赛配置的验证结果相一致,说明了实验结果的正确性。 在多版本程序的验证中,为了利用邻近版本之间的共享信息,本文提出了基于证据自动机的回归验证。基于CPAchecker中用辅助不变式增强的k-induction算法,本文设计并实现了三种使用不同不变式生成策略的回归验证方法,并与不使用不变式信息的直接验证进行了对比实验。实验结果表明,当程序满足其验证属性时,基于证据自动机的回归验证能极大地提高验证效率,而将证据自动机与数据流分析相结合的验证方式能得到更好的验证效果。 由于证据文件包含的不变式可能不足以辅助程序验证或不一定必需,基于证据自动机的回归验证仍然存在一定的局限性,三种回归验证方法之间的对比结果也反映了这一点。在已有回归验证实现的基础上,未来的工作方向主要在于改进不变式生成方法,提高证据文件中的不变式质量,使得只基于证据自动机的回归验证就能得到足够好的验证效果。2 回归验证过程
2.1 k-induction及其增强
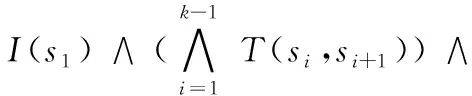
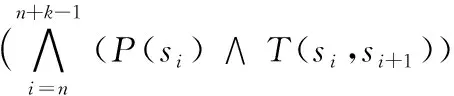

2.2 基于不同不变式生成策略的回归验证


3 实验

3.1 回归测例
3.2 运行环境
3.3 实验结果与分析

4 结语
