欺诈网页检测中基于遗传算法的特征优选
2018-03-20王嘉卿陈同孝张真诚
王嘉卿,朱 焱,陈同孝,张真诚
(1.西南交通大学 信息科学与技术学院,成都 611756; 2.台中科技大学 资讯工程系,台湾 台中 404; 3.逢甲大学 资讯工程系,台湾 台中 407)(*通信作者电子邮箱yzhu@swjtu.edu.cn)
0 引言
为了谋取高额利润,部分网站建设者利用变化多端的非法手段欺骗搜索引擎,以提高网站的关键排名进行网页欺诈。寻找高效有力的欺诈网页检测方法极为重要。针对欺诈网页的检测是一个二元分类问题(欺诈和正常),特征选择和分类算法是研究的焦点。Goh等[1]通过实验证明分类结果强依赖于使用的特征集合,并且不同的分类器带来的结果差异远小于不同的特征集合。本文侧重于特征选择,旨在找到最佳最小特征集合(Optimal Minimum Feature Set, OMFS),减小分类器计算代价,提高检测效率。
网页基本特征包括链接特征,如:网页的入度、出度、PageRank值[2]以及内容特征,如:网页单词数、平均单词长度。对应的网页欺诈分为链接欺诈、内容欺诈和隐藏型欺诈[3]。在使用网页基本特征的基础上,针对不同欺诈类型提取新特征,改进分类算法是近年来国内外学者研究的重点,取得的成果也较为显著。Araujo等[4]专注于网页链接质量分析,提取有效的基于链接的特征并构建语义模型,最后结合代价敏感的决策树分类器得到较高的真阳性率(True Positive Rate, TPR)、F1值和受试者工作特征曲线面积(Area Under receiver operating Characteristic, AUC)。Ntoulas等[5]提出了多个基于内容的特征,并结合分类器得到了良好的检测结果。Kumar等[6]提出了一个双边多分类的超球面支持向量机模型(Dual-Margin Multi-Class Hypersphere Support Vector Machine, DMMH-SVM)和多个新型隐藏型特征。国内学者也致力于欺诈网页检测研究。李法良等[7]针对内容特征和链接特征,设计一种集成主成分分析(Principal Component Analysis, PCA)与支持向量机(Support Vector Machine, SVM)的检测方法;基于链接和内容的新特征被继续提出,并应用于欺诈网页的检测[8-9]。然而新特征的提取需要大量的链接和网页内容分析,研究成本昂贵,且网页基本特征是高维且冗余的,直接使用会增加计算代价,影响分类性能,因此,研究高效的特征选择算法遴选网页基本特征,在不降低欺诈网页检测率的基础上,有效减小分类计算代价,降低欺诈网页检测成本优势明显。
Goh等[10]对不同类型的基本特征子集进行组合挑选,并结合多种机器学习算法比较,得到表现最好的特征子集和分类器。验证实验在数据集WEBSPAM-UK2007[4-11]上进行,结果表明基于内容和转换链接的特征组合,在随机森林(Random Forest, RF)中取得最高的AUC为0.850。Karimpour等[11]同样关注特征选择,应用传统的遗传算法(Traditional Genetic Algorithm, TGA)和帝国主义竞争算法(Imperialist Competitive Algorithm, ICA)找到基于基本内容特征的optimal subset来减小分类器的计算代价。特征有效性同样在WEBSPAM-UK2007数据上得到验证。结果表明,optimal subset在贝叶斯网络(Bayes Net, BN)中的F1值从0.854增加为0.876。
本文与上述方法的不同之处在于:上述基于新特征提取和分类算法改进的方法直接使用高维的网页基本特征,增加了分类算法的计算代价,检测成本较高;而特征选择的方法没有对网页基本特征进行深入、全面的遴选,最终得到的特征集合维度仍然较高。本文方法除了考虑内容和链接两类特征外,对基于信息增益(Information Gain, IG)算法和遗传算法(Genetic Algorithm, GA)的特征选择算法作改进,寻找OMFS并在一个广泛使用的标准欺诈网页数据集,WEBSPAM-UK2007上进行分类结果的对比与验证。在保证检测准确率不下降的同时,最大限度地减小分类器的计算代价,提高检测效率。文献[12]中指出,在欺诈网页检测中,评价指标AUC比其他指标更稳定,本文主要的评价指标为AUC、F1值作为参考。
1 特征选择算法
1.1 信息增益

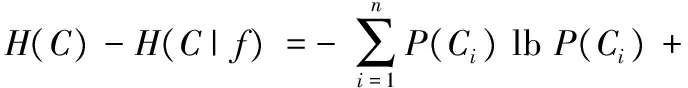
(1)
1.2 遗传算法
遗传算法(GA)[14]基于达尔文生物进化论中的自然选择和遗传过程,它是一种性能突出的特征选择算法。随机搜索的方式和根据适应值优胜劣汰保证了算法不会陷入局部最优。
参与遗传算法的初始种群由随机产生的一组染色体构成,在迭代中通过遗传算子生成更优的种群。其中,选择算子根据适应值挑选一定比例的染色体,而交叉算子和变异算子被用来生成新的种群。当适应值达到最大阈值或迭代次数达到最大时算法停止,具有最佳适应值的染色体就被解码为最优特征子集。通常,分类问题中的适应值可以设置为一般的分类评价指标。而如何将染色体解码为特征集合也是遗传算法在特征选择中至关重要的因素。
二进制编码是研究中最常使用的方法,其中染色体中的每个基因对应一个二进制位,“1”表示特征被选择,“0”表示未被选择。现在希望从含有nF个特征的集合中选出gn个有效特征形成一个特征子集(Selected Feature set by GA, GSF)。图1为遗传算法某一次迭代随机生成的染色体,省略位均为“0”。假设nF=200,gn=5,则此时GSF={f130,f45,f1,f11,f77},但是当nF足够大,gn又较小时,染色体会变得稀疏而冗长,这不利于算法的高效率。

图1 遗传算法某一次迭代随机生成的染色体
Fig. 1 Randomly generated chromosomes in one iteration of GA
遗传算法是自组织、自适应和自学习的算法。针对网页欺诈检测的高维特征作特征选择,遗传算法可以有效地收敛,有助于更快、更有效地得到OMFS。
2 改进的特征选择算法
为了减小网页欺诈检测中分类器的计算代价,提出了一个集成信息增益和改进的遗传算法的特征选择算法(Improved Feature Selection algorithm Based on Information Gain and Genetic Algorithm, IFS-BIGGA)。首先运用IG,通过动态阈值策略移除部分冗余特征,加速特征子集的收敛(参考算法1),输出的新特征集FS′成为改进遗传算法的输入。然后通过改进GA中的染色体的编码方式和选择算子,输出最小特征集(Minimum Feature Set, MFS),最后考虑到算法的稳定性,从多次实验的MFS中选择OMFS。
首先,动态阈值策略主要指对IG排序后的特征序列,通过实验动态选择合适的阈值T,删除IG值小于T的特征。为了找到一个优秀的特征集合FS′,不仅含有适量的特征,而且具有较高的AUC和TPR,T的设置极为重要,因此,式(2)定义了一个加权指标WS来权衡特征数量、AUC和TPR。其中:w1,w2和w3是按需可调节权重参数,card(FS′)表示FS′中的特征数量。auc和tpr表示针对不同的T生成的FS′,使用RF获取相应的AUC和TPR。WS越大,说明此时的T对应筛选的特征集合表现越好;然后,针对GA的改进,为方便后续说明,式(3)给出了2.2节中提到的常用二进制编码函数,其中:nF是FS′中的特征数量;G表示一条采用二进制编码的染色体;fn代表FS′中的特征。
WS=w1×auc+w2×tpr-w3×0.001×card(FS′)
(2)
(3)
G′(m)=Binary(GSF[m]);m=1,2,…,gn,
n=1,2,…,nF
(4)
算法1 特征选择——信息增益。
Input:原特征集合FS,阈值T。
Output:经过信息增益的特征子集FS′。
ForFS中的每个特征f
根据式(1)计算信息增益KLD(f)
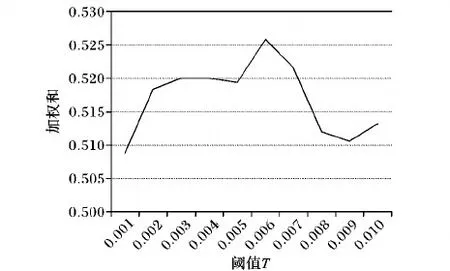
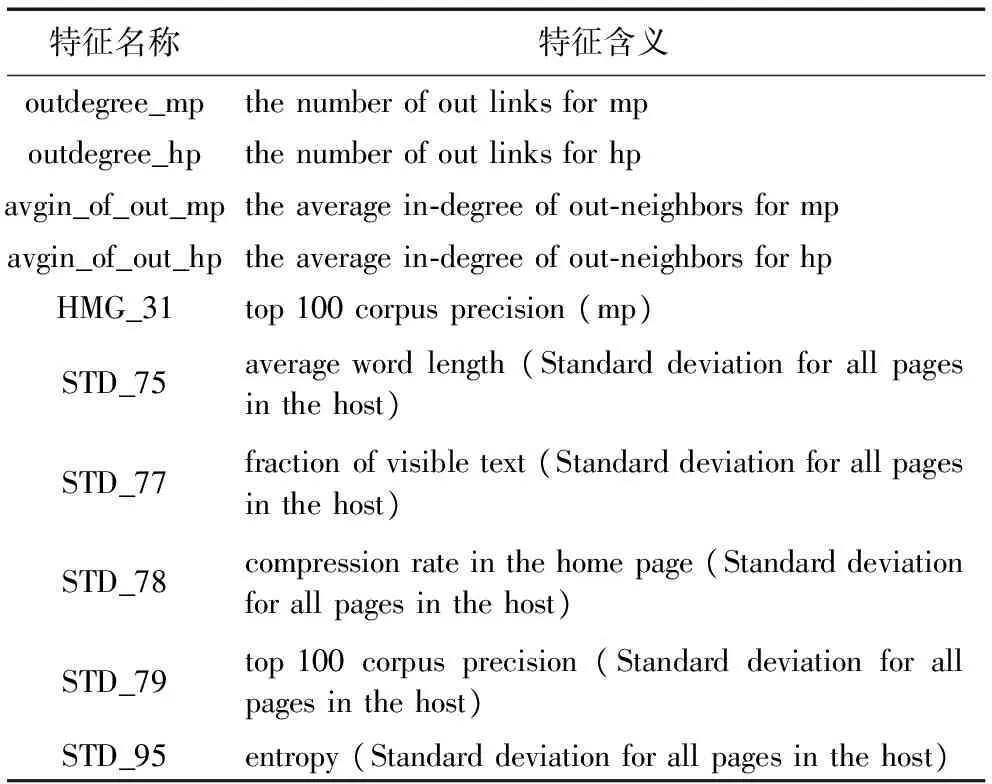
若KLD(f) 从FS中移除f end for 剩余特征组成FS′ ReturnFS′ 定义cl为染色体长度,式(3)的cl为nF。cl足够长时,遗传算法迭代耗时加长,考虑到算法的效率和染色体的稀疏表示改进编码函数,如式(4)所示。GSF[m]表示GSF中的第m个元素,同时也代表FS′中的特征f(GSF[m])。与式(3)中G不同的是,G′表示FS′中的特征编号的二进制编码。为了能取到FS′中的所有特征,(⎣lbnF」+1)比特被用来表示一个基因(特征),此时cl减小为(⎣lbnF」+1)×gn。染色体长度的减小显著降低了遗传算法的计算消耗,帮助更快收敛到最小特征集合。 图2给出了图1示例在式(4)下的编码,可以看到,cl已从200减小为40。算法2给出了改进后染色体编码的具体实现。由于遗传算法中的交叉和变异具有随机性,设定溢出重复查错机制,以避免式(4)产生的二进制组合超出特征集合的长度或互相重复。同时,所提方法中gn可变,增加了MFS的客观性。 图2 改进染色体编码示例 算法2 染色体的新编码方式。 Input:特征数量nF,挑选的特征子集大小gn。 Output:染色体c。 1) 定义gl=(⎣lbnF」+1) 2) 通过式(4)随机产生基因g的编码,转成十进制D(g) 3) 溢出重复查错: 若D(g)>nF 回到步骤2),重新生成g 4) 重复步骤2)~3)直到生成gn×gl个合法基因 5) 将基因组合成一条染色体c 6) Returnc IFS-BIGGA采用AUC作为适应度函数,Auc(c)表示一次进化过程中某条染色体c所获得的分类AUC。算法3给出了IFS-BIGGA的完整描述,其中:cp是一个记录进化代数的累加指针;mp表示最大迭代次数;ips是算法的初始种群大小。当cp累加达到mp时,算法终止,输出MFS。 算法3 IFS-BIGGA。 Input:迭代计数指针cp,最大迭代次数mp,初始种群大小ips,特征集合FS′。 Output:最佳特征集合MFS。 初始化指针cp=0 定义一代中的最大AUC为best-fitness 定义具有最大AUC的染色体为best-cho 重复算法2,直到生成ips条染色体,构成初始种群P(cp) 重复执行遗传算子 选择、交叉、变异 计数器加1:cp←cp+1 直到cp=mp 根据最终的best-cho解码出最佳特征集合MFS ReturnMFS 选择、交叉和变异是遗传算法的核心算子,考虑遗传算法的运行效率和收敛速度,本文对选择算子的改进主要结合了轮赌选择策略和最佳个体保存策略,算法4给出了具体实现。 算法4 选择操作。 Input:种群P;best-fitness;best-cho。 Output:选择后的种群PBS,更新后的best-fitness和best-cho。 对于一代中的每个个体,计算对应的AUC,若大于前一代保存的best-fitness,则更新best-fitness和best-cho 据AUC值计算选择概率和累积概率 对于每个非best-cho个体,生成随机数r,若累计概率大于r,保存该个体到PBS中 将best-cho保存到PBS中 ReturnPBS 轮赌选择时,选择算子根据AUC,计算每个个体的选择概率和累积概率。为了保证公平性,在选择良好个体时,产生符合0~1均匀分布的随机数r,当累积概率大于r时,该个体被保留;但是随着迭代次数增多,交叉和变异可能会破坏最佳个体,即适应度最好的染色体,导致进入下一代的个体平均AUC下降,因此结合最佳个体保存策略,在轮赌选择的第1)步,保存AUC最高的个体直接进入下一轮迭代,然后再进行后续的选择操作。另外,交叉算子是染色体随机交换基因的操作,选择与邻居染色体单点交叉;同时,根据经验设置交叉率控制交叉的比例,防止染色体信息过度丢失,最后得到选择操作的同代染色体种群。变异算子的作用对象为基因,由于参与变异的基因不宜过多,通过设置变异率控制基因变异的比例。 本文使用WEBSPAM-UK2007作为实验数据集,其中223个主机标注为欺诈主机(“1”),5 248个标注为正常主机(“0”)。欺诈检测算法和验证性实验基于Java平台和Weka软件构建。实验使用十倍交叉验证。 为了保证IFS-BIGGA的稳定性进行了30次重复实验,并选择贝叶斯网络和随机森林作为分类器。欺诈网页数据集是高度不平衡的,而TPR客观反映少数类的分类准确率,因此,当从MFS中选出OMFS时需要综合考虑AUC和TPR。在将OMFS与其他文献中的欺诈网页检测结果作比较时,使用AUC、TPR和F1值。 实验中,根据经验依次设置式(2)的三个权重参数为0.6,0.2,0.2,图3给出了不同T值下WS的分布。由图3可以看到,当T取0.006时,WS值最大,此时FS′含有64个特征,对应的AUC为0.820,TPR为0.233。最后,设置T为0.006,而根据经验设置算法3中的两个输入参数,最大迭代次数mp为100,初始种群大小ips为10。 图3 不同阈值T的WS值分布 实验主要以AUC、F1和TPR作为评价指标。为了方便说明,给出准确率(Precision, P)、召回率(Recall, R)的计算公式,如式(5)、(6)。式(7)、(8)中分别给出了TPR和F1值计算公式。AUC实际上为ROC(Receiver Operating Characteristic)曲线下的面积,计算公式较为复杂。通常,根据其物理意义:任取一对(正、负)样本,正样本的置信度大于负样本的置信度的概率,运用式(9)完成计算。其中:sp表示正类样本(欺诈网页)总数,sn表示负类样本(正常网页)总数,i表示每个正类样本,rank表示正类样本的置信度排序。 (5) (6) TPR=R (7) F1=(2×P×R)/(P+R) (8) (9) 为了从MFS中挑选OMFS,人为递增地给定gn多次构造IFS-BIGGA算法,同时对于每个gn,算法重复运行30次以排除随机干扰,实验结果用箱形图展示,如图4(a)和4(b)。每个数据箱分布着其对应gn重复30次实验得到的AUC和TPR。基本的统计量如最大值、均值、最小值等可以直观地从箱图中取得。箱子的形状和线段的长度反映数据的聚合程度,总的来说,箱子越扁,线段越短,数据分布越密集。 图4(a)中,gn取18时,数据分布不仅呈高聚合态,而且AUC总体偏高;若定义此时的箱子为优质箱(Box In Good Condition, BIGC),可以发现随着gn的增加,尤其在gn接近24后,对应的箱子稳定呈现BICG。由于MFS中的特征越少越好,gn只取到30。而在图4(b)中,只有gn取13,17,18,19时出现BIGC。综合两者,当gn为18时,30组数据中选择具有最大AUC的MFS作为最终的OMFS。表1列举了OMFS中部分典型特征含义[15],可以看到,特征分布包括了链接、内容和隐藏3种类型。 为了说明OMFS的有效性,进行两个实验。 实验1 从原始数据集Dinitial中抽取OMFS中的特征样本构成新数据集Dnew,结合当前热门的分类器,记录两个数据集下的检测耗时,如表2所示。由表2可以看到,与原始数据在各个分类器的平均检测耗时相比,新数据集耗时减小了83%,OMFS有效减少了分类器的计算代价。 图4 不同gn对应的AUC和TPR分布 Tab. 1 Specific meanings for part of representative features in OMFS 实验2 首先,结合RF分类器,将OMFS-RF的分类结果与文献[10]中结果最好的实验组,包括内容和转换链接共224个特征(Full Content-Based Features and Full Transformed Link-Based Features with Random Forest classifier, (FCBF+FTLBF)-RF)作比较,结果如表3所示;结果表明,尽管RF下的AUC减小了2%,但是真阳性率(TPR)提高了21%,并且特征维度减少了92%;其次,运用BN分类器,比较IFS-BIGGA和TGA[11]、ICA[11],结果如表3所示;结果表明,IFS-BIGGA的F1值分别提高了4.2%和3.5%。因此,本文提出的IFS-BIGGA算法有效,且得到的OMFS特征集合可以在不影响分类性能的情况下有效减小分类器的计算代价,提高欺诈网页检测的效率。 表2 不同分类器下Dinitial和Dnew检测耗时对比 ms 表3 不同方法的结果比较 本文针对网页欺诈检测遇到的网页基本特征高维、冗余的问题,提出一个基于信息增益和遗传算法的改进特征选择算法——IFS-BIGGA。本文方法的主要贡献在于运用信息增益对特征作排序,采用动态阈值策略高效删除冗余特征,并改进遗传算法,对网页基本特征进行有效的特征降维。实验结果证明,本文算法与其他特征选择算法相比,可以得到更少、更优的特征集合OMFS,其中仍覆盖了基于链接、内容和隐藏内容特征,而且基于OMFS的欺诈网页检测结果也可以近似达到甚至优于其他算法得到的结果,有效地减小网页欺诈检测时的计算代价,提高检测效率。另一方面,本文提出的算法不仅可以应用于欺诈网页检测,在其他具有高维、冗余特征的领域,也可以高效地进行特征选择。在接下来的工作中,研究在OMFS中加入从网页链接和内容中提取的新特征,更大程度地优化欺诈网页的检测性能。 References) [1] GOH L, SINGH A K, LIM K H. Multilayer perceptrons neural network based Web spam detection application [C]// Proceedings of the 1st IEEE China Summit and International Conference on Signal and Information Processing. Piscataway, NJ: IEEE, 2013: 636-640. [2] PAGE L. The PageRank citation ranking: bringing order to the Web [J]. Stanford Digital Libraries Working Paper, 1998, 9(1): 1-14. [3] 李智超,余慧佳,刘奕群,等.网页作弊与反作弊技术综述[J].山东大学学报(理学版),2011,46(5):1-8.(LI Z C, YU H J, LIU Y Q, et al. A survey of Web spam and anti-spam [J]. Journal of Shandong University (Natural Science), 2011, 46(5): 1-8.) [4] ARAUJO L, MARTINEZ-ROMO J. Web spam detection: new classification features based on qualified link analysis and language models [J]. IEEE Transactions on Information Forensics & Security, 2010, 5(3): 581-590. [5] NTOULAS A, NAJORK M, MANASSE M, et al. Detecting spam Web pages through content analysis [C]// Proceedings of the 15th International Conference on World Wide Web. New York: ACM, 2006: 83-92. [6] KUMAR S, GAO X, WELCH I, et al. A machine learning based Web spam filtering approach [C]// Proceedings of the 30th IEEE International Conference on Advanced Information Networking & Applications. Piscataway, NJ: IEEE, 2016: 973-980. [7] 李法良,朱焱,曾俊东.集成PCA降维与分类算法的垃圾网页检测[J].计算机应用与软件,2014,31(10):269-272.(LI F L, ZHU Y, ZENG J D. Spam Webpage detection combining PCA dimensionality reduction and classifier algorithm [J]. Journal of Computer Applications and Software, 2014, 31(10): 269-272) [8] 刘卫红,方卫东,董守斌,等.基于内容与链接特征的中文垃圾网页分类[J].微计算机信息,2010,26(9):6-8.(LIU W H, FANG W D, DONG S B, et al. Chinese Web spam identification through content and hyperlinks [J]. Journal of Microcomputer Information, 2010, 26(9): 6-8.) [9] 韦莎,朱焱.主题相似度与链接权重相结合的垃圾网页排序检测[J].计算机应用,2016,36(3):735-739.(WEI S, ZHU Y. Combining topic similarity with link weight for Web spam ranking detection [J]. Journal of Computer Applications, 2016, 36(3): 735-739.) [10] GOH K L, SINGH A K. Comprehensive literature review on machine learning structures for Web spam classification [J]. Procedia Computer Science, 2015, 70: 434-441. [11] KARIMPOUR J, NOROOZI A A, ABADI A. The impact of feature selection on Web spam detection [J]. International Journal of Intelligent Systems and Applications, 2012, 4(9): 59-64. [12] LUCKNER M, GAD M, SOBKOWIAK P. Stable Web spam detection using features based on lexical items [J]. Computers and Security, 2014, 46: 79-93. [13] KULLBACK, S, LEIBLER, R A. On information and sufficiency [J]. Annals of Mathematical Statistics, 1951, 22(1): 79-86. [14] GREFENSTETTE J J. Optimization of control parameters for genetic algorithms [J]. IEEE Transactions on Systems Man and Cybernetics, 1986, 16(1): 122-128. [15] CASTILLO C, DONATO D, GIONIS A, et al. Know your neighbors: Web spam detection using the Web topology [C]// Proceedings of the 2007 International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2007: 423-430. This work is partially supported by the Academic and Technological Leadership Training Foundation of Sichuan Province (WZ0100112371408, YH1500411031402), the Academic and Technological Leadership Research Foundation of Sichuan Province (WZ0100112371601/004), the Demonstration Project in Technology Service Industry of Sichuan Province (2016GFW0166). WANGJiaqing, born in 1993, M. S. candidate. Her research interests include Web data mining. ZHUYan, born in 1965, Ph. D., professor. Her research interests include data mining, Web anomaly detection, big data management and intelligent analysis. CHENTung-shou, born in 1964, Ph. D., professor. His research interests include image processing, data mining, information security. CHANGChin-chen, born in 1954, Ph. D., professor. His research interests include database design, e-business security, electronic multi-media imaging technique, cryptography.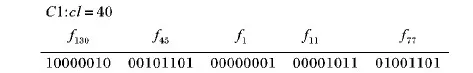
3 实验结果与分析
3.1 参数设置与评价指标

3.2 特征选择
3.3 结果与分析



4 结语
