上下文感知的移动社交网络好友推荐算法
2018-03-28孔聪聪陈曙东
孔聪聪,陈曙东
1(中国科学院大学 微电子学院,北京 100049) 2(中国科学院微电子研究所,北京 100029) 3(江苏物联网研究发展中心,江苏 无锡 214135)
1 引 言
随着智能移动设备的逐渐普及和通信技术的不断发展,移动社交网络服务也给用户带来了很大便利,而精准的好友推荐作为社交服务的重要一部分,可以给用户带来更好体验,对用户的行为偏好分析和网络服务推荐具有重要意义.虽然互联网领域的好友推荐技术已经趋于成熟,但是如何全面考虑移动互联网的移动性,实时性以及移动设备的便携性,上下文感知能力等特点,并将之应用到移动好友推荐中,提高推荐精准性和用户体验,成为移动好友推荐研究的重要研究方向.
在好友推荐领域内,传统的互联网领域推荐方法已经有很多,例如文[1]提出的基于协同过滤的好友推荐算法,根据用户兴趣相似度来进行推荐.文献[2]提出了一种基于网络图的朋友推荐方法,分析用户社交网络中的交互数据,设置权重推荐权重评分较高的用户作为好友.但是这些并不能适应移动互联网的特性.随着移动互联网的发展,移动环境下的上下文数据,例如地理位置,时间,同伴等,也被用于社交关系的挖掘.文献[3]使用链路预测的方法,综合考虑用户的之间的地理位置互动频率和时长,从而判断亲密度.文献[4]考虑时间上下文,利用朴素贝叶斯方法计算不同项目属于不同类别的概率,从而进行移动推荐,该算法只对时间分析,对于环境复杂的移动互联网有较大局限性.文献[5]提出一种基于多维相似度的好友推荐方法,计算时间兴趣等相似度通过差异距离进行评价,然而算法规则较为简单,不能很好发现规律.文献[6]提出一种基于相似度和信任度的关联规则算法STA,在时间和准确度上做了提升.文献[7]对移动领域好友推荐方面的研究进展进行了综述性介绍,指出上下文信息对提高推荐准确度有重要作用.然而很多方法在移动好友推荐中存在考虑因素单一,无法客观反映现实好友影响因素的不足.
本文面向移动互联网领域,考虑移动环境下的多种因素,在一种传统互联网好友推荐算法[2]上进行改进,提出一种基于移动上下文和影响力的好友推荐算法,首先根据通信数据计算用户间的通信社交信任度,之后利用用户之间的地理位置数据计算位置信任度,根据两方面的数据得到用户间的综合社交信任度,同时利用PageRank算法计算好友的影响力因子,最后使用一种基于社交图的好友推荐方法进行计算好友的推荐评分,得出用户的好友推荐列表.本方法创新性的考虑了移动上下文信息和影响力因子,并基于社交图进行算法实现,相对于传统协同过滤和关联规则等算法更好的反映好友之间的信息和关系网络,提高了推荐准确率.
2 基于图的移动好友推荐算法
本文面向移动互联网领域,提出一种基于移动上下文信息和用户影响力的好友推荐算法,一方面根据通信数据计算用户间的通信社交信任度,另一方面根据用户之间的地理位置数据计算位置信任度,结合两方面的数据得到用户间的综合社交信任度,并且利用改进后的PageRank算法计算好友的影响力因子,最后在优化的社交网络图上的进行好友的推荐评分计算,得出用户的好友推荐列表.
2.1 移动用户特征选取
移动互联网的用户特征一方面是通信数据,包括通话时长,通话频率,短信频率等;一般用户之间联系越频繁,则表示双方关系越紧密.然而现实社会中,单方面的高频通信并不能代表两者熟识,也可能是广告等骚扰信息,所以本文在数据选取时只选择用主动通信的数据,在构建网络时,也选取双方均有交互的关系链,剔除只有单方通信的数据.
而移动场景不同于一般互联网场景的特征在于其移动性,及其移动上下文信息.因此,在做好友推荐时应加入移动上下文信息,本文选取用户的移动地理位置交互数据,来更全面的进行网络构建.现在大多数用户都会随身携带手机,无线通信技术,GPS等技术可以方便记录用户的地理位置数据,而当两个用户在一段时间内处于同一位置,并且有经常性的这种交互,我们也可以认为两者之间存在一定的社交关系.
同时本文考虑好友之间的影响力因素,一般来讲,与其他人交互越多,影响力越大的人,其好友越多,也越容易与他人成为好友,因此用适当方法衡量好友的影响力因子,加入好友推荐中,也是本文的研究所在.因此,本文创新地将地理位置交互时长,交互频率作为参数加入的社交网络的构建中,考虑影响力因子,从而进行更合理的好友推荐.
2.2 移动社交信任度
移动场景由于其特殊性,具有很多因素可以考虑,因此本文的移动社交信任度,主要考虑两个方面,包括通信数据信任度与地理位置信任度,其中通信数据信任度包括了通话频率,通话时长,短信频率这三方面,而地理位置信任度包括了地理交互频率,交互时长这两个指标.
2.2.1 通信数据信任度计算
在移动通信领域中,用户主要通过语音通话和短信短信交流两种方式进行通信通信,因此用户之间的通信频率和时长是衡量好友关系紧密度的重要指标.而根据上文的分析,本文在数据选取时只选择用户主动通信的数据,即主动通话或短信的数据,在构建网络时,也选取双方均有交互的关系链,剔除只有单方通信的数据.
定义1.一定时间周期内,用户i对用户j 的通话次数为Vofrei,通话时长为Voduri,短信次数为Smsfrei,而用户i对所有用户的通话次数为∑Vofre,通话时长为∑Vodur,短信次数为∑Smsfre,则用户i对用户j的通信数据信任度CommTri定义如下:
(1)
2.2.2 地理位置信任度计算
在移动通信领域中,由于移动设备的随身性,移动性,使得我们可以利用地理位置信息分析真实用户的的社交关系成为可能.即用户之间处于同一位置交互次数越多,时间越长,则越有显著的社交关系.本文基于用户之间移动设备的蓝牙交互频率和时长来构建地理位置信任度.由于蓝牙设备的短距离交互性,设备之间交互频率越高、时长越长说明用户处于同一位置的次数越多、交流时间也越长,关系可能越亲密.
定义2.一定时间周期内,用户i对用户j的处于同一位置的交互次数为LocFrei,交互时长为LocDuri,而用户i对所有用户的交互次数为∑LocFre,交互时长为∑LocDur,则用户i对用户j的地理位置信任度LocTri定义为:
(2)
本文中α,β定为0.5,0.5.
2.2.3 综合社交信任度
综上,通过通信数据信任度和地理位置信任度计算得到综合社交信任度,如下
定义3.用户i对用户j 的通信数据信任度为CommTri,地理位置信任度为LocTri,则综合社交信任度MulTri为:
MulTri=λ*CommTri+(1-λ)*LocTri
(3)
2.3 构建网络评分预测
2.3.1 构建网络
在传统社交网络的研究中,一般可以用图来表示社交网络关系,其中节点代表用户,边代表用户之间的社交联系,以此来清晰的描述用户的社交关系.因此,图论在也广泛应用于社交网络的分析中.本文对一种传统互联网领域的好友推荐方法进行改进[2],利用上文计算出的综合社交信任度,推导出用户的好友列表.
由上文得出的综合社交信任度和社交关系,可以构建原始的有向带权网络图,其中节点表示用户,边表示用户之间的联系,箭头指向接收方.有向边的权重为发起方对接收方的综合社交强度,由此可以构建下页图1的原始有向社交网络图.
而真实社交关系中,一般交互应该为双向的,如果某方单方面主动联系,很有可能只是广告或骚扰行为,因此由于通信的不对称,单方高强度并不能表示双方熟识,所以去掉只有单向的边,并把双向有向边改为无向边,去最小权重为无向边权重.由此可构建无向带权信息图,见下页图2.
由于根节点用户到各个目标用户联系是层间直接联系的,同一层之间的联系显然是没有用的,例如A到C,是直接联系C,而不是经过B到C.因此同一层之间的边也可以去掉.由此得到最小无向带权信息图,见下页图3.
2.3.2 影响力因子
本文考虑好友之间的影响力因素,一般来讲,影响力越大的人,其好友越多,与好友互动联系也越多,也越容易与他人成为好友,因此用适当方法衡量好友的影响力因子,加入好友推荐中,也是本文的研究所在.PageRank算法[9]是为了衡量网页的相对重要性,它是基于网络中的图,计算每个网页的重要性排名.而在社交网络中评估一个用户的影响力,就是评估该用户在网络中的重要性排名.社交网络与网页之间形成的网络非常类似,PageRank同样也可以应用到社交网络影响力评估中去.因此本文提出的基于图的社交网络利用PageRank算法来进行用户影响力因子的评定,即每个节点j计算的影响力因子inf(j)为:

图1 原始带权网络图Fig.1 Original directed weighted graph

图2 无向带权信息图Fig.2 Undirected weighted graph
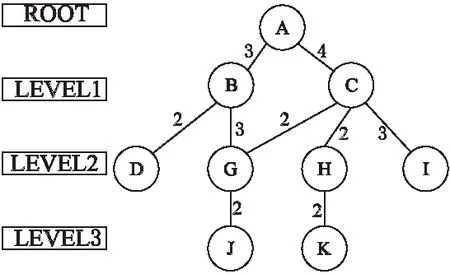
图3 最小无向带权图Fig.3 Minimum undirected weighted graph
inf(j)=Pr(j)*(1/level)
(4)
其中Pr(j)为节点的PageRank分数,level为节点j的层数.
2.3.3 评分预测
得到图3的网络图后,可以根据公式(4)对每个好友进行推荐评分.
(5)
其中Pk(j).Csum表示根节点i到节点j第k条最短路径上所有权值的和,W(Sl-1,Sl)表示节点Sl-1和Sl之间的移动社交强度,同第l层与第l-1层中所有相关节点间的权重之和的比值.其中level表示节点j的层数,即距离根节点的条数,Pr(j)表示节点j的 PageRank值.由于权值表示社交强度所以推荐评分应与之成正比,而层数代表了好友间的关系层次,层数越小,距离越近则关系越近,故评分应与之成反比;且每条路径代表i和j之间有一条关系链,故每条关系链都会贡献推荐评分,故需要将所有关系链的评分加起来.而节点的影响力只与节点自身相关,节点本身影响力越大,越容易与他人成为好友,故不需要涉及到路径上其他节点的影响力.
例如当网络图如图3时,目标节点为G,那么根节点A到G有两条路径,(A,B,G),(A,C,G),那么评分就是
(6×(3/7)+6×(4/7))×(1/2)=3,加上算出的PageRank评分值,即为综合推荐评分.
2.4 算法描述
综上,本文在文献[2]的WMR算法基础上进行的改进算法CFRM,步骤如下:
输入:表示用户关系的最小无向信息图
输出:用户的推荐好友列表
步骤1.根据最小无向信息图构建的以目标用户为源节点的层次关系树Tree,其中layer表示当前层次节点的集合,level表示当前指向的层次.
步骤2.找出根节点i到目标节点j的所有路径,对每条路径计算其权值总和,并乘上节点Sl-1和Sl之间的移动社交强度,同第l层与第l-1层中所有相关节点间的权重之和的比值,之后将每条路径的计算结果进行求和,乘上当前层数level的倒数.
步骤3.计算目标节点的PageRank值,同时也乘上当前层数的倒数,与步骤2的结果做和,得出最终推荐评分ReScore.
步骤4.对每个节点计算其到其他节点的推荐评分,即重复步骤2、3,对结果进行排序,得出每个节点推荐列表.
3 实验及结果分析
3.1 数据集及环境介绍
基于隐私和商业数据安全的考虑,因此本文利用MIT现实挖掘项目所提供的真实数据集reality mining[10]进行实验分析.该数据集包含了94个用户半年间的手机使用记录,其中有移动通话数据、短信数据、位置交互数据、应用程序使用数据等.该数据集同时还包括94个用户间的真实好友关系,可做实验正确性比对等.
本文用MATLAB处理原始数据集,由于原数据集包含通话信息,位置信息,mac信息,电量,应用软件等五十多项属性,还有一些数据关键属性缺失,所以需要进行清洗过滤,提取包含了通话、短信、位置、蓝牙交互等信息的属性,并且剔除缺失属性的数据.利用Python,及networkx包进行算法实现.硬件环境:window7系统,intel core i5 CPU,4G内存.
3.2 评价指标
好友推荐的结果分析一般用准确率与查全率对算法进行合理性和有效性的评估[11],其中准确率(Precision)为推荐出的已经成为好友的用户与推荐出的好友用户的比值,反映了推荐算法的准确程度.查全率(Recall)为推荐出的已经成为好友的个数与好友总个数的比值,反映了推荐方法的推荐广度.
在实验过程中,使用不同推荐比率评估性能,并取全部用户准确率和查全率的平均值作为算法在当前推荐比率下的性能表现.
3.3 实验步骤及结果分析
实验中,首先对原始数据集进行处理,剔除无效数据,提取有用的数据信息,本文用MATLAB处理原始数据集,提取mac,device_list,device_macs,device_names,neighborhood,comm,com_voice,comm_voice_date,comm_sms,comm_sms_date等属性,包括了有用的通话数据、短信数据,地理位置数据等,之后按照公式(1),(2),(3),(4)进行数据处理,并对公式(3)中λ进行测定,从测定结果准确率和查全率分析,发现当为0.6的时候准确率,查全率均较高,故选定λ为0.6.之后得出最小无向信息图.最后实验过程利用Python2.7进行算法实现.
由于本文是在文献[2]中提出的WMR算法上进行改进的,加入了移动上下文因素等,为验证本文算法的有效性和创新性,本文对WMR算法以及文献[3]提出的Friend Sensing(FS) 方法和文献[6]的STA算法进行对比实验.分析四种算法的准确率和查全率表现,对各个算法进行效果分析.
3.3.1 准确率分析
准确率反映了推荐算法的准确程度,图4位四种好友推荐算法准确率的对比图,可以看出,本文提出的算法CFRM(Context-aware Friend Recommendation algorithm based on Mobile network),准确率总体上明显高于原始算法WMR、FS和STA算法,尤其是当推荐比率较小时,由于本文算法因素考虑更全,以及所用图算法效率更高,准确度更高,例如当推荐比率为20%时,本文算法准确率达到52.63%,高于WMR算法的43.74%、FS算法的41.5%和STA算法的50.23%.而实际推荐时,为保证准确率,推荐比率一般不高于20%.而由于每个用户的好友数固定,当推荐比率增加时,准确率也会随之降低,并最终稳定下来,因此推荐比率60%之后,四种算法推荐的准确率差异不再明显.

图4 准确率Fig.4 Precision
3.3.2 查全率分析
算法的查全率反映了推荐算法挖掘出好友关系的广度.图5是四种算法查全率的对比图,可以看出在推荐比率较低时,本文算法CFRM查全率显著高于原算法WMR、FS算法和STA算法,例如当推荐比率为20%时,本文算法CFRM的查全率是41.2%,高于原算法WMR的30.19%、FS算法的34.89%和STA算法的35.25%.同样真实系统中中往往较低的推荐比率才是有效的.同时由于移动互联网环境获取用户信息的不完整性,当推荐比率较高时,4种算法查全率性能方面表现差异不再明显.

图5 查全率Fig.5 Recall
4 结 论
本文面向移动互联网领域,提出一种基于移动上下文和用户影响力的好友推荐算法CFRM,首先根据通信数据计算用户间的通信社交信任度,之后利用用户之间的地理位置数据计算位置信任度,根据两方面的数据得到用户间的综合社交信任度,同时利用PageRank算法计算好友的影响力因子,最后在优化的社交网络图上的进行好友的推荐评分计算,得出用户的好友推荐列表,进行社交网络构建.
本文搭建了实验环境,利用MIT reality mining数据集进行算法的功能和性能测试.实验结果表明该算法具有良好的性能,具有很好的正确性和查全率,在移动领域的好友推荐,充分考虑社交关系,影响力和地理位置等综合信息在移动领域会取得更好的推荐效果.
本文算法的功能和性能测试是在模拟环境中进行的,特别过滤掉了时间场景对算法的影响,在接下来的工作中,会进一步完善时空综合场景的分析.同时会将本文的CFRM算法扩展应用到移动互联网的应用服务推荐中,结合本文构建的好友社交关系和时空信息等,进行个性化的服务推荐等.
[1] Guy I,Ur S,Ronen I,et al.Do you want to know?:recommending strangers in the enterprise[C].Proceedings of the ACM 2011 Conference on Computer Supported Cooperative Work,ACM,2011:285-294.
[2] Lo S,Lin C.WMR-A graph-based algorithm for friend recommendation[C].Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence,IEEE Computer Society,2006:121-128.
[3] Quercia D,Capra L.FriendSensing:recommending friends using mobile phones[C].Proceedings of the Third ACM Conference on Recommender Systems,ACM,2009:273-276.
[4] Yu Z,Zhou X,Zhang D,et al.Supporting context-aware media recommendations for smart phones[J].Pervasive Computing,IEEE,2006,5(3):68-75.
[5] Wang Shan-shan,Leng Su-peng.Friend recommendation method for mobile social networks[J].Journal of Computer Applications,2016,36(9):2386-2389,2395.
[6] Wang Tao,Qin Xi-zhong,Jia Zhen-hong,et al.Association rules recommendation of microblog friend based on similarity and trust[J].Journal of Computer Applications,2016,36(8):2262-2267.
[7] Meng Xiang-wu,Hu Xun,Wang Li-cai,et al.Mobile recommender systems and their applications[J].Journal of Software,2013,24(1):91-108.
[8] Liu Shu-dong,Meng Xiang-wu.Approach to network services recommendation based on mobile users′ location[J].Journal of Software,2014,25(11):2556-2574.
[9] Page L,Brin S,Motwani R,et al.The PageRank citation ranking:bringing order to the web[J].Technical Report.Stanford InfoLab,USA,1998.
[10] Eagle N,Pentland A.Reality mining:sensing complex social systems[J].Personal and Ubiquitous Computing,2006,10(4):255-268.
[11] Meng Xiang-wu,Shi Yan-cui,et al.Review on learning mobile user preferences for mobile network services[J].Journal on Communications,2013,34(2):147-155.
[12] Qiao X,Su J,Zhang J,et al.Recommending friends instantly in location-based mobile social networks[J].China Communications,2014,11(2):109-127.
[13] Zhao G,et al.Service rating prediction by exploring social mobile Users′ geographic locations.IEEE Trans[J].Big Data,March.2016,DOI:10.1109/TBDATA.2016.2552541.
附中文参考文献:
[5] 王珊珊,冷甦鹏.面向移动社会网络的好友推荐方法[J].计算机应用,2016,36(9):2386-2389,2395.
[6] 王 涛,覃锡忠,贾振红,等.基于相似度和信任度的关联规则微博好友推荐[J].计算机应用,2016,36(8):2262-2267.
[7] 孟祥武,胡 勋,王立才,等.移动推荐系统及其应用[J].软件学报,2013,24(1):91-108.
[8] 刘树栋,孟祥武.一种基于移动用户位置的网络服务推荐方法[J].软件学报,2014,25(11):2556-2574.
