基于多分类器投票表决组合的私募股权投资风险预测度研究
2018-01-16张娅萍
张娅萍,赵 峰,张 杰
(1.河南牧业经济学院 会计学院,河南 郑州450044;2.山东科技大学 经济管理学院,山东 青岛 266590)
一、引 言
所谓私募股权投资是指对具有高成长潜力且未上市的企业,借由非公开的方式进行募集投资,以实现并购、上市等形式并最终获取收益,是一种高收益同时也潜藏着高风险的投资方式。投资的不确定性往往因信息不对称等原因而增高,为了减少和降低私募股权投资的风险,就必需对其投资项目进行必要的风险预测。国内外学者在该领域进行了大量的研究,如Ruth等选取了67个私募股权投资案例的相关材料数据进行实证分析,得出了最显著的风险是委托代理风险[1];Rosenberg等评估了私募股权投资进行决策之前的风险,认为信息不对称比法律体系对投资决策的影响更大[2];Bongaerts等认为如果拟投资企业将来上市或出售的前景不能够较好地预测,就应该放弃对该项目的投资,因此成功退出是私募股权投资中非常重要的一个环节[3];王开良等研究了非系统性风险在私募股权投资过程中的表现,创建了模糊综合风险评价模型及其度量方法,但该方法也存在静态预测、适用性不强的缺点[4];孟庆军等采用了模糊层次分析方法对私募股权投资项目进行风险预测,但也存在方法过于简单、预测的准确率较低的缺点[5]。
就国内外相关文献的研究成果而言,私募股权投资风险预测的方法研究较少,现有的研究方法多为静态预测,方法比较单一,大都侧重于投资项目的单方面因素。私募股权投资风险的各个阶段在大部的研究中被分离开来,没有作为一个系统来进行研究,缺乏整体性的私募股权投资风险的预测模型与方法。
二、多分类器投票表决组合预测模型
(一)多分类器组合的投票表决规则
将M个互斥训练数据集合组成特定类别空间P,P=C1∪C2∪…∪CM,其中Ci,∀i∈Λ={1,2,…,M}称之为一个类,例如在数字识别问题中,M对应于P中的样本x,指定x的具体类别的内容,并由分类器e完成,用代表类别的一个标号j∈Λ∪{M+1}来表示,当j∈Λ时,即表示模式x经过分类器e被分至类Cj中,j∈{M+1},这表示e对x拒识;如果排除e的内部结构因素,也忽略其原理与方法,分类化的x为输入部分,而分类标号j作为输出部分,即j=e(x)。
若有K个独立且同分布的分类器ek(k=1,2,…,K)分别作用于测试样本x,样本x∈P,且赋予每个分类器ek作用于输入x一个标号jk,jk为第k类输出,即jk=ek(x)。当K较大时,难以保证j1=j2=…=jK,要使各分类器的分类预测结果jk(k=1,2,…,K)达到理想的效果,必须将各分类器进行有效组合,构建一个有效的组合分类器E,使E具有对每个训练样本x都有确定的标号j,即E(x)=j,j∈Λ∪{M+1}。
为了讨论方便,针对分类结果ek(x)=i,定义一个二值函数:
(1)
选取一种简单组合规则:
E(x)=
(2)
其中,∩为逻辑与操作,此组合规则为当且仅当j1=j2=…=jk=j,∃j∈Λ时,分类结果将达到预期效果,否则分类过程停止,该规则为一套严格的投票表决规则。
现将该投票表决规则进行适当放宽,其结果如下式:
E(x)=
(3)
式(3)中,∪为逻辑或操作,若各分类器的分类结果不相互排斥和矛盾,且该分类器组合的投票表决规则在某个分类器拒识时也不影响分类的最终结果,例如,jk1≠jk2,且jk1,jk2∈Λ,同样也能得到有效的最终组合分类结果。
本质上而言,上述两种分类器组合方式是将组合后的分类结果改由投票的方式来决定,前者为一致性原则通过,后者可视为无反对票即获通过。结合两种组合投票表决规则方式的优缺点,现将多分类器组合的投票表决规则修改如下:
E(x)=
(4)
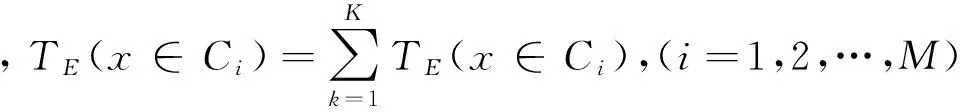
(二)基于先验知识的投票表决预测方法
在以往对单个分类器进行组合时,通常采用“一人一票”的方式进行表决[6],但因不同分类器的原理、算法及使用的特征不同,对训练样本的要求也不一样,并且不同分类器的训练过程也存在明显的差异,使得各分类器的分类性能存在明显差异,虽然各分类器之间可以相互补充,但总体的分类效果并不明显,甚至无法分类。为了充分发挥各分类器的优势,应放弃“一人一票”的表决方式,可以采用先验知识即“识别率+置信度”的投票表决方式,以提高分类器组合的分类效果。
首先,训练小样本,并得出每个分类器对其分类情况,在此基础上构建综合各分类器分类识别情况的混乱矩阵:
(5)

(6)
其次,在ek的识别结果为j的条件下,样本来自Ci类的概率可用条件概率表示如下:
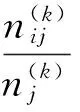
(7)
其中j=1,2,…,M+1。
如果混乱矩阵CMk的样本数量足够,还能将类别空间P的分布识别出来,则CMk也反映了ek的识别情况,因此可以将CMk作为分类器组合的先验知识,即把P(x∈Ci/ek(x)=j)作为投票表决后所得到的票数,则x∈Ci的概率或称为Ci的总得票数为:

(8)
其中i=1,2,…,M。
接着,以各分类器识别性能为先验识别的投票表决规则为:
E(x)=
(9)
即当类别不同设置不同时的表决阈值,其中我们可以通过训练获得阈值Tj。将Tj的初始值设置为:
(10)
其中,j=1,2,…,M;Nj为训练样本中包含于Cj类的所有样本的数量。
最后,训练时,若s类样本x的组合识别的结果显示为j类,则在识别情况不同时对Tj作如下修改:
(1)若j=s,表明x得到了正确识别,则不用修改Tj;
(2)若j=M+1,就是对x拒识,则:
ΔTj=
(11)
(3)若j≠s且j≠M+1,就是对x识别错误,则:
ΔTj=
(12)
ΔTs=
(13)
其中,α和β是学习步长,且α,β>0,为减小振荡,使α和β随学习次数增加呈现单调下降,取:
α=α0exp(-at),β=β0exp(-bt)
(14)
三、私募股权投资风险预测指标体系
(一)备选风险指标的选择原则
本文对私募股权投资风险指标体系的构建采取定性与定量相结合的方法,对于备选的私募股权投资风险定性指标先要进行标准化处理,然后进行赋权处理以便将指标数量化。对于风险定量指标直接采用相关的金融财务指标,并根据相关的金融财务数据进行赋值,为之后的实证仿真评价奠定了数据基础。综合借鉴其他文献关于风险指标的构建原则,本文遵循下面四个原则构建私募股权投资风险预测指标体系,具体为:
1.全面性原则。为了保证预测能够起到实际效果,备选的私募股权投资风险指标体系应具有高度覆盖性,要从各个方面反映私募股权投资风险的状况。
2.概括性原则。由于类型不同的风险往往随时间的变化而有特定的风险征兆,所以备选风险指标的概括能力应该比较高,这样才能够反映出私募股权投资风险中所蕴含的最本质属性。
3.灵敏性原则。所构建的指标体系要能够及时体现私募股权投资风险的状况,对私募股权投资风险和潜在的危机具有高度的敏感性。
4.可量化性原则。所构建的指标体系中,无论是定性指标还是定量指标,通过一定的方法都能够被量化和赋值或赋权,能够用精确的数值表示出来。
(二)备选风险指标的内容
基于现有的研究成果[7-10],本文综合定性和定量两个层面,选择了涉及市场风险、流动性风险、管理风险、道德风险、联合风险等五个方面的21个风险指标作为备选风险指标,进行私募股权投资风险预测指标体系的构建,如表1所示。

表1 私募股权投资风险预测的备选指标体系
对于表1中的定量指标,根据相关财务金融数据可以获取,对于定性风险指标,要先进行定量化处理才能对风险程度进行判定。本文为简化计算,对定性风险指标赋值采用比例一致的CR赋权方法。现设定第k位专家所在类中的专家个数为φk(φ≤m)个,将φk分为L个类别,第k位专家的权重为αk,其判断矩阵的一致性比例为CRk,可求出类别内专家的权重为:
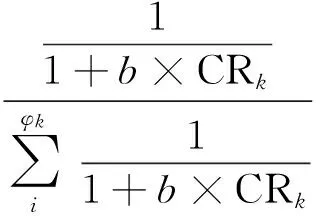
(15)
式(15)中,参数b起到调节作用,实际应用中一般取b=1。
类别间权重为:
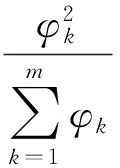
(16)
可求得总体权重为:
λk=αk×λj
(17)
其中,k=1,2,…,m;j=1,2,…,L。
实际获取的数据往往因各种原因而出现残缺、不完整或异常情况,所以要排除偏离期望值的异常数据。为了改善数据质量,本文对数据采取预处理,以便提高预测模型的有效性、准确性和可推广性等方面。对私募股权投资风险样本案例的初始训练数据子集,首先采用三倍标准差检验法进行稳健性预处理,把偏离均值三倍标准差范围以上的异常数据删去,然后各选取风险指标值最大的和最小的三个值,即共6个值进行分析,检查这6个指标值在数量级上是否存在极端情况,若出现异常就剔除极端值,否则说明训练样本数据集正常,可以运用这些数据对私募股权投资风险状况进行有效预测。
四、实证研究
(一)原始数据的收集与预处理
本文采用真实数据对私募股权投资风险预测模型进行实证仿真分析,数据集采用清科集团(Zero2iPo)发布的年度私募股权投资研究报告中的案例(http://www.pedata.cn/reportdo/toDetail/1427177395353033),根据统计原则,随机选取了78个典型项目作为本文实证仿真数据集。为了实证仿真训练的需要,所选取的私募股权投资项目中,一组投资项目存在潜在风险、或处在危机中、或者已经失败,另一组投资项目没有失败或尚不存在潜在投资失败风险。根据对这些项目进一步调查分析,其中有16个项目(20.51%)属于第一组情况,有62个项目(79.49%)属于第二组情况,两组数据可以进行对比训练。
一般来说,由于存在相对误差,私募股权投资风险财务比率有一定失真的可能性,而大多在技术评估私募股权的投资风险状况数据,所反映的财务稳定性较弱,这就要求对相关数据进行整理和技术处理,以避免预测模型在预测效果上的不准确。因而,针对异常投资项目,训练项目集在投资风险财务比率的前2%和后2%的数据将被排除,以确保模型预测结果的有效性和准确性。
(二)实验数据集的构造
为了得到预测结果性能指标,实证仿真实验中需要有多个数据集的支持,从统计角度需要进一步进行对比分析。本文采用的策略是先验知识投票表决规则,经过对训练样本的多次随机划分测试,模拟了多个实验数据集,排除了4%的投资项目后,训练实例集中还剩余75个投资项目。在这些投资项目中,有14个项目(18.67%)存在风险,有61个项目(81.33%)无风险或只存在潜在的风险;分析清科集团(Zero2iPo)年度私募股权投资案例的报告可以得出,存在风险的私募股权投资项目数量小于不存在风险的私募股权投资项目数量,这并不意味着目前不存在风险的投资项目将来不会出风险或项目失败的可能。
综上所述,训练案例数据集的训练方法为:把出现了投资风险的项目(14个)和尚未出现风险的项目(61个)随机分成2个子数据集,其中数据训练集涵盖大约81%的投资项目,验证集包含19%的投资项目。随机划分10次后产生了10个实验数据集,训练、测试和组合测试这10个实验数据集。
(三)基本分类器的选择
为了验证多分类器投票表决组合模型的有效性,本文选择了多元判别分析(MDA)、BP神经网络(NNs)、Logistic回归(Logit)、决策树(DT)和支持向量机(SVM)等5种不同单分类器模型进行实验对比训练[11-15],以此证明私募股权投资风险的多分类器投票表决组合模型对预测风险的有效性;同时,依据差异性原则和个体最优原则,对这5种单分类器的学习算法在同一个训练样本中进行建模优化,之后得到了基本的分类器,构建关于多分类器投票表决组合系统,根据单类择优运算,构成多分类器投票表决组合系统中构建基本模块。计算私募股权投资风险预测的单分类器及其组合成多分类器组合的样本训练实验结果,图1为所采集的经过预处理后的10个实验数据集的训练准确率的折线图,其中横坐标为数据集,纵坐标为准确率。
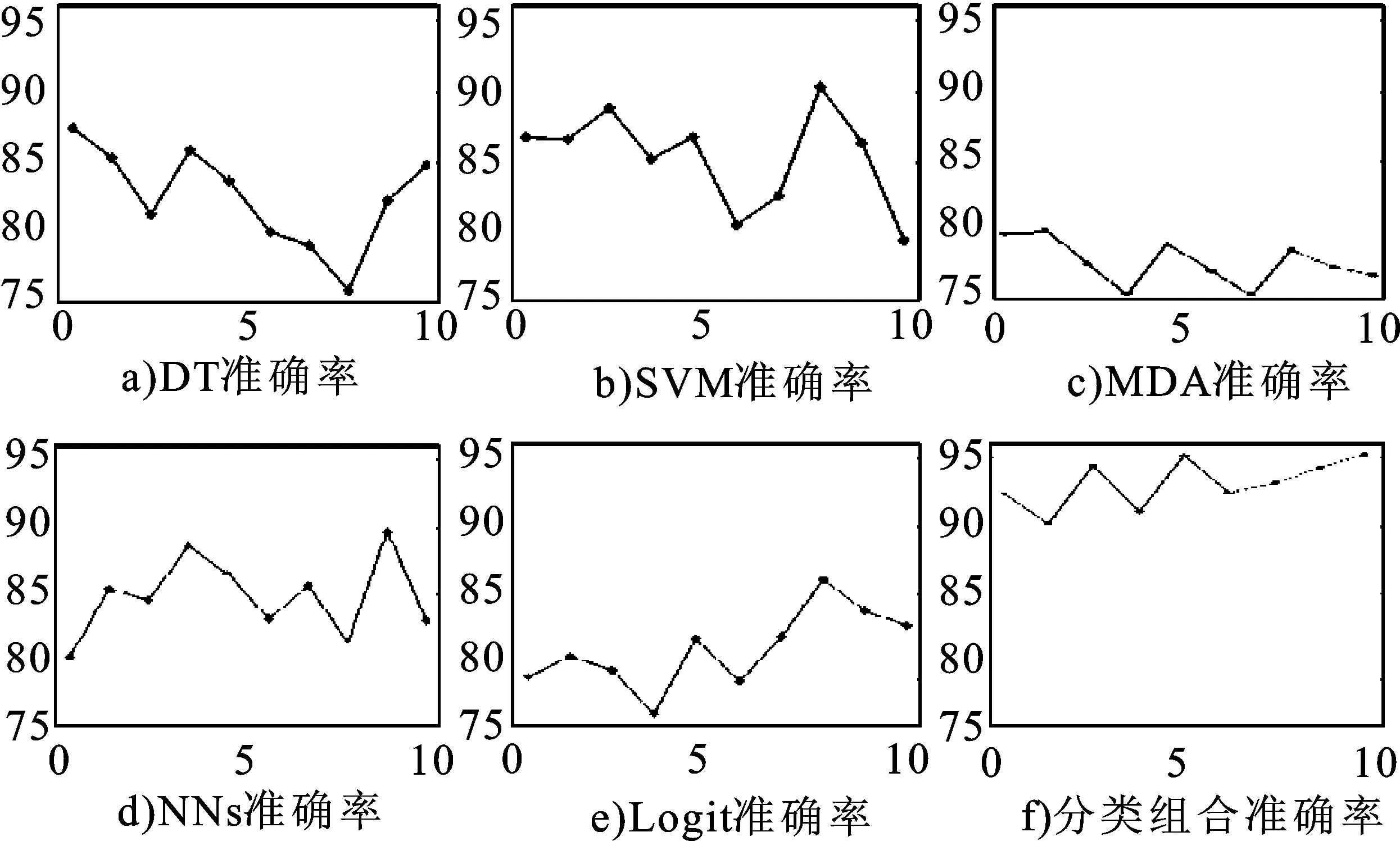
图1 各分类器在实验样本数据集上的训练准确率图
分析图1可以得出,在10个实验数据集上应用多分类器投票表决组合的私募股权投资风险来进行预测时,得出的离散系数和训练准确率方差均为最小。除此之外,在平均训练准确率方面,运用多分类器方法比所有的单分类器方法都更高。图1中的f图所显示的为多分类器的训练准确率折线图,与其他图相比,多分类器投票表决组合的平均位置较高,波动幅度也是最小的。
运用单分类器和多分类器投票表决组合方法对所选定的私募股权投资项目风险进行数据预测,以及相对应的10个实验数据集所对应的均值、方差和离散系数以及测试准确率,见图2。图2为测试准确率折线图,横坐标为数据集,纵坐标为准确率。
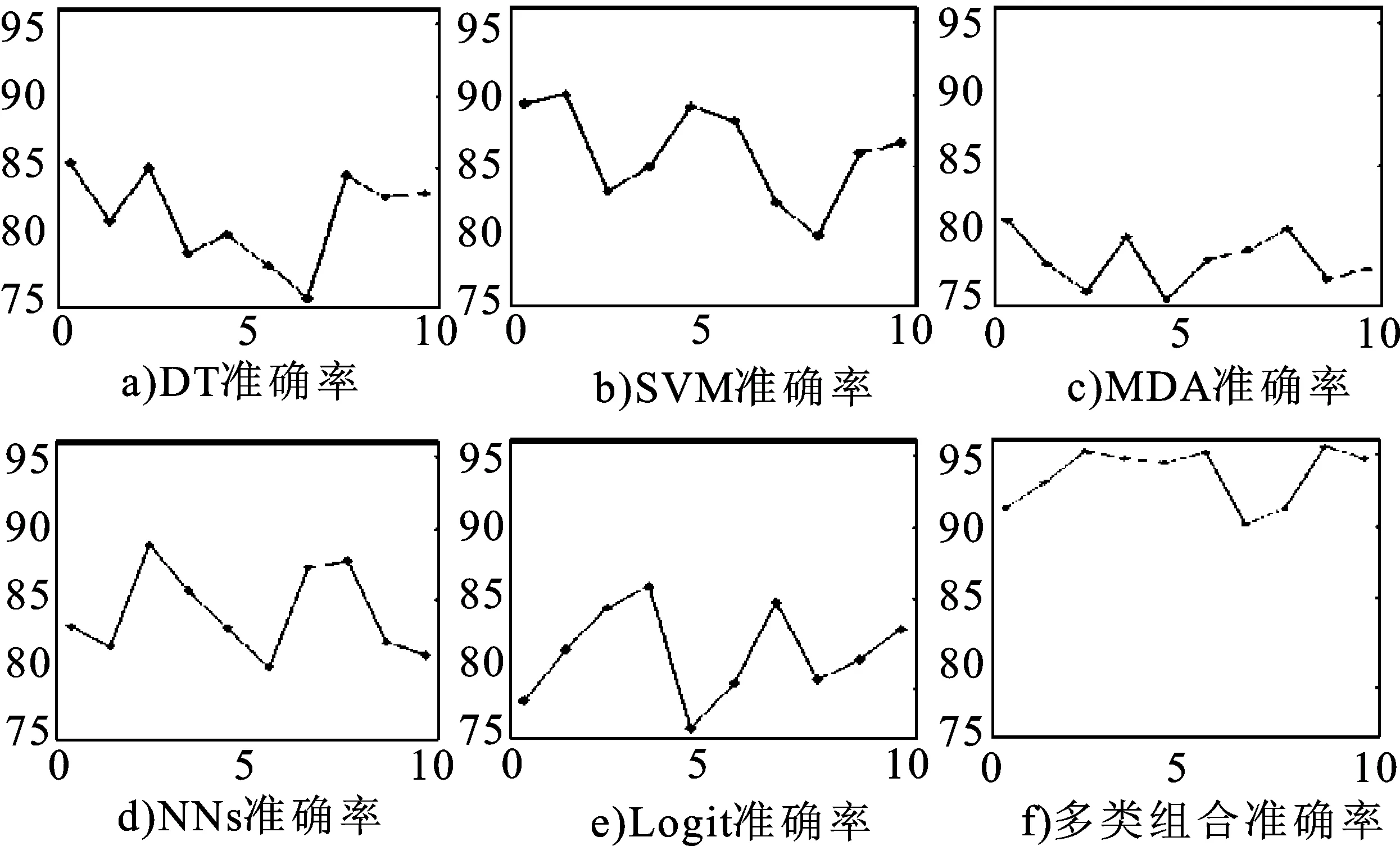
图2 各分类器对测试数据集准确率的折线图
图2可以得出,在私募股权投资风险预测的10个实验数据集中,测试准确率、方差和离散系数最小的是分类器投票表决组合的方法,平均测试准确率最高的也是多分类器投票表决组合方法。图2中的f图表示测试准确率折线为多分类器投票表决组合方法,此折线图与其他图相比,也说明这种方法预测的准确率最高,也最为稳定。
(四)实验结果及分析
为了进一步论证私募股权投资风险多分类器投票表决组合模型的预测效果,需要对多分类器模型进行更深入的验证。根据组合预测模型,取系数α0=1.0,β0=1.0,a=0.1,b=0.1,表2为训练次数所对应的置信度和识别率。如表2所示,训练次数不断增大时,相应的识别率和置信度也随之趋向稳定。
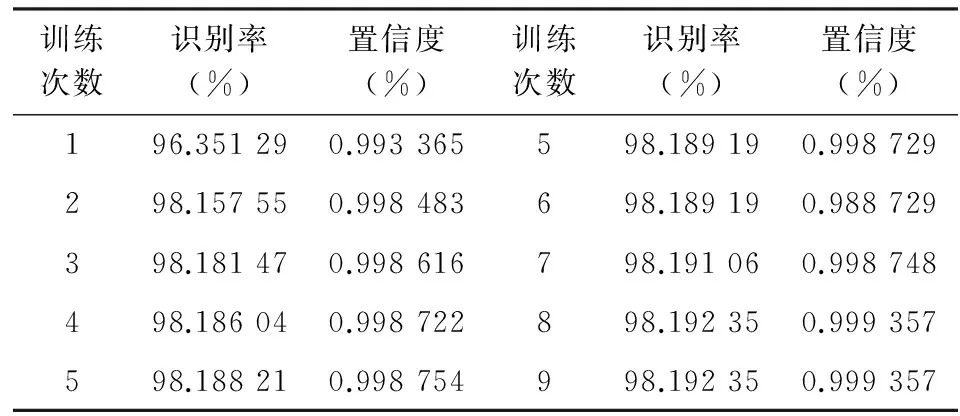
表2 实证训练次数与识别率及置信度的关系表
进一步分析,如表3所示,训练10次后,基于表决阈值对测试样本和训练样本的识别性能进行对比,依据训练集获取的表决阈值及混乱矩阵的有效性,实证结果表明了训练集和测试集在识别效果上基本一致。
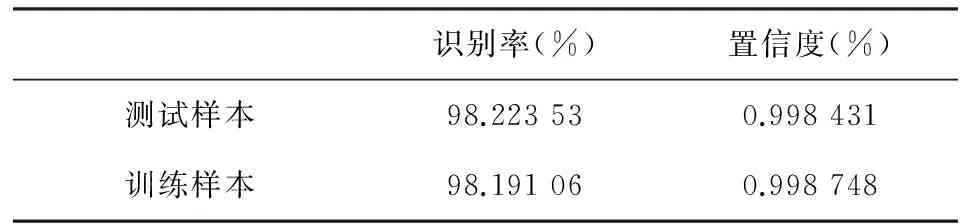
表3 训练样本与测试样本预测的结果比较表
常数α0、β0、a和b的取值不同,对样本数据集训练速度和训练效果的影响并不显著,对所得到的实证结果进行分析可以看出,训练速度与识别效果并不因常数的取值而发生剧烈变动。一般而言,循环训练次数较少时就会逐渐趋向稳定。表4为经过10个循环训练后α0不同取值所达到的识别率,从中可以发现识别效果相差并不明显,说明多分类器投票表决组合预测模型具有极高的分辨率,样本数量较少时也能达到预期目的。
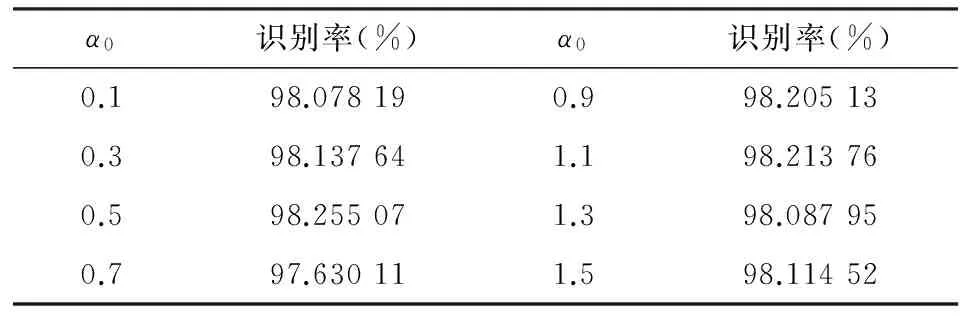
表4 α0不同取值识别率的比较表
以上实验结果表明,多分类器投票表决组合模型不仅能够提高平均预测的准确率,还能降低在不同数据集上预测准确率的离散程度,其在样本测试中延续了Logit和NNs方法的高识别度和SVM方法的高稳定性的同时,还解决了DT和MDA方法的低识别性能,以及在测试样本中除了SVM的基本分类器不稳定性的缺陷。因此,多分类器投票表决组合模型能够提高私募股权投资风险的预测效果,具有将不同基本分类器的性能互补和扬长避短的优点,在理论上与应用中都有着重要的价值。
五、结束语
在金融投资领域中,私募股权投资是一种新的投资方式,它的出现为企业融资及产业结构升级带来了新的资金融通渠道。与此同时,由于金融市场波动、信用机制缺失和信息不对称等因素诱发的不确定性和风险性,致使私募股权投资基金成为高风险行业[16]。因此,在实践中能够有效地预测私募股权投资风险就显得尤为重要。多分类器组合模型的投票表决规则具有较好的优越性,其能够获得单个分类器识别性能的先验知识,并据此改善投票表决的阈值,提升投票表决的效果。本文的实证仿真结果也表明,私募股权投资风险预测多分类器模型运用投票表决规则是有效的,置信度和识别率都得到明显提高,对私募股权投资风险预测的准确率能够达到预期效果。
[1] Ruth P,Ohashi T,Faber J H.Private Placements and Rights Issues in Singapore[J].Pacific-Basin Finance Journal,2002,32(10).
[2] Rosenberg J V,Schuermann A.General Approach to Integrated Risk Management with Skewed,Fat-tailed Risks[J].Journal of Financial Economics,2006,79(8).
[3] Bongaerts D, Charlier E.Private Equity and Regulatory Capital[J].Further Information.2008,52(3).
[4] 王开良,郭霞.私募股权投资基金投资风险评价及实证研究[J].改革与战略,2011,27(11).
[5] 孟庆军,蒋勤勤.基于模糊层次分析法的私募股权投资项目的风险评估研究[J].项目管理技术,2013,10(10).
[6] Elizabeth Ann,Andrés M.Discriminant Analysis of Multivariate Time Series:Application to Diagnosis Based on ECG Signals[J].Computational Statistics and Data Analysis,2014,70(9).
[7] 蒋伟,阮青松.跨期风险—收益权衡关系研究——来源于沪港通的新证据[J].统计与信息论坛,2017(3).
[8] 方红艳,付军.我国风险投资及私募股权基金退出方式选择及其动因[J].投资研究,2014,33(1).
[9] 李九斤,王福胜,徐畅.私募股权投资特征对被投资企业价值的影响——基于2008—2012年IPO企业经验数据的研究[J].南开管理评论,2015,18(5).
[10] 姜爱克,赵峰,李学伟.基于相似度加权投票组合的私募股权投资风险预测[J].科研管理,2017,38(7).
[11] Sangjae Lee A,Wu Sung Choi.A Multi-industry Bankruptcy Prediction Model Using Back-propagation Neural Network and Multivariate Discriminant Analysis[J].Expert Systems with Applications,2013,40(12).
[12] Mark McCartney,David H Glass.The Dynamics of Coupled Logistic Social Groups[J].Statistical Mechanics and Its Applications,2015(4).
[13] Eyup Bast1,Cemil Kuzey,Dursun Delen.Analyzing Initial Public Offerings′ Short-term Performance Using Decision Trees and SVMs[J].Decision Support Systems,2015,73(3).
[14] Hussain Ali Bekhet,Shorouq Fathi Kamel Eletter.Credit Risk Assessment Model for Jordanian Commercial Banks:Neural Scoring Approach[J].Review of Development Finance.2014,4(3).
[15] Paulius Danenas,Gintautas Garsva.Credit Risk Evaluation Modeling Using Evolutionary Linear SVM Classifiers and Sliding Window Approach[J].Procedia Computer Science,2012(9).
[16] 冯素玲,黄春晓.基于多任务代理模型的PZP网贷平台治理研究[J].河南师范大学学报:哲学社会科学学版,2017(9).
