半虚拟化框架Virtio的网络请求性能优化
2018-03-28刘禹燕牛保宁
刘禹燕,牛保宁
(太原理工大学 计算机科学与技术学院,太原 030024)
1 引 言
平台即服务PaaS(Platform as a service)是将系统作为一种服务提供的商业模式,提供应用程序的开发和运行环境.为了提高资源利用率,PaaS提供的平台并非与真实物理主机一一对应,而是在一个或多个物理主机上构建多个虚拟机,向用户提供平台服务.因此PaaS的实质是将物理资源虚拟化,形成一个大型分布式系统,虚拟化产生的每一个虚拟平台都是云端的分布式系统中的独立终端.
云计算的任何服务都必不可少的需要通过数据传输实现,与磁盘、网卡等物理资源的频繁交互带来的I/O瓶颈[1-3]是云计算系统面临的挑战.比如大量的磁盘读写和网络访问,在原本直接抵达物理资源的应用程序之下添加一层虚拟化监控器管理层,使得应用程序必须经过客户机操作系统和虚拟化监控器的多层管理,这期间势必增加了响应时间上的延迟和性能上的过多开销.以常见的虚拟化平台KVM为例,未虚拟化前,应用程序的网络数据包经由内核TCP/IP协议封装,调用网络驱动程序发送至网络设备,完成本机网络数据发送.KVM虚拟化后,虚拟机应用程序的网络数据请求经过虚拟机内核TCP/IP协议封装,调用虚拟机网络驱动程序发送至虚拟网卡,然后产生虚拟中断通知宿主机有数据要进行发送,宿主机接收中断进行处理,再经过真实物理网卡进行网络数据发送.这其中由虚拟机中断而切换到宿主机处理的过程被称为系统切换,而系统切换需要占用大量CPU资源来保存上下文,如保存寄存器状态、队列上锁、更新队列等.当有海量数据包发送,就需要进行多次系统切换,造成CPU资源的浪费,也是虚拟化造成巨大开销的来源之一.因此如何减少系统切换开销、提升系统I/O性能、快速响应请求、提高用户体验是虚拟化技术需要解决的问题.
本文基于KVM虚拟化平台,借助半虚拟化驱动框架Virtio改进virtio-net网络模块请求响应的执行流程.通过分析网络请求从虚拟客户机到宿主机的传输流程,我们发现每个请求都先要先经过前端驱动逐一处理,置于共享通道,并引起系统切换,接着转为后端接收,后端接口在接收宿主机的请求时,又采用逐一处理逐一通知的同步方式.对于每个请求都需要占用CPU时间进行进入共享通道,系统切换,接收请求,处理请求,处理完毕后保存上下文再次进行系统切换.大量的请求导致频繁的通知和系统切换,占用大量的CPU时间,造成系统性能下降.针对这一问题,我们尝试先将前端的多个请求聚合后再放置于共享通道,而后端则采用逐一处理,多次通知合并为一次通知的异步方式,从流程上多方面同步聚合以减少系统切换的开销,把节省的CPU时间用于接收更多的网络请求以及处理请求本身.
基于以上设想,本文提出基于virtio-net网络模块双端的优化方法TAM(two-end aggregation method),前后端分别加大工作量,批量聚合处理后再移交对应端,减少双端交互造成的系统切换.经过实验测试,该方法首先使后端接收到统一聚合后的请求,减少前端逐一传输造成的大量开销,随后减少后端逐一返回请求通知前端造成的频繁的上下文保存和系统切换的开销,提高平台的数据吞吐量和每秒处理事务数,减少端到端响应时间.
本文内容及结构如下:第二节概述相关工作.第三节介绍相关背景知识.第四节对KVM的Virtio标准框架处理网络请求的流程进行性能瓶颈分析.第五节对流程进行优化,详细介绍TAM,并分析该方法下请求的传输路径.第六节对优化方法进行实验测试,并分析实验结果.第七节总结全文并提出下一步研究工作.
2 相关工作
当虚拟客户机操作系统执行敏感指令时,为了保证系统安全,需要将控制权交给KVM,通过位于宿主机的Qemu软件模拟出物理硬件的行为,保存和恢复寄存器状态等,最终将执行结果返回,客户机操作系统再次获得控制权,这样的系统级上下文切换会造成大量的开销.为了提高系统性能,我们希望尽可能减少系统级上下文切换所带来的开销,现有的解决方法分别从指令层和算法层两个方面进行优化.
在指令层优化方面,BinBin Zhang等人[4]通过合并客户机操作系统中的连续I/O指令,降低虚拟机的时钟中断频率,从而降低系统切换的开销,提高系统性能.A.Gordon 等人[5]提出ELI(Exit-Less Interrupt)方法,通过将宿主机从中断处理路径中移除减少了KVM虚拟机管理层处理的中断数量,使网络数据吞吐量产生显著的提升,使I/O设备的性能达到接近原生设备的效果.本文方法从内核的执行流程角度分析,在算法层进行路径的优化.
在算法优化方面,Shuxin Cheng等人[6]提出AHC (Adaptive Hypercall Coalescing) 算法,在嵌入式ARM环境下,对半虚拟化驱动的前端处理网络请求的流程进行优化,在发送网络请求时加入计时器,以时间为判断标准,在一定时间内将待发送的请求聚合,提高了请求处理效率,减少了上下文切换代价.由于该方法只考虑到半虚拟化驱动的前端,且只有在网络I/O请求密集的场景下具有良好的优化效果,在网络I/O请求稀疏的情况下,由于计时器的缘故,无法充分利用CPU资源,优化方法的性能反而会降低.本文的方法在Intel X86体系架构环境下,对半虚拟化驱动的前后端分别进行了优化处理,并且不依赖于计时器,只与真实网络请求相关,因此在网络I/O密集的情况下有良好的优化效果,在网络请求稀疏的情况下也不会影响性能,
此外一些基于Xen虚拟化平台的一些解决方法也可以为KVM的优化提供方向,M.Bourguiba和S.R.Thakur等人[7-9]基于Xen[10]实现网络 I/O 虚拟化模型,并提出数据包聚合方法,提升了网络 I/O 虚拟化的性能与可扩展性.数据包聚合*https://en.wikipedia.org/w/index.php?title=Packet_aggregation&oldid=390003240.是为了减少每个数据包的传输开销将多个数据包组合进一个传输单元的过程,当过多的数据包消耗大部分CPU时钟而每个数据包都相对较小时,这种方法是有效的.本文的方法也参考数据包聚合的思路,将其应用到半虚拟化驱动前后端对数据包的处理上.
在虚拟平台后端的优化上,李家祥等人[11]将Xen后端驱动中负责处理请求转发的单tasklet改进为多tasklet并行,提高数据包转发的效率,从而提高整个网络的吞吐率.本文的方法基于KVM半虚拟化驱动框架Virtio前后两端,虽然没有进行多任务并行,但是对每一端单任务处理的优化使得资源得到最大化利用.
3 背景知识
Hypervisor是一种运行在基础物理服务器和操作系统之间的中间软件层,可允许多个操作系统和应用共享硬件.KVM是首个被集成到Linux内核的hypervisor解决方案,与Xen不同的是,KVM采用具有高级指令的新处理器,硬件虚拟化扩展(Intel VT)的X86平台.
Virtio是 KVM 虚拟环境下针对I/O虚拟化的最主要的一个通用框架,KVM使用半虚拟化框架Virtio前端后端驱动模块互相协作的方式,减少I/O操作时系统中断和权限转换所带来的开销,同时由于半虚拟化采用的数据描述符机制,用数据描述符来传递数据信息而不是进行跨主机数据拷贝,使得数据读写只发生在共享内存区域,减少冗余的数据拷贝,使用Virtio的KVM网络I/O性能有很大提升.
默认的标准Virtio的后端处理程序处于宿主机的用户空间,网络I/O请求从虚拟客户机经过系统切换首先到达宿主机用户空间Qemu后端,再陷入宿主机内核,现有的Vhost方法将Virtio后端处理程序直接放置于宿主机的内核中,这使得网络I/O请求经过系统切换到达宿主机时,直接转发给处于内核的Vhost,省去请求在宿主机用户空间转发的过程,通过缩短数据传输路径提升系统性能、减少响应时间.
4 Virtio性能瓶颈分析
4.1 总体框架
如图1所示,Virtio由三部分构成:前端驱动程序、后端驱动程序以及用于前后端进行信息传输的共享通道.Virtio-net是虚拟客户机与宿主机网络数据传输的前端接口,本节我们将分析前后端接口对网络数据包的处理流程与性能瓶颈.
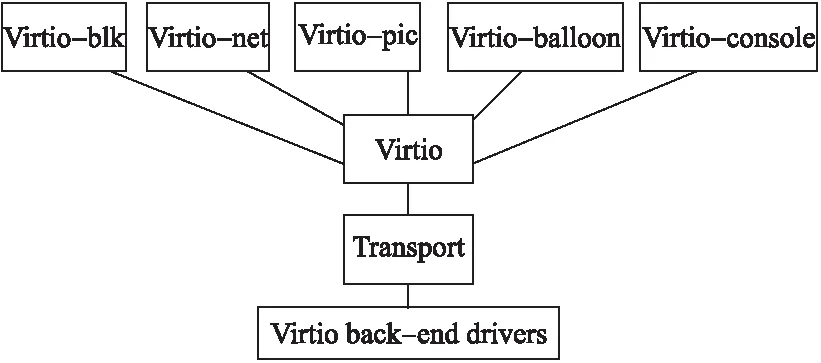
图1 Virtio半虚拟化框架Fig.1 Virtio para-virtualization framework
4.2 Virtio缓冲池
Virtqueue是承载着大量buffer数据的队列,Virtio前端驱动程序通过Virtqueue缓冲池与后端交互,把buffer插入队列交给后端实现数据传输,其中buffer数据是以地址-长度为格式的散集列表(scatter-gather)的形式存储的.Virtio_ring是Virtio传输机制的具体实现,ring buffers是数据传输的载体.Virtio_ring包含3部分:描述符数组(descriptor table)用于存储一些关联的描述符,每个描述符都是一个对buffer的描述,包含一个address/length的配对.可用的ring(available ring)用于虚拟客户机端表示哪些描述符是可用的或者待处理的请求.使用过的ring(used ring)用于宿主机端表示哪些描述符是已经处理的请求.
4.3 网络数据包发送流程
设备启动后,首先加载前端网络驱动,调用Virtio_dev_probe()进行Virtio设备识别、创建与初始化,其中find_vqs()创建一个与queue关联的结构体Vring,网络设备有2个Virtqueue,分别用于发送和接收数据包.
假设虚拟客户机发起一个网络I/O请求,virtio传输方式可见图2,前后端工作的具体流程如下:
1.虚拟客户机通过Virtio前端接口发送buffer数据包
a) 使用add_buf(),把buffer添加到队列描述符表中,填充addr,len,flags
b) 更新available ring的head,index信息
c) 调用kick()进行超级调用,将Virtqueue index写入到Queue Notify寄存器,产生中断通知宿主机
d) 虚拟客户机保存寄存器状态,交出控制权,随后系统切换到宿主机.
2.宿主机通过Virtio后端接口接收buffer数据包
a) 接收到中断通知后,陷入宿主机内核,CPU从中断控制器的寄存器读取数据确认中断
b) 调用Virtqueue_pop()从队列描述符表中找到available ring中的buffer并映射内存
c) 从散集列表读取buffer数据
d)Virtqueue_fill()更新ring[idx]字段id和len
e)Virtqueue_flush()更新Vring_used中的idx
f) 调用Virtio_notify()将ISR状态位写入1,通知虚拟客户机前端描述符已经使用
g) 宿主机保存寄存器状态,虚拟客户机得到控制权.
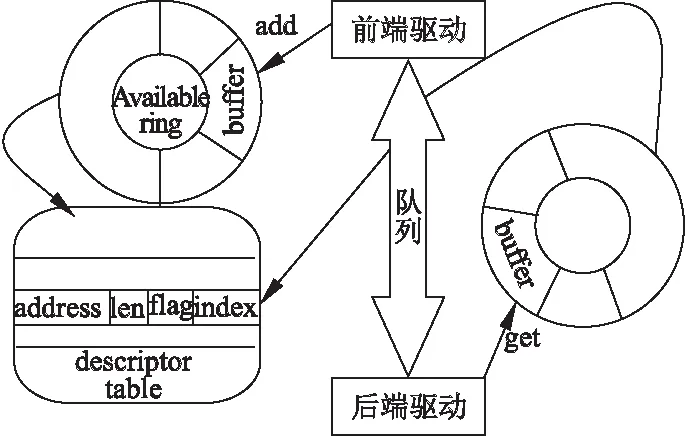
图2 Virtio前后端请求传输方式Fig.2 Request transmission between virtio front-end and back-end
4.4 瓶颈分析
通过分析Virtio-net前后端处理请求数据的流程,我们注意到Virtio后端驱动在将网络I/O请求从共享通道Virtqueue中取出后立即调用Virtio_notify()通知前端处理该请求,而通知函数分为两个阶段,封锁队列而后产生虚拟中断,这个过程的开销不可忽视.执行超级调用消耗的时间在响应延迟中占了很大的比例,也占用了大量的CPU资源.因此我们需要谨慎调用通知函数,在超级调用前,尽可能处理更多的请求以提高资源利用率.
对于高密集的网络I/O请求场景,队列中会有大量请求等待传输,如果每个请求都需要等待前一个请求处理完成并且超级调用通知前端,前端接收中断取得请求结果,才可以得到处理,这样无谓的等待不仅造成响应时间的延迟,还会使得大量CPU资源耗费在队列上锁、队列更新、修改寄存器状态、接收中断等系统切换所需的开销上,我们希望可以节省这些开销用于接收和处理更多的I/O请求上.
5 Virtio网络请求过程优化
根据上节对网络数据请求I/O路径的分析,可以知道,在网络I/O虚拟化过程中,超级调用造成开销的比例最大,而无论网络流量大小,每次I/O请求都需要通过超级调用进行系统上下文切换和权限转换以达到请求数据传输的目的.
我们设想通过减少超级调用的次数来减少系统上下文切换的次数,从而减低CPU负载,在网络I/O密集的场景下,每个请求都需要超级调用,批量请求产生的开销不可估量,为此我们考虑将多个请求的超级调用聚合为一个.
根据这个设想,我们对Virtio前后端进行改进,提出双端聚合的优化方法TAM,对于待传输的网络数据,前端将一个请求放入队列后,并没有立即调用hypercall通知后端,而是继续判断是否还有请求等待传输,以队列大小1024为依据,接收请求直到队列满,通知后端.后端在收到前端已将请求放入队列的通知后,得到队列控制权,取出队列中一个待处理请求后,同样并没有立即调用hypercall通知前端,而是处理完队列中全部请求后调用一次超级调用,产生虚拟中断通知前端,前端一次性读取队列中所有处理完毕的请求结果.通过控制超级调用通知对应端的时刻,将批量到达的多个请求所需的多次超级调用聚合为一次再通知,节省超级调用后系统切换造成的开销和时间,使CPU有更多的时间处理数据传输本身,理论上可以提高数据吞吐量,减少响应时间,降低CPU开销.
我们基于virtio前后端网络处理模块,对前端发送函数和后端接收函数进行优化,在单独处理的数据包外层增加while循环,使得处理完毕的数据包不被立即通知给对端,具体算法伪码如下.
算法1.前端聚合方法
输入:待发送的数据包*skb,发送数据的网络设备队列net_queue,队列状态state,virtio发送队列sq
①初始化:数据包入队后队列大小i
②while(i
③ skb入sq队列
④ i=i+skb.len
⑤ 移向下一个skb
⑥}end while
⑦ 触发中断,通知后端
算法2.后端聚合方法
输入:接收队列vq,队列元素&elem
①while(virtqueue_pop(vq,&elem)){
② handle the elem
③ 移向队列下一个元素
④}end while
⑤触发中断,通知前端
由于TAM方法双端处理流程优化的基本思路相同,且本文相比现有方法增加了后端的优化,图3只列出后端的网络请求处理过程:
该过程反应了优化后Virtio后端对网络请求的处理,前端将要发送的数据放入Virtqueue后,调用Virtqueue_kick()通知后端,这个过程涉及一次系统上下文切换,接着后端收到中断通知,调用virtio_net_receive接收数据,我们判断Virtqueue中是否还有请求需要处理,如果有,调用Virtqueue.pop()取出环中元素直到请求全部取出,如果没有等待中的请求,则调用Virtqueue_notify()产生虚拟中断通知前端处理后的结果,此时处理过的所有请求都已标记为used,并不会造成丢失请求的问题.
6 实 验
6.1 实验设计
实验测试的硬件环境:Intel Xeon E7-4809 v2 1.9GHz处理器.软件环境:宿主机Linux 4.7.0版本内核,Qemu 1.2.50,虚拟客户机Linux 4.6.1版本内核.

图3 TAM后端 I/O请求处理流程Fig.3 TAM back-end I/O requests workflow
实验设定请求队列大小为1024字节进行测试.
实验使用经典的基准测试程序Netperf和Ping对数据吞吐量、延时、TPS(每秒处理事务数)进行测试,同时对CPU开销也进行了监控测试.
每个实验进行以下三种半虚拟化方法的对比测试:
1)AHC:文献[6]的Virtio半虚拟化前端优化方法
2)VHOST:已有的Virtio半虚拟化的后端优化方法
3)TAM:本文的Virtio半虚拟化双端聚合优化方法
6.2 数据吞吐量
我们对上述三种方法使用Netperf进行批量数据传输(bulk data transfer)模式的网络性能测试.测试时,宿主机作为Netserver服务端,虚拟机作为Netperf客户端,客户端发送批量的TCP数据分组以确定数据传输过程中的数据吞吐量.
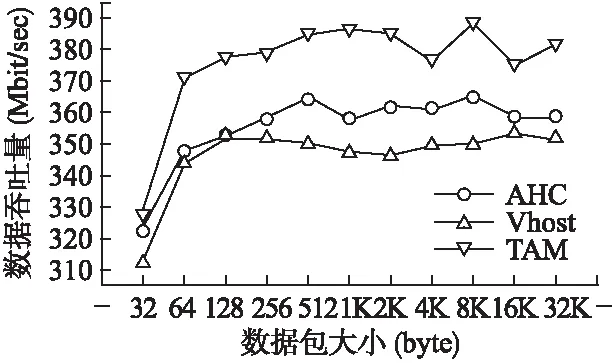
图4 数据吞吐量测试结果Fig.4 Test results of data throughput
图4是在不同数据包大小传输的情况下数据吞吐量的测试结果.TAM方法数据包大小在64 bytes到32K bytes时数据吞吐量基本稳定在350左右,Vhost方法数据吞吐量仅250左右,TAM方法数据吞吐量相比AHC提高5.76%,这是由于相比AHC,TAM方法的后端是将数据包请求聚合后才返回响应,节省了每个数据包通知的开销以及系统切换的开销,使得CPU时钟可以处理更多的数据流量传输.
6.3 延时
我们对上述三种方法使用Ping进行不同大小数据包传输的延时测试.测试时,虚拟机作为Ping发送端发送数据包,宿主机作为Ping接收端,收到数据包后返回一个同样大小的数据包来确定两台主机是否连接相通,时延是多少.
图5是在不同数据包大小传输的情况下,TCP延时的测试结果.AHC方法响应延时不太稳定,但总体看来,延时随着传输数据量的增大而增大,这是由于数据拷贝量的增加和系统之间的切换造成的.可以看到,使用Vhost后端优化处理后有一定的效果,这是由于缩短请求的响应路径,系统切换到宿主机后直接进入内核处理,节省了时间.由于TAM方法缩短的时间是系统切换的时间,对于每个请求,系统切换的时间远大于请求在宿主机用户空间转发的时间,所以TAM方法比Vhost方法时间更短.而相比AHC,时间上的减少则是双端同时优化改进起到了作用.
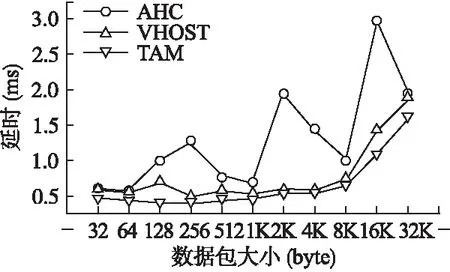
图5 延时测试结果Fig.5 Test results of delay
6.4 每秒处理事务数TPS
我们使用Netperf进行请求/应答(request/response)模式的网络性能测试,测试时宿主机作为Netserver服务端,虚拟机作为Netperf客户端,客户端向服务端发送小的查询分组,服务端接收到请求,经处理后返回大的结果数据.
6.4.1 一次连接多次请求TCP_RR
图6是在小数据包传输的情况下,TCP_RR的TPS测试结果.Vhost由于后端直接经内核转发请求,缩短了路径,节省了一定资源用于处理其他请求,TPS有一定提升,然而对于小数据包来说,频繁的系统切换才是真正的痛点,TAM方法虽然处于用户空间,但该方法在问题瓶颈点进行优化,减少超级调用,因此比Vhost方法效果更优.
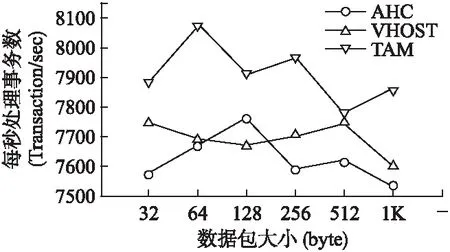
图6 小数据包TCP_RR测试结果Fig.6 Test results of small packages on TCP_RR
图7是在大数据包传输的情况下,TCP_RR的TPS测试结果.可以看到,单独优化前端的AHC和单独优化后端的Vhost基本重合,而TAM方法有少量提升,这是由于队列大小为1024,在传输大于1024的数据包时,TAM方法不能达到很好的利用,因此结果与其他两方法相近,效果不明显.
6.4.2 多次连接多次请求TCP_CRR
图8是在小数据包传输的情况下,TCP_CRR的TPS测试结果.总体来说,TAM方法以双端为出发点减少系统切换次数,达到比AHC和Vhost更高的TPS.
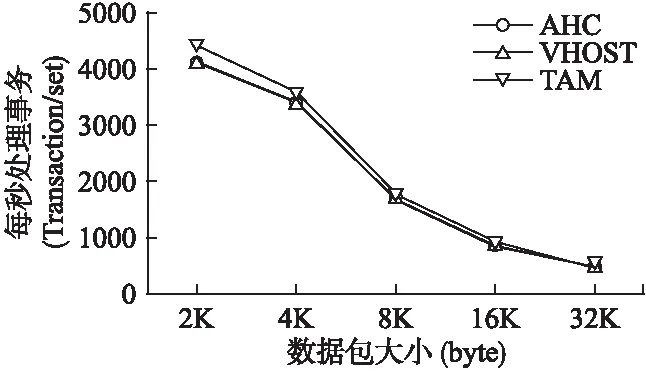
图7 大数据包TCP_RR测试结果Fig.7 Test results of big packages on TCP_RR

图8 小数据包TCP_CRR测试结果Fig.8 Test results of small packages on TCP_CRR
图9是在大数据包传输的情况下,TCP_CRR的TPS测试结果.由于大于1024的数据包传输所需的必要的系统切换很难因TAM的聚合而减少,因此TPS提升很小.

图9 大数据包TCP_CRR测试结果Fig.9 Test results of big packages on TCP_CRR
6.5 CPU开销
在使用netperf基准测试程序进行TCP_STREAM压力测试的同时,我们对作为netserver服务端的宿主机系统进行了整体性能监测,监测工具为vmstat.
表1 CPU开销
Table 1 CPU overhead

%wa%id%us%syincsTAM1325116637585430AHC73144187862104871
由表1可知,相比AHC方法,TAM方法减少了CPU等待I/O的时间wa,缓解I/O瓶颈,充分利用了CPU资源.此外,由于后端qemu工作量的集中机制,用户CPU使用率us提高,且聚合减少了系统内核切换的开销,系统CPU使用率sy有所减少.每秒中断次数in有一定减少,cs响应也有所减少.因此看出,双端聚合有一定成效,但cs依然很高,原因是在批量网络数据传输的测试下,传输队列大小设定相对较小的缘故.
7 结束语
本文针对虚拟化环境KVM中网络I/O性能的优化进行研究,通过分析KVM半虚拟化框架Virtio处理网络I/O请求的流程,得出占用CPU资源最多的场景是I/O请求数据转换时超级调用导致的系统切换,造成性能瓶颈.与现有的基于半虚拟化前端进行优化的解决方法不同,本文提出一种双端聚合方法TAM,该方法分别以Virtio前后端为基础,改进默认的后端Virtio-net处理网络请求的方式优化AHC前端网络请求处理方式,前端将待发送的网络请求聚合后统一通知后端,后端将共享通道队列描述符列表中的可用请求逐一处理后统一通知前端,将多次超级调用的开销合并为一次,减少系统切换次数和权限转换次数,降低CPU开销,提升系统性能.实验测试表明,使用TAM方法的Virtio网络模型,数据吞吐量相比只优化前端的AHC方法提高5.76%,TCP_RR的每秒处理事务数提高4.39%,TCP_CRR的每秒处理事务数提高4.32%,延时减少46.2%.接下来的工作,我们将测试并选取合适的请求聚合大小即传输队列大小以平衡系统性能和每个请求的等待时间.
[1] Caulfield A M,Mollov T I,Eisner L A,et al.Providing safe,user space access to fast,solid state disks[J].Acm Sigplan Notices,2012,40(1):387-400.
[2] Dall C,Nieh J.KVM/ARM: the design and implementation of the linux ARM hypervisor[J].Acm Sigplan Notices,2014,42(1):333-348.
[3] Har′El N,Gordon A,Landau A,et al.Efficient and scalable paravirtual I/O system[C].Usenix Annual Technical Conference(USENIX ATC′13),USENIX Association,2013:231-242.
[4] Rasmusson L,Corcoran D.Performance overhead of KVM on Linux 3.9 on ARM cortex-a15[J].Acm Sigbed Review,2014,11(2):32-38.
[5] Gordon A,Amit N,Har′El N,et al.ELI: bare-metal performance for I/O virtualization[J].Acm Sigplan Notices,2012,47(4):411-422.
[6] Cheng Shu-xin,Yao Jian-guo,Hu Fei.Optimizing network I/O performance through adaptive hypercall coalescing in embedded virtualization[C].Proceedings of the 30th ACM/SIGAPP Symposium on Applied Computing (SAC 2015),Salamanca,Spain,2015.
[7] Nordal A,Kvalnes,&#,Johansen D.Paravirtualizing TCP[C].Proceedings of the 6th International Workshop on Virtualization Technologies in Distributed Computing Date,ACM(VTDC′12),2012:3-10.
[8] Bourguiba M,Haddadou K,Pujolle G.Packet aggregation based network I/O virtualization for cloud computing[J].Computer Communications(COMPUT COMMUN),2012,35(3):309-319.
[9] Thakur S R,Goudar R M.Improving network I/O virtualization performance of xen hypervisor[J].International Journal of Engineering Trends & Technology(IJETT),2014,11(2):79-83.
[10] Abolfazli S,Sanaei Z,Ahmed E,et al.Cloud-based augmentation for mobile devices:motivation,taxonomies,and open challenges[J].IEEE Communications Surveys & Tutorials(IEEE COMMUN SURV TUT),2013,16(1):337-368.
[11] Li Jia-xiang.Research on optimization of xen network I/O performance [D].Wuhan:Huazhong University of Science and Technology,2013.
附中文参考文献:
[11] 李家祥.Xen虚拟机网络I/O性能优化研究[D].武汉:华中科技大学,2013.
