基于数据压缩的单字替换密码破译算法∗
2018-04-26钱宇环范洪博
钱宇环 范洪博
(昆明理工大学信息工程与自动化学院 昆明 650500)
1 引言
替换式密码是密码学中按规律将文字加密的一种方式[1]。替换式密码中可以用不同字母数为一单元,例如每一个或两个字母为一单元,然后再作加密。密文接收者解密时需用原加密方式解码才可取得原文本。单字母加密是实际中经常采用的一种,可以利用移位、仿射等方式实现。由于拼音文字中字的组成为有限的字母,以英语为例只有26个字母,组成可能的单元数较少,因此使用替换式密码相对较为容易,而且亦可使用简单机械进行加密;相反,非拼音文字如中文则因单元数非常大难以使用一般加密方式,必需建立密码本,然后逐字替换。更何况某些非拼音文字中字字皆由不同大小的字根来组字,较难转换,因此使用替换式密码的示例比较少[2]。
密文是利用单字母加密方法加密的,加密后,单词之间的间隔和标点符号全部被删去。在传输过程中,密文存在被丢失、添加和篡改字符的可能。本文对此设计了一个能够自动化破译密文的算法。该算法能够有效地避免错误字符对真实字符的影响,破译时误识别的概率很低,下文将详细介绍该算法。
2 破译算法设计
2.1LZW算法原理
LZW算法的基本原理[3~4]是根据原始文本文件中的不同字符,创建一个编码表。编码表中有两个属性,一个是字符本身,还有一个是字符的索引,然后用编码表中的字符的索引来替代原始文本文件中的相应字符,来减少原始数据大小。
当对大量真实文本进行压缩的时候,由于英语固有的语法特性和词汇特性,那些被索引替换的字串往往都是一个单词或者一个词组,它是具有真实语义的,对于那些无意义的字串在编码表中出现的频率会很小,所以当利用LZW对那些疑似明文进行压缩的时候,那些错误的明文里面的字串大多是无意义的,压缩的时候基本不被编码表中的索引所替换。而正确的明文里面会有大量有意义的字串在编码表中得到匹配,所以经过压缩后的文本长度相较错误的压缩明文会短了很多。
2.2 破译算法
首先,根据大量英文文献统计得到的英文字频表[5~6],可以得出一般英文文献中字母的频率分布。如下表1。

表1 英文字频表
该英文字频表即为后面算法设计的参照表,它代表了真实文本中字母的频率分布。
由上述表格,可以将不同频率的字母分为以下几组,如表2。算法流程图如图1所示。

表2 不同频率的字母分组
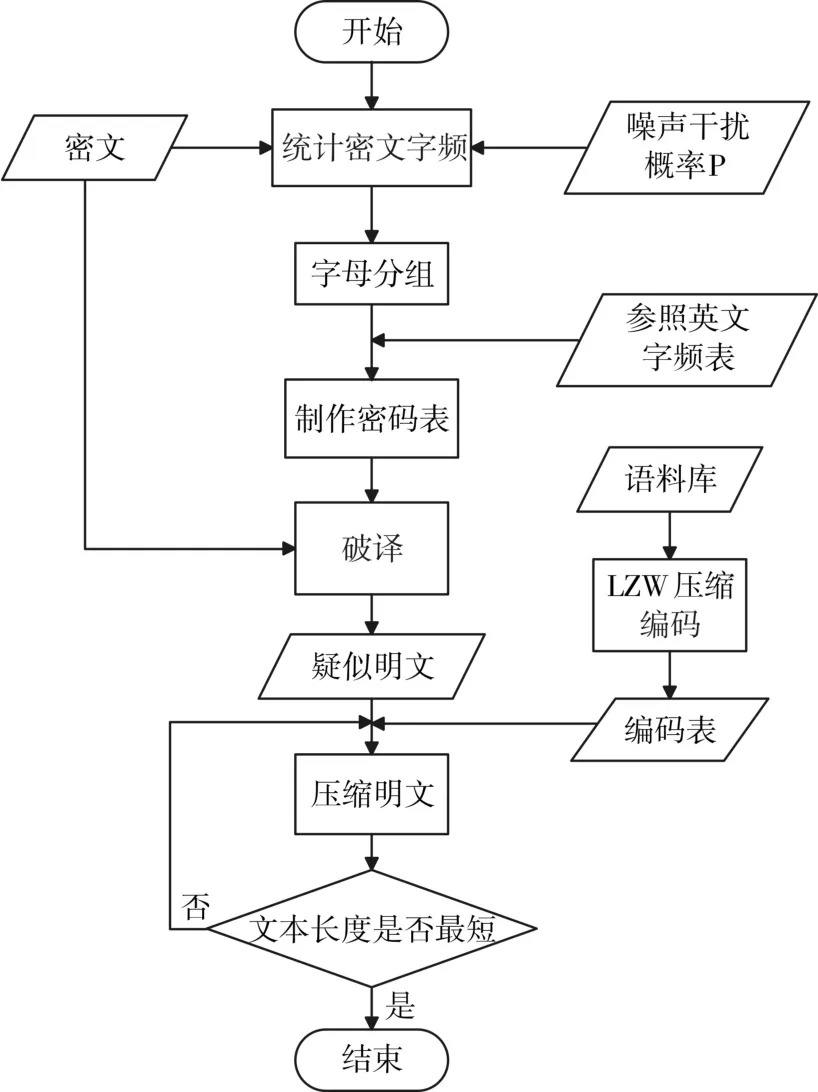
图1 破译算法流程图
算法详细步骤如下:
第一步:得到密文后,统计密文中的字母频率。
这里针对coca的语料库里面w_acad_1990.txt进行测试。先对该文本文件进行加密,
图2为明文和加密后的密文。
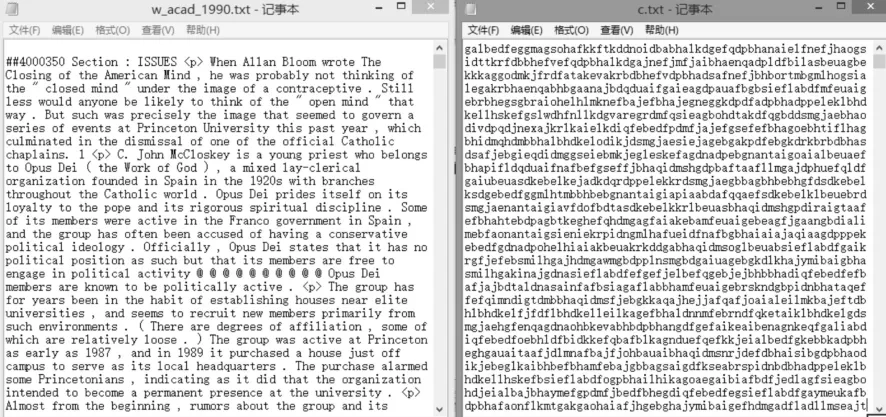
图2 明文(左)与密文(右)
经过程序统计得到密文的字频如图3。
这里由假设知密文有一定概率经过噪声的干扰,但是噪声和文本之间是相互独立的[5],而且假设噪声不会超过一定的限度,所以对字母的频率的影响不是很大,可以由噪声对字母影响的概率计算出受干扰之后的字频[7]。
以字符e为例来进行说明。已知在英文文章中,没有干扰的情况下各字符出现的频率为Px,字符e出现的概率记为Pe,文章中的字符个数记为N。在有噪声干扰情况下传输字符时,丢码率为P1,增码率为P2,误码率为P3。正常传输的概率为1-P1-P2-P3。根据以上信息,可以计算出字符e出现的频率。
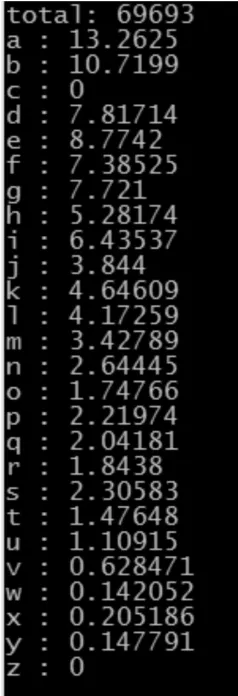
图3 密文的字母频率
1)在误码率P3的情况下,e字符出现的概率为Pe':
Pe'=Pe*P3(1-1/26)+(1-Pe)*P1*(1/26)
2)在增码率P2,丢码率P1的情况下,e字符出现的概率Pe':
Pe'=[Pe*N*P2*(1/26)]/N*(1+P2-P3)
第二步:由第一步中得到的密文的字母频率,对其字母进行分组[8],分组的依据如下(频率f):
极高频率字母组(f>10)
次高频率字母组(6<f<10)
中等频率字母组(4<f<6)
较低频率字母组(1.5<f<4)
甚低频率字母组(f<1.5)
根据以上准则,对密文进行分组,如图4所示。

图4 不同频率字母的分组
第三步:由第二步中得出的字母分组,对每个分组求其全排列。得出可能的排列数。如图5所示。

图5 每个分组的全排列数
第四步:根据不同的排列情况,制作出相应的疑似密码表,由于数量众多,这里不一一列举,
第五步:根据对应的疑似密码表可以生成若干的疑似明文。
第六步:利用LZW算法对大量真实文本进行压缩[9~10],并截取其中的压缩编码表。
LZW算法流程图如图6所示。
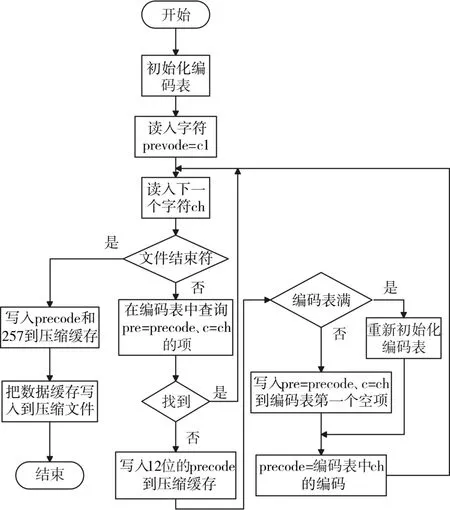
图6 LZW算法流程图
图6中precode为临时前向编码索引。
经过对大量真实文本,例如近十年的华尔街日报或者经济学人,对其进行压缩之后可以得到一个LZW编码表。在下一步中就要利用这个表来对明文进行验证。
第七步:利用上一步得到的LZW编码表对前面得到若干疑似明文进行压缩,最终长度最短的即为真实明文。
3 结果分析
实验选取了四组不同的文本进行对比,分别为英文论文、新闻、书籍、小说,主要测试内容为破译算法的准确度,即明文与破译后的文本相似度,实验结果如下表3所示。

表3 不同材料的破译准确度
可以看出在论文的测试当中,准确率明显不如其他三项,经过分析得出,论文中存在的专业术语比较多,所以基于频率分析的算法不能准确地还原这些不常见的词汇,使得破译过程中可能会存在一定的误差。其他一些材料则可以保持比较高的准确度。
4 结语
本文中提出的是基于LZW压缩的频率分析的算法,经过文中的理论和实验分析,压缩算法在效率上是非常高的。该算法实际应用中会存在一定的缺陷,在分组的过程中,如果有两个相似字母正好处于分界的地方,使得它们在不同的组,就有可能得出错误的密码表,即便后面采用了准确性非常高的LZW压缩编码来进行验证,也不能得出正确的明文,所以这里是有待改进的地方。
[1]Paul Garrett.密码学导论[M].北京:机械工业出版社,2013:1-48.Paul Garrett.Cryptography guidance[M].Beijing:Me⁃chanical Industry Publishing House,2003:1-48.
[2]雷新锋.密码协议分析的逻辑方法[M].北京:科学出版社,2013:1-12.LEI Xinfeng.Password logic method of protocol analysis[M].Beijing:Science Press,2013:1-12.
[3]KhalidSayood,萨尤得,贾洪峰.数据压缩导论[M].北京:人民邮电出版社,2014.KhalidSayood,JIA Hongfeng.Introduction to Data Com⁃pression[M].Beijing:Posts&Telecom Press,2014.
[4]吴家安.数据压缩技术及应用[M].北京:科学出版社,2009.WU Jiaan.Data compression technology and application[M].Beijing:Science Press,2009.
[5]维基百科,字母频率[EB/OL].http://zh.wikipedia.org/wi⁃ki/英语最常用单词2015/5/17.Frequency of Wikipedia,letters[EB/OL].http://zh.wikipe⁃dia.org/wiki/English is the most common words,2015/5/17.
[6]刘嘉勇.英语密码学[M].北京:清华大学出版社,2008:1-37.LIU Jiayong.Applied cryptography[M].Beijing:Tsinghua University Press,2008:1-37.
[7]吴干华.基于频率分析的代替密码破译方法及其程序实现[J].福建电脑,2006(9):125-125.WU Ganhua.Replacement password decipher based on frequency analysis and its program implementation[J].Fujian computer,2006(9):125-125.
[8]Willianm Stallings.密码编码学与网络安全——原理与实践[M].北京:电子工业出版社,2012:1-67.Willianm Stallings.Password encoding and network securi⁃ty—principle and practice[M].Beijing:Electronic Indus⁃try Press,2012:1-67.
[9]Abraham Sinkov.初等密码分析学—数学方法[J].信息安全与通信保密,1980(3):51-82.Abraham Sinkov.Primary cryptanalysis-mathematical method[J].Information security and communication con⁃fidentiality,1980(3):51-82.
[10]姜启源.数学建模[M].北京:高等教育出版社,2011:1-53.JIANG Qiyuan.Mathematical modeling[M].Beijing:Higher Education Press,2011:1-53.
