基于规则的动物卫生事件舆情信息抽取研究
2018-09-26丁晟春刘梦露
丁晟春 王 莉 刘梦露
(南京理工大学经济管理学院 江苏 南京 210094)
0 引 言
近年来,随着经济全球化的发展,动物及其产品流通频繁,疫病传播机会大大增加,加之环境严重污染,使动物疫病更加复杂,呈现危害加重、种类增加、混合感染等特点,给防制工作带来了新的挑战和困难。除了动物养殖人员对动物健康持有高强度的关注外,禽类、鱼、牛、羊等多种动物直接或间接的进入大众餐盘,这也使得每一个民众时时刻刻都关注着动物健康。在网络媒体时代,动物卫生事件一旦发生,很容易被推到风口浪尖上。如果不对动物卫生舆情加以有效管理和良性引导,轻则引起企业和行业巨大损失,重则发展为公共安全事件,引起群体恐慌,谣言的散布会危害社会的安定秩序,甚至会引发群体性事件。在海量信息面前很难通过直接浏览的方式获取信息,因此如何高效准确地从动物卫生舆情信息中抽取出卫生事件的主体信息成为研究的要点。本文以动物卫生事件新闻信息为研究对象,使用基于规则的抽取方法实现时间、地点、疫病名称、动物数量、应对措施等内容的抽取。
当前事故信息抽取研究中的不足主要有:(1) 为了能够达到较高的语言覆盖度,现有研究会构建大量抽取规则而且抽取关键字大都直接写入抽取规则,这使得抽取规则的后续查阅和维护变得困难;(2) 对于涉及多个事故信息或包含多个同一属性项值的文本,现有的基于规则抽取方法仅能抽取到属性值,无法准确区分抽取到的值哪个是最终有效信息,导致抽取效果差。
为了改善以上缺点,本文总结待抽取属性项的描述规律以及出现位置和方向,构建触发词表,使用各类触发词的词性标注设计抽取规则,提高抽取规则的使用和维护效率。提出基于节点比较的方法有效区分文本中出现的多个动物数量属性项,提高了抽取效果。
1 相关工作
在网络信息量呈指数级增长的环境下,如何从大量的信息中及时并准确地抽取、 过滤、归类形成便于用户使用的信息变得尤为重要。而信息抽取就是从一个文本中抽取指定信息并将其结构化的存入数据库中供用户查询使用的过程[1]。目前常用的信息抽取方法有:基于统计的信息抽取方法[2-3]和基于规则的信息抽取方法[4-5]。基于统计的信息抽取是一种基于概率性的非确定性的信息抽取方法。该方法首先需要构造一个模型模拟信息抽取过程,应用统计学方法从训练语料中得到模型的参数,然后利用训练好的模型进行信息抽取[6]。但是,统计模型通常借助于独立性假设使模型只能处理结构关系依赖性不强的对象。基于规则的信息抽取技术是相对应用比较广和比较成熟的一种抽取技术。霍娜等[7]以火山爆发、泥石流、客轮沉没三种灾难性追踪事件作为研究对象,分析相关事件报道之间的连续性、多角度性等文本特点,构建了54条抽取规则对灾难性追踪事件文本抽取。丁学军等[8]通过大量领域内文献的阅读、分析和归纳构建属性描述的规则,对《情报学报》2007年和2008年的文章里的学术概念进行抽取。蒋德良[9]把突发事件的结果总共分为20类,并为自然灾害事件、人为事件及疾病爆发事件三大类事件共建立了284条抽取规则,实现突发事件结果信息的抽取。余晨等[10]对长江海事局网站险情报告版块中描述海事险情概况的文本进行分析,人工编制规则实现对海事文本中时间、地点、船名和事故类型四个属性项的抽取。
本文的研究对象为新闻数据,由于各网站对动物卫生事件新闻报道的描写风格相对一致,且书写手法发生变化的可能性小,所以本文将总结待抽取实体描述的规律(如在新闻文本的表达方式及位置等),人工构建抽取规则,实现对动物卫生事件舆情信息的抽取。
2 动物卫生事件舆情信息的抽取
本文处理的动物卫生事件新闻数据主要来自我国政府官方网站和人民网、新华网、中国新闻网等新闻网站,从中抽取出动物卫生事件的报道时间、发生地点、引发卫生事件的疫病、卫生事件中涉及的动物数量(染疫、死亡、扑杀)以及为应对该卫生事件采取的措施。
2.1 信息抽取流程
本文的信息抽取主要包括词库构建、文本预处理和信息抽取三个模块,信息抽取流程如图1所示。

图1 信息抽取流程
(1) 词库构建模块:为了提高分词效果和规则制定需要构建动物疫病词典和信息抽取触发词表。动物疫病词典的主要来源为2016年世界动物卫生组织OIE(Office International Des Epizooties)公布的动物疫病名录,我国农业部2008年修订的《一、二、三类动物疫病病种名录》以及中国动物卫生与流行病学中心较为关注的疫病。
(2) 文本预处理模块:文本预处理模块主要包括分句、分词和词性标注。本模块使用动物卫生事件新闻的标题和正文作为实验语料,将标题拼接到正文前形成一整段文本。首先对待抽取语料以“,”、“。”、“!”、“;”、“?”等符号进行分句,再对分句后的文本使用中科院ICTCLAS分词工具进行分词并标注词性。
(3) 信息抽取模块:本模块将通过对待抽取语料的分析,基于触发词表制定抽取规则,并使用正则表达式描述抽取规则建立规则库,最后进行动物卫生事件新闻的信息抽取实验。
2.2 触发词表的构建
信息抽取规则是说明目标信息的约束条件,抽取规则主要有触发词、特征词、开始位置、结束条件等几项构成。触发词是指对某一属性的抽取起着识别、标志作用,可以触发抽取任务的词语。以往研究表明触发词一般是动词或名词,所以对其他词性的词语不予考虑[11]。通过对待抽取语料的文本特征和新闻描述习惯进行分析,构建待抽取属性项的触发词表。
(1) 时间触发词 网络新闻通常会包含新闻发表时间和报道时间,发表时间是指新闻网站刊登新闻时系统自动生成的时间,报道时间是指新闻内容向读者报道的时间。在网络中,同一件新闻事件会有多个新闻网站对其进行报道或转载,而不同网站新闻的发表时间是不同的,并且在数据抓取时不能保证抓取到的新闻为该事件的首条报道,所以新闻的发表时间不能准确地表示舆情信息的出现时间。由此,本文将抽取新闻的报道时间作为舆情信息的出现时间。报道时间作为新闻报道的六大元素之一,一般出现在新闻正文首句,包括年、月、日,不会精确到小时,如:“中新网11月17日电”、“农民日报12月6日讯”。根据对待抽取语料统计得出时间触发词有:“电”、“讯”、“报道”、“消息”、“发布”等。
(2) 疫病名称触发词 疫病名称作为动物卫生事件报道的核心,基本上会直接出现在动物卫生事件新闻的标题中,如:“香港活禽检出H7N9病毒,扑杀约两万只家禽”、“立陶宛野生猪染非洲猪瘟”。如果标题中未出现疫病名称,新闻正文的前两句都会对引发动物卫生事件的疫病进行描述。疫病名称触发词有:“检出”、“出现”、“发现”、“暴发”等。
(3) 动物数量触发词 动物卫生事件中涉及的动物数量可以用来判断事件的暴发程度,因此准确地获取事件动物数量十分重要。动物卫生事件动物数量主要包括染疫(疑似染疫)动物数量、死亡动物数量和扑杀动物数量三类。在医学上“染疫”和“发病”是两种概念,染疫是发病的必要条件,所以染疫动物数量包含发病动物数量,本文将发病动物数量纳入到染疫动物数量进行抽取。对应上述三类动物数量将动物数量触发词分为三类。染疫(疑似染疫)动物数量触发词主要有:“感染”、“发病”、“染病”等;死亡数量触发词有:“死亡”、“暴毙”等;扑杀动物数量触发词有:“扑杀”、“捕杀”、“宰杀”、“销毁”等。
(4) 应对措施触发词 动物卫生事件是否采取应对措施对该事件的危及程度有重要的影响,而且采取怎样的应对措施可以在后续事件处理起到借鉴作用。但是,只有少部分新闻会具体描述动物卫生事件的应对措施,而大部分新闻通常是大而空的描述采取应对措施,例如:“疫情发生后,当地按照有关预案和防治技术规范要求,坚持依法防控、科学防控,切实做好疫情处置工作”。大而范的应对措施对后续事件处理的借鉴意义不大,因此本文从控制传染源、切断传播途径、保护易感群体三个方面抽取具体的应对措施。通过对动物卫生事件常用的应对措施进行总结和对已有的新闻报道进行分析得到应对措施专用词语,如:“扑杀”、“宰杀”、“灭杀”、“消毒”、“隔离”、“无害化处理”等,将应对措施专用词作为该类的触发词使用。在扑杀动物数量触发词中有部分与应对措施触发词相同,将这部分词语以共用触发词进行标注。
根据信息抽取流程在触发词表构建之后需进行待抽取文本的预处理。本文将动物疫病词典和触发词表中的词语加入到ICTCLAS分词工具进行文本的分词和词性标注,自定义词性标注见表1。

表1 自定义词性标注
2.3 抽取规则表示
为了得知各待抽取项在本文的位置和触发词的触动方向,本文选取了300条动物卫生事件新闻进行待抽取项在文本语料的位置和触发词前后的位置进行统计分析。地点和应对措施待抽取属性项是通过触发词词性标注进行抽取的,所以只对时间、疫病名称和动物数量三个待抽取属性项的文本位置和触发词位置进行统计分析。统计结果如表2所示。
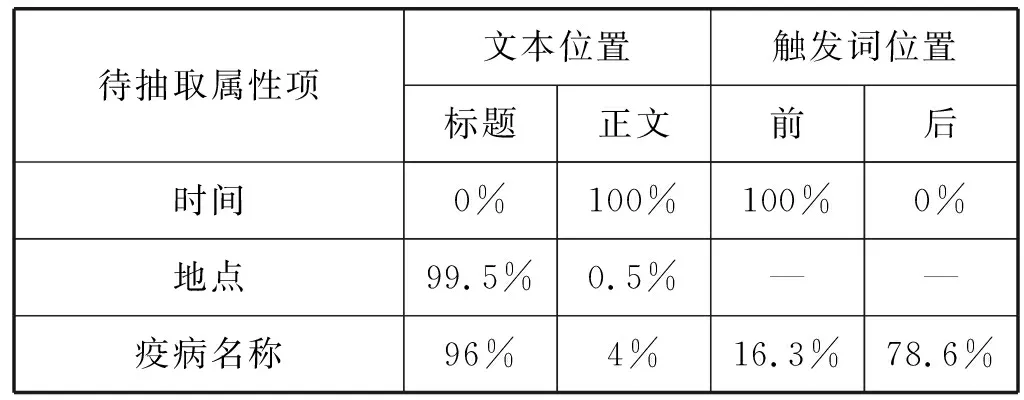
表2 抽取位置及方向统计分析结果

续表2
由表2中的待抽取属性项文本位置的统计结果可以看出,地点和疫病名称待抽取项可以直接从新闻标题中获得。因此,本文将新闻标题作为首句文本加入到正文中进行信息抽取。对触发词位置的统计结果可知,时间待抽取属性项为前向触发,疫病名称和动物数量待抽取属性项触发词为双向触发,根据位置前后概率可以确定其先行触发方向。
触发词主要是用来识别待抽取项的大概位置,可以通过使用正则表达式来匹配该属性项。根据对动物卫生事件新闻本文特征的分析,各待抽取属性项的抽取规则具体如下:
(1) 时间 根据对新闻文本特征的分析发现,时间属性项通常出现在正文首句,所以,对待抽取文本的第二句使用规则Regex1根据触发词向前查找标注为/t的词。
Regex1:([0-9u4e00-u9fa5]*/t)+(?=((?!/t).)*/date)
(2) 地点 根据表2看出地点待抽取属性项可以直接从新闻标题中获得,因此在第一句文本中使用规则Regex2查找标注为/ns或/nsf的词。
Regex2:([0-9u4e00-u9fa5]+/ns[a-z]*)+
(3) 疫病名称 疫病名称属性项将从新闻标题和正文首句中进行抽取。首先使用规则Regex3根据触发词向后查找标注为/disease的词,如果没有找到则使用规则Regex4据触发词向前查找标注为/disease的词,如果不存在触发词则使用规则Regex5查找标注为/disease的词。具体规则见表3。
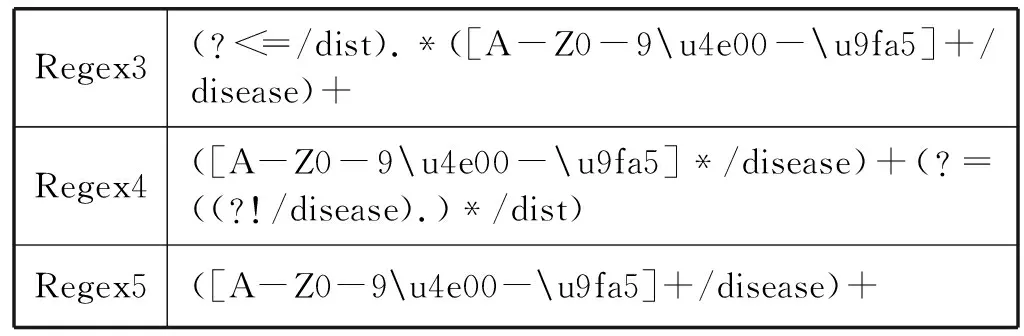
表3 疫病名称属性项抽取规则
(4) 动物数量 对于染疫(疑似染疫)动物数量,首先使用Regex6根据触发词向前查找与量词(标注为/q)相连标注为/m的词。如果没有找到则使用规则Regex7向后查找与量词(标注为/q)相连标注为/m的词。死亡动物数量和扑杀动物数量的抽取方式与染疫(疑似染疫)动物数量相同。具体规则见表4。
(5) 应对措施 从第一句文本开始,使用规则Regex12查找标注为/measure或/q_m的词语。
Regex12:[u4e00-u9fa5]+(?=/measure|/q_m)
2.4 实验结果分析
本文从新华网、环球网、中国新闻网等网站抓取了2017年1月至2017年6月期间共计800条动物卫生事件新闻数据。经过分词、分句、词性标注等文本预处理之后进行抽取实验。实验结果使用准确率(P)、召回率(R)及F1值进行测评,得到的测评结果如表5所示。
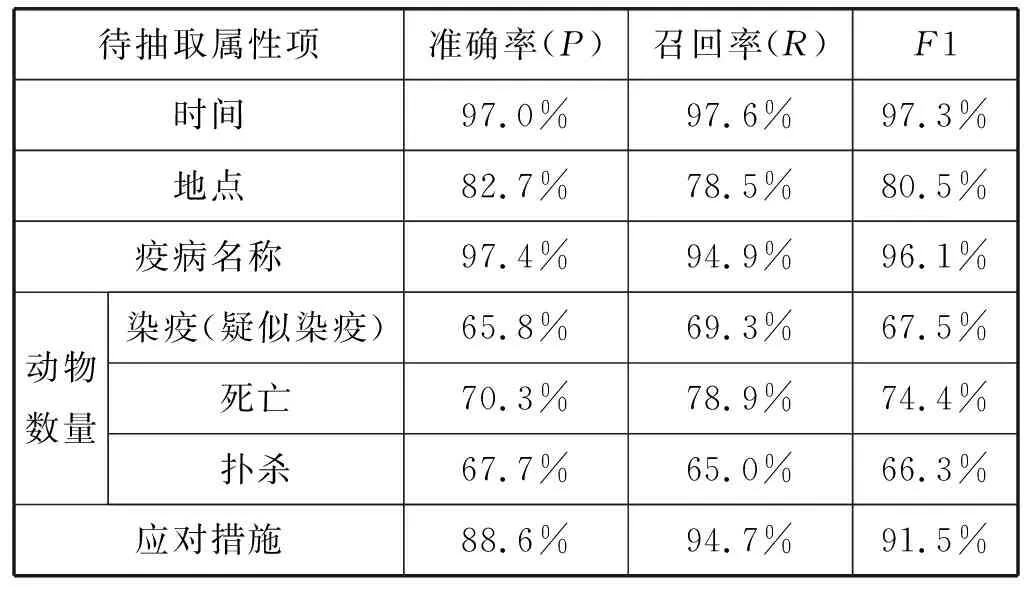
表5 动物卫生事件舆情信息抽取实验结果
从表5中可以看出:
(1) 时间属性项抽取的召回率和准确率最高,这是因为不同新闻网站对对新闻报道时间的表达方式高度统一。
(2) 地点作为新闻六大要素之一,而且动物卫生事件新闻的标题都会对地点进行描述。本文地点属性项的抽取仅依靠词性标注进行,导致地点抽取结果对ICTCLAS分词工具地名识别的准确度存在较大的依赖。例如:新闻中出现的国家名称简写“澳”和地名“圣海伦娜”ICTCLAS不能正确进行标注,还有少数国内的市、区、县和国外的州不能准确的标注,导致准确率低。如果将地点粒度变粗(国内精确到省,国外精确到国家),地点属性项的准确率可以达到92.4%,召回率达到87.7%。
(3) 疫病名称也是动物卫生事件新闻一定会描述的内容,其准确率达到97.4%,召回率达到94.9%。疫病名称属性项根据触发词对本文提供的动物疫病词典中的疫病名称进行抽取,由此可知,疫病名称的准确率和召回率与动物疫病词典中的疫病名称完备性有较大关联。后续研究中可以加入动物疫病知识本体以提高抽取效果。
(4) 根据本文动物数量的三类抽取规则对属性项进行抽取,抽取结果较其他属性项的效果差距较大。三种动物数量抽取结果的准确率和召回率普遍偏低,主要存在以下几种错误情况:
① 在抽取过程中,本文抽取实验中默认返回抽取到的第一个匹配项。有些新闻会在标题或者正文前部分先描写一个粗略的动物数量,再在下文中描写详细数据,还有部分新闻会在一个报道中对两个动物卫生事件进行描述。所以,在包含多个动物数量值的情况下根据抽取机制不能获取到准确结果。
② 本文制定的动物数量抽取规则是根据触发词和量词词性标注来定位抽取项,并未对具体量词进行定义,造成了大量错误。
③ 本文设定在死亡和扑杀动物数量触发词在抽取中有不错的适用性,但在对染疫动物数量抽取时新闻文本中出现了多种侧面描述方式,如:“表现出……症状”、“检测呈阳性”、“检测出……病毒”等,抽取触发词的不完善导致染疫动物数量抽取的效果差。
由以上分析可知,动物数量的抽取规则存在很多漏洞,需对其进行改进以改善其准确率和召回率。
(5) 动物卫生事件新闻对应对措施的描述方式差异大,而且大部分新闻对动物卫生事件应对措施的描述比较空泛。本文选取了应对动物卫生事件常用的具体措施作为触发词直接根据词性进行抽取。根据词性直接从文本中进行抽取可以做到抽取的高召回率,但是对其准确率的高低有影响。例如:文本“马拉维已经采取隔离检疫措施,尚未对受影响的动物接种疫苗”,根据抽取规则会将“隔离”、“接种疫苗”抽取出来,但是接种疫苗是尚未执行的措施不应该抽取出来。还有部分新闻在描述完当前时间会对过去事件进行描述,而根据抽取规则会将去年事件的应对措施抽取出来。后续研究需要对应对措施的抽取内容和抽取方式进行更详细的探讨。
3 动物数量属性项抽取的改进
3.1 基于节点关系比较的抽取方法
根据2.4节中对动物数量属性项抽取结果的分析可知,量词定义和染疫动物数量触发词不准确的问题可以通过表6中的抽取规则解决。但是,抽取效果差的核心问题在于抽取实验默认返回第一个匹配结果。如果抽取实验不再默认返回第一个匹配结果,而是返回新闻文本中根据规则可以匹配到的结果,那么如何判断和处理所有返回结果的关系就成为了改善动物数量属性项抽取的关键。

表6 修改及新增的抽取规则
本文提出基于节点关系比较的方法对动物数量属性项的抽取效果进行改进。将动物数量抽取所返回的结果记录在动物数量节点中,并为动物数量节点设置属性,通过各动物数量节点的属性值来判断节点之间的关系。动物数量节点包含的属性有:时间、地点、疫病、动物种类、结果精度。其中:时间表示该动物数量的动物染疫、死亡或被扑杀的时间;地点表示该动物数量所对应动物卫生事件发生的地点;疫病名称表示该动物数量的动物染疫、死亡或被扑杀的病因;动物种类表示该动物数量所对应的动物种类;结果精度表示抽取结果是精确值还是模糊值,用T和F表示。依据对动物数量属性项所在文本的位置分析,使用抽取规则从动物数量节点值前方文本中匹配获取动物数量节点的时间、地点和疫病属性值,选取距离动物数量节点值最近的名词作为动物数量节点的动物种类属性值,而结果精度属性值则通过判断动物数量节点值是否包含“多”、“余”等词语来确定。
为了简化判断各动物数量节点间的关系,本文设置一个参考节点。参考节点是用来表示该新闻报道的动物卫生事件的相关信息。参考节点本身没有值,其包含时间、地点、疫病三个属性。因为参考节点作为筛选动物数量节点的基础参照,所以参考节点的属性值为新闻描述的动物卫生事件的最粗粒度数据值。即选取新闻报道的时间作为参考节点的时间,地点则选取动物卫生事件发生的国家或省份,不细化到州或区县,疫病即引发动物卫生事件的疫病。
动物数量属性项的值需要经过参考节点与动物数量节点和动物数量节点间的两次关系判断才能最终确定。参考节点与动物数量节点之间的关系分为相关关系和无关关系两种;动物数量节点之间的关系包括:相等关系、包含关系和并列关系。动物数量属性项值确定流程如下:
输入:参考节点,动物数量节点集合。
输出:动物数量属性项值。
Step1进行参考节点与动物数量节点集合中每个节点的关系判断,与参考节点呈相关关系的动物数量节点进入Step2,删除与参考节点呈无关关系的动物数量节点;
Step2如果仅有一个动物数量节点则以该节点值作为动物数量属性项的值,进入Step5,如果存在多个动物数量节点则判断各动物数量节点间的关系,进入Step3;
Step3将动物数量节点以树形结构排列,进入Step4;
Step4选择树形结构顶层的节点,根据节点值及其精度判断最终结果,进入Step5;
Step5输出动物数量属性项值。
3.2 节点关系判断
参考节点与动物数量节点之间的关系分为相关关系和无关关系。相关关系是指动物数量节点值所描述的是当前新闻报道的动物卫生事件中涉及的动物数量;无关关系是指动物数量节点值描述的不是当前新闻报道的动物卫生事件,一般为过往类似动物卫生事件中涉及的动物数量。
设参考节点R{t1,add1,disease1},动物数量节点N{t2,add2,disease2,animal},R和N的关系判断方法为:
判定规则1若R和N满足t2∈[t1-1month,t1]、add2⊆add1、disease2=disease1,那么R和N两个节点为相关关系,否则为无关关系。
在判断完参考节点与动物数量节点之间的关系后,与参考节点呈相关关系的动物数量节点进行动物数量节点间的关系判断。动物数量节点之间的关系分为相等关系、包含关系和并列关系。由于进行动物数量节点间关系判断的节点都是与参考节点呈相关关系的节点,各动物数量节点疫病属性值是一致的,所以将从时间、地点、动物种类属性值对动物数量节点关系进行判断。相等关系表示两个节点描述的为动物卫生事件中的同一个数量值;包含关系表示两个动物数量节点值在时序或地点或动物种类上存在包含关系;并列关系表示两个动物数量节点值是对动物卫生事件在地点或动物种类上的细化描述。
设动物数量节点N1{t1,add1,disease1,animal1},N2{t2,add2,disease2,animal2},N1和N2间的关系判断方法如下:
判定规则2若N1和N2满足t1=t2、add1=add2、animal1=animal2,那么N1和N2为相等关系。
判定规则3若N1和N2满足t1≤t2、add1⊆add2、animal1⊆animal2,那么N2包含N1。
判定规则4若N1和N2满足add1≠add2或animal1≠animal2,那么N1和N2为并列关系。
在各动物数量节点关系判断之后,根据节点树形结构中顶层节点的个数和各节点的结果精度确定动物数量属性项的值,判定方法如下:
判定规则5如果顶层节点只有一个,则以该节点的值作为动物数量属性项的值。
判定规则6如果顶层节点有多个且这些节点呈相等关系,则选择结果精度属性为“T”的节点值作为动物数量属性项的值。
判定规则7如果顶层节点有多个且这些节点呈并列关系,则以这些节点值的和作为动物数量属性项的值。
3.3 基于节点关系比较方法抽取实验
使用表6中完善后的抽取规则和基于节点关系比较方法在2.4节的实验数据上重新进行动物数量属性项的抽取实验。基于2.4节中实验结果分析可知,动物数量节点属性值的抽取效果对分词工具、动物疫病词典和语法分析工具有较大依赖性,这可能会导致基于节点关系比较的动物数量抽取方法结果较之前的规则抽取结果更差。本文在此不再对节点属性值的抽取进行深入研究,所以为了减小节点属性值抽取结果对节点关系比较的影响,在自动抽取得到的参考节点和动物数量节点属性值进行人工审核。审核之后再进行节点关系判断,最终输出动物数量属性项的值。实验结果使用准确率(P)、召回率(R)及F1值进行测评。得到的测评结果如表7所示,与2.4节动物数量属性项抽取(改进前)结果对比如图2和图3所示。

表7 动物数量属性项抽取实验结果

图2 准确率对比图
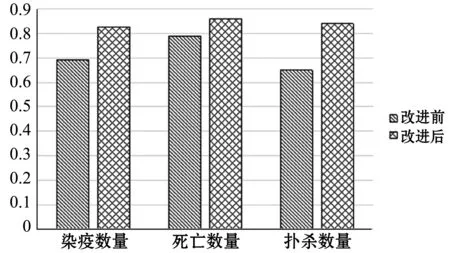
图3 召回率对比图
根据表7、图2、图3可以看出,基于节点比较的抽取方法提升了三种动物数量属性项的抽取效果。实验能取得较好的抽取效果有以下几个原因:
(1) 基于节点关系比较的抽取方法的抽取效果依赖于动物数量节点值的抽取效果。如果进入节点关系比较的动物数量节点是错误的,那么对节点间的关系比较会带来影响。表6对抽取规则进行补充并对抽取规则中的具体量词“只”、“头”、“例”进行定义,减少了因标注“/q”定位而获取的错误抽取结果个数,从而提高了动物数量节点值的抽取效果。
(2) 之前的抽取方法只能返回第一个抽取结果,无法判断新闻中多个动物数量值的关系。而动物数量节点和参考节点的关系比较排除了过往事件中的动物数量值,动物数量节点的关系比较可以很好地处理新闻中多个动物数量值的关系,提高了抽取结果的准确率和召回率。
4 结 语
本文总结了各待抽取属性项文本描述和分布规律,并使用正则表达式构建抽取规则实现了动物卫生事件舆情信息的抽取。本文还提出基于节点关系比较的方法对动物数量属性项的抽取进行改进。两次抽取实验可以证明本文提出的方法是可行的,且准确率较高。但是本文未对动物数量节点属性值的抽取方法进行改进,动物数量节点属性值抽取的错误结果影响了节点间关系的判断。下一步将对动物数量节点属性值的抽取方法进行研究,实现准确高效的自动抽取,减少人工工作量。
