渐进学习语音增强方法在语音识别中的应用
2018-03-28文仕学
文仕学,孙 磊,杜 俊
(中国科学技术大学 语音及语言信息处理国家工程实验室,合肥 230027)
1 引 言
随着移动互联网的发展,自动语音识别(Automatic Speech Recognition,ASR)在智能终端上得到了越来越广泛的应用.伴随着语音识别技术的不断发展,语音识别系统的性能不断提高,高信噪比条件下的语音识别系统取得了较高的识别率.然而,语音识别系统在复杂的应用环境中,由于测试环境和训练环境不匹配,导致传统的语音识别系统的性能会出现明显的下降[1].这是因为对基于统计模型的语音识别系统,训练的数据必须具有充分的代表性.然而,当识别系统应用于噪声环境时,测试语音中的噪声和训练语音中的噪声之间存在不匹配,识别系统在噪声环境下的性能下降主要归因于这种不匹配.而对于马路、餐馆、商场、汽车、飞机等信噪比恶劣环境中的语音信号来说,现有语音识别系统的鲁棒性还有待提升.因此噪声鲁棒性问题一直是限制语音识别系统在现实生活中得到大规模应用的一个主要问题[2].其中语音识别的噪声鲁棒性是指:当输入语音质量退化,语音的音素特性、分割特性或声学特性在训练和测试环境中不同时,语音识别系统仍然保持较高识别率的性质[3].
近年来,提高语音识别的抗噪声能力有很多比较成功的技术和算法,语音增强技术就是其中一种.语音增强的目的是从含噪语音中提取尽可能纯净的原始语音信号,以提高语音的质量和可懂度[4].语音增强在语音识别模型的前端进行降噪预处理,能有效的抑制背景噪声,提升测试语音信噪比,从而提高语音识别系统的性能[5].但带来的频谱失真和音乐噪声却是对识别的不利因素[6].
2 传统语音增强算法回顾
假设带噪语音在时域上符合下面这个显式的失真模型:
y[t]=x[t]+n[t]
(1)
x[t],n[t]和y[t]分别表示干净语音,加性噪声和带噪语音.从目前的发展上看,语音增强最常用的方法是基于短时谱估计的方法,即先作短时傅里叶变换,将失真模型变换到频域表示如下:
Y[l,k]=X[l,k]+N[l,k]l=1,2,…,N;k=1,2,…,M
(2)
其中X[l,k],N[l,k]和Y[l,k]分别表示干净语音,加性噪声和带噪语音在第l帧和第k频带的频域信号的复数表示,M为总频带数,N为总帧数.然后基于频域模型利用Y[l,k]来估计X[l,k],谱估计方法主要包括:
1.谱减法[7].谱减法(Spectral Subtraction,SS)假设噪声是平稳的加性噪声且与语音信号不相关,从带噪语音的功率谱中减去噪声功率谱,得到语音频谱.谱减法及其改进算法运算量较小,易于实时实现,增强效果也较好.但是增强后的语音容易留下类似音乐的噪声,对主观听感的影响较大.
2.维纳滤波[8].维纳滤波方法可以看作对时域波形的最小均方误差估计.该算法的优点是残余噪声较小,且信号各帧之间有较好的连续性,且几乎没有音乐噪声,但是会残留类似高斯白噪声的残差噪声.
3.最小均方误差估计[9].最小均方误差(Minimum Mean Square Error,MMSE)估计及其改进算法对非平稳的噪声具有良好的抑制作用,但是较难估计语音信号的概率密度函数.
以上三种无监督学习方法,都无法对非平稳噪声进行有效抑制,这是因为非平稳噪声具有突发性,如果仅仅通过前面的非语音帧来估计噪声的方差,很难有效跟踪非平稳噪声.

图1 基于深层神经网络的语音增强流程图Fig.1 Flowchart of speech enhancement based on DNN
4.基于深层神经网络的语音增强方法[10].在近些年来,随着深度学习的发展,深层神经网络的深层非线性结构可以被设计成一个精细的降噪滤波器,以很好地抑制非平稳噪声.其原理是利用深层神经网络作为学习带噪语音和干净语音之间非线性映射关系的回归模型,该方法流程如图1所示.
3 渐进学习语音增强及识别方法
从前面的传统语音增强算法我们可以看出,这些方法都是从带噪语音对语音进行直接估计.以前面的深层神经网络方法为例,为了提高深层神经网络模型对噪声的鲁棒性,通常需要使用大量的带噪语音来训练深层神经网络,这一方面将导致深层神经网络模型的参数增加,另一方面也会导致计算量的增加,以及系统处理速度的降低.此外,在低信噪比环境下,深层神经网络增强后的语音会存在较大失真[11].在保持深层神经网络模型对噪声鲁棒性的前提下,为了减少深层神经网络的参数,近年一种渐进学习[11](Progressive Learning,PL)语音增强方法被提出.不同于参考文献11仅使用该方法做语音增强,本文与参考文献的区别在于将该方法作为识别模型的前端部分,应用到语音识别领域.渐进学习语音增强及识别方法的流程图如图2所示.其中,在前端增强模块,渐进学习语音增强方法在传统的深层神经网络的语音增强方法基础上,可以进一步提高语音的听感和可懂度等指标.而在后端识别模块,通过该方法训练的PL-DNN对带噪语音进行前端降噪,然后提取Filter-bank特征,再送给后端识别ASR-DNN声学模型和语言模型进行解码搜索,最后输出识别结果.
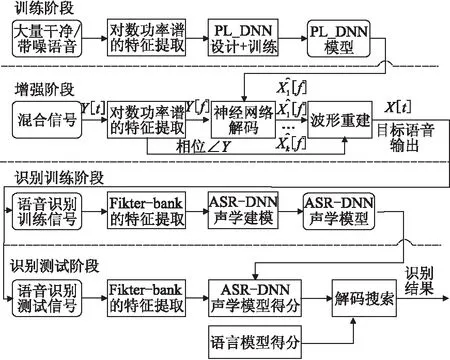
图2 渐进学习语音增强及识别方法流程图Fig.2 Flowchart of PL speech enhancement and ASR method
从渐进学习语音增强及识别方法可以看出,其与传统深层神经网络最大的区别在于训练深层神经网络模型阶段,该方法通过逐渐提升信噪比,将从带噪语音到干净语音的映射过程分为3个阶段,深层神经网络的中间隐层直接对应到学习一定的信噪比(如每次10dB),这可以有效减少深层神经网络模型的参数,同时可以更好地减少语音的失真,尤其是低信噪比环境下的失真.同时,每个阶段的学习过程,可以促进下一阶段的学习.此外,3个阶段的学习结果,可以提供丰富的信息量,这样通过后处理可以进一步提高性能.渐进学习的语音增强及识别方法的直观解释如图3所示.

图3 渐进学习语音增强及识别方法的图解Fig.3 Illustration of PL speech enhancement and ASR method
渐进学习语音增强方法训练的PL-DNN模型结构如下页图4所示.对于目标层(如目标1、目标2和目标3),采用的激励函数为线性激励;而对于其他隐层,则采用Sigmoid激励函数.这些目标层的设计,是为了逐步提高语音中心帧的信噪比,直到学习到干净语音.
3.1 语音增强训练阶段
在渐进学习语音增强方法的训练阶段,可以按以下步骤进行:
步骤1.加噪:通过对干净语音加噪,生成大量的带噪语音作为输入信号(如信噪比为0dB);与输入信号一一对应,生成指定信噪比的带噪语音作为目标1(如信噪比为10dB);相应地,生成指定信噪比的带噪语音作为目标2(如信噪比为20dB);同时,将加噪前的干净语音作为目标3.
步骤2.特征提取:利用语音信号的短时平稳性,通过在时域进行汉明窗加窗,对语音信号作分帧处理.选用对数功率谱(Log-power Spectrum,LPS)作为增强特征,通过对当前帧的时域采样点作离散傅里叶变换,将语音信号从时域变换到频域,并取当前帧及前后N帧(本文中选取N=3)的对数功率谱,作为训练PL-DNN的输入特征.
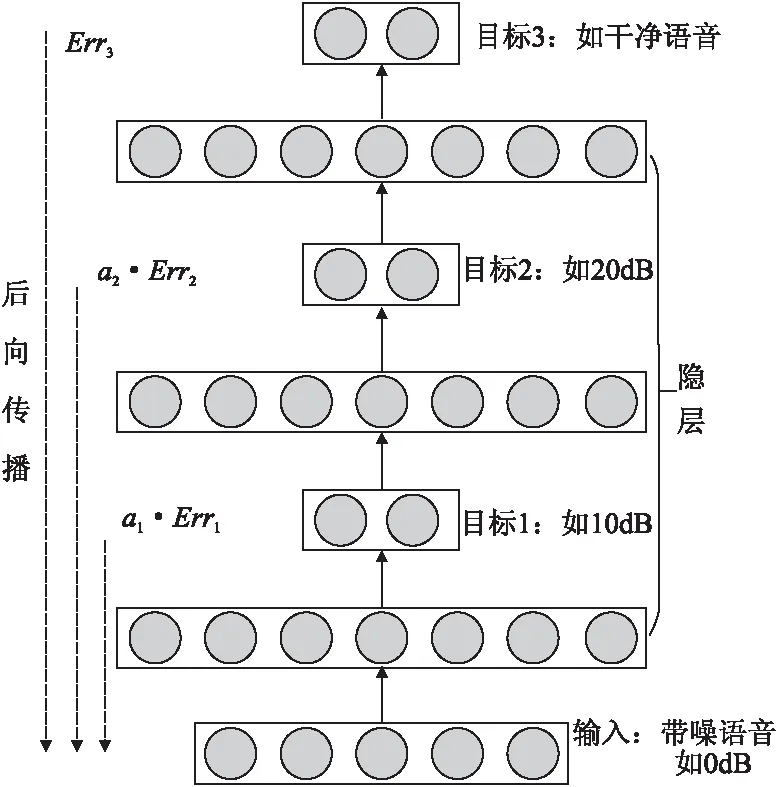
图4 渐进学习深层神经网络结构图Fig.4 Architecture of progressive learning DNN
步骤3.PL-DNN训练:渐进学习语音增强方法训练的PL-DNN模型结构如图4所示.在前向阶段,当前目标层增强后的对数功率谱特征作为下一目标层的输入;而在后向传播阶段,采用MMSE准则,作为K个(本文中选取K=3)目标层优化的目标函数,如式(3)所示.
(3)

(4)
其中,ε是指全部目标函数的梯度,Wl和bl分别是指第l层的待学习的权重和偏置,L1、L2和L3是指3个目标层,分别对应目标1、目标2和目标3.值得注意的是,每个目标层的梯度,只影响该目标层前面层的参数更新.为了平衡多个目标层,采用α1和α2作为目标1和目标2的加权权重.在这里可以发现,如果将α1和α2设为0,则该情况下PL-DNN与传统深层神经网络模型相同.在本文中,将α1和α2设为0.1.
步骤4.训练结束:训练多次迭代收敛后,保存PL-DNN.
3.2 语音增强阶段
在渐进学习语音增强方法的增强阶段,可以按以下步骤进行:
步骤1.数据准备:准备好需要增强的语音信号.
步骤2.特征提取:与训练阶段3.1中步骤2相同,选用当前帧及前后N帧的对数功率谱特征作为输入.
步骤3.网络解码:将输入特征通过3.1中训练的PL-DNN网络,解码得到3个目标层的输出,本文将目标1、目标2和目标3的输出分别定义为输出1、输出2和输出3.
步骤4.波形重建:在利用已经训练好的深层神经网络估计到干净语音的对数功率谱特征之后,就需要对语音的波形进行重建,以获得一个可以主观测听的波形文件,具体步骤如下:将3个输出的对数功率谱特征,使用增强前的语音信号的相位信息,通过傅里叶反变换,并在时域上通过经典的重叠相加法,对各帧进行重组,会分别得到3个增强后的整个句子的波形文件.可以分别采用这3个结果作为增强结果输出,也可以将这3个增强后的波形文件进行后处理(如加权平均),最终得到1个语音作为增强结果并输出.该步骤中,使用增强前语音的相位作为增强后语音的相位,是基于人耳对语音相位不敏感这一前提[12].
3.3 语音识别训练阶段
由于本文对比的是两种语音增强方法对语音识别性能的影响,因此在语音识别的训练阶段,渐进学习语音增强方法和传统深层神经网络的语音增强方法,使用完全相同的语音识别模型,都是按以下步骤进行:
步骤1.数据准备:将语音识别的语音训练数据,按照3.2中的步骤,通过3.1中训练的PL-DNN网络,得到增强后的语音训练数据.
步骤2.特征提取:与语音增强的训练阶段类似,将增强后语音训练数据,进行特征提取.不同于语音增强选取的对数功率谱特征,语音识别将选取Filter-bank特征,作为ASR-DNN声学建模训练过程的输入特征.其中,Filter-bank特征是指用Mel滤波器组滤波之后得到的声学特征.
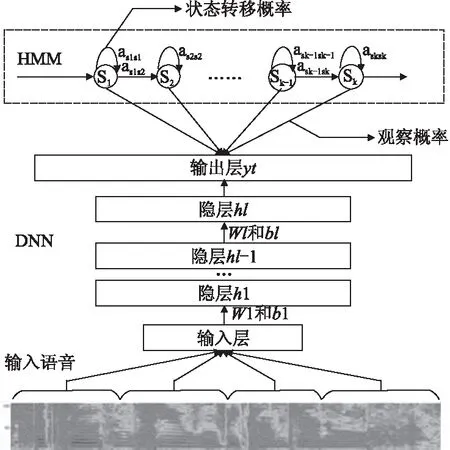
图5 DNN-HMM声学模型的流程图Fig.5 Flowchart of DNN-HMM based acoustic model
步骤3.ASR-DNN声学建模:这一步使用深层神经网络-隐马尔科夫模型(Hidden Markov Model,HMM)混合系统作为声学模型[13],对Filter-bank特征进行声学统计建模.声学模型将声学和发音学的相关知识进行整合,以3.3中的步骤2提取的特征作为输入,隐马尔科夫模型对语音信号的序列特性进行建模,深层神经网络对所有聚类后的三因素状态的似然度进行建模,并为可变长特征序列生成声学模型分数[14].使用隐马尔科夫模型和深层神经网络建立声学模型的流程如图5所示,在图5中,上半部分描述的是的隐马尔科夫模型结构,隐马尔科夫模型的结构和转移概率是使用训练数据训练一个隐马尔科夫模型-高斯混合模型(Gaussian Mixture Model,GMM)得到.图5中间部分描述的是一个深层神经网络,用来决定隐马尔科夫模型的发射概率.本文选用的深层神经网络声学模型的隐层数为6层,即包括输入、输出层的总层数为8层,6个隐层都选用2048个神经元.图5中的下半部分是深层神经网络模型的输入,需要注意的是,和语音增强使用的深层神经网络一样,语音识别使用的深层神经网络模型的输入同样是多帧特征,本文选取的是11帧输入.在语音识别过程中,一小段语音按照图5中的流程被处理,然后与不同的发音比较相似度,计算隐马尔科夫模型中的状态发射概率.
步骤4.训练结束:训练多次迭代收敛后,保存ASR-DNN.
3.4 语音识别测试阶段
在渐进学习的语音增强及识别的测试阶段,可以按以下步骤进行:
步骤1.数据准备:与训练阶段3.3中的步骤1相同,将语音识别的语音测试数据,按照3.2中的步骤,通过3.1中训练的PL-DNN网络,得到增强后的语音测试数据.
步骤2.特征提取:与训练阶段3.3中的步骤2相同,将增强后语音测试数据,进行特征提取.提取Filter-bank特征,作为ASR-DNN解码的输入特征.
步骤3.计算声学模型和语言模型得分:将3.4中的步骤2得到的语音测试数据的Filter-bank特征作为3.3中训练的ASR-DNN声学模型输入,生成声学模型分数.使用语言模型通过词与词、词与句子的映射,生成语言模型分数.语言模型表示某一词序列发生的概率,通过链式法则,把一个句子的概率拆解成句子中的每个词的概率之积.
步骤4.解码搜索:解码搜索是指对给定的特征向量序列和若干假设词序列,按3.4中的步骤3分别计算声学模型分数和语言模型分数,并将总体输出分数最高的词序列作为最终识别结果输出.这是因为在给定了根据语法、字典对马尔科夫模型进行连接后的搜索的网络后,通过在所有可能的搜索路径中选择一条或多条最优(如选用最大后验概率)路径作为识别结果,这样可以根据当前帧的前后帧,对时序的语音帧进行有效约束.
4 实验结果及分析
4.1 实验配置
为了验证渐进学习语音增强方法在语音识别中的有效性,我们在实际录制的真实语音数据库上进行了一系列的实验,实验配置介绍如下.
对于语音增强的训练数据,我们使用800小时真实场景下录制的干净语音数据(共约100万句,内容主要是在安静近场环境下录制的访谈和讲话)以及真实场景下录制的噪声数据,语音和噪声的采样率都是16kHz.
对传统深层神经网络,通过人工加噪,为输入层生成5种信噪比的带噪语音,5种信噪比分别是0dB、5dB、10dB、15dB和20dB,各信噪比的比例为1:1:1:1:1,即分别为160小时.具体加噪方式是从噪声数据中随机抽取一段,按已定信噪比加入到干净语音段,输出层为未加噪的干净语音,即表中的clean.以上数据构成传统深层神经网络的训练数据,具体如表1所示.

表1 传统深层神经网络语音增强训练数据Table 1 Training data for traditional DNN speech enhancement
对PL-DNN,通过人工加噪,为输入层、目标1和目标2各分别生成5种信噪比的带噪语音.其中输入层使用的5种信噪比分别是0dB、5dB、10dB、15dB和20dB,各信噪比的比例为1:1:1:1:1,即分别为160小时.目标1和目标2分别在输入层的对应信噪比上增加10dB和20dB,即分别为10dB、15dB、20dB、25dB和30dB,以及20dB、25dB、30dB、35dB和40dB,目标3为未加噪的干净语音.以上数据构成PL-DNN的训练数据,具体如表2所示.
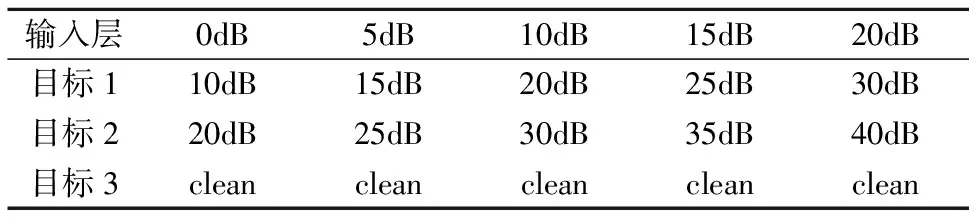
表2 PL-DNN语音增强训练数据Table 2 Training data for PL-DNN speech enhancement
在语音增强训练阶段,对于一段语音,先进行汉明窗加窗,帧长为512个采样点(对应32ms),帧移为256个采样点(对应16ms),这样相邻帧的重合率就是百分之五十,这种将相邻帧相互重叠的方法可以保证恢复的信号比较平滑,听感相对比较舒服.然后对每一帧作离散傅里叶变换,提取对数功率谱作为特征参数,离散傅里叶变换的结果总计为512维,除去重复的255维,对应最终选取的对数功率谱特征为257维.深层神经网络使用随机初始化,且对数功率谱特征在输入深层神经网络之前和深层神经网络输出之后,都使用全局均值方差规整(Global Mean and Variance Normalization,GMVN).渐进学习语音增强深层神经网络使用的配置是输入层扩7帧,中间3隐层采用Sigmoid激活且每个隐层为2048个单元,3个输出层都不扩帧.因此,PL-DNN的结构是1799-2048-257-2048-257-2048-257.而与PL-DNN对比的传统深层神经网络的配置是输入层扩7帧,中间3隐层采用Sigmoid激活且每个隐层为2048个单元,1个输出层不扩帧.因此,传统深层神经网络的结构是1799-2048-2048-2048-257.
对于语音识别的训练数据,我们仍然使用前面的800小时真实场景下录制的干净语音及噪声数据,及干净语音经过强对齐(Force Alignment,FA)的标注.为了让ASR-DNN达到更好的识别性能,我们同样对800小时干净数据进行人工加噪,生成800小时带噪语音数据,即ASR-DNN一共使用1600小时语音数据,并经过语音增强后用作ASR-DNN的训练.这里和语音增强阶段不同的是,语音增强中,PL-DNN的输入数据一共只有800小时,按各种信噪比生成的加噪数据对应着PL-DNN待学习的不同目标;而语音识别中,ASR-DNN的输入数据一共有1600小时,即800小时干净语音和800小时带噪语音经过增强都作为ASR-DNN的输入数据.这是因为区别于语音增强的目标是学习干净语音,语音识别的目标是学习语音经过强对齐的状态序列.
在语音识别训练阶段,同样地,对于一段增强后的语音,先进行汉明窗加窗,不同于语音增强阶段的是,识别中选取帧长为20ms,帧移为10ms,然后对每一帧提取对Filter-bank特征参数,Filter-bank特征总计为24维,计算一阶差分、二阶差分总计构成72维.为了达到更好的性能,本文还使用了表达基音变化规律的pitch特征参数,pitch特征对应3维,因此最终使用的特征是75维.ASR-DNN输出状态数选用的是9004种状态.ASR-DNN使用随机初始化,且Filter-bank和pitch特征在输入深层神经网络之前,使用全局均值方差规整.语音识别ASR-DNN使用的配置是输入层扩11帧,中间6隐层采用Sigmoid激活且每个隐层2048个单元,输出层9004个单元,对应9004个状态.因此,两种语音增强方法的语音识别模型相同,结构都是825-2048-2048-2048-2048-2048-2048-9004.语音识别ASR-DNN使用最小交叉熵作为训练的目标函数.
4.2 数据库介绍
实验中使用的干净数据为800小时,共约100万句.内容主要是在安静近场环境下录制的访谈和讲话,对生活中常见的语音应用场景拥有较广的覆盖率.加噪用的噪声数据是在不同噪声环境下录制的,包括ktv、会议室、室外以及一个包含100种真实噪声的噪声数据库,可以通过脚注的网址下载*http://web.cse.ohio-state.edu/pnl/corpus/HuNonspeech/HuCorpus.html.噪声数据既包括平稳噪声,也包括非平稳噪声,且包含了多个频段分量,对生活中常见的噪声拥有较广的覆盖率.
测试集共有3个,为在不同环境下录制的真实数据,分别为:
1)在近场环境下录制的日常对话,共3431个条目,信噪比较低,在后面的总结中定义为测试集1.
2)在多种噪声环境下录制的日常对话,有电视背景噪声等远场干扰,共6407个条目,在后面的总结中定义为测试集2.
3)在会议室环境下录制的会议语音,存在说话人干扰,共2274个条目,在后面的总结中定义为测试集3.
4.3 实验结果及分析
为了验证渐进学习语音增强方法在语音识别中的有效性,在实验测试时,共比较了5种方法,分别定义如下:
1)方法1.使用传统深层神经网络的语音增强及识别方法作为基线系统,定义为方法1.
2)方法2.使用渐进学习语音增强及识别方法,其中语音增强模块使用目标1的输出,作为增强结果送到语音识别模块.
3)方法3.使用渐进学习语音增强及识别方法,其中语音增强模块使用目标2的输出,作为增强结果送到语音识别模块.
4)方法4.使用渐进学习语音增强及识别方法,其中语音增强模块使用目标3的输出,作为增强结果送到语音识别模块.
5)方法5.使用渐进学习语音增强及识别方法,其中语音增强模块使用目标1、2和3的加权平均,作为增强结果送到语音识别模块.
值得注意的是,前面定义的5种方法中,方法1作为基线,为使用传统深层神经网络的语音增强及识别方法的结果.方法2-5均为渐进学习语音增强及识别方法的结果,其中方法2-4分别对应使用3个目标输出结果,方法5为使用3个目标进行后处理的结果.
在表3中比较了5种方法的性能(评价指标为字正确识别率).这5种方法使用相同的声学模型训练算法,均是用一遍解码,且使用同一个语言模型,各方法识别率如表3所示.

表3 渐进学习和传统深层神经网络识别率比较Table 3 Compare of results of different models
从结果可以看出,在3个测试集上,使用渐进学习的语音增强及识别方法(方法4),比传统深层神经网络的语音增强及识别方法(方法1)的性能均有较大提升,以3个测试集的平均识别率作为性能指标,使用渐进学习的语音增强及识别方法相对于传统深层神经网络的语音增强及识别方法,在识别准确率上有10.28%的相对提升.同时可以看到,渐进学习方法即便是层数比较浅的目标层(如方法2只有1个隐层,方法3只有2个隐层)也优于层数较深的传统深层神经网络(方法1有3个隐层),原因正是因为渐进学习的语音增强及识别方法能比传统深层神经网络的语音增强及识别方法能更好地在前端进行降噪、提升信噪比,进而提高识别系统对噪声的鲁棒性.此外使用渐进学习的语音增强结果,经过后处理再作识别(方法5)能在不作后处理(方法4)的基础上,进一步提高性能,这是因为渐进学习的语音增强及识别方法能提供多个输出,提供了丰富的信息量,可以通过选择合适的后处理方法,进一步提高性能.最后我们考察该算法在降低网络模型参数方面的有效性,统计两种网络的参数量如表4所示.

表4 渐进学习和传统深层神经网络参数量比较Table 4 Compare of number of parameters of different models
从结果可以看出,在网络参数量方面,传统深层神经网络的参数量是渐进学习网络参数量的2.65倍,而性能却低于渐进学习方法.这说明在保证渐进学习的性能不低于传统深层神经网络的条件下,渐进学习方法可以大大降低网络参数,减少计算量,这也证明了渐进学习方法的有效性.
5 总结和展望
在本文中,主要讨论了渐进学习的语音增强方法在语音识别中的应用.通过以上实验,我们已经证明了该方法在识别中的有效性.它的主要优点在于:比起传统深层神经网络的语音增强方法,它大大减少了模型参数,减少了计算量,提高了系统的运行效率,同时可以输出包含丰富信息量的多个目标,这便于通过后处理进一步提高性能.但本文在训练过程中只使用了近场噪声,如果在训练过程中加入混响环境,那么在远场测试集上应该能够取得更好的结果,这也是下一步的研究工作.
[1] Li J,Deng L,Gong Y,et al.An overview of noise-robust automatic speech recognition[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2014,22(4):745-777.
[2] Seltzer M L,Yu D,Wang Y.An investigation of deep neural networks for noise robust speech recognition[C].2013 IEEE International Conference on Acoustics,Speech and Signal Processing,Vancouver,Canada,2013:7398-7402.
[3] Acero A.Acoustical and environmental robustness in automatic speech recognition[M].Springer Science & Business Media,2012.
[4] Loizou P C.Speech enhancement:theory and practice[M].CRC Press,2013.
[5] Du J,Wang Q,Gao T,et al.Robust speech recognition with speech enhanced deep neural networks[C].Proceedings of the 15th Annual Conference of the International Speech Communication Association,Singapore:2014:616-620.
[6] Benesty J,Makino S,Chen J.Speech enhancement[M].Springer Science & Business Media,2005.
[7] Boll S.Suppression of acoustic noise in speech using spectral subtraction[J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1979,27(2):113-120.
[8] Chen J,Benesty J,Huang Y,et al.New insights into the noise reduction Wiener filter[J].IEEE Transactions on Audio,Speech,and Language Processing,2006,14(4):1218-1234.
[9] Ephraim Y,Malah D.Speech enhancement using a minimum mean-square error log-spectral amplitude estimator[J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1985,33(2):443-445.
[10] Xu Y,Du J,Dai L R,et al.An experimental study on speech enhancement based on deep neural networks[J].IEEE Signal Processing Letters,2014,21(1):65-68.
[11] Gao T,Du J,Dai L R,et al.SNR-based progressive learning of deep neural network for Speech Enhancement[C].Proceedings of the 17th Annual Conference of the International Speech Communication Association,San Francisco,USA:2016:3713-3717.
[12] Gerkmann T,Krawczyk-Becker M,Le Roux J.Phase processing for single-channel speech enhancement:history and recent advances[J].IEEE Signal Processing Magazine,2015,32(2):55-66.
[13] Hinton G,Deng L,Yu D,et al.Deep neural networks for acoustic modeling in speech recognition:the shared views of four research groups[J].IEEE Signal Processing Magazine,2012,29(6):82-97.
[14] Mohamed A,Dahl G E,Hinton G.Acoustic modeling using deep belief networks[J].IEEE Transactions on Audio,Speech,and Language Processing,2012,20(1):14-22.
