结合内容流行和主观偏好的节点缓存策略
2018-11-15曲大鹏程天放吴思锦王兴伟
曲大鹏,杨 文,杨 越,程天放,吴思锦,王兴伟
1(辽宁大学 信息学院,沈阳 110036 2(东北大学 计算机科学与工程学院,沈阳 110819)
1 引 言
由于具有资源共享和提供连通性等特点,互联网在人们生活和科研等工作中扮演着越来越重要的角色.随着通信技术的快速发展和网络应用的多样化,互联网逐渐从早期以主机为中心模式发展为面向内容模式[1].例如,绝大多数数据密集型产业服务迁移到网络,互联网成为储藏数据的工具;数字编码技术使得网络传输的内容由早期文本发展到图片、音频和视频等多媒体文件.因此,网络的主要功能已经由点对点通信变为了内容分发,原本以TCP/IP (Transmission Control Protocol/ Internet Protocol)架构为核心的网络模型很难适应这种变化,许多研究组织提出了发展内容中心网络(Information Centric Networking,ICN).通过在网络层命名信息,ICN架构内置缓存,为终端用户提供有效的内容分发,已经成为未来互联网研究中热点[2].
当前,未来互联网的研究主要有以下几个代表性工作.来自美国加州大学洛杉矶分校的Content-Centric Networking (CCN)和其后继Named Data Networking (NDN)*http://named-data.net/,来自欧盟的FP7(Seventh Framework Programme for Research)工程的PSIRP (Publish-Subscribe Internet Routing Paradigm)和其后继PURSUIT(Publish-Subscribe Internet Technology)*http://www.fp7-pursuit.eu/PursuitWeb/,来自日本的新一代网络R&D工程中的GreenICN工程*http://www.greenicn.org/.在上述工作中,NDN不仅保留了TCP/IP架构的细腰模型,而且通过将命名数据放在细腰重塑了互联网架构,因此获得广泛关注,也是本文工作的基础架构.
NDN通过Interest包和Data包来完成内容的请求和回应.具体流程为:源节点发出内含所需内容名的Interest包,其它节点在收到Interest包后检查自己的CS(Content Store),如果有相应内容,则直接回应内含具体内容的Data包;否则查看PIT(Pending Interest Table),如果内容名在PIT中,说明最近刚处理过相应请求,尚未收到结果,则记录新Interest包的进入接口后丢弃,等收到相应Data包后,再向所有相应接口进行转发;否则通过查找FIB(Forwarding Information Based)进行最长前缀匹配来确定下一跳节点[3].
虽然,NDN具有如缓存和内置多播等诸多特性,但还需深入研究.例如,缓存特性使得NDN能够缓存收到的内容,从而节点能够直接响应后继收到的Interest包,进而缩短路径长度和提高传输效率.但由于节点的缓存空间有限,目前经典的处处缓存(Leave Copy Everywhere,LCE),即cache everything everywhere,造成严重的缓存冗余和频繁缓存替换.因此需要设置一个合适的缓存策略.
本文设计了一种NDN中的节点缓存策略,每个节点通过自身收发Interest包情况来分别计算主观视角下的每类内容流行和偏好,得到每类内容的基本缓存优先级,从而在收到Data包后,结合内容大小评估来计算具体内容的缓存优先级,进行缓存和执行相应缓存替换策略.这种更侧重节点主观的内容流行无需节点间频繁通信开销,而且兼顾偏好的特性更符合节点局部视角,从而能够具有更高的缓存命中率和更低的缓存替换率.
2 相关工作
缓存策略使得节点能够通过缓存内容直接响应后继收到的相同请求,从而提高响应效率,受到了相关研究人员的广泛关注[4].由于信息中心网络的分布式结构,很难采用集中式管理架构模式,节点往往通过自身信息判断是否缓存经过的内容,因此,NDN中采用的最经典的缓存策略是LCE,即Data包在返回过程中在经过的每个节点处都要缓存,这不仅导致网络中出现大量冗余内容,而且受节点缓存空间限制,会频繁发生缓存替换.文献[5]提出了一种概率缓存策略(Leave Copy Probability,LCProb),即Data包在返回途中以一定概率缓存.两种缓存策略虽然简单易行,但缺乏对于内容和节点特性的分析.
为降低缓存冗余,提高内容多样性,显然需要在缓存节点间进行有效协同,根据其复杂性,可大致分为显式协同和隐式协同[6].前者需要了解内容访问模式和节点缓存等具体信息,通过复杂计算来确定节点缓存策略,可进一步分为全局协同、路径协同和邻域协同.其中,全局协同需要对网络整体拓扑结构等详细信息具有深入了解.例如,文献[7]定义了度中心性、紧密中心性和介数中心性,以分别衡量节点的邻居个数、与其它节点的紧密程度和控制信息传输的能力,从而尽量将内容缓存在网络拓扑的关键节点上;路径协同是指在Data包从响应节点到请求节点的传输路径上的节点进行协同决策,例如协同沿路缓存[8]中的Interest包会沿途收集节点状态和请求频率等信息,响应节点据此计算出优化的缓存位置和相应的替换对象,这种方式需要Interest包收集大量信息,不仅造成额外开销,而且泄露节点存储信息,不适合未来高安全性需求;邻域协同是指在节点的邻域范围内显式地进行缓存放置协作.例如,文献[9]通过运行一个后台程序来定期地或事件触发地清理邻域范围内的冗余缓存内容.显式协同方式虽然降低了内容在全局、路径或邻域范围内的缓存冗余度,有助于提高整体效用,但需要提前知道缓存节点的状态信息和用户对内容的请求频率等信息,而且计算方式比较复杂,易造成大量额外开销,更不利于安全性保障.隐式协同缓存策略是指每个节点无需了解其他节点的信息或只需要交互很少的信息就能自主决定是否缓存,更适合NDN环境.前面分析的LCE和LCProb都属于隐式协同缓存策略.
近年来,对于缓存策略的研究有两个方向非常值得注意:内容流行度和自私缓存[10].其中,基于内容流行度的缓存策略通过缓存网络中流行的内容来降低网络流量和减少时延[11].文献[12]提出一种基于流行度的协作缓存策略,利用全局流行信息来调整缓存放置策略,以在具有多个网关的网络服务供应商间和多路径路由中降低供应商间的流量和内容访问时延.文献[13]将垂直请求路径上的冗余消除和水平局域范围内的内容放置相结合,分别提出基于最大内容活跃因子的路径缓存策略和基于一致性Hash协同缓存的局域定向存储策略,从而提高缓存命中率.文献[14]提出了一种基于流行度的邻居协作缓存策略,通过计算数据传输代价,将内容缓存在流行度最大节点或邻居协作缓存节点,并记录邻居节点缓存内容,从而降低数据传输代价和提高邻域缓存空间利用率.自私缓存是指随着认知论的不断发展,人们不再默认网络中节点都是合作的,而是承认节点的自私性,只有当对自身有益时,节点才会与其他节点协作.文献[15]采用组密钥加密来控制群组间数据获取,从而解决自私缓存问题.
由于节点空间受限,因此当缓存空间已满,但节点又需缓存新内容时,需要设计缓存替换算法.其中,最近最少使用(Least Recently Used,LRU)和最不经常使用(Least Frequently Used,LFU)是应用最广的两种替换算法,前者替换最近一段时间内最长时间没有使用的内容,后者替换最近一段时间内使用次数最少的内容.为尽量减少替换次数和重要内容不会轻易被替换出去,研究者们往往聚焦于内容流行度和优先级.例如,文献[16]在CS中加入一个内容流行表以存储缓存命中率和内容流行度等信息,使得节点能够周期性地计算内容流行度,从而替换出流行度最低的内容,但该策略需要消耗大量资源去维护内容流行表.文献[17]通过特定的名字前缀来识别全域范围内的优先级,进而实现高效内容分发.文献[18]周期性计算CS缓存表中缓存内容的动态流行度与请求代价的加权值,一方面基于该值进行缓存替换,另一方面根据该值进行内容分类,执行区分化缓存策略.
从上述分析可以看出,由于能直接反映内容未来一段时间内被缓存的概率,因此内容流行性受到了广泛关注,但一方面现有方法,如文献[12-14]往往试图着眼全局因此导致开销增加和计算复杂,而且全局流行并不意味着局部一定流行;另一方面,考虑节点主观偏好能够促进节点合作,一定程度上解决节点自私问题.因此,本文通过节点自己收发Interest包情况从节点局部视角考虑内容流行和主观偏好从而判断每类内容的基本缓存优先级,不仅计算简单,无需额外开销,而且更能体现内容在节点的未来缓存概率,又适度解决了节点自私问题.最后,在每类内容的基本缓存优先级上加入内容大小的评估从而得到每个具体内容的存储优先级,以作为缓存和替换的依据.
3 缓存策略
3.1 基本思想
我们首先应用NDN的层次命名机制来表示内容和内容类型,con_k_l表示内容,CCon_k表示内容类型,con_k_l∈CCon_k;其次应用内容流行来反映网络中内容被需求情况,为降低节点周期交流造成的开销,我们统计节点收到的Interest包以计算每类内容的被请求比例来反映其局部视角下的流行性;再次应用节点偏好来反映自身对不同内容类型的喜爱程度,我们统计节点发送的Interest包(节点相连的终端主机发送的内容请求)以计算每类内容的请求比例来反映其偏好;然后将内容流行和节点偏好结合起来表征不同类型内容在节点处的缓存基本优先级,使得不仅能够通过缓存流行内容来提高节点缓存效率,而且能够通过满足偏好来促进节点合作;最后结合内容大小评估来计算具体内容在节点处的缓存优先级,从而使得当收到Data包时能够准确判断节点是否缓存以及如何替换.
3.2 参数定义
3.2.1 内容流行
为方便计算,我们应用节点收到的来自其它节点的对某一类内容的Interest包数量与其收到的所有Interest包数量的比值来表征流行度,如公式(1)所示:
(1)
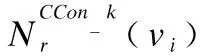
3.2.2 节点偏好
我们应用节点发出的对某一类内容的Interest包数量与其发出的所有Interest包数量的比值来表征其偏好度,如公式(2)所示:
(2)

3.2.3 缓存基本优先级
通过上述分析,我们设定缓存基本优先级由内容流行和节点偏好共同决定,如公式(3)所示:
caprCCon_k(vi)=wpo×poCCon_k(vi)+wpr×prCCon_k(vi)
(3)
其中,caprCCon_k(vi)表示CCon_k类型内容在节点vi处的缓存基本优先级,wpo和wpr分别表示内容流行和节点偏好的权重,且0<=wpo,wpr<=1,wpo+wpr=1.显然该类内容在网络中越流行,节点对其越偏好,则该类内容在节点处越应该被缓存.
3.2.4 内容大小评估
我们应用内容大小表征其在缓存中占据的空间.为降低内容大小对于缓存的影响和保证大内容也有一定的存储机会,我们引入如公式(4)所示的评价函数来计算具体内容大小评价值.
cscon_k_l(vi)=
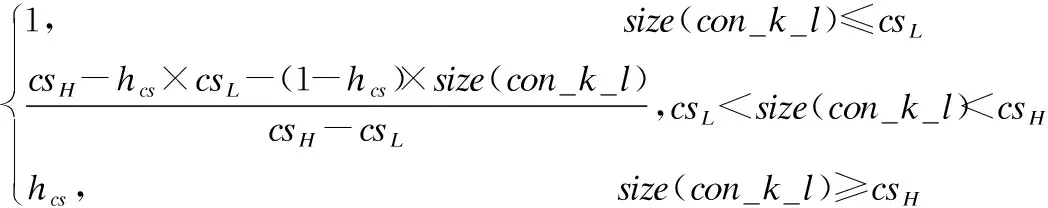
(4)
其中,cscon_k_l(vi)表示节点vi对内容con_k_l大小size(con_k_l)的评价值,csL和csH是内容大小的最低和最高阈值,可根据节点缓存空间自行设定,hcs是一个很小的正小数,表示当节点大小超过阈值上限时的评价值.
3.2.5 缓存优先级
我们在缓存基本优先级和内容大小评估基础上设计缓存优先级以反映具体内容con_k_l在节点vi处存储的优先级别,如公式(5)所示:
caprcon_k_l(vi)=caprCCon_k(vi)×cscon_k_l(vi)
(5)
3.3 缓存策略
3.3.1 缓存优先级更新
为及时更新反映节点对网络的局部视角,我们设定定期更新机制,在每个更新周期(update_circle)结束,节点更新其保存的每类内容的流行度和偏好度,以及缓存基本优先级,如公式(6)所示,以保证缓存策略的正确执行.
(6)

3.3.2 缓存策略
节点在运行前分配好缓存区域,因此当收到Data包,并且自身不是发出相应Interest包节点时,需要执行缓存策略,即首先判断该内容的缓存优先级是否超过阈值,如果没有超过阈值,则放弃存储;如果超过且缓存有足够空间,则直接存储;否则,执行缓存替换策略,即根据公式(5)计算得到的缓存优先级,按从小到大顺序在缓存内搜索低于新到内容缓存优先级的那些内容,直到找到的内容大小总和超过新内容,将它们清除以存放新内容,如果找不到则意味着需要将某些缓存优先级更高的内容替换出去才能放入新内容,代价太高,放弃存储.显然,在需要执行缓存替换策略时,本算法需要在一定范围内按优先级从小到大顺序依次累加,直到能为新到内容准备出足够空间.考虑到内容缓存优先级和大小实际情况,在绝大多数情况下,该算法涉及的内容规模较小,效率较高.详细过程如算法1所示,其中输入是收到的Data包和缓存CS,输出是新缓存CS*.
算法1.caching strategy
Input:CS,Data;
Output:CS*
1:Calculatecaprcon_k_l(vi)of Data packets;
2:if(caprcon_k_l(vi)≥caprth)then
3:if(there is enough space in CS)then
4:Cache contentcon_k_l;
5:else
6:forthe cached contents from small to large order of prioritythen
7:ifthe priority of the current content is smaller thancaprcon_k_l(vi)then
8:ifthe sum of the size of all contents is larger than size(con_k_l)then
9:Replace these contents with contentcon_k_l;
10:Break;
11:endif
12:else
13:Break;
14:endif
15:endfor
16:endif
17:endif`
在算法1中,line 1表示计算收到的Data包中的内容的缓存优先级;lines 3-4表示如果节点缓存足够,则直接缓存;lines 6-15表示按缓存优先级从小到大的顺序搜索内容,如果在优先级小于新内容的内容中找到的内容大小总和高于新内容,则执行缓存替换,否则放弃本次缓存.本算法最坏情况下的时间复杂度为O(N),其中N表示节点内已存储内容数量,而在普通情况下的时间复杂度为常数O(K),即节点只需将缓存优先级最小的几个内容替换出去即可缓存新到内容.
4 仿真实验
4.1 实验设置
我们应用linux 4.10.8-1下的gcc 6.3.1来模拟实现本文提出的结合内容流行和节点偏好的缓存机制(Cache strategy based on Content Popularity and Node Preference,CCPNP).拓扑结构分别为中国的CERNET2(20节点,22条边)、美国的ITC Deltacom(97节点,121条边)、欧洲的GTS CE(130节点,166条边)和OTEGlobe(61节点,69条边)4,具体如图1所示.为便于分析,我们设定26种Interest包类型,并遵循zipf分布,同时引入“单位时间”的概念,每个节点在每个单位时间内发送1个Interest包.
图1 网络拓扑图
评价参数分别为缓存命中率(Cache Hit Rate)、缓存替换率(Cache Replacement Rate)和平均请求距离(Average Request Distance).其中,缓存命中率是指节点从缓存中获取到内容的次数占获取内容总次数的百分比;缓存替换率是指缓存时发生替换的次数占缓存次数的百分比;平均请求距离是指从发出Interest包的节点到返回Data包的节点的平均距离(以跳数为单位).
实验中相关参数分别设置为:α=0.75,wpo=0.5,wpr=0.5,update_circle=20单位时间.

表1 仿真实验参数设置
4.2 实验结果及分析
在图2中,我们比较CCPNP和LCE、LCProb在四个不同拓扑下的缓存命中率,横坐标为每个节点平均发送的Interest包总数,纵坐标为不同缓存策略的缓存命中率.显然,随着节点发出的Interest包数量的增加,网络中返回的Data包数量也相应增加,因此三种不同策略的缓存命中率都呈增加趋势.
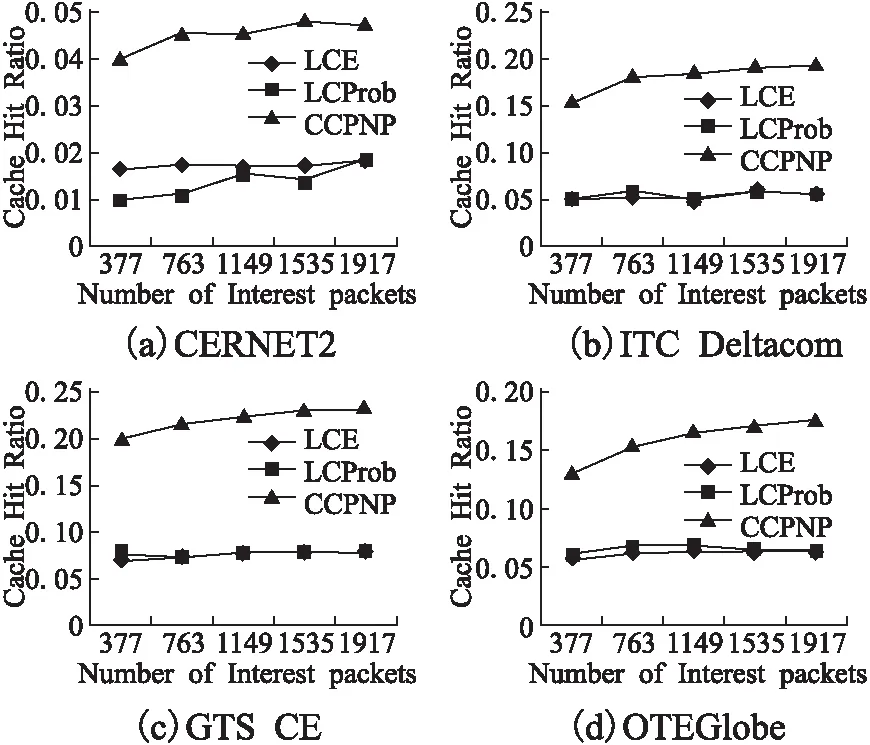
图2 缓存命中率比较
其中,由于考虑了内容流行和节点偏好,CCPNP的命中率显然远高于采取处处缓存方式的LCE和采取概率处处缓存的LCProb.由于采取概率缓存的方式,LCProb的命中率略高于完全缓存的LCE.
4http://www.topoloty-zoo.org/dataset.html
值得注意的是,由于CERNET2中只有20个节点,低于OTEGlobe的61个节点,更低于ITC Deltacom的97个节点和GTS CE的130个节点,使得在每个节点发出的Interest包数量相等的情况下,相应Data包从回应节点到请求节点的路径经过的节点数量较少,被缓存的数量相应较小,所以CCPNP、LCE和LCProb的缓存命中率按从小到大的顺序依次为CERNET2、OTE Globe、ITC Deltacom和GTS CE.过低的节点数量也使得在Interest包数量比较少的时候,LCE在CERNET2中取得了比LCProb略好的缓存命中率.
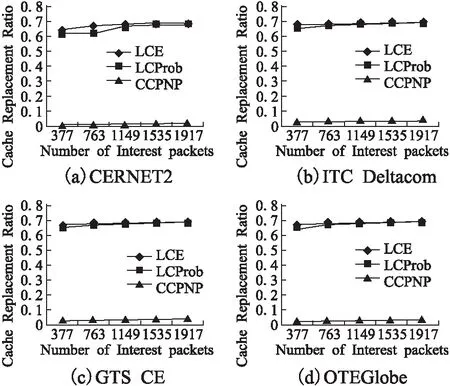
图3 缓存替换率比较
图3显示的是四种不同拓扑下三种策略的缓存替换率,可以看出,CCPNP的性能远远低于LCE和LCProb,原因是首先CCPNP在执行缓存策略时考虑了内容流行性和节点偏好性,从而尽量存储那些在未来更容易被请求的内容和更被自己喜欢的内容,可以以更大概率直接响应未来收到的Interest包,避免潜在的缓存替换操作;其次,CCPNP在执行缓存策略前有一个阈值判断过程,这使得一些优先级极低的内容不会被缓存,进一步降低了未来发生替换的概率;最后,CCPNP考虑内容大小,合理降低了一些占据空间过大的内容被缓存的概率,综上,CCPNP在每个拓扑上都取得了非常低的缓存替换率.
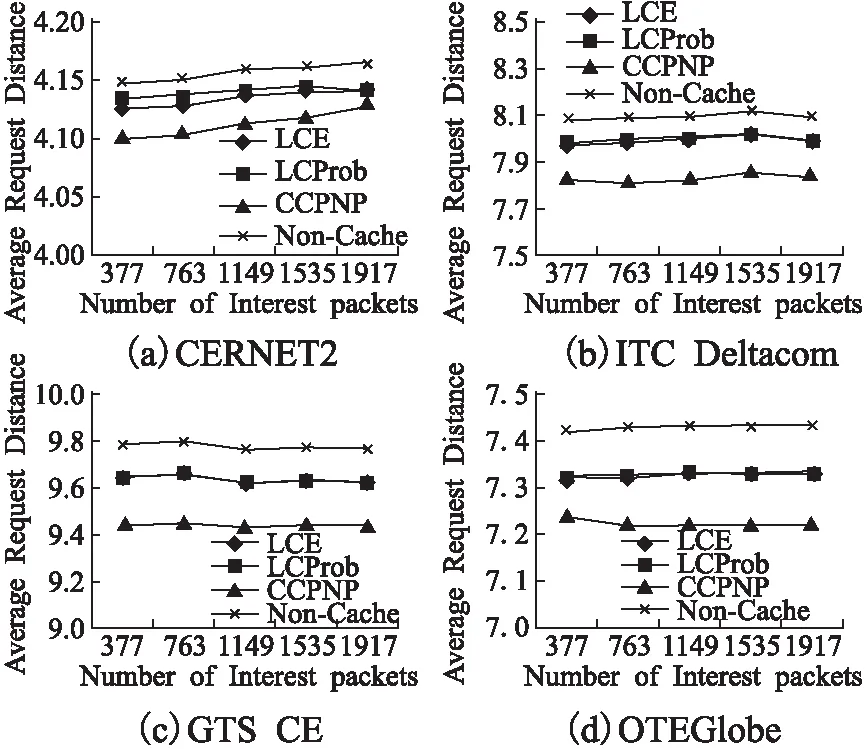
图4 平均请求距离比较
为进一步展现缓存策略对于网络性能的影响,特别是对于网络流量的影响,我们在四种不同拓扑下比较了三种缓存策略的平均请求距离,如图4所示,CCPNP的性能低于LCE和LCProb,这是因为CCPNP能更好地协调内容的缓存位置和节点的缓存内容,更有效地利用节点的缓存空间.为更好地进行比较,我们还加入了无缓存机制Non-Cache,可以看出当节点没有缓存机制时,平均请求距离值最大,因为节点只能从原持有节点处获取请求内容.虽然,LCE和LCProb的缓存机制效率较低,但毕竟能够在内容持有节点到请求节点的路径上进行相应缓存操作,因此较Non-Cache机制降低了平均请求距离.
5 总 结
针对现有NDN缓存机制存在严重缓存冗余,基于全局流行度的缓存机制需要大量协助开销,以及节点自私等问题,本文为NDN设计了一个节点主观视角下结合内容流行和自身偏好的缓存策略,通过对内容类型的流行度和节点偏好来表征不同内容类型在节点处的缓存基本优先级,进一步结合内容大小评估来表征具体内容在节点处的缓存优先级.实验结果表明该缓存策略比主流的LCE和LCProb具有更高的缓存命中率、更低的缓存替换率和更短的请求距离.
在未来工作中,我们一方面将引入其它协同方法以通过节点间的交互来强化节点对于全局内容流行的深入挖掘,并对取得性能和协同交互所需代价之间进行深入权衡分析;另一方面在节点偏好研究基础上,通过引入信任模型来解决存在自私节点的NDN网络环境中节点合作缓存问题.
