基于牛顿梯度优化的弹性多核学习*
2018-01-27何佳佳陈秀宏
何佳佳,陈秀宏,田 进,万 月
(江南大学 数字媒体学院,江苏 无锡 214122)
0 引 言
多核学习(multiple kernel learning,MKL)[1]是机器学习领域的热门研究课题,已成功应用于生物信息学[2]、计算机视觉[3]、数据挖掘等方向。与利用单一核的核方法相比,MKL通过组合多个基本核函数代替单一核函数,使得核函数的应用更为灵活;由于其不依赖样本数据,故具有更强的可解释性和可扩展性。
本文提出了一种基于牛顿梯度优化方法的弹性MKL (Newton gradient optimization method for elastic MKL,NO-EMKL)算法,根据弹性理论,将混合范数作为正则化项加入目标函数,使得MKL在实现自适应目的的同时能平衡解的稀疏性,采用二阶牛顿梯度下降法提高MKL的效率。结果表明:以上方法能计算多核学习的黑塞(Hessian)矩阵,获得的下降方向比快速下降法更好,进一步减少了算法的迭代次数。
1 MKL框架
给定数据集{(xi,yi)}ni=1,xi∈χ,χ为输入空间;yi表示数据xi的标签,对二分类问题,yi∈{+1,-1}。核方法通过映射φ:χ→h将数据变换到Hilbert空间h中,核函数定义为h中的内积,表明可通过核函数k(x,z)隐式地计算映射函数φ在h中的内积k(x,z)=〈φ(x),φ(z)〉,避免了维数灾难。在MKL中,核函数通常表示为多个基本核函数的加权相加或相乘。
根据Bach分块理论[4],MKL即为寻找以下问题的最优解
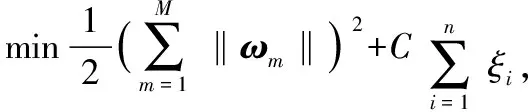
w.r.t.ω=(ω1,…,ωM)∈Rk1×…×RkM,
∀i∈{1,…,n}
(1)
MKL的决策函数为
f(z)=〈ω,z〉+b
(2)
式中μm为核函数的加权系数,可通过求解问题(1)的对偶形式获得。MKL分块阶段的l1范数将导致ω的稀疏性。
2 NO-EMKL
2.1 EMKL
多元线性回归的Lasso模型为
(3)
式中 ‖·‖为l2范数;‖·‖为l1范数。目标函数(3)第二项为正则化项,用来控制参数的稀疏性。Zou H等人[5]将式(3)中的正则项用混合范数代替以达到自适应调整稀疏性的目的,即考虑以下弹性优化模型
(4)
该模型通过正则化参数(λn,μn)调节l1范数项和l2范数项。
根据l1范数项的变分公式[6,7],并引入混合范数的正则项的弹性思想,得到以下EMKL模型


ω=(ω1,…,ωM)∈Rk1×…×RkM,
ξi∈Rn,b∈R
(5)
式中θ为变量,0<θ<1,用于平衡稀疏性。
2.2 EMKL的牛顿梯度法
本文EMKL框架考虑的合成核K(xi,xj)是一些基本核km(xi,xj)的线性组合
(6)

(7)

(8)

(9)
文献[6]指出,仅需用简单的梯度下降法即可解决该凸优化问题,且收敛较快。本文在快速梯度下降的基础上引入二阶牛顿优化来求解问题(9)以进一步提高收敛速度。
记问题(7)的目标函数为J(α,d),对d和α使用交替法求解。对于给定的d,式(7)即为标准SVM式(8),设其解为α*,相应的支持向量集为sv;求解式(9),计算J(α*,d)关于d的梯度
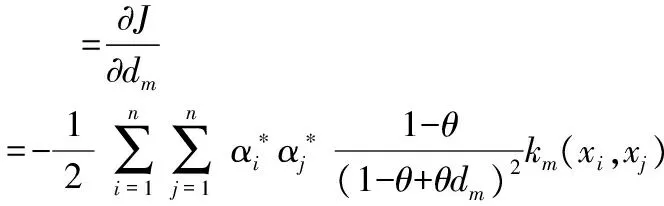
(10)
为了获得二阶信息,在对gm求导时需计算∂α*/∂dm。由于所有支持向量均处于最大间隔边界面上[9],故有
(11)
(12)
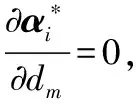
(13)
(14)

(15)
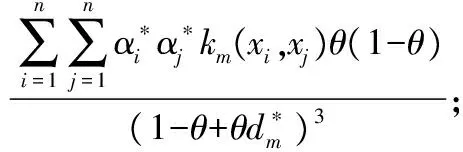
(16)
约束项保证了任何解都落在区间[d,d+s]中,从而满足原始约束式(9)。
3 实验与结果分析
为了验证本文NO-EMKL方法的有效性,与标准核SVM和基于快速梯度下降法的Simple MKL进行了实验比较。
3.1 参数设置和实验数据
Simple MKL和NO-EMKL实验中所使用的基本核函数包括:10个高斯核函数,其带宽σ,分别取0.5,1,2,5,7,10,12,15,17,20;3个多项式核函数,其中a=1,指数b的取值分别为1,2,3。对每个基本核函数分别计算核矩阵。通常核SVM中用到的单核为高斯核函数,其带宽σ取10;超参数C=100。本文讨论的是二分类问题,选取加州大学欧文分校提供的标准测试数据集(University of California,Irvine,UCI)中8种2类别数据集进行实验,这些数据集的构成如表1所示。
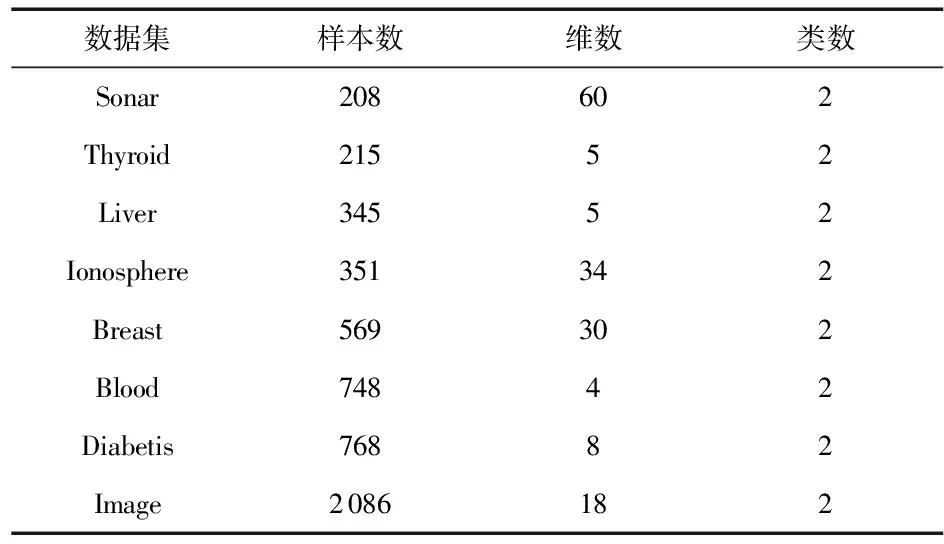
表1 UCI数据集
3.2 正则项参数θ选取
根据本文NO-EMKL算法,采用5折交叉验证的方法为表2中的8个UCI数据集分别选取合适的正则项参数θ。θ的取值分别为{0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9};将每个数据集中的样本数据分别分成5组,轮流将其中4组作为训练集而另外1组作为测试集,并分别计算分类精度,取5次实验结果的均值作为对应θ的分类结果,其对应关系如表2所示。对最高分类精确度进行标粗,如果不同的θ值对应着相同的最高分类精确度,选择其中一个标粗。

表2 数据分类精确度与θ关系 %
从表2可以看出,不同的θ值影响着NO-EMKL算法的分类精度,且不同数据集的最高分类精度对应的θ值一般也不相同,说明每个数据集均具有最合适的θ值。NO-EMKL算法可以根据数据集调节到最合适的θ值,使模型的分类效果达到最好。
3.3 分类精确度比较
根据表2,分别为8个UCI数据集选取最合适的θ值用于NO-EMKL算法,8个数据集Sonar,Thyroid,Liver,Ionosphere,Breast,Blood,Diabetis及Image对应的θ取值分别为0.3,0.6,0.8,0.6,0.5,0.2,0.7及0.3。随机选取8个UCI数据集中50 %的数据作为训练集,剩下的数据作为测试集;训练数据归一化为均值0及单位方差的数据,测试数据使用训练数据的均值和方差进行归一化。每种算法在每个数据集上运行10次求平均;对于Simple MKL和NO-EMKL,选择对偶间隙小于0.01或迭代次数大于500次作为终止条件;最后得到的3种算法对数据集的平均分类精度如表3所示,对分类精度最高的数据进行标粗。

表3 3种算法的分类精度比较 %
从表3中可以看出,单核的SVM分类结果较差,本文提出的NO-EMKL算法在大部分的数据集上(除了数据集Diabetis)相较其他两种算法有较好的分类精度,Simple MKL的分类结果处于两者之间。
3.4 迭代次数比较
Simple MKL和NO-EMKL在8个数据集上进行实验,并比较当达到停止迭代条件时迭代次数和对偶间隙的关系,如图1所示。可以看出:在开始阶段,Simple MKL的对偶间隙较NO-EMKL算法下降快,但是接近最优解时,收敛速度明显低于NO-EMKL,甚至出现了振荡,并导致迭代次数大幅度增加,从而增加了计算成本。由此可见,采用二阶牛顿梯度下降法的效果明显好于快速梯度下法。

图1 NO-EMKL和 Simple MKL收敛速度
3.5 训练时间比较
所考虑的训练时间不包含核矩阵的生成时间。由于标准SVM不需要对核系数进行学习,所以,NO-EMKL和Simple MKL 2种算法在8个数据集上的训练时间,在各数据集上运行10次后的平均训练时间如表4所示,正则项参数θ的选取根据表2确定。因此,Simple MKL算法相对于NO-EMKL长,尤其当数据集较大时,训练时间的差异更明显,这主要是因为在计算权系数时,两种方法所采用的梯度下降法不同,导致收敛速度不同,进一步说明了NO-EMKL算法的性能更优。

表4 训练时间 s
4 结束语
针对稀疏多核学习算法在产生权系数和收敛速度上的问题,提出了NO-EMKL算法。该算法根据弹性理论而在目标函数中引入弹性项,使得多个基本核函数能自适应地融合,从而能更好地保留有用信息;而在算法优化阶段,算法采用二阶牛顿梯度下降法,使算法在更少的迭代次数内即可达到收敛。实验结果表明:NO-EMKL算法相对于Simple MKL和SVM不仅具有更好的分类精度,还具有较快的收敛速度。
[1] Lanckriet G R G,Cristianini N,Bartlett P,et al.Learning the kernel matrix with semidefinite programming[J].The Journal of Machine Learning Research,2004,5:27-72.
[2] Damoulas T,Girolami M A.Probabilistic multi-class multi-kernel learning:On protein fold recognition and remote homology detection[J].Bioinformatics,2008,24(10):1264-1270.
[3] Duan L,Tsang I W,Xu D,et al.Domain transfer svm for video concept detection[C]∥IEEE Conference on Computer Vision and Pattern Recognition,2009:1375-1381.
[4] Bach F R,Lanckriet G R G,Jordan M I.Multiple kernel lear-ning,conic duality,and the SMO algorithm[C]∥Proceedings of the twenty-first International Conference on Machine Learning,ACM,2004:6.
[5] Zou H,Hastie T.Regularization and variable selection via the elastic net[J].Journal of the Royal Statistical Society:Series B(Sta-tistical Methodology),2005,67(2):301-320.
[6] Alain R,Francis R B,Phane C,et al.Simple MKL[J].Journal of Machine Learning Research,2008,9:2491-2521.
[7] Schölkopf B,Smola A J.Learning with kernels:Support vector machines,regularization, optimization,and beyond[M].Boston:MIT Press,2002.
[8] Bousquet O,Herrmann D J L.On the complexity of learning[C]∥Advances in Neural Information Processing Systems 15:Procee-dings of the 2002 Conference,MIT Press,2003:415.
[9] Chapelle O,Rakotomamonjy A.Second order optimization of kernel parameters[C]∥Proc of the NIPS Workshop on Kernel Learning:Automatic Selection of Optimal Kernels,2008:87.
