基于AlphaGo算法的网络媒体不良词汇自动检测模式研究
2018-08-29陈秋瑞郑世珏陈星男杨岚江
陈秋瑞 郑世珏 陈 辉 陈星男 杨岚江
(华中师范大学 武汉 430079)
1 引言
互联网的出现与高度普及,极大地拓展了人们语言生活的空间,在为上亿网民创造庞大自由的舆论市场的同时,良莠不齐的语言内容却让这个空间变得不再和谐,一些粗俗不堪的词汇越来越多地出现在网络媒体用语当中,并以越来越高的频率出现在大众的视野中,这对整体社会风气产生了一定的负面影响,因此有必要对网络出版语言进行动态监测以判别其是否为不良文本。
2016年AlphaGo战胜世界围棋冠军李世石,其运用蒙特卡洛树搜索结合了评估网络和价值网络两种深度神经网络方法[1],为中文信息领域网络不良文本分类决策提供了新的理论指导。
当前国内外针对网络文本不良信息的发现技术主要有以下四种:基于因特网内容分级平台过滤、数据库过滤、关键词过滤和基于内容理解的过滤[2]。但是在实际应用中,这些方法都存在各自的缺陷,也有众多学者对该项技术进行改进与应用。刘梅彦[3]等设计了一种采用主题信息过滤和倾向性过滤两级过滤模式的不良文本信息过滤模型。王铁套[4]等将文本情感分析技术应用于网络舆情研究,针对网络舆情的话题评论,语义模式和词汇情感倾向相结合的方法判断话题评论的情感倾向。
针对当前研究方法的缺陷,本文结合AlphaGo算法设计思想,在对网络媒体中获取的文本进行分词的过程中,对分词结果中的不良词汇进行筛选,建立起网络媒体不良词汇自动检测模型,最终为网络语言和语言动向检测预警提供评估依据,以抑制不文明的网络语言习惯和不规范的网络语言行为,为我国网络语言的净化和传播正能量探索行之有效的道路。
2 相关技术
2.1 蒙特卡洛树搜索
蒙特卡洛树搜索(Monte Carlo Tree Search)是一种人工智能问题中做出最优决策的方法,一般是在组合博弈中的行动规划形式,它结合了随机模拟的一般性和树搜索的准确性。MCTS受到快速关注主要是由于计算机围棋程序的成功以及其潜在的在众多难题上的应用所致。超越博弈游戏本身,MCTS理论上可以被用在以{状态(state),行动(ac⁃tion)}为定义的问题和用模拟进行预测输出结果的任何领域[5]。
MCTS的基本算法非常简单:根据模拟的输出结果,按照节点构造搜索树,其过程可以分为下面的若干步骤[6]:
1)选择(Selection):从根节点R开始,递归选择最优的子节点知道达到叶子节点L;
2)扩展(Expansion):如果L不是一个终止节点(即不会导致博弈过程结束),那么就创建一个或者更多的子节点,选择其中一个C;
3)模拟(Simulation):从C开始运行一个模拟的输出,直到博弈游戏结束;
4)反向传播(Backpropagation):用模拟的结果输出更新当前行动序列。蒙特卡洛树搜索过程如图1所示。
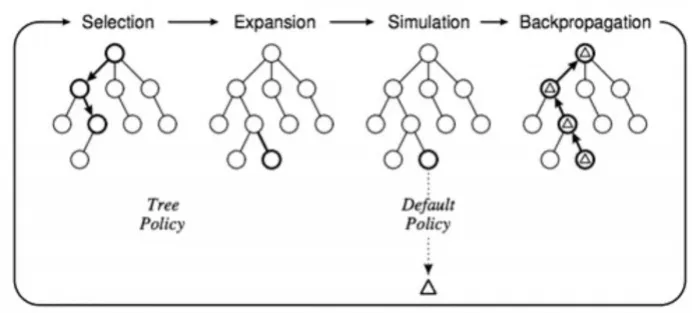
图1 蒙特卡洛树搜索过程
2.2 AlphaGo中的两个策略
阿尔法围棋是通过两个不同神经网络“大脑”合作来改进下棋。这些大脑是多层神经网络跟那些Google图片搜索引擎识别图片在结构上是相似的。它们从多层启发式二维过滤器开始,去处理围棋棋盘的定位,就像文本分类器进行分类一样。经过过滤,13个完全连接的神经网络层产生对它们看到的局面判断,这些层能够做分类和逻辑推理[7]。
阿尔法围棋的第一个神经网络大脑是监督学习的策略网络(Policy Network),在当前局面下判断下一步可以往哪里走[8]。它预测每一个合法下一步的最佳概率,那么概率最高的走法可以获得最大的期望收益;阿尔法围棋的第二个大脑是价值网络(Value Network),它的作用是学习评估整体盘面的优劣,预测每一个棋手赢棋的可能,通过整体局面判断来辅助落子选择器[9]。
3 检测模型的提出
AlphaGo中用到的诸多新技术,通过将策略网络、估值网络和蒙特卡洛树随机搜索这些技术连城一个完整的系统,使其实力有了实质性的飞跃。考虑到网络文本中不良信息的自动检测也是一个需要尽早实现智能决策的过程,因此,我们将上述思想应用到本文提出的模型中。
3.1 检测模型
本文根据AlphaGo设计思想,将网络媒体中不良词汇的自动检测模型分为以下过程。
第一步,“挑词阶段”。使用Python网络爬虫定向爬取微博、新闻网页、论坛评论等多种类别的网络出版语言内容,针对获取到的源码,过滤掉无关正文的部分,提取文本,作为测试用的文本语料库D={d1,d2,…,dn}[10]。对文本集进行预处理,结合用户词典和停用词词典,完成分词过程,得到分词后的文本集合Seged_Doc;对照不良词典BW_dic,自动检测Seged_Doc中是否包含不良信息[11]。
第二步,“判别阶段”。若没有,则为正常文本Normal_txt;若有,找出不良信息对应的网页文本,判断不良词汇是否超出阈值的文本,将其标记为待处理不良文本Bad_txt[12]。整体流程图如图2所示。
3.2 阈值设置
阈值的设置是十分重要的一项工作,阈值范围过大会使候选词集较为分散,不具代表性,阈值范围过小会导致候选词集过小,无法起到分类的效果[13]。在本文中,我们选择将不良词汇的统计信息超出阈值的文本判为不良文本,因此需要设置合理的阈值规则,阈值根据待发现新词语料的大小变化而变化,呈正相关关系,本文选用arctan函数来选择相应的阈值[14~15]。
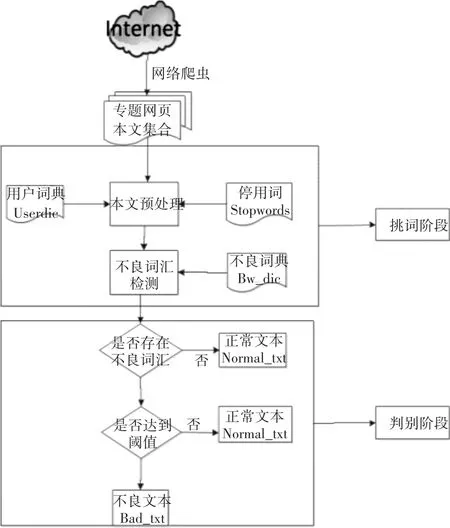
图2 不良词汇自动检测模型流程图

其中,|D|为语料库词语总数量,使用S型函数arctan防止阈值随着语料库的大小线性增长,经验表明,β取50,α取10-7。
4 仿真测试
4.1 仿真实验
本文采用Python爬虫技术,爬取的语料,主要基于国家语委语言资源网[16]提供的网络媒体语料,该语料库目前汇集了国家语委19家科研机构的48种语言资源,以及来自其他高校、研究所、社会机构的开放的各类语言资源,包括网络新闻、博客、微博、论坛四类语料,各类语料文本已近1.48亿篇次,总字符数达1500亿,其中汉字总数为1300亿。
网络爬虫作为搜索引擎关键技术之一,通过分析网页中的链接地址来寻找下载新的网页。一般从网站的某一个页面通常是首页开始,读取网页的内容,找到在网页中的其它链接地址,将其存放在一个堆栈当中,每次取出一个按照前面相同的方法抓取其中的链接,继续放入堆栈中,这样一直循环下去,直到把这个网站所有的网页都抓取完为止[17]。
实验平台为Win7 64位操作系统,搭建开发环境Scrapy1.0与Python3.6。为测试本文提出的检测模型的效果,本次实验共选取600份网页语料,其中500份为训练库,100份为测试库。共进行了10次实验,每次于训练库和测试库中各取十分之一作为实验数据。本文实验所采用的传统方法为关键词匹配法。
对获取到的网页进行分词的实施,分词过程结束之后,对照停用词表,除去其中的停用词。预处理过程如图3所示。

图3 文本预处理过程
经过预处理的文本根据模型流程进行自动检测,得到的不良文本检出率结果如表1及图4所示。
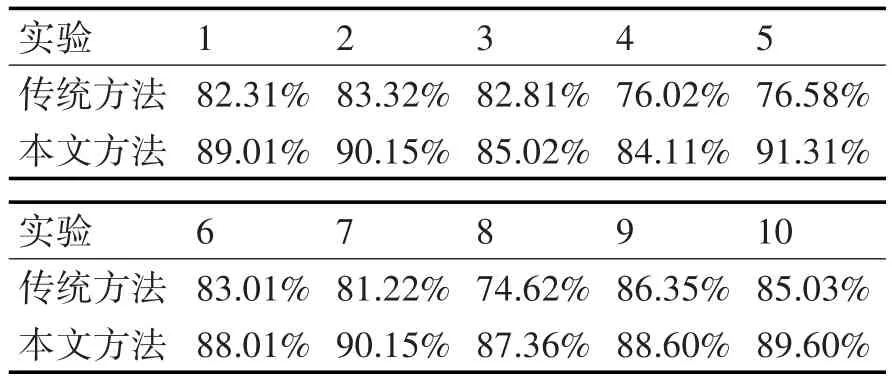
表1 本文方法与传统方法准确率对比
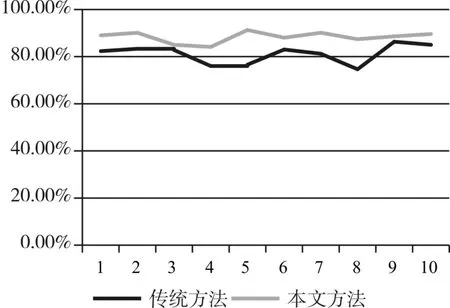
图4 本文方法与传统方法准确率对比
4.2 结果分析
传统方法平均准确率为81.13%,而采用本文提出的方法进行的测试实验平均准确率达到了88.33%,说明本文方法具有一定的改进效果,在网络文本不良词汇的自动检测方面有一定的优势。
总的来说,本文的基于AlphaGo算法思想的检测模型要优于传统的不良文本检测模型。
考虑到网络上存在的语料之多,本文模型需要更多的数据进行测试,下一步将扩大语料规模,并在此基础上进一步提高算法的运算效率。
5 结语
本文以检测文本中的不良词汇为目的,提出了一种基于AlphaGo算法设计思想的自动检测模型,用于判别网络出版语言是否为不良文本。从测试结果来看,相比于基于关键词的匹配的方法,本文模型采用两个阶段相结合的方法,可以有效地提高文本中不良信息自动检测的准确率。
