基于BP神经网络的国产电影票房预测研究
2018-10-15李奕王晓峰
李奕,王晓峰
(上海海事大学信息工程学院,上海201306)
0 引言
2017年中国电影总票房突破500亿大关,细数近10年,就中国电影票房而言,从2009年的100亿元激增到2017年559亿元,创造了各种票房神话。随着政府扶持政策不断出台,吸引了包括阿里在内多个互联网巨头投资影业,这种种迹象表明,我国电影市场正向产业化转型。然而经过调研表明,中国电影市场并没有表明上光鲜,除去国外引进片,多达七成的国产电影处于亏本状态,所以能否提前预测一部电影在上映之前的票房多少对投资人来说至关重要。
1 国内外研究现状
得益于国外电影业比中国成熟,国外学者在票房预测模型方面有很多建树,20世纪80年代李特曼票房模型[1]认为电影票房取决于创意、发行、营销三个方面,导演、演员、出品地、类型、续集、档期、提名、剧情、评分、发行公司这十大因素与票房相关。20世纪90年代斯格特·苏凯票房模型[2]认为电影票房主要包括创意、发行模式和市场推广三个方面,屏幕数量、分级、奥斯卡提名、奥斯卡获奖、档期、圣诞节上映、MPAAR分级、CR104等22个因素与票房相关。21世纪初陈白鹤等[3]提出电影票房取决于电影品牌、客观特征、专家的评级和观众的评级、经销商这四个方面,模型因素包括了预算、观众和专家评级、续集、屏幕数量、MPAAR、演员、剧本、档期、复活节上映等。2006年Sharda[4]提出以多层神经网络为基础对电影票房进行分类,但其数据收集时全部采用0,1赋值,丧失了数据的解释性。2012年Barman[5]等提出利用反馈神经网络算法对电影票房进行了预测,但其神经网络结构简单,只有一个隐藏层,也忽略了导演、演员等一系列影响因素。2013年Marshall[6]等提出结合电影实时观影人次进行动态预测电影票房。2014年随着大数据和云计算技术的迅猛发展,百度票房预测模型[7]利用搜索引擎和社交网络关键词的搜索量、转发量、评论量、各大主流视频网站电影预告片的点击量加上各项百度指数等诸多因素综合来预测电影票房,然而由于样本有些可以人为更改,“脏数据”的存在导致百度票房模型有时预测偏差过大,例如2014年上映的《黄金时代》,模型给出的两亿票房预测值与实际惨淡的4000万相去甚远。同年,郑坚[8]等在Barman的基础上根据电影上映期间的数据对BP神经网络进行了优化。2015年重庆大学李金芝[9]等提出了基于泛函网络的票房预测模型,通过先对电影进行聚类再预测的方法,但其仅选取了231部样本,其中15部作为测试集,一共选择了五个因子作为网络的输入端,误差精度也较大。2016年张慧[10]等提出基于深度学习对电影票房进行预测,但其仅选择2015年和2016年票房前25名共计50部票房相关数据作为样本,数据样本过小,导致说服力不大。2017年张雪[11]等探索性运用卷积神经网络对国内电影票房进行预测,但缺少制作成本、宣传成本、微博、电影评分等一系列相关数据导致结果不是非常理想。

表1 部分原始数据表
2 数据因子来源及说明
本文结合上述国内外现状,从豆瓣网、微博、时光网、艺恩网以及中国电影票房网这五个电影票房网站处选取了共计20个相关因素,并进行了适当的数据预处理,构建了一个国内电影票房相关因子数据集。其中微博2009年出现,导致相关数据仅能从2009年后开始搜集。因此本文选取了2010年到2017年这八年一共440部票房过千万的电影作品作为研究对象,由于国产电影的类型较为集中,因此本文未将电影类型选为因素,同时也去除了像音乐剧、动画剧、配音剧,爱国宣传剧等类型较少,数据无法考察的微量样本。除此之外,由于所有样本均是内地上映的国产电影,因此也未将出品地作为相关因子。
本文选取票房数据相关因素原始数据如表1,因子说明见表2。
3 实验模型构建及介绍
神经网络模型起源于人类对自身思维模式的探究,是一个非线性的数据建模工具,由输入层和输出层外加一个或者多个隐藏层,神经元之间相互连接并同时赋予相关权重,根据不同数据可以选择不同算法进行训练,通过不断调整学习率、偏置、网络权重等参数,从而当误差最小化时给出相应预测值。神经网络和传统的线性回归模型不同,它无需数据集的因变量和自变量有特定关系,随着大量数据进行不断迭代训练后,神经网络将自动接近最贴近的内在模型结构,从而建立函数内在映射关系。当前随着人工智能的复兴,针对各行各业的需求,越来越多的神经网络结构不断出现,并在图像处理、图像分类、导航、数据预测、通信等多个领域有了运用,这些运用正极大地改变人类的生活方式。

表2 数据因子说明表
本文采用的BP神经网络是所有神经网络中最为基础也是应用最广阔的模型之一。本文以电影票房数值为因变量,IP改编、特效、序列、出品公司、发行公司、档期为因子,剩余14个连续型因子作为协变量搭建模型。数据集划分为训练集和测试集,其比例为8:2如表3所示,采用交叉检验的方式,迭代次数5000次。模型结构如图2,其输入层共有20个神经节点,共计2个隐藏层,其中本文根据公式(1)-(3)选取了隐藏层节点个数,其中M代表隐藏层节点数,N代表输入层节点数,L代表输出层节点数,α代表1-10之间的常数,根据最佳节点选择公式,本模型分别试用了(9,4)和(7,3)节点数,经过多次测试发现当第一个隐藏层有9个节点,第二个隐藏层有4个节点效果最佳,网络信息如表4。此外激活函数选取了tanh双曲正切函数,训练类型采用批处理方式,学习算法采用梯度下降算法,经过多种调试后发现当学习率为0.38,动能0.9,偏置为0.5时可以得到令人满意的预测值,最终结果采用此参数设置运行10次后的平均值。

本文整体模型思路流程如图3。
4 实验结果分析
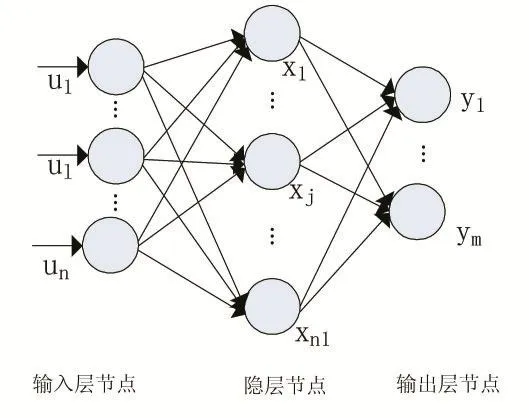
图1 BP神经网络最简单结构

表3
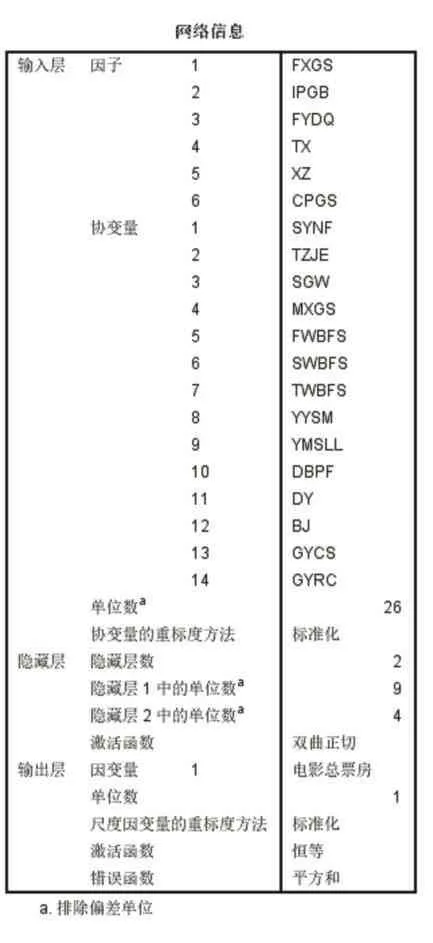
表4

图2
模型预测部分结果如表5。
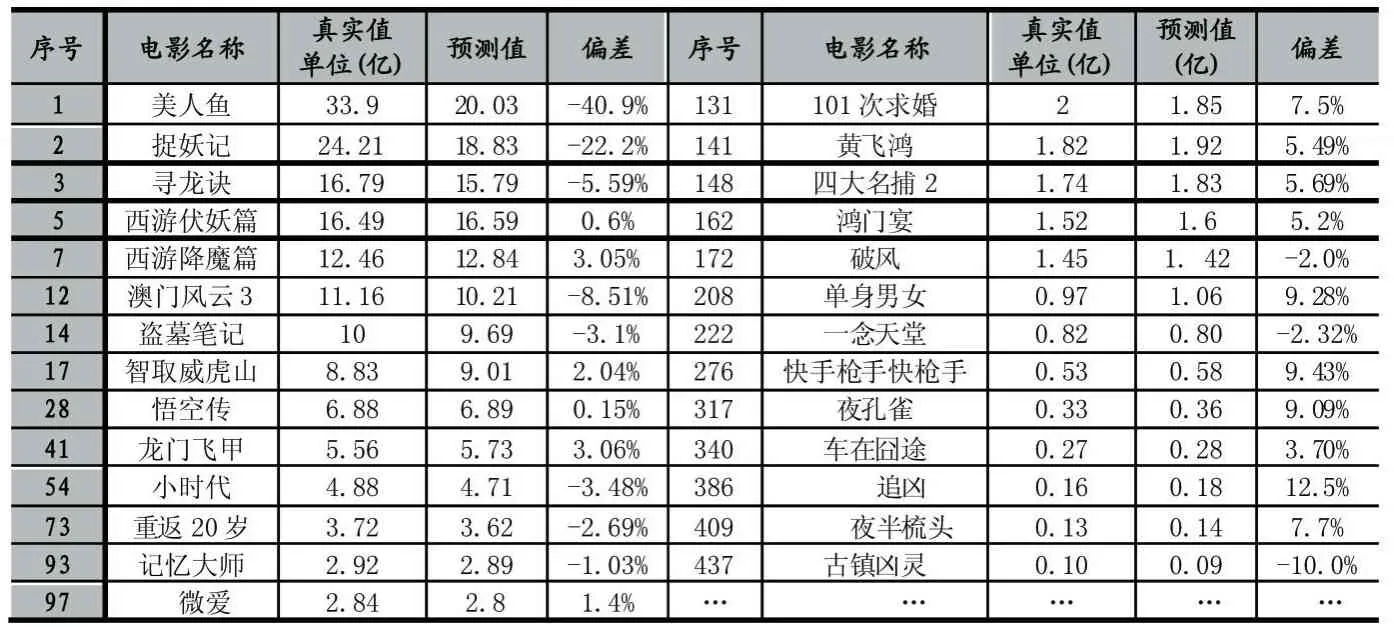
表5
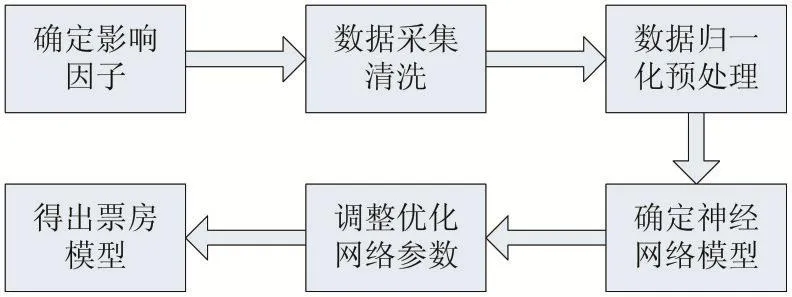
图3 模型的建立过程
摘录仿真实验的部分结果可知,发现各大票房区间拟合结果令人满意,第386条《追凶》误差值最大为12.5%,除去超过20亿票房的捉妖记和美人鱼误差预测较大外,其余误差基本控制在[-10%,10%]以内。其中捉妖记和美人鱼分别是2015年和2016年内地票房冠军,口碑良好,尤其《美人鱼》是导演周星驰历时三年创作出来的作品,鉴于星爷在中国粉丝众多,加上电影题材新颖与当时热门话题环保相结合,很多人二刷三刷电影票前去支持,由于本文所有数据是根据电影上映前收集而来,确实也未考虑到群众效应带来的影响,因此未能进行较为准确的预测情有可原。
5 结语
本文从中国内地电影票房市场出发,把电影实际总票房作为因变量,导演、编剧、第一主演、第二主演、第三主演、上映档期等多达20个因子作为自变量,并对其进行了归一化处理,另外对BP神经网络网络结构做了调整,优化了BP神经网络电影预测票房模型,最终效果令人满意。值得注意的是,本文暂未将盗版因素考虑在内,鉴于国内盗版情况屡见不鲜,为了更加精准的分析预测,希望相关部门加以管制,本文鼓励支持正版。
