重铸视角下对多媒体英语语音教学的思考❋
2018-01-04朱
朱
敏
中南林业科技大学
重铸视角下对多媒体英语语音教学的思考❋
朱
敏
中南林业科技大学
本文在重铸视角下反思现在的多媒体英语语音教学。在分别介绍多媒体教学、语音习得和重铸反馈的认知和行为特点后,指出,在重铸条件下多媒体语音教学有所为也有所不为,超音段学习与多媒体的结合被证实是有效的,多媒体提供的视觉反馈属于隐性重铸,对隐性的语音知识的发展有直接推动作用。但音段学习则属于封闭感知-动力回路反复运行后的知识程序化过程,基本与意义交际无关,所以多媒体提供的重铸的作用极其有限,音段学习应回归传统训练。
重铸,多媒体教学,语音习得,音段语音
1.多媒体与语音学习
1.1 多媒体的原理与模式
新世纪头十年中国多媒体教学迅猛发展。媒体即输入渠道或模式;“多”是指输入包括言语(verbal)模式的(口头或印刷文本)、图画模式的(图表,照片)、视频模式的,以及教师的肢体。视觉和言语材料的互补是多媒体教学的优势之所在(Mayer 2005)。
多媒体教学的优势的认知基础是1)Mayer(2005)的双渠道假设(dual channel assumption),即人类信息处理系统有彼此独立的言语和图像处理系统。2)二语研究者普遍接受的“反馈+加工”假设:学习的认知过程是不断用反馈性输入构建知识结构的过程,是加工旧的认知结构,使之逐渐同化(assimilate)为目标认知结构的过程。3)Mayer(2005)的空间连贯原则(spatial contiguity principle),即多媒体条件下,各种信息表征是邻近的,有利于学习者建立表征间的联系,因而比单媒体学习更能保持(retain)知识表征。结合这三大理论与Jones&Plass(2002)的综合模式,可得出图1所示的认知工作模式。
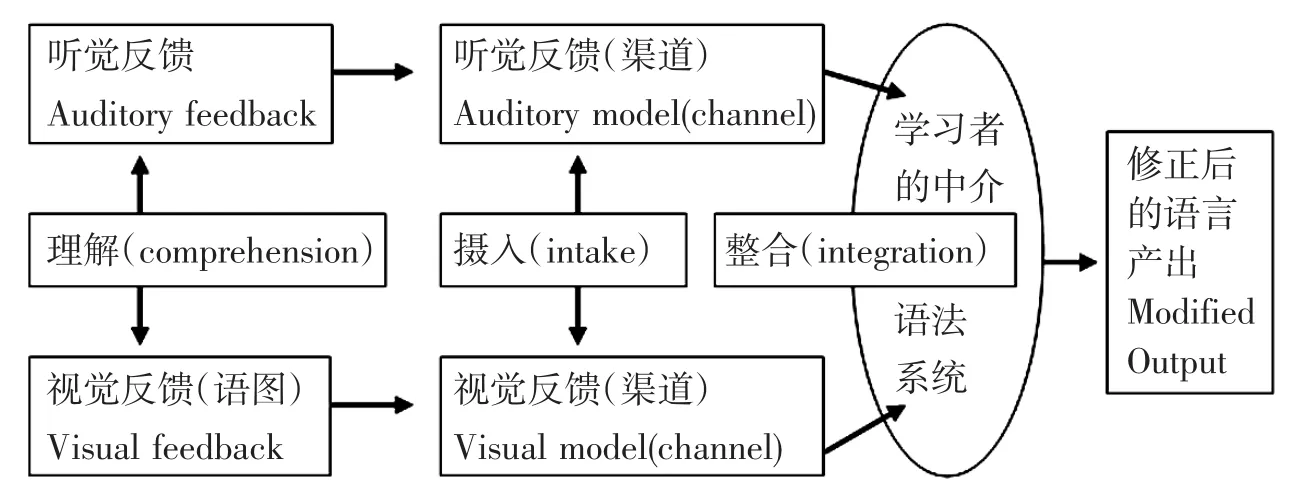
图1 多媒体语音学习(教学)认知模式
如图所示,教师的先行组织比如元语言知识讲解加上最初输入的可理解的输入(反馈)再分别进入视觉和听觉渠道,从而开始了新的认知过程——摄入;摄入意味着认知开始向长期记忆迈进,但仍在两个渠道中分别进行;摄入的信息在工作记忆中形成各模式心理表征后,在这些心理表征间建立互参的(co-referential)本质就是互相提醒联系,这就是整合。整合后的知识结构(表征)进入长期记忆,并被继续修正。
既然视觉输入是多媒体优势之所在,那关键的问题是多媒体语音教学的视觉模式的输入是指什么?要回答这个问题,必须先介绍语音习得的性质、过程和特点。
1.2 语音习得的过程与性质
相比语法、词汇习得,二语的(和一语的)语音习得非常独特,它极度依赖人脑对语言输入中原始的物理声学信号的感知。按照认知科学主流的联接主义模式,大脑神经是一个动态网络。神经网络(人脑)具有适应性与自组织性(self-organizing),可以在学习或训练过程中随环境输入的变化改变突触权重,使得细胞发射偏向(cell firing preferences)能忠实地反映输入的统计特点;输入语音特征的不均匀分布会导致神经发射偏向的不均匀分布,进而导致磁吸或扭曲(Kuhl 1991),在网状感知地图(perceptual map)形成有区分的两个(或以上)语音范畴(相当于音位)。所以语音学习是典型的统计学习(Maye Werkerb & Gerken 2002),是经验归纳。
神经网络除了感知地图还有发音地图,两幅地图上的感知元和动力元可随机联接,及彼此激活。动力元的激活偏向也可以凭借它们的整体向量(population vectors)加以预测,并适应环境输入即感知元整体向量在发音地图上形成若干向量高峰。这些高峰要是分得开,音段发音就有足够的区分度,beat就不会误发为bit。向量高峰要是毗邻,甚至交叠,那发音就会混同不同的音段。两类元或两幅地图的联接构成感知—动力 (发音)回路(Loops),这就是完整“输出—输入”反馈系统,只是这个反馈系统是个纯物理性的,没有意义或交际意图(intention)的介入,因此原则上,外人的提醒(Swain&Lapkin 1995)及提醒引发的注意在这种基于网络统计的语音学习中是不起作用的。感知元和动力元的联接就是反馈,就是提醒;这意味着语音学习是非常内在(radically internal),非常“隐私”的过程,似乎与教学设计、方法、水平等无关。
另一方面,由于是网络统计学习,语音学习不受形式语言学常说的“刺激贫乏”的制约,大脑中会忠实地反映输入的统计特点形成语音范畴,并不需要预制音系范畴或音系结构,因而属于无监管学习(unsupervised learning),完全靠对经验的归纳。在一语语音习得中,儿童最终归纳出的语音格局取决于环境输入既有的统计特点(Kuhl 1991;Maye et al.2002)。但二语的情况不一样,学习者大脑已有母语的音位范畴,会对输入形成磁吸,把音频教材、教师等提供的目标语输入归入到母语既有范畴,造成如中国学生/I/、/i/不分、/ε/、/æ/不分等。所以在二语习得中语音输入(经验)的质量和频次尤为重要,优质的教学设计和足量的反馈是二语语音学习成功的关键。
至此笔者发现,语音学习一方面“隐私”、个性化,教师反馈作用不大,一方面又很依赖反馈的质量和设计或预制格局,是不是自相矛盾?其实没有矛盾。“隐私”的纯物理反馈学习离不开语音输入蕴含的正确分布信息,教师、教材和课堂内容设计可以提供合理的、多模态的语音输入,该输入的统计(分布)特点正确地反映目标语标准语音的物理参数的统计特点,从而间接地引导个体内在的语音学习走在正确的方向。在这方面,多媒体课堂拥有海量的优质音视频及图文输入,无疑起到得天独厚的作用。稍后我们会回到这问题。
1.3 语图音征——多媒体语音教学的视觉反馈
鉴于语音习得的上述特点,学界提出多种基于感知的模型,如Kuhl(1991)、Best(1995)等。这些感知学习模型一致认为,学习者(包括儿童)产出的错误直接源于对目标语语音范畴的感知错误;学习就是对语音输入的感知过程。在这过程中,学习者逐渐将各类音征(cue)整合为与音姿(gesture)匹配的(听觉)感知项(percept),在认知中建立音姿和感知的内在联系。产出的错误会被不断地修正,直至被同化为目标范畴。
音征是声学概念,是语音稳定的声学表象,如塞音的音征就是爆破时产生的冲直条(spike),浊的音征就有接近零或呈负值的浊音起始时间(voicing onset time)。音征可以在语图上看到,语音学家通过观测语图音征可以判定音的类属。音征必然和特定的发音动态过程或声道形状对应,所以从语图音征也可大致推断发音情况。从感知的角度讲,音征构成听者(或学习者)对语音输入的感知项。所以音征既是发音参数也是听觉参数,在语音学习回路中负责连接感知与动力,是整个回路的基础。而对于多媒体教学来说,出现在语图的音征既是听觉的,也是视觉的,是真正能体现多媒体认知优势的视觉反馈。
2.多媒体语音教学的现状与反思
2.1 可视语音教学概况
国内外现有的多媒体语音学习模式的工作原理与上述语音习得和多媒体学习的性质、特点基本吻合,即在一个借助声学语音技术的平台上,通过持续地向学习者输入可视语图反馈(音征)和其它模式的知识,提醒他们自己的发音与目标的偏差所在,和偏差有多大,训练他们逐步调整发音-感知匹配,直到完全掌握目标语的发音与感知。
在国外,有很多商业软件用在语音教学。这些软件大多问世于交际教学法和语言测试风行的上世纪七、八十年代,比如CALL(Computer Assisted Language Learning)上世纪七十年代便投入使用,数十年来,一直朝实现交际功能最大化的方向发展,很适合提高学生口语表达的流利性和得体性。上世纪九十年代有了SpeechViewer(Stenson 1992),该训练系统依然侧重超音段和口语整体表现的提高。同时期还有SPELL(Steven,Rooney,Laver&Jack 1993)。欧洲则流行Tell me More等软件(沙国泉(2005)有较全面的介绍)。值得注意的是,绝大多数软件,如 CALL、SpeechViewer,都只用于超音段训练,适合音段训练的软件非常少,如SPELL。
但即便SPELL也只采用波形图(waveform)对照而不是声谱语图(spectrogram)对照来提供可视反馈,从声学角度讲这是不科学的,因为波形图能展示的声学信息远没有声谱展示的重要和细致。下图是SPELL提供的本族语者发的标准的/ɻ/的波形图(上)和使用者(学生)发的/ɻ/的波形图(下)的对比(注意白色的波形地带)。
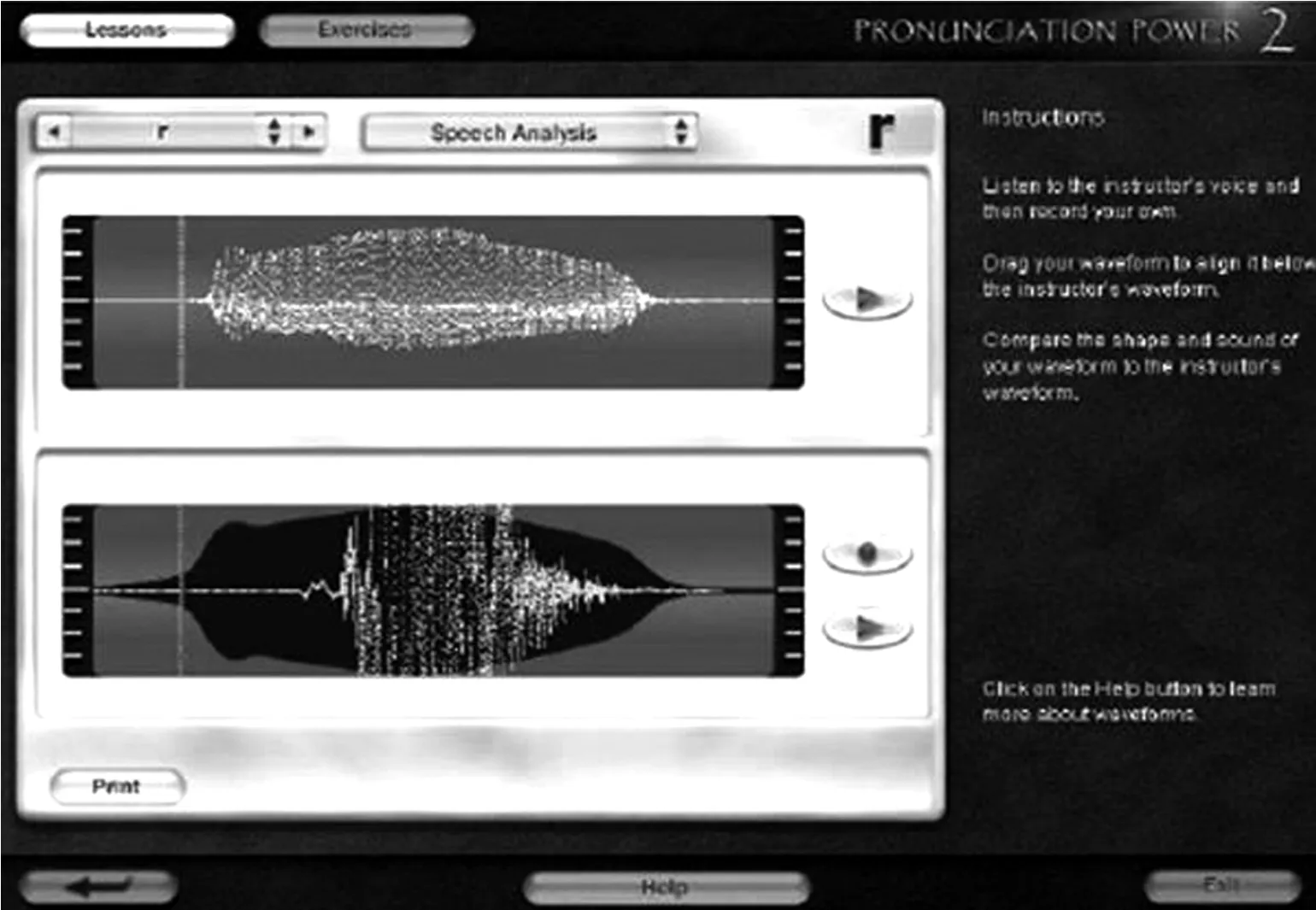
图2 SPELL的波形图反馈示例
CALL、SpeechViewer、SPELL 均因价格和知识产权等问题没有在中国普及。现在在中国普及的是最早创建于美国AT&T贝尔实验室现已无独立产权的ASR(自动语音识别)技术。目前国内很多高校的语音教室用的多媒体教学光盘中就有ASR技术,其主要功能是提供语音跟读训练和语音测试。国内还有金晓达(2004)、郑艳群(2006)等用电脑呈现元辅音发音舌位图来帮助学生理解正确发音过程的尝试。
近十年来欧美多媒体语音教学出现了有意思的趋势,教学软件不再由大公司针对集团客户研发,而是由个体研发,越来越方便获得和使用,越来越个性化。由两位荷兰语音学家研发的Praat是世界上最著名的免费语音分析和编辑软件,Moodle是一个用于制作网络课程或网站的开源软件包,不仅免费而且源码都对社会开放。国外某些发烧友将Praat和Moodle的某些功能结合,编创个性化语音学习程序,如Wilson(2008)用来训练超音段和Brett(2004)帮助训练元音发音的软件。此外还有音节圈(syllable circle)程序,帮助人们学习英语重音和语调(Whipple,Cullen,Gardiner&Savage 2015)。如图3所示,圈的大小表示词重音和语调重音的强弱,提醒学习者自己的偏误,非常醒目。
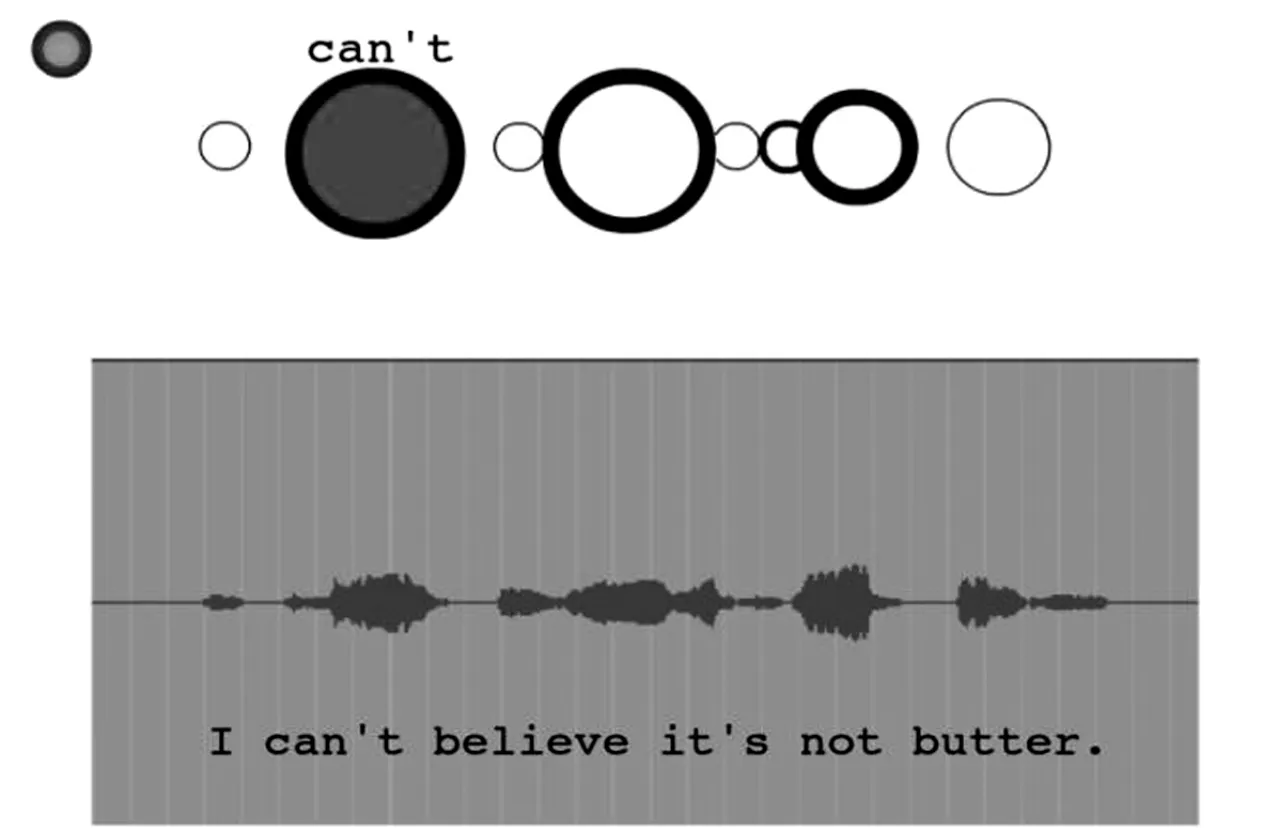
图3 音节圈程序示意图
2.2 我国多媒体语音教学的问题与反思
总的来说,国内外语音教学中的多媒体技术都关注超音段训练而相对忽略音段训练。此外我国的多媒体语音教学还有些自己的问题。国外比如美国没有像我国本世纪初那样举国规模地推广多媒体教学(包括语言、语音教学),学界“一窝蜂”地研究多媒体教学,“一边倒”地批判传统的非多媒体教学。可现状却是:(1)巨额投入并未换来学生口语水平的显著提高,相比阅读、词汇等,口语仍然是很多学生的“能力短板”。(2)研究方面,方案介绍和反思等描述性文献多(沙国泉2005;孟臻2006),实证研究少,多媒体语音教学实证研究更少,发表在外语类核心刊物的文章数量为0,也就是说多媒体于语音教学的优势其实至今未得到证实。近几年热潮退却,多媒体教学研究的文章数量也锐减,在多媒体已经成了默认的教学模式后,它如何更好地服务教学反而不再被关心和思考。
本文不否认多媒体在知识传授中的优势,这已被Myers等心理学家、教育学家反复证明。但语言是特殊的知识,语音又是特殊的语言知识。怎么个特殊法?我们还是要回到语音知识本身,回到语音习得和反馈的性质与特点。本文认为,国内外多媒体教学领域对语音知识的特殊性认识不够;无论是商业或个人开发的学习软件,还是教学实践与研究都没有准确地定义和区分可视反馈。可视反馈是一个复合概念,因为语音知识是复合的,由很多知识或能力版块组成。首先可以分成音段和超音段,超音段中又分重音、语调和声调;除了音段音系,还有语调音系、节律音系和音系与句法、形态的交互。这些版块彼此独立,又有联系,都是语音学习的任务。不同的学习任务、对象要求不同的可视反馈和不同的多媒体策略、方法,切不可笼统定义语音知识和所需之反馈,也不存在一种语音教学模式能服务好语音学习的所有方面或任务。
下面从重铸反馈的角度继续论证二语语音习得的确需要有效、针对性的视觉反馈,语音习得与多媒体是兼容的。但更应看到,多媒体有所为有所不为,有些语音知识的发展必须“交还”给传统语音教学法,不可全盘否定传统。
3.重铸视角下的多媒体语音教学:认识与反思
3.1 隐性学习和显性学习
前面说过,语音知识是复杂的、多元的,语音学习亦然,不同性质语音知识对教学方式和反馈类型的需求不一样。从大体上划分,语音学习包括两种性质完全不同的过程——隐性学习和显性学习。反馈不起作用的语音学习是物理过程(动物也有),是大脑神经网络物理自组性的展现。这时的语音参数和意义、交际没有联系,不在语言学范畴之列。这是纯粹的隐性(implicit)学习。反馈很重要的语音学习明显与意义有关,与语素区分有关,属于显性(explicit)学习;语调与语用和交际意义密切相关,因此语调学习也基本是显性的。显性学习中提醒(反馈)和注意的凸显性、频度和发生时间是非常重要的。但是,隐性和显性学习不可分割,前者是后者的基础,后者为前者提供自上而下的指导和约束。纯隐性学习获得的知识被称为隐性知识(implicit knowledge),又称程序性(procedural)知识,和意义有关的语音学习获得的除了音位概念,其它的也是隐性知识。总之,大部分语音(发音和感知)知识是隐性的,源自各器官(神经)的反复交互、磨合,最终在感知—发音回路形成固定格式,这就是程序化(proceduralization)。
与隐性知识对立的是显性知识,又称陈述性(declarative)知识。涉及音位的元语言知识是显性的,比如教师直接陈述/i/和/I/在英语是两个不同的音位,在汉语不是。语法和词汇知识基本上是显性的。隐、显知识的区别在于隐性知识来自艰苦的训练后的程序化,即常言说的孰能生巧,显性知识是被清晰表述的知识,不涉及复杂互动或训练。隐性知识不容易磨蚀,可长期滞留于认知,显性知识则容易磨蚀。
下节讨论为什么“重铸”对更深入认识、反思多媒体语音教学有重要意义。
3.2 隐性重铸与隐性语音知识的发展
近三十年来发育心理学(developmental psychology)和行为—构建主义语言发育(习得)观的发展推动了交际教学法的兴盛,现在“流行”的基于任务或项目、基于内容的教学都是交际教学的变种或新形式。交际教学强调意义与功能,关注在连贯语言交际(包括教学)过程中学习者的整体语言能力的发育,主张一语和二语习得没有本质上的不同,认为语言形式的知识的习得是整体语言能力发育的副产品。在这样的大背景下,滥觞于一语习得领域的“重铸”(recast)当仁不让地成为三十余年二语和外语教学研究的“主角”。
重铸是指对学习者产出的话语的重述,在保留原话意义的同时纠正其中错误,是一种隐性反馈(Lyster 1998;Ellis 2007)。与显性反馈不同,重铸并不直接指出对方语句中的错误,决不打断行进中的意义交流,更能帮助学习者将自己的语言与他人的重新表述进行对比并注意到新的语言形式,注意到自身中介语系统与目标语间的差异。Oliver&Mackey(2003)强调重铸式纠错属于隐性的否定反馈,它只重新表述学习者言语,而不提供明确的元语言信息。
多媒体在三个方面能有力地提升重铸。
1)在多媒体背景下,重铸式纠错作为对学习者含错误形式的言语的重述,也可以是多模式的,包括视觉的重述(语图)。
2)Loewen&Philp(2006)、Egi(2007)等提出重铸可以变得呈显甚至呈显著性,主要途径有(a)与其他纠错方式并用;(b)强调被修正的部分;(c)增加使用频度等。在这三点上多媒体有天然优势,计算机可以同时提供多种纠错,可以反复纠错而不会疲劳。
3)最重要的是,重铸是隐性反馈,语音知识是隐性知识,两者高度兼容,隐性反馈最适合隐性知识发展。
很多重铸研究都发现重铸和其它反馈相比作用甚微(Lyster 1998;Ammar&Spada 2006;Ellis 2007;Sauro 2007等),甚至一些研究反而显示,相比重铸,元语言解释则具有明显优势(Ellis,Loewen&Erlam 2006;Sauro 2007)。这些研究都是语法词汇习得研究,语法词汇知识基本都属于显性知识,这样,元语言反馈的优势和重要性就很好理解了。更有趣的是,近年重铸研究进军二语语音习得后,很多实证研究显示,重铸对语音习得的推促作用显著(Saito&Wu 2014;Saito 2015;Lee&Lyster 2015等)。这说明重铸效果与习得的知识类型直接相关。语音这样的隐性知识的习得中,隐性反馈作用最大,重铸效果好,而语法词汇等显性知识的习得则更依赖显性的元语言反馈和其中被清晰陈述的信息或知识结构。
阐明重铸对语音学习帮助最大之后,再来看看重铸和多媒体的关系。提倡重铸的教学中教师是绝对主导。很多时候,教学成功全靠教师及时以最适当的形式提供重铸,这时课堂设计远比媒体技术重要,所以把语音学习全部交给多媒体是不明智的,多媒体手段必须有针对性地纳入课堂设计,甚至要“甘当配角”。
3.3 重铸角度下的音段学习——向传统方法的回归
从任务及内容上划分,外(二)语语音学习可以分为超音段和音段的学习。多媒体对超音段学习有较大的帮助,这是前面介绍的各种学习软件能不同程度的成功的基础。但音段学习能否或如何在多媒体模式中确保成功?须回到语音知识发展阶段与性质的问题,探讨多媒体的所为与所不为,澄清语音(尤其音段)习得和多媒体的一些误区。
第一个误区是,受交际教学理论影响,语音知识长期被认为是整体性、功能性的,这使得超音段学习占据绝对优势地位,这一点上国内外一样,绝大多数学习软件都侧重超音段习得,音段习得被严重忽视。但事实上,相比语调、重音,音段的准确性更是中国学生的短板,受母语影响学生产出中很多元、辅音的分辨度偏低。学生如果音段错误都比较多,会认定自己“口语差”而不愿意主动交流,也会破坏交际。音段问题是更基础、更迫切的问题;绕开音段习得大谈超音段习得是不尊重实情,是不负责任的。
第二个误区是,多媒体提供的反馈,尤其是视觉语图反馈一定可以促进元辅音的习得,或者认为语图反馈是很适合音段学习的重铸。实际上,目前还没有找到直接支持上述观点的实证研究,查到的仅有的两篇“计算机辅助有益于音段习得”的文献是 Wang&Munro(2004)和 Neri,Cucchiarini&Strik(2006),都与可视反馈无关。国内还没看到设计和数据都很严谨的此类研究。所以目前尚无证据说明多媒体教学对音段习得有利。笔者认为,音段准确性的训练多媒体是无能为力的,应该回归传统方法,如跟读、复读、朗诵和教师的示范与元语言反馈。
不是所有的语音知识发育都与意义或交际有关,(二语)音段知识是大脑网络中感知元和发音元的激活与连接,完全在封闭的感知—动力回路进行,意义或外来提醒都不可能介入这个“封闭圈”。通俗点说就是,学习者只能内省地提醒自己,刚发的音与本族语的有差距,该如何调整音姿。所以,隐性阶段的语音学习的反馈不可能是视觉的,只能是声学和体感的(somatic,感知舌位等)。即便到了显性学习阶段,有关音段准确性的语图反馈也只是有提醒作用,并不能直接充当发给发音器官的动作指令,学习还是要进入封闭回路。所以音段学习的本质是程序化,是反复的发音感知训练;音段训练和竞技体育训练如出一辙,都属于肌肉训练,讲究孰能生巧(申雅娟2003)。比如,篮球运动员通过千万次的重复一套动作,使各肌肉的协调自动化,能熟练地完成突破、投篮等。语音学习者也一样,在通过重复运行感知—动力回路,协调好各发音肌肉,最终漂亮地发音。包括多媒体在内的各种教学设计都不过是让动作的重复不那么枯燥而已,并不改变语音学习的本质。
综上所述,笔者认为音段学习才是多媒体语音教学亟待优化的方面,音段能力是超音段能力的基石,也是外语交际的基础,音段不准确、音段间衔接不自然则遑论超音段表现的准确与流畅。另外学生对自身音段能力的欠缺远比对超音段能力不足敏感,由此造成的负面心理因素如自卑、焦虑、完美主义等要比超音段问题引发的多得多。音段的学习更依赖内省、隐性的发音—感知连接,更依赖肌肉训练,视觉或其它模态的反馈在这方面的作用仍不明朗,从发音语音学、儿童语音发育的角度看,作用应该很小。相反,“传统”教学法体现出独特优势,教师的示范和元语言反馈的作用应在教学设计中给予充分考虑。
4.结语
本文讨论了重铸、多媒体教学和二语语音学习相结合的兼容性、可行性及问题,思考了多媒体语音教学现状和发展或改进方向。本文首先介绍多媒体教学、语音习得和重铸各自的认知和行为特点,发现在重铸条件下多媒体语音教学有所为也有所不为,提出多媒体语音教学应走出不尊重语音能力发展规律和忽视传统教学的误区。具体而言,超音段学习与多媒体的结合被证实是有效的,多媒体提供的视觉反馈属于隐性重铸,对隐性的语音知识的发展有直接的推动,应大力提倡。但音段学习则属于在封闭的感知—动力回路进行的内省、隐性的学习,多媒体提供的重铸极其有限,所以本文主张音段准确性的训练应“回归”肌肉训练和反复输入-产出的传统。在语音教学中,要充分考虑人脑发展语音知识的特点,结合多媒体和重铸反馈的优势,针对具体的语音教学任务来制定最合适的教学方案。
Ammar,A.&Spada,N.2006.One size fits all?Recasts,prompts and L2 learning[J].Studies in Second Language(28):543-574.
Brett,D.2004.Computer generated feedback on vowel production by learners of English as a second language[J].ReCALL(16):103-113.
Best,C.T.A 1995.irect realist view of cross-language speech per ception[A].Strange,W.(Ed.),Speech Perception and Linguistic Experience:Issues in cross Language Research.Timonium,MD:York Press.Catford:171-204.
Jones,L.C.&Plass.J.2002.Multimedia learning second languageacquisition[A].The Cambridge Handbook of Multimedia Learning[C].Cambridge:Cambridge University Press.
Egi,T.2007.Interpreting recasts as linguistic evidence[J].Studies in Second Language Acquisition(29):511-537.
Ellis,R.2007.The differential effects of corrective feedback on two different grammatical structures[A].Mackey,A.(ed.).Conversational Interaction in Second Language Acquisition[C].Oxford:Oxford University Press.
Ellis,R.,Loewen,S.&Erlam,R.2006.Implicit and explicit corrective feedback and the acquisition of L2 grammar[J].Studiesin Second Language Acquisition(28):339-368.
Kuhl,P.K.1991.Human adults and human infants show a perceptual magnet effect for the prototypes of speech categories,monkeys do not[J].Perception and Psychophysics(50):93-107.
Lee,A.H.&Lyster,R.2015.The effects of corrective feedback on instructed L2 speech perception[J].Studies in Second Language Acquisition(42):1-30.
Loewen,S.&Philp,J.2006.Recasts in the adult English L2 classroom:Characteristics,explicitness,and effectiveness[J].The Modern Language Journal(90):536-556.
Lyster,R.1998.Recasts,repetition,and ambiguity in L2 classroom discourse[J].Studies in Second Language Acquisition(20):51-81.
Maye,J.,Werkerb,J.F.&Gerken,L.A.2002.Infant sensitivity to distributional information can affect phonetic discrimination[J].Cognition(82):B101-B111
Mayer,R.E.Cognitive theory of multi-media learning[A].The Cambridge Handbook of Multimedia Learning[C].New York:Cambridge Press.2005.
Neri,A.,Cucchiarini,C.,&Strik,H.2006.ASR-based corrective feedback on pronunciation:Does it really work?[P].Proceedings of ICSLP 2006,Pittsburgh PA,USA,1982-1985.
Oliver,R.&Mackey,A.2003.Interactional context and feedback in child ESL classrooms[J].Modern Language Journal(87):519-533.
Saito,K.,&Wu,X.2014.Communicative focus on form and L2 suprasegmental learning:Teaching Cantonese learners to perceive Mandarin tones[J].Studies in Second Language Acquisition(36):1-34.
Saito,K.2015.Communicative focus on second language phonetic form:Teaching Japanese learners to perceive and produce English/ɻ/without explicit instruction[J].Applied Psycholinguistics(36):377-409.
Sauro,S.2007.A comparative study of recasts and metalinguistic feedback through computer mediated communication on the development of L2 knowledge and production accuracy[D].Philadelphia:University of Pennsylvania.
Stenson,N.1992.The effectiveness of computer-assisted pronunciation training[J].CALICOJournal(9):1-19.
Steven,H.,Rooney.E.Laver,&Jack,M.1993.SPELL:An automated system for computer-aided pronunciation teaching[A].Speech Communication-Speech Science and Technology:A Selection from the Papers Presented at the Fourth International Conference in Speech Science and Technology(13):463-473.
Swain,M.&Lapkin,S.1995.Problems in output and the cognitive processes they generate:A step towards second language learning[J].Applied Linguistics(16):371-391.
Wang,X.,&Munro,M.2004.Computer-based training for learning English vowel contrasts[J].System(32):539-552.
Whipple,J.,Cullen,C.,Gardiner,K.&T.Savage.2015.Syllable circles for pronunciation learning and teaching[J].English Language Teaching Journal(ELT)(69):151-164.
Wilson,I.2008.Using Praat and Moodle for teaching segmental and suprasegmental pronunciation[A].Toshiko Koyama.Proceedings of the 3rd International WorldCALL Conference:Using Technologies for Language Learning[C].Japan:T h e Japanese Association for Language Education and Technology:112-115.
金晓达,2004,《汉语正音课》与语音实验 [A],《数字化对外汉语教学理论与方法研究》[C]。北京:清华大学出版社:305-308。
孟臻,2006,反思多媒体外语教学 [J],《外语界》(6):9-15。
沙国泉,2005,计算机辅助语音训练与测试:问题与思考[J],《外语电化教学》(4):67-71。
申雅娟,2003,浅析The Jingles语音教学法对中国高校传统语音教学的突破 [J],《西南民族大学学报》(人文社科版)(10):374-377。
郑艳群,2006,《对外汉语计算机辅助教学实践研究》[M]。北京:商务出版社。
H319
A
2095-9648(2017)04-0071-07
❋本文系湖南省教育厅高校教学改革课题《基于重铸的大学英语语音多媒体教学实践研究》(项目号:湘教通[2014]247)的部分成果。
(朱 敏:中南林业科技大学外国语学院讲师)
2017-09-28
通讯地址:410004湖南省长沙市中南林业科技大学外国语学院
