基于Gamma随机效应分层贝叶斯模型的汽车延保定价
2018-01-16谢远涛
谢远涛,毛 羽
(对外经济贸易大学 保险学院,北京 100029)
一、引 言
汽车延保合同是指在汽车原厂保修期结束后汽车所有人与延保人签署的合同,也是在约定时间内由延保人提供合同责任范围内机动车维修费用的合同。因汽车故障率常呈现浴盆型状的曲线,而厂家保质期后汽车保修的需求却得不到满足,延保作为厂家保质期的延长应运而生。延保市场在中国刚刚兴起,目前只是通过主机厂或者经销商提供延保服务,还没有成为备案的保险产品,市场潜力巨大,为延保产品提供精算定价方案具有很强的现实意义。Majeske提出了一个一般混合模型,该模型认为延保索赔是由制造过程、销售过程和使用过程共同决定的,并采用实际数据建立了威布尔-均匀混合模型[1];之后,Majeske又假设汽车故障过程是一个非泊松过程,故障次数由两部分共同决定:规模函数和瞬时故障率,其中规模函数描述了在规定时段内且没有超过保修里程范围的汽车数量,从而实现了二维保证下的故障次数估计[2];Tong等人在最小维修和组合保修策略的假设下,将延保分为销售时购买和基本保修期结束时购买两种情况,基于故障率和使用率给出了两种延保定价的模型[3]。国内关于延保的研究非常少,能采用实际数据的实证研究更是寥寥无几。叶武等人使用最小维修,假设故障发生满足非齐次泊松分布,从博弈论的角度讨论生产商、维修商和消费者共同博弈时生产商的最优定价策略[4];智晓梅研究了单个零部件的故障率分布,应用可靠性理论和更新过程理论构造了成本预测模型[5]。
鉴于上述研究未能遵从“从人、从车、从环境”的定价原则,故与成熟商业车险定价尚有很大差距[6]。因此,本文在前人研究基础上引入费率因子进行延保定价,由于获取大量延保数据存在困难,若在费率厘定时引入的费率因子太多使风险同质化有可能造成某些单元格数据缺失,甚至出现维度灾难,故使用贝叶斯MCMC方法,通过先验假设解决样本数据不足的问题。
二、模型的构建
(一)模型的选取与基本假设
已有学者将贝叶斯分析用于寿命数据分析。金博轶基于有限数据条件,使用贝叶斯MCMC方法估计Currie模型参数,预测了中国人口动态死亡率[7]。考虑到产品寿命表现出加速失效特征,通常假设寿命时间满足威布尔分布,在工程实践应用中威布尔分布更是被广泛使用。Ganguly等人基于贝叶斯MCMC方法,使用简单步进应力模型(工程中常用的一种可靠性分析模型,该模型可以在较短时间内评定出产品的可靠性,且对样本量要求不高,适用于高可靠长寿命产品)估计加速寿命试验数据的分布参数[8],其中假设寿命服从威布尔分布,且在不同应力水平下的分布具有相同的形状参数,而尺度参数随应力水平上升而增加。
本文将使用威布尔分布拟合不同地区、不同车型汽车的七大系统的寿命,但在实际操作中想要获得所有车辆的所有维修保养记录是不现实的,因此在分析中常常会遇到选择性样本的问题。举例来说,可获得的数据仅为一家4S店一段时间内所有车辆的保养维修记录,在这个样本数据中主要有两个问题:一是存在右删失:即到观察结束为止还未发生故障的汽车系统的寿命删失了,同时数据中还有大量的保养记录,汽车进行保养之后其机能发生了改变,若忽略两次故障之间的保养记录,会使汽车系统的寿命被严重高估,因此保养数据也应视为删失数据;二是存在左截断:即一辆车的第一条维修记录仅代表这辆车在这家4S店的第一次维修,但也可能并非是这辆车真实的第一次维修。
孙丽玢等人在定数截尾情况下利用平均剩余寿命构造样本矩,将威布尔分布数据转换为均匀分布,利用第一个次序统计量代替第三阶矩得到修正矩估计[9];周晓东等人研究当寿命数据为服从威布尔分布的删失数据时分布参数的贝叶斯估计[10],其中对于尺度参数假设其先验分布为逆伽马分布,至于形状参数先验分别考虑离散分布和均匀分布两种情况。
本文为了解决以上选择性样本的问题,首先假设汽车系统发生故障的时刻随机,并且汽车的保养或维修是完美保养或维修,即汽车经过保养或维修后相应的系统可以达到初始状态。也就是说,系统的故障过程是一个更新过程,更新过程是Poisson过程的一个推广,在更新过程中两次故障的时间间隔是相互独立的。因此,对于同一个系统,当汽车经过一次保养或维修后就可以将这辆车视为一辆新车,从零开始计算其到下一次保养或维修的时间间隔。通过这样的假设,本文将汽车故障这样一个可重复发生的事件转化为一个类似于汽车报废的不可重复事件,从而将故障分析问题转化为生存分析问题,以解决右删失问题。由于无法判断第一条观测中的寿命是否存在左截断问题,故舍弃每一辆车在样本数据中观察到的首次故障时的寿命观测值。
(二)多层贝叶斯模型
当先验分布含有超参数但又缺乏相关信息来确定这个超参数时,可对超参数再次设定一个先验分布构建分层先验分布。多层先验分布因其可以降低先验分布设定误差的风险而被广泛使用。周丽莉等人使用分层先验和MCMC方法缓解了数据缺失和异质性度量问题[11]。本文将构建一个多层贝叶斯模型来估计汽车系统寿命的后验分布。
1.考虑删失寿命的威布尔分布及先验分布。



(1)
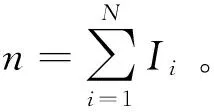
令λ=s-υ,s为尺度参数,可见λ的分布中也包含了υ的信息,故即使υ的先验假设不够精确,由于下文会对λ的先验分布进行详细的估计,所以参数υ的信息也会因此得到一定补偿;虽然使用贝叶斯假设是最简便和常用的方式,但鉴于本文可以从样本中获取部分先验信息,所以对υ使用贝叶斯假设显然是不妥的。鉴于υ作为威布尔分布的形状参数必须为正,且为了简化模型,不妨简单假设形状参数υ满足Gamma分布,并与寿命X相互独立,采用共轭先验形式:f(υ|x)=f(υ)~Gamma(a,b),当υ已知时,参数λ的共轭先验也为Gamma分布,设λ~Gamma(α,β),则λ的后验分布为:
f(λ|υ,x)
(2)

为了求得υ、λ的后验分布,需要知道超参数a、b、α、β,但是由于缺乏先验信息,故需要对超参数设置超先验分布。为了更加准确地估计λ的后验分布并分析相关因子对系统寿命的影响,在设置超先验分布之前,不妨建立第二层模型对λ进行更加准确的描述。
2.威布尔混合效应模型。引入合理的协变量描述λ可构建威布尔回归模型。Jeon等人通过使用关联规则分析寻找产品数据与故障数据之间的关系,根据关联规则确定故障时间间隔,并利用威布尔回归研究了相关因子对故障时间间隔的影响[12];孙维伟等认为考虑随机效应并引入分层模型,可以极大改善拟合优度和充分反映非正态分布的个体异质性[13]。本文也将引入威布尔回归分析,同时考虑固定效应和随机效应。在研究汽车系统寿命的时候,通常关心系统、车型、地区等因素对系统寿命的影响,把这些费率因子设定为固定效应,但是固定效应仅解释了组间差异,因此同时引入个体随机效应解释组内差异。个体随机效应认为相关性来自重复响应,即在同一固定效应下不同个体之间的系统寿命也会有所不同,研究者对随机效应大小的关注胜过其形成机制,其模型具体形式如下:
λ=yf+γ
(3)
其中λ=(λ1,λ2,…,λN)′;f=(f11,f12,…,fij,…,fkn)′为固定效应系数向量,fij表示第i个影响因子第j个水平,且本文假设固定效应系数均为来自某特定分布的定值;

引入威布尔混合效应模型后,由于假设给定样本的固定效应系数均为定值,故只要求得f和αr、βr的值就可通过式(4)式(5)求得参数α、β,从而将对λ先验分布的估计转化为对f和γ分布的估计:

(4)
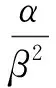
(5)
因为难以获得固定效应系数的先验信息,故对f的分布采用贝叶斯假设,即g(fij)∝1,为了保证参数λ>0,将fij的定义域设为(0,∞)。在以往的研究中,通常假定随机效应系数满足正态分布,但这显然是不合理的。在给定固定效应系数的条件下,同一组内固定效应是一个常数,在第一层模型中已经假设λ服从Gamma分布,那么根据威布尔混合效应模型的形式应认为γ也服从Gamma分布才合理,故令γ~Gamma(αr,βr)。如果直接通过回归,一般的软件难以实现这一假设,但是构建分层贝叶斯模型,使用Winbugs通过基于Gibbs抽样的MCMC方法,则可以实现随机效应系数的非正态分布。
3.超先验分布。综合上述两层模型,现在需要设置分布的超参数有a,b,α,β。
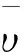
(6)
再令其分别等于分布的期望与方差,即:
(7)
则可得超参数a,b的估计值:
(8)
αr,βr是随机效应系数γ~Gamma(αr,βr)的超参数。假设αr满足贝叶斯假设,f(αr)∝1,定义域为(0,)。根据Jeffreys准则,当γ服从Gamma分布时,其Fisher信息矩阵为:
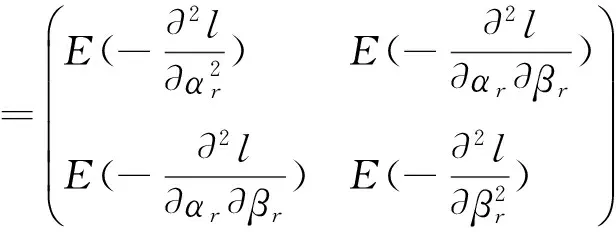
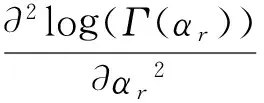
三、系统寿命与维修次数的转换
(一)维修次数
由于延保期内系统可能发生多次故障,因此延保的定价需要依托于系统寿命与故障次数的转换。由于前文已假设系统的故障过程是一个更新过程,所以系统在特定时间内的平均故障次数等于总时长除以平均系统寿命。
(二)竞争风险
实际上,在每一个系统中都包含很多部件,只要这些部件中有一项发生了故障都会形成一次故障记录,也就是说这些系统中存在竞争风险。假设X1,X2,…,Xn为汽车对应系统发生故障时的潜在寿命,这些变量是在实际操作中无法观察到的;实际观察到的寿命是真实寿命,是所有潜在寿命中最短的一项,也就是T=min{X1,X2,…,Xn},但是每一个部件对应的平均维修费用也存在差异,假设存在两个部件:一个部件潜在寿命较长但维修费用较高;另一个部件潜在寿命较短但维修费用较低,因为在次均维修费用上使用的是整个系统的平均费用,因此相应的故障次数也应由系统平均寿命求得,但事实上用真实数据估计出的寿命计算得到的是平均故障次数等于总时长除以系统最短潜在寿命,故障次数实际上被高估了,为了解决这一误差,还需要还原平均系统寿命的分布。
不妨假设系统c(c=1,2,…,n)中存在k个部件,部件d(d=1,2,…,k)的寿命Xcd相互独立且服从威布尔分布ω(υcd,λcd);系统寿命Xc~ω(υc,λc),那么有Xc=min(Xc1,Xc2,…,Xck),即Xc的分布为最小值分布,易得:
(9)
此外,由于延保的计算是以时点为标准的,而这里计算的平均寿命是以故障为标准的,因此在计算故障次数时总时长也应当做适当调整。一般汽车保修期为三年,比如计算一个延长到五年的延保,那么在计算三年到五年这个时间段内的平均故障次数时所使用的总时长应为两年加上第三年初这一时刻到最近的上一次故障发生时刻这两者之间的时间间隔。由于假设故障时间是随机的,因此不妨假设距离上次故障已经过了系统平均寿命的一半。
四、实证研究
本文数据来自某4S店的2014—2016年的保养维修数据,有效观测3 894条。在威布尔混合模型中选取地区、车型及系统为固定效应因子,为了防止虚拟变量陷阱,同时考虑到在固定效应中未设置常数项,分别选取车型中的“雅阁”水平和系统中的“保养”水平为基础水平,参数估计值为0,其余参数的估计使用Winbugs通过基于Gibbs抽样的贝叶斯MCMC方法实现。
仿真分析从两组初始值出发进行Gibbs抽样,得到两条马氏链,每条马氏链都经过5 000次迭代,为了保证参数的收敛,舍弃前500次的抽样数据。图1展示了各参数两条马氏链的参数历史迭代图,从中发现各参数随着迭代次数的增加,绝大部分后验参数估计值趋于稳定且两条马氏链几乎完全重合,可认为结果收敛效果非常好。表1展示了参数的后验估计的均值、标准差以及2.5%、50%、97.5%的分位数。



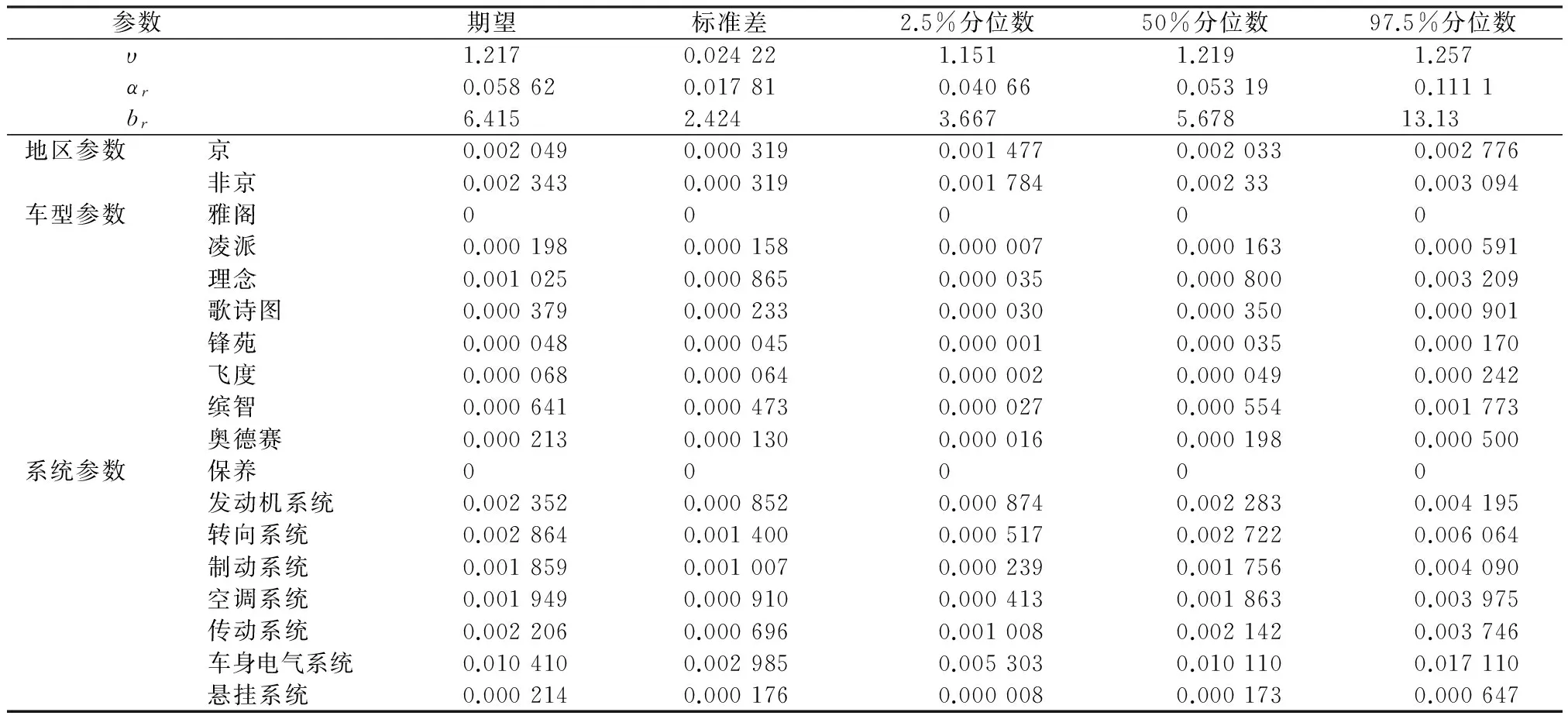
参数期望标准差2.5%分位数50%分位数97.5%分位数 υ1.2170.024221.1511.2191.257 αr0.058620.017810.040660.053190.1111 br6.4152.4243.6675.67813.13地区参数京0.0020490.0003190.0014770.0020330.002776非京0.0023430.0003190.0017840.002330.003094车型参数雅阁00000凌派0.0001980.0001580.0000070.0001630.000591理念0.0010250.0008650.0000350.0008000.003209歌诗图0.0003790.0002330.0000300.0003500.000901锋苑0.0000480.0000450.0000010.0000350.000170飞度0.0000680.0000640.0000020.0000490.000242缤智0.0006410.0004730.0000270.0005540.001773奥德赛0.0002130.0001300.0000160.0001980.000500系统参数保养00000发动机系统0.0023520.0008520.0008740.0022830.004195转向系统0.0028640.0014000.0005170.0027220.006064制动系统0.0018590.0010070.0002390.0017560.004090空调系统0.0019490.0009100.0004130.0018630.003975传动系统0.0022060.0006960.0010080.0021420.003746车身电气系统0.0104100.0029850.0053030.0101100.017110悬挂系统0.0002140.0001760.0000080.0001730.000647
根据后验参数的估计值,可以得到每种系统、每一地区、每一车型的系统寿命分布;再根据竞争风险对参数进行调整即可得到平均系统寿命分布,这里是按车型和地区分类的平均故障时间间隔和三年到五年的两年全面延保价格,即所有系统的故障都保障的延保价格。从结果来看,平均故障时间间隔在387~417天,价格区间在2 479元~8 878元,与市面的真实价格相近,这也证明了使用本文的模型进行定价具有合理性(见表2)。
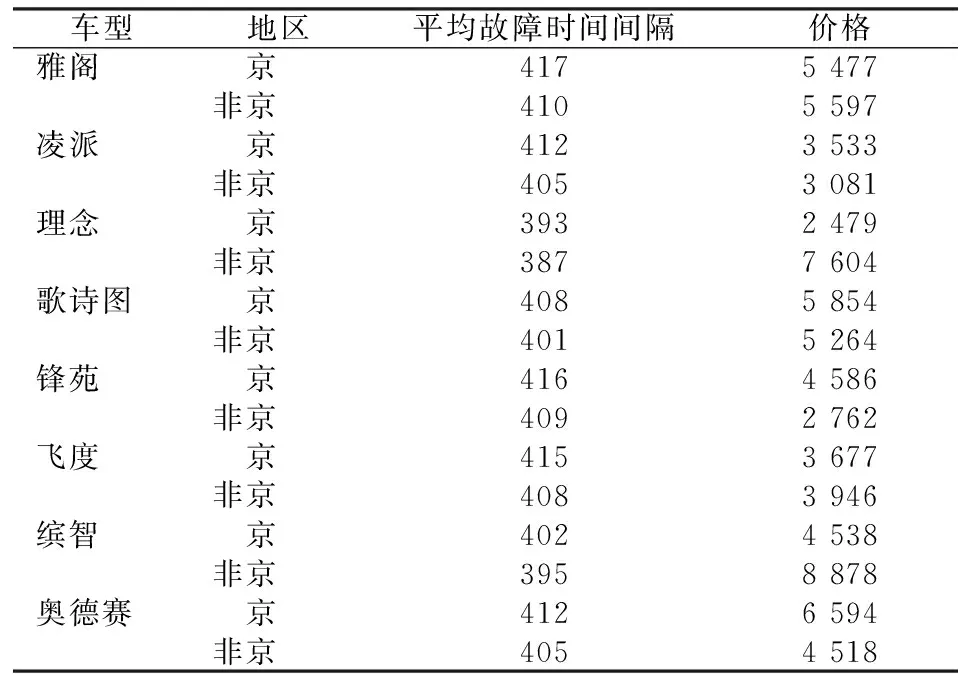
表2 按车型和地区分类的平均故障时间间隔与两年全面延保价格表
五、结论与展望
目前,汽车延保只以延保服务的形式出现在主机厂或者极少数专业服务公司业务列表中,纵观英美发达国家的经验,最终都需要发展成为标准化的保险产品才能提供更好的保障。主机厂有维修保养数据,但是很难实现与其他主机厂数据的共享且缺乏精算定价能力,而保险公司只有事故理赔方面的数据积累,因此数据的割裂将长期限制延保的发展。
本文利用有限的维修保养一手数据,使用SAS编程处理,结合Winbugs进行建模分析;精算定价中使用的两大主流模型是广义线性模型与信度模型,这两个模型分别使用了样本信息和先验信息;本文基于贝叶期分析整合了样本信息与先验信息,实际上是广义线性模型与信度模型的完美统一,可以有效避免过度奖惩效应[14],而且模型还综合考虑了选择性样本问题。本文的创新点体现在:构造了一个多层贝叶斯模型估计系统寿命的分布参数,引入了一个威布尔混合效应模型,在以地区、车型与系统作为协变量描述威布尔分布参数的同时,实现了非正态随机效应的估计;随机效应设定方面使用了Gamma分布,与现有文献通常采用的正态分布假定形成对比,模型考虑了竞争风险,对参数进行了调整。基于Gibbs抽样的贝叶斯MCMC方法估计结果收敛性较好,最终定价也与实际情况较符合,为延保定价提供了可行方法,并将会为保险公司推出延保产品提供精算定价支持。
本文还存在进一步研究的空间:第一,只考虑了时间一个维度描述两次故障间隔,而实际需求通常还需考虑里程数;第二,更新过程和完全维修的假设过强,现实中较难到达;第三,系统寿命与故障次数的转换比较粗糙,没有找到准确的转换数学形式,故仍需进一步深入研究。
[1] Majeske K D.A Mixture Model for Automobile Warranty Data[J].Reliability Engineering & System Safety,2003(1).
[2] Majeske K D.A Non-Homogeneous Poisson Process Predictive Model for Automobile Warranty Claims[J].Reliability Engineering & System Safety,2007(2).
[3] Tong P,Liu Z,Men F,et al.Designing and Pricing of Two-Dimensional Extended Warranty Contracts Based on Usage Rate[J].International Journal of Production Research,2014(21).
[4] 叶武,邵晓峰.产品质量保证的延保定价研究[J].西南民族大学学报:自然科学版,2012(6).
[5] 智晓梅.汽车零部件故障率基础分布及保修成本测算[D].长春:吉林大学硕士学位论文,2014.
[6] 谢远涛,毛羽.基于进展时间和操作时间的两步广义线性混合模型非寿险准备金估计[J].保险研究,2016(11).
[7] 金博轶.动态死亡率建模与年金产品长寿风险的度量——基于有限数据条件下的贝叶斯方法[J].数量经济技术经济研究,2012(12).
[8] Ganguly A,Kundu D,Mitra S.Bayesian Analysis of a Simple Step-Stress Model under Weibull Lifetimes[J].IEEE Transactions on Reliability,2015(1).
[9] 孙丽玢,费鹤良.在定数截尾样本下三参数威布尔分布的矩估计[J].应用概率统计,2003(3).
[10] 周晓东,汤银才,费鹤良.删失数据威布尔分布参数的贝叶斯统计分析[J].上海师范大学学报:自然科学版,2008(1).
[11] 周丽莉,丁东洋.基于MCMC模拟的贝叶斯分层信用风险评估模型[J].统计与信息论坛,2011(12).
[12] Jeon J,Sohn S Y.Product Failure Pattern Analysis from Warranty Data Using Association Rule and Weibull Regression Analysis:A Case Study[J].Reliability Engineering & System Safety,2015(133).
[13] 孙维伟,张连增,胡祥.基于分层广义线性模型的非寿险费率厘定精算模型研究[J].统计与信息论坛,2017(6).
[14] 谢远涛,王稳,谭英平,杨娟.广义线性混合模型框架下的信度模型分析[J].统计与信息论坛,2012(10).
