An Iterative Method for Optimal Feedback Control and Generalized HJB Equation
2018-09-28XuesongChenandXinChen
Xuesong Chen and Xin Chen
Abstract—In this paper,a new iterative method is proposed to solve the generalized Hamilton-Jacobi-Bellman(GHJB)equation through successively approximate it.Firstly,the GHJB equation is converted to an algebraic equation with the vector norm,which is essentially a set of simultaneous nonlinear equations in the case of dynamic systems.Then,the proposed algorithm solves GHJB equation numerically for points near the origin by considering the linearization of the non-linear equations under a good initial control guess.Finally,the procedure is proved to converge to the optimal stabilizing solution with respect to the iteration variable.In addition,it is shown that the result is a closed-loop control based on this iterative approach.Illustrative examples show that the update control laws will converge to optimal control for nonlinear systems.
I.INTRODUCTION
THE optimal control of nonlinear systems is one of the mostchallenging and difficultsubjects in controltheory.A large number of theoretical results about the nonlinear optimal control problems have been reported in the past few decades[1]-[9].The dynamic programming algorithm is widely regarded as the most comprehensive method in finding optimal feedback controllers for generic nonlinear systems.However,the main drawback of dynamic programming methods today is the computationalcomplexity required to describe the value function which grows exponentially with the dimension of its domain.It is well known that continuous-time nonlinear optimal control problem depends on the solution of Hamilton-Jacobi-Bellman(HJB)equation,which is a nonlinear partialdifferentialequation(PDE).Even in simple cases,the HJB equation may nothave globalanalytic solutions.Various methods have been proposed in the literature forcomputing numericalsolutions to the HJB equation,see for example Aguilar et al.[10],Cacace et al.[11],Govindarajan et al.[12],Markman et al.[13],Sakamoto et al.[8],Smears et al.[14],and the references therein.
It is known that the generalized Hamilton-Jacobi-Bellman(GHJB)equation is linear and easier to solve than HJB equation,butno generalsolution for GHJB equation is demonstrated as to the best knowledge of authors.Beard et al.[15]presented a series of polynomialfunctions as basic functions to solve the approximate GHJB equation,however,this method requires the computation of a larger number of integrals.Galerkin’s spectralapproximation approach is proposed in[16]to find approximate but close solutions to the GHJB at each iteration step.The reader is also referred to Markman et al.[13],Smears et al.[14],Saridis et al.[17],Aguilar et al.[10],Gong et al.[18]for more details and different perspectives.Although many articles have discussed the solution to the HJB equation for the continuous-time systems,currently there is very minimal work available on iterative solution approach for GHJB equation.
In this paper,we propose a new iterative method to find the approximate solution to GHJB equation which is associated with the optimal feedback control for nonlinear systems.The idea of this iterative algorithm for GHJB equation is based on Beard’s work[16].Our approach is designed to obtain the general computational solution for the GHJB equation.We firstly convert the GHJB equation to a simple algebraic equation with vector norm,which is essentially a set of nonlinear equations.Then we propose the procedure of this method to compute the solution to the GHJB by considering the linearization of the nonlinear equations under a good initial control guess.The stability and convergence results of the proposed scheme are proved.
The paper is organized as follows.The problem description is presented in Section II.The main result of this paper is derived in Section III,i.e.,the iterative algorithm forthe GHJB equation and the detailed mathematical proofs and justifications of the proposed approach.The numerical example is provided in Section IV.Finally,a brief conclusion is given in Section V.
II.PROBLEM STATEMENT
Consider the following continuous-time affine nonlinear system:

where x∈Ω⊂Rnis the system state,f(0)=0,x0∈Ω⊂Rnis the initial state and u∈Rmis the control input,and f:Ω → Rn,g:Ω → Rn×m,u:Ω → Rm.Assume that the system is Lipschitz continuous on a setΩthat contains the origin.
The optimalcontrolproblem under consideration is to find a state feedback controllaw u(x)=u∗(x)such thatthe system(1)is closed-loop asymptotically stable,and the following infinite horizon cost function is minimized:

where l:Ω→ R is called the state penalty function,and it is a positive-defi nite function onΩ.Typically,l is a quadratic weighting of the state,i.e.l=xTQx where Q is a positivedefinite matrix.
It is well known that the optimal control can be directly found to bewhere V satisfies the HJB equation
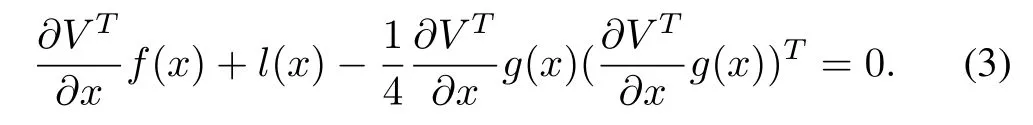
Although the solution to the nonlinear optimal problem has been well-known since the early 1960s in[3],relatively few control designs explicitly use a feedback function of the form given in(3).The primary difficulty lies in solving the HJB equation,for which general closed-form solutions do not exist.It is noted that the HJB equation is a nonlinear PDE that is impossible to be solved analytically.To obtain its approximate solution,in Saridis[17],the HJB equation was successively approximated by a GHJB equation,written as GHJB(V,u)=0,if
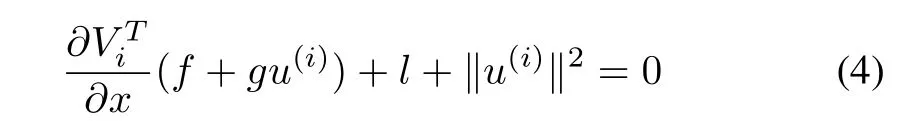
with

The cost of u(i+1)is given by the solution of equation GHJB(Vi,u(i))=0.Since the GHJB equation is linear,it is theoretically easier to solve than the nonlinear HJB equation.
III.THE MAIN RESULTS
In many numerical methods for HJB equations,which are typically solved backward in time,the discretization is based on spatialcausality and the computation is explicitin time.The value of the solution function V at a grid point is computed at an earlier time using the known value of the function at neighboring grid points at a later time.This coupling usually comes from the discretization of the spatial derivatives.In order to mitigate the curse of dimensionality,a new iterative method using a simple algebraic equation with vector norm is proposed.
A.Iterative Method for the GHJB Equation
It is obvious that the GHJB equation(4)can be rewritten as

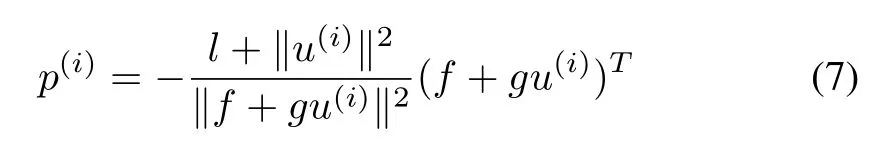
with
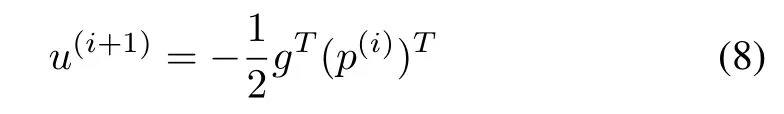
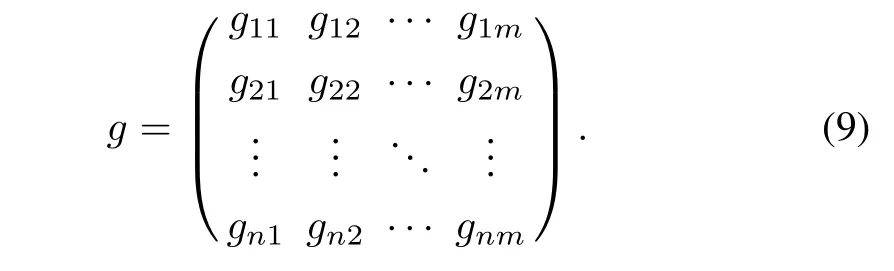
Let F(i)= (f+gu(i))T,define the norm of x =(x1,x2,...,xn)Tas follows

then(7)can be rewritten as

where

Then,we obtain the feedback control from(8)

The method proposed in this paper may be implemented by applying the following procedure on the system(1).
In Algorithm 1,p is a function of the state x,that is to say,p(x)belongs to an infinite-dimensional functional space.The notation of this norm is defined as follows:
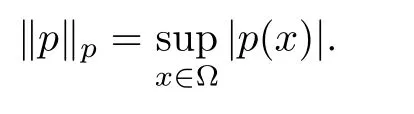

Algorithm1: IterativeAlgorithmBasedonGHJBEquation u(i):=GHJB(f,g,l,u(1))IF(‖p(i)-p(i-1)‖p < ϵ)Solvenumerically:u∗=u(i)ELSE Restriction:u(i+1)=-12gT(p(i))T Computation:p(i+1)=-l+‖u(i+1)‖2‖f+gu(i+1)‖2(f+gu(i+1))Recursion:i←i+1 ENDIF RETURNu(i).
B.Initial Control Guess
To apply the method introduced in this paper we mustchoose an initial stabilizing contro u(1)for the system(1) and an estimate of the stability region of u(1).A good estimate for u(1)can be found by considering the linearization of (11).
If q∈Rnis an equilibrium point for system(1),and F(i)is differentiable at q, then its derivative is given byJF(i)(q).In this case,the linear map described byJF(i)(q)is the best linear approximation of F(i)near the point q, in the sense that
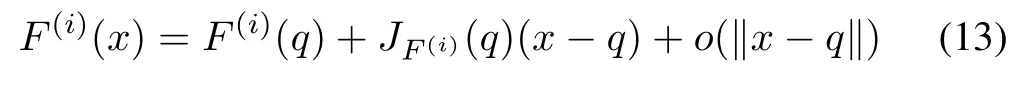
for x close to q and where o is the little o-notation(forx→q)and ‖x-q‖ is the distance between x and q.
C.Stability Analysis
In this subsection, we conduct the stability and convergenceanalysis of the proposed scheme. First, we define the pre-Hamiltonian function for some control u(x) and an associatefunction V (x)

Lemma1:The optimal control lawu∗and the optimal value functionV∗(x),if they exist,satisfy(4)and
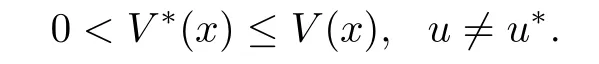
This lemma is proved in [17] which is a sufficient conditionfor the optimal control solution to the nonlinear systems.
There is a bulk of literature devoted to the problem ofdesigning stable regulators for nonlinear system. The mostimportant and popular tool is Lyapunov’s method. To useLyapunov’s method, the designer first proposes a control andthen tries to find a Lyapunov function for the closed-loopsystem. A Lyapunov function is a generalized energy functionof the states, and is usually suggested by the physics of theproblem. It is often possible to find a stabilizing control for aparticular system. Now we show that value function V1is aLyapunov function for the system(f,g,u(2)).
Theorem 1: Assume Ω is compact set,u(1)∈ Au(Ω)is anarbitrary admissible control for the system (1) onΩ,if there exists a positive definite continuously differentiable function V1(x,t)on[t0,∞)× Rnsatisfying the GHJB equation

associated with

then for all t∈ [t0,∞),system(1)hahas bounded trajectories over[t0,∞),and the origin is a stable equilibrium point forsystem (1).
Proof:SinceV1(x,t)is a continuously differentiable function,we take the derivative ofV1(x,t)along the system(f,g,u(2))and the factthat


Substituting (17) into (16), we can get
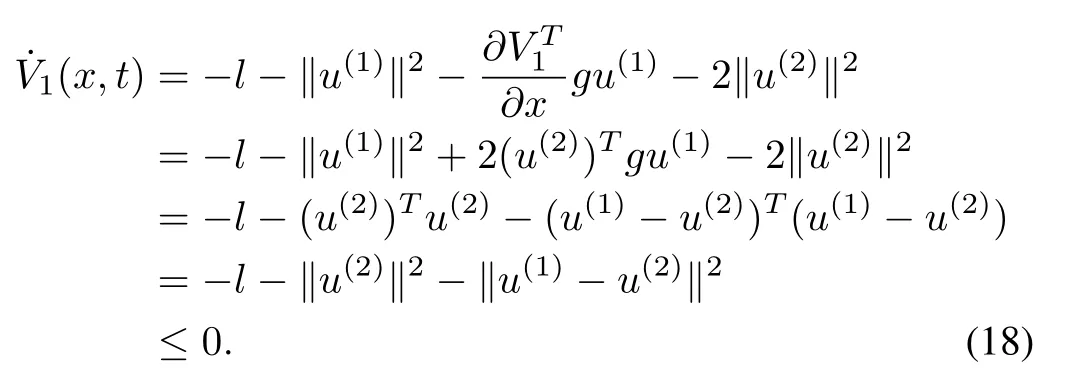
This establishes the boundaries of the trajectories of system(1)over[t0,∞).Under the assumptions of the theorem,(x,t)<0 is a Lyapunov function, and the origin is a stableequilibrium point for system (1). ■
D.Convergence Results
In this subsection, the Algorithm 1 converges to the optimalcontrol will be shown when it exists. It is clear that thefollowing equation is easily obtained from (7) and (8)
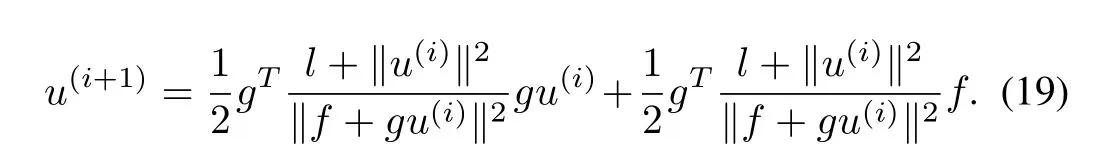
Linearizingtheequation(19)accordingto(13),weobtain

where T is a linear operator. In its general form the classicalmethod of successive approximation applies to equations of theform=T(u).solution u to such an equation is said to be afixed point of the transformation T since T leaves u invariant.To find a fixed point by successive approximation, we begin with an initial trial vector u(1)and computeu(2)=T(u(1)).Continuing in this manner iteratively, we compute successive vectors u(i+1)=T(u(i)).Under appropriate conditions the sequence{u(i)}converges to a solution of the original equation.
Definition 1:Let S be a subset of a normal space X and let T be a transformation mapping S into S.Then,T is said to be a contraction mapping if there isα,0≤α<1 such that‖T(u(1))-T(u(2))‖ ≤ α‖u(1)-u(2)‖.
Note for example that a transformation having ‖T′(u)‖≤α<1 on a convex set S is a contraction mapping since,by the mean value inequality,‖T(u(1))-T(u(2))‖ ≤ sup‖u(1)-u(2)‖≤ α‖u(1)-u(2)‖.
Lemma 2:If T is a contraction mapping on a closed subset S of a Banach space,there is a unique vector u∗∈ S satisfying u∗=T(u∗).Furthermore,u∗can be obtained by the method of successive approximation starting from an arbitrary initial vector in S.
Proof:Select an arbitrary element u(1)∈S.Define the sequence{u(i)}by the formula u(i+1)= T(u(i)).Then‖u(i+1)-u(i)‖=‖T(u(i))-T(u(i-1))‖ ≤ α‖u(i)-u(i-1)‖.Therefore,
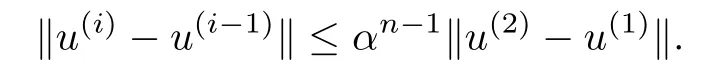
It follows that

and hence we conclude that{u(i)}is a Cauchy sequence,since S is a closed subset of a complete space,there is an element u∗∈ S such that u(i)→ u∗.
We now show that u∗=T(u∗).We have

By appropriate choice of n the right-hand side of the above inequality can be made arbitrarily small.Thus‖u∗-T(u∗)‖ =0.
It remains only to show that u∗is unique.Assume that u∗andare fixed points.Then
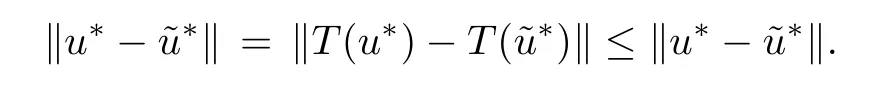
Thus u∗=.■
Defining T(u)=Au+B,the problem is equivalent to that of finding a fixed point of T.Furthermore,the method of successive approximation proposed above for this problem is equivalentto ordinary successive approximation applied to T.Thus it is sufficient to show that T is a contraction mapping with respect to some norm on n-dimensional space.For the mapping T defined above we have
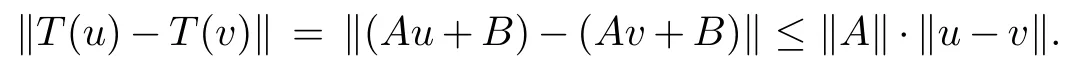
The basic idea of successive approximation and contraction mappings can be modified in several ways to produce convergence theorems for a number of different situations.We consider one such modification below.
Theorem 2:Let T be a continuous mapping from a closed subset S of a Banach space into S,and suppose that Tnis a contraction mapping for some positive integer n.Then,T has a unique fixed point in S which can be found by successive approximation.
Proof:Let u(1)be arbitrarily selected from S.Define the sequence{u(i)}by
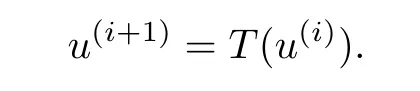
Now since Tiis a contraction,it follows by Lemma 1 that the subsequence{u(ik)}converges to an element u∗∈ S which is a fixed point of Ti.We show that u∗is a unique fixed point of T.
By the continuity of T,the element T(u∗)can be obtained by applying Tisuccessively to T(u(1)).Therefore,we have u∗=limk→∞Tik(u(1))and
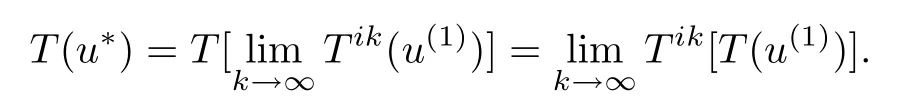
Hence,again using the continuity of T,
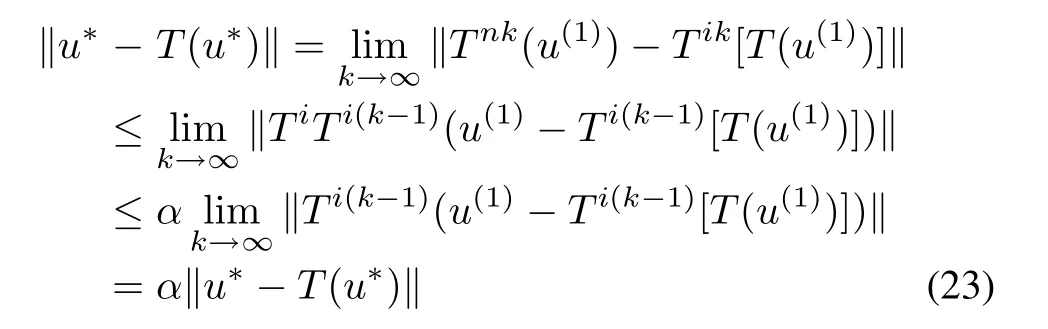
where α < 1.Thus u∗=T(u∗).If u∗,v∗are fixed points,then
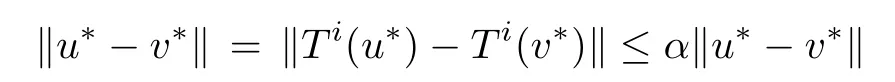
and hence u∗=v∗.Thus the u∗found by successive approximation is a unique fixed point of T. ■
IV.ILLUSTRATIVE EXAMPLES
In this section,we will show how this solution using the proposed method is worked to obtained a control law which improves the closed-loop performance of the original control.
A.One Dimensional Nonlinear System
A first-order nonlinear system is described by the state equation
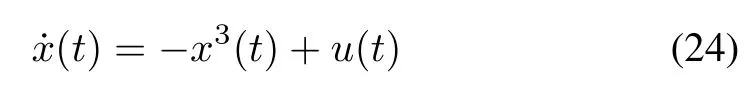
with initial condition x(0)=x0.It is desired to find u(t),t∈ (0,∞),that minimizes the performance measure

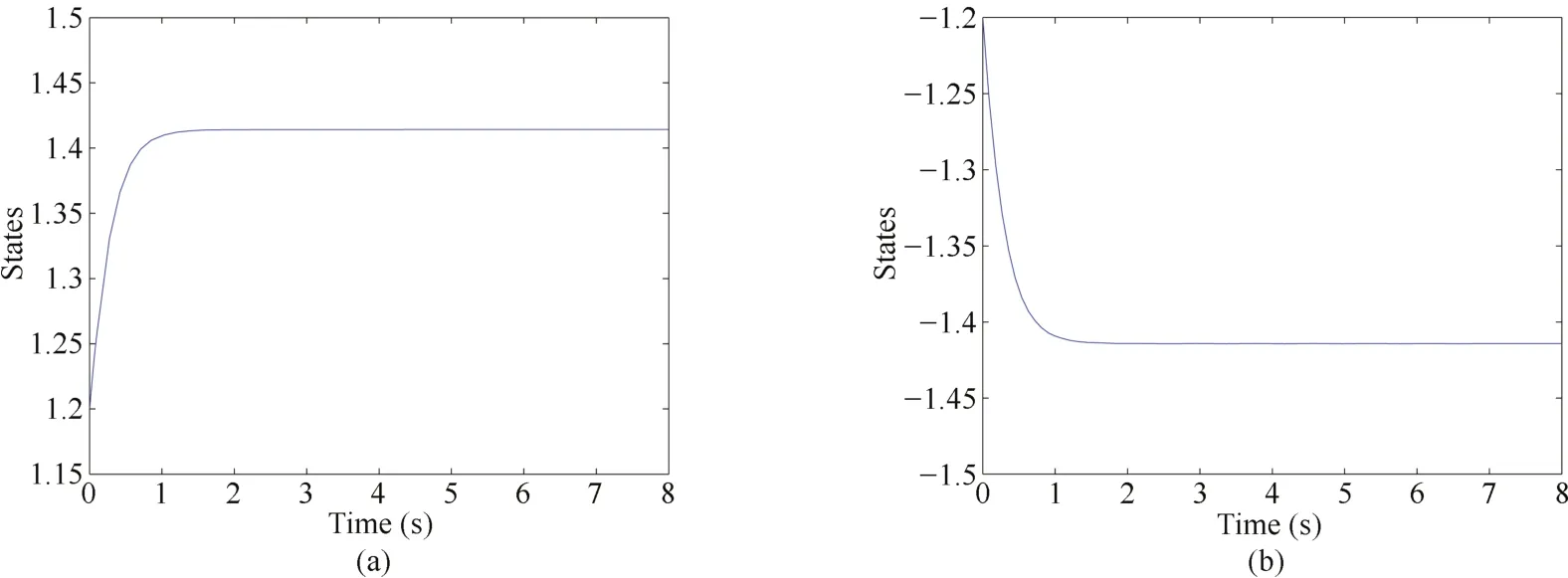
Fig.1. A continuous stabilizing control u(1)with different initial state.
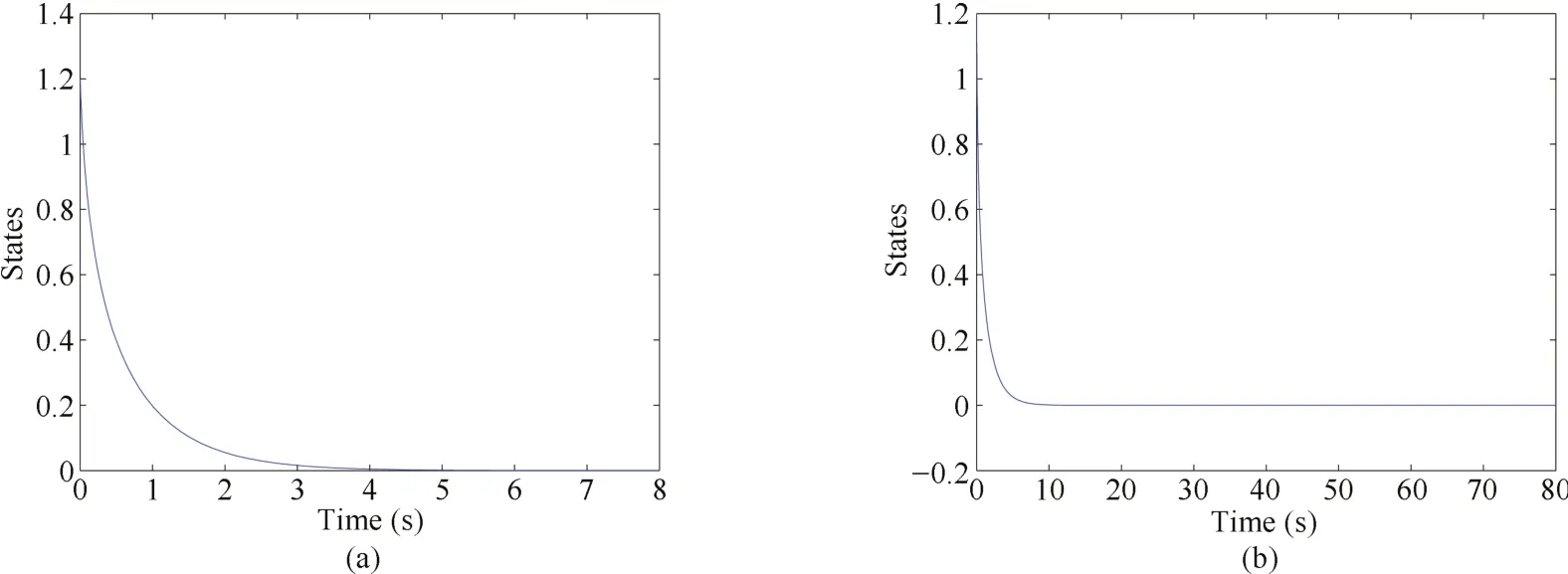
Fig.2. A continuous stabilizing control u(2)with different time.
Assume a linear control to start with
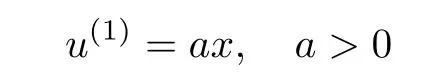
it is clear that the system is stable when a>0.Now select a feedback initial control

then the system(24)under controller u(1)is stable with different initial value as shown in Fig.1.Substitute u(1)into(7),we have

The above yields

Then the system(24)under controller u(2)is stable with different time domain as shown in Fig.2.
To continue the iterative algorithm,we would repeat the preceding steps,using this revised value.If we select x=2,then we can obtain the value p(i)(i=1,2,...),for example,p(1)(2)=-8.000,p(2)(2)=-2.500,p(3)(2)=-0.4120,p(4)(2)=-0.2594,p(5)(2)=-0.2552,p(6)(2)=-0.2550.It is obvious that
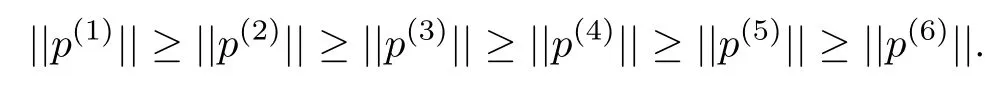
Eventually the iterative procedure should converge to the optimal control history,u∗.The preceding example indicates the steps involved in carrying out one iteration of Algorithm 1.Letus use this algorithm to determine the optimaltrajectory and control for a continuous stirred-tank chemical reactor.
B.Two Dimensional Nonlinear System
The state equations for a continuous stirred-tank chemical reactorare given below from[1].The flow ofa coolantthrough a coil inserted in the reactor is to control the first-order,irreversible exothermic reaction taking place in the reactor.x1=T(t)is the deviation from the steady-state temperature and x2(t)=C(t)is the deviation from the steady-state concentration.u(t)is the normalized controlvariable,representing the effect of coolant flow on the chemical reaction.The state equations are
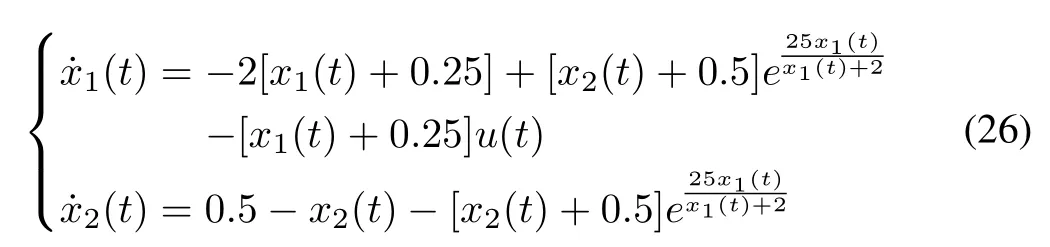
with the boundary conditions x0=[0.05,0]T.The performance measure to be minimized is


Fig.3.(a)Optimal control and trajectory;(b)Performance measure reduction by Algorithm 1;(c)Performance measure reduction by Beard in[16].
indicating thatthe desired objective is to maintain the temperature and concentration close to their steady-state value without expending large amounts of control effort.R is a weighting factor that we shall select arbitrarily as 0.1.To ensure that a monotonically decreasing sequence of performance indices was generated,each trial control was required to provide a smaller performance measure than the preceding control.This was accomplished by re-generating any trial control that increased the performance measure.
With t∈[0,0.78],and an initial value equal to 1.0,the value of the performance measure as a function of the number of iterations is as shown in Fig.3(b).The results compared with Beard’s method are shown in Fig.3(c).In this figure,J is regarded as the performance obtained by Beard’s method in[16].It is seen from Fig.3(b)and Fig.3(c)that the optimal feedback controlobtained by ourmethod is betterthan Beard’s method.However,the approximate optimal controlunder our approach can be decreased by strengthening the stopping criteria even if it costs further computations.
To illustrate the effects of differentinitialparameters for the control history,different additional solutions were obtained.The results ofthese computer runs are summarized in Table I.

TABLE I SUMMARY OF ALGORITHM 1 WITH DIFFERENT PARAMETERS
The value of the performance measure J as a function of the number of iterations with different initial control(u(1)=1.0,0)and different stopping criterion(ϵ=10-6,10-7)is as shown in Table I.To ensure thata monotonically decreasing sequence of performance indices was generated,each initial control was required to provide a smaller stopping criterion than the preceding initial control.This was accomplished by havingϵand re-generating any trial control that increased the performance measure.It could be seen from Table I when the initial control is equal to zero and the stopping criterion is 10-6,the steps of iteration reduced significantly,however,the performance measure yielded only very slightreduction.This type of progress is typical of the iterative method.
Remark 1:To conclude our discussion of Algorithm 1,let us summarize the important features of the algorithm.First of all,from the nominal control history,u(1),must be selected to begin the numerical procedure.In selecting the nominal control we use whatever physical insight we have about the problem.Secondly,the current control u(i)and the corresponding state trajectory x(i)are stored.If storage must be conserved,the state value needed to determine p(i)can be obtained by reintegrating the state equations with the costate equations.If this is done x(i)does not need to be stored;however,the computation time will increase.Generating the required state values in this mannermay take the results ofthe backward integration more accurate,because the piecewiseconstant approximation for x(i)need not be used.Finally,the proposed method is generally characterized by ease of starting the initial guess for the control is not usually crucial.On the other hand,the method has a tendency to converge slowly as a minimum is approach.
C.Robot Arm Problem
The robotarm problem is taken from[1].In the formulation the arm of the robot is a rigid bar of length L that protrudes a distanceρfrom the origin to the gripping end and sticks out a distance L-ρin the opposite direction.If the pivot point of the arm is the origin of a sphericalcoordinate system,then the problem can be phrased in terms of the lengthρof the arm from the pivot,the horizontal and vertical angles(θ,φ)from the horizontal plane,the controls(uρ,uθ,uφ),and the final time tf.Bounds on the length and angles are
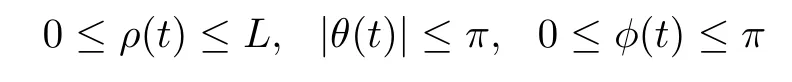
and for the controls

The equations of motion for the robot arm are
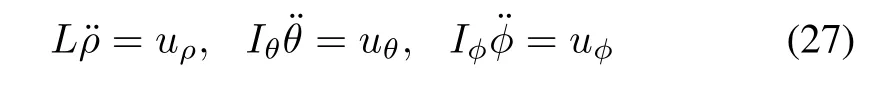
where I is the moment of inertia,defined by
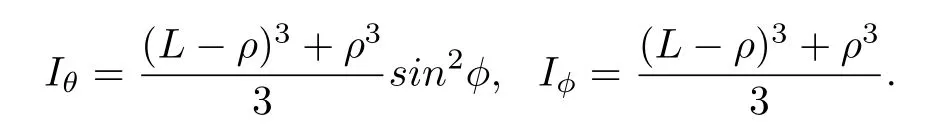
The boundary conditions are
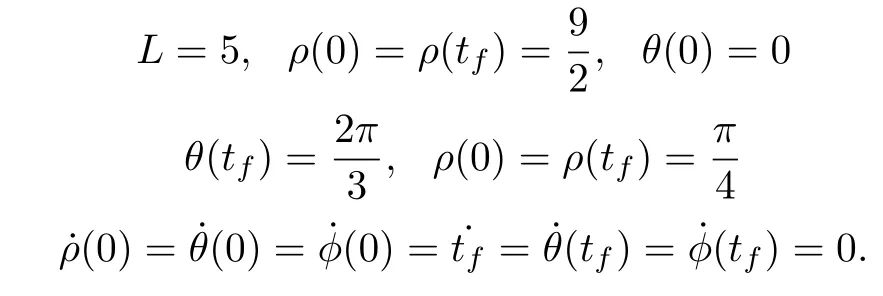
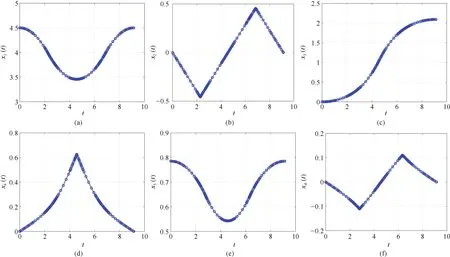
Fig.4. Variables x1,...,x6 for the robot arm problem.

Fig.5. Control variables uρ,uθ,uφ for the robot arm problem.
This model ignores the fact that the spherical coordinate reference frame is a non-inertial frame and should have terms for Coriolis and centrifugal forces.Let x1=ρ,x2=˙ρ,x3=θ,x4=˙θ,x5=φ,x6=˙φ,then the optimal control of this robot arm problem is stated as follows.Find the controls(uρ,uθ,uφ)such that they minimize the cost functional

subject to the dynamic constraints
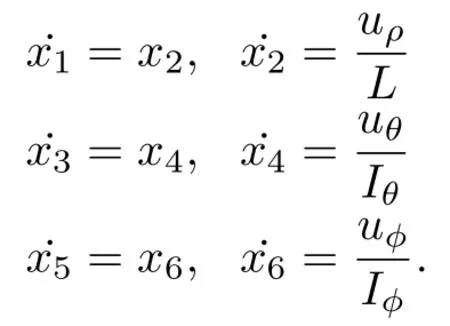
The control inequality constraints and the boundary conditions are shown in the above statement.
Fig.4 shows the variables x1,...,x6for the robot arm as a function of time.The control variables uρ,uθ,uφfor the robot arm as a function of time are also shown in Fig.5.Note that the functions x1,x3,x5for the robot arm are continuously differentiable,but since the second derivatives are directly proportionalto the controls,the second derivatives are piecewise continuous.
V.CONCLUSION
In this paper,we proposed a new iterative numerical technique to solve the GHJB equation effectively.There is a need for numerical methods which approximate solutions to the special types of equations which arise in nonlinear optimal control.We also showed that the resulting controls are in feedback form and stabilize the closed-loop system.The procedure is proved to converge to the optimal solution to GHJB equation with respect to the iteration variable.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Iterative Learning Control With Incomplete Information:A Survey
- Fundamental Issues in Networked Control Systems
- Adaptive Neural Network-Based Control for a Class of Nonlinear Pure-Feedback Systems With Time-Varying Full State Constraints
- A Dynamic Road Incident Information Delivery Strategy to Reduce Urban Traffic Congestion
- Feed-Forward Active Noise Control System Using Microphone Array
- Energy Efficient Predictive Control for Vapor Compression Refrigeration Cycle Systems