基于聚类的W i-Fi与移动智能终端商场室内定位
2018-10-15周明王晓峰
周明,王晓峰
(上海海事大学信息工程学院,上海201306)
0 引言
在互联网爆炸的时代,人们对位置信息的关注越来越多。基于位置的服务(Location Based Service,LBS)是指通过用户当前定位信息,根据用户需求为其提供相应的服务。LBS作为定位技术的核心,在导航、人员跟踪、室外游戏、物流等诸多方面得到了应用,它能够根据移动对象的位置信息提供个性化服务[1]。室外定位系统主要有四大卫星导航系统,分别为美国的GPS、俄罗斯的GLONASS系统、中国的北斗系统、欧盟的Galileo系统[2]。当今社会主流的室外定位技术之一是全球定位系统(Global Position System,GPS),其通过卫星获取地理位置信息[3]。GPS拥有建设和运行时间长,技术成熟,性能稳定可靠,定位精度高,适应能力强,应用广泛等优点,可以较好地满足户外定位需求,然而在封闭的室内,由于布局复杂和障碍物对信号的干扰严重等缘由,GPS通常不被使用在室内定位[4];室内的定位技术有:①室内部署红外线设备来定位的方法[5];②室内部署超声波设备来定位的设计方案[6];③室内部署射频设备来定位的方案[7-8];④室内部署UWB设备来定位的方案[9-10]。虽然以上方法能得到较高的精度,但在实施前需要安装昂贵的设备和定位前需要采集必需的位置信息,这就使得这几种方法得不到普及[5]。
随着Wi-Fi技术的成熟和无线网的普及,基于Wi-Fi的室内定位技术不断成为研究热点。Wi-Fi信号能被用于定位的特征有ID、强度、传播时间、接受角度等。其中,基于Wi-Fi信号的接受强度指示(Re⁃ceived Signal Strength Indication)的应用尤为广泛。根据采用的算法各异,定位模型可分为两种:基于信号传播模型的定位和基于位置指纹识别算法的定位[11]。
基于信号传播模型的定位是对无线网的传播信道进行建模,这种定位方式难度较大,因为需要用数学模型去拟合障碍物难以模拟的特征。基于位置指纹识别的定位方法通过提取指纹数据库中的模式特征,与信号传播模型不同,通过构建RSSI信息与位置信息之间的函数关系,降低定位的复杂度。
本文在基于位置指纹识别的定位算法研究传统的K近邻(K Nearest,KNN)方法在Wi-Fi定位中的应用,提出基于簇和KNN相结合的室内定位算法,并将两者的定位效果进行比较。
1 定位算法
1.1 传统指纹搜索算法
指纹算法是在复杂的室内环境下,针对特征参数有变动性而进行匹配的一种识别技术。该算法的实现分为离线阶段和在线阶段这两个过程,如图1所示。离线阶段的主要内容是将训练集数据按照映射关系存储到数据库中,在数据库存储着m×n的指纹库矩阵,其存储方式如表1,其中RSSij(i=1,2...,n;j=1,2,...,m)表示第j个APs在第i个检测点的RSS值,其目的是为了让在线阶段更好地根据数据库匹配数据。在线阶段的目标是对未知位置的用户进行位置估计,其做法是将该用户的特征信息(在本文是RSS值),根据特定的匹配算法,在数据库中搜寻特征与之最相似的特征点,然后将其归于该类中。特定的匹配算法主要有K近邻(K-Nearest Neighbor,KNN)、决策树和支持向量机等算法。
机器学习算法之一的KNN算法,因其简易且方便而被经常使用,其原理是通过计算未知类别样本的特征信息与K个最相似的参考点,然后将未知类别的样本归于这K个最相似的点中,出现类别个数最多的那一类。
传统定位匹配KNN算法过程如下:
(1)输入要估计位置的数据r,计算其与各个训练数据ri之间的相似度,其公式如下:

rij表示第j个Wi-Fi源到第i个点的信号强度;
(2)按照相似度大小顺序进行排序;
(3)选取相似度最大的的K个已知类别的数据点;
(4)计算前K个点各类别点出现的次数;
(5)将未知类别点的预测类别定位前K个点中,出现频率最高的类别[12]。
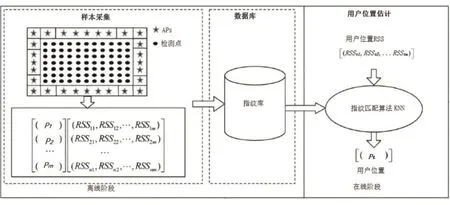
图1 基于传统指纹搜索算法的室内定位流程图
该传统的定位算法有一个必要的过程,就是在每执行一次KNN算法时,都需要遍历数据库中所有的APs,当然在匹配少数据量时,其匹配速度还可以接受,然而在匹配大量数据量时,要找出K个相似度最大的值,系统的时效性不容乐观了。为解决这个系统时效性问题,本文将引入指纹簇的所搜方法,在保证室内定位的准确率情况下,能够减少算法在匹配时搜索的数量,减少估计时间和计算量。
1.2 本文簇类指纹定位算法
(1)按经纬度聚类的指纹定位算法
本文簇类指纹定位算法的目标是在保证定位的准确率情况下,减少搜索的数据量,减少估计的时间和计算量,图2是簇类指纹定位算法的流程图。其工作模式和传统定位算法的工作模式相同,也包含离线阶段和在线阶段,然而优势之处是将训练数据按使用K-means算法聚成簇后存储在数据库中。离线阶段中,使用K-means方法把数据集分成不同簇,并把每个簇包含位置的无线网特征存储在数据库中。在线定位数据匹配时,先对数据进行簇匹配,然后进行指纹定位匹配。在线阶段将未知位置的数据,使用分级的搜寻模式,先用KNN算法将其归于簇类中,确定簇类,然后在簇类中使用传统的指纹定位算法,将其所在的位置估计出来。
Means聚类方法:
K-means算法是机器学习中的无监督分类算法,它是根据距离来确定类别分类的,距离越大,其相似性越低,距离越小,其相似性越高。
具体如下:
输入:k=97,data[n];
①随机选择97个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];
②对于 data[0]….data[n],分别与 c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
③对于所有标记为i点,重新计算中心坐标c[i],n为该类所有实例数目

④重复②③,直到所有c[i]值的变化小于给定阈值或达到指定迭代次数。
簇类KNN算法实现:
①输入要估计点r的经纬度值(W,S),计算其与各个训练数据ri之间的相似度,其公式(3)如下:
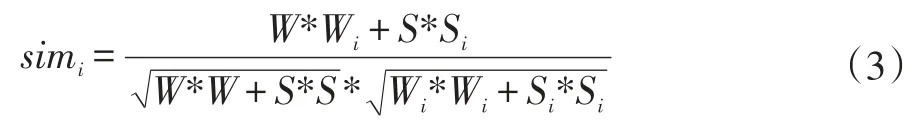
W表示地球的经度值,S表示地球的纬度值,Wi表示第i个点的经度值,Si表示第i个点的纬度值;
②按照相似度大小顺序进行排序;
③选取相似度最大的K个已知类别的数据点;
④计算前K个点各类别点出现的次数;
⑤将未知类别点的预测类别定位前K个点中,出现频率最高的簇中[12]。

图2 基于簇方法的定位流程图
本方法虽然能够在很大程度上减少定位时搜索的数量,提高系统的时效性,但是由于在按经纬度聚类时会出现归类错误,导致在线定位阶段出现无法定位的数据,从而降低定位的准确度。所以,就提高聚类的准确度,需要有所研究,下文提出根据无线网进行聚类。
(2)按无线网聚类的指纹定位算法
依据无线网发射器的识别码具有唯一性的特性,本文提出一种根据无线网识别码来聚类的方法,然后再使用上文的定位法进行定位。图3是根据无线网识别码分簇图。而整个定位算法工作模式和基于KNN聚类的指纹定位算法的工作模式相同,也包含离线阶段和在线阶段,相对于基于K-means聚类的指纹定位算法的优势在于按照无线网的识别码来将数据进行簇类聚类,这样可以提高聚类的正确率,然后将训练数据按簇存储在数据库中,在数据匹配时,也是先按照无线网识别码对数据进行簇匹配,然后进行指纹定位匹配。离线阶段中,把数据集根据不同商场为簇来分开,并把每个簇包含位置的无线网特征存储在数据库中,呈现出一种分级存储格式。在线阶段将未知位置的数据,使用分级的搜寻模式,先根据无线网识别码将其归于簇类中,确定簇类,然后在簇类中使用KNN指纹定位算法,将其所在的位置预测出来。通过以上这种做法,可以极大地减少了遍历数据库中的数据个数,较少的计算量,达到可靠地系统时效性。

图3 按识别码分簇图
理论分析本方法具有更好的聚类效果,能够为在线定位提更高的数据匹配环境。
2 实验与结果分析
2.1 数据清洗
本实验数据来至阿里竞赛数据集,97个不同的商场和54个店铺类型在某月份的客户发生交易行为的实际记录,数据集包含两部分,其中一部分是店铺与商场的对应关系,记为U,拥有的字段如下:商场id,店铺id,店铺经纬度,店铺类型,和消费金额,另一部分数据集是发生交易数据集,记为C,含有的字段如下:店铺id,发生交易的时间,发生交易时的地球经纬度数值,发生交易时的Wi-Fi信号强度数值,用户id。在数据集中,需删除无意义的字段,如消费金额和用户id。由于在智能终端(手机)定位时,定位往往会发生不准确的,偏离真实地点很远的点,以及流动热点的Wi-Fi情况,所以数据不能直接使用,需要对数据进行数据清洗,具体处理如下:
数据存储方式转换,原始的CSV格式的文件不好清洗,所以利用Navicat for MySQL把CSV格式的数据存到MySQL数据库中。
数据处理,对数据做以下处理:
(1)由于智能终端性能等多方面因素,经纬度定位有偏离真实的数据,本数据的范围是国内,把所有点映射到地图上,可以确定把纬度高于50度和低于20度的数据清洗过滤,把经度低于100度高于130度的数据清洗过滤。
(2)将偏离点,单个点和聚类点数目个数聚集较少的点清洗过滤。
(3)如今的智能终端拥有开启手机热点的功能,这种热点将会极大地影响精度的计算,取交易时Wi-Fi标识码的交集,清洗过滤临时的热点Wi-Fi,将稳定的Wi-Fi标识码作为店铺的最终评判Wi-Fi。
(4)确定稳定Wi-Fi后,若某个数据Wi-Fi中没有相对应的Wi-Fi识别码,则将该Wi-Fi强度置0。
(5)把清洗好的数据集合理拆分,第二部分的数据集随机分成1/3和2/3,数据集的1/3为测试集,记为C1,数据集的2/3训练集,记为C2。
2.2 实验结果与分析
为了验证本文提出的簇类算法的系统时效性,将传统算法和本文提出的两种算法进行试验对比,将清洗好的实验数据输入上三种方法进行实验,得到实验结果如图4和表2展示,图4中红虚线代表传统指纹算法的实验结果图,绿线为本文算法的实验结果图,rate为实验的准确率,K_num是KNN的K值,K=1,2,3,4,5,6,7,表2为三种方法在线定位一次所需要的时间和在数据库中搜索的数目比例。从图中可知,传统的指纹搜索方法准确率比本文提出的第一种方法的方法要好些,但两者相差较小,但从表2中可知,本文提出的第一种方法在线阶段所花费的时间比传统方法的少了60%左右,搜索的数目也只占全部数据集的一部分,系统的时效性提高,计算量明显减少;传统方法相比较于本文提出的第三种方法,准确率两者几乎同等,但是在搜索时间和搜索数目上,本文第二种方法具有明显的优势,定位时间更短,搜索数目减少了59%左右。从实验结果可知本文方法的理论与实践皆优于传统方法。

图4 三种算法的实验结果图K_num是KNN的K取值,K=1,2,3,4,5,6,7,rate为实验的准确率

表2 传统方法与本文方法的定位耗时以及搜索数目
由图3折线看出,当K=5时,本文的定位准确率达到最大,为此取K=5时,将数据集按1:2的比例随机分配,继续用本文方法对数据做4次实验,得到四次结果,绘制图5,count_num_k=3表示第三次实验。从图5中可知,这四次实验的结果相对稳定,且第二种方法的准确度比第一种高些。
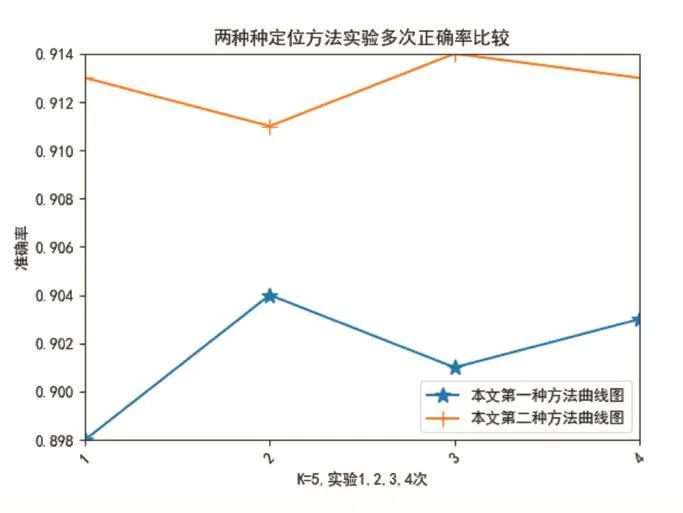
图5 K=5的本文方法4次实验结果
3 结语
本文通过介绍传统指纹定位算法的介绍,剖析其算法原理,指出其系统时效性不足的问题,并针对问题提出本文的两种簇指纹定位方法,将原始数据集按分级搜索,减少数据计算量,减少在线定位的时间,让系统时效性更好,同时还保证定位的准确性。最后通过实验来验证所提方法的可行性,实验结果得出:本文方法能够减少算法在匹配时搜索的数量,减少估计时间和计算量,让系统时效性让人更能接受。
