基于混合高斯和HOG+SVM的行人检测模型
2018-07-05龚露鸣徐美华刘冬军张发宇
龚露鸣, 徐美华,, 刘冬军, 张发宇
(1.上海大学微电子研究与开发中心,上海200072;2.上海大学机电工程与自动化学院,上海200444)
行人检测是机器视觉领域的研究热点,在智能监控、辅助驾驶、人机交互等系统中都有着广泛的应用,如超市中的人流量监测等.然而,由于在视频摄取过程中存在多种干扰,易导致图像分辨率低,特征信息不显著,再加上在实际情况下行人姿态多样化、复杂现实场景变动频繁等原因,故行人检测的准确率受到了较大的制约.
基于机器视觉的行人检测主要分为2个部分:运动目标区域提取和行人识别[1].目前,运动目标区域提取的主流算法有如下几种:①光流法[2-4].该方法在进行运动目标提取时,虽然无需预先知道场景信息,但易受光线变化影响,且计算量大,实时性差.②帧间差分法[5].通过直接比较相邻两帧之间对应的像素点值的变化,能简单快速地提取出运动目标,但该方法对噪声非常敏感,当目标运动较慢、形变较小或相邻帧重叠时,易出现运动目标的错提取或漏提取.③背景建模法[6].该算法具有简单易实现、提取结果完整、适合实时处理等优点,得到了广泛研究与应用,其中高斯模型是应用最为广泛的背景建模模型.在简单场景中,对于背景变化平缓的视频帧序列,单高斯背景模型取得了较好的效果[7];而在复杂场景下,由于环境突变,背景像素值呈多峰分布现象,故该模型无法建立相应的背景模型.Stauあer等[8-9]以单高斯背景模型为基础,提出了混合高斯模型(Gaussian mixture model,GMM),该模型能随背景不断变化,提高了算法的鲁棒性.本工作正是利用背景建模算法中的GMM进行了运动目标区域的提取,以此减小行人检测的搜索区域.
但是,以上提到的算法只能进行前景图像的提取,而无法识别其前景图像中所包含的信息类别.因此,为了快速构建前景图像并进行行人识别,本工作提出了一种基于混合高斯背景建模结合梯度方向直方图(histogram of oriented gradient,HOG)+支持向量机(support vector machine,SVM)的行人检测模型,该模型总体结构如图1所示.首先,将待检测的原始视频图像输入到运动目标区域后提取模块,利用混合高斯背景建模,提取其前景图像;然后,对前景图像进行去噪连通等处理,提取最终的运动目标区域;最后,对于行人识别部分,本工作对Dalal等[10]提出的HOG特征结合SVM分类器的方法,在正样本及检测窗口上做出适当的调整,在保证检测率不变的同时,大幅降低HOG特征维数,最终对运动目标区域进行行人识别,并在图像中将行人框出.
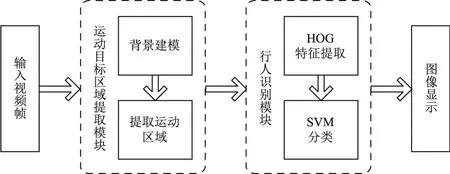
图1 模型总体结构Fig.1 General architecture of the model
1 基于混合高斯的运动目标区域提取
混合高斯背景建模是在复杂现实场景下前景图像提取的有效方法,但该方法会引入一些额外的干扰噪声,并且由于在得到的前景图像中,单个目标被分割成多个连通域,导致检测率的下降.因此,为保证检测率的不变,本工作对取得的前景图像进行去噪处理,最终以中心点不变原则进行区域连通以提取运动目标区域.
1.1 混合高斯前景分割
Stauあer等[9]提出的GMM如下:
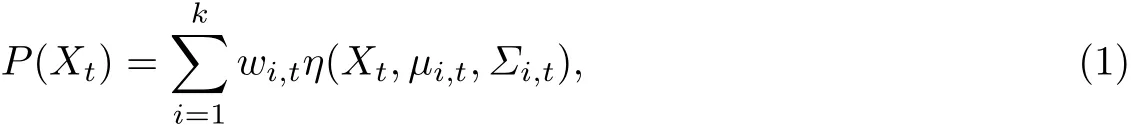
式中,Xt为t时刻像素点的像素值;K为高斯分布函数的个数,通常取3~5,其值越大,处理变化的复杂场景的能力越强,但计算量也越大;wi,t为t时刻第i个高斯分布模型的权重,满t时刻第i个高斯分布的均值;Σi,t为协方差矩阵;η为高斯密度函数,
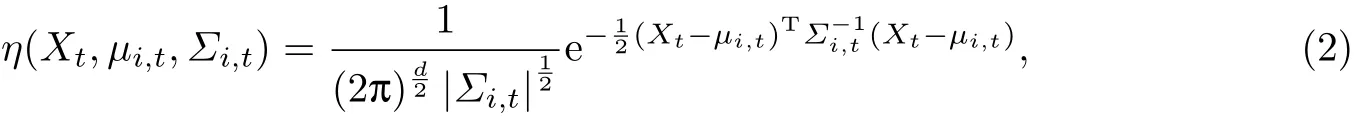
式中,d为Xt的维数.
由于现实场景会随时变化,因此模型参数需要不断地进行学习和更新,并与适合的高斯分布进行匹配,各参数更新公式如下:
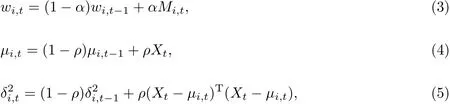
式中,α为权重学习参数,ρ=α/wi,t为参数学习率,为t时刻第i个高斯分布函数的方差.如果t时刻输入的像素值满足|Xt−µi,t−1|≤2.5δi,t−1,则认为该Xt是和第i个高斯分布是匹配的,记Mi,t=1;反之,则Mi,t=0.如果某像素点与所有的高斯分布均不匹配,则把该像素点视为前景点,并利用新的高斯分布取代权值最小的高斯分布,新分布均值为Xt,标准差为σ0,权重为w0.
在参数更新后,对所有高斯成分进行排序,取满足如下公式的前M个模型视为背景模型,其余的视为目标前景[9],当阈值T较小时,模型通常为单高斯模型;当T较大时,则采用多高斯分布.
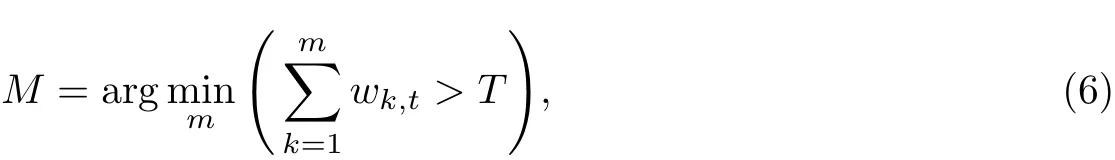
本工作采用GMM进行前景分割的实验结果如图2和3所示(图2为原始视频帧,图3为采用混合高斯提取的前景图像).从图中可以看到,GMM前景分割的效果是理想的,行人大致轮廓的提取较完整,边缘信息清晰.

图2 原始视频帧Fig.2 Original video frame

图3 前景提取结果Fig.3 Result of foreground extraction
1.2 基于多连通域的运动目标区域的提取
GMM前景分割效果理想,但同时也引入一部分噪声的干扰,这些噪声会使图像质量退化,导致目标识别检测率下降.常见的去噪方法有均值滤波和中值滤波,其中均值滤波会引起边界模糊和细节严重丢失等现象,而中值滤波不仅能消除孤立噪声点,还能较好地保留运动目标的边缘信息,计算量小,有助于提高运行速度.中值滤波的基本原理是以图像中某一像素点为原点,取其邻域内其他像素点灰度值的中间值,代替该像素点的初始值,其表达式为

式中,Sf(x,y)为f(x,y)的邻域,f(i,j)为所求像素点幅值.
通过将原始图像与背景图像进行差分运算可以得到前景图像.但由于滤波后的图像存在许多不连通域,如果直接与背景图像差分则会导致前景图像出现空洞,单个目标会被分成多个连通域,成为独立区域,进而造成漏识别,因此本模型对目标区域进行相应的融合,以保证运动目标区域提取的有效性.
首先,对去噪后图像的连通域提取外包络矩形框(见图4)可以发现,单个的行人目标被划分成多个连通域;随后,以中心点不变原则,将矩形框扩至扫描窗口的大小(见图5),大量矩形框将重叠在一起,对其进行二值填充,此时邻近框的重叠部分已将不连通域变成连通域,将填充后的图像再次视为连通域进行外包络矩形框的提取和二值填充,而小于扫描窗口的矩形域则可视为噪声点剔除;最终,所得运动目标区域如图6所示.

图4 连通域提取Fig.4 Extraction of connected domain
图5 目标区域融合Fig.5 Merging of objectives region

图6 运动目标区域提取Fig.6 Extraction of moving objective region
可见,混合高斯背景建模能有效地提取出视频帧中的前景图像,并针对出现的噪声以及单个目标多区域化等现象,采用中值滤波、中心点不变的连通域提取和目标区域融合等方法,完整地提取出所需的运动目标区域.
2 基于小样本的降维HOG+SVM行人识别
Dalal等[10]提出的HOG特征结合SVM分类器的方法具有较高的检测率,但计算量较大.本工作通过缩小正样本和检测窗口的大小,将3 780维HOG特征向量降为1 764维;并以INRIA数据库为基础,建立新的小样本库;最后通过样本库更新和二次训练SVM,得到最终分类器.
2.1 降维HOG特征提取
HOG[10-11]描述是利用梯度特征和边缘特征对目标进行描述,其特征的构建主要有如下4步.
(1)对输入图像进行颜色空间标准化,以减少光照以及复杂背景色带来的干扰.
(2)梯度计算.对于图像中的像素点(x,y),其梯度幅值G(x,y)和梯度方向Q(x,y)分别为

式中,Gx(x,y)和Gy(x,y)分别为水平方向梯度和垂直方向梯度,H(x,y)为输入像素点的像素值.
(3)构建降维的梯度方向直方图.本工作取单元格大小为8×8像素,梯度方向量化为9,即每个单元格需要一个9维向量来描述其梯度信息;块大小为16×16像素,即特征向量为2×2×9维;检测窗口从64×128像素缩小至64×64像素,以8像素为步长滑动检测,这样一个检测窗口内的特征维数从2×2×9×7×15的3 780维降低到了2×2×9×7×7的1 764维(见图7).
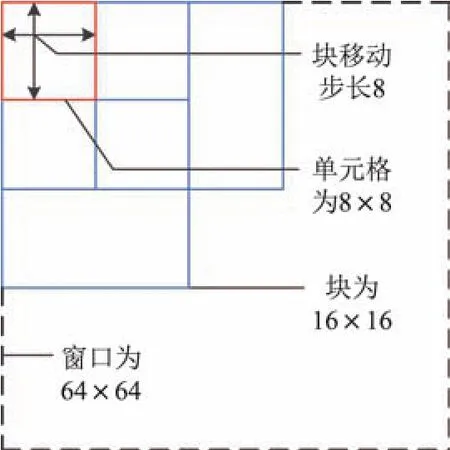
图7 HOG检测窗口Fig.7 Detection window of HOG
(4)区间归一化.由于局部光照的变化以及前景-背景对比度的变化,使得梯度强度的变化范围非常大[11],故在对单元格进行梯度强度计算后,再对邻近区域内的单元格进行局部归一化处理,可进一步保证检测效果.现有如下4种不同的方法,其中v表示为归一化前的向量,|v|k为v的k阶范数,ε为一个微小量,本工作采用L2-norm实现.
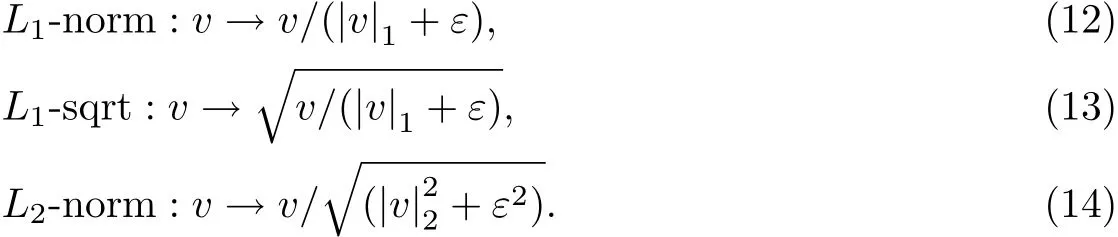
L2-Hys:利用L2-norm进行归一化后,将v最大值限制为0.2,再进行一次L2-norm归一化.
2.2 小样本库建立
在对SVM进行训练前,需要创建相应的样本库.本工作以INRIA数据库为基础,同时加入大量拍摄视频中的样本素材.为解决行人遮挡问题,对于站立的行人,只取行人的上半身作为正样本加以训练,并将其下半身加入到负样本中,所有训练正样本均裁剪成64×64像素大小,负样本大小不一,此为初步形成的样本库,部分样本集如图8所示.

图8 正负样本集部分示例Fig.8 Some examples of positive and negative sample sets
2.3 SVM分类器
SVM是一种监督式学习算法,由Cortes等[12]于1995年首次提出,常用来分析线性可分问题,即将线性不可分问题在高维特征空间转化成线性可分问题,构造出最优分类面[13-14].因此,该算法需要确定一个线性函数,在最大间隔超平面内将不同类别的样本分开.
设一个样本集为(Xi,Ti),i=1,2,···,k,Xi∈Rn,Xi为一个n维样本向量,Ti∈ {1,−1}为样本标签,1为正样本,−1为负样本.在n维空间中,线性可分的最优超平面为

式中,x为样本集Xi中的点,w为线性函数的法向量.
超平面需满足如下要求:能将所有的训练样本正确无误地分开,同时离超平面最近的训练样本到平面的间距最大,|w|2/2最小;满足所有样本点到超平面的距离大于1,
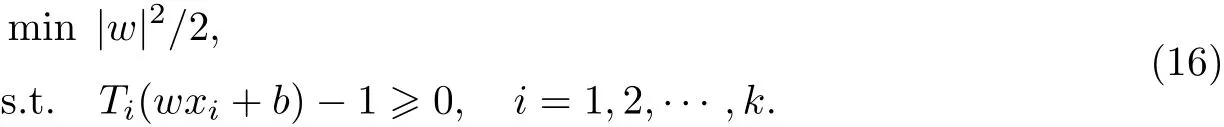
此外,通过引入非松弛变量ζi≥0,i=1,2,···,k,解决一些样本无法被正确分类的问题:
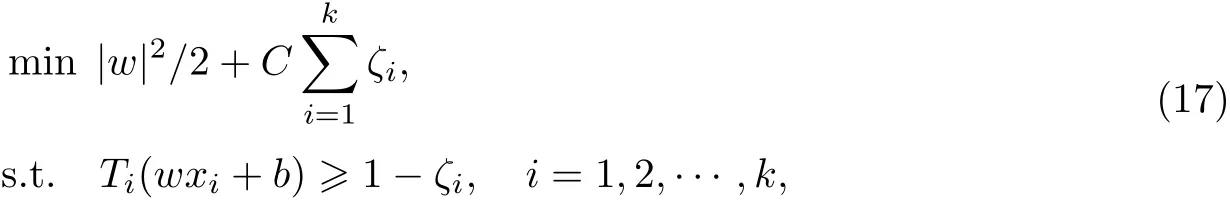
式中,C为惩罚因子,C越大则对错误的惩罚越严重.
将上述线性分类问题转换为一个凸二次规划问题.根据对偶条件,亦可以转化为对偶问题,约束条件为
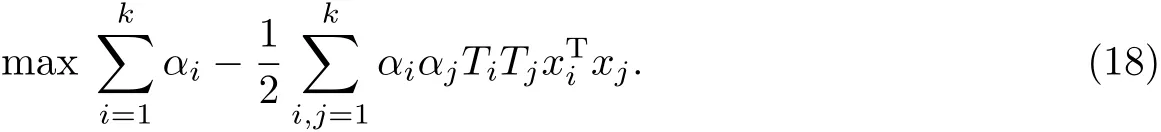
这样,可得到最优分类函数,其分类的阈值为b,
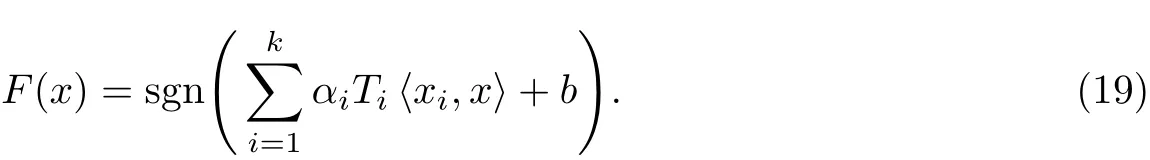
2.4 SVM训练及样本库更新
在本模型中,检测窗口大小为64×64像素,其HOG特征维数是1 764,为保证操作的实时性,选用线性核函数进行训练,其流程图如图9所示.首先,对于最终形成的样本库中所有的正负样本,提取其HOG特征,并给正样本添加标签1,负样本添加标签−1以区分;随后,将所得的HOG特征及标签输入到线性SVM中进行第一次训练,生成基本分类器;接着,用基本分类器对负样本进行识别,提取误识别区域,作为新负样本加入到原负样本集,形成最终样本库,该样本库包含3 000个正样本集和7 000个负样本集;最后,对更新后的样本集再次提取HOG特征,添加标签,输入SVM进行二次训练,生成最终分类器,以进行行人检测.
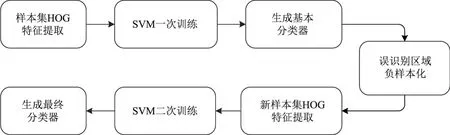
图9 SVM训练流程图Fig.9 Flowchart of SVM training
3 实验及结果分析
为了验证本模型的性能,训练样本采用的3 000个正样本(源于INRIA数据库中部分正样本以及视频中的行人)和7 000个负样本(源于INRIA数据库中部分负样本以及视频中的非行人场景),此外还加入部分基本分类器一次训练时的误识别区域.本行人检测模型的性能评估环境采用Microsoft Visual Studio 2010软件,检测得到的行人区域用红色矩形框标记,其结果如图10所示.图11为样本所属类别的定义.

图10 行人识别结果Fig.10 Result of pedestrian recognition
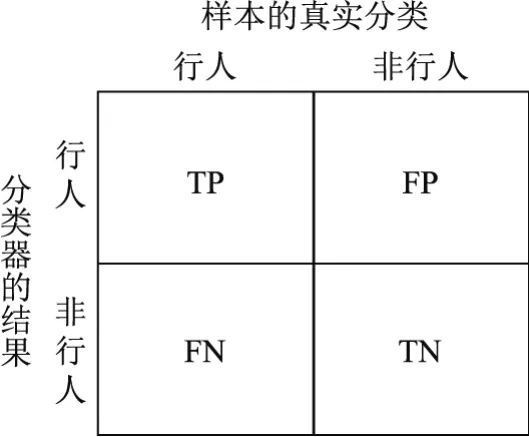
图11 样本所属类别的定义Fig.11 Def i nition of sample category
最后,在拍摄的视频中随机选取600帧,共含有待检测行人964人,将这些视频帧用文献[15]中改进的HOG特征模型与本模型分别进行行人识别,其部分识别结果分别如图12和13所示.同时,采用检测率和误检率来评估模型性能,其计算公式如式(20)和(21)所示.
根据式(20),(21)及图11,统计检测数据并计算得到表1.在表1中,检测数表示分别采用文献[15]和本模型检测到的行人数,包括正确检测的行人数,即真正样本(true positives,TP)数和不包含行人、但误检测为包含行人并标记的区域(false positives,FP)数;正确检测数表示分别采用文献[15]和本模型检测到的正确行人数,即真正样本数.

表1 文献[15]模型与本模型性能比较Table 1 Performance comparisons of model in Ref.[15]and this model
根据式(20)计算检测率,统计600帧图像中包含的所有TP与错误否定(false negatives,FN),将TP除以TP与FN之和,其比值即为检测率;误检率根据式(21)计算,统计600帧图像中包含的所有正确否定(true negatives,TN)与FP,将FP除以TN与FP之和,其比值即为误检率.


图12,13中的视频拍摄于一家小型超市.由于超市内物品繁杂,右侧更有杂志海报等印有众多的人物图像,故文献[15]的模型虽然具有较高的检测率,但误检率同样偏高,为8%;而本模型首先用GMM将待检测的视频帧进行前景提取,去除复杂场景的干扰,然后对前景图像进行去噪和连通处理,实现运动目标区域的提取,将搜索面积减少了50%以上,在保证检测率的前提下大幅降低误检率至4%,较大地提高了行人检测的准确率.此外,本工作还对模型的检测速率进行了统计,发现在不采用混合高斯进行运动目标区域提取的情况下,对整幅图像穷尽搜索以检测行人的速率为10帧/s左右;而采用混合高斯结合降维HOG+SVM模型的检测速率可达到20~30帧/s,部分检测速率如图14所示.

图12 文献[15]模型Fig.12 Model in Ref.[15]

图13 本模型Fig.13 This model
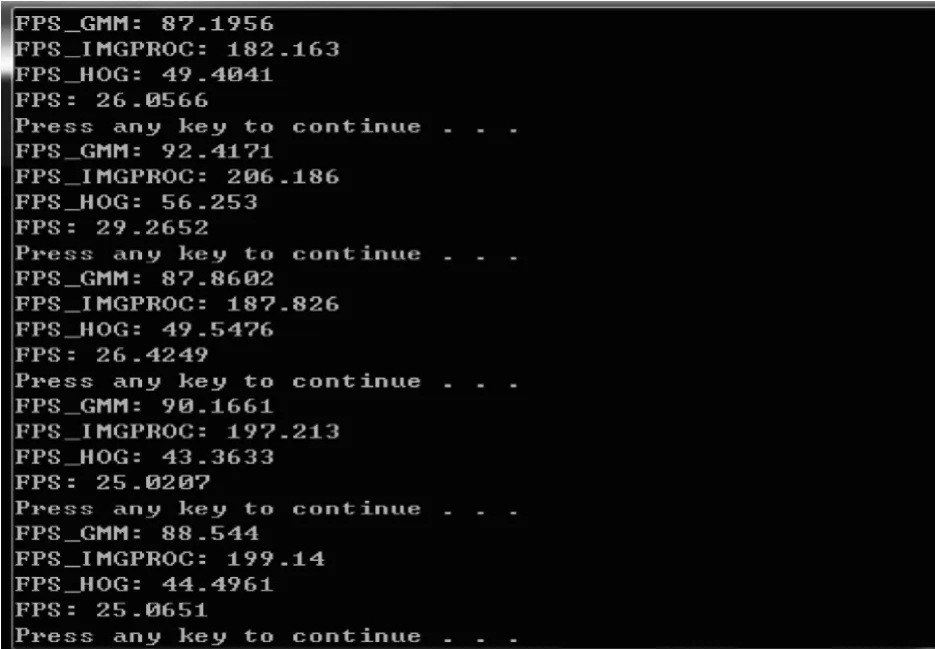
图14 本模型部分检测速率Fig.14 Part detection rates of this model
4 结束语
本工作提出了一种新的基于混合高斯结合HOG+SVM的行人检测模型.首先,该模型利用混合高斯进行前景分割,以提取运动目标区域,同时将搜索面积减小50%以上;随后,用缩小的检测窗口提取出降维的HOG特征;最后,用优化的SVM分类器在所提取的运动目标区域中进行行人判别.实验结果表明,在保证检测率和检测速率的前提下,该模型能有效实现在复杂场景下的行人检测,并将误检率降低至4%.
[1]许腾,黄铁军,田永鸿.车载视觉系统中的行人检测技术综述[J].中国图象图形学报,2013,18(4):359-367.
[2]SUN D,ROTH S,BLACK M J.Secrets of optical f l ow estimation and their principles[C]//2010 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).2010:2432-2439.
[3]张正鹏,江万寿,张靖.光流特征聚类的车载全景序列影像匹配方法[J].测绘学报,2014,43(12):1266-1273.
[4]杨亚东.光流法在运动目标识别领域的理论与应用[J].电子设计工程,2013,21(5):24-26.
[5]严晓明.一种基于改进帧差法的运动目标检测[J].莆田学院学报,2011,18(5):69-72.
[6]杨恒,王超,姜文涛,等.基于随机背景建模的目标检测算法[J].应用光学,2015,36(6):880-887.
[7]黄大卫,胡文翔,吴小培,等.改进单高斯模型的视频前景提取与破碎目标合并算法[J].信号处理,2015,31(3):299-307.
[8]BOUWMANS T,EL BAF F,VACHON B.Background modeling using mixture of Gaussians for foreground detection:a survey[J].Recent Patents on Computer Science,2008,1(3):219-237.
[9]STAUFFER C,GRIMSON W E L.Adaptive background mixture models for real-time tracking[C]//1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.1999:2.
[10]DALAL N,TRIGGS B.Histograms of oriented gradients for human detection[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.2005:886-893.
[11]徐超,高梦珠,查宇锋,等.基于HOG和SVM 的公交乘客人流量统计算法[J].仪器仪表学报,2015,36(2):446-452.
[12]CORTES C,VAPNIK V.Support-vector networks[J].Machine Learning,1995,20(3):273-297.
[13]郭明玮,赵宇宙,项俊平,等.基于支持向量机的目标检测算法综述[J].控制与决策,2014,29(2):193-200.
[14]溪海燕,肖志涛,张芳.基于线性SVM的车辆前方行人检测方法[J].天津工业大学学报,2012,31(1):69-73.
[15]田仙仙,鲍泓,徐成.一种改进HOG特征的行人检测算法[J].计算机科学,2014,41(9):320-324.本文彩色版可登陆本刊网站查询:http://www.journal.shu.edu.cn
