基于Spark Streaming的在线KMeans聚类模型研究∗
2018-04-26侯敬儒李英娜
侯敬儒 吴 晟 李英娜
(昆明理工大学信息工程与自动化学院 昆明 650500)
1 引言
相比离线计算,在线学习是以对训练数据通过完全增量[1]的形式顺序处理一遍为基础(就是说,一次只训练一个样例)。当处理完每一个训练样本,模型会对测试样例做预测并得到正确的输出(如得到分类的标签后者回归的真实目标)。在线学习背后的想法就是模型随着接收到新的消息不断更新自己[2~3],而不是像离线训练一次次重新训练。
在完全在线环境下,我们不会(或者也许不能)对整个训练集做多次训练,因此当输入到达时我们需要立刻处理。在线方法还包括小批量离线方法[4],并不是每次处理一个输入,而是每次一个小批量的训练数据。Spark Streaming[5]作为 Spark 框架中专门处理实时数据的模块,就是采用这种微批处理思想来达到准实时计算的目的[6]。
聚类分析[7]是一种数据挖掘领域中常用的无监督学习模型,旨在发现紧密相关的观测值群组,使得与属于不同簇的观测值相比,属于同一簇的观测值相互之间尽可能相似[8],在识别数据的内在结构方面具有极其重要的作用[9]。但其复杂度一般较高,所以单机环境执行存在低吞吐、高延迟等问题,难以适应当下大数据环境,故而通过分布式并行计算来解决此类问题。文章采用了KMeans聚类算法,实现KMeans算法的并行化,并研究设计实现了基于Spark Streaming的在线KMeans聚类模型。
2 Spark Streaming流式计算框架研究
2.1 Spark Streaming处理流程
Spark Streaming是Spark计算框架中专门处理实时数据流的模块,它能实现对实时流数据的高吞吐、高容错率[10]的流处理。
Spark Streaming的处理流程是当Spark Stream⁃ing接收到来自数据源的实时输入数据后,将数据按照指定大小划分为若干个数据片段DStream(DStream是Spark Streaming的基本抽象,是一系列RDDs组成),并将每个片段转化为RDDs,然后由Spark Enigne对DStream中的RDDs进行批处理,将RDD经过变换等操作后的中间结果缓存在内存中,最终实现大规模的流处理。Spark Streaming的处理流程图如图1所示。
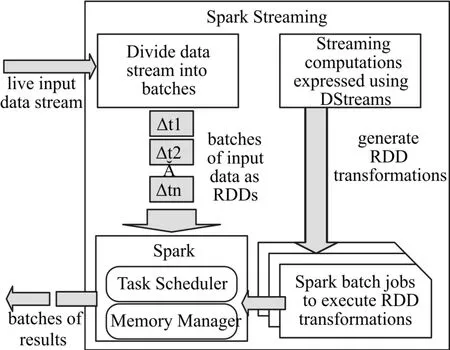
图1 Spark Streaming的处理流程图
目前,Spark Streaming支持最小的Batch Size是0.5s~2s之间,所以Spark Streaming能满足除对实时性要求非常高之外的所有流式实时处理要求。
2.2 Spark Streaming内部实现原理
使用Spark Streaming编写的程序与编写Spark程序非常相似,在Spark程序中,主要通过操作RDD(Resilient Distributed Datasets,弹性分布式数据集)提供的接口,如map、reduce、filter等,实现数据的批处理。而在Spark Streaming中,则通过操作DStream(表示数据流的RDD序列)[11]提供的接口,这些接口和RDD提供的接口类似。图2和图3展示了由Spark Streaming程序到Spark jobs的转换图。
在图2中,Spark Streaming把程序中对DStream的操作转换为DStream Graph,图3中,对于每个时间片,DStream Graph都会产生一个RDD Graph;针对每个输出操作(如 print、foreach等),Spark Streaming都会创建一个Spark action;对于每个Spark action,Spark Streaming都会产生一个相应的Spark job,并交给 JobManager。JobManager中维护着一个Jobs队列,Spark job存储在这个队列中,JobManager把 Spark job 提 交 给 Spark Scheduler,Spark Scheduler负责调度Task到相应的Spark Ex⁃ecutor上执行。
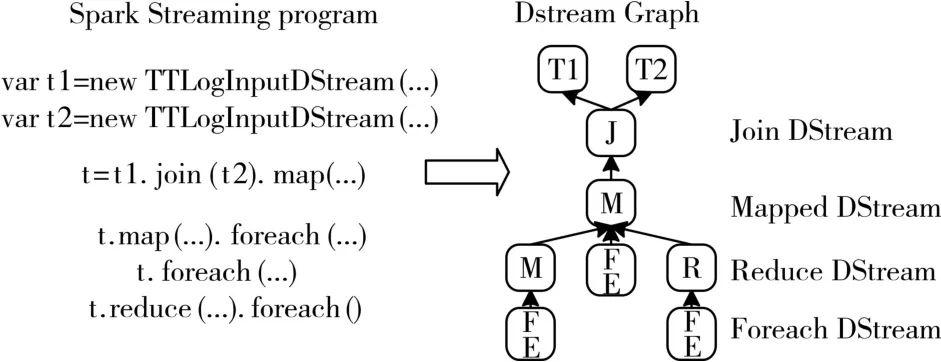
图2 Spark Streaming程序转换为DStream Graph
Spark Streaming的另一大优势在于其容错性,RDD会记住创建自己的操作,每一批输入数据都会在内存中备份,如果由于某个结点故障导致该结点上的数据丢失,这时可以通过备份的数据在其它结点上重算得到最终的结果。
正如Spark Streaming最初的目标一样,它通过丰富的API和基于内存的高速计算引擎让用户可以结合流式处理,批处理和交互查询等应用。因此Spark Streaming适合一些需要历史数据和实时数据结合分析的应用场合[12]。当然,对于实时性要求不是特别高的应用也能完全胜任。另外通过RDD的数据重用机制可以得到更高效的容错处理。
3 基于Spark Streaming的在线KMeans聚类模型
3.1 KMeans聚类算法原理
KMeans均值算法的思想一般是先初始化随机给定K个clusters(簇)中心,将待分类的样本数据点依照最近邻原则分配到各个cluster中。之后以一定法则重新计算各个cluster的质心,以确定新的cluster。不停的循环计算,直到cluster的质心移动距离小于某一个实际给定的具体值。
KMeans均值聚类算法“三步走”如下简介:1)寻找待聚类的样本数据点的聚类中心。
2)计算每个样本数据点到之前寻找到的聚类中心的距离,将每个样本数据点聚类到离该样本数据点最近的聚类中去。
3)计算每个聚类中所有样本数据点坐标的平均值,然后将这个计算的平均值作为新的聚类中心。
循环执行第2)、3)步,一直计算到新的聚类中心移动距离小于某个给定的具体值或者聚类次数达到了设定值为止。
3.2 基于Spark Streaming的在线KMeans模型实现
3.2.1 数据接入模块
文章利用分布式“准”实时计算框架-Spark Streaming进行实时数据的KMeans在线聚类,以下是数据接入部分的实现。
通过StreamingContext实例调用socketText⁃Stream方法实现数据接入。该方法会从一个TCP源创建一个输入数据流。其使用TCP套接字接收数据,并且以UTF-8编码方式、换行符( )为分隔符接收字节。socketTextStream需要传递三个参数,分别是hostname(接收数据的主机名)、port(接收数据的端口号)、storageLevel(用做存储接收数据的存储级别,默认是MEMORY_AND_DISK_SER_2级别)。以下是socketTextStream方法的详细定义。
def socketTextStream(
hostname:String,
port:Int,
storageLevel:StorageLevel=StorageLevel.MEM⁃ORY_AND_DISK_SER_2
):ReceiverInputDStream[String]=withNamed⁃Scope(“socket text stream”){
socketStream[String](hostname,port,SocketRe⁃ceiver.bytesToLines,storageLevel)
}
调用示例:val trainingData=ssc.socketTextStream(“192.168.1.100”,8341,StorageLevel.MEMO⁃RY_AND_DISK_SER_2).map(Vectors.parse)
3.2.2 主函数
作为程序入口,主函数的任务是设置Job执行的相关参数,步骤如下:
1)设置程序运行名称、执行集群的Master、相关jar包等实例化SparkConf对象
val conf=new SparkConf()
.setAppName(“StreamingKMeansModel”)
.setMaster(“yarn-cluster”)//spark://hjr:7077
2)通过SparkConf对象和batchDuration参数实例化StreamingContext对象
val ssc=new StreamingContext(conf,Seconds(args(2).toLong))
3)通过 StreamingContext的对象的 socketText⁃Stream方法实现数据接入
val trainingData = ssc.socketTextStream(“192.168.1.100”,8341,StorageLevel.MEMO⁃RY_AND_DISK_SER_2)。map(Vectors.parse)
4)设置相关参数,实例化StreamingKMeans模型
val model=new StreamingKMeans()
.setK(args(3).toInt)
.setDecayFactor(1.0)
.setRandomCenters(args(4).toInt,0.0)
5)使用实时数据训练模型
model.trainOn(trainingData)
6)启动流执行,并等待执行停止
ssc.start()
ssc.awaitTermination()
4 实验与分析
文章实验基于QJM(Quorum Journal Manager)下的HA(High Available)大数据平台,其中,以Ha⁃doop的HDFS为基础存储框架,主要以Spark为计算框架,使用Zookeeper统筹HA下的大数据平台,管理整个集群配置。平台包括2个Master节点和3个Worker节点,节点之间局域网连接;平台的资源管理和任务调度采用Yarn模式。
集群网络配置如表1所示。

表1 网络配置
集群的各个服务组件配置情况如表2所示。
4.1 Spark集群吞吐能力分析
文章这组实验是比对Java单机环境和基于Spark的分布式集群环境的吞吐能力,吞吐量(吞吐能力测试指标)是指系统在单位时间内处理数据的数量。实验不停的增加Application执行的数据量,步长为50万条记录,统计数据处理完成所需时间,单位为秒(s)。考虑到结果的准确度,此组实验数据均是经过3次试验结果的平均值,具体如图4所示。

表2 各个服务组件版本配置信息
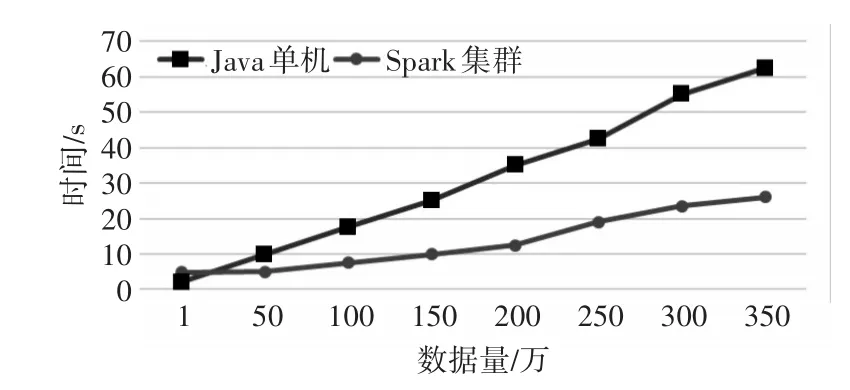
图4 Java单机和Spark集群运行时间对比
由图4实验结果分析:刚开始数据量较小的时候,Spark集群计算需要消耗更多的时间,这种结果的原因是Spark Application在分布式集群运行的时候需要通过网络传输数据、分发任务,故而消耗了一部分集群资源和时间。
随着数据量的成倍增长,Spark分布式集群的处理时间显著缩短。这是因为在Spark内部计算Jobs是由不同的executor(一个执行Task的容器)在集群的worker计算节点中分布式执行。由图4分析,当数据量稍大时,Java单机环境下已经需要很长时间了,可见若数据量呈现指数级增长时,Java单机处理时间将不能够忍受,但是基于Spark的分布式集群规模还可以继续横向扩展,对于大数据量的处理需求依然游刃有余。
4.2 数据处理延迟分析
该组实验中,定义的数据延迟是从一条数据(Event)发出到其被完全处理的时间,文章通过Spark Streaming的Web UI界面查看处理延迟。数据处理延迟和处理模块的并行度有关,也就是该实验下集群的Worker数量有关,Worker节点数越多,Spark Streaming接受的Events等待被处理的时间就越短,故而延迟就越小,以下是对比实验。
将Spark Streaming的数据源设置为2,Receiv⁃ers设置为1,程序分别在Worker节点数为1、3上执行情况如图5~6所示。

图5 Worker数量为1
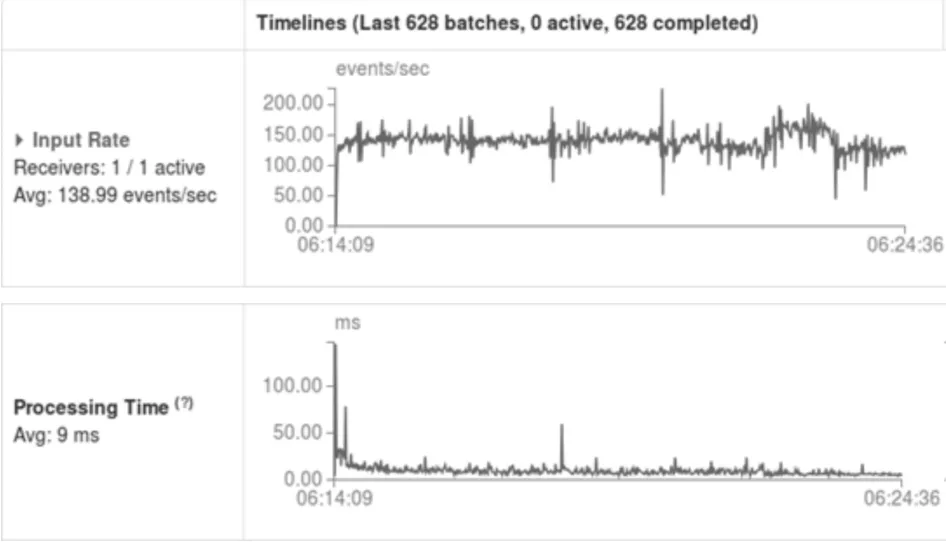
图6 Worker数量为3
从上图可以看出:当在线KMeans聚类模型的数据源数目为2,Worker数为1时,会有部分数据处理延迟在100ms~800ms之间,这是因为当数据源数目为2,两个数据源不停生成新数据,而在线KMeans聚类模型不能够及时处理数据,从而数据会有些许积累,因而会有部分数据处理延迟。当在线KMeans聚类模型的并行度增加到3(Worker数量)时,绝大部分的处理延迟都在50ms以内,这就说明两个数据源产生的数据被Spark Streaming很快处理完了。
根据业务实际情况设置数据源数目和Spark Streaming的并行度以及任务需要的CPU Cores、Memory等是优化Spark Streaming性能的重要途径,要根据计算任务合理分配,最大限度发挥了Spark Sreaming的并行处理能力。
5 结语
基于在线计算与机器学习的结合使用需求,引入了Spark Streaming准实时计算框架,设计并编程实现了基于Spark Streaming的KMeans在线聚类模型,最后通过集群吞吐、处理延迟分析了集群的性能,集群运行状况良好。
接下来的工作中,将对Spark2.0的Structured Streaming、流数据处理结果的可视化展开研究,从而达到数据流的产品化。
[1]赵玲玲,刘杰,王伟.基于Spark的流程化机器学习分析方法[J].计算机系统应用,2016,25(12):162-168.ZHAO Lingling,LIU Jie,WANG Wei.Method of Imple⁃ment Machine Learning Analysis with Workflow Based on Spark Platform[J].Computer Systems&Applications,2016,25(12):162-168.
[2]金瑜.在线学习算法及其应用研究[D].西安:西安电子科技大学,2012.JIN Yu.Study of Online Learning Algorithms with Applica⁃tions[D].Xi'an:Xidian University,2012.
[3]吴健,陈克寒,吉利川,等.一种基于用户聚类的sky line在线计算方法:CN,CN 103150336 A[P].2013.WU Jian,CHEN Kehan,JI Lichuan,et al.A kind of based on user clustering sky line online calculation method:CN,CN 103150336 A[P].2013.
[4]武海丽,李彩玲.基于Google云计算的在线学习系统设计研究[J].山西煤炭管理干部学院学报,2016,29(4):214-216.WU Haili,LI Cailing.The online learning system design based on Google's cloud computing research[J].Journal of Shanxi Coal-Mining Administrators College,2016,29(4):214-216.
[5]赖小平.基于Logistic回归的在线广告并行运算模型[J].计算机工程,2015,41(8):42-45.LAI Xiaoping.Online Advertising Parallel Operation Mod⁃el Based on Logistic Regression[J].Computer Engineer⁃ing,2015,41(8):42-45.
[6]尹清波,王慧强,张汝波,等.半监督在线增量自学习异常检测方法研究[J].计算机研究与发展,2006(z2):419-424.YIN Qingbo,WANG Huiqiang,ZhANG Rubo,et al.Semi-Supervised Increment Anomaly Detection[J].Jour⁃nal of Computer Research and Development,2006(z2):419-424.
[7]张贤德.基于Spark平台的实时流计算推荐系统的研究与实现[D].镇江:江苏大学,2016.ZHANG Xiande.Research and Implementation of Real Time Stream Computing Recommendation System Based on Spark Platform[D].Zhenjiang:Jiangsu University,2016.
[8]岑凯伦,于红岩,杨腾霄.大数据下基于Spark的电商实时推荐系统的设计与实现[J].现代计算机,2016(24):61-69.CEN Kailun,YU Hongyan,YANG Tengxiao.Design and Implement of E-Commerce Real-Time Recommender Sys⁃tem with Spark Based on Big Data[J].Modern Computer,2016(24):61-69.
[9]胡俊,胡贤德,程家兴.基于Spark的大数据混合计算模型[J].计算机系统应用,2015,24(4):214-218.HU Jun,HU Xiande,CHEN Jiaxing.Big Data Hybrid Computing Mode Based on Spark[J].Computer Systems&Applications,2015,24(4):214-218.
[10]陈侨安,李峰,曹越,等.基于运行数据分析的Spark任务参数优化[J].计算机工程与科学,2016,38(1):11-19.CHEN Qiaoan,LI Feng,CAO Yue,et al.Parameter opti⁃mization for Spark jobs based on runtime data analysis[J].Computer Engineering and Science,2016,38(1):11-19.
[11]薛瑞,朱晓民.基于Spark Streaming的实时日志处理平台设计与实现[J].电信工程技术与标准化,2015(9):55-58.XUE Rui,ZHU Xiaomin.Real-time log processing sys⁃tem based on spark streaming[J].Telecom Engineering Technics and Standardization,2015(9):55-58.
[12]方峰,蔡志平,肇启佳,等.使用Spark Streaming的自适应实时DDoS检测和防御技术[J].计算机科学与探索,2016,10(5):601-611.FANG Feng,CAI Zhiping,ZHAO Qijia,et al.Adaptive Technique for Real-Time DDoS Detection and Defense Using Spark Streaming[J].Journal of Frontiers of Com⁃puter Science&Technology,2016,10(5):601-611.
