基于遗传算法改进的一阶滞后滤波和长短期记忆网络的蓝藻水华预测方法
2018-08-27于家斌尚方方王小艺许继平张慧妍
于家斌,尚方方,王小艺,许继平,王 立,张慧妍,郑 蕾
(1.北京工商大学 计算机与信息工程学院,北京 100048; 2.北京师范大学 水科学研究院,北京 100875)(*通信作者电子邮箱wangxy@btbu.edu.cn)
0 引言
随着我国社会经济迅速发展,河流湖泊污染问题日益加剧,由于水体富营养化而造成的藻类水华灾害成为水环境污染的突出问题[1]。研究藻类水华预测方法,提前对水华爆发的可能性进行预测,有助于减少水华带来的生态危害和健康风险。
目前藻类水华预测方法主要分为两大类。第一类是以生态动力学为理论基础,通过研究藻类水华的形成机理,对水华的生态变化进行模拟及预测。孔繁翔等[2]认为蓝藻水华的爆发是一个逐渐形成的过程,提出了蓝藻水华成因的四阶段理论假设,即休眠、复苏、生物量增加和上浮聚集四个阶段,每个阶段中藻类的生理特性及主导环境影响因子有所不同。王长友等[3]根据蓝藻水华形成的“四阶段理论”搭建三维水动力模型与水生生态动力学模型相结合的耦合模型,对蓝藻水华进行短期预测;但是由于水体是一个开放性的复杂系统,藻类水华出现的诱导因素很多,具有突发性、复杂性和时变性等特点[4-5]。以上方法通常结构复杂,涉及的参数众多,应用非常困难。第二类方法是利用数据挖掘技术分析藻类水华指标与环境因子的关系,建立水华预测模型,如聚类模型、回归模型和神经网络模型等。常淳等[6]基于逐步聚类分析法建立了叶绿素a含量的聚类分析模型,并对其进行预测分析;但这种方法适用于小样本数据,而且容易陷入局部最优,模型易受异常数据的干扰。王小艺等[7]提出一种基于模糊Petri网的复杂网络动态模型,采用粒子群算法优化网络权重,最终实现对蓝藻水华预测。郑剑锋等[5]建立了基于数学统计分析的径向基函数(Radial Basis Function, RBF)神经网络,实现对水华发生的概率计算及预警等级划分。这类智能建模方法所需模型参数少,计算过程快速简便,成为解决现实复杂系统问题的主要方法,但是没有充分考虑数据随时间变化的特点。
基于前期研究可知,蓝藻水华这一动态过程前期的时间序列状态对其演化具有重要影响。循环神经网络(Recurrent Neural Network, RNN)作为深度学习方法的一种,擅长处理连续的时间序列数据,RNN的改进结构长短期记忆(Long Short-Term Memory,LSTM)循环神经网络改善了RNN梯度消失、梯度爆炸等问题,在不同时间序列研究领域已经取得了不少成功应用的经验。语音识别及机器翻译方面的尝试成功,表明LSTM在此领域的实用化效果。文献[8]基于LSTM循环神经网络对交通流速预测的研究取得满意效果。目前国内将LSTM循环神经网络用于蓝藻水华预测研究还未发现公开的报道。本文尝试使用LSTM循环神经网络,从实测的时间序列数据出发,用以建立蓝藻水华的时间演化模型,预期探索其不同运行阶段的演化特征。
由于蓝藻水华爆发是由渐变到突变的状态阶跃过程,具有非连续、阶跃式的特征,本文以叶绿素a浓度值为蓝藻水华爆发程度表征指标,通过遗传算法改进的动态一阶滞后滤波(Genetic algorithm-First order lag filter, GF)优化算法改善了叶绿素a浓度数据的平滑滤波处理效果,解决了非连续、阶跃式数据的预测问题,提高了模型预测精度,并通过LSTM循环神经网络构建基于GF-LSTM网络的蓝藻水华预测模型,更为准确地预测蓝藻水华的发生,并以太湖的水质监测为样本验证模型的有效性。
1 一阶滞后滤波算法与LSTM循环神经网络
在数据预处理阶段对一阶滞后滤波(First Order Lag Filter, FOLF)算法进行改进,由遗传算法(Genetic Algorithm, GA)优化FOLF参数,提出动态一阶滞后滤波优化算法——GA-FOLF(GF)对数据进行平滑滤波处理,并结合LSTM循环神经网络构建GF-LSTM网络模型,对蓝藻水华的发生进行预测。
1.1 一阶滞后滤波算法的改进
在数据预处理阶段,由于采集到的时间序列数据经常受到各种因素的干扰而呈现一定的波动性,并且容易产生噪点。如以表征蓝藻水华发生的叶绿素a浓度数据,因为采集时间间隔长短,以及水体中营养盐浓度变化、降雨等多种因素的影响而复杂多变,使得模型在模拟时易造成系统误差,影响模型预测的精确度;因此通过数据平滑滤波处理,改善时间序列的光滑度,保证模型输入数据的有效性,能够极大提高系统的精度,在此采用FOLF算法对数据进行平滑滤波处理。
1.1.1 FOLF算法改进
FOLF是一种动态数字滤波算法,可以通过改变滤波系数得到不同的滤波属性[9]。该算法原始公式如下:
st=αxt+(1-α)st-1
(1)
其中:st为本次滤波结果;xt为本次采样值;st-1为上次滤波结果;α为滤波系数,一般取值为0<α<1。
考虑FOLF算法具有相位滞后、灵敏度低的缺点,对数据进行滤波处理时,滞后现象比较明显,故对该算法进行改进,添加误差修正项,改进后的滤波公式为:
(2)
(3)
其中:β为误差修正系数,满足0<β<1。添加修正项后,每批取N个采样数据,根据每个数据的误差进行数据修正,经过改进后的FOLF处理的数据,平滑度更好,也有效地减轻了因数据滤波造成的滞后性。
1.1.2 参数优化
由于蓝藻水华变化过程具有突发性和复杂性,因此选择固定的滤波系数并不能很好地对叶绿素a浓度值进行平滑处理。故对FOLF算法进一步优化,对每隔N个采样数据,采用GA优化方法对系数α和β进行动态参数选定,在数据预处理阶段提出一种GA-FOLF(GF)算法。GF算法对叶绿素a浓度值的平滑滤波处理过程如图1所示,将取出的数据,经过GA优化的FOLF算法作滤波处理,再更新样本数据。
1.2 GF-LSTM网络模型
1.2.1 循环神经网络
深度学习作为深层次的神经网络,是机器学习中的一个新的研究领域[10]。RNN是一种前馈神经网络,擅长处理可变长度的时间序列的数据输入,其最大特点是网络具有自连接的隐层,即当前时刻隐层的状态依靠前一时刻隐层的状态进行更新,能够有效地解决长期依赖问题[11-12]。
图2为循环神经网络的结构,包含输入层x、隐藏层h和输出层o,每层有若干个神经元,依赖信息通过隐藏层传递。其中,图2(a)是RNN的基本结构,一条单向的信息流由输入层到隐藏层,再由隐藏层到输出层,构成基本的神经网络结构,另一条信息流由隐藏层到隐藏层构成闭环,形成自连接的隐层。为了更加清楚地说明RNN的结构,将图2(a)中RNN的基本结构展开,如图2(b)所示,当前t时刻的隐藏层ht的输入除了包含输入层信息xt以外,还包含上一时刻t-1时的信息ht-1,而ht也会对下一时刻t+1时的隐藏层产生影响。RNN隐藏层的结构特点使得循环神经网络能够对前面的信息进行“记忆”并作用于此刻的输出,因此能够有效地解决长期依赖问题。
1.2.2 GF-LSTM网络原理
由于RNN在实际训练过程中,常常发生“梯度消失”或“梯度爆炸”问题[13]。为解决这个问题,很多研究学者对RNN网络结构进行了改进,其中效果较好的改进模型是LSTM网络模型[14]。在此结合LSTM网络模型,采用改进的GF算法对数据进行平滑滤波处理,构成GF-LSTM网络模型预测蓝藻水华的形成过程。
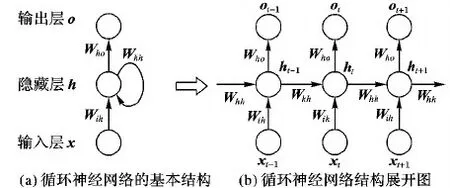
图2 循环神经网络的结构
LSTM与RNN的原理在本质上是相似的,只是对RNN的结构进行了优化[15]。其不同之处是LSTM网络模型在隐藏层中引入被称为“记忆细胞”的结构,使用不同的函数去计算隐藏层的状态。在“记忆细胞”中,使用三个门限层控制可以通过门的信息量,对具有长期序列依赖问题的数据非常有效。图3为典型的LSTM中“记忆细胞”的结构。
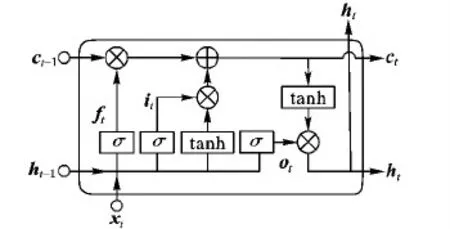
图3 LSTM记忆细胞的结构
图3中:it为输入门限层(input gate);ft为遗忘门限层(forget gate);ot为输出门限层(output gate);ct为记忆细胞在t时刻的状态;xt为输入层的输入向量;ht为隐藏层的输出向量[16]。
it=σ(Wxixt+Whiht-1+bi)
(4)
ft=σ(Wxfxt+Whfht-1+bf)
(5)
ot=σ(Wxoxt+Whoht-1+bo)
(6)
ct=ft⊙ct-1+it⊙ tanh (Wxcxt+Whcht-1+bc)
(7)
ht=ot⊙ tanh (ct)
(8)
其中:⊙是指矩阵逐元素点乘;bγ是各层输出的偏差向量,例如bi是输入门限层的偏差向量,bf是遗忘门限层的偏差向量;σ(x)是sigmoid函数;Wαβ是对应层的权重矩阵,例如Wxf是输入层到遗忘门限层的权重矩阵,Whi是隐藏层到输入门限层的权重矩阵,Who是隐藏层到输出门限层的权重矩阵;ct用来更新细胞状态。由式(7)可知,遗忘门ft控制有多少上一时刻的记忆细胞中的信息ct-1可以传输到当前时刻的记忆细胞中;输入门it控制有多少信息可以流入记忆细胞ct中;而输出门ot控制有多少当前时刻的记忆细胞ct中的信息可以流入当前隐藏层ht中[17]。
2 基于GF-LSTM的蓝藻水华预测模型的构建
基于GF-LSTM网络的蓝藻水华预测模型流程如图4所示,主要包含数据预处理和GF-LSTM模型建立两部分。图4中:RMSE(Root Mean Square Error)为均方根误差,MRE(Mean Relative Error)为平均相对误差。
2.1 数据预处理
步骤1 GF平滑滤波。以叶绿素a浓度采样数据为样本,对样本数据按照图1流程,每隔N=30个数据,进行平滑滤波处理。
步骤2 极差标准化处理。对平滑滤波处理后的叶绿素a浓度按照式(9)进行极差标准化处理,使样本数据处于[0,1]区间:
Xnor=(X-Xmin)/(Xmax-Xmin)
(9)
X=Xnor(Xmax-Xmin)+Xmin
(10)
其中:Xnor和X分别为样本处理前、后的数据;Xmax与Xmin表示样本中数据的最大值和最小值。
步骤3 样本划分。用以上方法处理之后的数据按照简单交叉验证法划分为训练集与测试集,前85%组数据作为训练集,余下的15%组数据作为测试集,输入到网络模型中进行训练。
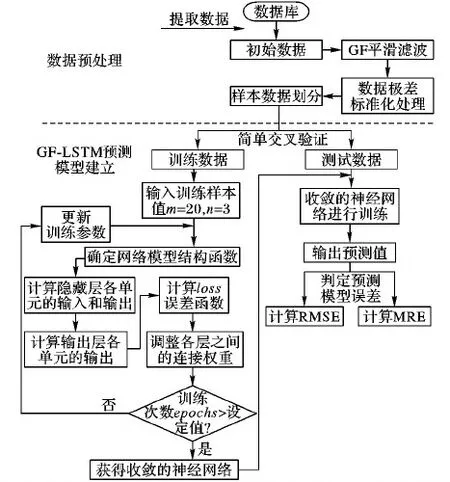
图4 基于GF-LSTM的蓝藻水华预测模型流程
2.2 GF-LSTM预测模型的建立
本文实验硬件设施为Windows 7操作系统,8 GB内存,基于Python3.5编程,使用Keras深度学习框架,搭建LSTM循环神经网络模型。在网络结构设计中,通过多次实验调试,最终确定LSTM网络结构由1层输入层、2层隐藏层和1层输出层组成。根据GF平滑滤波处理后的叶绿素a浓度样本数据,预测模型框架如图5所示。
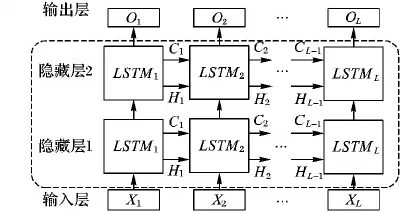
图5 基于LSTM的预测模型框架
结合图4可知,其运行步骤如下:
步骤1 确定输入层、输出层。设置网络为每批m个变量作为输入X={xi|i=1,2,…,m},n个变量作为输出O={oi|i=1,2,…,n},网络经过训练会输出接下来连续的n个小时的叶绿素a浓度预测值。本实验中设定m=20,n=3,每批20个数据预测未来3 h的叶绿素a浓度值。
步骤2 设置隐藏层参数。本实验中设定隐藏层数为2层,每层320个神经元。根据图3中LSTM隐藏层记忆细胞结构,确定激活函数为sigmoid函数和tanh函数,由隐藏层到输出层的激活函数选择Linear线性函数。
步骤3 设置预测模型训练过程参数。构建GF-LSTM网络预测模型之后,对数据进行训练过程中,由loss损失函数获得网络模型的输出误差,并由梯度下降法寻找最小值,更新权重,最终使模型收敛。
1)确定loss损失函数。loss损失函数选择均方误差(Mean Square Error, MSE),用来衡量网络每一步训练后预测值与真实值的偏差,在运行过程中loss损失函数输出值越来越小,最终趋近于0。MSE公式如下:
(11)
其中:x为序列样本的期望值;x*为预测值;N为样本总数。
2)优化器选择随机梯度下降法(Stochastic Gradient Descent, SGD)或RMSProp法分别进行训练,测试中发现RMSprop法训练的误差更小。RMSprop法是对梯度下降法的改进,能够自动调节学习速率,很好地解决了深度学习中学习率急剧下降和过早结束的问题,适合处理非平稳目标。
步骤4 判定预测模型误差。对GF-LSTM网络模型预测结果,采用两种误差分析方法验证其预测精度,即均方根误差(RMSE)和平均相对误差(MRE)[18]。
(12)
(13)
其中:x为序列样本的期望值,x*为预测值,N为样本总数。
3 仿真结果及分析
3.1 实验数据
对太湖地区蓝藻水华演化状况进行建模仿真,在太湖蓝藻水华爆发频率高的梅梁湖区域设置采样点,进行遥感监测和站点检测。梅梁湖景区由梅梁湖和沿湖山峦组成,该景区水域面积158.9 km2,是太湖著名的旅游景点之一。由于该区域水位较低、上游水质恶化、水体自净能力低等原因,梅梁湖水域常年爆发严重的蓝藻水华灾害,对当地环境、水中生物以及人们的身体健康产生重大影响。太湖蓝藻水华中含有丰富的叶绿素,通常用叶绿素a浓度表征浮游植物的生物量[19]。
对该区域2015年6月至9月水质信息进行采样分析,每日采集24组数据,作为预测蓝藻水华发生趋势的建模数据。
3.2 实验结果
表1给出部分实验数据,以及LSTM、GF-LSTM网络模型的预测结果和误差,表中GF-LSTM网络预测结果更接近叶绿素a浓度真实数据,且误差比较小。图6是分别采用常规LSTM网络模型(未进行数据平滑滤波处理)和提出的GF-LSTM网络模型对太湖蓝藻水华发生过程中叶绿素a浓度值的预测结果曲线图。由图6可以看出,常规的LSTM模型预测曲线与真实值曲线拟合得不太理想,而GF-LSTM网络模型能够较好地跟踪叶绿素a浓度变化趋势,并响应叶绿素a浓度的波动变化,实现了更为精确的预测。为了更好地比较网络模型对蓝藻水华爆发过程预测的准确性和有效性,对两种模型的预测曲线与真实数据曲线作相关性分析。其中,LSTM预测曲线与真实曲线的相关系数为0.783,GF-LSTM预测曲线与真实曲线的相关系数为0.807,GF-LSTM网络模型的相关系数大于LSTM网络模型。由此可知,提出的GF-LSTM网络模型对叶绿素a浓度的预测更为准确。
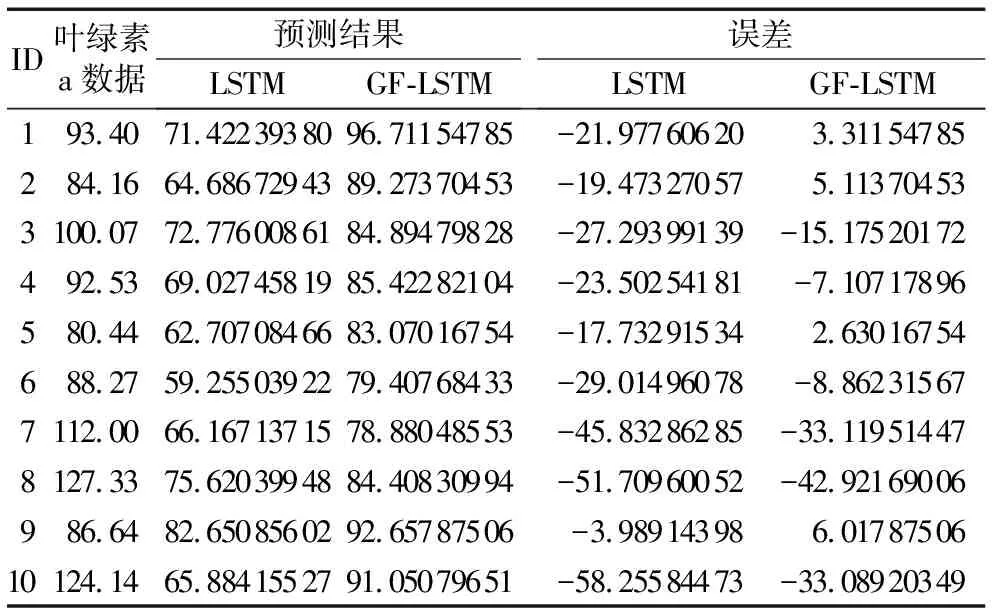
表1 不同模型预测结果及误差比较
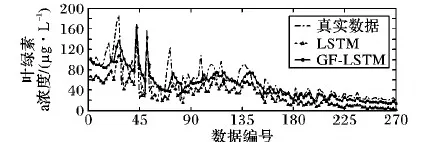
图6 LSTM和GF-LSTM对叶绿素a浓度预测曲线
为了进一步比较LSTM与GF-LSTM两种网络模型的效果,给出预测结果与真实数据的误差箱线如图7所示。箱线图中离散的圆点表示异常值,上下边缘代表该阶段误差的最大值与最小值范围,矩形盒的上下两边分别代表误差的75%和25%分位数,矩形中间的线代表了数据的中位线。对每40个误差数据进行统计分析,并用箱线图呈现每个阶段误差的变化范围。
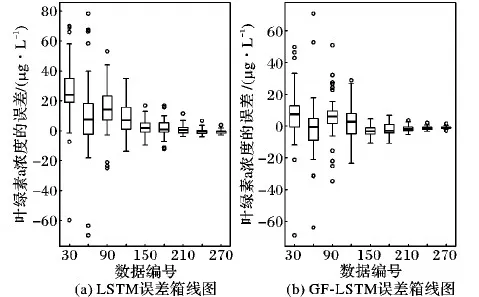
图7 LSTM和GF-LSTM误差箱线图
由图7可以看出,在数据编号0~150,图7(a)中LSTM与图7(b)中GF-LSTM网络的误差变化都偏大,但是最终都趋于0。GF-LSTM的整体误差较小,范围在-20~20 μg/L,大部分误差在0值附近小范围波动。与LSTM相比,GF-LSTM预测结果的误差小,波动范围小,验证了GF-LSTM网络模型对叶绿素a浓度值预测精度更高、效果更好。
3.3 精度分析与验证
建立传统RNN网络、LSTM网络、GF-LSTM网络模型,设定网络模型参数并各自训练100次,记录程序运行结束后损失函数值和总的运行时间,对不同模型预测精度比较结果如表2所示。由表2可以看到:相比RNN、LSTM网络,提出的GF-LSTM网络模型对叶绿素a预测的均方根误差(RMSE)、平均相对误差(MRE)和Loss最小;RNN程序运行时间比较短,而LSTM与GF-LSTM耗时相当,由于其隐藏层结构更为复杂,运行时间长一些,但是在合理的范围内,GF-LSTM网络有效地提高了预测精度。
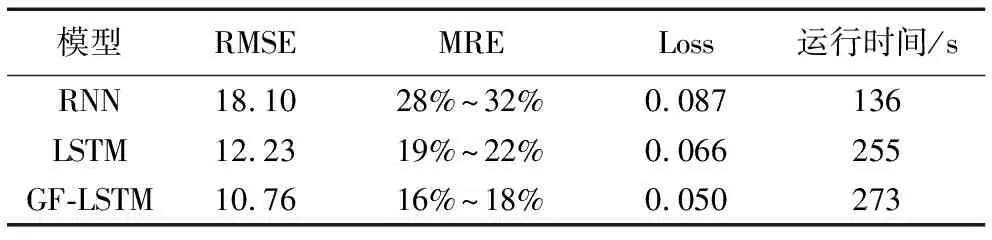
表2 不同模型预测精度比较
4 结语
针对数据采集过程中因受各种干扰呈现一定波动性并产生噪点而造成系统误差,影响模型精度等问题,本文首先对一阶滞后滤波算法进行改进并优化,改善了其相位滞后、灵敏度低的缺点。其次,结合擅长处理复杂突变的时序数据的LSTM循环神经网络,提出了GF-LSTM网络的蓝藻水华预测模型,提高了模型对蓝藻水华的预测精度;但是训练过程的耗时也更多。最后,以太湖梅梁湖水域为例对该方法进行应用与验证,实验结果表明GF-LSTM网络模型显著地提高了蓝藻水华预测精度。
蓝藻水华发生有多种影响因素,仅根据叶绿素a浓度指标分析建模具有一定的局限性。结合蓝藻水华发生的多种因素指标,分析其相关性,进一步提高模型对复杂输入的处理效率和预测精度,并将模型改进以适用于其他复杂领域,将是下一步研究的重点。
