基于Hadoop的区域土壤侵蚀强度计算GIS设计与实验
2018-09-17岳德鹏YANGDi罗志东许永利
雷 章 岳德鹏 YANG Di 罗志东 许永利 于 强
(1.北京林业大学林学院, 北京 100083; 2.佛罗里达大学地理系, 盖恩斯维尔 32611; 3.水利部水土保持监测中心, 北京 100053; 4北京地拓科技发展有限公司, 北京 100083)
0 引言
土壤侵蚀直接或间接导致土壤肥力下降,造成土质恶化、生态破坏,不利于农业可持续发展[1]。我国是世界上土壤侵蚀最严重的国家之一,区域土壤侵蚀预测预报一直是水土保持科研领域的研究热点[2]。区域土壤侵蚀预测预报研究的一项重要内容是根据土壤侵蚀模型快速计算土壤侵蚀强度,及时定量评价目标区域的土壤侵蚀状况[3-6]。近年来随着空间信息技术的发展和生产实际的需要,区域土壤侵蚀预测预报研究使用的空间数据精度越来越高,米级、亚米级高分辨率遥感影像已经得到广泛应用,土壤侵蚀强度计算涉及的数据量也越来越大,第一次全国水利普查水土保持普查各类侵蚀因子栅格数据约14TB[7-9]。对于这种大数据量栅格计算应用,传统的地理信息系统(Geographic information system,GIS)开发技术已难以满足实际需求[10-12]。一是大量数据的网络传输耗时太长,整个程序难以快速出结果;二是内存有限,无法写入整个数据,即使采用多线程进行数据分块读取分析的方式,仍无法解决这个内存限制,并且程序复杂度大大增加。目前已有文献研究使用Hadoop解决大数据量栅格数据计算应用方面的相关问题,在数据存储管理和查询应用方面取得了一些成果[13-22],但对栅格数据坐标关联性问题和多栅格因子之间的计算应用考虑较少,不适合处理区域土壤侵蚀计算这种涉及多个栅格数据层处理的情况。
本文探讨可适应多栅格数据层处理的土壤侵蚀因子栅格数据分割分块算法、Hadoop数据节点选择策略和土壤侵蚀模型MapReduce编程等技术问题,构建区域土壤侵蚀计算GIS,并通过实验验证系统功能和性能。
1 设计与实现
该系统主要功能是实现在任意空间范围内土壤侵蚀强度快速分析计算并将结果数据发布为地图服务供查询应用,涉及土壤侵蚀因子栅格数据存储管理、土壤侵蚀强度分析计算和土壤侵蚀强度数据发布3个模块。其中土壤侵蚀因子栅格数据存储管理模块需解决大数据量栅格数据在Hadoop的分布式文件系统( Hadoop distributed file system,HDFS)集群环境下的高效存取问题;土壤侵蚀强度计算模块需设计以MapReduce编程模式开发土壤侵蚀模型程序的方法并实现;土壤侵蚀强度数据发布模块是将计算结果实时发布为Web地图瓦片服务(Web map tile service,WMTS),以便于查询应用。由于Hadoop是JAVA语言开发的,且仅支持在Linux平台上运行,故本研究同样采用JAVA和Linux系统,以避免采用不同开发语言和操作系统平台可能引起的额外工作。
1.1 土壤侵蚀因子栅格数据存储管理
根据Hadoop的计算任务本地化思想,数据存储非常关键,需尽可能使计算关联紧密的土壤侵蚀因子栅格数据存储于同一个数据节点,使计算关联不紧密的数据分散存储在不同的数据节点。这样设计可降低土壤侵蚀强度计算程序通过网络从不同数据节点抓取数据的数据量及频率,减少网络传输对系统性能的影响,因为网络传输速度远小于本地硬盘读速度,同时使土壤侵蚀强度计算程序运行时始终有最多的计算节点并行执行,提高计算性能。
由于土壤侵蚀强度计算是分地理区域进行的计算,所以土壤侵蚀因子栅格数据存储管理的基本思路是:划分地理网格,分割栅格数据,改进Hadoop存储数据时数据节点选择策略使同一地理网格的栅格数据可存储于同一个数据节点,即一个计算单元中,以实现大区域内多个地理网格栅格数据并行处理。分割栅格数据也可以根据栅格文件大小直接分成数据量在HDFS默认的文件大小64MB之内文件块,分块存储,但这样仅适用于栅格图层连续完整的情况,生产实际中栅格图层很可能只是某个特定区域的,不能够保证每个栅格图层都是连续完整的情况,所以本文采用地理网格分割数据,这样即使栅格数据不连续,也可使其放到既定数据节点。具体算法如下:
(1)依2000国家大地坐标系(China geodetic coordinate system 2000,CGCS2000)划分地理网格。
地理网格划分非常重要,它决定了栅格数据分块的数据量大小。在并行计算中,如果数据分块太大,各计算单元处理的数据量就大,不能充分发挥并行计算的优势,同时会造成很多数据分块空间未占满,磁盘空间利用率不高;分割太碎,会使一个文件需要存放在大量的文件块上,而这些位置信息需要被管理节点记录,浪费管理单元的存储空间,检索文件开销会比较高,同时会使磁盘频繁寻址,降低数据读取效率,也不利于并行计算,所以地理网格划分是栅格数据存储的关键。
HDFS研发之初的目标是解决大数据分布式存储,以支持并行计算的问题,它假定数据都是以大文件的形式存在的,不是只有几KB的小文件,以此为单位读取数据文件,这是以空间换时间的策略,降低文件读取时磁盘访问次数,使文件系统具备较高的性能。目前一般计算机磁盘数据传输速度在100 MB/s以上,平均寻址时间约10 ms,为了使数据块读写时,寻址时间小于整个时间的10%,需设置数据块在100 MB以上,这里设定数据分块大小为128 MB。
CGCS2000是国家2008年规定使用的大地坐标系统,要求测绘结果逐步统一到该坐标系统下。土壤侵蚀栅格因子是单波段数据,每个像素记录的数据最短类型为byte(字节型),占空间是1个字节,最长是float(单精度)4个字节,所以一个像素数据量在1 byte到4 byte之间。分析某区域土壤侵蚀状况,比如一个生产建设项目所在区域,需要遥感分辨率一般不大于2 m,所以本研究中考虑栅格数据分块大小,也以2 m分辨率栅格数据量估计为基准。128 MB栅格文件2 m分辨率所占面积在134.217~536.871 km2,选取范围较小的作为划分地理网格的基础,这样每个栅格块数据量都会在128 MB以内,所以纵横轴都选取11.585 km为跨度划分地理网格。为了便于实际应用,将跨度提升为12 km,将数据分块大小响应调整为138 MB。
假定(x0,y0)是CGCS2000坐标系下我国国土的左下角坐标,以12 km×12 km为一个网格,编号为(i,j),那每一个网格坐标范围计算公式为
(1)
式中 (xi,yj)——网格左下角坐标
(x′i,y′j)——网格右上角坐标
(2)根据网格坐标范围从栅格文件左下角开始逐列分割栅格数据,并建立元数据。
假定栅格文件左下角坐标为(x,y),根据此坐标计算第1个栅格分块的位置编号,计算公式为
(2)
式中 (ri,ci)——栅格分块位置编号
用位置编号(ri,ci)根据式(1)计算出(xmin,ymin)和(xmax,ymax),即第一个栅格块四角坐标。
假定栅格文件右上角坐标为(x′max,y′max),先计算栅格文件可分割的行数和列数,计算公式为
(3)
式中f——可分割总列数
f′——可分割总行数
将(xmin,ymin)代入式(1),计算各栅格分块的四角坐标,计算方法为
(4)
为便于土壤侵蚀因子栅格数据块的快速查找,设计元数据信息由栅格数据分块编号C、分辨率R、因子名N和数据时相T组成,并且在数据分块存储时直接将CRNT 4类信息记录为栅格数据文件名。这样将不用侵入Hadoop内部修改Namenode的元数据管理程序,直接根据文件名称判别目标文件是否属于当次计算任务涉及的栅格数据块,降低开发难度。
(3)栅格数据块上传存储于Hadoop的数据节点datanode集群中。
需遵循两个原则:①不同土壤侵蚀因子栅格数据所在网格编号相同的栅格数据块存储于同一个数据节点。②任何相邻网格的栅格数据块不能存储于同一个节点,这样可使多个栅格图层进行数学计算时能尽可能多的利用多个计算单元并行处理。由于每一行的格子最多与上一行的3个格子相邻,所以最少需要4个存储单元,才能让该行每个格子与上一行相邻的格子错开存储,每个格子对应的存储单元编号计算方法如下:
假定有4个存储单元,编号分别为0、1、2、3;每个栅格分块的编号为(x,y)。计算每个栅格分块对应的存储单元编号f(x,y)为

(5)
Hadoop数据存储是由管理节点选取3台数据节点冗余存储每个数据块,其中第1个数据节点随机选择,第2个与第1个在同一个机架,第3个在其他机架,这样是为了保障数据存储稳定。按照上述原理,可以配置至少4个数据节点,改进数据存储时管理节点选择数据节点的策略,使其按照式(5)策略选择存储单元,计算过程如图1所示。
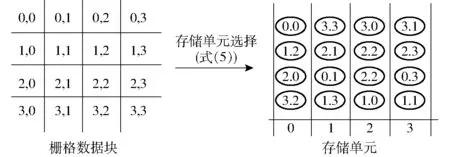
图1 存储单元选择算法Fig.1 Storage unit selection algorithm
1.2 土壤侵蚀强度分析
土壤侵蚀强度分析是根据土壤侵蚀模型,计算单位面积单位时间内土壤侵蚀数量。土壤侵蚀模型实质为同一地理坐标系统下同一个地理坐标点上栅格像素计算,只要设计一种侵蚀模型对应的MapReduce程序,其他侵蚀模型可以此类推。研究中通用水土流失方程为
A=RKLSCP
(6)
式中A——年平均土壤流失量,t/(hm2·a)
R——降雨侵蚀力因子,MJ·mm/(hm2·h·a)
K——土壤可侵蚀性因子,t·h/(MJ·mm)
LS——地形因子
C——植被覆盖因子
P——水土保持措施因子
根据式(6),设计土壤侵蚀强度并行计算程序。根据MapReduce并行编程框架的思想,设计土壤侵蚀强度并行计算程序的Mapper和Reducer接口的输入输出如表1所示,程序逻辑如图2所示,具体算法如下:
(1)根据计算区域查找其覆盖的栅格文件集合
假定输入的计算区域对应的外包矩形,其对角坐标分别为(xmin,ymin)和(xmax,ymax),根据式(2)可分别计算出对角对应的栅格块编号分别为(rmin,cmin)和(rmax,cmax),形成了一个编号区间。该编号区间涵盖的全部文件即为该区域覆盖的栅格文件集合。根据上述元数据定义,即可推知全部栅格文件的名称。
(2)通过Mapper程序读取栅格值
按照栅格数据分块存储时建立的元数据,以文件名和文件数据内容组成的形式如表1中的〈“C|R|N|T”,“V”〉,输入到Mapper程序,读取每个像素位的栅格值,并形成新的key-value形式作为Reducer程序的输入。
(3)通过Reducer程序进行栅格计算
Reducer程序通过对像素坐标相同的值进行解析,获取同一个像素坐标下,不同栅格因子对应的栅格值,并按照式(6)计算形成侵蚀强度数据,并输出成栅格文件。
MapReduce执行逻辑如图2所示。

表1 Mapper程序和Reducer程序的输入输出说明Tab.1 Input and output instructions for Mapper and Reducer program
注:C|R|N|T表示栅格文件名称,具体为分块位置编号|分辨率|侵蚀因子名|时间;V表示栅格文件数据内容;P表示像素坐标。
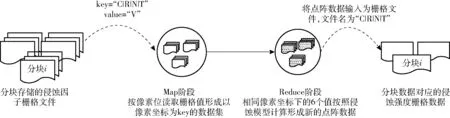
图2 土壤侵蚀模型MapReduce程序逻辑图Fig.2 MapReduce program algorithm overview
1.3 土壤侵蚀数据发布
本研究中使用GIS中间件Geoserver对生成的土壤侵蚀强度栅格数据进行发布,形成土壤侵蚀WMS(WEB地图服务)。由于土壤侵蚀强度栅格数据存储于HDFS集群中,一般的GIS中间件如ArcGIS Server、SuperGIS等不支持HDFS数据读取,所以无法直接应用。而Geoserver是开源项目,可以直接获取源代码,在源码基础上扩展开发Geoserver栅格数据源识别功能,使Geoserver可以支持直接读取HDFS文件系统中的栅格数据,实现土壤侵蚀强度栅格数据的动态实时发布。
Geoserver数据源管理功能程序设计比较简洁,是采用JAVA SPI(Service provider interface,服务提供接口)机制实现的,添加HDFS栅格数据源读操作时需先创建HDFS数据读操作类,实现org.geotools.coverage.grid.io.GridFormatFactorySpi接口规定的createFormat方法;然后根据JAVA SPI的规则要求在目录META-INF/services/下增加文件org.geotools.data.GridFormatFactorySpi,内容为HDFS数据读操作类的完整类名。完成后重启Geoserver服务,即可读取HDFS栅格数据源。
2 实验与分析
2.1 实验环境和数据
实验中使用了5台计算机组成集群部署运行该系统。每个节点机器软硬件配置相同,具体为:CPU4核4线程、3.4 GHz频率,内存4 GB,硬盘500 GB,操作系统ubuntu linux 14.04,Java虚拟机JRE1.7,网络带宽为各节点独享100 Mb/s。其中一台部署为HDFS管理节点namenode,并运行该系统程序,另外4台作为HDFS的数据节点datanode使用。
在上述测试环境下,采用大凌河流域的R、K、LS、C和P共5个土壤侵蚀因子栅格数据做实验,数据见图3。大凌河位于辽宁省西部低山丘陵区,长约435 km,流域面积约23 549 km2,各因子数据分辨率为2 m、像素值类型为IEEE单精度浮点数(4字节)、数据量为5.632 GB,总数据量为28.16 GB。
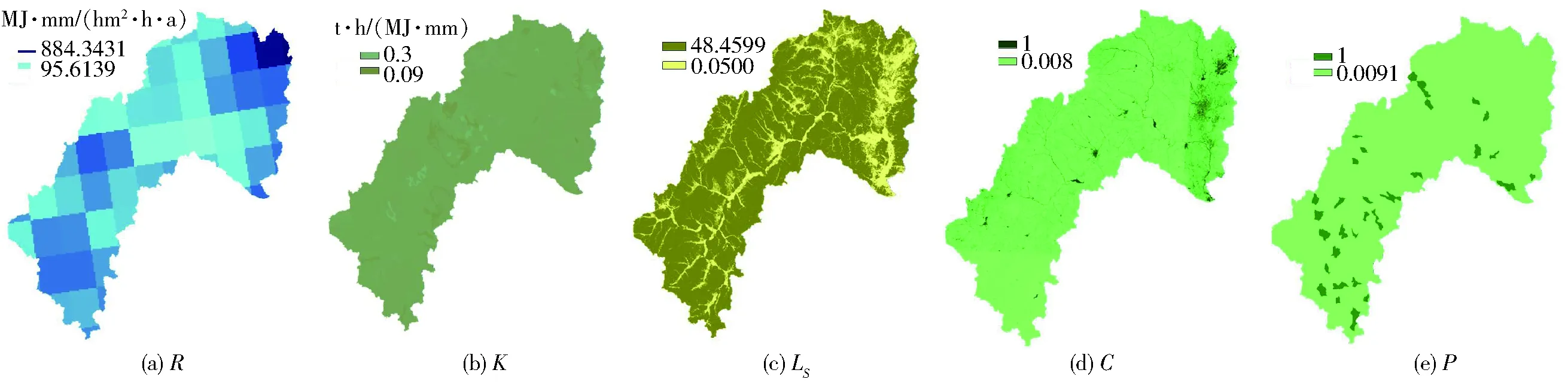
图3 土壤侵蚀因子分布Fig.3 Distribution of soil erosion factors
2.2 功能分析
输入5个因子数据,系统生成大凌河流域水力土壤侵蚀强度栅格如图4和表2所示,栅格图上颜色越深的区域土壤侵蚀强度越大,表2是根据土壤侵蚀分类分级标准[23]统计生成的。
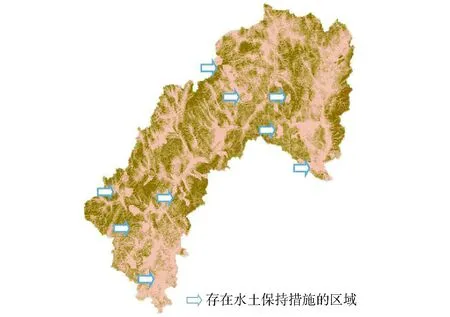
图4 土壤侵蚀强度图Fig.4 Map of soil erosion

土壤流失量/(t·hm-2)分级面积/km2面积百分比/%0~5微度8453.47 59.605~25轻度4215.3929.72 25~50中度1336.12 9.42 50~80强烈177.29 1.25 80~150极强烈1.41 0.01
由图4和表2可知:①栅格图上颜色比较浅区域,其数量、位置和形状与水土保持措施分布的数量、位置和形状完全吻合,说明存在水土保持措施区域,土壤侵蚀强度都比较小,符合RUSLE模型中水土保持措施与土壤侵蚀强度的负相关特征。②表2中微度和轻度流失区域占总面积89.32%。微度主要位于城区,强烈和极强烈流失区的面积之和为178.7 km2,占总面积1.26%,这些区域为需优先治理的区域,它们主要分散在山沟地区。
2.3 性能分析
系统输出的大凌河流域水力土壤数学侵蚀强度栅格数据,分辨率为2 m、像素值类型为无符号整数(1字节),数据量为1.412 GB。执行过程中执行时间和网络使用率如图5所示。
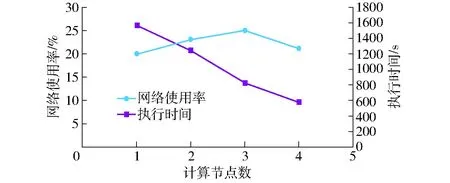
图5 不同计算节点数量下的网络使用率和执行时间Fig.5 Network utilization and execution time of different numbers of compute node
由图5可知:①随着计算节点从1台增加至4台,该区域土壤侵蚀强度栅格图生成过程耗时明显降低,说明本研究提出的系统构建方法可以实现区域土壤侵蚀快速计算与实时发布,并通过增加计算节点可显著提升系统性能。②计算过程中集群环境网络负载较低,使用率保持在22%左右。说明研究中设计的数据存储策略使数据本地化较好,在区域土壤侵蚀强度计算过程中,按数据分块启动的多个并行执行的计算任务都较好地分布在各数据分块对应的数据节点上,没有出现通过网络异地大量读取数据的现象。
3 结论
(1)该系统可快速计算出大凌河流域不同强度的水力土壤侵蚀分布区域及占比,可以为大凌河流域水力土壤侵蚀监测和治理提供参考依据。
(2)该系统可明显提升基于大数据量高分辨率土壤侵蚀因子栅格数据的区域土壤侵蚀强度从分析计算到发布应用的效率,可较好满足区域土壤侵蚀预测预报的时效性要求。
(3)所设计的土壤侵蚀模型MapReduce编程模式,可以为同类模型的MapReduce并行计算程序研究提供参考。
(4)对于大数据量栅格数据并行计算时,该系统计算任务本地化效果明显,显著降低了计算过程中的网络传输压力,系统性能较好,通过增加计算节点,系统性能还可进一步提升。
