基于改进聚类的电力大数据审计证据发现
2018-08-29余从容卢利娟梁东贵
余从容 卢利娟 梁东贵
(广州供电局有限公司 广州 510000)
1 引言
电力企业的投资规模,影响着国计民生和国家经济命脉[1],随着投资规模的扩大,对资金使用效益、管理和资金风险管控有重要监督作用的工程审计逐渐成为公司的重要工作。而信息系统的逐步完善与提升,电力企业产生的电子数据比以往更多,审计数据呈海量化的增长趋势,已建立起TB甚至PB级的大数据库[2]。面对数据量的海量增长以及各种管理系统中大量的非结构化数据存储,依赖于审计经验的数据库语句查询方法不能充分发挥大数据在揭示数据疑点方面的优势,而且审计经验往往落后于审计数据的发展,使得许多新的审计疑点不能被及时发现,给审计带来风险,为此,如何整合充分利用这些数据,实现审计大数据的全覆盖并从中发现疑点,是计算机审计面临的迫切要求和全新挑战[3]。
数据聚类[4]可以在无需给定先验知识的情况下即可揭示出数据元素之间内在关系完成数据分类,审计聚类中包含较少实例的簇由于其与实例较多的“大簇”之间的特征属性差异较大,因此可被视为潜在的审计疑点,在进行大数据计算机审计证据发现时,聚类可以将具有更大审计疑点的占较少比例的数据聚类为可疑数据“小簇”,配合审计经验从而实现快速审计疑点定位,既充分利用大数据的全覆盖优势又能揭示潜在可疑审计数据。为此,王会[5]根据大数据聚类技术初步完成计算机辅助审计框架,秦志光等[6]提出了基于云存储技术的的大数据审计,秦荣生[7]分析了大数据聚类技术对于审计方式的影响,但这些研究对基于聚类的大数据审计的实施并不具体,更多停留在理论探讨。
为此,在已有研究基础上,提出了基于并行蜂群迭代聚类的电力审计大数据疑点发现算法,算法在经典K-means算法基础上,采用Leaders算法获得大数据的初始聚类中心数,然后采用改进蜂群算法与K均值组合迭代优化聚类中心及聚类结果,实现审计大数据的精确聚类,并采用消息传递接口MPI进行算法并行改进,以适应大数据聚类的运行时间需要,最后以实例数较少的异常聚类或离散值识别为潜在疑点,实验验证了算法在审计大数据疑点发现的有效性。
2 基于并行蜂群迭代聚的疑点发现算法
在进行大数据聚类时,经典的K-means算法存在依赖初始聚类中心设置、极易形成局部最优收敛和无法满足大规模数据聚类的性能和效率要求的问题,而且,在审计大数据中潜在的疑点簇和不相关小簇并不能依靠审计经验确定聚类中心数。为此,针对这些不足,文中算法通过Leaders算法获得大数据的初始聚类中心数,改善初始聚类中心的设置;通过改进改进蜂群算法与K均值组合迭代优化聚类中心及聚类结果,实现大数据的精确聚类;通过并列运行,以满足电力审计大数据处理的性能和运行效率需要。
2.1 基于Leaders算法的初始聚类中心数获取
基于增量聚类的 Leaders算法[8~9]能够忽略聚类类别的归属模糊性,不需指定聚类中心数,仅扫描一遍数据并选取簇的Leader代表点实现聚类,且仅存储提取的Leader,节省运行时间和存储空间,对处理大规模数据十分有利[10]。
Leaders算子自动计算大数据聚类中心,但其对数据输入顺序敏感,且易形成图1所示的类间相似大于类内相似的情况,加之固定距离导致聚类结果分布均匀,因此Leaders算子可以快速获得审计大数据的聚类,但其准确性不能令人满意。
为此,结合已有研究成果,以Leaders簇心作为初值应用于K-means算法中,以期精确聚类审计疑点簇及不相关的小簇。
2.2 改进的蜂群算法
蜂群算法是一种基于群体智能原理的搜索算法,其蜜源代表大数据聚类的一个潜在聚类中心。蜜源由相应的位置和优化目标函数决定其适应度值,由适应度值衡量蜜源的优劣。本文改进的蜂群算法里的蜜源在第K+1次迭代操作中通过学习前gbestk来更新蜜源位置。改进后的蜜源位置公式为
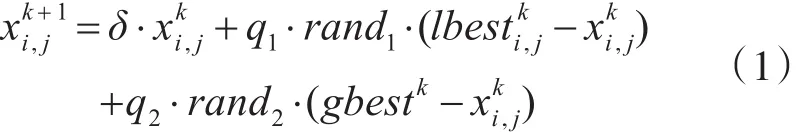
2.3 蜂群优化K-means聚类算法
Leaders初始聚类中心解决了K-means算法初始值设置问题,但Leaders算法的初始聚类中心并不精确,为此文中采用改进蜂群算法与K-means算法相结合,优化聚类中心,进而获得精确聚类。算法的基本思想为,以Leaders初始聚类中心为初始值,使用式(1)所示的改进蜂群优化各中心,然后以优化后的聚类中心采用K-means算法进行一次聚类,再以新聚类形成的中心更新蜂群,如此多次交替执行蜂群优化算法和K-means算法,直到满足条件结束。
蜜源与算法中的聚类中心相一致,而聚类簇的质量可以根据蜜源的适应度值来判断,适应度越大而目标函数值越小则聚类效果越好。因此本文中的蜜源适应度函数构造如下

式中J为K-means算法的聚类质量目标函数[11],蜂群优化K-means聚类算法的实现步骤为
步骤1,Leaders算法计算数据集初始聚类中心数k,蜂群优化算法中观察蜂与采蜜蜂设置为相同数目SN,算法迭代次数阈值为itmax,蜜源开采次数控制限值li;
步骤 2,随机生成蜜源 X={X1。X2。…。XSN} 及适应度 fiti,设置蜜源初始局部最优值lbesti=fiti,
步骤3,采蜜蜂根据式(1)搜索邻域新蜜源,并计算其适应度值,按照贪婪原则,选择最大适应度
步骤4,所有的邻域搜索完成后,蜜源的最终选择概率由式(3)计算得到。
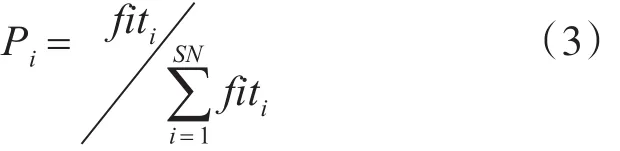
根据Pi值,观察蜂转换为采蜜蜂,并重复步骤3;
步骤5,如果对蜜源 Xi经过li次开采后,其适应度不变且非全局最优,则该蜂变换为侦察蜂,并根据式(1)和式(2)搜索生成新蜜源;
步骤6,对蜜源表示的聚类中心进行K-means聚类,并用新类更新蜂群,当更新次数大于预设阈值itmax则蜜源为最优聚类中心。
2.4 基于MPI接口的并行运算设计
网络技术和计算机硬件的高速发展使得并行计算成为实用高效的大规模数据处理方法[12],而K-means算法对大数据集中每个数据的操作是相同的,无需数据间的依赖[11],因此可以通过并行运算优化蜂群K-means算法,以使其满足大数据聚类对算法运行效率的要求。
MPI[13]是适于并行计算的消息传递接机,其提供多个支持并行运算函数调用。文中采用MPI接口模型搭建分布式存储模式,采用主从节点模式程序实现并行化,程序通过进程号ID来标识MPI进程并分配不同的程序块完成并行聚类,其流程图如图2所示。
图中主进程完成访问NFS数据集获取并分成子集,根据Leaders算法计算审计大数据的初始聚类中心数K,然后将子集及初始聚类中心传递给各从进程;从进程执行改进的蜂群优化K-means算法;从进程完成后对所有聚类合并,并采用式(4)计算归并所有聚类,并重新传送到各从进程。当从进程中全局新聚类中心相对于原聚类中心的移动距离满足算法收敛条件时,并行迭代聚类结束;最后将MPI资源释放。
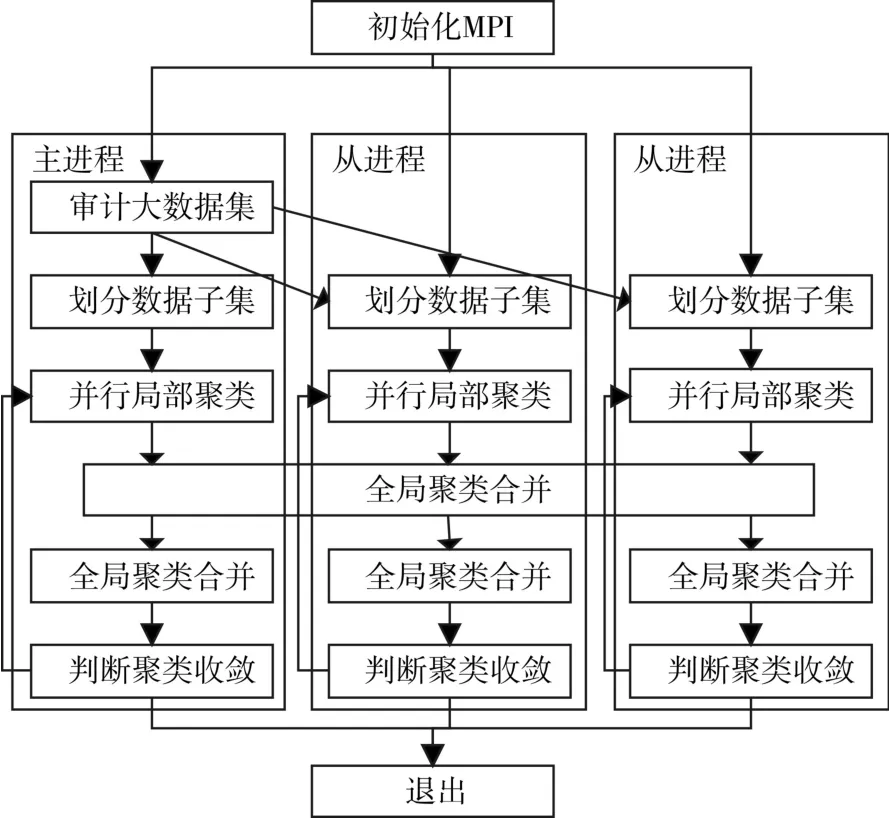
图2 MPI信息模型并行聚类算法
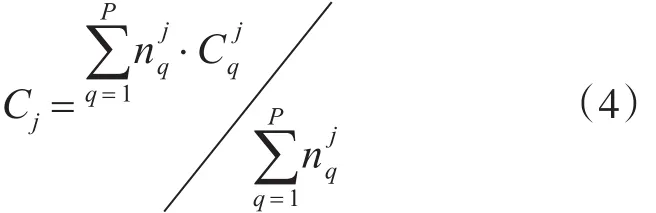
3 实验及验证
为验证文中算法的有效性,实验采用仿真集和真实数据进行测试,仿真数据由文献[14]中方法生成,而真实数据由收集自网上数据,并根据证监会等处罚公开信息进行算法结果验证。实验运行在Intel(R)Core(TM)i5 2540M CPU@2.60Hz,4GB的计算机上,采用VC++和MPICH2并行环境。
3.1 仿真实验结果
采用文献中方法随机生成D1、D2和D3三个数据集,实例数分别为10K、150K和5000K,数据实例为数值类型,数据集类型为同规圆、圆环与圆及嵌套圆环,如图3所示,测试数据集由NFS管理。
为验证算法的有效性,选用经典K-means算法和大数据集聚类Rough-DBSCAN算法[15]进行实验对比,评价指标定义为执行时间(t)、聚类准确率(F)和适应值(fit),实验结果如表1所示,表中实验结果为算法在三个数据集上运行50次聚类的相应平均值。

图3 人工数据集几何形状
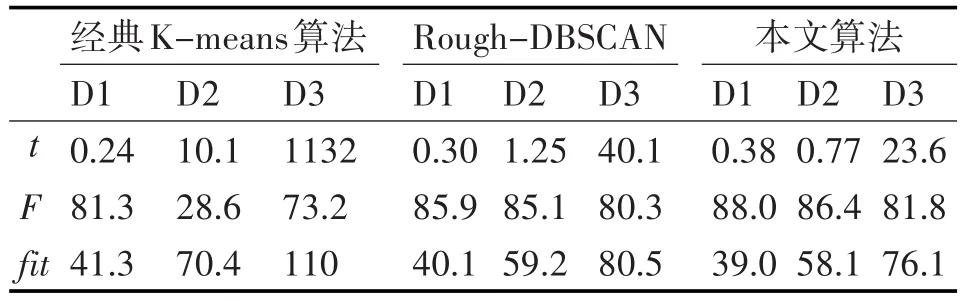
表1 三种方法实验结果对比
从表中经典算法与文中算法的实验对比结果看出,在三个数据集上,文中算法聚类性能要明显优于经典算法,尽管在数据集D1上,文中算法优势不显示,甚至性能有所下降,这主要是由于数据集D1数据量较少,数据子集之间通信反而点用更多的时间,但在大数据集D2和D3上,性能优势明显;与Rough-DBSCAN算法相比,在大数据聚类准确性和算法运行时间方面,文中算法比Rough-DBSCAN算法相当或性能有所提高,在运行时间方面提高明显,从而说明本文算法在大数据聚类的有效性。
3.2 实测数据实验结果
考虑到财务审计数据的保密性,文中利用经典的网络爬行技术收集2010~2017年2207家公司的公开财报数据,分析形成实验数据213620条,实验中算法迭代次数为10次。如图4所示为采用本文方法对数据聚类结果,实验分析了与企业利润相关的四个指标,可以看出数据被聚成5簇:第0簇指标均衡,其实例数占总数据实例数的比例为99.88%,而第1~4簇,其聚类实例数占总数据实例数仅在0.03%左右,且各实验参考的各个指标异常,可以认为是潜在疑点聚类。
根据实验结果,参考分析的公司中有28家的审计数据存在于疑点数据聚类中,表现异常,而通过证监会等机构网上可查的处罚情况,这些可疑公司中,大部分收到了相关单位的整改通知或处罚,从而检验了文中算法的有效性。
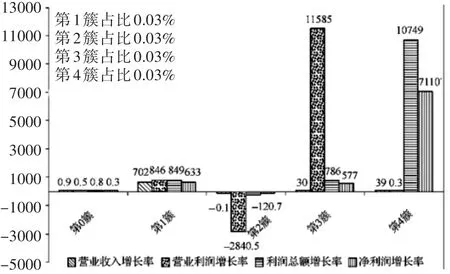
图4 聚类后各簇指标特点
另外,通过审计大数据聚类发现的审计可疑公司并不一定就有审计问题,仅说明疑点聚类中的实例具有更好的审计问题发生概率,其需结合审计经验进一步分析确认,但经过大数据聚类后,在进行审计证据发现时,一方面可以充分利用大数据的全覆盖优势,全局发现审计疑点,另一方向减少审计处理数据量,提高审计效率,因而对于大数据环境下审计证据的快速获取意义重大。
4 结语
针对电力企业数据量的海量增长导致计算机辅助审计的局限性,文中提出了基于并行蜂群优化K-means聚类电力大数据审计证据发现算法,算法在聚类中心初始设置、聚类中心优化精确以及并行运算提高算法效率方面对经典的K-means算法进行改进,以期提高聚类精确性的同时,提高算法的执行效率,以满足审计大数据的性能要求,仿真数据和真实网络公开数据对比实验验证了文中算法的有效性。
