云计算环境下虚拟机部署策略研究
2018-08-29袁爱平
袁爱平
(长沙民政学院软件学院 长沙 410004)
1 引言
云计算是从分布式计算、网格计算和并行计算等概念发展而来一种新型的计算模式,它是一种基于互联网相关服务的增加、使用和交付模式。虚拟机资源是云计算环境中的主要资源,数据中心的各种硬件资源通过使用虚拟化技术形成虚拟资源池,系统动态部署虚拟机,用户透明使用。随着用户数量的持续增加,数据中心规模不断扩大,如何提高云计算环境中的虚拟机资源利用效率以及用户响应的等待时间,已成为云计算资源部署的关键问题。
虚拟机部署策略的优劣决定了数据中心云计算系统的性能。目前,针对云计算环境中的虚拟机资源部署问题,专家和学者们进行广泛研究并提出了各种策略。文献[1]通过计算待部署虚拟机和服务器性能向量的相对距离,获得待部署虚拟机的匹配向量,将匹配向量与系统负载向量综合分析得到虚拟机的部署位置;文献[2]提出了多周期分配策略,建立了多周期分配的虚拟机负载均衡问题的数学模型,利用改进的蚁群算法进行了求解;文献[3]提出了一种面向多目标优化的虚拟机初始放置方法,基于改进的分组遗传算法和多目标模糊评估方法计算虚拟机的放置问题。本文在分组遗传算法的基础上,提出了一种负载均衡的虚拟机调度算法LBGA,综合考虑虚拟机资源提供过程中资源容量的限制以及负载均衡的需求,从空间利用率、重量和负载变化三个方面来定义评价函数,并通过加权方法定义适应度函数。另外,对选择和变异操作进行了优化,以获得算法的近似最优解。最后通过云仿真计算器CloudSim[4]进行了仿真,仿真结果表明本文的算法均衡了服务器资源的分配,提高了资源的综合利用率。
2 调度算法模型
我们假设有m台可用的物理服务器,定义为M={PSi|1≤i≤m},另有n个虚拟机调度请求,定义为N={VMi|1≤i≤n}。虚拟机需物理服务器上的多维资源来实行运算,定义虚拟机i对资源的请求向量为 qi={qi。1qi。2… qi。k} ,qi。j表示虚拟机 i对 j类型资源的需求量。同样,定义物理服务器i能提供的资源容量向量为 ci={ci。1ci。2… ci。k} ,ci。j表示服务器i能提供的 j类型资源容量。服务器资源负载等于虚拟机所占各维资源向量的和。
定义1:S={S1。S2。…。Sn}表示虚拟机的映射解集合,Si表示主机i上的一种虚拟机映射方案,令T为负载监测周期,根据主机负载的变化规律,将T划分为r个时间段为
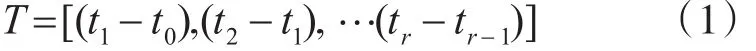
定义2:假设虚拟机的负载在各个时间段中是稳定的,定义虚拟机VMi在时间段k的负载为VL(i。k),则周期T 中主机 PSi的总负载 PL(i。T)为
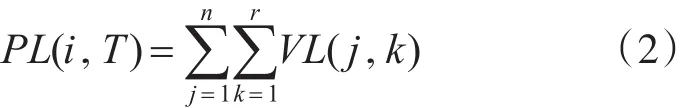
通常虚拟机配置到主机后,资源负载会发生很大的变化,因此,需通过虚拟机的动态迁移来调整资源负载以达到负载均衡,我们把虚拟机配置到物理服务器后在周期T内的负载标准偏差设置为
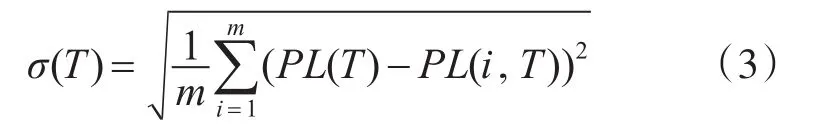
其中
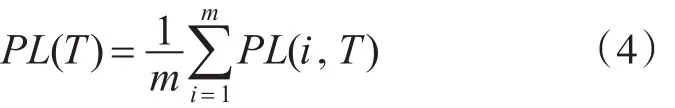
σ(T)反映了样本总体相对于平均值的离散程度,即表示了各物理主机负载相对于平均负载的离散程度。
由于云计算环境中虚拟机所需物理服务器的资源具有多维性(如不同的CPU、内存和I/O等),各维资源的请求及性能差异很大,因此可以通过资源使用状况的负载度量来反映多维资源的利用情况。本文将同时考虑主机的三种资源:CPU、内存和I/O,把虚拟机负载定义为
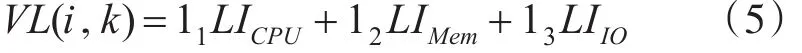
其中 01。12。131,且 11+12+13=1,表示资源的负载权值。 LICPU、LIMem和 LIIO分别表示为主机中CPU、内存和I/O的利用率。我们算法的目标是启动最少的物理服务器以获得最大的资源利用率,同时确保被分配的资源不超过服务器的容量上限。
3 算法实现
如上所述,本文在设计算法时重点考虑多维资源之间的均衡负载,以实现最小化物理服务器启动数量和最大化资源综合利用率的目标。基于服务器聚合思想的虚拟机调度属于组合优化中的装箱问题,传统的遗传算法由于编码等问题对于分组问题的适应性很差[5]。因此,本文提出了一种改进的分组遗传算法来求解虚拟机的调度问题。该算法在分组遗传算法的基础上,采用负载均衡的资源分配方案,从空间利用率、重量和负载变化三个方面来定义适应度函数。另外算法采用轮盘赌法来选择个体,并优化了种群中个体之间的交叉及变异,以快速有效地获取近似最优解。其算法流程如图1所示。
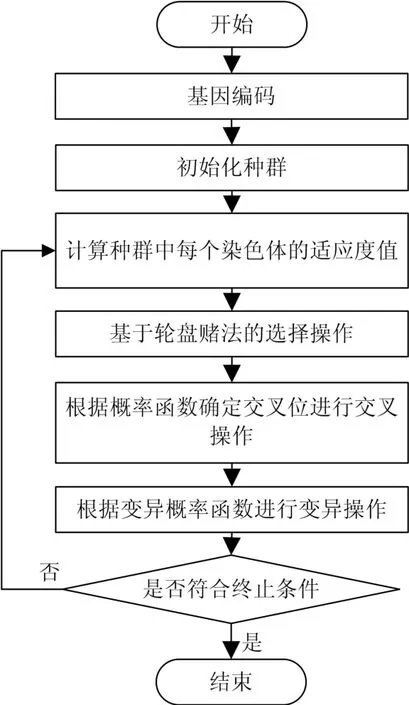
图1 算法基本流程
3.1 基因编码
在给出的分组遗传算法中,为了避免编码的长度过长而影响计算的效率,以及后面的交叉和变异等操作不会破坏服务器的硬约束条件,我们用服务器的数量来决定染色体的基因位数。染色体中的每一位基因代表一个物理服务器,基因的值表示该服务器上装载的虚拟机集合,也就是虚拟机的一个分组,如图2所示,A、B代表物理服务器,1~5代表虚拟机,染色体的编码为:AB(A:{1、3},B:{2、4、5})。
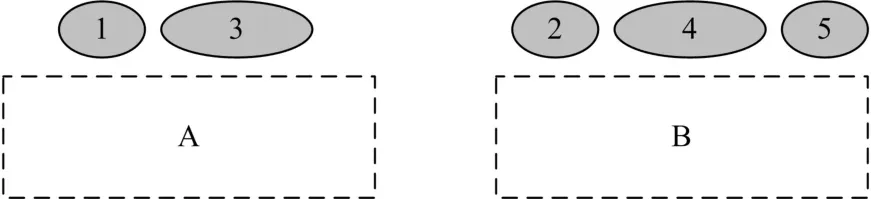
图2 算法中的染色体基因编码示例
3.2 适应度函数
适应度函数的选取直接影响到分组遗传算法的收敛速度以及能否找到最优解,为了达到最小化物理服务器启动数量和最大化资源综合利用率的目标,适应度函数的设计应综合考虑物理服务器的使用数量和多维资源的均衡分配。考虑到虚拟机资源提供过程中资源容量的限制以及负载均衡的需求,从空间利用率、重量和负载变化三个方面来定义评价函数,并通过加权方法定义最终的算法适应度函数。
1)空间利用率函数
空间利用率为虚拟机体积占主机体积的比率,定义为

其中,BVi表示放入主机的第i个虚拟机的体积,CV表示主机的体积,n为主机中的虚拟机数量。第i个虚拟机的体积定义为
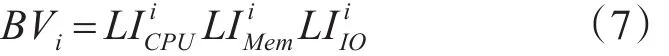
2)重量函数
虚拟机的重量以其负载VL表示,定义为
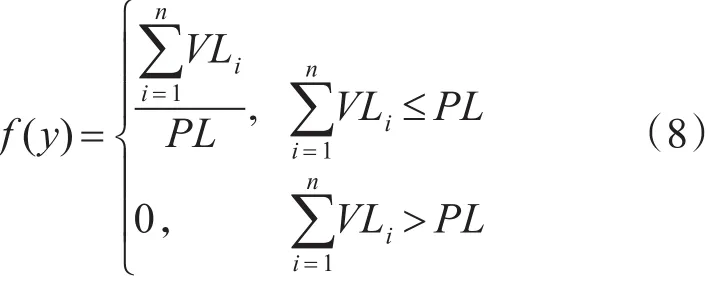
其中,VLi表示第i个虚拟机的重量,PL表示主机的最大承载重量,若虚拟机的总重量超过主机的最大载重,则函数的值为0。
3)负载变化函数
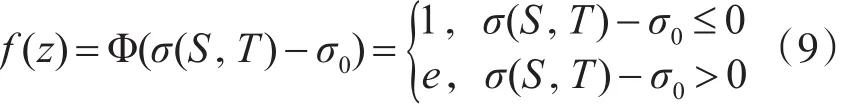
σ0表示实现主机负载均衡所允许的负载变化约束值,σ(S。T)表示主机在T时间段内实际的负载变化值,Φ(x)为惩罚函数,当个体满足负载变化约束时,其值为1,否则为e。
根据惩罚函数和处理多目标优化的加权系数方法,本文定义适应度函数为
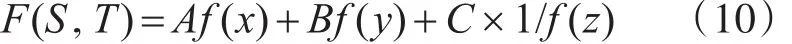
其中,A、B和C表示加权因子,0≤A。B。C≤1,且A+B+C=1。
3.3 选择
选择操作就是对每次迭代产生的个体进行整体评估,然后选择适应度值较大的个体作为下一代种群的初始集合。为了避免仅挑选适应度较大的个体而使解陷入局部最优,我们采用轮盘赌法来选择种群的个体,其基本原理是根据每个染色体适应度的比例来确定该个体的选择概率。具体步骤如下:
步骤一:根据式(10)定义的适应度函数计算每个个体的适应度值和种群的适应度总和。
步骤二:计算个体的适应度值在总和中所占的比例,作为该个体的选择概率 ps(ai)。
可以看出,这种选择算法随机性较强,适应度值越大的个体被选择的概率越大,同时具有较小适应度值的个体也有被选择的机会。
3.4 交叉
交叉操作通过选择两个父代个体的部分结构进行交换以生成新的个体,可以极大提升遗传算法的全局搜索能力。但如随机选择交叉位,则会造成全局搜索效率的下降;如每次选择评估值较高的基因进行交叉,则算法很容易陷入局部最优并出现早熟收敛现象。因此我们引入可调参数的概率函数,既保证了评估值较高的基因被选择以进行交叉,同时制造了全局搜索的随机性。我们首先计算染色体中的基因评估值并排序,再定义排在第1位的基因被选择为交叉位的概率为 p(q),服从 p(q) ~q-ε的分布函数,其中,ε≥0,且取值为2。可以看出,概率的随机性保证了全局搜索的性能,同时评估值较高的基因具有较大的概率被选择为交叉位。选择基因进行交叉操作之后,去掉含有相同基因值的服务器编码,同时采用FFD[6]方式回填因消除服务器而失去从属关系的虚拟机。
3.5 变异
变异算子通过赋予个体以很小的概率产生转变而形成新的个体,增加了种群的多样性,使得遗传算法在交叉算子决定的全局搜索能力的基础上,还具有局部的随机搜索能力,以防止出现非成熟收敛。为了保证算法的局部搜索能力,变异率不能过大,如果变异率过大,则算法就退化成随机搜索,因此设置变异概率函数如下:
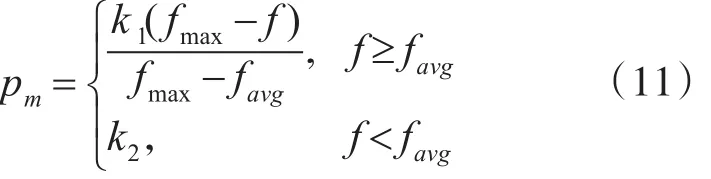
式中,f为要变异的个体适应度值,favg为当代种群的平均适应度值,fmax为种群中最大的适应度值。当 f≥favg,表示个体适应度值较大时则应该让pm较小,防止适应度值较大的个体被破坏;当f<favg,表示个体适应度值较小时则应该让 pm较大,以开辟新的搜索区域。在本文中设定k1=0.003,k2=0.0042。通过引入变异概率函数,根据种群适应度值的情况调整变异概率,不仅加快了算法的收敛速度,同时防止出现非成熟收敛而陷入早熟情况。
3.6 终止条件
算法的终止是防止出现迭代次数过多的情况,本文基于最优跨度的适应度函数值标准差来决定算法的终止,如式(12)所示:
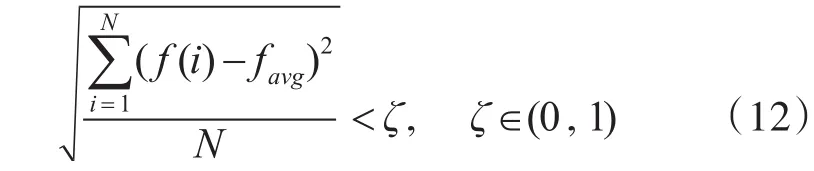
其中,f(i)表示第i个个体的适应度值,favg为当代种群的平均适应度值,N为种群的个体数量,ζ为收敛的阈值,在这里取ζ=0.1,当算法的标准差小于这个阈值时终止迭代,否则继续进行迭代进化。
4 仿真实验
为了验证负载均衡调度算法LBGA与传统算法相比在效率上的提高,本文采用CloudSim工具进行仿真,通过与该领域的服务器聚合算法FFD以及多维资源调度算法DRF[7]进行比较。实验运行的工作负载规模分为100、300、500、800及1000个虚拟机这五个实例,参数设置参考 Feitelson[8]和Mishra[9]等方法,我们把每个实例中的算法均运行30次,取其平均值作为性能分析的依据。
物理服务器的使用数量是衡量服务器资源均衡调度性能的重要指标[10]。LBGA算法、DRF算法和FFD算法在物理服务器使用数量方面的比较如图3所示。通过分析可以看到,由于LBGA算法综合考虑了资源负载的均衡,因此对于实验运行的各个工作实例都只需要启动最少的物理服务器,LB⁃GA算法相比FFD算法、DRF算法分别节省11.2%和4%的服务器使用量。LBGA算法由于在调度中综合考虑了虚拟机的多维资源需求及服务器的资源容量,通过虚拟机的合理部署使服务器的空余资源达到均衡,为后续虚拟机的资源使用提供了更多的可能性,相应地减少了服务器的使用数量。
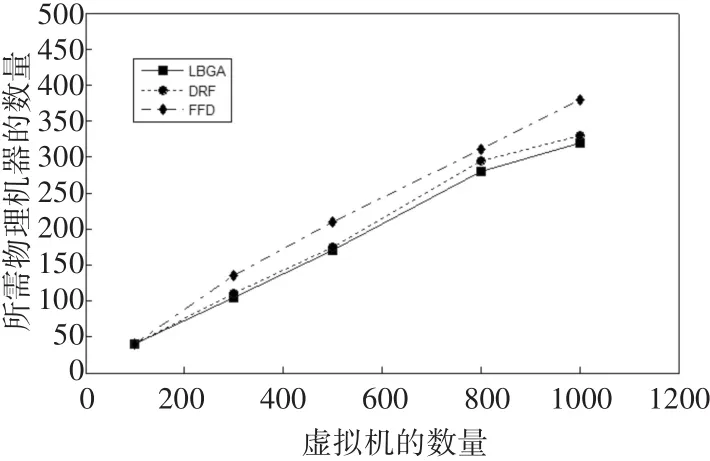
图3 服务器使用数量比较
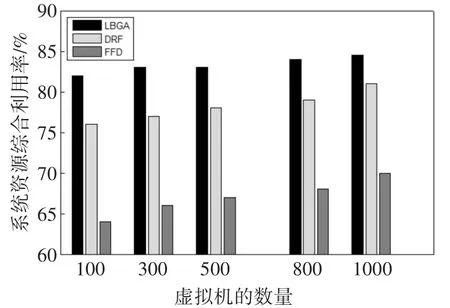
图4 系统资源综合利用率比较
系统资源的综合利用率也是衡量调度算法性能优劣的重要依据[11]。通过图4中LBGA算法、DRF算法和FFD算法的比较可以看到,LBGA算法相比DRF算法和FFD算法在资源综合利用率方面取得了6.5%~12.1%的提高,并且由于LBGA算法具有较小的标准差,算法在稳定性方面也具有一定优势。由于LBGA算法在虚拟机部署过程中注重物理服务器资源之间的负载均衡,每次虚拟机部署时尽量满足服务器多维资源之间的互补关系,防止出现因某种资源过早饱和而抑制其它资源使用的现象,因此从整体上提高了服务器资源的综合利用率。
5 结语
本文针对传统的遗传算法在解决装箱问题上效率的不足进行了改正,并将其应用于云环境中虚拟机的部署问题。该算法在分组遗传算法的基础上,从空间利用率、重量和负载变化三个方面来定义适应度函数,并通过加权方法定义适应度函数。同时,算法对选择和变异操作进行了优化,实现了数据中心服务器资源的高效均衡分配。最后,通过与该领域的聚合调度算法FFD和多维资源调度算法DRF比较,证明了该调度算法的有效性和高效性。
