Slope One推荐算法改进
2018-01-18黄义纯
黄义纯
(四川大学计算机学院,成都 610065)
0 引言
随着信息技术和互联网技术的飞速发展,人们逐步从信息匮乏的年代迈入了信息过载的时代。为了解决人们信息过载的问题,推荐系统受到了广泛的使用。近年来,推荐算法的研究主要分为以下三个方向:协同过滤、项目内容和用户知识[1]。Slope one是一种协同过滤的推荐算法,首先由Lemire等人提出。它是基于物品之间的平均评分偏差来预测评分,只依照项目评分计算,而不考虑项目之间的相似度。该算法思想虽然简单却极为高效,同时它的推荐精度也令人满意。相比其他基于邻域的协同过滤算法[2],Slope one算法一个很重要的特点就是基本不存在“冷启动”问题,即推荐精度不受系统评分数据的数量的影响。因此,该算法被广泛应用于工业界。
1 Slope One推荐算法
对于Slope One算法,其推荐流程为1)计算物品之间的平均评分偏差矩阵;2)计算用户对未评分项目的预测评分值;3)最后,对该用户所有未评分项目按评分预测值倒序排序,取得前N个物品推荐给用户[3]。
下面,通过一个例子来对Slope One算法的工作过程进行说明。如表1所示,user1、user2同时对item1和item2进行评分,现在要预测user3对item2的评分。Slope One算法首先计算item1对item2的平均评分偏差:(( 5 -3)+(4 -3))/2=1.5,这意味着用户对item1的平均评分比item2多1.5,因此user3对item2的评分则可以认为是:4-1.5=2.5。再假设表1中还有一列物品 item3,user1对 item3评分为 2,user2对item3的评分为3,user3对item3的评分为4,继续预测user3对item2的评分值。

表1 用户-物品评分矩阵
此时,使用item1对item2的平均偏差来预测得到的是2.5,使用item3对item2的平均偏差来预测得到的是4-((2-3)+(3-3))/2=4.5,原生的Slope One算法通过求平均值的方式获得最终的预测值(2.5+4.5)/2=3.5。
假如有100个用户同时对item1和item2进行了评分,5个用户对item3和item2进行了评分,上述单纯求平均值的方式在各个用户共同评分数差异过大的,对结果的预测不是很准确,这时可以通过使用带权重的 Slope One求预测值(100×4.5+5×3.5)/(100+5)=4.45更加合理。
综上所述,Slope One算法的重点在于求物品间的平均偏差以及使用的预测评分计算上[4]。设评分矩阵为R,若devj,i表示项目i,j之间的平均偏差,则:
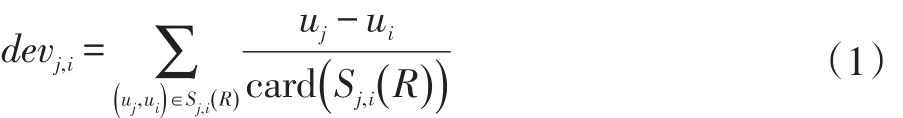
其中,ui、uj表示用户u的评分向量中对物品i,j的评分值,Sj,i(R)表示评分矩阵R中对物品i,j都有评分的用户集,card()用于求集合中的元素个数。
用户u对物品j的预测值可以表示为devj,i+ui,对于整个评分矩阵R来说,要预测用户u对物品j的评分则需要依赖所有其它物品与物品j的平均偏差[5],同时考虑到计算不同项目间的平均偏差值时,使用的项目评分对的数量不一致,导致每个平均偏差值在R中的权重是不一样的。因此,文献[6]将用户共同评分数作为Slope one的权重,其预测评分公式可表示为:
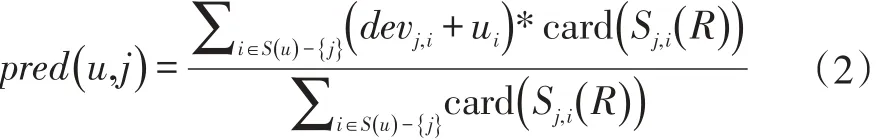
上式用来预测用户u对物品 j的评分值,S(u)表示用户u评过分的物品集。
2 项目相似度
在基于用户的协同过滤或者基于物品的协同过滤算法中,相似度的计算是推荐系统实现的关键步骤[7]。常用的相似度计算有三种,下面以基于项目的协同过滤为例,分别进行介绍。项目相似度的计算要基于用户-物品评分矩阵[8],如表2。
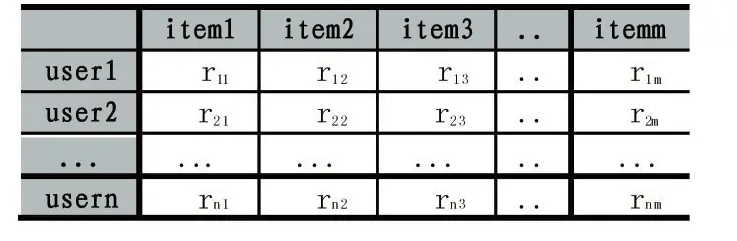
表2 用户-物品评分矩阵
余弦相似度(Cosine):余弦相似度是通过计算向量之间的余弦夹角来计算两个向量的相似度[9],取值范围是(-1,1)。若r→i和r→j分别表示物品i和物品j物品的评分向量,则余弦相似度可以用如下公式表示:
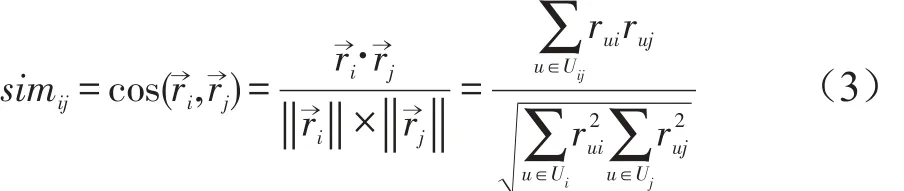
其中,Uij表示同时对物品i、j评分的用户集合,Ui和Uj分别表示对物品i和物品 j评分的用户集合,rui和ruj分别表示用户u对物品i和物品 j的具体评分值。
修正的余弦相似度(Adjusted Cosine,AC):修正的余弦相似度是在余弦相似度基础上,修正了不同用户评分尺度的问题[10]。以星级评分1-5分制为例,用户A认为评分在4分及以上才是自己喜欢的物品,而对于用户B来说可能评分在3分及以上就属于自己喜欢的了。为此,AC算法在计算相似度时先计算每个用户的平均评分,然后将每个具体评分减去该用户的评分均值。具体公式如下:
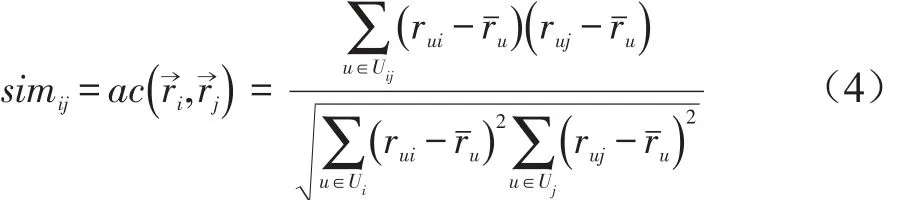
其中,rˉu表示用户u对物品评分的均值。
皮尔逊相似度(Pearson Correlation,PC):皮尔逊相似度是从Pearson相关系数发展而来,其计算是在物品i和物品 j具有共同评分的基础上,同时考虑了用户评分尺度和物品评分尺度的问题[11]。在不同的算法中需要使用不同的评分尺度,比如,在User-based CF中考虑的是用户评分尺度,而在Item-based CF中考虑的是物品评分尺度。其计算方式如下:
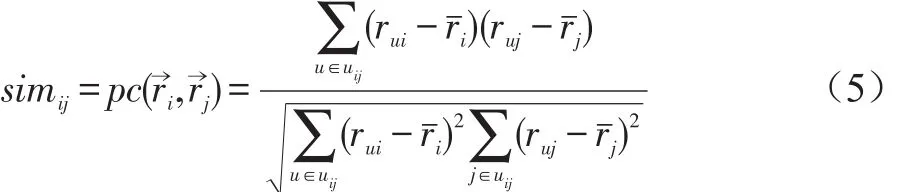
其中 rˉi代表物品 i的平均评分,rˉj代表物品 j的评分均值,其他符号含义同公式(3)。
3 改进的Slope One算法
3.1 使用项目相似度作为权值
评分预测公式(2)中通过使用card(Sj,i(R))加权的方式,即考虑到了不同项目之间用户评分数量的差异,在一定程度上提高了可信度和推荐精度。但是这种加权方式并没有考虑到项目之间的内在相关性,即所有用户对两个项目的评分会反映出这两个项目之间的内在关系。因此文献[12]中采用了项目相似度作为权值的Slope One算法,算法的评分预测公式如下:
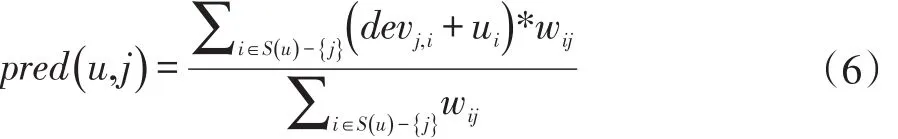
其中wij表示项目之间的皮尔逊相似度[12],但本文将分别使用余弦相似度、修正余弦相似度、皮尔逊相似度对wij进行求解,进行对比试验。
3.2 使用项目相似度与用户共同评分数乘积为权值
使用项目相似度为权值的Slope One算法,只考虑了项目相似度而未考虑用户共同评分个数[13]。因此本文在此的基础上,采用项目相似度与用户共同评分数乘积为权值进行算法的改进。改进后的算法不仅考虑项目间的相似度,同时也考虑到当用户对物品的共同评分个数,两者的结合不仅解决了原生Slope One算法因用户共同评分数差异过大导致推荐精度下降问题,同时也考虑了项目之间的内在相关性。改进后的Slope One算法的评分预测公司如下:
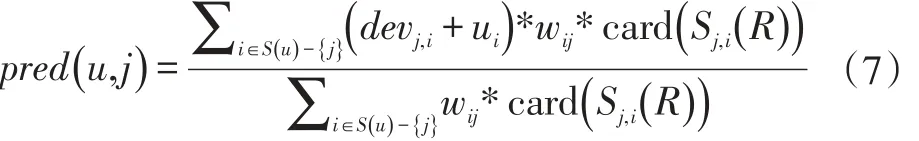
本文将使用余弦相似度与用户共同评分数乘积为权值的算法称为CCW Slope One,使用修正余弦相似度优化与用户共同评分数乘积为权值的算法称为ACCW SlopeOne,使用皮尔逊相似度与用户共同评分数乘积为权值的算法称为PCCW Slope One。
4 实验
4.1 实验数据集及检验标准
本文使用数据集来源于MovieLens,该数据集包含100万条真实电影评分记录(6040个用户对3952部电影的评分)。使用RMSE(均方根误差)对预测结果精度进行评价,RMSE越小表示预测准确度越高[14]。
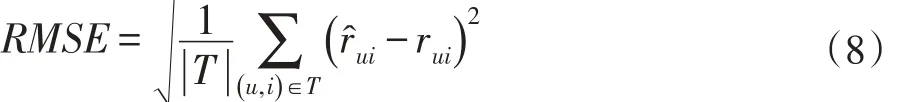
其中ui表示在训练集上产生的对物品i的预测评分,rui表示测试集上用户u对物品i的正式评分, ||T表示测试集的大小。
实验按以下步骤进行:
处理下载的数据集,即将本地数据集读入到内存,并用合适数据结构存储。
划分数据集,每轮实验将数据集随机分成10份,每次选择其中的9份作为训练集训练出推荐模型,剩余的一份作为测试集计算RMSE评价指标,每轮实验进行10次,分别选取不同的测试集,最后得到的10次实验的平均RMSE值作为本轮实验的RMSE值输出。
4.2 实验结果
(1)余弦相似度改进的算法
比较原生的Slope One算法和使用余弦相似度改进的后的算法Slope One、CCW Slope One算法在推荐精度RMSE上的差异。如图1。
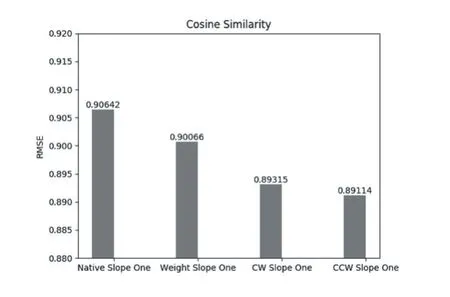
图1 余弦相似度改进算法精度对比
上图中Native Slope One代表原生Slope One算法,Weight Slope One代表使用用户共同评分数为权值的Slope One算法。CW Slope One算法代表使用余弦相似度为权值的Slope One算法。从上图可以看出使用余弦相似度为权值对于推荐精度有较大的提升,而同时考虑余弦相似度和用户共同评分数的CCW Slope One算法比仅使用余弦相似度的Slope One算法的推荐精度又有所提升。
(2)修正余弦相似度改进的算法
比较原生的Slope One算法和使用相似余弦相似度改进的后的Slope One算法、ACCW Slope One算法在推荐精度RMSE上的差异。如图2。
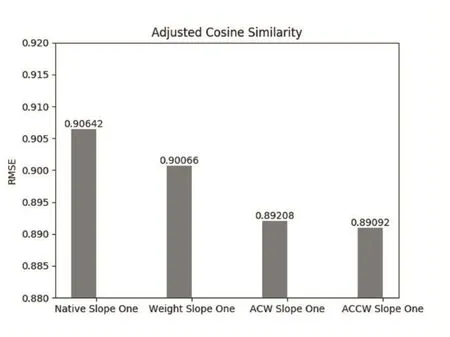
图2 修正余弦相似度改进算法精度对比
上图ACW Slope One代表使用修正余弦值为权值的Slope One。可以看出使用修正余弦相似度为权值改进的Slope One算法与原生算法相比推荐精度有了明显的提高,而采用修正余弦相似度和用户共同评分数乘积为权值的ACCW Slope One算法比仅使用修正余弦相似度为权值的Slope One算法的推荐精度又有所提升。
(3)皮尔逊相似度改进的算法
比较原生的Slope One算法和使用皮尔逊相似度改进的后的算法Slope One、PCCW Slope One算法在推荐精度RMSE上的差异。如图3。
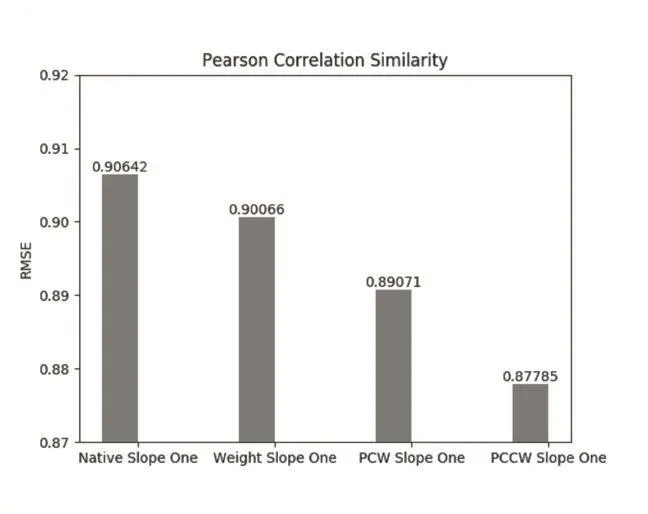
图3 皮尔逊相似度改进算法精度对比
上图可以看出使用皮尔逊相似度改进的Slope One算法和PCCW Slope One算法相比原生算法有了很大的改进,且以修正余弦相似度和用户共同评分数为权值的PCCW Slope One算法比PCW Slope One算法的推荐精度又有所提升。
4.3实验总结
从上面3组实验可以表明采用项目相似度作与用户共同评分数乘积为权值的Slope One算法相比本文中的其他算法推荐精度是最高的。其中,使用皮尔逊相似度改进的算法与原生Slope One算法比较提高的推荐精度达到了0.029,是所有改进算法效果最好的。同时也进一步说明,改进的Slope One算法不仅考虑到了项目之间的关联性,同时也解决了原生算法出现的用户共同评分差异过大的问题,有效地提高了算法的推荐精度。
5 结语
本文介绍了Slope One推荐算法,同时也介绍了以项目相似度为权值Slope One算法,在此基础上又结合了用户共同评分数再次改进了Slope One算法,采用项目相似度与用户共同评分数为权值的Slope One充分考虑了用户自身的喜好,以及项目之间的关联度。实验结果也明显表明了,改进后的算法与原生Slope One算法推荐精度有了明显的提高。
[1]基于用户相似性的加权Slope One算法[J].刘林静,楼文高,冯国珍.计算机应用研究,2016(09).
[2]李淋淋,倪建成,于苹苹,姚彬修,曹博.基于聚类和Spark框架的加权Slope One算法[J].计算机应用,2017,37(05):1287-1291+1310.[2017-08-23].
[3]丁少衡,姬东鸿,王路路.基于用户属性和评分的协同过滤推荐算法[J].计算机工程与设计,2015(02).
[4]孙天昊,黎安能,李明,朱庆生.基于Hadoop分布式改进聚类协同过滤推荐算法研究[J].计算机工程与应用,2015(15).
[5]郝立燕,王靖.基于填充和相似性信任因子的协同过滤推荐算法[J].计算机应用.2013(03).
[6]Lemire,D.,&Maclachlan,A.(2007).Slope One Predictors for Online Rating-Based Collaborative Filtering.
[7]周涛,李华.基于用户情景的协同过滤推荐[J].计算机应用,2010,30(04):1076-1078+1082.[2017-08-23].
[8]冷亚军,陆青,梁昌勇.协同过滤推荐技术综述[J].模式识别与人工智能,2014,27(08):720-734.[2017-08-23].DOI:10.16451/j.cnki.issn1003-6059.2014.08.005.
[9]一种改进的Slope One协同过滤算法[J].王毅,楼恒越.计算机科学.2011(S1).
[10]柴华,刘建毅.一种改进的slope one推荐算法研究[J].信息网络安全,2015,(02):77-81.[2017-08-23].
[11]基于邻近项目的Slope One协同过滤算法[J].杜茂康,刘苗,李韶华,浦琴.重庆邮电大学学报(自然科学版).2014(03)
[12]张玉连,郇思思,梁顺攀.融合用户相似度与项目相似度的加权Slope One算法[J].小型微型计算机系统,2016,37(06):1174-1178.[2017-08-26].
[13]基于不同数据集的协作过滤算法评测[J].董丽,邢春晓,王克宏.清华大学学报(自然科学版).2009(04)
[14]基于项目语义相似度的协同过滤推荐算法[J].肖敏,熊前兴.武汉理工大学学报.2009(03)
