基于迁移学习的知识图谱问答语义匹配模型
2018-08-27刘兴昱
鲁 强,刘兴昱
(石油数据挖掘北京市重点实验室(中国石油大学(北京)),北京 102249)(*通信作者电子邮箱luqiang@cup.edu.cn)
0 引言
基于知识图谱问答系统[1-2]中的语义匹配是指根据用户输入的问句,在特定知识图谱中匹配与该问句对应的关系。在所有问句中有一种只需要知识图谱中单一事实(三元组)作为支持证据的问句,在本文称其为单一事实类问句。例如问句“奥巴马的夫人是谁?”能够被单一事实〈奥巴马,配偶,米歇尔〉回答。为了回答单一事实类问句,需要在知识图谱中匹配与问句相对应的关系,如例句对应知识图谱中的关系是“配偶”,本文称该任务为语义匹配任务。语义匹配任务可表示为概率形式:给定单一事实类问句q,从知识图谱K中找出关系r*,使其最大化条件概率p(r|q),即:
(1)
在特定领域的问答系统中,例如石油勘探、医疗等领域,由于数据来源有限、人工标注样本的难度和成本过高,经常只能获取少量(数千条)的有标注样本。而当前解决语义匹配任务的方法[3-6]主要是有监督的学习方法,这些方法的语义匹配准确率依赖于标注样本的数据量,在标注样本数量较少的情况下难以学习到较高的语义匹配准确率,但是大部分情况下,通过互联网等途径容易获取大量通用领域的无标注样本,因此研究利用这些无标注样本来提高语义匹配的准确率具有重要意义。
通过引入大量通用领域(源领域)的无标注样本来提升少量专业领域(目标领域)有标注样本学习效果的方法,可以看作是一种迁移学习方法[7]。已知的迁移学习方法[8-11]通常假设源领域采用有标注样本进行训练,不能直接解决本文提出的问题。其中自学习方法[12]跟本文提出的问题比较接近,但其源领域的无监督学习方法适合处理图像数据,无法直接应用于自然语言处理问题。至于自然语言处理方面的无监督学习方法主要有word2vec[13]、GloVe[14]等方法,但是这些方法只解决了词粒度的语义学习,不能学习到句子粒度的语义特征,因此需要设计一种能够解决源领域是无标注自然语言数据的迁移学习模型。
本文针对特定领域内有标注样本数量不足的问题,提出一种基于循环神经网络(Recurrent Neural Network, RNN)的迁移学习模型,能够利用大量无标注样本学习问句的语义空间分布以提高语义匹配准确率,进而解决面向特定领域单一事实类问答系统中的语义匹配任务。该模型首先使用基于RNN的序列到序列(sequence-to-sequence, seq2seq)无监督学习算法,通过序列重构的方式在大量无标注样本中学习问句的语义空间分布,即词向量和RNN,作为迁移学习模型中源领域的特征空间分布。然后,使用此语义空间分布作为有监督语义匹配算法相应的参数。最后,通过计算问句特征和关系特征内积的方式,在有标注样本下训练并生成语义匹配模型,其中通过线性函数来建立源领域语义空间分布到目标领域语义空间分布的映射。实验结果表明,与传统的有监督学习方法相比,本文提出的迁移学习模型在小规模有标注样本中取得较高语义匹配准确率。此模型在解决因特定领域标注样本不足而导致语义匹配准确率不高的问题有重要意义。此外,该模型还可以扩展应用到如情感分析等其他的语义匹配相关任务。
本文主要研究工作如下:
1)提出了序列到序列无监督学习问句语义空间分布的算法,该算法使用大量无标注样本学习问句的语义空间分布,作为迁移学习模型中源领域的特征空间分布;
2)提出了基于RNN的迁移学习模型,该模型通过将源领域的语义空间分布映射到目标领域的语义空间分布来提高语义匹配准确率;
3)通过实验验证了基于迁移学习的语义匹配模型在小规模标注样本情况下可以提高语义匹配准确率。
1 相关工作
1.1 问答语义匹配
在基于知识图谱单一事实类问答系统的研究工作中,一条传统的研究线路是采用语义解析的方式[15],该方式针对特定领域设计语法解析规则,对于规则可以覆盖到的情况有较高的准确率,但是泛化能力较差,不易扩展。
除此之外,另一条重要的研究线路是词嵌入方式[16],这种方式主要使用基于深度学习的相似匹配来完成语义匹配任务。其核心思想是学习问句和知识图谱中关系的语义特征向量表示,使相匹配的问句和关系在向量空间中距离最接近。目前已经提出很多基于神经网络学习问句和关系语义特征的方法。其中:Bordes等[3]使用相对浅层的词嵌入模型学习问句和关系的语义向量空间分布;Yih等[4]使用卷积神经网络(Convolutional Neural Network, CNN)生成问句和关系的语义向量空间分布;Dai等[5]使用RNN提取问句的语义向量空间分布。词嵌入方式具有很强的泛化能力,易于扩展,但是该方式采用有监督学习模型,依赖于有标注样本数量,在标注样本数量少的情况下准确率不高。
本文提出的方法接近第二条研究线路,应用神经网络学习问句和关系的语义特征向量表示;但是有别于传统的有监督学习算法,本文提出迁移学习模型来解决标注样本不足的问题,通过无监督算法预学习问句的语义空间分布来提高有监督语义匹配算法的准确率。该方法解决了有监督学习算法在特定领域标注样本数量少而语义匹配准确率不高的问题,拥有更强的泛化能力。
1.2 迁移学习
迁移学习[7]主要分为基于实例和基于特征的两种方式。其中基于实例的方法,具有代表性的工作有Dai等[8]提出的提升方法,其通过改变源领域和目标领域中有标注数据样本的权值来达到迁移学习的目的;但基于实例的方法通常假设源领域和目标领域都是有标注数据,而本文中源领域采用无标注数据,目标领域采用有标注数据,所以不适用于本文提出的问题。
此外,基于特征的方法对于源领域和目标领域是否有标签没有严格要求,其主要解决两个问题:如何学习特征和如何迁移特征。例如Oquab等[9]提出的基于特征迁移的方法与本文方法比较接近,其首先通过有监督训练方式学习得到源领域的分类器,然后将该分类器的模型参数作为目标领域分类器参数的初始值,最终通过训练目标领域的有标注数据学习得到目标领域的分类器。由于该方法假设源领域是有标注数据,所以具有一定局限性,不能完全适用本文所要解决的问题。在图像识别领域,Raina等[12]提出的自学习方法与本文方法更加接近,其首先通过源领域无标注数据学习得到表示图像的基特征;然后根据上步的基来表示目标领域的有标注数据;最终根据这些数据的特征进行有监督训练学习得到目标领域的分类器。本文与自学习方法的主要区别在于学习无标注数据特征的方法不同,并且特征迁移的方式也有所区别。近几年领域适应(domain adaptation)[10-11]结合对抗训练思想取得了一些进展,但是由于这些方法假设源领域采用有标注数据,目标领域采用无标注数据,所以不能直接解决本文提出的问题。
2 问题定义
本文假设Dt={〈qt,r〉|qt∈Qt,r∈K}表示目标领域的有标注数据集,其中Qt是有标注问句集,关系r取自知识图谱K;Ds={〈qs〉|qs∈Qs}表示源领域的无标注数据集,其中Qs是无标注问句集。需要强调的是有标注数据集的数据量远远少于无标注数据集的数据量,即|Qt|≪|Qs|,并且无标注问句Qs不需要与有标注问句Qt符合同一分布。由于目标领域有标注数据量较少,难以直接学习得到准确率较高的语义匹配模型;而源领域无标注数据量庞大,可以用来辅助学习语义匹配模型。本文通过将源领域中无标注问句的语义空间分布Fs映射到目标领域中有标注问句的语义空间分布Ft来提高语义匹配准确率,得到语义匹配模型h:
(2)
首先为了学习得到源领域中无标注问句的语义空间分布Fs,本文使用无监督学习算法,令qs=d(Fs(qs)),其中Fs也可以视为源领域问句的编码过程,d表示解码过程,最终通过类似自编码的方式学习得到Fs。
然后通过特征迁移的方式令Ft(qt)=φ(Fs(qt)),其中映射函数φ将源领域语义空间分布Fs映射到目标领域语义空间分布Ft。
最后语义匹配模型h(qt,r)=f(Ft(qt),r),其中f表示问句与关系的语义匹配函数,即语义匹配模型推导为:
(3)
3 基于迁移学习的语义匹配模型
3.1 基于RNN的迁移学习模型
本文提出的迁移学习模型通过预学习大量无标注样本数据的语义空间分布来提高小规模标注样本环境下的语义匹配准确率。如图1所示,步骤①用于学习无标注问句的语义特征,本文使用基于RNN的序列到序列无监督学习算法,在大量无标注样本Ds中学习问句的语义空间分布Fs,而此空间分布Fs由词向量Es和编码RNNEncoders组成,解码过程d由Decoders组成,该部分在3.2节详细描述;步骤②用于迁移参数,本文使用步骤①中学习得到的语义空间分布作为有监督语义匹配算法中词向量Et和编码RNNEncodert的参数,即令Et=Es,Encodert=Encoders;在步骤③中,本文使用有标注样本Dt训练生成语义匹配模型h,其中将线性函数Linear作为特征映射函数φ来建立源领域语义空间分布到目标领域语义空间分布的映射,语义匹配函数f通过内积(Linear(ct)TEr(r))的方式计算问句与关系的语义匹配程度,该部分在3.3节详细描述。本文最后在3.4节详细阐述了迁移学习模型的整体训练算法。

图1 迁移学习模型框架
3.2 无监督语义空间分布学习算法
本文通过序列到序列算法[17]学习源领域问句Qs的语义空间分布。该算法在给定输入序列x=(x1,x2,…,xT)后,可以计算与之相对应的最可能的输出序列y=(y1,y2,…,yT′),其采用两种RNN共同训练以最大化lnP(y|x),其中所有序列的结尾加入“
vs=Es(x)
(4)
cs=Encoders(vs)
(5)
y=Decoders(cs)
(6)
其中编码部分首先通过一层词嵌入层Es将词序列x映射到分布式的向量表示vs,然后经过由两层BiLSTM组成的编码器Encoders转化为固定长度的向量cs,作为问句的语义特征向量表示,其中cs是BiLSTM的最终隐层状态;解码器Decoders通过另外的一层LSTM进行解码得到输出序列y。最终通过自编码的方式使词嵌入层Es和编码RNNEncoders学习到源领域问句的语义空间分布。
本文采用最大似然估计(Maximum Likelihood Estimation, MLE)和反向传播(Back Propagation, BP)算法训练序列到序列算法的参数,解码器Decoders以固定长度的向量cs为条件计算y=(y1,y2,…,yT′)的产生概率,计算公式如下:
其中,每一个p(yt|cs,y1,…,yt-1)的分布由作用于词嵌入层中所有词的softmax函数表示。
3.3 有监督语义匹配算法
本文定义给定目标领域问句qt与对应关系r的概率为p(r|qt),由以下公式建模:
(8)
其中r′是知识图谱K中的负例关系,打分函数s(r,qt)衡量了问句和关系的匹配相似度,计算公式如下:
s(r,qt)=g(qt)TEr(r)
(9)
其中,关系的词嵌入层Er将关系r映射到分布式的向量表示,作为关系的语义空间分布。Er中的关系向量参数经过语义匹配算法的神经网络训练得到。g(qt)计算了问句的语义向量,代表问句的语义空间分布,两者语义向量的内积数值代表两者语义向量的空间距离大小,内积得分越高代表两者语义向量的空间距离越近,即两者语义的匹配程度越高,其计算过程如式(10)~(12)所示:
vt=Et(qt)
(10)
ct=Encodert(vt)
(11)
g(qt)=Linear(ct)
(12)
其中g(qt)先由一层词嵌入层Et将词序列qt映射为分布式的向量表示vt,然后经过由两层BiLSTM组成的编码器Encodert学习问句的语义特征向量ct,其中ct是BiLSTM的最终隐层状态,最终经过一层线性层Linear进一步学习问句的语义空间分布,并将ct映射到与Er中向量维数相等的向量空间。
本文采用MLE和BP算法估计语义匹配算法中pθ(r|qt)的参数θ:
(13)
本文采用基于负采样的合页损失(Hinge Loss)函数作为语义匹配算法训练过程中的损失函数,其计算公式如下:
(14)
其中:N是Dt中的样本数量;rj是负例集合Mr中的一个负例,随机从知识图谱K中采样;γ是预设的边界值。
3.4 迁移学习模型的实现
综上所述,此迁移学习模型的训练算法如下所示。
Input:Ds,Dt。
Output:Et,Encodert,Linear,Er。
1) Training semantic space distribution:
2) Randomly initialize the parameters ofEs,Encoders,Decoderslayers
3) On theDsdata set, the parameters of each layer are unsupervised trained by MLE and BP algorithm according to formula (7)
4) Get the parameters ofEs,Encoders,Decoderslayers
5) Training semantic matching:
6) LetEt=Es,Encodert=Encoders, and random initialize the parameters ofLinearandErlayers
7) On theDtdata set, the parameters ofEt,Encodert,Linear,Erlayers are supervisedly trained by MLE and BP algorithm according to formula (14)
8) Get the parameters ofEt,Encodert,Linear,Erlayers
该训练算法的输入是无标注数据集Ds和有标注数据集Dt,输出是语义匹配算法中Et、Encodert、Linear、Er层的参数。其中第1)~4)行用来训练源领域的语义空间分布,第2)行是随机初始化Es、Encoders、Decoders层的参数,第3)行是在无标注数据集Ds上根据式(7)采用MLE和BP算法无监督训练各层的参数,第4)行是得到训练完成后Es、Encoders、Decoders层的参数;第5)~8)行用来训练语义匹配算法,第6)行是用第4)行得到的Es、Encoders层的参数作为Et、Encodert层的初始值,并随机初始化Linear、Er层的参数,第7)行是在有标注数据集Dt上根据式(14)采用MLE和BP算法有监督训练各层的参数,第8)行是得到训练完成后Et、Encodert、Linear、Er层的参数。
4 实验
4.1 实验数据和参数设置
语义匹配算法分别采用三套有标注数据集作为迁移学习的目标领域。为了验证本文提出的迁移学习算法在特定专业领域有标注数据量较少情况下的效果,本文制定了一套中文有标注数据集OIL进行实验,该数据集由4 465条有标注数据组成,主要涉及石油探勘领域,并且该数据集的每条问句都对应同一个石油勘探领域知识图谱的实体-关系-客体三元组。
除此之外,为了验证算法的有效性和泛化能力,本文采用两套英文数据集WebQuestions(WBQ)[15]和SIMPLE-QUESTIONS(SQ)[19]。WBQ包含5 810条有标注数据,SQ包含108 442条有标注数据。WBQ和SQ中的每条问句分别对应来自Freebase[20]知识图谱中的实体-关系-客体三元组,主要涉及人物、地理等有限的几个领域。
本文将以上有标注数据集全部按照训练70%、验证10%和测试20%进行划分。
序列到序列算法采用两套无标注数据作为迁移学习的源领域。中文采用WebQA[21]作为训练集,该数据集来源于某度知道的问答语料,包含42 223条无标注问句样本,主要涉及人文、地理、影视、学科知识以及一些专业性的领域等多种领域。英文采用WikiAnswers Paraphrase(WAP)[22]数据集作为训练集,该数据集来源于WikiAnswers互动问答网站,用户可以在该网站提问或回答任何问题。该数据集包含258万条无标注问句样本,没有包含与之匹配的关系,其中问句涉及科技、生活、人文、历史、地理等众多领域,问句描述较为复杂,有些问句可能涉及多种关系。
本实验采用Tensorflow[23]深度学习开发平台,其中问句词向量的维数设为200,所有RNN结构体的隐层大小设为256,关系词向量维数设为256;其中问句词向量和关系词向量参数的随机初始值满足均值为0,标准差为1E-4的正态分布,RNN参数的随机初始值都采用服从[-1,1]均匀分布的初始化方式;所有合页损失函数的边界值γ设为0.1,负采样数量设为1 024;所有实验采用基于mini-batch的Adam[24]优化方式训练参数,学习率设为0.001。
4.2 对照基准和评估
本实验采用词嵌入平均模型[3]作为对照基准,该模型的核心思想是采用问句中每个词向量的平均值作为其问句的向量表示,本文称之为Embed-AVG(Average Embeddings)。此外,本文将基于迁移学习的语义匹配模型称为RNNpretrain,将基于RNN的完全随机初始化参数进行监督训练的语义匹配算法称为RNNrandom(random initialization of RNN)。
为了验证迁移学习算法在小规模标注样本环境下的学习效果,本文分别设置了三组对照实验数据。如表1所示,语义匹配算法数据集表示Embed-AVG、RNNrandom和RNNpretrain语义匹配模型采用的训练集和测试集,序列到序列算法数据集表示RNNpretrain中序列到序列算法训练阶段的训练集。其中SQ(5k)表示从SQ数据集中随机抽样5 000条样本,WAP(200k)表示从WAP数据集中随机抽样20万条样本。
除此之外,为了验证有标注样本的数据量对实验的影响,本实验从SQ数据集的训练集中分别随机采样,产生多个不同数量的样本集,作为Embed-AVG、RNNrandom和RNNpretrain语义匹配模型的训练集。为了验证无标注样本的数据量对实验的影响,本实验从WAP数据集中分别随机采样,产生多个不同数量的样本集,作为RNNpretrain中序列到序列算法训练阶段的训练集。最终所有语义匹配算法的评估全部采用SQ数据集的21 687条测试样本作为测试集。本文实验以目标关系得分最高视为匹配正确,以问句和关系的匹配正确率作为评估标准。

表1 实验数据集设置
4.3 实验结果分析
图2展示了Embed-AVG、RNNrandom和RNNpretrain算法分别在data1、data2和data3数据集上的表现。从图2可以明显看出,在有标注数据量较少的情况下,RNNpretrain在各个数据集上的准确率,与RNNrandom相比分别大约提高8.6、9.1和8.8个百分点,平均提高8.8个百分点;与Embed-AVG相比分别大约提高6.7、5.7和4.4个百分点,平均提高5.6个百分点。甚至简单的Embed-AVG也比RNNrandom的学习效果好。从中可以看出RNNrandom在有标注样本规模很小的情况下学习效果比较差,因为越复杂的模型需要越多数据进行训练学习。而本文提出的RNNpretrain可以在有标注数据量较少的情况下,通过学习大量无标注数据来明显提高语义匹配准确率。
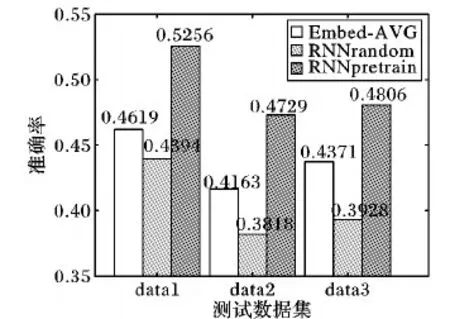
图2 各语义匹配模型对不同测试数据集测试准确率
此外,为了展示有标注样本和无标注样本的数据量对实验的影响,表2列举了各个模型分别在不同有标注数据量和不同无标注数据量学习后的语义匹配准确率,其中:SQ后面的括号内容表示语义匹配算法训练阶段在SQ数据集中随机采样的样本数量,WAP后面的括号内容表示序列到序列算法训练阶段从WAP数据集中随机采样的样本数量。例如:SQ(20k)情况下的Embed-AVG和RNNrandom分别表示从SQ数据集中随机采用两万条样本用来训练其语义匹配算法;SQ(5k)情况下的RNNpretrain(WAP100k)表示RNNpretrain模型首先从WAP数据集中随机采样10万条样本用来训练序列到序列算法,然后从SQ数据集中随机采用5 000条样本用来训练语义匹配算法。图3以折线图的方式描绘了表2中的数据,通过图3可以更加明显地观察到所有语义匹配算法的准确率在不同数量训练样本上的变化趋势,以及其相互间的差距。
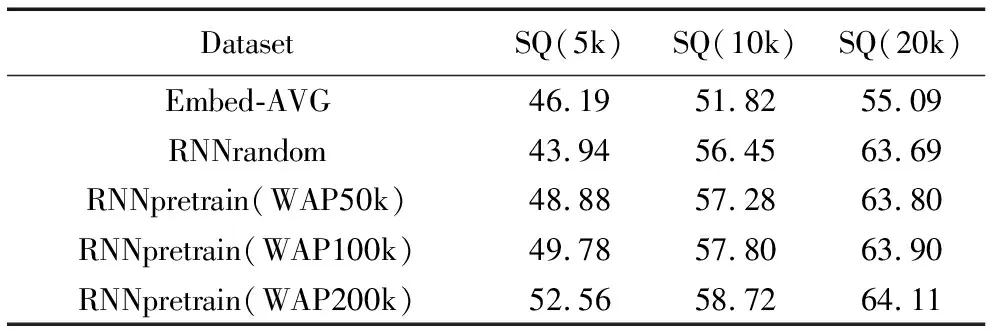
表2 语义匹配模型测试准确率对比 %
从表2可以看出在SQ(5k)的情况下,RNNpretrain(WAP200k)的准确率分别比RNNpretrain(WAP50k)和RNNpretrain(WAP100k)大约提高3.7和2.8个百分点,说明在一定范围内使用相同数量的有标注样本,RNNpretain会随着预训练无标签样本WAP数量的增加而提高语义匹配准确率,说明增加无标注样本数量可以提升语义特征提取效果,使源领域学习到的语义空间分布能更大程度地覆盖目标领域的语义空间分布。
此外,RNNpretrain(WAP200k)使用5k有标注样本训练得到的学习效果超过了Embed-AVG使用10k有标注样本训练得到的学习效果,体现了迁移学习算法在小规模样本集上优越的性能。而且随着有标注样本数量的增加,RNNrandom的学习效果逐渐超越了Embed-AVG的学习效果,证明在有监督学习中,越复杂的模型需要越多数据进行训练学习。
从图3可以看出,随着有标注样本数量的增加,RNNrandom的学习效果将会缩小与RNNpretrain的差距。其中RNNpretrain(WAP200k)的准确率相比RNNrandom在SQ(5k)、SQ(10k)的情况下分别大约提升8.6和2.3个百分点。这主要有两点原因:一个直观的原因是增加有标注样本的数量,可以学习到更加精准的目标领域语义空间分布,进而提升语义匹配准确率,但是在专业领域的实际开发中,难以获得数量足够庞大的有标注样本集;另一个原因是当RNNpretrain使用相同数量的无标注样本,在序列到序列算法训练阶段没有学习到更加通用的问句语义空间分布时,随着有标注样本的增加,将会减弱这些预训练得到的特征在有监督训练中发挥的作用。
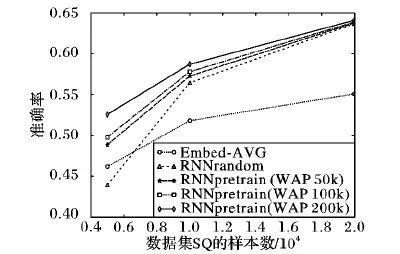
图3 各语义匹配模型在不同数据集规模时测试准确率
为了更加直观地分析实验结果,本文采用t-SNE(t-distributed Stochastic Neighbor Embedding)[25]算法将各个模型的词向量映射到二维空间并进行可视化展示。如图4,本文画出了词频数量排名前300的词向量,其中,“+”符号表示源领域词向量的分布,此分布通过对源领域数据使用序列到序列(seq2seq)算法进行预训练而生成;“o”符号表示目标领域词向量分布,此分布通过对目标领域有标注数据使用RNNrandom算法训练而生成;“△”符号表示源领域到目标领域迁移后的词向量分布,此分布通过RNNpretrain算法训练而生成。其中每一幅对比图中RNNpretrain和RNNrandom使用的有标注样本SQ完全相同,例如“SQ (10k) WAP (50k)”表示序列到序列算法采用50 000的WAP进行训练,RNNpretrain在该预训练基础上采用10 000的SQ数据进行训练,RNNrandom采用同样10 000的SQ数据进行训练。
从图4(a)可以看出,源领域(“+”符号)与目标领域(“o”符号)的词向量分布虽然有较大差异但是也有相似的部分,最终源领域经过迁移学习之后的词向量分布(“△”符号)趋近于目标领域的词向量分布,发生了明显的迁移现象。由此可以说明本文提出的迁移学习方法可以将源领域的词向量分布迁移到目标领域的词向量分布,进而提升最终的语义匹配准确率。从图4(b)和图4(a)对比来看,在增加无标注样本的情况下,源领域的词向量分布更加全面广泛,经过迁移学习后的词向量分布更接近目标领域的词向量分布。这说明增加无标注样本可以学习到更通用的源领域词向量分布,使迁移现象更加明显,进而更加有效地提升语义匹配准确率。从图4(c)和图4(b)对比来看,在增加有标注样本的情况下,目标领域的词向量分布更加广泛并且与源领域词向量分布的差异变小,经过迁移学习后的词向量分布非常接近目标领域,发生了较弱的迁移现象。这说明增加有标注样本可以学习到更好的目标领域词向量分布,在源领域没有学习到更通用的词向量分布的前提下,会降低迁移学习的提升效果。
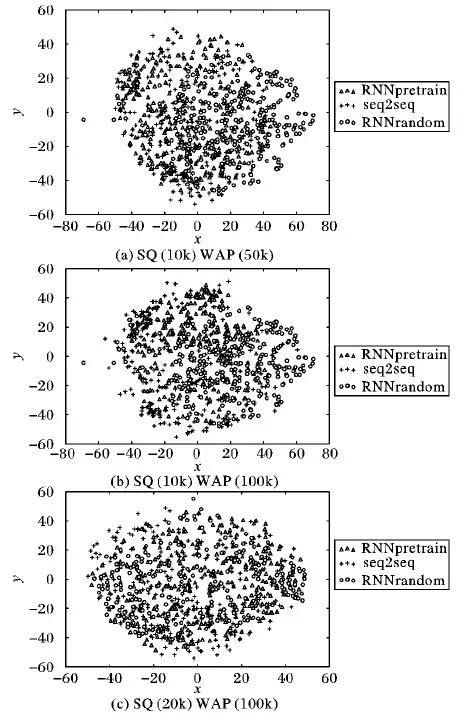
图4 词向量空间分布图
此外,为了更好地展示实验结果,本实验列举出一些具体的例子。例如有标注数据集OIL的测试集中存在样本〈“油气开采技术水平的重要指标是什么?”,“评价标准”〉,输入该样本中的问句,RNNrandom计算出得分前两名的关系为“重要环节(0.71),评价标准(0.65)”,而RNNpretrain计算的结果为“评价标准(0.73),重要环节(0.64)”,其中括号内的数值表示问句和关系的语义匹配得分。对于该测试样本,RNNrandom匹配错误的主要原因是OIL的训练集中包含关系“评价标准”的标注样本较少,导致RNNrandom在训练过程中难以学习到与“评价标准”相关的问句语义空间分布。而且该测试问句中出现“重要”等词语,进一步导致“重要环节”被错误地计算为最佳匹配关系。
但是对于该测试样本,RNNpretrain计算得到了正确的匹配结果。其主要原因是无标注数据集WebQA的训练集中包含大量与测试样本相关的问句,如“雾霾污染指标是什么?”“如何衡量雾霾污染程度?”“米其林餐厅评价主要标准是什么?”等。这些无标注问句不仅提供了对同一关系“评价标准”的多种形式表示,而且还展现出丰富多样的提问方式,进而促使RNNpretrain在训练过程中可以学习到关于“评价标准”更加通用的问句语义空间分布。
综合以上实验结果表明,在有标注样本数量较少且无标注样本数量较大的情况,RNNpretrain的语义匹配准确率相比RNNrandom和Embed-AVG有明显提升,拥有更强的泛化能力。
5 结语
对于单一事实类问答系统中的语义匹配任务,传统的有监督学习方法需要依赖大量的有标注样本才能取得较高的语义匹配准确率。针对这种问题,本文提出基于RNN的迁移学习模型,其通过预学习大量无标注样本数据的语义空间分布来提高小规模标注样本环境下的语义匹配准确率。实验结果表明,在小规模有标注样本上,该模型可以明显提高语义匹配准确率,并且该准确率在一定范围内随着无标注样本数据量的增大而有所提升。本文提出的模型适用于特定领域因有标注数据量少而导致有监督学习模型准确率不高的情况,此外这种迁移学习的方式也可以推广应用到其他与语义匹配相关的任务中。
下一步本文将探究预处理无标注样本的方法来过滤更多的噪声,以及探索使用生成对抗网络[26]改进序列到序列算法来提升学习问句语义空间分布的能力。
