一种融合近邻用户影响力的矩阵分解推荐算法
2018-03-28李昆仑郭昌隆关立伟
李昆仑,郭昌隆,关立伟
(河北大学 电子信息工程学院,河北 保定 071000)
1 引 言
随着互联网经济的高速发展,商品种类与数量均呈爆发式增长.在此情况下,能够利用各种已知信息刻画出用户喜好并为之推送感兴趣内容,进而将潜在购买力转化为实际购买力的推荐算法受到了越来越多的重视.它在帮助用户从海量商品中快速准确发现感兴趣商品的同时也极大地提高了网站的销售额与用户忠诚度.
推荐系统的概念最初由斯坦福大学MarkoBalabanovic等人提出.其主要分为两大类:基于内容的推荐以及基于协同过滤的推荐[1].基于内容的推荐建立在项目内容的相似性上,通过比较用户喜好物品与推荐物品的相似性来产生推荐.例如在文本推荐中,TF-IDF算法通过计算文章中某些关键字所对应的权重,进而将有着相似的关键字权重的文章推荐给读者.而基于协同过滤的推荐建立在相似用户(或项目)对于相似项目的评分也是相似的这一假设之上.例如基于用户的top-N算法[2-5],首先根据用户相似性得到与目标用户最为相似的N个用户,其后从这N个用户中寻找评分最高的商品推荐给目标用户;同理基于项目的推荐则是寻找用户评分较高的项目,并将与之类似的项目推荐给用户.
矩阵分解算法近来已经逐渐应用于推荐系统中.传统的矩阵分解算法包括奇异值分解[6](Singular Value Decompostion),QR分解(QR Factorization),三角分解法(Triangular Factoriz-ation)等等.随着研究的深入,针对SVD分解出现负值的问题提出了非负矩阵分解[7,8]的方法,增加了推荐结果的可解释性;Parivash等人利用矩阵分解算法对用户对相似度矩阵进行填充以此改善数据稀疏问题[9];Mnih等人以SVD为基础,假设用户与物品的隐式特征符合高斯分布进而得到最有可能的用户与商品信息矩阵[10].但以上方法均试图将高维数据分解为低维数据,仅考虑了用户与商品各自的属性问题,并未意识到用户之间也蕴含着复杂的关系.因此本文针对此问题从邻近用户对目标用户的影响出发,提出了一种融合近邻用户影响力的矩阵分解推荐算法,在考虑用户信息与评分信息的同时,将近邻用户的影响力融入到矩阵分解模型中并通过优化目标函数训练此模型,之后利用此模型对用户的评分进行预测.实验结果表明本文算法相较传统推荐算法其推荐精度有明显提高.
2 相关工作
2.1 近邻用户的相似性度量
用户间的影响相当复杂,仅通过用户间有无共同评分项来判断两者之间有无影响是不准确的.例如作为目标用户的家人、老师等,可能因年龄段等问题其共同购买或评价的商品很少,但依旧能通过一些日常行为影响到用户对某些商品的评价.而采用传统的如余弦相似度和皮尔逊相似度等方式在寻找用户近邻时可能会面临共同评分项极少甚至无共同评分项的情形,导致其效果很差,严重影响目标用户近邻的确定.考虑到共同评分项很少或无共同评分项的用户之间其评分趋势是相似的这一事实,我们采用一种基于Cloud-model[11]的相似度计算方法,从统计学意义上考虑用户间评分的相似性.
2.1.1Cloud-model
Cloud-model最初是李德毅在解决概率论和模糊数学等问题时提出的一种进行定量与定性之间转换的数学模型[11].模型用Ex(期望),En(熵),He(超熵)三个参数来表征一个模糊的概念,从而将事物的模糊性与随机性有机结合在一起.在某个数域空间中,模型中的数值点(云滴)在如上三个参数控制下选取和产生,其产生的数值点(云滴)构成了整个模型(Cloud-model).因其在三维空间中成云状,因此也称其模型为云模型.其模型定义如下:
定义:云和云滴:设U为某个模糊集合,C是U上的定性概念.若数值a∈U是C上的一次随机实现,A对于C的确定度y(a)∈[0,1]是有稳定倾向的随机数且y:Y→[0,1] ∀a∈Y a→y(x),则所有的a在模糊域U上的分布可称为云.而云中的每个数值a可称作云滴.其中Ex表示a在模糊域U上分布的期望,En表示C的可度量性,且En的大小与其C的模糊性呈正比.He表示熵的不确定性,由熵的随机性和模糊度共同确定[12].
如将每位用户U视为一个Cloud-model,则其对物品的评分值r为隶属于云U上的云滴,用户所有的评分项构成用户U的Cloud-model.若用户之间的评分趋势相似,则其构成的Cloud-model也将是相似的.由此通过比较两者模型即可得到用户间的相似度,进而避免了余弦相似度等传统方法在面临共同评分项较少时误差较大的缺点.
2.1.2 逆向云算法
若用户间的Cloud-model是相似的,则控制其云滴(评分)产生的三个参数Ex(期望),En(熵),He(超熵)所构成的三维向量也应是相似的.本文通过逆向云算法求取上述三个参数.此算法是基于数理统计的样本均值和样本方差的均值算法,也可以称其为均值法.其步骤如下:
输入:n个云滴(评分值){r1,r2,r3,…rn-2,rn-1,rn}
输出:控制云滴产生的三个参数Ex,En,He
步骤:
1)①计算云滴的样本均值:
(1)
②计算云滴的一阶样本绝对中心距:
(2)
③计算云滴的方差:
(3)
2)根据(1)、(2)和(3)式得到其模型的Ex,En,He:
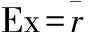
(4)
(5)
(6)
2.1.3 基于Cloud-model的相似度计算
每位用户的Cloud-model用向量(Ex,En,He)表示,则比较用户相似度时只需比较代表其Cloud-model的向量相似度即可.但仅用Ex,En,He三者构成的向量在计算相似度时面临一个问题:假设U(Eau,Enu,Heu)与V(Eav,Env,Hev)两者均与欧式空间中某条直线平行,若采用余弦相似度等方法得到其相似度定为1,但两者所代表的Cloud-model显然不同.在计算向量相似度时一般认为两者的距离与其相似度成反比,于是得到向量U与V的距离表达式:
(7)
同时引入一个单调递减的指数函数,将距离标准化到(0,1)之间:
D(dis(U,V))=e-dis(U,V)
(8)
显然此函数与距离成反比,当距离为0时函数值为1,表示两者相似度最大,当距离为无穷时函数值为0,表示两者相似度最小.
2.2 矩阵分解
矩阵分解模型
矩阵分解其目的是将高维的户-项目评分矩阵分解为低维的用户隐含信息矩阵和物品隐含信息矩阵.其算法涉及三个矩阵:用户信息矩阵P:{u1,…,um},物品信息矩阵Q:{i1,…,in},以及评分矩阵R.其原理是由两个低秩矩阵P,Q构造的预测矩阵相乘逐渐逼近原评分矩阵R(训练集)进而进行参数训练,并将训练完毕后的各参数应用到推荐模型之中.即:
(9)
(10)
其中μ为所有项目评分的平均值,bu为用户偏置矩阵,bi为项目偏置矩阵.bu表示某用户的平均评分,用户的bu大(小)表明此用户评分普遍偏高(低).同样某项目的bi大(小)表明整体用户对此项目的评分普遍偏高(低).
3 基于近邻用户影响力的矩阵分解模型
为了反映出近邻用户对目标用户的影响,本文提出的一种基于近邻用户影响力的矩阵分解算法将近邻用户对目标用户的的影响力融入到矩阵分解模型中去.假设近邻用户对目标用户产生的影响力用W表示,则N个近邻用户对目标用户的影响力可以表示为:
(11)
其中T(a)表示近邻用户的集合,wf代表每位近邻用户产生的影响力的隐式反馈.于是得到一个如下所示的新的评分模型:
(12)
设损失函数为SSE,表示所有误差的平方和:
(13)

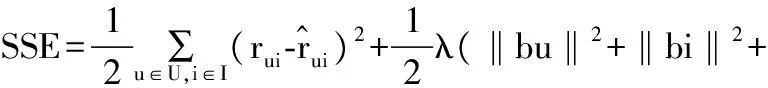
(14)
采用随机梯度下降法最小化损失函数,设α为损失函数中需要更新的参数,则在任意一次更新中的任意参数的更新式为:
α←α+Δα
(15)

(16)
根据(15)式,将(11),(12),(13),(14)式带入(16)式中,则得到各参数的如下更新式:
(17)
其中η为更新步长.
实验步骤:
输入:用户与项目所组成的评分矩阵,过拟合因子λ,更新步长η,最大迭代次数N以及最小提升阈值M.
输出:用户U对项目i的预测评分
Step1.根据评分矩阵得到用户的Cloud-model,利用逆向云算法得到用户的Ex,En,He值.
Step2.用向量(Ex,En,He)表示每位用户的评分模型,通过比较向量的相似性得到与目标用户相似的N个近邻用户.
Step3.构造近邻用户的影响力模型W,将其融入矩阵分解模型中得到新的评分模型:
Step4.根据评分模型对预测矩阵进行参数训练:
1:for(最大迭代次数或者最小提升阈值)
2: for(循环遍历每一名用户):
3: for(循环遍历每一个项目):
4: (计算用户对此项目的预测评分以及与真实评分的误差e
5:更新各项参数
6: end
7: end
8:end
4 实验及分析
4.1 数据集
为验证本文算法的有效性,实验采用由Minnesota大学的Grouplens项目组提供的Movielens数据集,记录了943位用户对1682部电影共计10万条的评分记录.用户评分值在1-5分之间.分数低(高)代表用户对电影不满意(满意).在整个实验中,每次随机抽取20%的用户作为测试集,另外80%作为训练集.
实验环境:CPU 为Intel(R)-Core(TM) i5-2450M @ 2.50GHz、内存为6GB的微机;软件为Python2.73.
4.2 度量标准
本文采用均方根误差(RMSE)作为度量标准.RMSE的值越小证明算法的准确度越高.

4.3 实验结果及分析
实验将从如下几方面来验证本文算法的有效性:不同近邻个数对本文算法(NUISVD)的影响;不同隐因子个数对本文算法的影响;不同正则化系数对本文算法的影响;对比本文算法与BSVD在不同隐因子个数条件下的差别;采用余弦相似度与Cloud-model在获取近邻用户时对本文算法的影响;对比本文算法与BSVD算法在相同学习率、正则化系数以及隐因子个数情况下的收敛速度.
4.3.1 不同近邻个数对本文算法的影响
如表1所示,在保持其他参数不变的情况下,选取不同数量的近邻个数,验证不同近邻个数对本文算法以及传统的基于用户相似度(UBCF)的推荐算法的影响.

表1 不同近邻个数对本文算法的影响Table 1 Influence of different nearest numbers
图1为上述两算法在表1所给出的各项参数下所获得的结果.
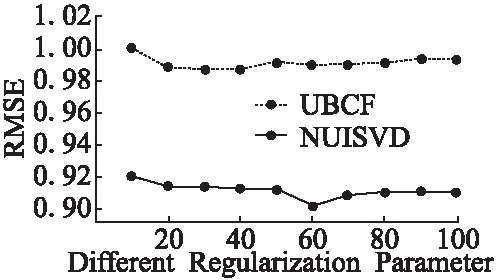
图1 不同近邻个数对本文算法的影响Fig.1 Influence of different nearest numbers
如图1所示,显示了传统的基于用户相似度的推荐算法(UBCF)与本文算法在表1各参数下所获得的推荐精度.可看出本文算法在近邻个数为60时取得结果约为0.90,且在近邻个数为10-100的情况下,本文算法所获得的精度均远远高于UBCF.但无论是传统的基于用户相似度的推荐算法还是本文算法,其精度均不会随着近邻个数的增加而持续提高.
4.3.2 不同正则化系数对本文算法的影响
如表2所示,在保持学习率,隐因子个数,迭代次数不变的情况下,给定不同正则化系数,验证不同正则化系数对本文算法的影响.

表2 正则化系数对本文算法影响Table 2 Influence of regularization parameter on NUISVD
图2为在表2所给出的各项参数下,本文算法所得到的推荐精度.

图2 不同正则化系数对本文算法的影响Fig.2 Influence of regul-arization parameter on NUISVD
如图2所示,可以看出算法在迭代20次左右时趋于稳定,在迭代次数为5-10时,正则化系数为0.145的曲线所对应的RMSE最小且下降最快,但在迭代次数约为15次之后,正则化系数为0.160的曲线所对应的RMSE最小.可见正则化系数小,则RMSE下降快,但过小的正则化系数有可能会造成算法的过拟合现象进而影响算法精度.可正则化系数过大时,则又会导致RMSE下降速度过慢,增加了算法的迭代次数以及计算成本.
4.3.3 本文算法与BSVD算法在不同隐因子个数下的对比
如表3所示,在保持学习率,正则化系数,迭代停止条件以及次数不变的情况下,验证不同隐因子个数对本文算法以及BSVD算法的影响.
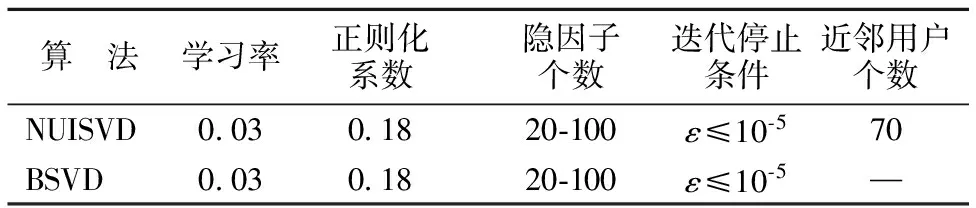
表3 本文算法与BSVD算法在不同隐因子个数下的对比Table 3 NUISVD and BSVD in different latent factors
图3为本文算法与BSVD算法在表3所给出的各项参数下得到的结果.

图3 不同隐因子个数对UNISVD和BSVD算法的影响Fig.3 NUISVD and BSVD in different number of latent factors
如图3所示,是本文算法与BSVD算法在上述表3各项参数下所获得的推荐精度.可以看出BSVD算法在隐因子个数为80时推荐精度趋于稳定且取得最高的推荐高精度约为0.919,本文算法在隐因子个数为70时趋于稳定,且在隐因子个数为90时取得的最高精度为约为0.901.且在表3各项参数下本文算法的推荐精度均高于传统的BSVD算法,这是因为相较于BSVD而言,本文算法将近邻用户的影响力加入其中,从而提高了推荐精度.而且还可看出两算法在隐因子个数为40至80之间时,其推荐精度呈现出逐渐减缓的上升趋势,之后均趋于稳定.证明适当增加隐因子个数会提高算法的精确度,但隐因子个数过多时其精确度提高并不明显,反而增加了计算的复杂度.

表4 余弦相似度与Cloud-model的对比Table 4 Comparison of Cosine similarity and Cloud-model
4.3.4 余弦相似度与Cloud-model在相同近邻个数时的对比
如表4所示,在保持学习率、正则化系数、隐因子个数及迭代次数相同的情况下,比较余弦相似度(COS)与Cloud-model(CM)在获取同等数量的近邻时对算法的影响.
图4为本文算法在上述表4中各参数情况下采用余弦相似度和Cloud-model获取相同数目的近邻时得到的推荐精度:

图4 余弦相似度与Cloud-model的对比Fig.4 Comparison of cosine similarity and Cloud-model
由图4可以看出,本文算法无论是采用余弦相似度还是Cloud-model均在近邻个数为60时取得最高推荐精度,但相较于余弦相似度,采用Cloud-model所获得的推荐精度要明显高于前者.这是由于在遇到用户间共同评分项很少甚至没有共同评分项的极端情况时,余弦相似度得到的目标用户近邻的准确性较低,而Cloud-model则是从统计学意义上根据用户的评分趋势获得目标用户的近邻,从而有效避免了上述问题.
4.3.5 本文算法与BSVD算法在相同系数下的收敛速度
如表5所示,在保持各项参数相同的情况下,比较本文算法(NUISVD)与BSVD算法的收敛速度.

表5 NUISVD与BSVD的收敛速度Table 5 Convergence rates of NUISVD and BSVD
下页图5为本文算法与BSVD算法在相同参数下迭代300步的收敛曲线.
可看出在相同参数情况下,本文算法RMSE的下降速度明显快于BSVD算法.

图5 本文算法与BSVD的收敛速度Fig.5 Convergence rates of NUISVD and BSVD
这是因为在相同参数情形下,本文引入了近邻用的影响力,考虑了更多影响推荐精度的因素,但同样因为用户影响力的引进也使得本文算法每一步的计算复杂度要高于传统的BSVD.
5 结论和未来工作
本文针对用户间的影响力作用提出的基于近邻用户影响力的矩阵分解推荐算法,与传统矩阵分解推荐算法相比在考虑用户与商品各自隐含信息的同时还综合考虑了用户间的隐含联系,并将其融入到了矩阵分解中去.通过实验表明,相较于传统基于用户相似度的推荐算法以及BSVD算法而言,本文算法在推荐精度上有较大的提高.
影响力是具有时效性的.因此在未来研究中我们将考虑上述问题,通过建立影响力的时效性模型并尝试将其融入到矩阵分解推荐算法中,相信可以取得更为优异的推荐精度.
[1] Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[C].Proceeding of the 10th international Conference on World Wide Web,ACM,2001:285-295.
[2] Hoens T R,Blanton M.A private and reliable recemendation system for social networks[C].Proc.of the IEEE Social Com.Washington:IEEE Computer Society,2011:816-825.
[3] Min J K,Cho S B.Mobile human network management and recommendation by probabilistic social mining[J].IEEE Trans.on Systems,Man and Cybernetics,Part B,2011,41(3):761-771.
[4] Colombo-MendozaLO,Valencia-GarcíaR,Rodríguez-Gonzál-ez A,et al.A context-aware knowledge based mobil recommender system for movie showtimes[J].Expert Systems with Application,2015,42(3):1202-1222.
[5] Kasap O Y,Tunga M A.A polynomial modeling based algorithm in top-N recommendation[J].Expert Systems with Applications,2017,79:313-321.http://dio.org/10.1016/j.eswa.2017.03.005
[6] Zhang X D,Feng X C,Wang W W.Two-direction nonlocal Model for image denoising[C].IEEE Transactions on Image Processing,2013,22(1):408-412.
[7] San Juan P,Vidal A M,Garcia-Molla V M.Updating/downdating the NonNegative matrix factorization[J].Journal of Computational and Applied Mathematics,2017,318:59-69.http:// dio.org/10.1016/j.cam.2016.11.048.
[8] Yang Yong-sheng,Ming An-bo,Zhang You-yun.Discriminative non-negative matrix factorization (DNMF) and its application to the fault diagnosis of diesel engine[J].Mechanical Systems and Signal Processing,2017,95:158-171.
[9] Wang Xi-men,Liu Yun,Xiong Fei.Improve personalized recommendation based on a simliarity network[J].Physica(A),2016,456:271-280.
[10] Mohsen Jamali,Mtin Ester,A matrix factorization technique with trust propagtionfor recommendation in social net work[C].ACM Recomemender System,2010:135.
[11] Zhang Guang-wei,Li De-yi,Li Peng,et al.A collaborative filtering recommendation algorothm based on cloud model[J].Journal of Software,2007,18(10):2403-2411.
[12] Xu Xuan-hua,Wang Pei,Cai Chen-guang.Linguistic multiattribute large group decision-making method based on similarity measurement of cloud model[J].Control and Decision,2017,3(32):459-466.
[13] Zhu X,Huang Z,Shen H T,et al.Dimensionality reduction by mixed kernel canonical correlation analysis[J].Pattern Recognition,2012,45(8):3003-3016.
[14] Ma H,Zhou D,Liu C.Recommender system with social regularization[C].Proceedings of the 4th ACM International Conferenec on Web Search and Datam Mining,Hong Kong,China,2011:287-296.
[15] Zheng N,Qi L,Guan L.Generalized multiple maximum scatter difference feature extraction using QR decomposition[J].Journal of Visual Communication &Image Representation,2014,25(6):140-147.
[16] Song F X,Cheng K,Yang J Y,et al .Maximum scatter difference,large margin linear projection and support vector machines[J].Acta Automatical Sinical,2004,30(6):890-896.
[17] Gao S,Tsang I W H,Chia L T.Sparse representation with kernels[J].IEEE Transactions on Image Processing,2013,22(2):423-434.
附中文参考文献:
[11] 张光卫,李德毅,李 鹏,等.基于云模型的协同过滤推荐算法[J].软件学报,2007,18(10):2403-2411.
[12] 徐选华,王 佩,蔡晨光.基于云相似度的语言偏好信息多属性大群体决策方法[J].控制与决策,2017,3(32):459-466.
