基于DEC算法的多标记学习
2018-07-03王一宾李闪闪裴根生
王一宾,李闪闪,裴根生
(1.安庆师范大学计算机与信息学院,安徽安庆246133;2.安徽省高校智能感知与计算重点实验室,安徽安庆246133)
聚类分析是机器学习[1]与数据挖掘领域中一种多元统计分析算法[2],在模式识别、图像处理、文本分析等领域有着广泛的应用。由于各领域数据本身的复杂性,聚类算法在处理低维数据时效果不错,但在高维空间,直接聚类存在一定的挑战。为了解决这一问题,将降维思想与聚类相结合解决实际问题的方法相继被提出[3],其中,PCAKM算法[4-5]、LDAKM算法[6]最为常见。而判别嵌入式聚类(Discriminative Embedded Clustering,DEC)算法[7]是一种聚类高维数据的整合框架,将降维与聚类迭代交替进行,规避了传统聚类算法存在的缺点。现今大数据时代,多标记学习已成为国内外机器学习领域的研究热点[8-9]。但在实际应用中,多标记学习会涉及许多高维数据。因此,鉴于DEC算法有效解决高维数据的特点,针对多标记学习中可能存在的“维度灾难”问题[10],本文提出基于DEC算法的多标记学习。
1 DEC算法
DEC算法[7]是一种集合多种维度约简算法处理高维数据的整合框架,而PCAKM算法(当平衡参数λ→0时)、OCMKM算法[11](当平衡参数λ=1时)、MMCKM算法[12](当平衡参数λ=2时),均可看做是DEC算法的特例,其基本差异在于平衡参数λ的取值不同。DEC算法包含维度约简函数和聚类损失函数两个目标函数。
DEC算法中维度约简部分,以MMC算法为例,对应目标函数描述如下:

其中,Q ∈ RD×d表示转换矩阵c(xj-xˉi)T为类内散布矩阵。这里高维空间数据{xi∈RD|i=1,2,…,n},对应到低维空间描述为{yi∈Rd|i=1,2,…,n},D和d分别指高维空间和低维空间对应的维度。

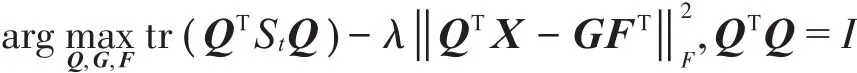
此处,与低维空间矩阵Y对应,X=[ X1,X2…,Xn]∈RD×n为高维空间的数据矩阵。
2 多标记学习
2.1 问题定义
假设有p维样本空间X=Rp,Y={ y1,y2,…,yq}表示包含q个不同的分类标签的标签属性。给定多标记数据集D=其中每一个xi=[xi1,xi2,…,xip]都是p维属性向量,Yi=[yi1,yi2,…,yiq]表示与xi相对应的一组标签向量。多标记学习主要就是在给定数据集D的情形下,构造一个多标记分类器,使得当输入待分类的实例属性xi∈X时,分类器f能够推测出从属于该实例的类别标记集合f(x) ⊆Y。
2.2 多标记学习评价指标
由于多标记学习框架中,每个对象同时属于多个类别标签,因此其性能评价指标与传统单标记学习有所不同。最为经典的多标记评价指标有平均查准率(Average Precision,AP)、覆盖率(Coverage,CO)、汉明损失(Hamming Loss,HL)、一错误率(One-Error,OE)、排位损失(Ranking Loss,RL)[8]等。设有预测函数f( )·,·,定义排序函数rankf( )·,·,若给定多标记测试集S=则各评价指标定义如下[8]。

AP用于评估全部样本的预测标记排序,排在相关标记之前的标记也属于相关标记的概率的平均。APS越大,分类性能越优,当APS(f)=1时,取得最好结果。
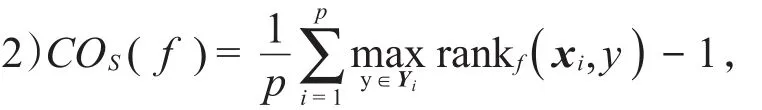
CO用于评估样本的预测标记排序,平均需要移动多少步才能覆盖样本的全部相关标记。COS(f)越小,分类性能越优,最好的分类结果为
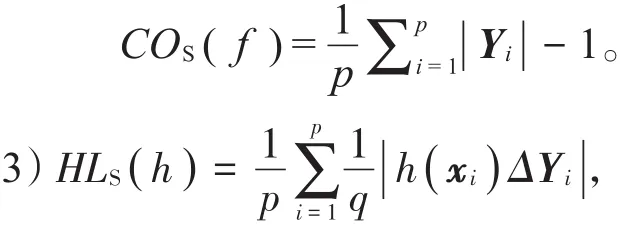
其中Δ表示两个集合之间的“对称差”,HL用于评估样本标签被错误分类的情况,即相关标记未出现在该样本的预测标签集中,而无关标记却出现在该样本的预测标签集中。HLS()h越小,分类性能越优,当HLS()h =0时,分类结果最好。

RL用于评估不相关标记排位高于相关标记排位的次数情况。RLS(f)越小,分类性能越优,当RLS(f)=0时,分类结果最优。

OE用于评估所有样本的预测标记排序,排在最前面的标记不属于该样本的相关标记集的次数情况。越小,分类性能越优,当0时,分类结果最好。
3 基于DEC算法的多标记学习
3.1 算法描述
多标记学习的主要任务是多标记维度约简和多标记分类,本文基于DEC算法,对数据做维度约简处理,训练多标记分类器,最后分析算法的实验性能。算法具体流程如下:
1)输入数据集以及平衡参数λ;
2)通过PCA等算法初始化转换矩阵Q,执行K-means算法计算QTX、初始化聚类指示器F;
3)交替更新Q,G,F直至收敛:通过某种比较准则更新聚类指示器F,根据计算第d个特征值对应的特征向量并更新转换矩阵更新聚类中心矩阵G;
4)输出转换矩阵Q及聚类指示器F;
5)设定最终聚类数目k以及特征维数d,得到约简数据集;
6)数据处理,划分训练集和测试集比例;
7)训练多标记分类器MLKNN(MLNB),输出各评价指标。
λ是平衡维度约简与聚类效果的参数,λ越大,表明越重视聚类的影响。λ=2时,算法性能较好,而且在λ=2时,DEC算法采用MMC算法代替其他维度约简算法,其鉴别准则为类间散布矩阵与类内散布矩阵的迹之差,避免了因矩阵不可逆而无法求解的问题[7,10]。因此本文取λ=2。对于不同的数据集,聚类数目k以及约简维数d设定值也不相同;d太大,无法降低数据冗余,d太小可能造成不同聚类间的重叠,因此需要多次试验以选择实验结果最优的取值。
3.2 计算复杂度分析
若将n个D维数据构成c类,则K-means算法的计算复杂度为O( n cD)。DEC算法分为特征分解以及聚类两个步骤,对应的计算复杂度分别为假定迭代次数为T,则DEC算法的计算复杂度为O((D2n+ncd)T)。由此看出,算法的计算主要在于特征分解部分,对于维度很高的大规模数据集,算法运行速度还有待提升。
4 实验及结果分析
4.1 实验数据
为了分析基于DEC算法的多标记学习算法的实验性能[13],本文共选取了5个公开的多标记数据集如表1所示,这些数据集全部来自http://mulan.sourceforge.net/datasets.html.,其基本信息描述如表1所示。

表1 多标记数据集
4.2 实验环境与方法
实验均在3.30 GHz的处理器、2.00 GB的内存、Windows7系统及Matlab R2012b的实验平台上运行。多标记分类方法参数值设定如下:
1)基于K近邻分类器的多标记学习算法[14](MLKNN),平滑参数设定s=1,近邻k=10;
2)基于朴素贝叶斯分类器的多标记学习算法[15](MLNB),平滑参数设定为默认值s=1。
实验主要分为两个部分,第一部分利用多次交叉验证的思想,先使用DEC算法对多标记数据集进行维度约简,然后分别采用MLKNN和MLNB分类,进行多次验证,对比未使用DEC算法直接分类的结果。第二部分将基于DEC算法的多标记学习与其他多标记维度约简方法PCA、MLKNN、MDDM[16]、PMU[17]等对比。为了便于对比,在DEC算法作降维处理前,先对数据集做两折离散化处理。
4.3 多次交叉验证结果与分析
为了分析DEC算法在多标记学习中的性能,实验采取多次验证。一个交叉验证是将样本数据集分成训练集和测试集两个互补的子集,然而训练和测试比例每次不同的划分结果,都会导致实验性能的差异。为了降低交叉验证结果的差异,对每个数据集做多次不一样的划分,得到不一样比例的互补子集,然后做多次验证,即训练集与测试集分别按照9∶1、8∶2、7∶3、6∶4、5∶5的比例进行实验,最终实验结果则选择了多次验证的均值。
表2分别给出在Arts,Health,Entertainment,Computers和Reference数据集上的算法实验结果。紧随每个评价指标之后的“↑”表示该评价指标取值越大,实验效果越好;“↓”则表示该评价指标取值越小,实验效果越好。表格中斜体加粗的数字则表示算法对数据集分类处理的效果更佳。

表2 不同数据集下算法分类性能对比
由表2可以看出,处理Arts数据集时,在分类之前利用DEC算法对多标记数据进行维度约简,再利用MLKNN进行分类处理,实验结果所得的5个多标记学习评价指标值都明显优于未使用DEC约简的分类结果。因此,基于DEC算法的多标记分类比MLKNN直接分类的效果更佳。利用MLNB算法进行多标记分类处理之前,如果先采取DEC算法对数据集进行维度约简,则AP、CO、HL这3个评价指标都明显优于未采取DEC算法的分类结果。由此可以得出,在处理诸如上述多标记数据集时,由DEC算法约简之后再分类,最终可以取得相对不错的实验结果。
4.4 多标记学习算法性能比较
该实验与5种多标记维数约简算法PCA、MLKNN、MDDMspc[16]、MDDMproj[16]以及PMU比较,同时以PMU离散化为标准,本次实验在进行特征降维前对数据进行了两折离散化处理。该实验训练MLKNN分类器处理约简后的数据集,同时选取AP、HL、RL、OE 4个评价指标评估实验结果。表3给出基于4个评价指标的算法分类性能对比,表格中斜体加粗的数字则表示算法对数据集分类处理的效果更佳,仅加粗的数字表示在对比算法中性能居于第二。
由表3可以看出,PCA算法仅在OE这一个评价指标占据优势,而从其他评价指标来看,PCA效果远远不及其他算法。在AP这一指标上,基于DEC的多标记学习算法(表3中将此算法表示为MLDEC)要明显优于其他5个算法;HL的取值仅在处理Entertainment这一数据集的实验对比结果不是很好;RL也只是处理Reference数据集的实验性能不及PMU算法。从评价指标OE可以看出,本文算法结果虽不如PCA,但却优于MLKNN、MDDMproj以及PMU等。因此,根据以上分析可得,基于DEC算法的多标记学习的实验结果整体较优,换句话说,DEC算法在多标记学习中的应用是可行的。
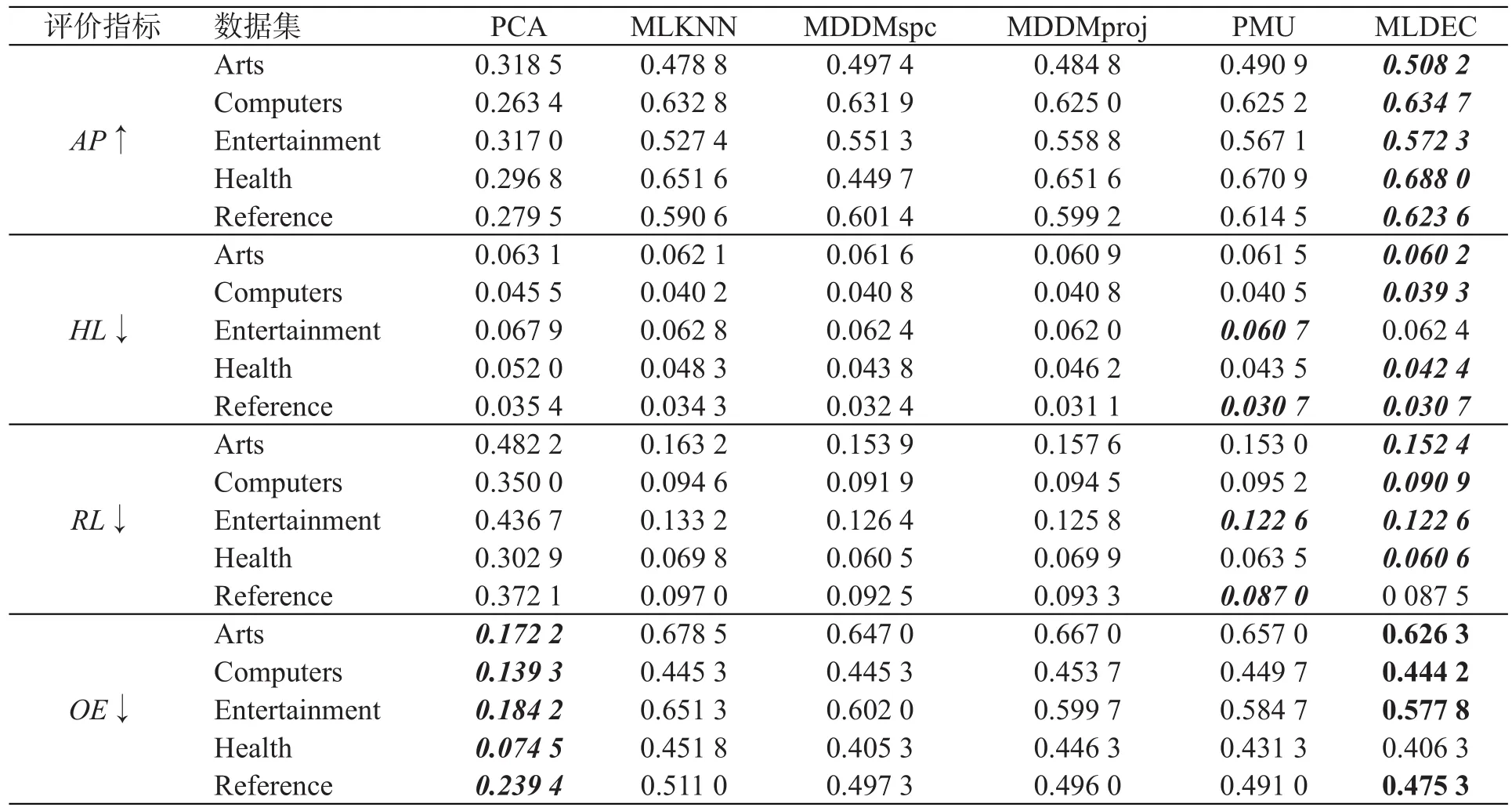
表3 各评价指标下算法分类性能对比
5 总结
本文提出的基于DEC算法的多标记学习,即首先采取判别嵌入式聚类(DEC)算法对多标记数据集进行降维处理,对降维后的数据再采取MLKNN和MLNB多标记分类方法进行分类处理。与未采取DEC算法的多标记分类以及其他多标记维度约简算法对比结果表明,基于DEC算法的多标记学习在一定程度上提升了多标记数据的分类性能,但是,对不同的多标记数据集,采取DEC算法作维度约简处理时,数据集约简的维数以及聚类的类别数目会影响最终的分类性能。因此,下一步研究计划提出一种能自动计算出最恰当的聚类数和约简维数的算法,从而使分类器性能达到最优。
[1]MITCHELL T M.Machine learning[D].New York:McGraw-Hill,1997.
[2]范明,孟小峰.数据挖掘概念与技术[M].北京:机械工业出社,2012:48.
[3]徐勇,陈亮.一种基于降维思想的K均值聚类[J].湖南城市学院学报,2017,26(1):55-61.
[4]师黎,杨振兴,王治忠,等.基于PCA和改进K均值算法的动作电位分类[J].计算机工程,2011,37(16):182-184.
[5]潘巍,周晓英,吴立峰,等.基于半监督K-Means的属性加权聚类算法[J].计算机应用与软件,2017,34(3):190-193.
[6]DELA T F,KABADE T.Discriminative c1uster analysis[C].International Conference on Machine Learning,New York:ACM,2006:241-248.
[7]HOU C P,NIE F P,TAO D C.Discriminative embeded clustering:A general framework for grouping high dimensional data[J].IEEE Transactions on Neural Networks&Learning Systems,2015,26(6):1287-1299.
[8]ZHANG M L,ZHOU Z H.A review on multi-label learning algorithms[J].IEEE Trans on Knowledge and Data Engineering,2014,26(8):1819-1837.
[9]余鹰,多标记学习研究综述[J].计算机工程与应用,2015,51(17):20-27.
[10]燕凯.多标记维度约简和分类算法研究[D].重庆:重庆大学,2014.
[11]卢桂馥,邹健,陈富春.一种求解MMC的快速算法[J].安徽工程大学学报,2014,29(4):57-62.
[12]支晓斌,燕华芳.改进的判别嵌入式聚类算法[J].西安邮电大学学报,2017,22(1):34-37.
[13]刘景华,林梦雷,王晨曦,等.基于局部子空间的多标记特征选择算法[J].模式识别与人工智能,2016,29(3):240-251.
[14]ZHANG M L,ZHOU Z H.ML-kNN:a lazy learning approach to multi-label learning[J].Pattern Recognition,2007,40(7):2038-2048.
[15]ZHANG M L,ROBLES V.Feature selection for multi-label naive bayes classification[J].Information Sciences,2009,179:3218-3229.
[16]ZHANG Y,ZHOU Z H.Multi-label dimensionality reduction via dependency maximization[J].ACM Transactions on Knowledge Discovery from Data,2010,4(3):14-24.
[17]LEE J,KIM D W.Mutual information-based multi-label feature selection using interaction information[J].Expert Systems withApplications,2015,42(4):2013-2025.
