基于深度学习的二维人脸检测研究现状
2018-01-18郑成浩杨梦龙
郑成浩,杨梦龙
(1.四川大学计算机学院,成都 610065;2.四川大学空天科学与工程学院,成都 610065)
0 引言
人脸检测是自动人脸识别系统中的关键环节,它利用一定的策略对图片或者视频进行处理,判断图片或视频中是否存在人脸,如果存在则返回人脸框的位置、大小甚至姿态。早期的人脸检测研究只适用于严格的约束环境下应用[1-2]。自Paul Viola等人创造性地提出Viola-Jones检测器[3]后,人脸检测开始展现出商业化潜力。传统的人脸检测算法主要是提取Haar特征[4]或HOG[5]特征,并将这些特征输入到支持向量机(SVM)分类器中进行分类识别后实现人脸检测,特征的优劣决定人脸检测的准确性。Haar等特征本质上是手工设计的特征,研究人员设计一种好的特征提取方法耗时耗力,而且一种特征只能对有限场景下的人脸有较好的效果,因而传统的方法具有很大的局限性。
自Geoffery Hinton等人首次提出基于深度信念网络使用非监督的逐层贪心训练算法可训练深度神经网络[6]后,深度学习的应用逐渐发展起来。2012年,采用深度学习的AlexNet[7]赢得ImageNet目标检测比赛冠军,准确率比之前有了极大的提升。作为目标检测的一种,深度学习在人脸识别和人脸检测中也得到了普遍的应用。
采用深度学习的人脸检测算法,主要的结构或框架有以下四种,分别是卷积网络级联结构、多分类网络结构、人脸结构化网络结构和Faster R-CNN框架。下面将对这四种结构结构进行介绍。
1 卷积网络级联结构
级联结构可以看作是一个退化决策树。在检测过程中,候选窗口会通过一系列的弱分类器,每一个弱分类器都会判别候选窗口是否包含人脸,只有当所有弱分类器都判定是人脸时,整个检测器才会判定它是人脸。
自Viola-Jones检测器被提出以来,简单特征的级联结构成为人脸检测最有效和最流行的设计。简单特征能够快速评估和及早排除非人脸候选框,同时级联结构又能提高检测精度。Viola-Jones检测器使用Haar特征,速度快,对正面人脸有比较好的检测效果。过去的十多年,研究人员对Viola-Jones检测器进行了很多改进,他们大多采用更高级的特征,但仍然是级联结构。高级的特征能够构造一个更精确地二分类器,在达到相同精度的条件下,所需的级联结构更简单,整体计算代价保持不变甚至更少。
Cha Zhang和Zhengyou Zhang提出了一个采用级联结构的深度卷积网络[8]用于人脸检测,结构如图1[8]所示。此方法使用基于级联的多角度检测器排除掉大量的非人脸检测框,再经过预处理将图片调整到32×32像素,然后输入到一个更复杂的深度卷积网络中得到最后的结果。在预处理阶段需要进行三个步骤:直方图均衡化、线性变换和归一化处理。图像预处理的主要作用是增强对比度及移除阴影。此方法在FDDB库上测试的成绩优于VJGPR、XZJY和PEP-Adapt,在18个误检时检测率为77.32%。

图1 Cha Zhang等人提出的人脸检测框架结构图
李皓翔等人提出了一种卷积网络级联结构的人脸检测算法(CascadeCNN)[9]。卷积网络级联结构是指将多个卷积网络组合,构成一个完整的人脸检测器。每个级联的卷积网络的结构不同,具有不同的功能。人脸检测流程如图2[9]所示,整个算法有六个级联的卷积网络,包括3个用以判别人脸和非人脸的二分类分类器和3个用以调整人脸框边界的卷积网络(校准网络)。在训练数据有限的情况下,校准网络更容易训练。在FDDB库上,CascadeCNN的测试成绩超过ACF、PEP-Adapt、Boosted Exemplar、HeadHunted 等方法,最大检测率为85.6%。CascadeCNN不仅正检很高,而且速度很快。在CPU上可以以14fps的速度处理VGA画质的图片,在GPU上,相同条件下可以达到100fps。这种方法有两个特点,一是多分辨率的网络级联,加强了时间效率;二是边界校准网络,降低了对大量训练数据的依赖而且增加了召回率。此方法的缺点是,虽然在一定程度上比传统的方法有所提高,但是性能仍然不是非常突出。85.6%的检测率在今天看来成绩并不突出。
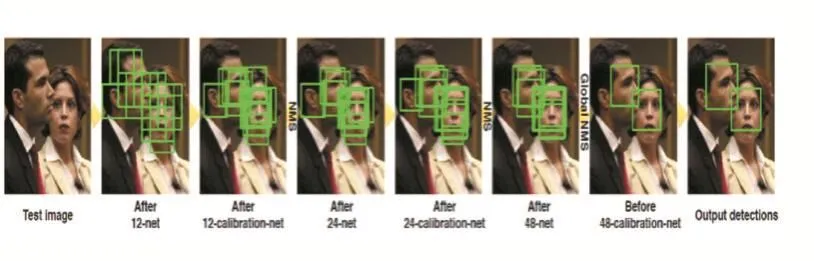
图2 检测器测试过程
很多级联结构的人脸检测器对正面人脸有较好的检测效果,但对不同角度的人脸比如侧脸或者部分遮挡的人脸,检测率较低。这源于级联检测器的一个固有劣势,组成强分类器的每个弱分类器都是一个二分类器。二分类器只能区分人脸和非人脸,在实际使用中,每个角度的人脸不尽相同。为了解决这个问题,有些学者采用多通道的级联结构。然而,这种方法需要面向对象的标记,而且,训练和测试的复杂性随模型数量呈线性增长。时至今日,卷积网络级联结构的人脸检测器仍然在不断发展,速度快和检测率也在逐渐提升,但是在FDDB库测试的成绩排在前10名之后。
2 多分类网络结构
为了解决计算复杂的问题,Viola和Jones提出首先使用树分类器估算脸部姿态,然后使用相应角度的级联检测器[10]。虽然提高了检测速度,但初始树分类器的错误是不可逆的,综合的准确性有所降低。
如把人脸检测看作一个二分类问题,采用深度学习的人脸检测算法的网络结构,最后一层通常是Sig⁃moid层。目前,大多数研究者为了克服多角度人脸问题,通常将人脸检测看作一个多分类问题,把Softmax层作为最后一层。S.S.Farfade等人放弃了使用二分类器,提出了基于多分类网络的DDFD(Deep Dense Face Detector)[11]算法用以解决多角度人脸检测问题。DDFD的网络结构类似AlexNet,前五层依然是卷积层;不同的是,DDFD算法中,将最后三个全连接层改变为卷积层,然后接一个Softmax层得到分数。DDFD的另一个特点是非极大值抑制过程,S.S.Farfade等人提出了两种方法,NMS-max和NMS-avg。NMS-max的流程是首先找到分数最高的框,然后移除所有与这个框的交并比(IoU)大于某个阈值的框。重复这个过程,直到处理完所有的框。NMS-avg的流程是先去除得分小于0.2的框,对剩下的框根据某一个阈值使用OpenCV中的聚类方法得到最后结果。对每一个聚簇,去除得分小于分数最高的框90%的所有的框,然后对余下的框做位置平均得到最后的人脸检测框,分数取聚簇中的最高分。图3[11]是不同非极大值抑制策略和阈值对结果的影响,可以看出,非极大值抑制的策略对结果有较大的影响。此算法在FDDB库上的测试结果是:2000个误检时检测率为84.8%,低于CascadeCNN。
DDFD算法的优点是:(1)使用SoftMax层对人脸进行多角度的划分以提高精度。(2)对非极大值抑制策略进行首次探究。缺点是:(1)网络结构类似AlexNet,较简单。(2)人脸模板大。文章中能检到的最小人脸是45x45,对于更小的人脸,图片需要调整到很大的尺寸,增加了计算代价。
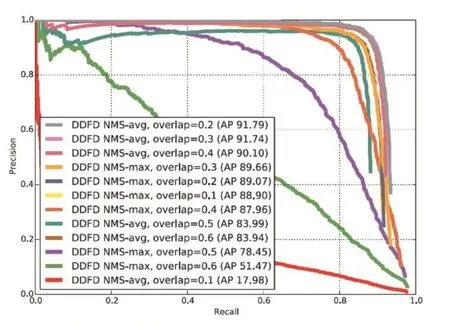
图3 不同NMS策略和阈值的影响
3 人脸结构化网络结构
Felzenszwalb提出的可变形部件模型(DPM,De⁃formable Parts Model)[12]使用了人脸结构化的思想。部件模型假设每一个物体都是由几个组件和它们之间的空间位置关系组成的,检测大物体就可以转换成检测每一个小组件及其空间位置问题。可变形部件模型是一种基于组件的检测算法,包括一个粗糙的包含整个目标的全局模板,以及若干个高分辨率的部件模板。模板就是梯度方向直方图HOG特征向量,每个部件模型包括一个空间模型和一个部件滤波器,空间模型定义了一系列此部件相对于检测窗口的空间位置,以及每个相对位置的变形花费。
人脸同样也可以认为由几个部件组成,例如鼻子、眼睛、嘴巴等。在局部环境中,人脸局部结构的检测是解决人脸检测的关键。只要在一个检测框准确地检测到人脸的几个组件并且各个组件之间的空间关系是正常的,那么就可以认为这个检测框里存在人脸。正如上文提到的,手工设计的Haar或HOG等特征不能在无约束的环境中精确地捕捉不同姿态和照明条件下的面部信息。随着深度学习技术和GPU并行计算加速的进步,使用深层卷积神经网络进行特征提取成为可能。Krizhevsky等人提出使用在大型通用数据集预训练的深度卷积网络可以作为有使用价值的特征提取器[7]。
在可变形部件模型的基础上,利用深层卷积网络的表征学习能力,Shuo Yang等人首次提出用以解决严重遮挡和大姿态下难以检测问题的Faceness-Net算法[13]。Faceness-Net的检测过程包含三个阶段:生成局部信息图、根据得分对候选窗口排序、矫正检测结果。第一个阶段,生成局部信息图,如图4[13]所示。图片X作为5个卷积网络的输入,每个网络检测人脸一个特定部分在图中的位置。通过人脸标签特征图,能够清楚地指定人脸位置。为了节省计算代价,五个卷积网络会共享卷积层。在第二阶段,根据现有的方法比如选择性搜索(selective search),在局部特征图上生成候选框。通过平均一个人脸所有部分的得分获得这个人脸的分数。最后,所有的窗口通过一个多任务卷积网络进行完善。
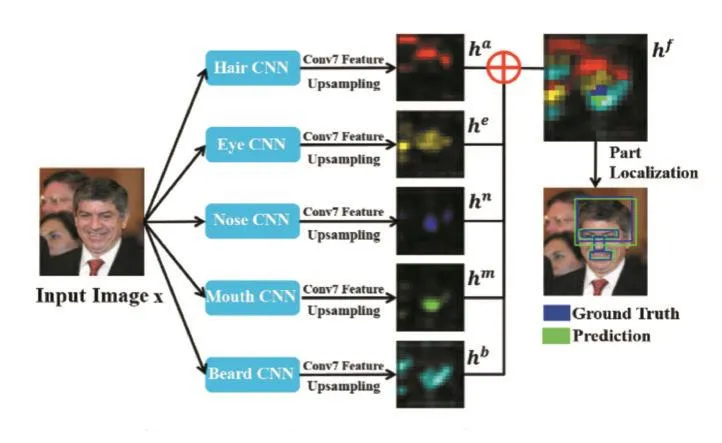
图4 Faceness-Net生成特征信息图
Faceness-Net中的5个属性感知的卷积网络结构相似,受到了AlexNet的启发。卷积网络结构包括7个卷积层和2个池化层。很多研究表明,增加卷积层数比如AlexNet可以粗略捕获目标位置。在第二个阶段中,算法用先验知识对候选框打分,比如头发在脸的上方,眼睛在脸的中央等。以头发为例,它贡献的得分的计算方法如下:
图5是在局部特征图上得到的一个候选框ABCD。考虑头发的空间位置,在人脸的上方,头发在候选窗口的位置是ABEF。头发提供的得分是ABEF/EFCD,如下式(1)所示。
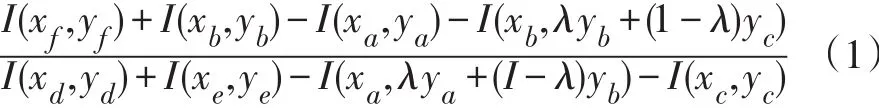
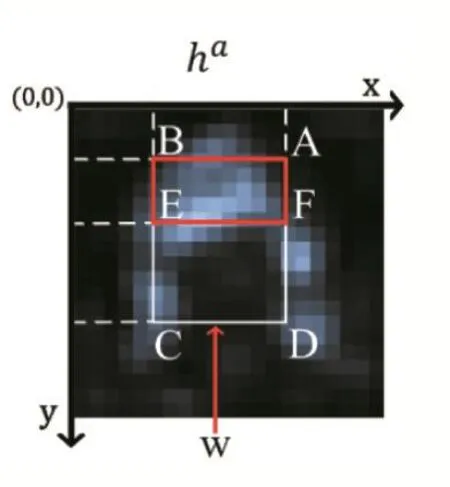
图5 特征图
部件的得分越高说明与人脸相交的比例越大。通过不同的λ,使得各个部件的空间分配更加合理。模型中的λ可以通过学习的方法得到。给定一个训练集,是指第i个人脸和标签,是第i个候选框比如图5中ABCD。通过最大后验来获得λ。Shuo Yang等人通过使用AFLW和PASCAL VOC2007的数据来微调这个网络。
Facsness-Net的优势在于人脸进行结构化的分割,增加了对遮挡的鲁棒性和对多角度人脸的检测能力。在FDDB库上测试,在2000个误检时达到了90.9882%的检测率,优于卷积网络级联结构和多分类网络结构的某些算法,比如Cascade CNN和DDFD。
4 Faster R-CNN框架
Faster R-CNN的前身可追溯到R.Girshick等人提出了R-CNN框架[14]。该方法由提取候选框、特征提取和分类器(SVM)三部分构成。R-CNN有两个缺点:(1)在特征提取阶段,输入图片尺寸必须是固定的;(2)对每一个候选框都要进行卷积网络的前向传播,耗时多。为了解决这两个问题,何恺明等人提出了SPPNet框架[15],通过添加空间金字塔池化(Spatial Pyramid Pooling)层速度提高了24-102倍,准确率也有所提高。为了进一步减少时间与空间代价,在SPP-Net基础上,R.Girshick等人提出了 Fast R-CNN框架[16]。Fast R-CNN框架过程是利用selective search产生候选框,缩放图片得到金字塔,将图片输入到卷积网络,用Softmax和回归得到得分和检测框。Fast R-CNN的缺点是候选框提取方法不能与卷积网络一起进行端到端的训练,消耗时间仍然较多。端到端是指输入原始数据,输出最后的结果。在人脸检测领域,非端到端的方法的主要不同是输入端不是原始数据,而是在原始数据中提取的特征。端到端的方法的优势是,研究者只需要关心输入端与输出端,中间过程不需要人工干预。R.Girshick等人通过改进Fast R-CNN提出了Faster R-CNN框架[17]。
Huaizu Jiang和Erik Learned-Miller将Faster RCNN应用于人脸检测问题[18],处理过程如图6[18]所示。Faster-RCNN包括两个模块,第一部分是RPN(Region Proposal Networks),一个产生候选区域的深度卷积网络,第二部分是Fast-RCNN检测器。RPN的核心思想是通过卷积网络直接产生候选区域。RPN网络可以接收任意尺寸的照片,对最后一层卷积层产生的特征图使用3×3的滑动窗口,每个中心点生成9个候选区域,最后输出一系列的建议区域和分数。在第二个模块中,候选框被输入到Fast RCNN网络获得最后的得分与人脸框。在FDDB库上测试,在747个误检时达到了96.1129%的检测率。Faster R-CNN创造性地采用卷积网络自行产生建议框,并且两个模块共享卷积网络。

图6 Faster R-CNN网络结构
Shaohua Wan和Zhijun Chen等人在Faster R-CNN基础上使用负样本挖掘技术进行训练[19],解决正负样本的分布不均衡的问题。孙旭东等人在Faster R-CNN框架基础上提出了DeepIR方法[20],常见的Faster RCNN只在最后一层特征层进行感兴趣区域(Region of Interest,RoI)池化产生区域特征,孙旭东等人认为,这种方式会漏掉一些重要信息。为了捕获更细粒度的RoI细节,Deep IR通过混合不同特征层进行特征池化。在FDDB上测试,DeepIR在956个误检时达到了97.0605%的检测率,远超 CascadeCNN、DDFD、Face⁃ness-Net等方法。
5 结语
我们对四种典型的深度学习人脸检测算法框架进行了研究。以Faster R-CNN为代表的端到端网络在检测率方面显示出了极大的竞争力,而且检测速度也在不断提升,具有较好的应用前景。在完全无约束的环境,特别是姿态和光照变化极大时的面部检测仍然是极具挑战性的问题。对于有监督的深度学习来说,收集大量的真实数据仍然是一项困难的工作。在改进训练数据方面,也需要更多的研究,无监督或半监督的学习方法将非常有利于减少数据收集所需要的工作量。改善人脸检测性能的另一个可能的办法是考虑上下文信息,如身体其他部位可以提供人脸所在部位的提示。
[1]FISCHLER M A,ELSCHLAGER R A.The Representation and Matching of Pictorial Structures[J].IEEE Transactions on Computers,1973,100(1):67-92.
[2]BLEDSOE W W,CHAN H.A Man-Machine Facial Recognition System—Some Preliminary Results[J].Panoramic Research,Inc,Palo Alto,California,Technical Report PRI A,1965,19(1):1965.
[3]VIOLA P,JONES M.Rapid Object Detection Using a Boosted Cascade of Simple Features;Proceedings of the Computer Vision and Pattern Recognition,2001 CVPR 2001 Proceedings of the 2001 IEEE Computer Society Conference on,F,2001[C].IEEE.
[4]PAPAGEORGIOU C P,OREN M,POGGIO T.A General Framework for Object Detection;Proceedings of the Computer Vision,1998 Sixth International Conference on,F,1998[C].IEEE.
[5]DALAL N,TRIGGS B.Histograms of Oriented Gradients for Human Detection;Proceedings of the Computer Vision and Pattern Recognition,2005 CVPR 2005 IEEE Computer Society Conference on,F,2005[C].IEEE.
[6]HINTON G E,SALAKHUTDINOV R R.Reducing the Dimensionality of Data with Neural Networks[J].Science,2006,313(5786):504-507.
[7]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Imagenet Classification with Deep Convolutional Neural Networks;Proceedings of the Advances in Neural Information Processing Systems,F,2012[C].
[8]ZHANG C,ZHANG Z.Improving Multiview Face Detection with Multi-Task Deep Convolutional Neural Networks;Proceedings of the Applications of Computer Vision(WACV),2014 IEEE Winter Conference on,F,2014[C].IEEE.
[9]LI H,LIN Z,SHEN X,et al.A Convolutional Neural Network Cascade for Face Detection;Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,F,2015[C].
[10]JONES M,VIOLA P.Fast multi-View Face Detection[J].Mitsubishi Electric Research Lab TR-20003-96,2003,3(14).
[11]FARFADE S S,SABERIAN M J,LI L-J.Multi-View Face Detection Using Deep Convolutional Neural Networks.Proceedings of the Proceedings of the 5th ACM on International Conference on Multimedia Retrieval,F,2015[C].ACM.
[12]FELZENSZWALB P,MCALLESTER D,RAMANAN D.A Discriminatively Trained,Multiscale,Deformable Part Model.Proceedings of the Computer Vision and Pattern Recognition,2008 CVPR 2008 IEEE Conference on,F,2008[C].IEEE.
[13]YANG S,LUO P,LOY C-C,et al.From Facial Parts Responses to Face Detection:A Deep Learning Approach.Proceedings of the Proceedings of the IEEE International Conference on Computer Vision,F,2015[C].
[14]GIRSHICK R,DONAHUE J,DARRELL T,et al.Region-Based Convolutional Networks for Accurate Object Detection and Segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(1):142-158.
[15]HE K,ZHANG X,REN S,et al.Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.Proceedings of the European Conference on Computer Vision,F,2014[C].Springer.
[16]GIRSHICK R.Fast r-cnn;proceedings of the Proceedings of the IEEE International Conference on Computer Vision,F,2015[C].
[17]REN S,HE K,GIRSHICK R,et al.Faster r-cnn:Towards Real-Time Object Detection with Region Proposal Networks.Proceedings of the Advances in neural information processing systems,F,2015[C].
[18]JIANG H,LEARNED-MILLER E.Face Detection with the Faster R-CNN[J].arXiv Preprint arXiv:160603473,2016.
[19]WAN S,CHEN Z,ZHANG T,et al.Bootstrapping Face Detection with Hard Negative Examples[J].arXiv preprint arXiv:160802236,2016.
[20]SUN X,WU P,HOI S C.Face Detection Using Deep Learning:An Improved Faster Rcnn Approach[J].arXiv Preprint arXiv:170108289,2017.
