基于骨骼向量夹角的人体动作识别算法*
2018-01-26顾军华刘洪普马鹤芸
顾军华,李 硕,刘洪普,3,马鹤芸
(1.河北工业大学 计算机科学与软件学院,天津 300401;2.河北省大数据计算重点实验室,天津 300401;3.华北科技学院 河北省物联网数据采集与处理工程技术研究中心, 河北 廊坊 065201)
0 引 言
21世纪初,在人机交互、虚拟现实、视频智能监控、医疗诊断和监护以及运动分析等诸多应用背景下,动作分析已经成为图像分析、心理学、神经生理学等相关领域的研究热点[1]。因此,人体动作识别技术被很多国内外的大学和研究机构进行了深入的研究[2],并拥有十分广阔的应用前景[3]和非常可观的经济价值。传统的解决人体动作识别问题常用方法有两种:模板匹配法和状态空间法[4]。模板匹配法一般会将运动状态序列转化为一个或一组静态的模板,通过将待识别样本的模板与已知的模板进行匹配获得识别结果。模板匹配法可细分为两类:是帧对帧匹配方法,其最经典的算法就是动态时间规整(dynamic time warping,DTW)[5];融合匹配方法,例如Davis J W与Bobick A F[6]提出的识别方法。状态空间法就是将图像序列的每个静态姿势或运动状态作为一个状态节点,状态节点之间由给定的概率联系起来,任何的动作序列可以认为是这些静态动作在不同状态节点中的一次遍历过程,常见的状态空间法的算法有隐马尔科夫和动态贝叶斯等[7]。
由于状态空间法需要的样本空间过大,迭代次数过多,鉴于智能家居中对于识别简单动作的效率有很大的要求,在智能家居的人体动作中不易采用该方法;而模版匹配的帧对帧匹配也会涉及时间敏感对应匹配的问题且鲁棒性差等问题,为此,本文采用基于神经网络的分类方法。该方法属于融合匹配方法,其优点在于可以有效避免一般模板匹配法中的时间间隔敏感的问题,且迭代次数少,算法更加高效。
1 动作特征提取方法
1.1 姿态描述
研究表明,人体运动时相应的关节点角度、角速度及角加速度可以表征人体姿态。文献[8]也证明了人体骨骼角度在样本空间具有聚集性,并在规则化处理后满足平移和缩放不变性。因此,肢体关节角度可以作为人体运动特征的动态分量提取。
本文采用微软推出的KINECT[9,10]深度摄像头提取人体的20个骨骼关节点,并提供每个骨骼节点的三维坐标,识别的人体关节点图像如图1(a)所示。由骨骼点之间的坐标得到每段骨骼的向量,最终得到骨骼向量夹角[11],即关节角度,如图1(b)所示,模拟了某个状态下右肩—右肘—右手三个骨骼节点间的夹角,其命名方式为Rshoulder-Relbow-Rhand。以类似的命名方式取骨骼向量夹角,共20组。
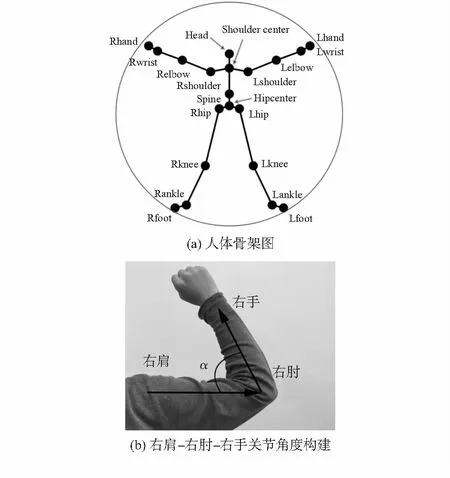
图1 骨骼向量夹角特征提取
1.2 神经网络训练样本优化
Partridge D[12]认为对于分类的神经网络,训练集对泛化能力的影响十分显著,甚至优于隐含层数和节点数对网络泛化能力的影响。因此,本文提出对训练数据进行优化,以此提高网络的泛化能力。
在基于骨骼向量夹角的人体动作识别中,由于KINECT传感器检测时经常会有关节点检测失效或者关节点偏移的情况发生,例如:图2(a)是正常情况下的人体站立姿势的骨架,图2(b)是关节点发生偏移后的骨架,可知采集到的训练数据有可能并不准确,导致训练后的网络有可能并不可靠,泛化能力较差,要解决此类问题:提高KINECT采集关节点的正确性,对关节点错误的数据进行剔除;通过数据间的相关性对样本进行优化,提高训练数据精度,加强网络的泛化能力。

图2 KINECT捕捉关节点骨架
1.2.1 剔除无效数据
在提高训练数据正确性方面,Li J F等人[13]根据文献[14]提供的数据指出,普通人自身的不同骨骼间的比例大致上是固定的,其统计得出的肢体数据如下
{Htorso≈4Hhead
Harm≈2.2Hhead
Hforearm≈1.9Hhead
(1)
式中Htorso,Harm,Hforearm,Hhead分别为脊柱、上臂、前臂和头的长度。
在构成人体动作描述特征向量之前要先判断该数据是否为无效数据,判断的依据为
(2)
式中L(shouldercenter,spine)为Shouldercenter到Spine的长度;a为允许误差范围,取0.1;后两式分别为左右两个上臂长度和左右两个前臂长度与头长度的比例。当条件均满足时,判断为有效数据,最终构建人体动作描述特征向量。
根据已知的身体各部分的比例系数,可以判定获得的训练数据是否为关节点失真后的错误数据,一旦出现了错误数据,则认为这组训练数据是无效数据,直接从训练数据中删除,在一定程度上保证了训练样本的准确性。
1.2.2 降低样本维度
在保证关节点基本不失真的情况下,由于训练样本维数较多,且精度不一,对样本进行二次优化。对样本进行因子分析[15,16],即在处理多指标样本数据时,将具有错综复杂关系的指标(或样品)综合为数量较少的几个因子,以再现原始变量之间的相互关系,通常被用来降低样本维度。
因子分析的数学表示为矩阵:X=AF+B,即
(3)
式中 向量X=(x1,x2,x3,…,xp)为原始观测变量;F=(f1,f2,f3,…,fp)为X的公共因子;A=(αij)为公因子F的系数,称为因子载荷矩阵;αij(i=1,2,…,p;j=1,2,…,k)为因子载荷,是第i个原有变量在第j个因子上的负荷,或可将αij看作第i个变量在j共因子上的权重。αij为xi与fi的协方差,亦即xi与fi的相关系数,表示xi对fi的相关程度。αij的绝对值越大,表明fi对xi的载荷量越大。
设神经网络的总体样本为X=(xij)n×p,其中,xij为xi的第j个指标,i=1,2,…,n;j=1,2,…,p。本文神经网络样本因子分析的主要步骤:
1)原始数据进行标准化,采用零均值标准差标准化方法,标准化后的样本为Xnp。但要注意,在神经网络训练输出时,需要对输出的结果进行还原量纲值。
2)计算总样本的相关系数矩阵R=(rij)p×p,并求解R的特征根及其相应的单位特征向量。其中
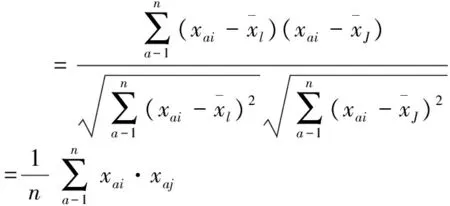
(4)
求解出R的p个特征根及其对应的特征向量,分别表示为λ1≥λ2≥…≥λp>0和μ1,μ2,…,μp。根据贡献率的要求,取前q个特征根及其相应的特征向量的构成因子载荷矩阵A
(5)
3)对求出的因子载荷矩阵进行因子旋转,并计算出因子得分。旋转后的因子载荷矩阵记为
(6)
因子得分的计算公式为
(7)
通过上述的因子分析操作可对样本进行降维处理,提高样本精度。
2 实验及结果分析
实验硬件采用KINECT传感器捕获人体动作特征向量,实验数据采集软件环境为Visual Studio 2010和KINECT SDK v1.8,开发语言为C#.net,神经网络仿真实验环境为MATLAB 2012b。
实验训练了5组动作,分别为坐下、站起、蹲下、喝水和坐在椅子上站起,共5×160=800组训练数据。测试数据使用相同的测试集,每个动作取60组数据,共有5×60=300组测试数据。实验中,设置网络的期望均方误差为0.01,最大迭代次数是1 000次。
为了验证本文方法的性能,设计了4组对比实验:1)采用不删除不降维的神经网络算法进行实验,原始数据即为训练集;2)采用仅剔除无效数据的识别方法,对原始数据进行无效数据剔除后的数据为训练集;3)采用不剔除无效数据仅进行因子分析的方法,对原始数据进行因子分析,得到训练集;4)采用既剔除无效数据又进行因子分析的方法,首先将训练样本中的无效数据排除,然后进行样本优化,对样本数据进行因子分析,组成新的训练集。表1给出了不同方法测试动作在测试集合上的正确识别率;表2给出了训练数据迭代次数及测试数据的总体识别率。

表1 测试中每个动作的正确识别率 %

表2 算法的迭代次数和总体识别率
由表1看出,采用样本优化后的方法,所有动作的识别准确率均有所提高,特别是在喝水动作的识别方面,优化后可以使得测试数据获得高达100%的准确率;而且在站起动作方面,识别准确率有了很大提高,由最初的85 %提升至95 %。造成这种现象的原因是,一方面了剔除无效数据,另一方面减少了数据的冗余,一些容易混淆的动作特征对比度更大,例如站起和坐在椅子上站起两个相似的动作区分更加明显,识别更加准确。通过表2看出:本文方法实验(4)在总体的识别率方面有了提升,由90.7 %增加到了95.7 %,而且在迭代次数方面也大幅缩减,由375降到了112,主要是因为数据维度减少,简化了网络结构,因此,加快了收敛速度,缩减了训练时间。
由表2可以看出,4次实验的迭代次数分别是375,372,123,112次,分别如图3所示,迭代次数由375次下降到了112次,而总体识别率由未优化的90.7 %提高到了优化后的95.7 %。

图3 训练神经网络的迭代次数
由实验结果可知,由于算法提高了训练样本的精度,使得训练出的网络更加稳定,泛化能力更好,因此,神经网络的迭代次数更少,准确率更高。
3 结束语
本文确定了动作描述方法,利用KINECT摄像头的骨骼关节点识别功能对人体进行建模,以骨骼的关节角度作为动作特征向量。在分析了几种传统的动作识别算法的基础上,利用神经网络实现动作识别的算法。为提高识别率和降低训练网络的迭代次数,根据实验本身的特性,对样本优化方面提出了改进,实验结果证明:算法取得了较好的性能。
[1] Yuan C,Li X, Hu W, et al. 3D R transform on spatio-temporal interest points for action recognition[C]∥Proc of the IEEE Conference on Computer Vision and Pattern Recognition,2013:724-730.
[2] 朱 煜,赵江坤,王逸宁,等.基于深度学习的人体行为识别算法综述[J].自动化学报,2016,42(6):848-857.
[3] 沈淑涛,高 飞,许 宁.基于Kinect的头部康复虚拟现实游戏[J].系统仿真学报,2016(8):1904-1908.
[4] 谷军霞,丁晓青,王生进.动作分析算法综述[J].中国图像图形学报,2009,14(3):377-387.
[5] Sakoe H,Chiba S.Dynamic programming algorithm optimization
for spoken word recognition[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1978,26(1):43-491.
[6] Davis J W,Bobick A F.The representation and recognition of human movement using temporal templates[C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,San Juan,Puerto Rico,1997:928-9341.
[7] 李瑞峰,王亮亮,王 珂.人体动作动作识别研究综述[J].模式识别与人工智能,2014,27(1):35-48.
[8] 韩 旭.应用Kinect的人体行为识别方法研究与系统设计[D].济南:山东大学,2013.
[9] 杨文璐,王 杰,夏 斌,等.基于Kinect的下肢体康复动作评估系统[J].传感器与微系统,2017,36(1):91-94.
[10] 李 彬,谢 翟,段渭军,等.基于Kinect的课堂教学状态检测系统[J].传感器与微系统,2017,36(1):67-70.
[11] 战荫伟,于芝枝,蔡 俊.基于Kinect的角度测量的姿势识别[J].传感器与微系统,2014,33(7):129-132.
[12] Partridge D.Network generalization differences quantified[J].Neural Networks,1996,9(2):263-271.
[13] Li J F,Xu Y H,Chen Y,et al.A real-time 3D human body tra-cking and modeling system[C]∥IEEE International Conference on Image Processing,2006:2809-2812.
[14] Bruderlin A,Calvert T W.Goal-directed,dynamic animation of human walking[J].Computer Graphics,1989,23(3):233-242.
[15] Irani R,Nasimi R.Evolving neural network using real coded genetic algorithm for permeability estimation of the reservoir[J].Expert Systems with Applications,2011,38 (8):9862-9866.
[16] Kim K,Ahn H.Simultaneous optimization of artificial neural networks for financial forecasting[J].Applied Intelligence,2012,36(4):887-898
