一种改进的基于N-List的频繁项集挖掘算法
2018-09-26孙建言
翟 悦 王 璨 孙建言
(大连科技学院信息科学系 辽宁 大连 116052)
0 引 言
频繁项集挖掘是数据挖掘研究中最为突出的任务之一,也是数据挖掘中最为耗时的部分,一旦挖掘出所有的频繁项集,关联规则即可通过简单的数学计算得到,可以说频繁项集挖掘算法的效率直接影响着整个数据挖掘的效率,因此十分有必要深入研究频繁项集挖掘算法。传统数据频繁项集挖掘算法主要分为两类: 一类是以Apriori算法为代表的产生候选频繁项集的挖掘算法,Apriori类算法具有需要重复扫描数据库及产生大量候选项集等缺陷;另一类是FP-growth为代表的采用分而治之策略挖掘频繁项集算法,该种采用频繁模式增长类的算法将数据压缩到FP-tree,需要递归构建条件FP-tree,时间性能无法保证。
尽管近年来研究者提出诸多改进的频繁项集挖掘算法,但当事务数据库非常稠密,并且最小支持度设定非常低时, 频繁项集数量会随着其长度呈指数型增长,频繁项集挖掘时间复杂度仍然存在下降空间。因此,Deng等[3-4]提出了基于PPC-tree结构的挖掘算法PrePost,利用一种新的数据结构N-List,通过N-List的交集运算求得项集支持度,它在频繁项集挖掘中有很高的效率。Song等[2]提出的包含因子概念提高了频繁项集的挖掘速度。
本文提出一种借鉴包含因子概念融入PrePost算法,结合两种策略的优势,给出HNSFI算法。该算法利用哈希表存储N-List数据结构所表示的项集,N-List表示的项集与FP-tree相比拥有较高的压缩率,哈希表存储利用空间换时间的方法进一步降低N-List相交运算的时间复杂度,并可根据性质快速计算项集的支持度,同时结合项集的包含因子概念省略某些情况下N-List相交运算过程。包含因子及其相关定理可直接生成频繁项集,当数据集比较稠密时,包含因子的生成时间代价远远小于大量N-List相交运算以及支持度计算时间,因此本文算法特别适合应用在稠密数据库。
1 相关工作
设I={i1,i2,…,in}是n个不同项目的集合,如果对一个集合X,有:X⊆I且k=|X|,则X称为k项集。记D为事务T的集合,T⊆I。对于如表1所示给定事务数据库D共有n条记录, 包含项集X的事务集合记为g(X)={t∈D|∀i∈X,i∈t},集合X的支持数为D中包含X的事务个数,记为X.count;X的支持度为sup(X)=X.count/n,用户可自定义一个最小支持度,记为minsup[5]。
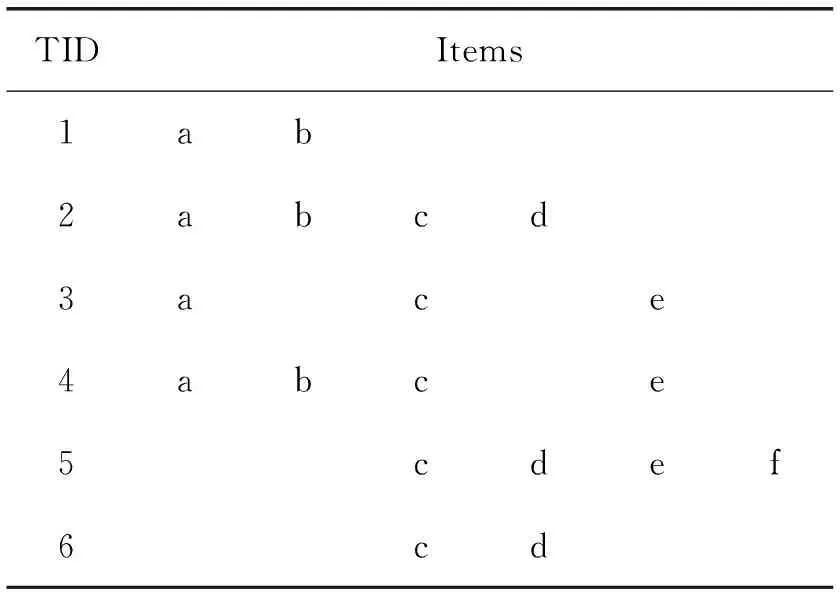
表1 事务数据库D
定义1[11]给定事务数据库D和minsup,对于项集X⊆I,若sup(X)≥minsup,则称X为D中的频繁项集。
定义2[1]PPC树定义如下:
每个结点N由5 个域组成,分别是N.item、N.count、N.preorder、N.postorder和N.child。其中,item表示项集;count域记录了项集的支持数;preorder 域为前序遍历PPC树的序号;postorder 域为后序遍历PPC树的序号;child域指向N的孩子结点。另根结点root.preorder=0,其余各域值均为null。
如表1所示数据,对每个事物项按照出现频度降序排列,如表2所示,根据文献[3]提出的prepost算法生成PPC树如图1所示。
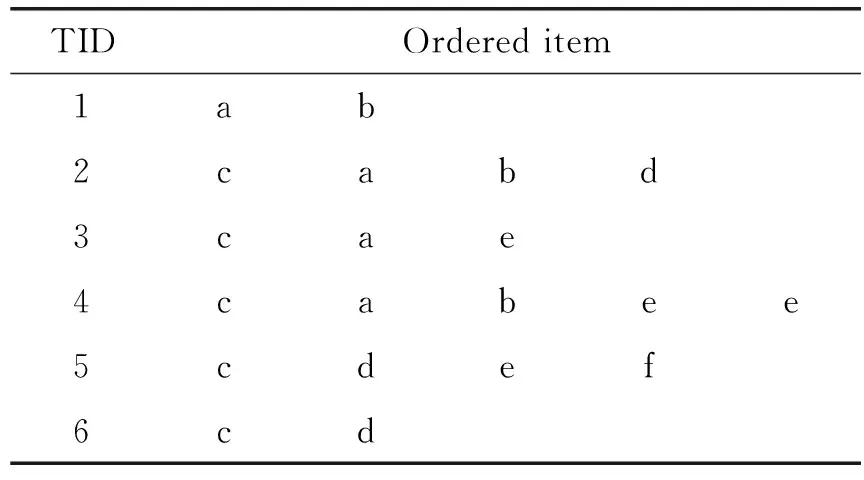
表2 按事物项出现频度降序排列事务数据库D
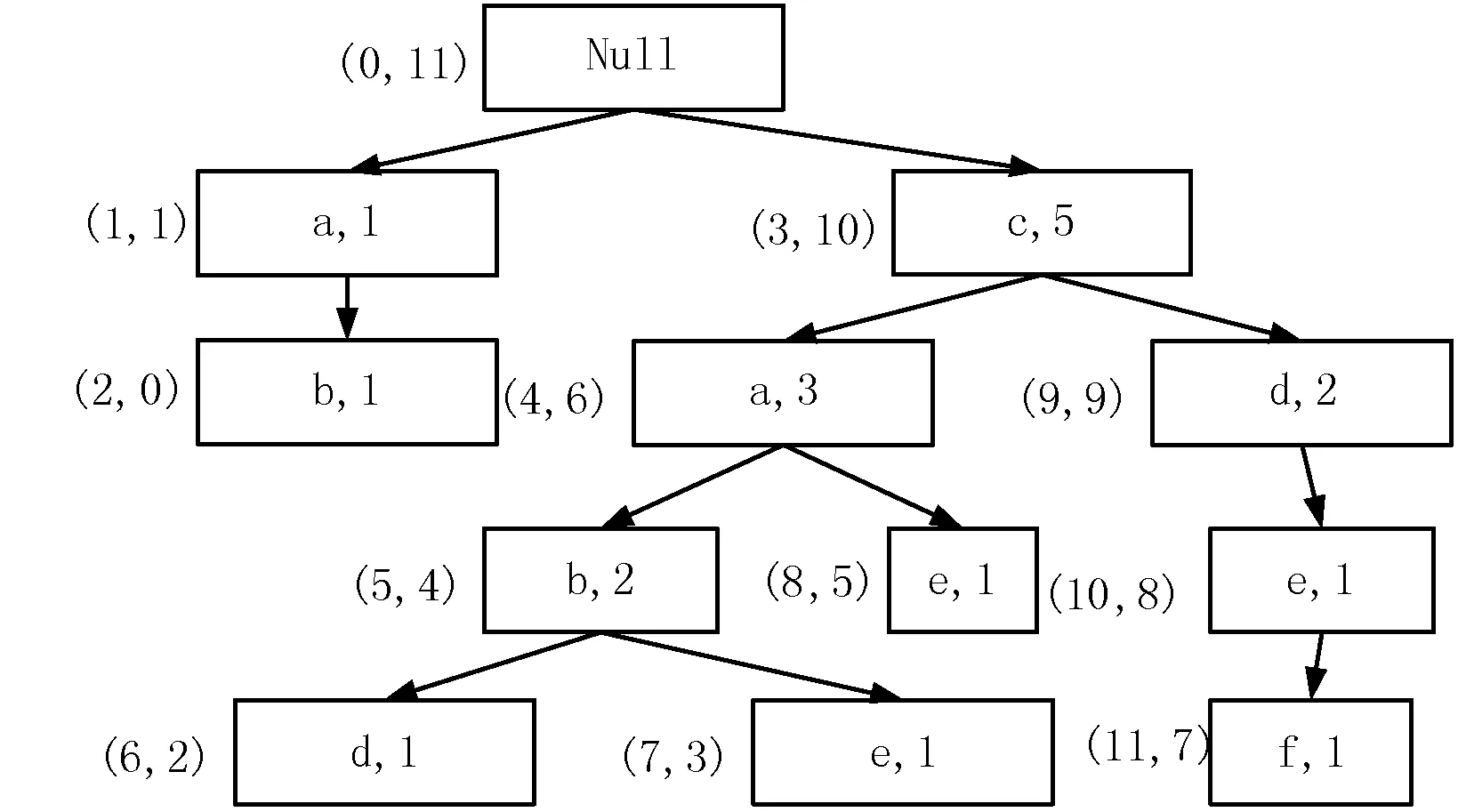
图1 事务数据库D生成的PPC树
2 构造哈希表存储的N-List
2.1 引用哈希表存储N-List
本文提出利用2级的哈希表存储N-List,这样可以加快N-List相交计算的运算速度,改进文献[3]提出N-List交集算法性能。为了避免1级哈希表在键值上的冲突,本文设置2级的哈希表结构如下:1)第1级,使用项目集的长度定为键值;2)第2级,项目集中包含的各个项的键值累加和作为新键值存储;为了进一步避免不同的项目级对应的键值产生冲突,本文使用素数序列作为1-项集的键值Key。如表3中列出1-项集的键值序列为素数序列,2-项集中项集ab的键值计算为:Key(a)+Key(b)=3+5=8。
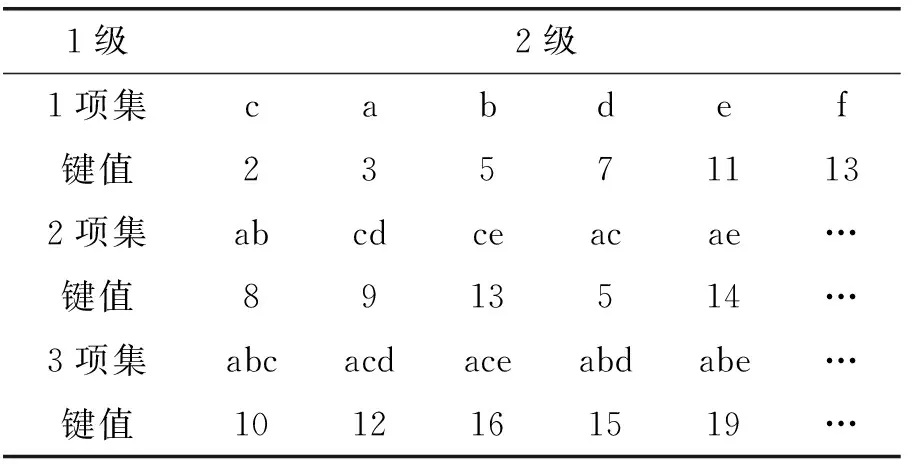
表3 使用哈希表存储N-List的键值
定义3[3]N-List结点由PPC树结点中3个域组成,表示为ppi=Ni.preorder,Ni.postorder,Ni.count。
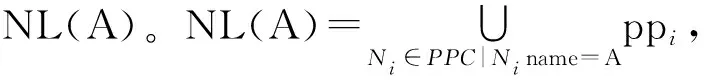
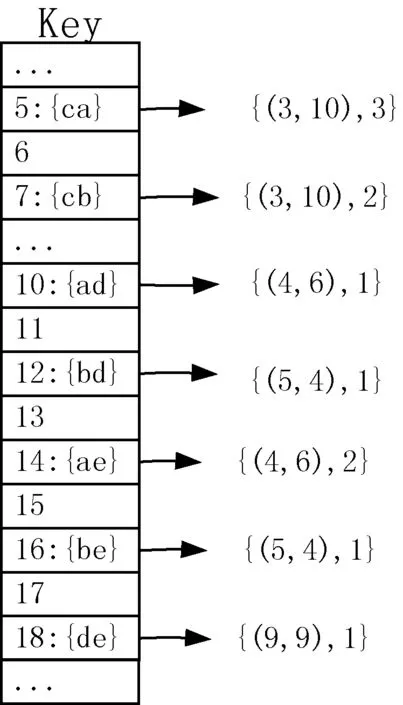
由定义4,按照文献[1]提出的N-List建立方法生成哈希存储的1-项集N-List如图2所示。其中每个1-项集的链表结点按照前序遍历顺序链接。

图2 表2对应的哈希存储的1-项集的N-List
性质1K-项集P对应的N-list为NL(P)={pp1,pp2,…,ppn}
可知P.count=pp1.count+pp2.count+…+ppn.count
例如:键值为3的哈希表存储的{a}存在2个链接结点{(1,1),1},{(4,6),3},按照性质1可知1-项集{a}的支持数a.count=1+3=4。
2.2 哈希存储N-list的链接方法
性质2假设∀ppi,ppj,当且仅当ppi.preorder< ppj.preorder,且ppi.postorder>ppj.postorder时,则称ppi为ppj的前驱结点,记为ppi∝ppj。
例如:ppi={(3,10),5},ppj={(11,7),1},因为ppi.preorder=3
定义5假设XA与XB是两个前缀同为X的k-1项集,由其对应的NL(XA)与NL(XB)合并生成k-项集的N-list的步骤如下:
1) ∀ppXA∈NL(XA), ∀ppXB∈NL(XB),如果ppXA∝ppXB,则生成结点(ppXA.pre,ppXA.post,ppXB.count)∈NL(XAB)。
2) 合并NL(XAB)中前序和后序值相同的结点。
由定义5可知,NL(c)={(3,10),5},NL(d)={<(6,2),1>,<(9,9),2>},NL(cd)生成过程如图3所示。根据性质2可知结点{(3,10),5}为结点{(6,2),1}的前驱结点,因此将结点{(3,10),1}插入NL(cd)中,同理结点{(3,10),5}∝{(9,9),2},故{(3,10),2}也同样插入NL(cd)中。
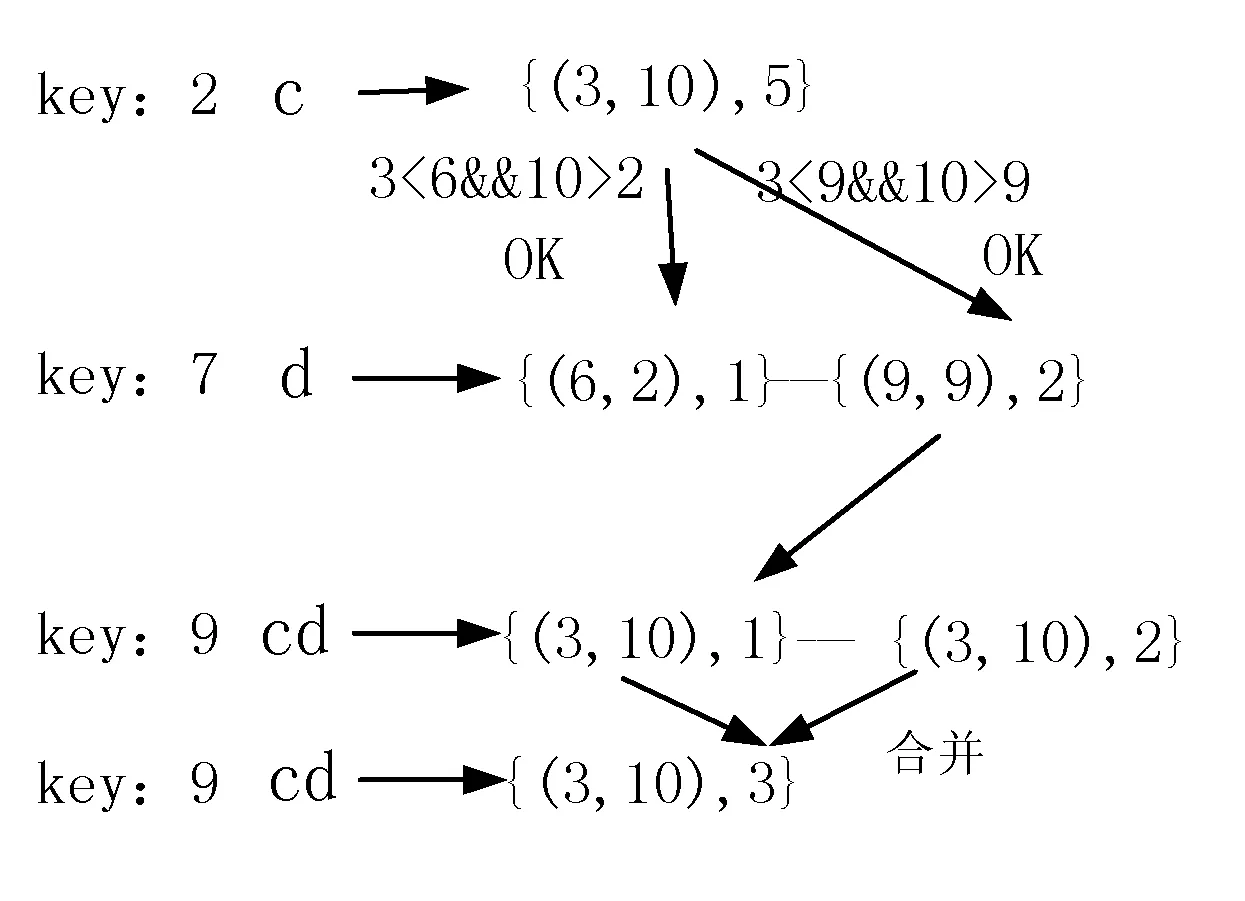
图3 N-list合并生成cd的过程
3 包含因子与N-List相交运算
3.1 包含因子的引入
定义6[6]假设i为一个项目集,如果存在另一个项目集j,使得满足j∈I,且g(i)⊆g(j),则称j为i的一个包含因子,记为subsume(i)。例如:g(b)={1,2,4},g(a)={1,2,3,4},因为g(b)⊆g(a),故subsume(b)=a。
性质3假设项集x的包含因子subsume(x)={a1,a2,…,am},由x与其包含因子合并生成的2m-1个非空子集的支持数均为x.count。
例如:subsume(b)=a,那么无需进行进一步计算即可得知:b.count=ab.count=3。
定理1[10]假设a,b,c∈I1,如果a∈subsume(b),且b∈subsume(c),则有a∈subsume(c)。
证明:由于a∈subsume(b),b∈subsume(c),根据定义6可知g(b)⊆g(a),g(c)⊆g(b)。必然有g(c)⊆g(a)。因此得出a∈subsume(c)。
包含因子生成算法Gen_subsume()描述如下:
Gen_subsume(I1)
1:for i=1 to |I1|
2: for j=i-1 to 0
3: if j∈i1[i].subsume continue
4: if checkSubsume(I1[i].NL,i1[j].NL)==true
5: 添加I1[j].item和其索引j到I1[i].subsume中
6: 将I1[j].subsume元素添加到I1[i].subsume中
//根据定理2
checkSubsume(NL(a),NL(b))
//根据定理1
1: while j<|a| && i<|b| do
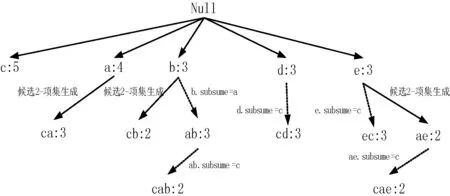
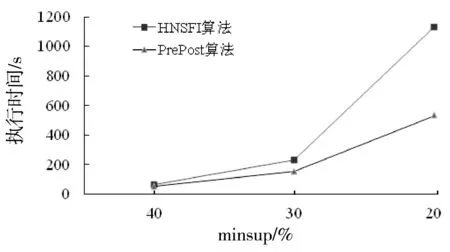
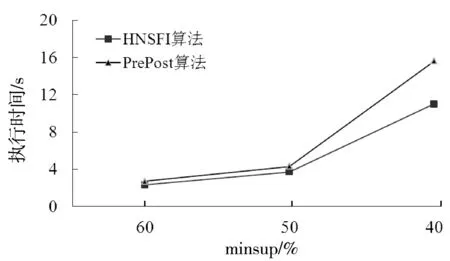
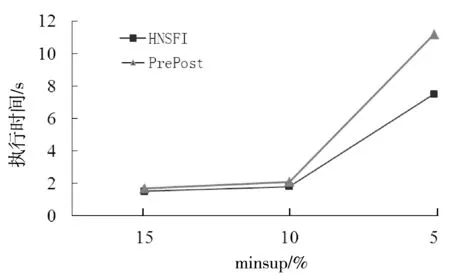
2:if b[i].preorder b[i].postorder>a[j].postorder then j++ 3: else i++ 4:if j==|a| return true 5:else return false 定理2假设a为频繁1-项集I1,如果∀ppi∈NL(a), ppj∈NL(b),都有ppj∝ppi, 则有b∈ subsume(a)。 证明:由于ppj∝ppi,说明所有包含a的事务项也都包含b,可知g(b)⊆g(a),因此得出b∈subsume(a) 例如:NL(c)={<(3,10),5>}, NL(d)={<(6,2),1>,<(9,9),2>},根据定理1,满足{<(3,10),5>}结点为{<(6,2),1>, <(9,9),2>}结点的前驱结点,则有c∈subsume(d)。 文献[7-8]提出NList交集运算的方法,算法NL_intersection ()描述如下: Function NL_intersection(NL1,NL2) 1:NL3=∅ i=0,j=0 2:while i<|NL1| and j<|NL2| 3:if NL1[i].preorder 4: if NL1[i].postorder 5: NL3.add(NL1[i].preorder, NL1[i].postorder, NL2[j].count) 6: else j++ 7: else i++ 8:return NL3 基于哈希存储的N-List与包含因子的频繁模式挖掘算法包括以下5个步骤: (1) 建立PPC树;扫描PPC树生成频繁1-项集对应的N-List。 (2) 计算频繁1-项集对应的包含因子;调用包含因子生成算法Gen_subsume()搜索频繁1-项集对应的包含因子。 (3) 将频繁1-项集对应的包含因子直接合并生成频繁2-项集插入结果中,其支持数与频繁1-项集相同。 (4) 合并生成候选2-项集。使用X与不属于其包含因子的其他频繁1-项集合并生成候选2-项集,选择满足最小支持度条件的插入结果中。 (5) 针对每个频繁2-项集计算包含因子,将X与其包含因子根据性质3合并能生成2m-1个项集直接插入结果中。然后再生成候选3-项集,选择选择满足最小支持度条件的插入结果中。 (6) 重复步骤4和步骤5,生成频繁t-项集。直到不再有新的候选t+1频繁模式生成算法结束。 HNSFI算法描述如下: HNSFI (DB) 1:call function create-ppc-tree() 2:create frequent 1-pattern N-List of I1 3:call Gen_subsume(),find the subsume of each item in I1 4: insert frequent-1-pattern and combined with 2m-1 subset from subsume into Lattice 5: for(i=1;Lj-1≠∅;j++) 6:CIj← gen_candidate(Lj-1) 7: for c∈CIj,C is generated by p1 and p2 8: C.NL←NL-interseaction(p1.NL,p2.NL); 9: if c.count≥ minsup*n 10: insert c into Lattice 11: if c.subsume≠∅ 12:insert each subset from c.subsume into lattice Function gen_candidate (Lj-1) 1: CIj=∅ 2: for each Cu∈Lj-1 3: for each Cv∈Lj-1(Cu≠Cv) 4: if(Cv[1]∉Cu.subsume )and (Cv[1] ≠Cu[1]&& Cv[2] ≠Cu[2]&&…&& Cv[j-1] ≠Cu[j-1]) 5: then C← Cu[1] Cv[1] …Cu[j-1]Cv[j-1] 6: C.subsume.add(Cu.subsume) 7: if each (j-1)-subset of C belongs to Lj-1then 8: CIj←CIj∪{C} 9:return CIj 以表1数据为例,minsup=30%,图1为其对应的PPC树,扫描PPC树生成频繁1-项集N-list,并按照2.1节所示存储方法进行Hash存储结果如图2所示,因为1-项集{f}不满足minsup,故不存储该结点。将搜索完成的频繁1-项集{c}、{a}、{b}、{d}、{e}按照支持数从大到小插入如图3所示结果的第一层中,调用算法Gen_subsume()搜索频繁1-项集所对应的包含因子如表4所示。 表4 频繁1-项集对应的包含因子 由性质3可知结点{ba,dc,ec}可无需计算直接插入结果第二层结点中,由包含因子直接生成的结点插入结果使用虚线表示。然后由1-项集结点与不属于包含因子的其他频繁1-项集通过N-List链接生成候选2-项集为{ac,bc,da,db,ea,eb,ed},链接过程如图4所示。链接过程中由于使用的哈希存储能够缩减候选项集的生成时间,其中满足minsup的频繁2-项集为{ca,cb,ae},将此3个结点插入结果中,使用实线表示。 图4 N-List链接生成候选2-项集 接下来调用算法Gen_subsume()计算2-项集的包含因子,bc.subsume=a,ea.subsume=c, 由性质3直接生成结点{cab,cae}插入结果中,寻找3-项集的候选项集,发现无候选3-项集生成,算法结束。算法最终的执行结果如图5所示。由图5可得出本文HNSFI算法无需存储与计算N-list中的结点{ab,cd,ec,cab,cae},这些结点均使用包含因子直接生成从而大大减少了算法的运行时间。 图5 HNSFI算法挖掘结果的生成过程 本文提出的HNSFI算法通过使用二级哈希表存储N-list头结点,引入素数序列为项集设置键值不易发生冲突,尽管由此带来了一些空间上的代价,但取出任意N-List头结点的时间复杂度为O(1)。文献[9]提出了改进的N-list交集运算,对于任意的两个N-List链,交集运算的时间复杂度已由O(m×n)下降到O(m+n),其中m、n为两条N-List链的长度。而本文提出的HNSFI算法使用了文献[6]提出的包含因子概念,该算法无需遍历N-List中所有的头结点,在某些情况下可通过包含因子直接生成频繁项集。 为了进一步验证算法的时间性能,我们主要比较本文HNSFI算法与文献[3]所提到的PrePost算法之间在运行时间上的性能差异。测试的硬件平台为:Intel Core i7-4510 CPU 2 GHz、16 GB 内存。两个算法均采用Java编程语言实现,实验数据使用从 http://fimi.ua.ac.be/ data/下载上获得的Chess、Retail和mushroom3个数据集进行频繁项集挖掘实验,其中chess数据库共有75个不同的项,3 196个事务,Retail数据库共有16 470个不同的项,88 162个事务。Mushroom数据库共有119个不同的项,8 124个事务。运行时间的实验结果如图6-图8所示。 图6 retail数据库两种算法执行时间对比 图7 chess数据库的两种算法执行时间对比 图8 mushroom数据库的两种算法执行时间对比 由图6所示的对比结果可以发现,本文提出的HNSFI算法针对于类似Retail数据库这种拥有较少频繁项目集的稀疏数据库,时间耗费大于PrePost算法,因为本文引入的查找包含因子需要计算时间,而对于有较少项集的稀疏数据库来说通过包含因子直接生成项集节省的时间小于计算包含因子的时间。而针对chess与mushroom这两个数据库,由于哈希表使用以及包含因子的计算可以减少频繁项集挖掘时间,如图7-图8所示,针对于稠密数据库,包含因子直接生成的频繁项集能够大大节省时间使得因子计算的时间可以忽略不计。通过实验可以得知本文提出的HNSFI算法对于稠密数据库,算法执行具有一定的稳定性,随着minsup不断降低,本文HNSFI算法有明显的优势。 本文提出了一种高效地利用N-List生成频繁项集的方法。与文献[9-12]提出的众多PrePost改进方法方法不同,HNSFI算法特点为:1)使用了哈希表存储N-List结构,从而进一步加快了通过N-List相交生成频繁项集的速度。2)通过引入包含因子以及其相关性质可以在某些情况下省去对N-List的链接操作直接生成频繁项目集。HNSFI算法尽管在稀疏数据库中的性能比不上PrePost,但针对与稠密数据库的时间性能具有优势。 在今后的研究工作中可以考虑将本文算法推广到挖掘频繁闭项集[14]或加权频繁项集[15]中,可以为每个项目引入带有某种含义的权值,使算法挖掘的结果更具参考价值。此外还可以借助分布式计算的思想,研究并行处理条件下频繁项集增量挖掘[16],从而提高频繁项集挖掘的工作效率扩宽应用范围。3.2 N-List交集运算
4 频繁项集挖掘算法HNSFI
4.1 HNSFI算法步骤描述
4.2 HNSFI实例分析

5 实验结果
5.1 定性分析
5.2 定量分析
6 结 语
