Iterative Learning Control With Incomplete Information:A Survey
2018-09-28DongShenSeniorMemberIEEE
Dong Shen,Senior Member,IEEE
Abstract—This paper conducts a survey on iterative learning control(ILC)with incomplete information and associated control system design,which is a frontier of the ILC field.The incomplete information,including passive and active types,can cause data loss or fragment due to various factors.Passive incomplete information refers to incomplete data and information caused by practical system limitations during data collection,storage,transmission,and processing,such as data dropouts,delays,disordering,and limited transmission bandwidth.Active incomplete information refers to incomplete data and information caused by man-made reduction of data quantity and quality on the premise that the given objective is satisfied,such as sampling and quantization.This survey emphasizes two aspects:the first one is how to guarantee good learning performance and tracking performance with passive incomplete data,and the second is how to balance the controlperformance index and data demand by active means.The promising research directions along this topic are also addressed,where data robustness is highly emphasized.This survey is expected to improve understanding of the restrictive relationship and trade-offbetween incomplete data and tracking performance,quantitatively,and promote further developments of ILC theory.
I.INTRODUCTION
M ANY practicalsystems follow the same operation mode where they repeatedly complete a given task in a finite time interval.For instance,the industrial production process generally consists of successive batches of production tasks;that is,the system completes a production batch following a given procedure within the desired time interval and then repeats itagain and again.Forsuch systems thatcan be clearly divided into successive operation batches,ifthe operation time lengths of each batch are identical and the operation circumstances of different batches are similar,then we can fully utilize the operation data and experience to adjust the action strategy for the next batch.This basic concept of “learning”motivates the proposal and developments of iterative learning control(ILC),which is now an importantbranch ofintelligent control[1].In other words,ILC is a typical control strategy mimicking the learning process of the human being,of which the pivotalidea is to continuously learn the inherentrepetitive factors of system operation processes based on various data from completed batches such that the tracking performance is gradually improved.This control strategy imposes little requirementon system information and thus is typically a datadriven control methodology,which can effectively deal with the traditional control challenges such as high-nonlinearity,strong coupling,modeling difficulty,and tracking of high precision.
After developments over three decades,ILC has resulted in a number of valuable results in both theory and applications;for details,see survey papers and special issues[2]-[7].We note that the invariance of system dynamics including identical tracking reference,identical operation length,and identical initial state is a basic requirement of ILC,for which the proposed update law can reduce the invariance and improve tracking performance.Recently,much efforthas been devoted to relax this requirement.For example,in[8],[9],attempts have been made for the nonrepetitive uncertain system to take into account essential limitations of ILC dealing with nonrepetitive factors.The case of nonrepetitive parameters was also explored in a recent paper[10]among others.Moreover,scholars are working on novel analysis and synthesis approaches other than the conventional contraction mapping method,which imposes some restrictive conditions on the systems.The repetitive process based approach has shown its effectiveness in[11]-[14],and ILC can be easily turned into a repetitive process whose dynamics and control problems have been wellinvestigated.Various stability criteria have been studied in[11]-[14]for different problems which can be applied to derive fruitful results of ILC by suitable transformation.We note that the 2D system based approach[15]and frequency based approach[16]are both important synthesis methods for deriving performance-guaranteed controller design of ILC.In addition,it should be pointed out that,along with fast developments in theoretical analysis,the applications of ILC have been greatly enlarged such as robotics[17],[18],dual-mode flyback inverter[19],and stroke rehabilitation systems[20].In sum,ILC has gained significant progress for both theoreticalanalysis and practicalapplications in the past decades.
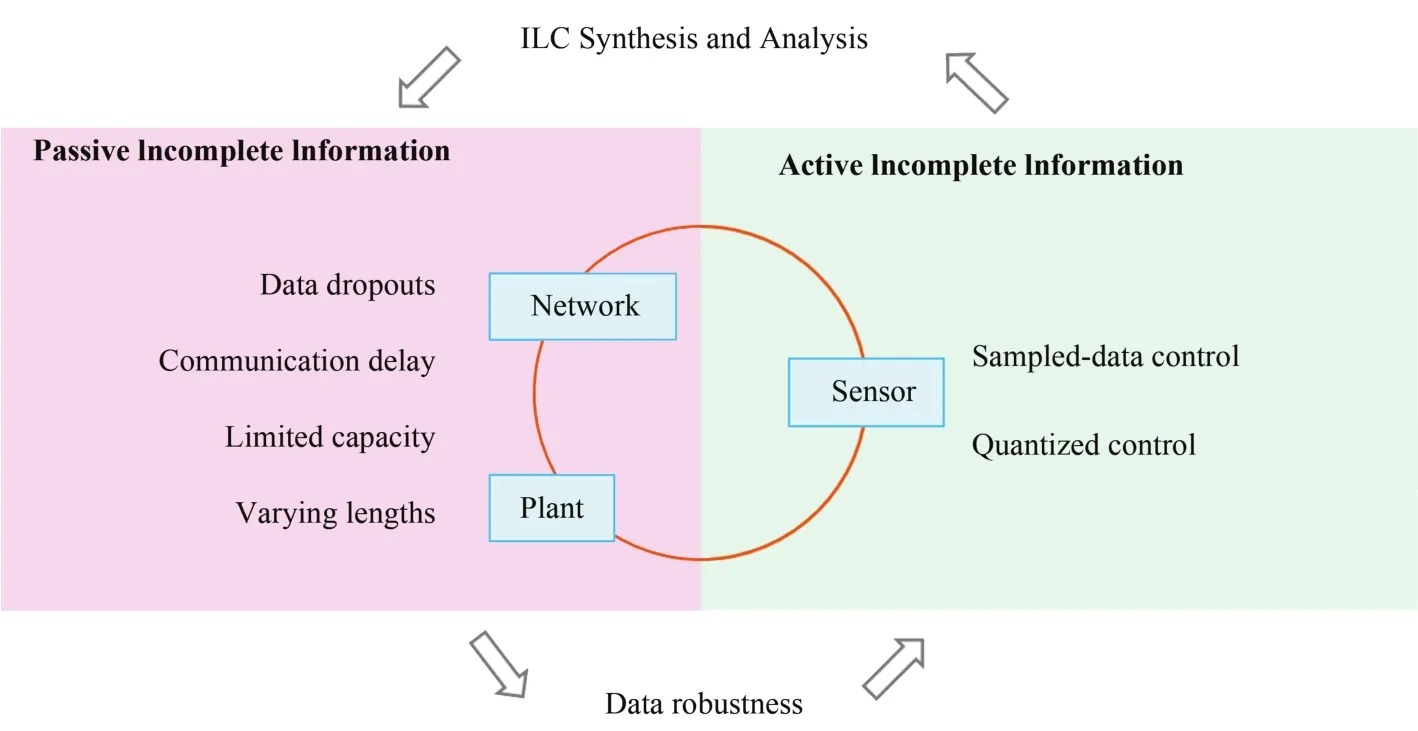
Fig.1. Main structure of the overview.
In order to achieve excellent control performance,most ILC literature depends on the acquisition and utilization of full system information and operation data.That is,the data employed by the learning algorithms are assumed to have infinite-precision.To this end,we have to increase the quantity and precision of sensors for complex systems to acquire more accurate information,increase the network bandwidth to transmit mass data,and increase the number of servers and improve the computation ability to guarantee good execution of complex algorithms.All of these inevitably increase the system burden and control cost.On the one hand,due to various uncertainties,the practical systems would suffer data dropout and loss during the operation,which results in additional difficulty in acquiring complete information.On the other hand,if we could efficiently reduce the acquisition and computation ofmass data,provided thatthe tracking precision and control performance is decreased,we can not only reduce the cost of hardware and software,but also increase operationalefficiency and system robustness.In consideration of the above two aspects,itis ofgreattheoreticaland practicalsignificance to design data-driven ILC algorithms with incomplete information such that a high quality of control performance is achieved.We note thatthe influence of incomplete information on the tracking performance of data-driven ILC is essentially a robustness problem of ILC.It is worth pointing out that such robustness problem is different from the traditional modelbased robustness problem.That is,the former emphasizes the perspective of data,which focuses on the inherent restriction between the incomplete information and control performance,whereas the latter emphasizes the perspective of the model,which concentrates on the robustness with respect to the unmodeled dynamics.
In practical applications,there are various factors that can lead to the incomplete information problem,including both objective and subjective factors.To make our expression clear to follow,we classify the incomplete information scenarios into two categories:passive incomplete information and active incomplete information.Passive incomplete information refers to incomplete data and information caused by practical system limitations during data collection,storage,transmission,and processing,such as sensor/actuator saturation,data dropouts,communication delay,packet disordering,and limited transmission bandwidth.This incomplete information problem is common in networked control systems that are widely employed in engineering implementations due to their high flexibility and robustness.Active incomplete information refers to incomplete data and information caused by man-made reduction of data quantity and quality on the premise that the specified control objective is satisfied,such as sampling and quantization.By sampling,we acquire the operation data of a continuous-time system with a specified frequency only and skip the information between adjacentsampling time instants.By quantizing,we transform a value interval as an integer within a finite or infinite candidate set,which is common in the conversion from analog signal to digital signal.Clearly,both sampling and quantization can reduce the mass of data,which reduces the burden in acquiring,storing,and transmitting and increases the system operating efficiency.Therefore,it is of great importance to investigate how incomplete information influences controlperformance as wellas determine how large the influence is and how to overcome the influence.
We note that the control design and analysis with both passive and active incomplete information have obtained many results in traditional control methodologies,especially in the fi eld of networked controlsystems.However,ILC differs from traditional control methodologies in that it considers dualevolution along both the time axis and iteration axis.The kernel dynamics lie in the iteration-axis,which is essentially differentfrom the time-axis-based evolution of traditional system dynamics.Consequently,the results in networked control systems cannot be extended to ILC directly.Indeed,in ILC field,related results are very few and there are many open problems.Moreover,for learning control with incomplete information,itis mostimportantto consider the data robustness of incomplete information and the associated overall design of the control systems;that is,it is important to understand the inherent restriction between incomplete information and control performance in a novel framework.
This paper is devoted to providing a survey of ILC with incomplete information,where we address the recentprogress on ILC with passive incomplete information such as data dropouts,communication delays,and iteration-varying length,as wellas with active incomplete information such as sampling and quantization.We will give a research framework for various incomplete information problems from the perspective of design and analysis techniques.Moreover,we provide a primary discussion on the data robustness and related topics in ILC with incomplete information.Itis expected thatthe survey can help the reader to grasp the overallview of this topic and comprehend the fundamental techniques.The structure of the overview is shown in Fig.1.We note that,to some extent,terminal ILC and point-to-point ILC can be regarded as a type of incomplete information.The methods for this issue have been well reviewed in[5]and thus will not be repeated here.
The rest of this paper is arranged as follows.Section II gives the basic formulation,design and analysis techniques,and primary convergence results of ILC.In Section III,the recent progress on ILC with passive incomplete information is discussed,where the issues of random data dropouts,communication delays and limits,and iteration-varying lengths are elaborated,respectively.In Section IV,we proceed to review the progress on ILC with active incomplete information,where the sampling and quantization issues are emphasized.The data robustness and promising research directions are expounded in Section V.Section VI concludes the paper with remarks.
Notations:Throughout the paper,we use k and t to denote the iteration index and time index,respectively.‖·‖ denotes a unspecified but well-defined norm of a vector or matrix.P(·)denotes the probability ofits indicated eventand E denotes the mathematical expectation of the indicated random variable.
II.ILC BACKGROUNDS
In this section,we provide the basic formulation of ILC as well as the primary design and analysis techniques.To this end,we first propose the essential principle of ILC.In particular,the fundamental idea of ILC is to improve the tracking performance for a given reference along the iteration axis.The main concept of networked ILC is shown in Fig.2,where yddenotes the reference trajectory.Atthe k th iteration,the input ukis fed to the plant and the corresponding system outputis denoted by yk.Generally,ukis notgood enough and therefore,the tracking error at the k th iteration ek=yd-ykis nonzero.In this case,the input for the next iteration(i.e.,the(k+1)th iteration)is constructed as a function of the input and tracking error of previous iterations,although it is usually specified as a linear combination for the algorithm’s simplicity.Then,the newly generated input uk+1is transmitted to the plantand stored in the memory forsubsequentupdating.Consequently,a closed-loop feedback is formed along the iteration axis.In other words,ILC can be viewed as an iteration-based feedback controlmethodology.In addition,the system should be repeatable;that is,the given tracking task is iteration-invariant,the system can be reset to the same initial state,and the operation process is completed in the same time interval.In other words,repetition is the inherentrequirement for learning systems.
Now we proceed to the basic formulation of ILC according to the discrete-time system.Consider the following discretetime linear time-invariant system:
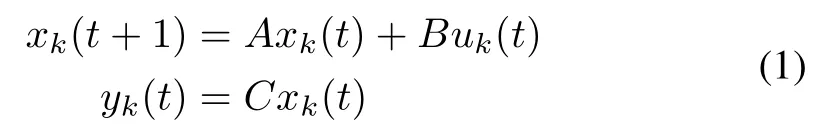
where xk(t)∈Rn,uk(t)∈Rp,and yk(t)∈Rqdenote the system state,input,and output,respectively.The subscript k denotes the iteration index,and t labels the time instantin an iteration with t=0,1,...,N,where N is the iteration length.Matrices A,B,and C are system matrices with appropriate dimensions.If we append the subscript t to these matrices,i.e.,At,Bt,and Ct,the system turns into time-varying case.

Fig.2.Framework of networked ILC.
We denote the reference trajectory as yd(t),t=0,1,...,N.The general control objective for ILC is to seek a suitable updating algorithm such thatthe generated inputsequence can drive the corresponding output yk(t)to track yd(t)asymptotically as the iteration number k increases.
We assume the initialstate to be resetto the desired one at each iteration,which is the well-known identicalinitialization condition(i.i.c.).That is,xk(0)=x0,∀k,where x0satisfies yd(0)=C x0.If such condition is not satisfied,it leads to an initial-state-shift problem,which has been deeply studied in ILC.A most common case is called bounded uncertain initial state assumption;that is,the initial state xk(0)locates in a smallneighborhood of the desired one,i.e.,‖xk(0)-x0‖ ≤ ϵ,where‖·‖denotes some predefined norm.
Note that the correction mechanism of ILC is to employ the tracking error information of previous iterations to adjust the input signal.To this end,denote the tracking error ek(t)=yd(t)-yk(t),∀t.Then,the updating algorithm for generating uk+1(t)is actually a function of previous inputs uk(t)and errors ek(t),of which the general form is

where h(·)is a function to be designed in practical applications.When the update depends only on the information of the last iteration,it is called a first-order ILC update law;otherwise,it is called a high-order ILC update law.To save memory size and enhance the operation efficiency,most ILC update laws are of first-order,i.e.,

Additionally,the update law is usually linear for simplicity.A simple but common update law is as follows:
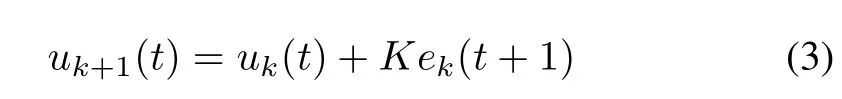
where K is the learning gain matrix and also the designed parameter.In(3),uk(t)can be viewed as the current input command,while K ek(t+1)is the innovation term.The update law(3)is called P-type.If the innovation term is replaced by K[ek(t+1)-ek(t)],the update law is called D-type.
For system(1)and update law(3),a basic convergence condition on K is that the following inequality is fulfilled,

where I denotes the unity matrix.Then,we have‖ek(t)‖→ 0 as k→ ∞.This condition can be easily derived from the lifted formulation in the following.We observe from this condition thatthe system matrix A is notinvolved in the above convergence condition,which originates from the essential update mechanism of ILC.Italso reveals that ILC can handle more system unknowns for a precise tracking task.
For discrete-time ILC,the lifting technique is a useful tool to transform the two-axis-based evolution dynamics into oneaxis-based evolution dynamics.To see this point,considering system(1)and learning law(3)and noting that the iteration length is N,we define

as the lifted supervectors of input and output at the k th iteration,respectively.Denote

then we have

where

where K=diag{K,K,...,K}.By simple calculation,one has
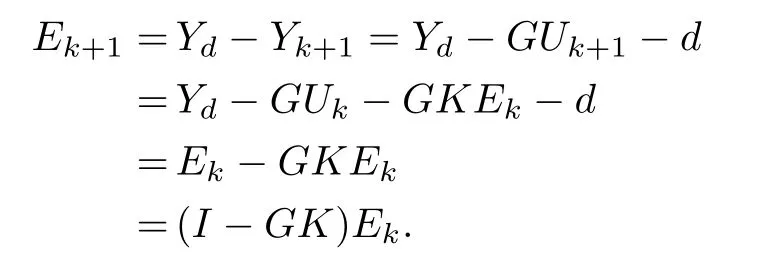
Consequently,noting that GK is a lower block-triangular matrix with the diagonal blocks being C B K,we can clearly obtain the above convergence condition‖I-C B K‖< 1.Moreover,with lifting techniques,it is noted that the time instantvariable t has been removed from the new formulations;that is,the time evolution dynamics of an iteration has been integrated into G,whereas the relationship between adjacent iterations has been highlighted.Indeed,the lifting technique has provided us an intrinsic understanding of the principle of ILC.
Atthe end of this section,we remark that the asymptotical tracking performance is derived according to the tracking error ek(t)directly in the above statements.If we have additional assumptions on the reference trajectory yd(t)that it is realizable in the sense that there exists a unique desired input ud(t)such that Yd=GUd+d,where Ud=then the proof is usually conducted by showing Uk→Udas k→∞.For a system with stochastic noises,this transformation is more convenient for convergence analysis.In sum,if the existence of a unique desired inputis guaranteed according to the specified tracking reference,we can prove the asymptotical convergence of the input sequence.The output convergence to the desired reference is a directcorollary.If the uniqueness of the desired inputis notavailable,we can either prove the convergence of the input sequence to the set of all possible desired inputs or verify the convergence of the output to the reference directly.
III.ILC WITH PASSIVE INCOMPLETE INFORMATION
In this section,we provide an in-depth survey of ILC with passive incomplete information,where we concentrate on random incomplete information scenarios such as random data dropouts,communication delays and limits,and iterationvarying lengths.The common factor of these scenarios is that their information loss is due to practical conditions and environments.We note thatother hardware limitations such as sensor/actuator saturation may also reduce the quality of data and information;however,they are omitted in this paper as they are generally deterministic.
A.Random Data Dropouts
From Fig.2 itis seen thatthe measured outputand generated input are transmitted through networks.Due to data congestion,limited bandwidth,and linkage fault,the data packetmay be lost during transmission.The data transmission has two alternative states:successful transmission and loss.Thus,the data dropoutis usually described by a random binary variable,sayγk(t)for the data packet at time instant t of the k th iteration.In particular,the variableγk(t)is set to 1 if the corresponding data packet is successfully transmitted,and 0 otherwise.Indeed,whether the data dropoutoccurs or notcan be regarded as a switch that opens and closes the network in a random manner.Generally,to describe the random data dropout,we need to establish a suitable mathematical model for the binary variableγk(t).Specifically,we have the following three most common models.
1)Random sequence model(RSM):For each time instant t,the data dropout is random without assuming any certain probability distribution,but there exists a positive integer K≥1 such that at least in one iteration the data packet is successfully sentback during arbitrary successive K iterations.
2)Bernoulli variable model(BVM):The random variable γk(t)is independent for different time instants t and iteration number k.Moreover,γk(t)obeys a Bernoullidistribution with

3)Markov chain model(MCM):The random variableγk(t)is independent for different time instants t.Moreover,for an arbitrary fixed t,the evolution ofγk(t)along the iteration axis follows a two-state Markov chain,of which the probability transition matrix is
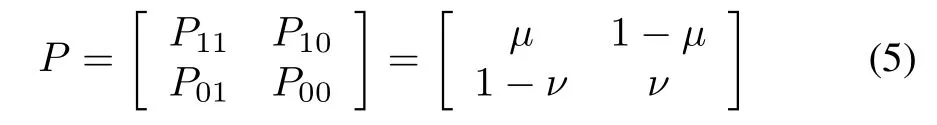
We first remark on the inherent connections among the above three models.Clearly,BVM is a special case of MCM as MCM would convert into BVM whenµ+ν=1.RSM differs from both BVMand MCMas itrequires no probability distribution or statistics property of the random variableγk(t).However,compared with BVM and MCM,RSM pays the price that the successive data dropout length is bounded.In particular,both BVM and MCM admit arbitrary successive data dropouts associated with a suitable probability of occurring.Consequently,RSM cannot cover BVM/MCM and vice versa.The range relationship of these models is shown in Fig.3.Itis worth pointing outthat RSM implies thatthe data dropoutis nottotally stochastic.Moreover,BVM differs from MCM because the data dropout occurs independently along the iteration axis for BVM,while it occurs dependently for MCM.This point can also explain why MCM is more general than BVM.

Fig.3.Data dropout models.
From the definition of RSM,we note that RSM only requires an upper bound of successive data dropouts along the iteration axis for every time instant t.In particular,it is required the information packetto be received atleastonce for any successive K iterations;thatis,for all k≥ 1,∀t.Therefore,the maximum length of successive data dropouts is K-1.Itis clear thatwhen K=1 there is no data dropoutoccurring and when K=2 there is no successive data dropout occurring.Moreover,the value of K is an index of the data dropout level.However,it is not suffi cient to depict the influence of data dropouts,because K corresponds to the worst case of data dropouts rather than the general case.
To clearly describe the average level of data dropouts along the iteration axis,we introduce a concept called data d£Propout¡ rate(DD¢R⁄),which is defined as limn→∞1/n×For RSM,we note thata larger K generally corresponds to a higher DDR and vice versa;however,the connection between K and DDR is not necessarily positively correlated.In other words,the DDR is another important index of the average level of data dropouts and it should be additionally clarified as we assume no probability property of RSM.For BVM,the mathematicalexpectationof the BVM(see(4))is closely related to the DDR in the light of the law of large numbers;that is,DDR is equal to 1-.Specifically,the data dropout is independent along the iteration axis;thus,If=0,which implies that the network is completely broken down,then no information can be received from the plant,and thus no algorithm can be applied to improve the tracking performance.If=1,which implies that no data dropoutoccurs,then the framework converts into the classical ILC problem.For MCM,the transition probabilitiesµandν denote average levels ofretaining the same state forsuccessful transmission and loss,respectively.By solving the equation πP= π,where P is given in(5),we have the stationary distributionπas follows,
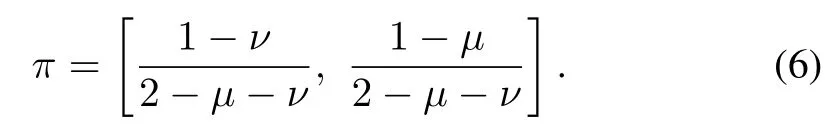
Taking the recent research literature into account,we observe thatthe progress can be reviewed from five perspectives:system types,data dropout models,dropout positions,update schemes,and analysis techniques,as is shown in Fig.4.In the past decade,ILC under random data dropouts has been fully developed in allthe perspectives;however,there are stillopen problems for further research.

Fig.4.The research framework of ILC with data dropouts.
1)Analysis Techniques:For smooth reading,we first review the analysis techniques and the related convergence results,especially the convergence meanings in consideration of the randomness of data dropouts besides optionalstochastic noises.We review papers from the research groups in this issue to provide a basic outline of recent works.
Ahn et al.provided earlier attempts to the ILC for linear systems in the presence of data dropouts[21]-[23]using the Kalman filtering based technique,which was first proposed by Saab in[24].The main difference among the contributions lies in the descriptions of data dropouts.In particular,the fi rst paper[21]assumed that the whole output vector was considered as a packet,whereas this assumption was relaxed to the case that only partial information of an output vector may suffer loss problem in[22].Moreover,in[23]both data dropouts and delayed controlsignals were taken into account.In[24],the input was derived by optimizing the input error covariance and thus the mean-square convergence of the input sequence was obtained.Therefore,[21]-[23]all contributed to a mean-square convergence.
Bu et al.contributed different research angle for this problem in[25]-[29].First,by using the exponential stability theory of asynchronous dynamical systems,which was given by Hassibi et al.in[30],the convergence of both first-and high-order update laws was established with an existence assumption of certain quadratic Lyapunov functions.Such a technique is noteasy to extend to othersystems and the authors used an expectation-based transform technique to derive the convergence for linear systems.In particular,in[26]the recursion of the tracking errors along the iteration axis,where the random data dropout variable was involved,eliminated the randomness by taking mathematical expectation to both sides.As a result,only the convergence in expectation sense was obtained.The techniques were then extended to nonlinear systems in[27]and an inequality of the inputerror ratherthan a recursion was obtained due to the nonlinearity.Moreover,in[28],a new H∞framework was defined with the help of lifting techniques and resolved the ILC problem under the newly introduced framework.In particular,an H∞performance index along the iteration axisand the asymptoticalconvergence were obtained and the design condition for learning gain matrices was solved through LMI techniques.Furthermore,in[29]the widely used 2D systems approach was revisited for the case with data dropouts.Specifically,a 2D system involving with dropout variables was derived and a meansquare asymptotically stability technique for 2D systems[31]was applied to deduce the convergence.Additionally,an LMI-based controller design was also provided.
Liu and Ruan considered the problem using the traditional contraction mapping method in[32]-[34].In[32],both linear and affine nonlinear systems were taken into account,where the data dropouts were assumed to occur at both the output and input sides.The recursion of the input error was first taken with an absolute operator and expectation operator,and then the convergence in expectation sense was derived using a technical lemma on contraction with respect to all previous iterations.As a result,the design condition forlearning gains is fairly restrictive.A similarproblem was also addressed in[33]following the same procedures of[32],where the difference between the two papers was the renewalof outputinformation.When removing the data dropout atthe inputside,the results for both intermittent and successive update algorithms were also given in[34].To recap,in these results,in order to allow a general successive data dropouts along the iteration axis,a restrictive convergence property for nonnegative sequences was derived and employed,which in turn may limit its applications.
Shen etal.considered the random data dropouts forstochastic systems in[35]-[42],where the stochastic approximation was employed to derive the almost-sure and mean-square convergence.First,Shen and Wang proposed the RSMfor data dropouts in[35]for both linear and nonlinear systems with stochastic noises.The almost-sure convergence was obtained by introducing a decreasing sequence to suppress the noise influence and improve the input signal.However,in[35],the control direction was assumed to be known prior,and this restriction was removed in[36],where a noveldirection probing mechanism was employed.When considering the BVM,[37],[38]also addressed both intermittent and successive update schemes with a strict almost-sure convergence analysis for linear and nonlinear systems,respectively.Note thatstochastic noises are involved in the systems.Thus,the controller design and convergence analysis are distinctfrom the existing related literature.Detailed performance comparisons between the two types of algorithms and for related design parameters were also provided in[37],[38].Moreover,the generaldata dropout case,i.e.,both networks atthe outputand inputsides suffering loss,was considered in[39]-[41]for deterministic linear systems,stochastic linear systems,and nonlinear systems,respectively.In these three papers,the data dropout was only described as a Bernoulli variable without any further restrictions on its successive dropouts.Note thatthe inputfed to the plant and the one generated at the learning controller may be different due to the lossy network at the input side.Thus,the asynchronism between the two inputs should be well depicted.In fact,such asynchronism was modeled as a Markov chain and then the almost-sure and mean-square convergence were established in the papers.The first attempt fordata dropouts modeled by Markov chain was given in[42].For both noise-free and stochastic linear systems,a unified framework was established for the design and analysis of ILC for three models,namely,RSM,BVM,and MCM.Both mean square and almost sure convergence of the input sequence to the desired input were strictly established.In short,the stochastic approximation technique is successfully applied to systems with stochastic noises and random data dropouts in the above papers.
There are scattered results on this topic such as in[43]-[47].In[43],the authors contributed a detailed analysis of the effect of data dropouts.In particular,when only a single packet at the output side or the input side was dropped,the fundamental influence of data dropouts on tracking performance was carefully evaluated and revealed that neither a contraction nor expansion arose.This technique was then extended in[44]to study the general data dropout case;that is,networks at both output and input sides suffer data dropouts.In[45],both data dropouts and communication delays were jointly considered,where the expectation operator and the traditional contraction mapping technique withλnorm were applied in sequence to show the convergence in the expectation sense.In[46],the singular coupled systems were investigated for a finite-iteration tracking problem,where the basic contraction for tracking error was established under suitable norms.In[47],the ILC problem for multi-agent systems with finite-leveled quantization and random packet losses was addressed,where the packet loss occurring at the communication networks among agents was modeled by BVM.We note that a decreasing sequence in[47],which originated from the stochastic approximation theory,ensures the asymptotical convergence.
To recap,the main techniques for addressing random data dropouts are done by either eliminating the randomness by taking mathematicalexpectation or projecting the problem into a traditional analysis framework for stochastic systems using Kalman filtering and stochastic approximation techniques.We should emphasize thatthe former method actually ignores the specific effect but considers the averaged performance of data dropouts.

TABLE I CLASSIFICATION OF THE PAPERS ON ILC UNDER DATA DROPOUTS
2)System Types:Like the development processes of other control methodologies,the research results for linear systems are much more than that for nonlinear systems.We note that ILC focuses on evolution along the iteration axis,whereas the time-axis-based dynamics is less significant due to finite operation length.Therefore,research for linear time-invariant systems and linear time-varying systems have little distinction.Results with linear systems include[21],[23],[25],[26],[28],[29],[32],[33],[39],[42],[44],[45],most of which are the discrete-time type.
There are some papers for nonlinear systems such as[27],[32]-[34],[41],[43].However,we note thatnonlinearsystems are generally ofthe affine type.This is because affine nonlinear systems separate the evolution influence of the previous state and the current input with respect to time instants.Moreover,the nonlinear functions are assumed to be globally Lipschitz.Thatis,for a nonlinear function f(x),the condition indicates‖f(x1)-f(x2)‖ ≤ kf‖x1-x2‖,where kfis a Lipschitz constant.This condition is imposed to facilitate the use of Gronwall’s technical lemma[48],which is fairly common in the convergence analysis of ILC for nonlinear systems.One promising direction forreducing restrictions on nonlinear functions is to introduce other convergence analysis methods.The case of general nonlinear functions without global Lipschitz condition is still of great significance both in theory and for practical applications.
In addition,stochastic noises are also included in systems in several papers including[22],[35]-[38],[40].Specifically,in[22],[35],[37],[40]both random systems disturbances and measurement noises are assumed for linear systems,whereas in[36],[38]only measurement noises are considered as the involved systems are nonlinear.For systems with stochastic noises,the techniques of stochastic control would play an important role in the design and analysis.We also remark that a few results on special systems are reported such as singular systems[46]and multi-agentsystems[47].Itis worth pointing out that the ILC problem for special types of systems under data dropouts have few reports.
3)Data Dropout Models:As we have clarified at the beginning of the section,there are three models of random data dropouts,namely,RSM,BVM,and MCM.The most popularmodelis BVM,where data dropouts have a clearprobability distribution and good independence.Most ILC papers adopt this model,including[21]-[23],[25]-[29],[32]-[34],[37]-[41],[44]-[46].However,a major issue in BVM is the treatmentof successive data dropouts where severallimitations are imposed in the existing literature.In particular,the data dropoutis independentfordifferenttime instants and different iterations in BVM.Thus,itis naturalthatadjacentdata packets may be dropped simultaneously.In many existing papers,in order to provide a specifi ed data compensation,additional requirements are imposed.For instance,in[27],[43],the dropped packet was compensated for with a packet onetime-instant back within the same iteration.Consequently,a limitation arises where packets at adjacent time instants are not allowed to drop within the same iteration.In[44]-[46]the lost packet was compensated for with the packet at the same time instant,butone-iteration back.Consequently,there is no simultaneous data dropoutatthe same time instantacross any two adjacent iterations under this condition.Indeed,a more suitable compensation mechanism for the lost packet is to employ the packet at the same time instant from the latestavailable iteration.In other words,say we find a packet,yk(t),which is lost during the transmission.We may replace it with the latest available packetfrom previous iterations,say yτ(t),where τ< k.Clearly,yτ(t)is successfully transmitted while yi(t)withτ+1≤ i≤ k-1 are all lost.This general compensation mechanism is investigated in[32]-[34],[37],[38],[40].
There are quite a few papers on other models.In[35],[36]the RSMwas used for data dropouts.In this case,the statistical property of data dropouts is removed and thus can vary along the iteration axis.In other words,the distinct difference with RSM is the removal of steady distribution assumptions on data dropouts.In[42],a unified framework was proposed for all the three models where MCM was first studied in the ILC fi eld.Moreover,the authors of[43]carefully analyzed the effect of single packet loss.For the multiple packet loss case,a generaldiscussion was given instead of strict analysis and description.The authors claimed that the data dropout level should be far smaller than 100%to ensure a satisfied tracking performance.In short,the development of various data dropout models other than BVM requires more effort because the quantitative depiction of the relationship between data dropouts and tracking performance is still unclear.
4)Dropout Positions:As is seen from Fig.2,there are two networks connecting the plant and the learning controller,which are separated into different sites.One is at the measurement side to transmit the output information back to the learning controller.The otheris atthe actuatorside to transmit the generated input signal to the plant for the next operation process.To facilitate convergence analysis,most papers only assume data dropouts at the measurement side,while the network at the actuator side is assumed to work well,as in[21],[22],[25],[26],[28],[29],[35]-[38].Although some papers claimed thattheirresults can be extended to the general case that both networks suffer packet loss,it is actually not a trivial extension.
In particular,when the network at the actuator side is assumed to work well,i.e.,all generated input signals can be successfully transmitted to the plant,the computed control generated by the learning controller and the actual control fed to the plant are always the same.Thus,the input used in the update algorithm is always equal to the actual control.However,when the network at the actuator side is lossy,the computed control may be lost during the transmission and then the plant has to compensate for it with other available signals.Consequently,the actual control may differ from the computed control.In other words,there exists an additional asynchronism between the computed control and the actual control.This random asynchronism imposes extra difficulty in addressing the data dropout problem since it is hard to separate from evolution dynamics as an individual variable.As a matter of fact,it has been proven in[39]-[41]that such asynchronism can be described by a Markov chain when modeling the dropouts by BVM,which paves a novel way to establish the convergence.Other papers considering the generaldata dropoutposition problem include[27],[32]-[34]where the randomness of the data dropout at the actuator side is eliminated by taking mathematical expectation for recursions of both input errors and tracking errors.
5)Update Schemes:There are two major update schemes which can be referred to when designing the update algorithms.One is event-triggering and the other one is iterationtriggering.We provide a brief explanation of the schemes by taking the algorithms in the learning controller as an example.The principle of the first update scheme is as follows:if the output information is successfully transmitted,then the learning controller employs such information to generate a new input signal;otherwise,the learning controller would stop updating until the corresponding output information is successfully transmitted in the subsequent iterations.In other words,when the corresponding packetis lost,itis replaced by 0.Clearly,this updating scheme is event-triggering.We call it an intermittent update scheme(IUS).The principle of the other update scheme is as follows:if the outputinformation is successfully transmitted,then the learning controller employs such information to generate the input,which is same as the previous update scheme;if the output information is lost during transmission,then the learning controller would employ the iteration-latest available output information for generating the input,which is different from the previous scheme.This update scheme keeps working for all iterations no matter whether the information is lost or not,so it is iterationtriggering.We call it a successive update scheme(SUS).
When considering an unreliable network atthe measurement side,ithas been shown thatboth IUS and SUS work wellfor the learning controller,as shown in[37],[38].It is worth pointing outthata SUS outperforms an IUS when the DDR is large,as it continuously improves the tracking performance.When considering the unreliable network at the actuator side,itis clearthatthe IUS scheme is notapplicable.In otherwords,the computed control packet which is lost cannot be simply replaced by 0 as it would greatly damage the tracking performance.That is,the lost input signal must be compensated for with a suitable packet to maintain the operation process of the plant.Clearly,the simple compensation mechanism is to employ the latest available input from the previous iteration.In such case,we may regard itas a SUS.As a matter of fact,such mechanism for the input has been reported in[32]-[34],[39]-[41].From another viewpoint,we could regard an IUS as a non-compensation type and a SUS as a simple compensation type.Generally,a sufficient compensation for the dropped data can effectively improve the tracking performance.Thus the specific compensation mechanism is of great significance according to particular problems,but related results are very few.
We have classified the above literature on ILC under data dropouts in Table Ifrom the mentioned five perspectives.From this table,itcan be seen thatthe data dropoutproblem has been deeply investigated from all perspectives.However,we note thatthe research for MCMand its generalization is promising.
B.Communication Delay and Limited Capacity
Besides random data dropouts,there are many other random factors caused by limited communication capacity.Communication delay is one of them,which has been witnessed to somewhatprogress in the pastdecade.In earlierattempts[23],[45],the time-delay within an iteration was discussed.Such a delay was assumed to occur for the input signal and modeled by a random matrix according to the lifted system in[23].The Kalman-filtering-based stability analysis technique was applied to derive an iteration-stability of the proposed update law.In[45]the one-step delay was addressed such that the packet could be transmitted on schedule or one-step later.A Bernoulli random variable was used to describe a random delay,of which the randomness was eliminated by taking expectation in the convergence analysis.
The Bernoulli model was then employed in[49],[50]for describing the random one-iteration communication delay,where the communication delay was assumed to occur at both the output and input sides.That is,the output signal for updating the input may come from either the current or previous iteration,and obeys a simple Bernoulli distribution.Technically,the one-iteration delay provides a certain deterministic property of the communication delay,which allows us to constructa finite-iteration contraction along the iteration axis.Indeed,in[49]the error of the(k+3)th iteration can be bounded linearly by the error of the k th,(k+1)th,and(k+2)th iterations.In[50]the authors derived an interesting condition on the probability of the occurrence of communication delay.In particular,assume the probabilities to beandfor the case where one-iteration communication delay occurs at the output side and the input side.It is deduced in[50]that the condition<0.5 should be fulfi lled.In other words,the probabilities of communication delay should be sufficiently small.This condition may shed light on the development of the inherent relationship between random communication delay and tracking performance.However,more efforts are needed to discover a quantitative description of the influence of incomplete information on tracking performance.
The successive iteration-based communication delay was considered in[51].In particular,a large-scale system consisting of several subsystems was considered in the paper,where the communication between different subsystems suffered random and possibly asynchronous communication delays due to potentially differentwork efficiency among subsystems.The communication delay was modeled similarly to the RSMgiven in the last subsection and decentralized ILC algorithms were constructed based on available information.However,due to random successive communication delays,the memory was assumed to have enough capacity such that the arrived data can be well stored.An extreme case for the memory size is that only the data of one iteration can be accommodated by the memory.Clearly,it is the minimum buffer capacity to ensure the learning process.Such a case was studied in[52],where multiple communication constraints were considered for networked nonlinear systems,including data dropouts,communication delays,and packet disordering.In that paper,a RSM was employed to describe the combined effect of the multiple communication constraints.Both an IUS and a SUS were applied to construct the learning algorithms.Compared with[50],the restrictions on occurrence probability ofcommunication delays were removed and successive communication delays were allowed in the progress.However,we would like to remark that the research on ILC with communication delays has gained little attention from scholars compared with that on ILC with data dropouts.The randomness of uncertain communication delay may lead to a mismatch of the input and tracking error in the update law(for example,(3)).It is vital to figure out the effect of this mismatch in convergence analysis and provide a data compensation mechanism in control synthesis.
C.Iteration-Varying Lengths
In Section III-A,the data dropout is considered independently for different time instants,whereas in practical applications,the data may be dropped dependently along the time axis.In other words,the data dropouts atthe former time instants would have a directinfluence on those atthe latertime instants within the same iteration.For example,if one data packet is dropped due to a linkage fault at some time instant,then the following data of the iteration may be all dropped.That is,to the learning controller,the iteration ends early.It results in a typical problem,called the iteration-varying length problem.This problem has been encountered in certain biomedical application systems.For example,while applying ILC in a functional electrical stimulation(FES)for upper limb movement and gait assistance,it has been seen that the operation processes end early for at least the first few passes due to safety considerations because the output significantly deviates from the desired trajectory[53].The FES-induced foot motion and the associated variable-length-trial problem are detailed in[54]and[55],which clearly demonstrate the violation ofthe identical-trial-length assumption typically used in ILC.Another example can be seen in the analysis of humanoid and biped walking robots,which feature periodic or quasi-periodic gaits[56].For analysis,these gaits are divided into phases that are defined by the time at which the foot strikes the ground,and the duration of the resulting phases are usually not the same from iteration to iteration.A third example can be found in[57],where the trajectory-tracking problem for a lab-scale gantry crane was investigated.In this example,the output was constrained to be within a small neighborhood of the desired reference,because the iteration would end if the output drifted outside the specified boundary,thereby resulting in the varying-length iteration problem.Whether caused by the communication limits or by the safety consideration,iteration-varying length problem always results in incomplete information problem for the learning process.
There were some early research attempts to provide a suitable design and analysis framework for the iterationvarying length problem thatcontributed to the groundwork for subsequent investigations[53]-[57].For example,based on experimental verifications and primary convergence analysis that were given in[53]-[55],a systematic proof of the monotonic convergence in different norm senses were further elaborated in[58].In particular,necessary and sufficient conditions for monotonic convergence were derived strictly by carefully analyzing the path property of the proposed algorithm.Moreover,other issues including the controller design guidelines and influence of disturbances were also discussed.However,no specific formulation of iteration-varying length was imposed in this framework as itconcerned the contraction between adjacent iterations.
The first random model of iteration-varying length was proposed in[59]for discrete-time systems and then extended to continuous-time systems in[60].In the model,a binary random variable was used to represent the occurrence of the output at each time instant and each iteration;that is,the random variable is equal to 1 if the output appears and 0 otherwise(similar to the model of data dropout).The variable was then multiplied with the tracking error denoting the actual information of the update process.To compensate for the lost information,an iteration-average operator for averaging all historical data was introduced to the ILC algorithm in[59],whereas in[60],this average operator was replaced by a moving-iteration-average operator to reduce the infl uence of very old data.Both operators provide good compensation as shown by the theoretical analysis and simulations.Moreover,a lifted framework of ILC ofa discrete-time linearsystem was provided in[61]to avoid the conservatism of the conventional λ-norm-based contraction analysis in[59],[60].In these papers,we note two distinct points that the asymptotical convergence in mathematicalexpectation sense is derived and the distribution of the introduced random variable is known to the controller.
Stronger convergence results were given in[62]and[63]for linear and nonlinear discrete-time systems,respectively.In particular,the classical P-type ILC algorithm was employed for the discrete-time linear system in[62],where the possible iteration length has finite cases.Next,the evolution of lifted-error-vectors along the iteration axis was transformed into a random switching system with finite switching states.Consequently,the authors established recursive computation formulas of such vectors’statistics(i.e.,the mathematical expectations and covariances).The convergence in the mathematicalexpectation,mean square,and almostsure senses were derived simultaneously.In[63]the affine nonlinear system was considered.It is clear that the lifting techniques cannot be applied to such types of systems.As a result,a technical lemma on the commutativity of the expectation operator and the absolute-value operator was first created for paving a novel way to derive the strong convergence.A recent work[64]proposed two improved ILC schemes to fully utilize the iteration-moving-average operator.Specifically,a searching mechanism was introduced to collectusefulinformation while avoiding redundant tracking information from the past,so a faster convergence speed was expected.In these contributions,the probability distribution of the random length is notrequired prior.
In addition,some extensions have also been reported in the existing literature.Nonlinear stochastic systems were investigated in[65],where the bounded disturbances were included.The average-operator-based scheme similar to[59]was improved by collecting all available information.Nevertheless,we note that a Gaussian distribution of the variable iteration length was assumed,which limits the possible application range.In[66],the authors extended the method to discrete-time linear systems with a vector relative degree.Thus,we need to carefully select the output data for the learning algorithms.In addition,the variable length issue was extended to stochastic impulse differential equations in[67]and fractional order systems in[68].The sampled-data controlfor continuous-time nonlinear systems was proposed in[69],where both the generic PD-type and a modified PD-type scheme were employed with suitable design conditions of the learning matrices.We remark that the convergence analyses derived in these papers were primarily based on the mature contraction mapping method.
In short,as a special case of passive incomplete information,the iteration-varying length problem has gained some progress.However,the existing literature has witnessed the following limitations.First,most papers considered discretetime systems so that the possible length has finite outcomes.Second,the systems are limited to be linear or globally Lipschitz nonlinear.Third,the average-operator-based design of ILC controller is widely studied,which motivates us to consider how to efficiently use the available information.Novel analysis techniques are also of great interest to replace the conventional contraction-mapping method.Additionally,the randomly iteration-varying length problem can be regarded as a special case of the data dropout problem;that is,the former is a time-axis-based successive dropoutcase(from the actualending time instant to the desired ending time instant).Therefore,the results in ILC with data dropouts can be applied to deal with the varying length problem and vice versa.
IV.ILC WITH ACTIVE INCOMPLETE INFORMATION
In the previous section,we reviewed recent progress on ILC with passive incomplete information.In the section,we proceed to review the progress on ILC with active incomplete information.In other words,we collect the papers where information quality is intentionally reduced.Two major reduction actions are considered,namely,sampled-data ILC and quantized ILC.The former case indicates that only the signal at assigned time instants,rather than the whole time interval,are available,and the latter case indicates thatonly the assigned values rather than the precise values are available.By sampling and quantization,we can heavily reduce the amount of the data.
A.Sampled-Data ILC
In this subsection,we present a review of sampled-data ILC from the perspective of research issues.Before that,we fi rst formulate the problem of sampled-data ILC,as shown in Fig.5.LetΔTbe the sampling period of the digital control system and NΔT=T,where T is the iteration length and N is the totalsampling numberwithin one iteration.Forsampleddata ILC,only information on the sampling time instants nΔT,0≤n≤N,is available.The block diagram in Fig.5 consists of a sampler atthe outputside to generate sampled output and a holder at the input side to regain continuous signal for the controlled plant.
There are two primary problems associated with sampleddata ILC:the behavior at the sampling instants and how the interval performance(between sampling instants)is.To be specific,the former aims to construct suitable learning algorithms to guarantee convergence atthe sampling instants,and the latter focuses on quantitative analysis of the tracking performance between differentsampling instants and possible solutions to reduce the tracking errors in the sampling interval.Generally,the former problem is similar to discrete-time ILC as they share the same design and analysis techniques.However,the latter problem indeed makes sampled-data ILC different from the traditional discrete-time systems.
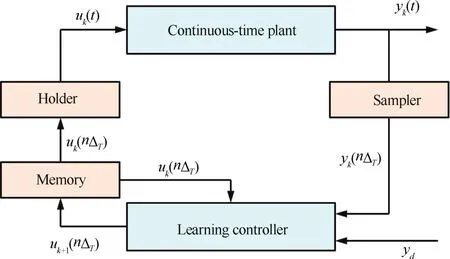
Fig.5.The research framework of sampled-data ILC.
Considering the system models,both linear and affine nonlinear systems withoutdisturbances attractthe mostattention,and both linear and affine nonlinear systems with bounded disturbances have been under investigation,while the other systems are of little consideration.The reference classification is given in Table II.These papers are mainly written by several research groups with different special interests.Therefore,we review the publications by the research interests/groups.In each category,four perspectives of the publications are explored,i.e.,the system model,the update scheme,the convergence result,and the analysis techniques.
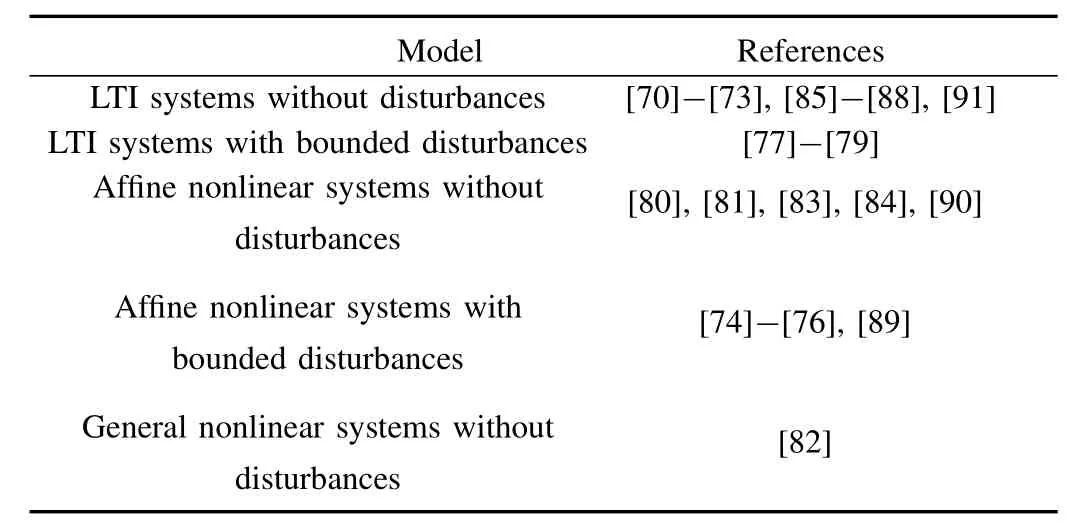
TABLE II CLASSIFICATION OF REFERENCES FOR SAMPLED-DATA ILC
1)Frequency-Based Sampled-Data ILC:The frequencybased design and analysis of sampled-data ILC are presented in[70]-[73],where the kernel issue focuses on the fundamental analysis and synthesis of sampled-data theory in ILC.
Reference[70]presented a framework for the design and analysis of sampled-data ILC in both time and frequency domains.For a fundamental framework,the LTI system was adopted,while P-type,D-type,D2-type,and generalfilteralgorithms were studied with deriving the sufficientconditions for monotonic convergence.The relative degree issue between the continuous-time system and its corresponding sampled-data system was remarked upon.These theoreticalresults were then experimentally verified by a piezoelectric motor in[71]and some selection guidelines were also provided for practicalapplications.In[72],a novelsampled-data ILC algorithm in the frequency form was proposed for the extreme precision motion tracking problem of a piezoelectric positioning stage.The convergence condition and the robustness analysis under the inverse model in the frequency field were expressed with an experimental validation.It was shown that sampled-data ILC is better than conventional open-loop control and PI control.This problem was extended in[73],where a sampled-data ILC was added to a direct feedback control with both repeatable and nonrepeatable components simultaneously.As verified by experimentstudies,this combination was demonstrated to have an advantage in precise tracking and fast convergence speed.In short,frequency-based design and analysis is an interesting perspective for sampled-data ILC,but there still exist many areas to be investigated by scholars and engineers.
2)Bounded Convergence Under Bounded Disturbances:A series of papers on the bounded set convergence at the sampling time instants are contributed for linear and nonlinear systems with bounded disturbances[74]-[79].In these papers,bounded system disturbances wk(t)and/or measurement noises vk(t)are added to the linear and nonlinear systems,that is, ‖wk(t)‖ ≤ ϵ1, ‖vk(t)‖ ≤ ϵ2,where ϵ1and ϵ2are some positive constants.In addition,the initial state error is also assumed to be bounded,i.e., ‖xk(0)-x0‖ ≤ ϵ3,where x0denotes the desired initial state andϵ3is a positive constant.Due to the existence of such unknown disturbances,it is difficult to expect zero-error tracking performance no matter whether atallsampling instants or during the sampling interval.Instead,it is shown that the tracking errors at the sampling instants converged to a set whose bounds are a function ofϵi,i=1,2,3.The majordifferences between these papers lie in the design of updating schemes.
In an early paper[74],the conventional P-type update law was employed using the available sampling information for affine nonlinear systems.The convergence was conducted based on the well-knownλ-norm techniques.As is pointed out in many papers,the convergence inλ-norm might result in poor transient performance before coming to ultimate convergence.The result in common norm sense was given in[75]according to the D-type update law,where a directcalculation on the inequalities of the input error norm led to a contraction mapping.A similarproblem was also addressed in[76].Papers[77]-[79]concentrated on the impact of involving current iteration tracking error or feedback control for LTI systems.In particular,[77]constructed an update law with only the tracking errors from the current iteration and as a result a lot of storage can be saved facilitating practical applications.An extension to general formulations of the update law was provided in[79],where a fullutilization of the tracking errors in the currentiteration was deeply discussed.The convergence was established using the Lyapunov method.The combination of feedback control and ILC for sampled-data was proposed in[78].
It is noted that different update algorithms are investigated by Chien and his co-workers including P-type,D-type,and feedback of current error.This research mainly focuses on bounded convergence to some given setby letting the sampling period be small enough under bounded disturbances.
3)Sampled-Data ILC With Arbitrary Relative Degree:An in-depth study on sampled-data ILC fornonlinear systems with arbitrary relative degree was carried out in[80]-[84].The relative degree is a description ofthe input-outputrelationship,which reflects the minimum effect order between the input and its corresponding output.For continuous-time systems,the relative degree is defined by the Lie derivative of the output with respect to the input;for discrete-time systems,it is defined by the function composition.However,for sampleddata control,the integral should be included to define the relative degree.Consider the following SISO affine nonlinear systems as an example,
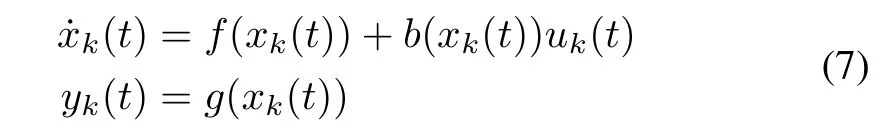
where f(·),b(·),and g(·)are nonlinear functions.The above system with input generated by a zero-order holder from sampled signals has extended relative degreeηfor xk(t),if,∀0≤ j≤ N-1,
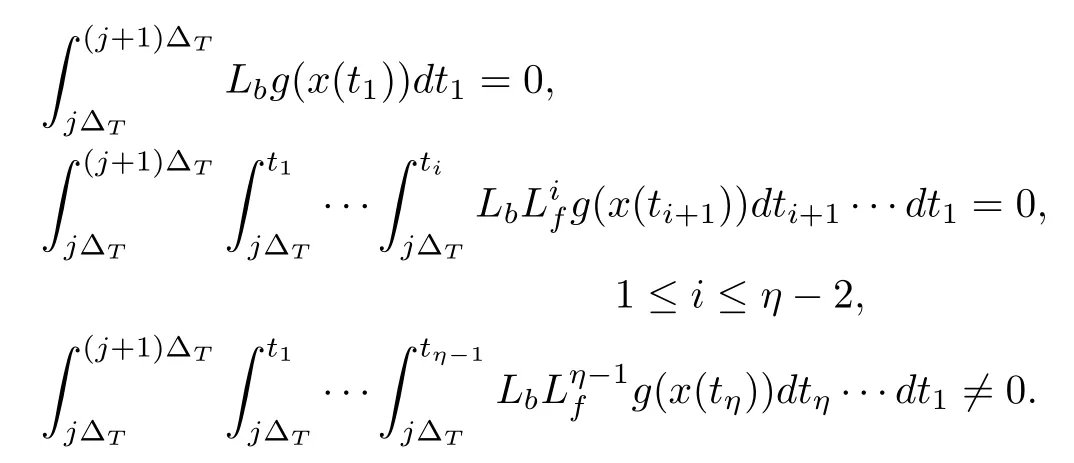
Roughly speaking,a relative degree larger than 1 indicates that the directinput-output coupling matrix is zero.In such a case,it is interesting to ask whether the conventional P-type update scheme guarantees the convergence.Such a problem was resolved in[80]-[82].In particular,it was shown in[80],[81]that the basic P-type scheme based on the available sampled data can ensure a zero-errortracking forthe sampling time instants.It was then extended to a general case called sampled-data ILC with lower-orderdifferentiations forgeneral nonlinear systems in[82],where the authors used lower-order to indicate that the derivative in the learning controller was less than the relative degree.
Another important issue is the initial rectifying problem[83],[84].In other words,the initial state is shifted from its desired value.These papers propose an effective rectifying mechanism such that the actual output would be shifted back to the desired one after some time interval.In[83],the fixed initialshiftwas considered and the proposed initialrectifying action was able to drive the system output to the desired trajectory within a specified error bound.Then the initialshift was extended to an arbitrarily varying case and a so-called varying-order sampled-data ILC was designed and analyzed.In all the studies,the convergence analysis was established with the help of a technical lemma,which is an extension of the contraction mapping principle.
4)Interval Performance of Sampled-Data ILC:It is observed that in papers such as[74]-[84],only the performance at the sampling instants is considered while the intersample behavior is seldom discussed.However,achieving good performance at the sampling instants(at-sample)can be at the expense of poor intersample behavior[85].However,guaranteeing acceptable intersample tracking performance is a difficult problem for sampled-data ILC.Early attempts are given in[86],[87].
In[86],the multirate ILC approach was proposed to balance the at-sample performance and the intersample behavior,where the key idea was to generate a command signal at a low sampling rate by using fast sampled measurements.The details of multirate systems and multirate ILC were given to enable an optimal sampled-data ILC in the paper.Further,the authors developed an ILC framework for sampled-data systems by incorporating the system identification and a loworder optimal ILC controller in[87],as an on-going study of[86].The proposed system identification procedure delivers a modelthatencompasses the intersample in a multirate setting for the closed-loop system so that the resulting model could be used for the optimal ILC synthesis.As a consequence,the computationalburden is much less than common optimizationbased algorithms for large systems.
In short,there still lack more in-depth studies on the intersample behavior of sampled-data ILC including novel design and analysis technique for improving the tracking performance between different sampling instants.
5)Scattered Contributions:Reference[88]presented a limiting property of the inverse of sampled-data systems.To be specific,fora continuous-time system with a relative degree of one or two,the inverse of the corresponding sampled-data system can approximate the inverse of the originalcontinuoustime system independently of the stability of the zeros as the sampling periodΔTgoes to zero.
Time-delay was introduced into the affine nonlinear model in[89]with other settings similar to[74],[75].The PD-type update scheme was employed with a bounded convergence analysis;however,the differential signal is not suitable for sampled-data implementation.
The sampled-data ILC forsingularsystems was addressed in[90]using a P-type learning algorithm andλ-norm techniques.An online optimal sampled-data ILC problem was dealt with in[91]for LTI system with bounded disturbances,where the control objective was to minimize a smooth objective function of inputs and outputs.A gradient descent method was employed to generate the optimal solution iteratively.
Based on the above reviews,we have severalremarks.First of all,much attention is paid to LTI and affine nonlinear systems with/without bounded disturbances,whereas there has been little progress with time-varying systems,general nonlinear systems,and stochastic systems.Moreover,most papers contribute to the at-sample performance,while the intersample behavior is seldom considered.However,good at-sample tracking performance does not necessarily imply acceptable intersample behavior.Furthermore,the traditional contraction mapping method and its extensions are the main technique for convergence analysis,which restricts the research range of systems and problems.Last but not least,the implementation of sampled-data ILC in practical applications is of greatsignificance,butfew publications are found on this direction[92].Therefore,a systematic framework of sampleddata ILC is yetblank and much effortshould be made by considering the above aspects of sampled-data ILC.Meanwhile,a sampled-data controlmethodology is usually combined with the quantized technique to further reduce the data amount,where the latter is reviewed in the next subsection.
B.Quantized ILC
To reduce the communication burden,another effective method is to introduce a quantization mechanism.That is,we firstquantize the measured signaland then transmitthe signal.In fact,the quantization method has been deeply studied in the networked control field;however,few papers have been reported on quantized ILC.
An early attempt on the quantized ILC was given in[93],where the output measurements were quantized by a logarithmic quantizer and then fed to the controller for updating ILC law.By using the sector bound technique and conventional contraction mapping method,it was shown that the tracking errorconverged to a smallrange whose upperbound depended on the quantization density.Meanwhile,the tracking error also depended on the target value,which can be seen from the expression of the upper bound.That is,the larger the output measurement is,the larger the final tracking error upperbound is.To achieve zero-errortracking performance,an alternative framework was proposed in[94],where the desired reference was first transmitted to the local plant to generate a tracking error and then the tracking error was quantized by a logarithm quantizer and transmitted.In other words,the tracking error,rather than the output signal,was quantized.This scheme can guarantee the zero-errorconvergence with the inherent principle of the logarithmic quantizer.The extension to stochastic systems was addressed in[95],where a detailed comparison of the tracking index was provided by considering both stochastic noises and quantization error.It can be seen from the simulations that the ultimate index value is completely generated by the stochastic noises,indicating that the quantization error is eliminated asymptotically.The extension of the above quantization methods to input quantization case was provided in[96]with similar conclusions of[93],[94].Similar idea of quantizing the measured error was also used in[97],[98]for dealing with discrete-time and continuoustime multi-agent systems,respectively.We remark that the logarithm quantizer should have infinitesimal precision near zero,which is hard to implement in applications.Thus,it is importantto propose new quantization mechanisms to improve the tracking performance.
In[99],a uniform quantizer was used with an additional scaling mechanism implemented between the plant and controller.In this case,the measured signalis firstscaled by prior scaling functions and then quantized by the uniform quantizer;then,at the controller,the received signal is converted using the scaling functions again to obtain a well-approximation of the original signal.Such process is called the encoding and decoding mechanism.In fact,the scaling functions play a role to enhance quantization precision.In[47],another quantization method calledΣΔ-quantizer,of which the parameters selection ensured a quantization bound similarly to the logarithm sector bounded property,was introduced.The quantization errorwas treated as a zero-mean martingale difference sequence,which may be a restrictive condition.In[100],a probabilistic quantizer was first introduced into the design of quantized ILC.This quantizer clearly produces a random quantization error with zero-mean and bounded variance.As a result,with the help of a decreasing learning gain,it can be proven that the actual tracking error would converge to zero although a rough uniform probabilistic quantizer.These results show a promising research direction for addressing the quantized ILC problem according to practical requirements.
In sum,quantized ILC is still in its first stage compared with more fruitfulresults using conventionalquantized control.Two valuable research directions should be highlighted forthis issue.The firstone is to provide an estimation on the relationship between quantized data and the tracking performance.The other one is to investigate effective soft mechanisms for data acquiring,transforming,transmitting,and recovering to eliminate or reduce the effect of quantized data.
V.DATA ROBUSTNESS AND PROMISING DIRECTIONS
As has been explained in the previous sections,ILC requires little information on the system matrices.In other words,the design of learning controller mainly depends on the input and tracking information of the previous iterations.Thus,it is a typical data-driven method[101].From this viewpoint,the ILC problem under incomplete information essentially is a data robustness problem.Thatis,the inherentcontrolobjective is to investigate how the controlschemes perform according to differentlevels ofdata loss.Generally,ifthe designed learning control scheme can behave well even if most data is lost due to various restriction conditions,we say the scheme has good data robustness;ifthe designed learning controlscheme is very sensitive to the data loss,we say the scheme has poor data robustness.However,we should note that the concept of data robustness is stillunclear[101],and therefore,the research on ILC under incomplete information would settle a fundamental cognition and may guide us to find a direction in establishing the data robustness for data-driven control.

Fig.6. The research triple of ILC with incomplete information.
In the traditional control theory,robust control indicates an approach to controller design for dealing with model and/or parameter uncertainty.We define the robustness of this framework as the property of maintaining certain control performance when the uncertain parameters or disturbances vary within some set(typically compact).Therefore,the traditional control robustness is defined with respect to the system itself.While considering the data-driven control,the system information is excluded.Thus,it is not suitable to follow the above definition of controlrobustness.As a matter offact,the robustness fordata-driven controlshould be coined with respect to the information/data itself.Particularly,the inherentrelationship between the incomplete information/data and the control performance would explicitly describe the robustness issue.Along this line,we would like to share the following points.First,the average data loss can approximate 100%in various passive incomplete information cases(e.g.,data dropouts)while retaining the asymptotical convergence.That is,the DDR can be any number less than 1 while the convergence of ILC algorithm is guaranteed.Thus,there may not exist a critical value of the data loss for data robustness issue.Second,although the asymptotical convergence can be ensured when large data loss appears,the transient performance of the learning algorithms would generally deteriorate(for example with the slow convergence speed and transient growth problems).Thus,the description of data robustness should take these indices into account.Third,data-driven control features little modelinformation in designing the controlalgorithms and thus,the data robustness may be defined independentof the system model.Thatis,the data robustness should be same for allor atleastmosttypes of systems.In sum,a mathematicalformulation of such definition needs more investigations.
In ILC with incomplete information,the emphasis should be put on the robustness significance contained in the lost information and related controlsystem design.In other words,we should concentrate on the in-depth understanding of the restriction and trade-off between the information and tracking indices of ILC(such as tracking precision,convergence speed,control energy,and data amount).Based on this relation,we can evaluate the key factors of improving the tracking performance when losing partial data.In this respect,we highlight the following possible prospective research topics.
1)A good solution for data dropout problem can be extended to many other types of incomplete information environments;thus,it deserves more deep investigations on the essential points,for examples,the quantitative influence ofdata dropouts on tracking performance,novelcompensation mechanisms of the lost data with respect to specified objectives,and the controllerdesign and analysis undergeneraldata dropout environments.
2)When considering communication channels,many open problems are waiting for profound exploration and exploitation on various communication constraints such as random communication delay and multiple delays,random and/or unrecognized packet disordering,very limited communication bandwidth,insufficient memory storage,and multi-channel transmission and fusion problem.Moreover,the combined effectofmultiple communication constraints is also of interest.
3)Sampling is an effective and economic treatment of continuous-time systems using computer technology,whereas the specific involvementofsampling techniques is notso clear for applications.It yet lacks an explicit answer to the many practical requirements such as the lowest sampling frequency,the specific sampling pattern(uniform or nonuniform),the inherentrelation between the sampling pattern and the control performance.Moreover,itis also importantto develop suitable sampling framework to satisfy the trade-offbetween minimum data amount and optimal tracking performance.
4)Quantized ILC is in its embryonic stage as only tentative convergence results for the common quantizer are provided,whereas the essential performance improvements based on finite precision quantizer are notinvestigated.The kernelissue is to deal with the inevitable quantization error,find out the tracking limitation using quantized data,search suitable treatments for eliminating or reducing the effect of quantization,and establish the analysis and synthesis framework for quantized ILC.
5)In the existing literature,the passive incomplete information is generally formulated by random variables and techniques in stochastic control are applied to derive the performance analysis,whereas the active incomplete information is usually described as a certain loss variable and the bounded convergence analysis for conventional ILC is achieved.Since the ILC problem can be well conducted as a repetitive process[102],it is expected the repetitive process based approach can provide a meaningfulsolution framework to the ILC with incomplete information.
When investigating the data robustness issue of ILC,we should pay special attention to the triple shown in Fig.6:(incomplete)information,index,and control.The incomplete information not only includes both passive and active types,but also includes a mixture of both.The indices contain tracking precision,convergence speed,input energy,etc.The controlpartincludes algorithms design and analysis as wellas the experimental verification of the theoretical results.Based on this triple,we have a triple of key points in investigation:restrictive relationship,controlsystem,and synthesis/analysis.In particular,the restrictive relationship between the incomplete information and controlindices plays a fundamentalrole.With an in-depth understanding of the relationship,one can implement the specific realization of the control system and then establish the synthesis and analysis framework for the specific problems.
VI.CONCLUSIONS
In this paper,we have surveyed the recent progress on ILC with incomplete information,which is caused by practicalconditions,or passive incomplete information,and manmade treatments,or active incomplete information.For passive incomplete information,the random loss conditions such as data dropouts,communication delay and constraints,and iteration-varying lengths are given much attention.For active incomplete information,we focus on the sampled-data ILC and quantized ILC,both of which considerably reduce the amount of data required for acquiring and processing.Based on this survey,it is observed that ILC with incomplete information is actually a case of the data robustness problem.For such a problem,two issues should be given sufficient concern:the first is to evaluate the influence of incomplete information on control performance,and the second is to design a suitable synthesis and analysis framework.It is expected that this survey will give the reader a better understanding of ILC with incomplete information and provide usefulguidelines for further research to perfect the framework.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Fundamental Issues in Networked Control Systems
- Adaptive Neural Network-Based Control for a Class of Nonlinear Pure-Feedback Systems With Time-Varying Full State Constraints
- A Dynamic Road Incident Information Delivery Strategy to Reduce Urban Traffic Congestion
- Feed-Forward Active Noise Control System Using Microphone Array
- Energy Efficient Predictive Control for Vapor Compression Refrigeration Cycle Systems
- A Robust Reserve Scheduling Method Considering Asymmetrical Wind Power Distribution