基于超图排序和组稀疏最优化的推荐系统
2018-07-19海本斋
于 琨,孙 波,海本斋
(1.河南工学院 计算机科学与技术系,河南 新乡453002;2.河南师范大学 计算机与信息工程学院,河南 新乡453002)
0 引 言
社交媒体的发展引起了与图像相关的元数据信息如标签和地理标签广泛的研究。许多社交媒体共享平台如各种社交网站、微博、微信、博客、论坛、播客等等,不仅成为人们彼此之间用来分享意见、见解、经验和观点的工具和平台,还可以允许用户注释图像,根据他们的观点来描述内容。由于人们之间的文化差异,所以对图像内容的感知可能会有所不同。图像标注的目的就是弥合这种语义差距,有利于图像搜索和分类。这个任务可以通过利用另一种与图像相关的元数据信息如地理标签进一步得到提高。现代移动设备如相机或智能手机能够在它自动拍摄的时候给一个图像指定专门的地理坐标,用这种有价值的地理信息来丰富图像有助于图像进一步搜索。
标签是分配给一个图像的语义关键字。图像标注能够使社交媒体用户共享平台注释图像,有利于图像搜索和内容描述。关于该领域尽管已有大量的相关研究,但诸如精度或效率等问题仍然是人们十分关注的问题。近年来,许多研究集中于图像标注和利用图像内容。文献[1]提出了一种图像和视频标注模型。注释概率的估计是基于一个多伯努利模型,同时非参数核密度估计(kernel density estimates,KDE)被用作为图像特征;文献[2]基于Markov随机场(Markov random fields,MRF)提出了一种概率模型来捕捉不同特征之间的相关性;文献[3]采用基于图的方法,将多类型相互关联的目标信息用于图像特征的描述和标注;文献[4,5]分别提出对图像进行分割提取低层视觉特征作为图像区域标注和提取图像前景与背景区域并分别进行预处理来实现对图像的自动标注;文献[6]提出将联合分类和回归模型同时用来实现图像注释和地理标签预测;文献[7]对于地理标签预测问题提出了一种基于数据驱动场景匹配方法的解决方案;文献[8,9]分别将基于超图的方法用于三维目标的检索和估计用户标注图像的相关性;文献[10,11]提出了基于组稀疏(group sparsity,GS)和多核学习方法(multiple Kernel learning with group sparsity,MKLGS)先将包含多种异构特征的非线性图像数据映射到一个希尔伯特空间,然后利用希尔伯特空间中的核函数以及组LASSO对每个图像类别选择最具区别性特征的集合,最终训练得到分类模型对图像进行标注;文献[12]提出了一种图正则化约束下的非负组稀疏(graph regularized non-negative group sparsity,GRNGS)模型来实现图像标注,并通过一种非负矩阵分解方法来计算其模型参数。
本文在超图排序框架内针对同时性图像标注和地理位置预测提出了一种方法实现的推荐系统,并通过执行组稀疏最优化来使图像标注和地理位置预测的准确性得到进一步提高。通过从中国旅评网抽取出的数据集的实验结果表明,本文提出的方法相比于其它方法,不仅能够获得更高的召回-精确率和F1测量值,而且能够对排名前3位的地理位置获得更高的正确预测率和累计评分。
1 基于超图排序和组稀疏最优化的推荐系统

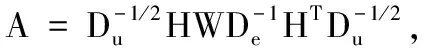
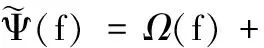
(1)
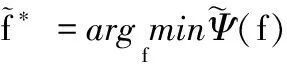
(2)
式(2)就是一般推荐系统问题的解,通过式(2)获得的排名可用于超图图像标注,但是其精确度是很低的,因为它没有对标注对象进行细分;为了提高其精确度,我们把每个顶点的子集称为对象组,当然每个对象组对排序过程的贡献是不同的,并把超图顶点分割成S个非重叠对象组(图像、用户、社会群体、地理标签和标签),而且对每个对象组分配不同的权值γs(s=1,2,…,S), 以使下列目标函数最小化
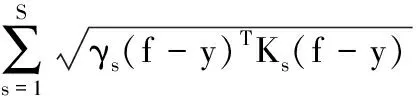
(3)
式中:Ks为大小为 |V|×|V| 的对角矩阵,而且对于属于第s个对象组的顶点来说,其元素等于1。为简便起见,我们把式(3)的最小化问题表示为
(4)
这样,就得到由式(4)表示的经过组稀疏最优化的排序向量f*。
为了求解式(4),令x=f-y, 并引入辅助变量z=x, 式(4)右端可重写为
(5)
这样,式(5)的解就可以通过使增广拉格朗日函数最小化来得到

(6)
式中:λ是拉格朗日乘子向量,并在每次迭代中被更新,μ是一个参数,调整约束以使x=z。求解式(6)的算法的伪代码如下。
算法1:
(1)给定xt,zt和λt
(2)设置算法收敛的精度值ε并初始化μ0

(6)λt+1=λt+μt(zt+1-xt+1)
(7)μt+1=min(1.1μt,106)
(8)else
(9) returnxt+1,zt+1
(10)f=xt+1+y
(11)endif
算法求解第(3)行的xt+1得到
xt+1=(L+μtI)-1(λt+μtzt-Ly)
(7)
仔细观察式(7)可以发现,在每次迭代不需要矩阵的逆,只需要一个特征值分解。事实上,令Qt=L+μtI, 则有
(8)
(9)
这样,算法1的第(4)行所描述的最小化问题就可表示为
(10)
通过应用软阈值算子[17]得到
(11)
2 算法实例
2.1 数据集描述
为了实现和评价本文提出的算法,收集的图像数据集来自于中国旅评网[18],它包含哈尔滨市的索菲亚大教堂地标、防洪纪念塔和流行的俄罗斯风情大街城市风等景观照片,如图1所示,而且还下载了一大组“地理标记”图像以及与它们相关的有价值的信息(id、标题、所有者、纬度、经度、标签、图像视图)。然后,基于图像视图及用户的上传统计对数据集进行过滤。假设具有多视图的图像通常描绘值得注意的地标和具有许多上传图像的用户是活跃群体,他们拥有许多社会关系(朋友、社交群体),则抽取相应的社会信息(朋友、社交群体),而且只有来自于数据集的至少有5个用户的群体作为成员被保留。具体基数见表1。

图1 数据集采集图像
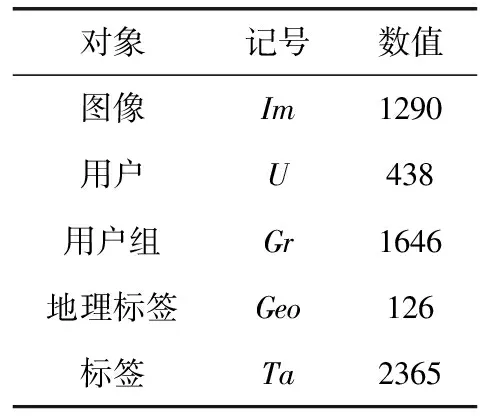
对象记号数值图像Im1290用户U438用户组Gr1646地理标签Geo126标签Ta2365
2.2 超图的构建
顶点集定义为V=Im∪U∪Gr∪Geo∪Ta。 超图H由连接6个超边集构成,超边集如表2的列所示。H的大小为5866×30920个元素,超边集E(1)-E(6)的权值设置为1。

表2 超图关联矩阵H及其子矩阵的结构
E(1)表示用户之间的两两关系。超图关联矩阵UE(1)有大小为442×2273个元素;
E(2)表示用户组。它包含相应用户的全部顶点以及相应用户组的全部顶点。超图关联矩阵UE(2)-GrE(2)有大小2080×1642个元素;
E(3)包含一个用户和一个上传的图像,代表一个用户图像拥有的关系。每个图像只有一个拥有者。超图关联矩阵的UE(3)-ImE(3)有大小为1730×1294个元素;
E(4)捕获地理位置关系。这个超边集包含Im、U和Geo。超图关联矩阵ImE(4)-UE(4)-GeoE(4)有大小1858×124个元素;
E(5)也包含Im、U和Geo。每个超边表示一个标记关系。超图关联矩阵ImE(5)-UE(5)-TaE(5)有大小4099×19124个元素;
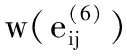
为了构成这部分超图,采用全局和局部特征。首先,采用GIST描述符[19]对每个图像的100个最近邻居进行确定,而且通过采用尺度不变特征变换(scaleinvariant feature transform,SIFT)[20]把它们减少到5个最相似的图像作为参考图像。
通过设置对应于参考图像im的记录及其拥有者的u=1来使查询向量y初始化。连接到该图像的标签ta设置为A(im,ta)。对应于gr和geo且与图像拥有者u相关联的对象分别设置为A(u,gr)和A(u,geo)。查询向量y具有5866个元素的长度。
通过求解式(2)或式(4)和已经设置的查询向量y、正则化参数ϑ和在式(4)情形下的对象组权值γs(见第3节)来得到排序向量f*,它与y有相同的大小和结构。对应于标签的值用于具有排名最高的标签(被推荐为参考图像)的图像标注,对应于geo的值用于具有仅排名前3的地理位置(即地理集群,被推荐为参考图像)的地理位置预测。
3 算法性能仿真
为了评价本文提出的算法性能,一方面,我们把经过组稀疏最优化处理的式(4)获得的排名、通过式(2)获得的排名以及文献[3]采用简单的基于图的方法获得的排名进行比较(为简便起见,把本文提出的方法即式(4)的算法称为方法1,式(2)的算法称为方法2,文献[3]采用简单的基于图的方法称为方法(3)),性能指标为平均召回-精确率和F1测量值;另一方面,把本文提出的方法1获得的地理位置正确预测率、通过式(2)方法即方法2获得的地理位置正确预测率以及将图像地理坐标之间的距离(即地面真实距离)与地理名称相关联的距离通过采用“半正矢公式”进行计算得到的地理位置正确预测率(称为方法4)进行比较;最后我们还比较了在相同的数据集上前3种方法关于平均召回率和平均精确率的收敛特性。
为了计算召回率和精确率,把排名最高的15个标签推荐给任意测试图像,5个不同对象组(图像、用户、用户组、地理标签和标签)的权值分别设置为0.9、0.9、0.6、0.2和0.2,μ0、ε和ϑ的典型值分别为10-6、10-8和2。图2 所示为3种方法得到的平均召回-精确率曲线,曲线是对至少4个标签的1180个图像的召回-精确率取平均值得到的。从图2可见,本文提出的方法1的排名的平均召回-精确率性能得到了显著提高,方法2次之,文献[3]采用简单的基于图的方法获得的排名的平均召回-精确率是最差的;表3所示为对应于5种不同的排名位置时3种方法得到的平均F1测量值。从表3可见,显然本文提出的方法1取得了较好的F1测量值,明显优于其它2种方法。

图2 3种不同方法的平均召回-精确率曲线比较
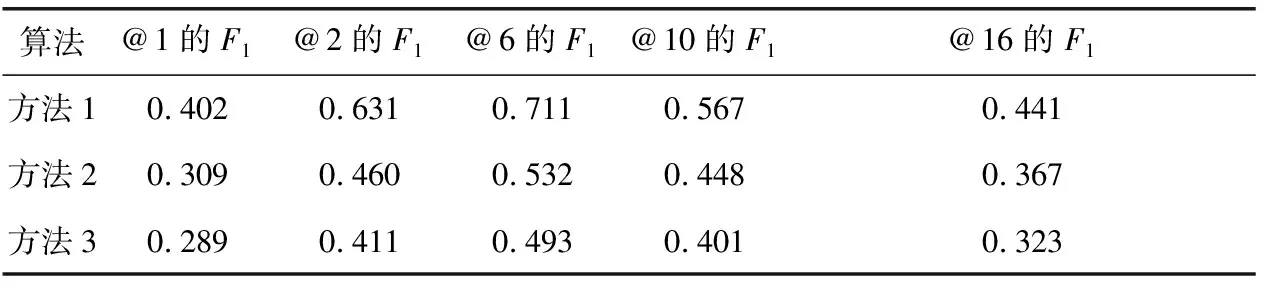
算法@1的F1@2的F1@6的F1@10的F1@16的F1方法10.4020.6310.7110.5670.441方法20.3090.4600.5320.4480.367方法30.2890.4110.4930.4010.323
表4所示为对应于排名前3位元素时3种方法得到的地理位置正确预测率。从表4可见,本文提出的方法1不仅能够获得全部排名较好的位置预测率,而且排名前3位的元素的正确预测率达到了87%,总评分明显高于其它2种方法,分别平均高24%和61%,说明基于组稀疏最优化处理后的效果是很明显的。
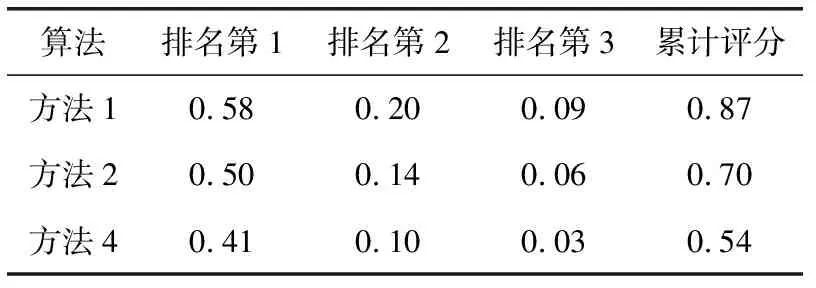
表4 3种方法得到的排名前3的位置预测率及累计评分
图3所示为相同数据集上得到的前3种方法的平均召回率和精确率的收敛过程。从图3可见,随着迭代次数的增加,3种方法的平均召回率和精确率都在不断增加,但本文提出的方法1的增加速度明显高于另外2种方法,平均召回率大约高31%和42%,平均精确率大约高29%和41%。这不仅有利于快速获取图像标注的时效性,而且也大大提高了图像标注的准确性和可靠性。
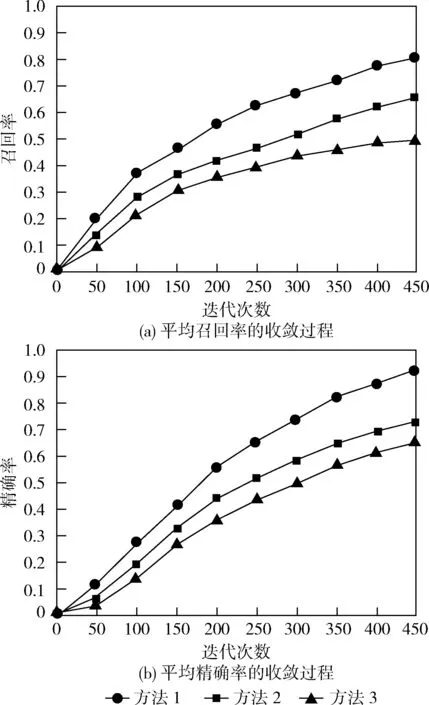
图3 平均召回率和平均精确率的收敛特性
4 结束语
在本文中,提出了一种有效的同时性图像标注和地理位置预测算法。方法基于超图学习,充分利用了图像内容、背景和社交媒体信息,而且通过执行组稀疏优化使得算法性能得到进一步提高;采用哈尔滨地标图像集合通过仿真实验对本文所提出的算法性能进行了评价和比较,结果表明,本文提出的算法在召回-精确率、平均F1测量值和位置正确预测率方面都是有效和可行的;本文提出的算法还可以适用于标注任何多媒体(如音乐和视频场景)以及它们之间的融合,对诸如基于图像和地理坐标的旅游指南系统或基于查询的推荐观光目的地系统的应用也有启发和借鉴意义。
