网评信息的关键词计算方法
2018-08-29张世博魏战红
张世博 魏战红
(北京石油化工学院计算机系 北京 102600)
1 引言
移动互联网发展迅速,人们不但是信息的消费者,也是生产者,在电商或信息服务类平台的评论系统中产生了海量的评论文本,人们在消费前越来越倚重这些信息,公司方面也重视它们,以辅助其做决策判断。面对如此庞大的评论信息量,期望有自动化的方法来提取关键有用的信息,帮助人们提高主旨把握能力。本文介绍一种结合评论信息句子特征而设计的Sentence-LDA(Latent Dirichlet Al⁃location,潜在狄利克雷分布)模型,设计此模型的出发点是基于观察大量的网络消费评论句子特点,即句子句式较短,一句话中描述一个事项。在文中推理了模型主题分布的计算方法,优化选取代表主题的关键词,力争清晰反映评论信息的主题脉络。
2 主题模型及相关工作
网络评论属于非结构化的信息,要从大量评论文本集合中提取事先未知的,有潜在实用价值的知识,需要基于评论挖掘技术,这是分析海量评论信息的有效手段,在技术上处理方法有无监督方法、有监督方法和概率模型等。
无监督学习方法,是典型的基于频率的处理方法,通过对大量商品评论的观察,可以粗略地发现评价对象大都是名词或者名词短语。Hu[1]从某一领域的大量语料出发,先进行词性标记得到语料中的名词,再使用Apriori算法来发现评价对象。Popescu 和 Etzioni[2]通过进一步过滤名词短语使算法的准确率得到了提高,通过计算名词短语与所要抽取评价对象的分类的点间互信息(Point Mutual Information,PMI)来评价名词短语。此种方法虽然简单,但效果较好,其原因在于人们对某一实体进行评价时,其所用词汇是有限的,或者收敛的,那么经常被谈论的名词通常就是较好的评价对象。
监督学习方法,事先需要有标记数据进行训练,提取段落层级的含义,考虑句子的语义关系,依靠句法分析器的分析结果,推导合适的机器学习特征,在评论分析任务上取得了很好的效果。Riloff[3]提出一种包容层级(Subsumption hierarchy)结构来形式化词汇特征信息,提高了观点分类任务性能。Pang[4]提出基于度量标签的元算法来对评论进行评级,该算法可以保证类似的元素可以获得相似的评级标签。Yu等[5]使用单类SVM监督学习方法来提取评价对象。单类SVM的特点在于其训练所需的样本只用标注某一类即可。他们还对相似的评价对象进行了聚类,并根据出现的频率和对评论评分的贡献进行排序,取得较优质的评价对象。
概率模型方法,则代表着目前的主流方法。Blei[6]描述了概率主题模型,其主要创新点在于其描述了可普遍应用的文本语料处理框架模型,克服了过度依赖于有标记的训练集,用一个特定的词频分布来刻画主题,并认为一篇文章、一段话、一个句子是从一个概率模型中生成。每个主题是一个多项式分布,维度较少,参数简单,不容易产生过拟合现象。
针对特定的网络评论对象,通过扩展LDA主题模型,出现了如下几项代表性的工作:
1)MaxEnt-LDA(Maximum Entrpy LDA)。Zhao等[7]提出来为评价对象和评价词联合建模,并使用句法特征辅助分离两者,使用多项分布的指示变量来分辨评价对象、评价词和背景词(即评价对象和评价词以外的词),指示变量使用最大熵模型来训练其参数。Sauper等[8]则在此基础上通过加入HMM模型达到进一步区分评价对象、评价词和背景词的目的。
2)JST(Joint sentiment-topic model)[9]。 此模型框架结构比LDA多一层,在文档层与主题层之间加入了一个附加的情感层,形成词、文档、主题和情感四层结构,目的是在分析文档主题的同时,联合情感进行分析,获取评论的主题及其情感极性。
3)ASUM(Aspect and sentiment unification mod⁃el)。 由Jo Y[10]提出,和 JST一样由四层结构组成。二者的不同之处在于ASUM模型中,同一个句子中的词都来自于同一个语言模型,而JST模型中句子中的词可以来自不同的语言模型。
3 Sentence-LDA模型和主题词优化
3.1 Sentence-LDA模型
标准的LDA主题模型是基于Bag-of-words模型假设,即文档集合中的单词之间没有含义上的关联,但在网络评论中口语化短句较多,一个句子中往往有针对性的表达看法,突出表达某一种观点或主旨,即在词的概率分布上更倾向于同一个主题。基于此,提出普遍性假设,即假设一个句子中的词是由同一个主题概率分布生成的,这一点不同于标准LDA,在标准LDA中没有“句子”的概念。改进模型的示意图如图1所示,加粗的黑色框Sentence表示句子层级。生成过程如下:
1)对每一个主题,抽取一个单词分布fz:Dirichlet(β)
2)对文档集中的每一篇文档d
(1)抽取主题分布 qd:Dirichlet(α)
(2)对于文档d中的每一个句子
抽取一个主题z:Multinomial(qd)
生成单词w:Multinomial(fz)
从生成过程描述看出,“句子”特征应用在文档下一级的处理中。
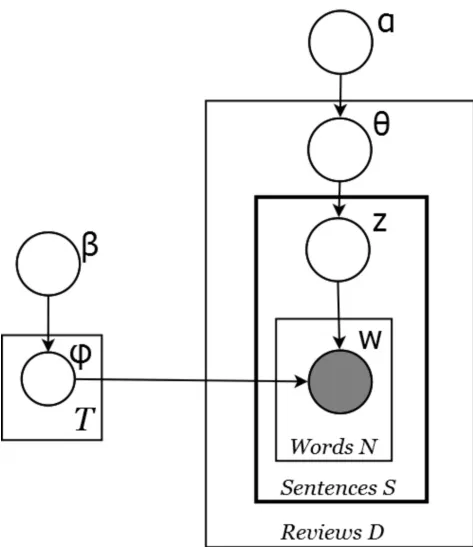
图1 Sentence-LDA模型示意图
在图1的模型中,一条句子内的所有单词w共享同一个主题分布Z。使用Gibbs抽样[11]估算潜在变量ϕ和 φ。第i个句子的主题由下述条件概率计算:
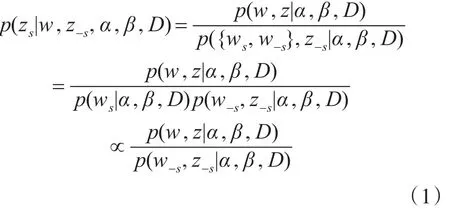
式(1)中的变量含义如表1所示。

表1 式中的变量含义
评论文档d的主题分布为
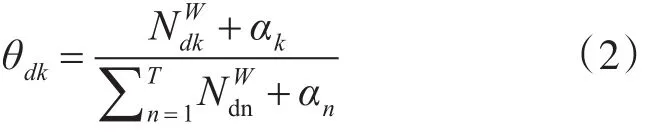
主题k中的单词w的概率分布为
采用Likelihood为判断主题数k的依据,通过最大化所有评论文档的log-likelihood之和,得到k值[12]。计算过程如下:
首先,计算每个评论文档的概率:
然后,计算数据集中文档d的条件概率,为了计算方便,对计算结果取log。
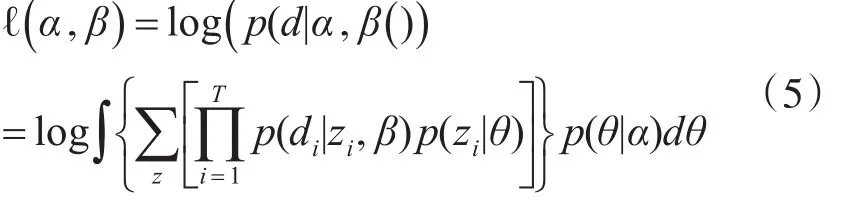
根据经验,设定主题数的一个范围,并在这个范围内计算各个主题数所对应的log-likelihood值,较高的log-likelihood值意味着较好的建模效果[13],在此范围内取得最高log-likelihood值的主题数设定为模型中的k值。
3.2 计算主题词相关性
主题模型可视化展示结果最常用的方法是在各个主题下依次列出最有可能的前n个代表性单词,但是并没有考虑主题之间关系,所以会在不同的主题上出现很多相同的主题词。为了形成更清晰的主题脉络,减少主题间的交叉,提出了一种计算主题词相关性的方法,对于出现在多个主题上的词汇进行因子惩罚,过程如下:
首先,利用在某一个主题k下的词频概率p(w|k),而不是考虑全局的词频 p(w),并使其被指数熵eHw
除,其中
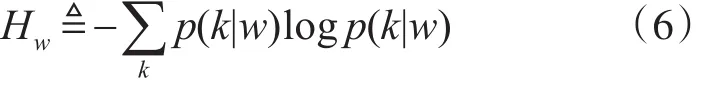
代表指定单词w下的主题分布的熵,表示了单词w横跨多个主题的程度。定义相关度为
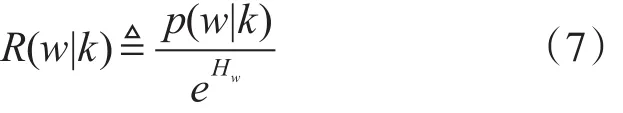
用指数熵去除主题k下的单词w的条件概率,得到相关性的进一步计算如下:
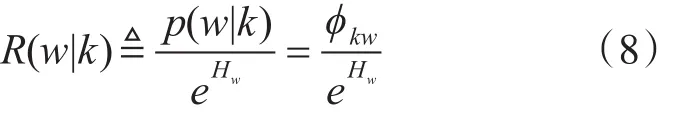
计算得到的熵:
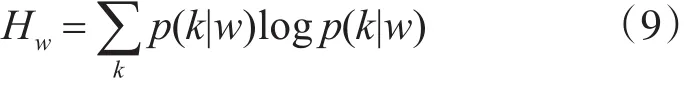
在概率 p(k|w)上应用贝叶斯规则
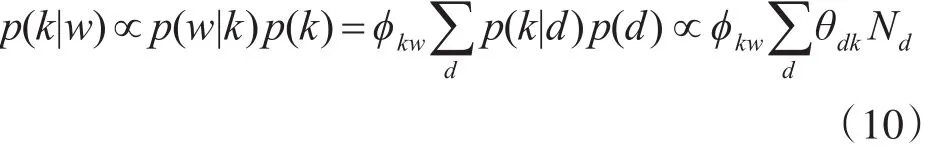
其中,Nd表示文档的长度。至此,得到计算主题词相关性的过程:
根据给出的单词w计算主题分布
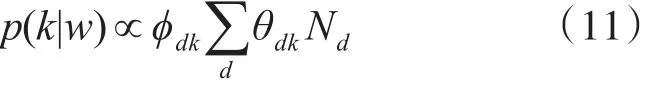
计算熵
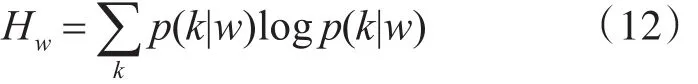
用指数熵除单词w在主题k下的条件概率
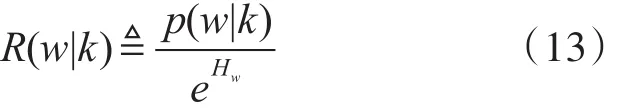
4 实验
4.1 实验数据
电影“肖申克的救赎”是一部广受欢迎的电影,在豆瓣网影评评分中,得到了9.6的高分,有近60万条评论。为了验证模型在提取主题线索上的有效性,抓取了此部电影在豆瓣网上的20000条短评论和3000条长评论,对数据进行预处理,删除仅仅有英文单词的评论和少于两个字的评论,保留了22476条评论信息。然后分词并根据哈工大信息检索实验室发布的停用词表去除停用词[14],最终,评论集共涵盖69841个词汇。
4.2 主题-文档分布结果
改进的Sentence-LDA模型以句子为单位,在实验中把符号“。”“!”“?”作为断句特征,其他符号则过滤掉。根据上述章节中提出的Sentence-LDA模型和单词相关性计算方法,对抓取的实验数据进行了主题计算。
当以Gibbs抽样计算LDA模型的参数时,参考Qiu[15]中介绍的经验值,设置α为 50/k,设置β为0.01。实验过程中迭代次数置为1,000,分别抽取每个主题的前10个单词,表2显示了实验结果,以概率降序排列。
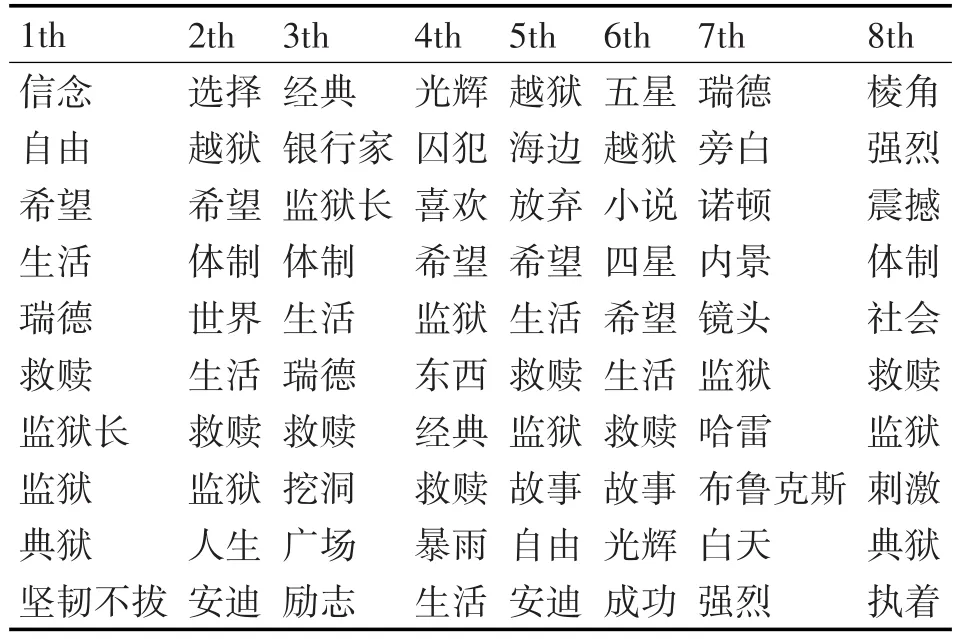
表2 Sentence-LDA模型下的前10个主题词
从表2中看出,第3个主题有“挖洞”、“广场”等词,此主题涵盖有越狱线索;第6个主题有“五星”、“四星”等词,主题表示了以观影者角度对影片给出的评价;第 7 个主题有“内景”、“旁白”、“镜头”等,主题阐述了电影拍摄的内容;第8个主题中有“强烈”、“震撼”、“刺激”等,表示了主题在反映情感倾向。上述分类结果显示了模型得出的结果有较强的主题倾向性。
为了分析模型的效果,针对同样的网评数据利用标准LDA计算了主题分布,提取了8个主题的前10个主题词,限于篇幅,此处不再一一列出。LDA模型和Sentence-LDA模型得到的主题脉络对比图如图2所示。

图2 两种模型LDA和Sentence-LDA的主题脉络图
从图2可以看,相对于LDA模型,基于Sen⁃tence-LDA的模型能够更清晰地计算出主题的脉络线索,在主题间有较少的重叠,跨主题单词相关性计算起到了一定作用。分析结果,在所提出的Sentence-LDA算法中,依据一句评论中的词共享同样的主题分布的假设,在迭代计算中,使得文档的主题分布更加趋近集中,更突出刻画主题。
在计算代表主题的前n个词时,主题内的词频计算根据上面小节的主题词相关性优化计算方法,对横跨多个主题的而且无意义的高频背景词来说,其eHw值较高,通过惩罚因子e-Hw降低了在主题内的相关性,而采用p(w|k)e-Hw得出的词排序高,则更具有主题的描述价值,所以计算结果显示主题间的关联上耦合度更小。
4.3 Sentence-LDA和LDA的比较
困惑度(Perplexity)是一种信息理论的测量方法,经常用于语言模型的评估[16],评价一个概率模型好坏,困惑度小,说明模型具有更好的推广能力;困惑度越大,说明模型的推广能力越差。在Blei的实验[6]中即采用Perplexity值作为评判标准。困惑度被定义为
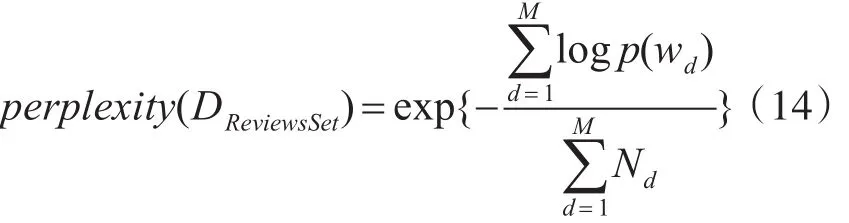
其中M为文档的数量,wd代表文档d中的单词,Nd表示文档d中的单词数量。每个词的概率p(w):

由于采用Bag-of-words模型,评论语料的Like⁃lihood为所有词概率的乘积,计算出Perplexity。两种模型下Perplexity和迭代次数之间的曲线关系如图3所示。
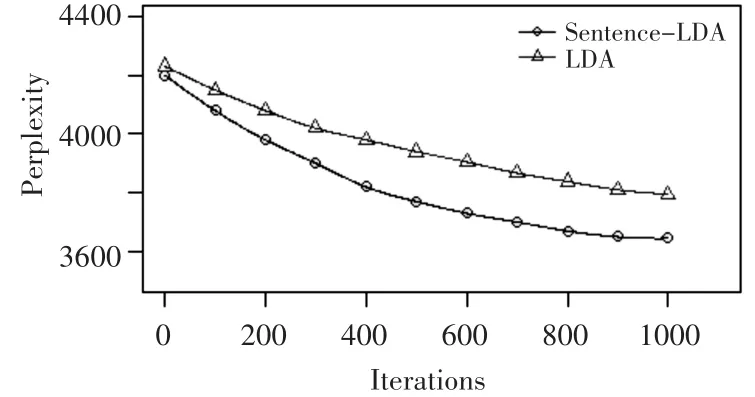
图3 根据困惑度值对比LDA模型和Sentence-LDA模型
△曲线表示LDA模型计算的Perplexity和迭代次数之间的关系,○曲线基于Sentence-LDA模型计算的关系。随着迭代次数的增多,○曲线下降的速度更快,基于Sentence-LDA模型的困惑度相对更低。
为了更好地量化表示跨主题的词相关性计算效果,基于Sentence-LDA和LDA两种模型的计算结果,对每个主题分别选取前50个主题词,针对跨2个主题、3个主题、独立出现在某一主题的情况分别进行汇总,结果如表3所示。
在Sentence-LDA模型下,共有341个独立的单词,而基于LDA模型计算的情况下,则只有303个单词。独立出现在一个主题中的单词比例,前者比后者高约7%,在横跨2或者3个主题的主题词比例上,均低2~4个百分点。这表示前者对于跨主题的关键词处理效果更好。
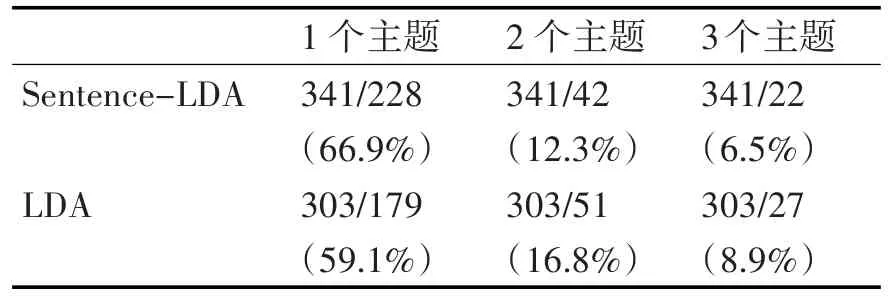
表3 前50个主题词横跨多主题的统计分析
5 结语
本文基于网络评论的句子普遍性特征,设计了基于句子的Sentence-LDA模型,利用惩罚因子调节算法调整横跨多个主题的关键词,降低了多主题间共用关键词的概率,以便清晰地显示不同主题的脉络。实验结果验证了算法的有效性,能够有效地提取评论数据的主题。
但因本算法假设某句子的单词由一个主题分布生成,容易造成严重的数据稀疏性,从而在计算上会耗时较多,计算过程还需要加强优化。
