短语的词典学意义及基于语料库的拉丁语短语提取研究*
2018-09-19李德俊杨晓冬
李德俊 杨晓冬
一、 引言
大多数情况下,人们查词典不外乎两个目的: 其一是查询生字词的意义,以便理解;其二是查询字词(未必是陌生的字词)的搭配以便使用。以上两点关涉词典的释义和配例,是词典编纂的核心内容。借助语料库,释义和配例都走出了内省的困境,在方法和手段上都发生了革命性的变化。语料库通过索引行显示使用中的语言素材,同时也提供了语境。但是,基于索引行的词典编写也有一些明显的缺陷,例如释读索引行仍然需要花费大量的时间,特别是当数据过大时,仔细阅读和分析索引行数据其实是不可行的,大量的有价值信息淹没在索引行中而得不到利用。研究表明,通过统计方法将索引行数据转化为包含关键词和搭配的短语级语料,在冗余的信息被过滤掉之后,有价值的信息得以凸显。短语驱动不仅与索引行驱动的效率相当,而且还可以节约大量的时间。短语驱动是语料驱动的最简方案。(李德俊 2016)40
二、 语料库语言学视野下的短语
广义上的短语指由两个及以上词语组成的语言单位。当代语言学对短语的兴趣一直很浓,因此也产生了若干类似的术语,例如搭配(collocation)、语块(chunk)、词簇(cluster)、多词单位(MWU, multi-word unit),等等。搭配一直是语料库语言学的重要研究领域,同时也是词典学的主要讨论对象之一。但有趣的是,在语言学界对什么是搭配并没有形成共识,下面的不同定义反映了人们对搭配的理解存在一定差异:
1. 搭配是符合语法的相邻词之间的语义兼容关系。(Hartman & James 2000)
2. 搭配是一些语言学家,特别是Firth学派的语言学家在词汇学领域使用的一个术语,它指词汇单位的习惯性共现。(Crystal 2008)
3. 两个或两个以上的词在文本中很短距离内的共现。(Sinclair 1991)
4. 搭配是具有统计意义的词汇共现。(Hunston 2006)
上述定义给我们呈现了搭配研究对象相对混乱的一面,搭配可以仅指固定结构,也可以包括所有具有共现关系的词语组合,而不论其组合是否具有独立的语义。Siepmann(2005)认为搭配不仅包含类联接(colligation),也包括短语。此时,搭配具有了无所不包的性质。
由于对搭配理解的差异较大,语料库语言学在开创短语研究的新领域时,放弃了搭配这个术语,使用了一个全新的词汇“phraseology”来表示短语,并将这个新的研究领域称为“短语学”。1998年,第一部全面论述短语学的著作《短语学: 理论、分析与应用》由牛津大学出版社出版。此后,短语学的研究在语料库语言学领域逐渐升温并逐渐成为核心研究内容之一。
目前,短语的定义已经基本趋于统一,它可以定义为: 短语是一个词汇单位和另一个或几个词汇单位的共现,该共现组合具有独立完整的语义功能(function as one semantic unit),其共现频率大于理论频率。(Gries 2008)6短语不仅是心理上的语义共现关系,更为重要的是构成短语的词语间共现频率大于理论频率。这个定义克服了对短语判断的纯主观性缺陷,是对短语进行统计识别的基础。
Gries的定义较为全面地概括了短语的特征,据此短语可以是两个词构成的词组,也可以是多个词组成的词簇。短语未必相邻,也可以是不相邻的结构模板形式(template),例如: x(number) hours drive from y(place)。短语可以是固定词组,也可以是某些自由词组。固定词组包括成语、谚语、歇后语、专门用语、惯用语等;自由词组指按照语法规则组成的临时结构,如“红花、绿叶子、词典的结构、英国大学”等。“词典的结构;英国大学”不是短语,因为构成这些词语串的语词间是偶然的共现关系,不具有统计学意义,它们是完全自由词组;与之不同的是,构成“红花、绿叶子”等词语串的语词具有相互吸引的倾向,共现频率也具有统计学意义,它们是半自由词组,是短语的一种形式。
短语学与语料库语言学具有良好的互动关系,2005年10月,来自世界各地的170位学者聚集比利时新鲁汶(Louvain-la-Neuve)就短语学的研究展开研讨。会议肯定了语料库语言学对短语学的贡献,会后出版的3本著作有力推动了短语学研究在世界各地的发展。
正如Granger & Meunier(2008)所言的那样,今天,短语学正日益成为众多学科领域的研究中心,不管是传统的语言教学,还是前沿的自然语言处理领域都是短语学的舞台。词典作为指导人们对语言进行解码或使用语言进行编码的工具书,短语的价值何在也需要认真思考。
三、 短语的词典学意义
在语料库语言学、二语习得、自然语言处理等领域,短语的价值受到了普遍的关注,但是在词典学领域,只有少数学者注意到了短语及短语学的价值。(徐海 2013;李德俊 2014)除了传统的熟语、固定搭配等之外,非典型的短语并没有得到重视。例如汉语里的“谨慎乐观”“互利共赢”“小心台阶”等非典型短语,在翻译成英语时很可能会给译者带来挑战,“谨慎”有careful, prudent, cautious等译法,它们是不是都可以和“乐观”的英文optimistic组成地道的英语表达?这是编码词典需要思考的问题。对于解码词典来说,短语的价值也是不言而喻的,例如英语里的confidence man也是非典型的短语,其词义并不能从字面推出,词典如果不收录,就会降低词典的交际价值。以下从语言交际和词典研编两个方面来具体谈谈短语的词典学意义。
(一) 短语在言语交际中的意义
1.基本表义单位
如果对表义单位进行排列,从小到大的顺序是义素、词、短语、小句、语篇。那么哪个该是表义的基本单位?这里说的表义基本单位指的是使用语言组织思想时我们的语言官能习惯使用的语言单位。基本表义单位需要具有模块化、使用频率高和无歧义等基本特征。很显然,只有词和短语才是基本表义单位的选项。词是可以独立使用的最小意义单位,但是在表义的时候,词有一个天然的缺陷,很多词的意思通常都是不明确的,例如汉语的“打”,英语的“foot”。除了词义相对比较固定的技术类词汇之外,多数词汇,我们不仅不能明确它们的意思,有时甚至连词性都无法确定。
短语是比词高一级的表义单位。Firth(1957)说的“由词之伴而知其义”充分肯定了短语在词义显化中的重要作用。Sinclair也一再强调词汇不是孤立的,它们相互作用、搭配是词义形成的关键。(Moon 2008)短语还原的是“使用中语言”的最小语境,词义在该语境中得以显化。研究表明,词汇的两种最重要意义,概念义和情感义,大多可以通过该词语所处的短语语境而得以明晰。(李德俊 2016)34-35
Sinclair(2004)36-37的习语原则(idiom or phraseological principle)认为语言使用者在理解和造句时遵循的是一套短语规则。有大量的半加工、预处理过的短语如同成品的建筑构件被储存在使用者的头脑中,它们在语言的编码和解码中发挥着比词更为重要的作用。我们使用语言很大程度上就是对短语的调用。
通过对语料的统计,研究者发现短语在语言的编码和解码中所占比例远远超过词的比例,语料库语言学家Altenberg(1991)对LLC(London-Lund Corpus)语料库的抽样研究表明在总形符中(token),短语所占的比例高达70%。
因为短语同时具有模块化、使用频率高和无歧义3个特征,我们认为短语是基本的表义单位。它在言语交际中发挥主要的作用。
2.词汇和结构共选
对意义的形成起作用的不仅是词汇,结构也是重要因素。对结构义的关注可以追溯到Fries(1952),在《英语结构》(StructureofEnglish)中,他区分了词汇义和结构义两种意义,并指出习得语言就是习得由词汇组成的结构。Harris(1982)认为形和义(或者说语法结构和语义)是不可分割的,他的理论“算符语法”(Operator Grammar)通过形式推演证明了自然语言是个“自组织系统”(self-organizing system),在这个系统中,词汇的结构和语义属性通过与其他词汇的联系而得到明确。Harris(1991)还认为,我们对结构的习得是通过语言接触来完成的。
对“结构”和“句型”的研究催生了若干语言理论,例如“构式语法”(Construction Grammar)、“型式语法”(Pattern Grammar)和“短语学”(Phraseology)。构式体现的是形和义的配对,它是语言社团习惯使用的,并固化在头脑中的具有符号象征特性的语言单位(symbolic units of language)。构式将形态、词汇和句法形式与语义、语用和语篇功能相连接。(Goldberg 1995, 2006)型式语法由Hunston等人倡导,基于在COBUILD语料库建库和研究时所接触的大量语言实例和积累的丰富经验,他们发现每个词都有属于自己的型式,在此型式下,该词汇使用的典型语境得以复现。(Hunston & Francis 2000)短语学由语料库语言学家提出,它是语料库语言学所研究的主要内容之一,它不仅强调短语的可计算性,而且更加重视词汇和结构、型式与意义的共选(coselection)。当我们选择短语从事言语实践时,同时就选择了词汇、语法和语用关系。(Partingtonetal. 2013)正是由于短语集词汇和语法结构于一身的特征,短语才具有了消除歧义、语义自足的优点。从简单搭配foot the bill,到成语take a French leave,再到由固定词汇和自由选项组成的“模板”(template)“{see} + [out of/from] the corner of [possessive] eye”(Sinclair 2004)171,短语都体现了词汇和结构共选、型式与意义共选的特征。因此,学会一个短语就同时掌握了该短语的语义,以及它所包含的词汇搭配关系和语法结构。短语融词法和语法于一身。
(二) 短语在词典研编中的意义
正因为短语在言语交际中的重要作用,所以对于指导言语交际的词典来说,短语的价值是不言而喻的。
首先,短语是词典交际力的主要体现。词典是语内或跨语交际的工具书,由于单个词语的交际功能弱,不能体现“使用中语言”的特征。特别是对于积极型双语词典来说,对词语的单纯释义并不能对语言的编码具有可靠的指导作用。以前文的“打”为例,暂且不考虑一词多义,在“用手或器具撞击物体”的意义之下,“打”的英文释义为“strike; hit; knock; smash”。(《新时代汉英词典》)如果不提供短语作为例证,单凭这些释义词很难为诸如“打翻;打更;打鼓;打屁股”等短语的翻译提供帮助。对于双语词典来说,短语收录的多寡与词典编码交际力休戚相关。再看一个词典指导语言解码的例子。《柯林斯COBUILD高级英汉双解词典》(2009)对英文单词call用了4个版块来处理,前3个为call的义项大类,最后列出的是短语动词。该词典共列出与call相关的短语10多个,有些短语的意义很难从字面推理得出,例如call off。短语收录的质量不仅影响词典的编码能力,也与词典解码交际力成正相关。对于意义不能自明的短语来说,如果漏收录,将会对词典交际力产生很大影响。例如:
Meanwhile the defence ministry, which calls the shots on such vital questions as procurement and promotions, is staffed with career bureaucrats and political appointees.
在这句话中,对理解起关键作用的是短语“call the shots”,只有知道其义为“做决断、做主”,才能理解这个英文句子的意思。《柯林斯COBUILD高级英汉双解词典》并没有列出这个短语,不能不说是一种遗憾。
作为基本表义单位,短语也是基本的认知单位;在跨语交际时,它又是基本的翻译单位。因此,不论是对于服务于母语学习者的普通语文词典,还是学习词典或者翻译词典,短语的收录与词典的交际力都息息相关。
其次,短语是语料驱动释义的抓手,使用短语驱动可以获得最佳收益。短语的释义功能还体现在一词多义的分辨上,由于短语提供了分辨词义的最小语境,义项的分析也可以在短语语料的基础上来进行。基于索引行的释义和义项分辨固然可行,但因为索引行的固有缺陷,对索引行的分析需要花费大量的时间。当索引行被进一步浓缩为短语后,冗余信息被过滤,关键信息得以凸显。短语驱动是释义和义项分辨经济且高效的选项。
再次,短语收录与词典的经济性也有密切关系。由于释义并不能指导语言使用,需要发挥例证的辅助释义功能。短语比句子具有更好的经济性,在短语能满足指导语言使用的前提下,不需要收录完整的句子。
四、 基于统计值的拉丁语短语识别
短语的识别有两个基本方法: 人工识别和自动识别。从目前的技术条件来看,自动识别的精度低于人工识别。但是,人工识别只适合于小规模的文本,针对大型语料库的短语识别必须采用自动识别的方式。短语自动识别也是语料库工具软件必须具备的功能。
(一) 短语自动识别的基本方法
短语的自动识别主要基于统计值,最简单的判断短语的方法就是依据节点词和搭配词在一定跨距内的共现次数。Wordsmith将次数门槛(threshold)设为5,即在设定跨距内如果某个词与节点词的共现次数达到5次或以上即为短语。图1是Wordsmith(Version 7.0)识别的与节点词NATURA相关的、频率最高的10个搭配词(语料由西塞罗作品组成,共计137932个形符):
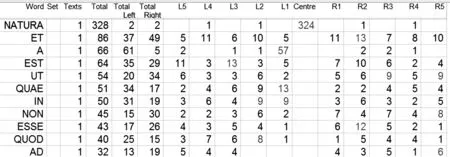
图1 与NATURA共现频率最高的10个搭配词
从图1可知,10个频率最高的搭配词基本都是介词、连接词等功能词,它们与节点词的共现既没有词典学意义,也没有统计学意义。它们并不是词典编纂所需要的短语,突出的共现频数只是由于et,a,est,ut等词汇在语料库文本中的超高频使用所致。为了克服简单频数这一缺点,语言学家设计出了一些实用的计算短语的统计学方法。
Evert(2004)提出过30多种统计算法。Wordsmith(Version 7.0)工具识别短语使用了7种方法,其中Z值测量法、T值测量法和MI(Mutual Information)值(互信息值;互信息熵;MI值)测量法最为常用。此外,Dice系数也是甄别短语的重要方法。Dice系数介于0至1之间,数值越大表示搭配力越强。
使用上述统计方法,大于门槛值(具有统计意义)的共现得以凸显,大多数简单频率高的搭配词会被过滤。例如使用Z值,以ORATIO为节点词,从当前语料库中可以识别出NUMEROSA ORATIO,OMNIS ORATIO,VIDETUR ORATIO等短语,随着语料库容量的增大,识别的短语会越来越多。从理论上说,只要语料库达到一定规模,与节点词(例如ORATIO)相关的搭配词都蕴藏在其中,提取短语就是一个数据挖掘的过程。
表1是以ORATIO,NATURA和SOLUM三个拉丁词为节点词,通过不同统计值识别所得的短语数量。

表1 四种统计方法所得的显性共现词语数量[1]
从表1可知,使用MI值时,所获得的共现词语对数量最多,T值最接近平均数,基于Dice系数的共现词语对数据最为稳定。
以ORATIO为例,从ORATIO的共现词汇来看,在通过4种不同方法得到的排序最前的40个词汇中,有11个是相同的,分别为: omnis (general), nostra (our), numerosa (numerous), videtur (it seems good), habetur (deemed), tua (your), philosophorum (philosophers), fit (is), ratione (reason), autem (however), debet (should)。4种方式识别的一致性比率为27.5%。
在针对ORATIO的短语识别中,T检验方法将部分功能词和关联词判断为具有共现关系,例如et (with),si (if),quod (and),aut (or)和verum (but)等,其他3种短语识别方式都没有此种情况。使用T检验法,MOLLIS (FLEXIBLE)与ORATIO (SPEECH)的共现T值为1.41,不具有统计意义,而另外3种统计方法都将其识别为最常用的20个共现词语。这表明T检验的识别精度相对较差。Z值和Dice系数(设系数为0.03时)识别的数量相当,MI值识别的数量最多。
再以NATURA为节点词,基于本研究所使用的西塞罗作品语料库,通过上述4种短语识别方法获取的基本数据如下:
1. 识别的短语数量依次为: MI值>T值>Z值>DICE系数。
2. T值和DICE系数识别的前50个共现词语大多数为功能词,与NATURA的共现没有词典学意义。Z值和MI值识别的前50个词以实义词为多,其中多数具有词典学意义。
3. 在前20个被识别的词语中(见表2),Z值和MI值识别的一致率达到80%,其中多数具有词典学意义或为实义词,例如DEPRAVATA, ABHORRERE, ADHIBENTEM, PARABILES, CERTOS, CONIUNCTOS, REPUGNANTE等。
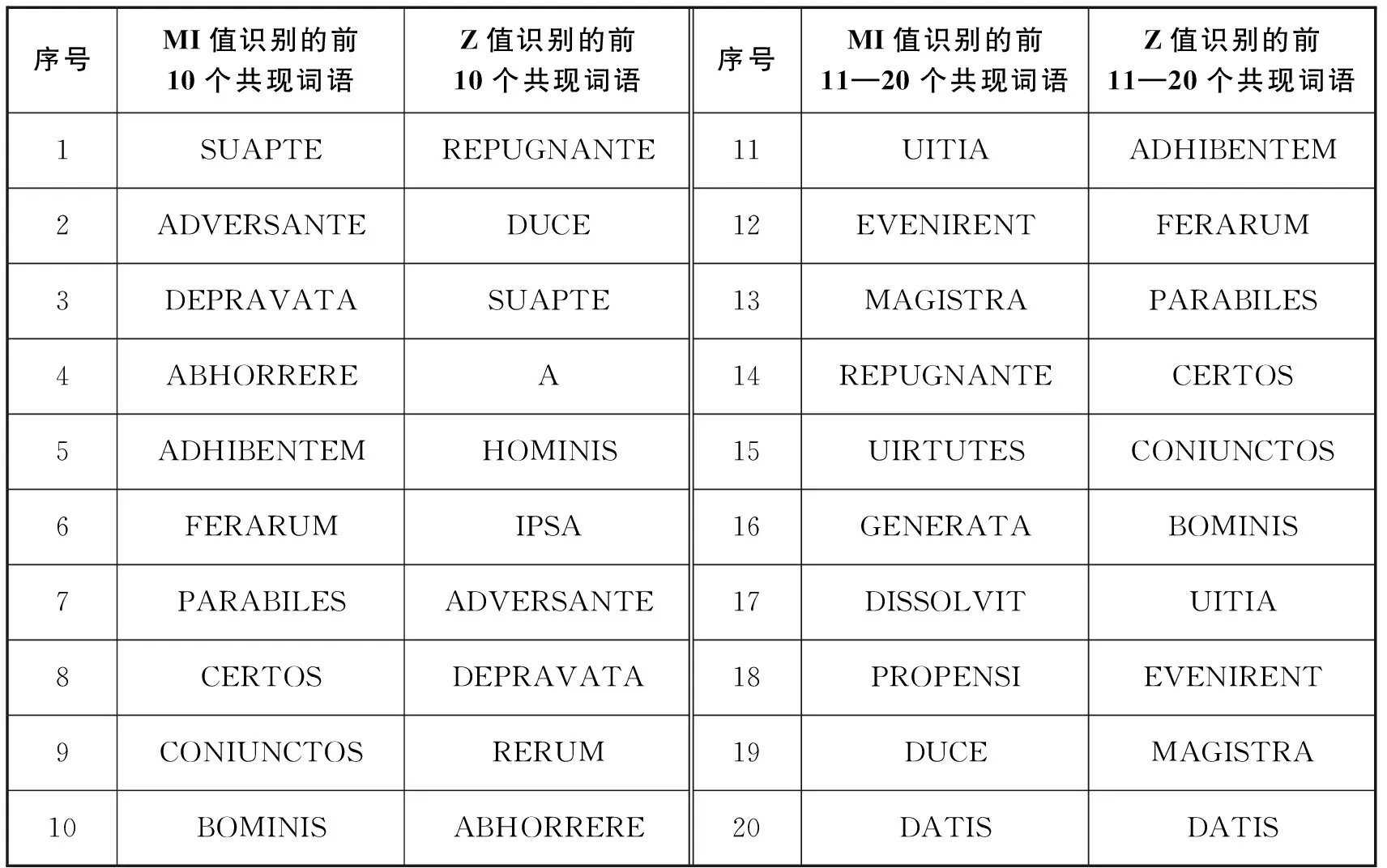
表2 MI值与Z值算法识别的前20个共现词语
SOLUM的情况与ORATIO和NATURA类似,也表现为MI值识别数量最多,T值较大的(排序靠前的)多为功能词等特征。根据以上3个节点词短语识别的数据,我们对常用识别方法总结如下: 不同识别算法在识别精度和效率方面有一定差异,T值较差,可以在实际短语识别和提取中放弃该算法;Dice系数在识别具有词典学意义的短语时,效果也不稳定,排序靠前的识别结果也有较大噪音;MI值和Z值短语识别的效度较好,可以将它们作为短语识别的首选方法。MI值和Z值最大的区别在于短语识别的数量不同,为了取得最佳效果,可以将两者综合起来使用,以取舍短取长之效。
(二) 短语统计识别的缺陷
基于统计的短语识别是目前短语自动识别最为有效的方法,但该方法也存在下列几个不足:
1. 算法本身的缺陷。各种算法都有过度匹配的问题,其中以互信息值算法最为严重。例如: HABEAMUS,VI,A,FINIS,SIVE等与NATURA的共现关系。
与过度匹配相反的是数据稀疏带来的关键短语统计值不具有显著意义和漏识别的问题,例如上文提到的MOLLIS和ORATIO的T值问题。同样使用T值,以NATURA为节点词,也有很多具有词典学意义的短语被排除在外,如HUMANI(T值为1.38),COMMUNIA(T值为1.37),PERSPICUUM(T值为1.37)等。
以上问题是统计识别的共性问题,增加语料可以解决数据稀疏的不足,但过度匹配暂时难以解决。
2. 跨距设定的悖论。目前普遍认为跨距为4或者5比较合适,Wordsmith默认值为5。从语言的实际情况看,短语共现的跨距是不固定的,跨距小会过滤掉大量短语,跨距大则会导致短语的过度识别。
3. 语料库工具在词形还原方面的缺陷。基于统计的搭配识别需要获得节点词、搭配词的频数及它们的共现次数等数值,目前这些数值都依靠相关软件获得。以Wordsmith为例,它所生成的数值有时并不可靠。例如NATURA,NATURAM,NATURAE是同一个词形(lemma),但是Wordsmith将它们作为不同的词形列出,当数据差异较大时,短语识别的结果不可避免会产生误差。在词形还原(lemmatization)问题得以解决之前,此缺陷难以避免。
五、 结语
对短语的记录任务通常由词典(纸质词典或机器词典)来承担,但是在词典学领域,词典理论家和编纂者长期以来主要关注相对较为固化的表达。(Gries 2008)3因此,词典对短语的记录任务还远远没有完成,大量的短语被有意或无意地排斥在词典收录范围之外。由于短语在语言交际中的重要地位,积极型的编码词典和面向语言理解或智能翻译的机器词典都应该多收录短语。
基于语料库的短语识别主要是自动识别,人工识别处于辅助地位,只有在对结果进行梳理时,人的判断才真正有价值。虽然自动识别目前还有一些不足,但总的来说,短语自动识别的结果还是可靠的。短语的漏识别是对自动识别的严峻挑战,但随着语料容量的增加,数据稀疏问题会得以解决。过度匹配并不是严重的问题,人工梳理阶段可以剔除没有词典学意义的短语。
本文的研究主要针对拉丁语,但由于西语多以拉丁字母为基础,有屈折变化,词语间不需要分词处理等共性,因此,该研究的结论有普遍性意义,同样适合其他以拉丁字母编码的语言。
附注
[1] 本文所言的“显性共现”值指具有统计意义的T值、Z值和MI值,分别为T值大于等于1.645(p值为0.05),Z值大于2,MI值大于3。本研究中,Dice系数大于0.03被认定为显性共现。
