面向低资源神经机器翻译的回译方法
2021-06-22张文博张新路杨雅婷
张文博,张新路,杨雅婷,董 瑞,李 晓*
(1.中国科学院新疆理化技术研究所,新疆 乌鲁木齐 830011;2.中国科学院大学计算机科学与技术学院,北京 100049;3.新疆民族语音语言信息处理实验室,新疆 乌鲁木齐 830011)
端到端的神经机器翻译方法已经成为目前主流的机器翻译方法[1-3].在高资源语言对之间的翻译任务上,神经机器翻译已经取得令人满意的效果;但对大多数领域或语言对来说,足够数量的高质量平行语料往往难以获取.相对于平行语料而言,单语数据广泛地存在于互联网上,往往更容易获取,因此利用单语数据提高低资源神经机器翻译质量成为一种常用的手段[4-8].
下一个目标语言单词可通过平行语料训练得到的神经机器翻译模型,根据源语言句子和之前的目标语言单词预测得到;而语言模型可以根据之前的目标语言单词给出下一个目标语言单词的概率分布,并且其只需要单语数据训练得到.因此,通过语言模型来利用大规模的单语数据是一个自然的方式.Gulcehre等[4]提出通过浅融合和深融合的方式将语言模型整合到神经机器翻译模型中,在预测下一个目标语言单词时,该模型可以综合语言模型和翻译模型的打分;Skorokhodov等[5]利用大量的源语言和目标语言单语数据分别训练源语言和目标语言的语言模型,然后利用语言模型初始化翻译模型的参数,在预测下一个目标语言单词时,合并目标语言模型的打分.虽然语言模型可以提高低资源神经机器翻译的质量,但是通常需要对翻译模型进行大量的修改来整合语言模型和翻译模型,这使神经机器翻译模型变得更加复杂.Sennrich等[7]提出一个基于回译的数据增强方法.该方法通过一个反向的翻译模型将目标语言单语数据翻译成源语言数据,并和原始目标语言单语数据联合形成伪平行语料;合并伪平行语料和真实的平行语料可以提升语料规模,从而提升翻译效果.Hoang等[8]提出通过迭代回译,同时利用源语言单语数据和目标语言单语数据进一步提升翻译效果.
基于回译的方法可以不用修改神经机器翻译模型就能有效地利用单语数据;但是当平行语料规模较小时,通过回译生成的伪平行语料质量往往较差,而且大规模的伪数据和较小规模的平行语料混合使得真实的平行语料难以被有效地利用.针对这些问题,本文提出一种针对较小规模平行语料下的解决方案.该方法通过调节字节对编码(BPE)[9]融合数以及失活率(dropout)[10]参数来训练一个尽可能好的低资源神经机器翻译系统,从而提升伪平行语料的质量;将汉语单语按照词覆盖率划分成不同领域相似的单语数据,从而通过回译利用汉语单语数据生成伪平行语料和高领域相似的伪平行语料;通过分段训练分别利用伪平行语料和领域相似的伪平行语料进行预训练和微调;使用模型平均和模型集成提升系统的鲁棒性,进一步提升翻译质量.
1 数据及预处理
本文使用第16届全国机器翻译大会(CCMT 2020)提供的维吾尔语-汉语(维汉)、蒙古语-汉语(蒙汉)平行语料以及汉语单语语料搭建翻译系统,并进行对比实验.其中维汉平行语料是新闻领域数据,蒙汉平行语料是日常用语数据,汉语单语语料是新闻领域数据.
1.1 预处理
数据预处理阶段,过滤平行语料中重复的句对,将语料中的字母和数字的全角形式转换成半角形式.在维汉翻译和蒙汉翻译两个任务中,分别使用moses脚本(https:∥github.com/moses-smt/mosesdecoder)处理维吾尔语和蒙古语,使用Jieba分词工具(https:∥github.com/fxsjy/jieba)对汉语分词.
1.2 子词化处理
BPE[9]是目前缓解机器翻译任务中未登录词问题[11]的一种普遍方法.本文使用fastBPE工具(https:∥github.com/glample/fastBPE)处理维汉翻译和蒙汉翻译这两个任务,融合数分别为1 000和5 000.并联合源语言和目标语言进行BPE切分处理,而不是分别处理源语言和目标语言.相应地,神经机器翻译模型中源语言和目标语言也共享同一个嵌入(embedding)矩阵.同时,本文都只使用平行语料作为BPE的词频统计语料,因此对汉语单语语料,分别采用维汉平行语料和蒙汉平行语料学习得到的模型进行汉语单语切分.
2 神经机器翻译模型的训练方法
回译[7]是一种能够有效地利用目标端单语数据的数据增强方法.针对回译的研究有很多,如Graça等[12]和Edunov等[13]通过研究生成伪平行语料的方式对回译进行改进,Hoang等[8]提出同时利用源语言单语数据和目标语言单语数据的回译方法.基于回译的方法中一般都使用和平行语料数量相差不大的单语数据,本文也通过回译利用汉语单语数据提升维汉和蒙汉翻译质量;但为了能在低资源情况下利用尽可能多的汉语单语数据,本文采用首先在大规模伪平行语料上预训练,再在高领域相似的伪平行语料上微调这样分段式的训练方法来训练翻译模型.除此之外,本文在生成伪平行语料时,还采用随机采样(sampling)[13]和过滤质量较差的伪平行句对来提升翻译质量.回译所用模型为Transformer_big.
2.1 伪平行语料生成
首先训练一个目标端到源端的翻译模型,利用翻译模型将筛选到的目标端单语语料翻译成源端单语语料,翻译得到的源端单语语料和原来的目标端单语语料联合构成伪平行语料.在解码过程中,为了增強数据多样性,本文设集束大小(beam size)为1,并使用随机采样[13]的方式生成源端数据.迭代回译[8]可以同时利用源端单数数据和目标端单语数据获得更好的效果,但是本次评测只提供汉语单语数据,因此本文中的伪平行语料由在平行语料训练得到的反向翻译模型和汉语单语数据一次生成.为了过滤噪声数据,本文删除伪平行语料中长度(BPE之后)小于5或大于250以及长度比大于2的句对.
2.2 高领域相似伪平行语料
与Zhang等[14]的研究类似,本文根据单语句子中所有词在平行语料词典中出现的比例挑选和平行语料领域接近的单语数据.为了降低平行语料中低频词的干扰,在统计完平行语料的词典(BPE之前)之后,删除词典中频率小于3的词.对维汉翻译和蒙汉翻译,本文均挑选比例大于0.9的汉语单语句子用来生成伪平行语料.同时本文还从比例等于1的汉语单语数据中额外提取一份作为高领域相似的单语数据,并通过回译生成高领域相似伪平行语料,即高领域相似伪平行语料的汉语部分句子中所有词都在平行语料词典中出现过.生成的伪平行语料和高领域相似伪平行语料主要用于下面的分段式训练方法.
2.3 分段式训练方法
回译常见的做法是将伪平行语料和平行语料合并作为新的平行语料,用来直接训练翻译模型或者微调[7].由于单语语料的规模要远大于平行语料,所以直接合并训练并不能有效地利用平行语料.过采样虽然可以使平行语料和伪平行语料保持接近的比例,但是对平行语料采样次数过多也容易使得模型对平行语料过拟合.因此本文使用两段式的训练方法:第一阶段只使用所有伪平行语料训练翻译模型;第二阶段将高领域相似的伪平行语料(由经过筛选得到的高领域相似的汉语单语生成)和平行语料结合,继续训练翻译模型,并且在训练过程中使用过采样使伪平行语料和平行语料保持1∶1的比例.对于维汉翻译任务,本文在第二阶段训练完成之后,进一步使用平行语料微调.
3 模型平均和集成
模型平均和集成都可以提升模型的鲁棒性,有助于进一步提升翻译质量.前者将同一个模型在训练阶段不同时刻保存的参数平均作为最后的模型参数;后者使用多个模型同时解码,在生成候选词概率表时,将多个模型生成的概率词表平均作为用于生成下一个词的概率表.本文对翻译模型进行多次训练和微调,在每个训练阶段之后,根据在验证集上的表现,选择平均最后5或10个模型或最佳模型作为该阶段的输出模型.对维汉和蒙汉本文分别使用3个不同的随机种子训练3个模型(这3个模型中的每个模型都是平均之后的模型或best模型),最后集成这3个模型对测试集进行解码.
4 实 验
4.1 参数设置
使用开源工具fairseq(https:∥github.com/pytorch/fairseq)在两块32 G英伟达V100显卡上进行机器翻译模型的训练.本文采用transformer_big模型[3]作为翻译模型,并且使用GELU激活函数.在训练中,使用fairseq的update-freq将每个批次(batch)的最大标记(token)设置为64 000.为了节省时间,在CCMT 2020评测时使用Transformer_base测试dropout和BPE参数,最终将维汉翻译任务的dropout(d1)设置为0.3,activation-dropout(d2)设置为0.3,attention-dropout(d3)设置为0.2,BPE融合数设为1 000;蒙汉翻译任务的d1设置为0.3,d2和d3都设置为0,BPE融合数设为5 000.所有模型都采用Adam优化器,在训练过程中,维汉第一阶段使用0.000 5的学习率,蒙汉第一阶段使用0.000 7的学习率,warmup设置为4 000;第二阶段,warmup都设置为1 000,学习率为0.000 3.对维汉翻译,最后使用固定学习率0.000 1在平行语料进一步微调.本文所有系统在解码时,beam size均为12.
4.2 评测结果
对维汉翻译和蒙汉翻译,都分别提交了3个结果,其中主系统primary-a为通过3个随机种子利用汉语单语料分段式训练得到的模型进行集成的结果.对比系统contrast-c为使用单语语料但没有进行集成的单个模型的结果,contrast-b为只使用平行语料训练得到的单个模型的结果.表1为这3个系统在CCMT 2020评测结果中的双语互译评估(BLEU5-SBP)分数.
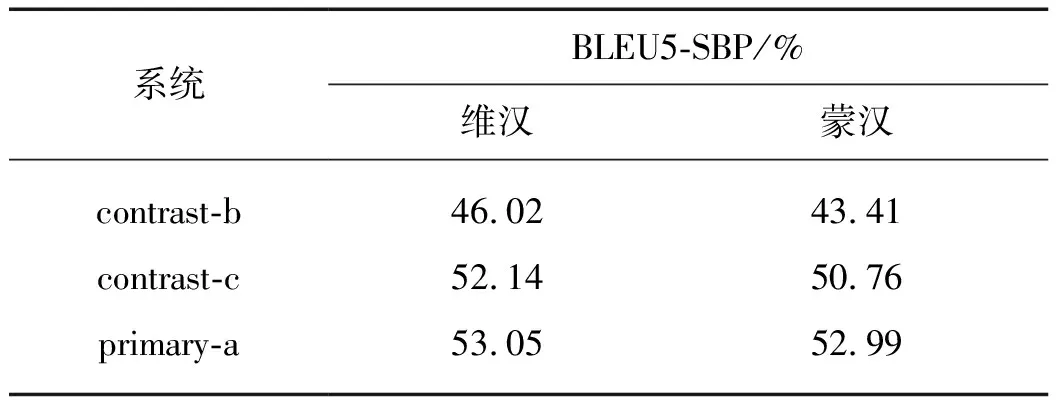
表1 不同系统在测试集的测试结果Tab.1 Test results of different systems on test sets
由表1可以看出使用汉语单语语料可以显著提升翻译质量,在维汉翻译和蒙汉翻译上分别提升了6.12 和7.35个百分点.最后使用模型集成可以进一步分别提升约0.91和2.23个百分点.
4.3 重要参数对比
低资源神经机器翻译往往具有容易过拟合以及存在较多集外词[11]的问题,因此本文使用transformer_big模型在平行语料上,通过对dropout[10,15]和BPE[9]融合数这两个参数的调节来缓解这两个问题.考虑到Transformer_big与Transformer_base的最佳参数可能不一样,故对Transformer_big的dropout和BPE参数进行验证.表2是在维汉翻译和蒙汉翻译上使用30 000融合数时不同dropout的测试结果.表3是dropout为表2中的最佳取值时,在维汉翻译和蒙汉翻译任务中,不同BPE融合数的测试结果.
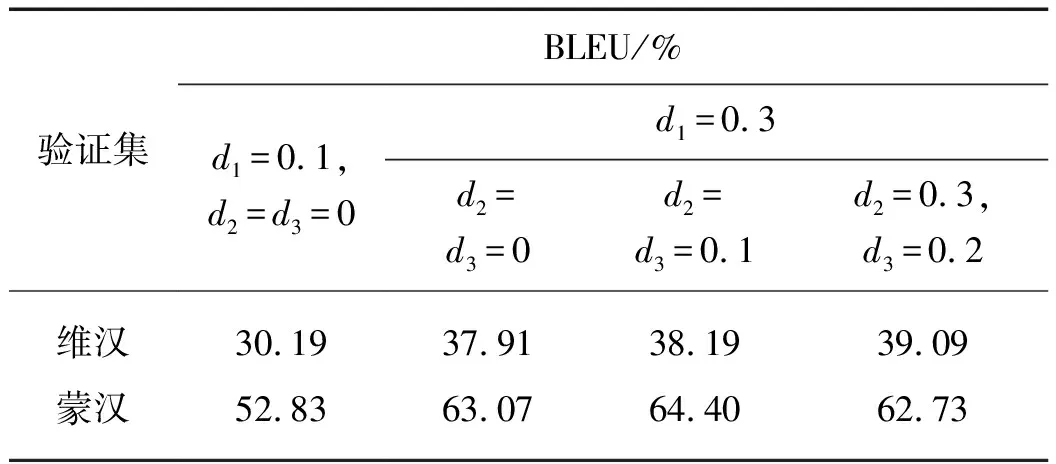
表2 不同dropout参数在验证集的测试结果Tab.2 Test results of different dropoutparameters on validation sets

表3 不同BPE融合数参数在验证集的测试结果Tab.3 Test results of different BPEparameters on validation sets
从表2和3中可以看出,Transformer_big与Transformer_base的最佳dropout参数并不同,但最佳BPE融合数一致.该结果还表明dropout和BPE融合数这两个超参数对维汉翻译和蒙汉翻译在低资源神经机器翻译中均有不同程度的影响.对低资源神经机器翻译,合适的dropout可以显著提升翻译质量,合适的融合数也有利于提高翻译质量.表明通过调整dropout和BPE参数可以进一步提高系统的翻译性能.
4.4 其他实验结果与分析
为了验证分段式训练方法的有效性,本文使用multi-bleu.perl(https:∥github.com/moses-smt/mosesdecoder/scripts/generic/multi-bleu.perl)在验证集上计算不同系统基于字的BLEU[16]值.表4展现本文在本次评测中筛选之后得到的数据规模.表5对比了不同训练方式在验证集上的实验结果.

表4 不同类型语料的规模Tab.4 The scales of different types of corpus

表5 不同训练策略在验证集的结果Tab.5 The results of different training strategies on validation sets
由表5可以看出语料规模对翻译结果有着重要的影响:只使用大量的伪平行语料就可以获得比只使用平行语料更好的性能;在伪平行语料的基础上加上平行语料虽然可以获得进一步的提升,但是提升幅度并不大;而分段式地训练可以在只使用伪平行语料的基础上获得更显著的提升.
5 结 论
本文通过调节dropout和BPE融合数两个参数,缓解了低资源神经机器翻译易过拟合以及存在较多低频词和集外词的问题;并借助回译,通过分段式训练同时有效地利用单语语料和平行语料资源,较大地提升了低资源情况下维汉翻译和蒙汉翻译的质量.
