基于系统聚类的高速公路超载超限分析
2018-10-15李保龙王晓峰
李保龙,王晓峰
(上海海事大学信息工程学院,上海201306)
0 引言
公路运输在国民经济发展中具有重要作用,相比于铁道运输、空中运输、航海运输具有方便快捷、价格低廉、机动性强、服务面广等优势,占据了运输方式的主导地位[1]。但受利益驱动,车辆运输中经常出现超限超载现象。超载超限就是公路运输中出现货运车辆实际装载量超过道路限定装载量的现象[2]。超限超载会导致公路损坏,严重缩短公路使用寿命,容易引发安全事故,还会扰乱运输市场秩序,阻碍公路运输事业的发展[3]。因此,分析车辆超载超限的规律,进一步降低车辆超载超限,能够有效降低高速公路的维护费用,减少由超限超载所引发的交通事故从而避免重大经济损失,有助于高速公路的健康发展。
目前高速公路超载超限治理多以车辆自动识别管理系统的研究与联网检测的结合。例如美国使用传感器技术,全美约有1000多个动态称重站,采用视频采集设备和路边控制器技术,通过计算机系统与高速公路巡警的电脑相连接,对货车进行捡测,及时获得检测数据和鉴别超载车辆的身份[4]。日本多采用静态固定的或移动的称重设备对超限车辆进行检测,南非也很重视自动称重技术的研究和应用,并且将电子称重设备应用于治理超限超载工作中。王鹏、刘震、刘强等人从高速公路车辆超限检测联网系统的应用来检测车辆超载超限[5]。我国采用设立固定检查站和抽调人力在高速公路上抽查等方式检查车辆超载超限情况。这种方式存在检测范围有限、车辆选择辅路逃避检测、耗费人力物力较大、检测过程时松时紧等问题。因此分析车辆超载与时间、季节的关系是很有必要的,这样能够为科学合理的分配人力物力、节约资源作出指导。
为了使检测站科学合理地分配资源,本文从时间角度应用系统聚类方法对车辆超限率问题进行分析,客观反映了车辆超限率的现状,为有效降低高速公路超载超限率提供理论依据,解决成本过高和检测站车辆通过效率的问题,提高高速公路治理水平。
1 数据处理
本文的原始数据源于某省高速公路联网监控系统2016年全年的实际监测记录,由于人工操作不规范和工作繁杂,实际记录数据量庞大,存在很多无效的数据,无法直接应用。因此,在进行数据聚类分析之前有必要对数据进行预处理,解决原始数据中不一致、重复、纬度高等噪声问题[6]。处理中应选取合适的属性,尽可能赋予属性名和属性值明确的含义,统一多数据源的属性值编码,去除惟一属性,去除重复性,去除可忽略字段,合理选择关联字段为主要原则[7]。具体处理如下:
(1)数据存储方式转换。原始数据为2016年1月至2016年12月的CSV文件,文件存储量巨大不易处理,所以需要把文件存储到MySQL数据库中。
(2)数据预处理。对以下不同情况采取的处理方式:
①数据缺失。数据元素缺失分两种情况:第一种是无效属性字段的缺失,这种情况下直接将该属性丢弃;第二种是部分字段缺失,数据元素不能补全,这种情况应忽略该记录。例如:记录中ETC车辆电子标签OBU编号、支付方式代码属性并未录入,并且该属性也使用不到,所以对其作丢弃处理。
②数据错误。原始数据部分字段的数据是错误的,不能达到本文数据处理要求,所以对这些数据进行修复处理。修复分为三种情况:第一种情况:部分字段错误的数据,该记录直接丢弃;第二种情况:部分字段缺失,需要手工填写空缺值;第三种情况是字段的部分缺失,这时要进行截取。例如:部分时间是1997年开始的,这些记录是操作失误或者仪器调试的无用数据,应丢弃;有些记录的超限率为空值,可以根据载重和核重计算出来。
③数据过滤。一般来讲,车辆超载之后才有超限率,所以对结果数据中超出该范围的数据进行过滤,降低错误记录对结果的影响。
2 车辆超限率聚类分析模型
车辆超限率能够较好的反映出车辆超载超限的情况。降低车辆超限率就表示有效地治理了车辆超载超限现象,因车辆超限超载而造成的道路交通事故就会减少,道路运输市场秩序将得到明显好转,公路通行率和运输效益就会得到提高。设车辆实际载重为w(单位:吨),车辆额定载重为u(单位:吨),车辆超限率为v,定义超限率如(1)式所示。

为了分析出不同时间段车辆超载情况,我们定义车辆平均超限率,表示在单位时间内每辆车的超限率之和与通行车次的均值。平均超限率可以较好地体现车辆在不同时间段的超载情况。如果时间跨度大,就对车辆超限的作用减小。考虑到以月和季度划分时间跨度大,对车辆超载超限影响太大,另外由于数据量庞大,数据不易处理,所以取车辆平均超限率的时间单位为每小时。以每天0-24小时为总的统计时间段,分析各个时间段车辆超载超限的变化规律。平均超限率为vˉ,单位时间内通行车次为n,vi表示每辆车的超限率,,其中未超限车辆超限率为0,平均超限率定义为式(2)。

3 聚类方法和原理分析
聚类分析就是按照某个特定标准把一个数据集划分成不同的类或簇。通常划分后同一簇内的数据特征相近,不同簇间的差异很大。聚类的属性语言描述为:
初始时将每小时的平均超限率作为一簇,然后计算各小时超限率之间的距离,选择特征距离最小的一对合并成新簇,计算新簇与其他簇之间的特征距离,再将特征距离最近的两个簇合并,循序渐进,直至所有小时的平均超限率归并一簇为止。
设 Ni表示小时特征,把 N1,N2,N3,…,Nn各自为一簇,Vi表示 Ni的平均超限率,dij表示Ni与Nj之间的特征距离:

聚类步骤:
(1)使用式(3)计算各个小时特征之间的距离,得到特征距离矩阵D0,各时间段集合自成一类。
(2)在矩阵D0非对角线的元素中找出最小元素,设为 dij,将 Ni和 Nj合并成新的簇 NM1,则{Ni,Nj}即NM1的全部样本,使用式(2)计算出NM1的平均超限率。
(3)使用式⑶计算NM1与其他时间段特征的距离,得到距离矩阵D1。
(4)重复(2)(3)步骤,直到所有的小时特征归为一个簇。
例如:N1,N2,N3,N4的平均超限率为2.2245,2.7173,3.1212,3.3530,第一步计算出D0矩阵(因为特征距离得出的为对称矩阵,因此只展示上三角矩阵)如表1:

表1
第二步可以得出D0中计算将N3和 N4特征距离最近,合并成新的簇 NM1,接着计算NM1与其他属性的特征距离矩阵D1,如表2:
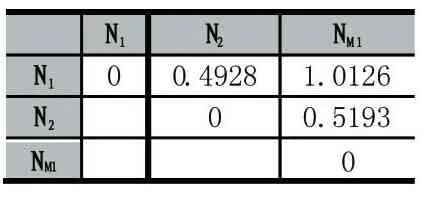
表2
重复以上步骤,直到所有的特征分为一个簇为止。
4 车辆超限率聚类分析
4.1 数据选取
2016年分为四个季度,可以分析出季节对超限率的影响,对超限车辆的时间属性进行分析,探讨超限率分布规律。
4.2 平均超限率聚类分析
把时间序列分成不同簇,对图1中四个季度聚类谱系图进行对比分析,为了更清楚地描述车辆超载的严重程度,使用A、B、C三个等级来表示(A表示严重超限,B表示一般超限,C表示轻微超限),把每个季度的平均超限率以表格形式表现,如表3所示。由表3可知,各个簇分别按照A、B、C各自的平均超限率依次降低,可以清晰的显示四个季度车辆平均时间超限率的差异。同样的对图2的2016年全年谱系图进行分析,由表4显示超限率在时间上的差异。

表4 2016年全年数据聚类结果

图1 2016年各季度聚类谱系图

图2 2016年全年聚类谱系图
系统聚类算法根据每个时间段的平均超限率把24个时间段对应的数据分成了不同的簇,再根据不同超限率水平将簇分为高、中、低三类,分类结果如表3所示。从表3中可以看出,车辆在1-6h时间段内的平均超限率在四个季度都比较严重;在19-24h时间段四个季度的平均超载率表现一般;在12-17时间段四个季度内平均超限率都较低。在第一季度内车辆超限程度分布的时间段也和其他季度差别较大,第一季度严重超限集中分布在1-11时间段之间,而其他几个季度相差不大且集中分布在1-6时间段,说明车辆受季节的影响较大。对比表3和表4车辆严重超载的高峰期在1-6时间段,这个时间段应加大超限检测和治理力度;在19-24时间段内超载率一般,在这个时间段内保持正常检查力度即可;在12-17时间段内平均超载率较低,说明下午的超限平均水平较低,应适当减少交通检测人力投入。根据不同时间段超限率的高低决定检测及相关人员的投入力度,可以最大程度的节约人力等相关资源,提高交通部门的管理水平和治理效率。同时交通管理部门可以结合不同的季节合理调整工作人员的上班时间,有效提高工作效率。
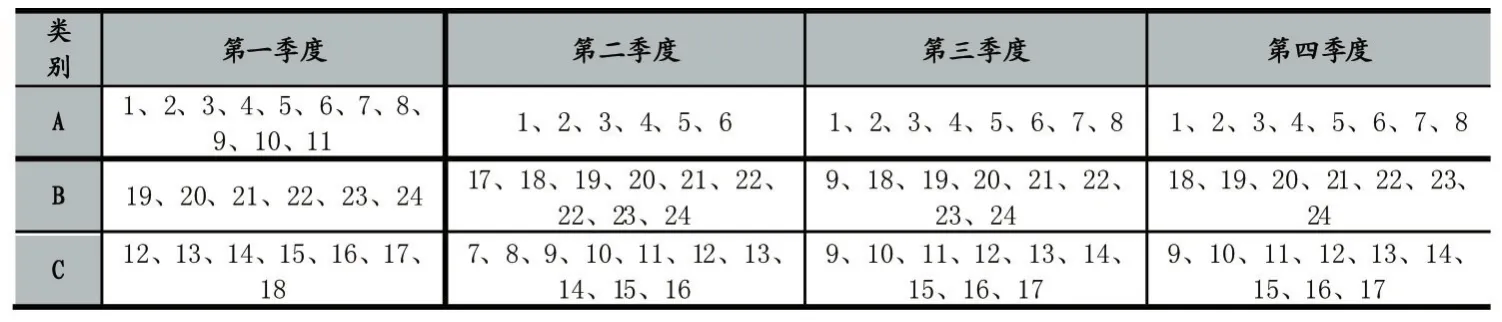
表3 2016年各季度聚类结果
5 结语
本文构建了车辆超载超限模型,结合单位时间内的平均超限率对24个时间段车辆平均超限率进行了分析。以2016年全年高速公路通行流水数据为研究对象,运用系统聚类方法对一天24小时时间段进行了聚类分析,挖掘出车辆超载存在的时间特征和规律。高速公路检测站可以在车辆超载超限严重的时间高峰期采取措施,例如加大力度检查,上路抽查等手段去检查过往车辆,以此来降低车辆超限率。在车辆超载超限较低的时间段内减少人力物力投入,以此来节约成本。
