结合动态代价和协同标注的网络异常检测*
2017-11-16杜红乐
张 燕,杜红乐
商洛学院 数学与计算机应用学院,陕西 商洛 726000
结合动态代价和协同标注的网络异常检测*
张 燕,杜红乐+
商洛学院 数学与计算机应用学院,陕西 商洛 726000
针对网络行为数据中中类样本不均衡、样本标注代价大的问题,结合委员会投票和动态代价思想提出一种针对不均衡数据集的分类算法DC-TSVM(dynamic cost and cooperative labeling transductive support vector machine)。该方法在构建每个子分类器时利用类密度之间的关系动态计算各个类的错分代价,减少分类超平面的偏移,然后利用投票熵选择标注准确性较高的样本进行投票标注,减少错误的累积和传递,提高标注准确率,增强最后分类器的泛化性能。KDDCUP99数据集上的实验结果表明该方法对未知攻击有较高的检测准确率。
支持向量机;网络异常检测;投票委员会;协同标注
1 引言
网络运行过程中产生大量反映用户行为的数据,如何利用这些数据提高系统的安全性受到广泛关注,网络入侵检测利用用户的行为数据识别用户行为是否存在威胁,是网络安全体系中的一个重要组成部分。在日益复杂的网络环境中,攻击方法变得多样化、复杂化,新攻击方法不断涌现,异常检测能够检测未知类型的攻击方法越来越受到关注,也是网络安全领域的研究热点。
基于数据的网络异常检测方法大多采用机器学习和数据挖掘,将检测问题转换为分类问题进行求解,如基于概率统计的方法[1]、基于支持向量机方法[2-3]、基于神经网络方法等。这些方法都依赖于充分的有标记的训练样本集,然而,在实际应用中,收集入侵行为数据并进行标注,需要花费很大的代价。另外,新的入侵手段不断涌现,很难及时收集并标注对应的行为数据,迁移学习为该类问题提供了一种解决途径。直推式学习[4-10]是一种重要的迁移学习方法,同时利用有标签样本和无标签样本进行学习,把无标签样本中的空间分布信息转移到最终的分类器中,则能大幅降低学习成本,提高分类器泛化性能。
由于支持向量机自身的优点,直推式支持向量机[5](transductive support vector machine,TSVM)也备受关注。在TSVM中,若样本标注错误将导致错误的传递,虽然样本标记错误有可能会被重置(也可能不被重置),但至少会影响标记错误的下一次迭代生成的分类器。TSVM每次迭代从未标注样本中选取“重要”的未标记样本进行暂时标记,如何计算未标注样本的“重要”程度是这类改进的切入点。文献[11]利用聚类方法增加每次迭代标注样本的数量,减少迭代次数;文献[12]利用半监督聚类对未标记样本进行预分类,然后再进行迭代,减少迭代次数。
以上算法都是基于每次迭代中分类器的分类准确率较高的前提,然而在不均衡数据集下,分类超平面会向少数类方向偏移[13-14],因此很多学者采用代价敏感支持向量机[15],对各个类采用不同的错分代价来修正分类超平面。然而,错分代价需要依据经验给出,不同的数据集很难给出准确的错分代价。数据集不均衡实质是密度的不均衡,因此依据各类密度之间的关系,在每次迭代中计算各个类的错分代价,能够准确地描述类之间的不均衡程度,从而减少分类超平面的偏移,提高样本标注的准确率。另外,网络数据集规模较大,把数据集划分为多个子集,构建多个子分类器,可以大大减少每次迭代中训练的时间,同时利用多个分类器的投票结果对样本进行标注,可以提高准确率,减少样本重置次数,进一步提高算法速度及最终分类器的性能。
基于以上分析,针对类样本不均衡,样本标注代价昂贵,数据集规模大的问题,本文把投票机制和密度均衡引入到直推式支持向量机中,提出一种动态代价和协同标注的直推式支持向量机算法(dynamic cost and cooperative labeling TSVM,DC-TSVM)。该算法依据有标记样本构建多个分类器,利用投票结果对无标签样本进行标注,提高样本标注的准确率;在迭代过程中,利用类样本密度之间的关系计算错分代价,减少分类超平面的偏移,提高标注准确率;最后把该算法应用到网络异常检测中,在KDDCUP99数据集上的仿真实验结果表明该算法在不均衡数据集下的有效性。
2 代价敏感支持向量机
在不均衡数据集下分类超平面会向少数类样本侧移动,这是因为两类样本的错分代价相同,即两类采用相同的惩罚因子,支持向量机为使分类间隔尽可能得大,同时分类错误的代价尽可能得小,分类超平面会向少数类侧(样本密度小的区域)偏移,即对多数类的过学习和对少数类的欠学习。因此,文献[15]采用不同的惩罚因子,为体现对少数类的重视,对少数类使用较大的惩罚因子,而对多数类使用较小的惩罚因子,但在实际应用中惩罚因子很难计算。数据不均衡问题本质在于类样本密度的不均衡,本文从样本的密度入手,利用类样本密度确定惩罚因子,减少分类超平面的偏移,从而提高分类器的分类性能。
2.1 核空间中类样本密度
支持向量机最终构建的分类超平面是特征空间中的,因此特征空间中类密度能更准确反映样本的分布情况。下面在特征空间中给出几个相关概念的定义。
定义1设样本x、y,则两样本之间的距离d(x,y)为:

其中x、y为多维向量,||x||为二阶范数。
若线性不可分,支持向量机将使用核函数将样本从输入空间映射到某一特征空间中,使得样本在该特征空间中线性可分。设映射函数为:ϕ∶Rk↦F,核函数为K(x,y)=<ϕ(x),ϕ(y)>,则在特征空间中两个样本之间的距离为:

假设核函数采用RBF,即K(x,y)=exp(-g||x-y||2),g为一待定的常数,且g值会影响最终结果,g多取值为维数的倒数,由式(2)可得:
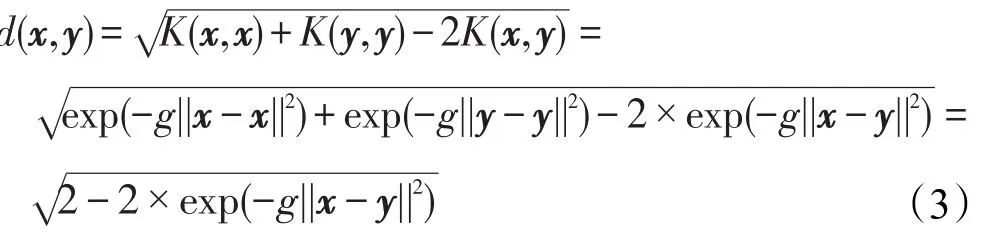
经过划分后的每个类可以看作是一个超球,类中心及类密度定义如下。
定义2(类中心)数据集划分后的第i个类Gi,设包含ni个样本,则类中心Ci为:
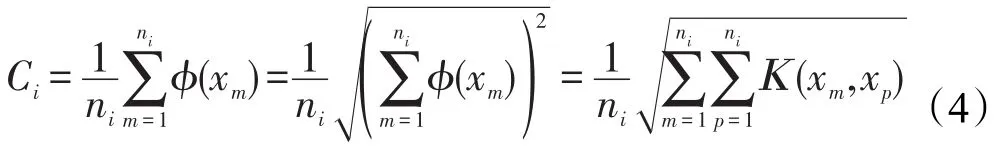
若采用RBF核函数,则第i个类的中心Ci为:
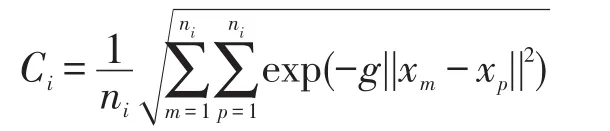
由此可得类内样本xj到类中心Ci的距离为:
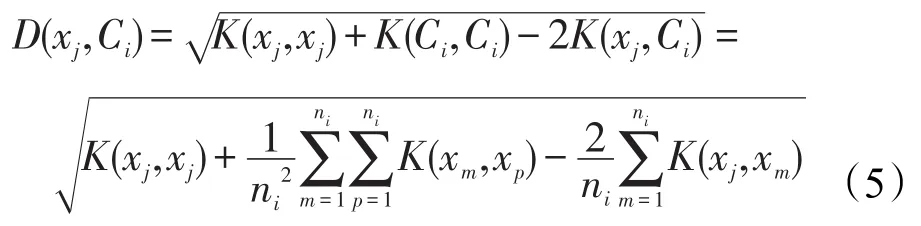
为了对多数类的样本进行密度均衡化处理,需要计算类密度。下面先给出在核空间下类样本空间大小的描述,类空间大小多用样本到类中心的最大值作为超球体的半径来描述,如果存在噪声数据,则导致半径值偏大,因此不能准确描述类空间大小。本文采用样本到类中心距离的平均值来描述类空间大小。
定义3(类空间大小)设类Gi的样本xij表示第i个类内的第j个样本,则类Gi的空间大小Si表示为类内样本到类中心平均距离的m倍,即:
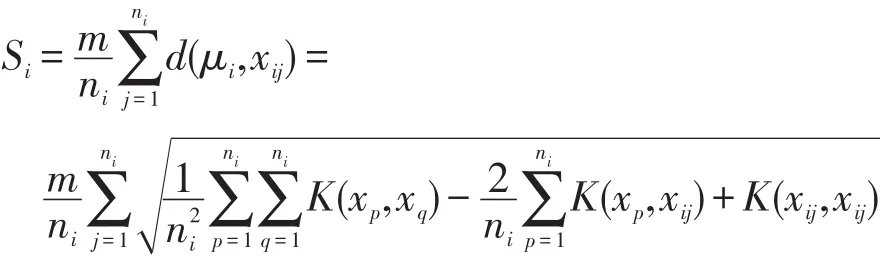
本文算法中需要计算两类样本密度的比值,因此m的取值对计算结果没有影响,为了简化计算,这里m取值为1。根据上面类空间大小的定义,给出下面类样本密度的定义。
定义4(类密度)设类Gi的样本xij表示第i个类内的第j个样本,则类密度ρi为类内样本数与类空间大小Si的比值,即:
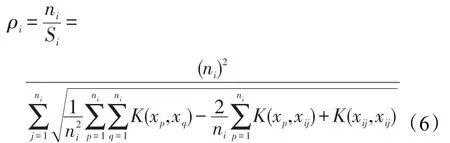
若核函数采用RBF,则类Gi的密度为:
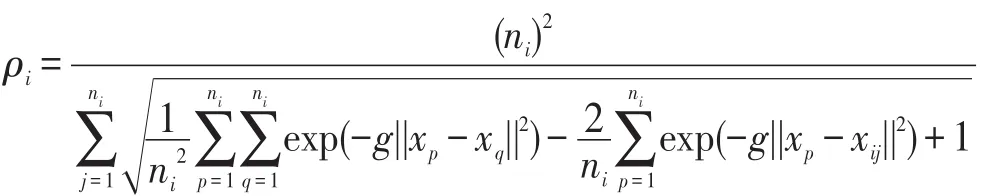
2.2 惩罚因子
分类超平面会向密度小的方向偏移,因此密度小的类应该赋予较大的惩罚因子,密度大的类赋予较小的惩罚因子,可以把惩罚因子与密度之间视作成反比的关系。对于两类问题,假设C1、C2为类的惩罚因子,即错分代价参数,ρ1、ρ2为类的密度,则惩罚因子之间的关系为:
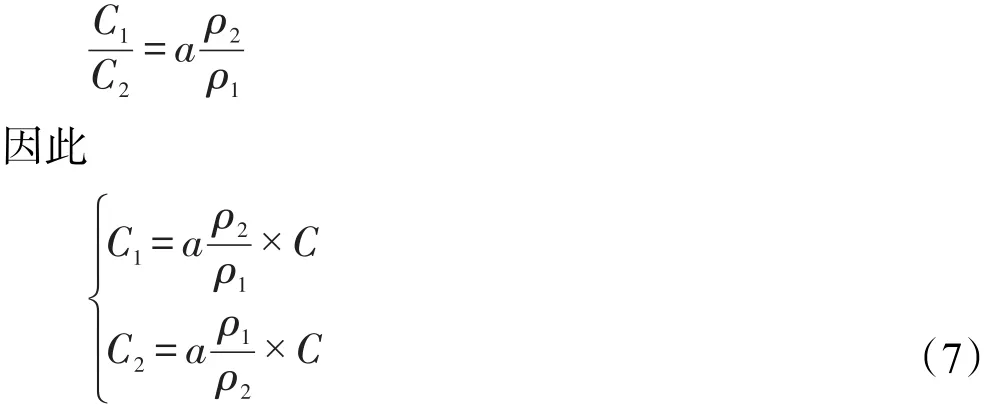
其中,a为惩罚因子调控系数;C为支持向量机算法中的惩罚因子。
3 协同标注算法
3.1 算法思想
为了进一步提高每次迭代对样本标注的准确率,通过有标签样本构建多个分类器,然后利用委员会投票算法的投票结果进行标注。投票委员会中为了描述投票结果的一致程度,熵越小表明结果越一致,即标注结果越准确。投票熵的计算可简单表示为:
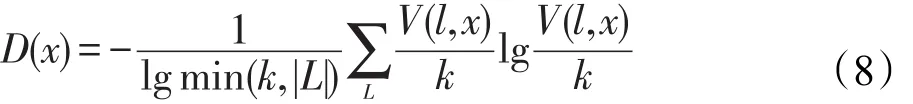
其中,D(x)表示对样本x的投票结果的差异程度,值越大表示越不一致;k表示投票成员的个数;L表示类别数;V(l,x)表示对样本x的类别l的投票数。
投票熵越大,样本包含的信息越大,越靠近分类超平面,这样的样本对分类超平面的影响也越大,一旦标记错误,不但会导致错误的传递和积累,也会影响后续样本标注类别的准确性,从而影响最终分类器的分类性能。因此每次迭代选择对分类超平面有影响的,投票熵小的样本,即选择能够改变分类超平面,且标注最可能准确的样本进行标记,而把标注准确性不高的,投票熵较大的样本等到分类器完善的时候再进行标注,使得分类超平面被逐渐地修正,获得最优的分类器。
把有标签样本集记为T,无标签样本集记为U,图1给出了协同标注算法的流程。对有标签样本集划分为多个训练集,并与无标签样本放在一起进行归一化;然后采用一定的样本打散方法,把样本集T分为m(m取奇数,如3、5、7等,文中m取值为3)个差异性较大的子集T1,T2,…,Tm作为训练集;随后分别训练得到m个初始分类器C1,C2,…,Cm,m个分类器对每个无标签样本的输出为f1i,f2i,…,fmi;接下来是对无标签样本进行标注、迭代。
3.2 算法描述
该算法结合投票委员会算法和动态错分代价思想,提出基于动态代价和协同标注的直推式支持向量机算法。该算法利用类密度之间的关系确定错分代价,减少分类超平面的偏移,然后利用投票委员会算法选择标注准确性最高的样本进行标注。该算法可以提高样本标注的准确率,减少样本重置次数。现将算法详细过程描述如下。
算法 动态代价和协同标注的直推式支持向量机算法DC-TSVM。
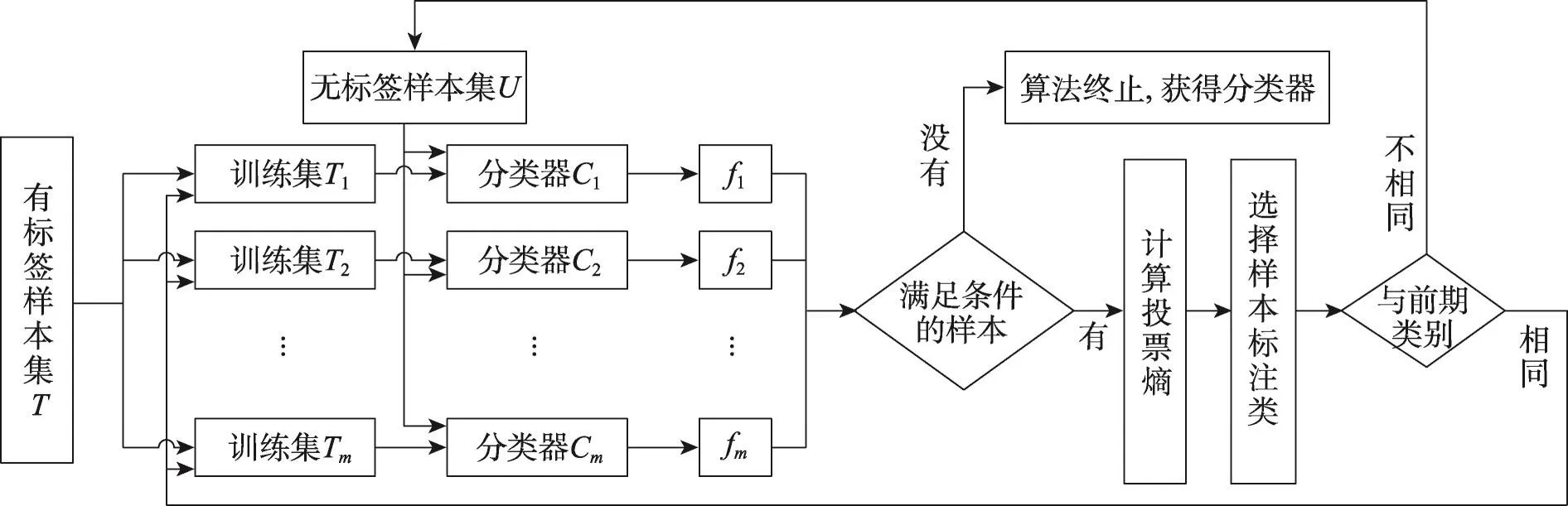
Fig.1 Cooperative labeling TSVM图1 协同标注TSVM
输入:有标签样本集T,无标签样本集U,分类器数目K。
输出:最终分类器。
步骤1把有标签样本集T按照一定的方法打散为K个子集,分别记为T1,T2,…,TK。
步骤2用支持向量机分别对K个子集进行训练,得到K个初始分类器C1,C2,…,CK。
步骤3用分类器C1,C2,…,CK分别对无标签样本集进行测试,输出每个样本的测试结果f1i,f2i,…,fKi。
步骤4任意无标签样本xi,若存在测试结果|fij|<1,则计算样本的投票熵,选择投票熵最小的若干个样本按照投票结果进行标注类别。
步骤5如果对样本xi前期已经标注,且与这次标注类别不一致,则取消标注,并且从对应训练集中删除该样本;如果类别与前期一致,但xi没有加入到相应的数据集中,若满足条件则加入;如果前期没有标注,则依据条件加入到对应的数据集中,返回步骤2。
步骤6重复上述操作,直到未标注样本集中没有满足条件的样本,算法终止。
算法的步骤2中,对增加新样本的训练子集重新训练,对无新样本增加的训练集仍然使用上轮迭代中的分类器。算法最终的分类由多个分类器共同构成,样本测试采用的决策函数为f=a1f1+a2f2+…+akfk,fi表示第i个分类器的测试结果,ai表示第i个分类器的权重,这里为了简化计算,取值都为1,即f=f1+f2+…+fk。
4 实验及数据分析
实验是在Matlab 7.11.0环境下,结合中国台湾林智仁老师的LIBSVM(a library for support vector machines)[16],主机为 Intel Core i7 2.3 GHz,4 GB 内存,操作系统为Win7的PC机上完成。
4.1 实验数据选取
KDDCUP1999数据集是关于入侵检测的标准数据集,包括训练集和测试集,其中训练集有494 022条记录,测试集有311 030条记录,训练集中包含24种攻击,在测试集有38种攻击(增加了14种攻击)。攻击包括四大类,在本实验中把所有攻击看作一类,abnormal类,即把入侵检测看作二类分类问题。
数据集中每条记录有41个属性,有数值型,也有字符型。首先对数据集进行数值化和归一化,数值化是对字符类型数据用数字进行简单的替代,归一化采用LIBSVM中的归一化工具进行处理。由于数据集规模较大,本节分别从训练集和测试集中选择部分样本进行实验。数据集包括有标记样本集(Train set)和无标记样本集(Test set),Test set在训练阶段是无标记样本集,测试的时候是作为测试集。为了说明本文算法的有效性,采用两组数据进行实验,每组数据集中训练数据300条记录,测试数据1 000条记录,并且在测试数据集中有训练数据中没有的攻击类型。详细的数据集信息如表1和表2所示。
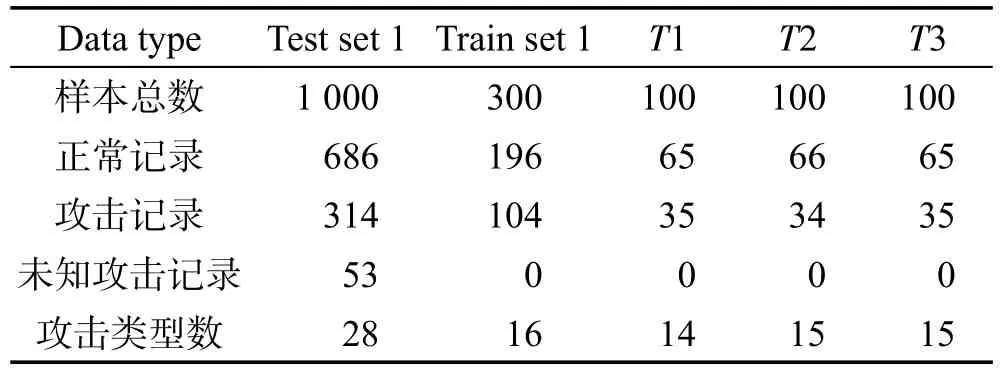
Table1 Experimental dataset 1表1 实验数据集1
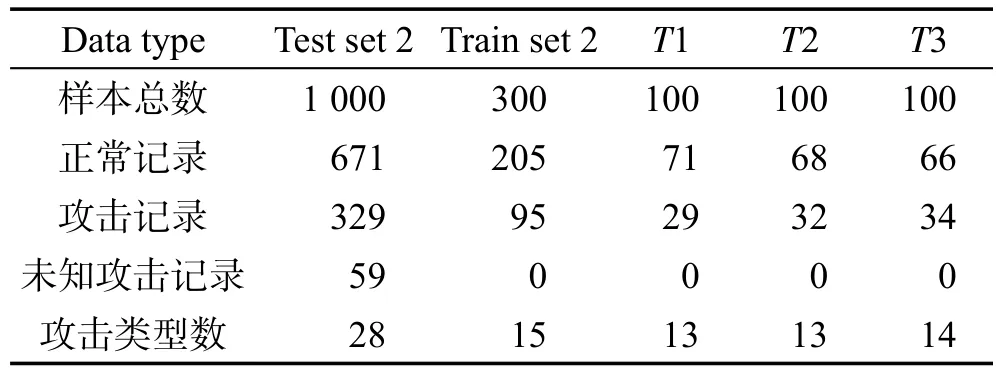
Table 2 Experimental dataset 2表2 实验数据集2
两个数据集中两类样本数量不均衡,训练集和测试集中两类样本数量约为2∶1。实验中用本文的计算密度的方法,数据集1在特征空间中两类的密度之比为1.8∶1和2.1∶1,数据集2在特征空间中两类的密度之比为1.9∶1和2.29∶1,也是不均衡的。
4.2 实验结果及分析
准确率反映的是分类器对整体的分类性能,而对于不均衡数据集下,更多关注的是少数类的分类准确率,仅仅用准确率就不能很好地描述分类器的性能。这里采用文献[13]中的性能评价指标,Fv综合考虑少数类样本的准确率和查准率,能够更准确地反映对少数类样本的分类性能;而Gm综合考虑多数类和少数类样本的分类准确率,能够衡量分类器的整体分类性能。
本实验中把训练数据集分为3个,通过训练得到3个分类器,也就是投票委员会算法中k取值为3,3个训练集中各100条数据,正常数据和攻击数据数量尽可能平均。对3种算法SVM(support vector machine)、PTSVM(progressive transductive support vector machine)[5]和DC-TSVM进行结果比较,SVM算法的实验结果是依据训练集进行归纳学习后对测试集测试的结果,PTSVM算法是采用成对标注法进行直推式学习,DC-TSVM算法是本文提出的算法。
由表3可以看出,本文算法的训练时间明显缩短,支持向量机的时间复杂度在一般情况下可以表示为O(Nsv3+l×Nsv2+d×Nsv)(具体情况有所区别)。其中d是维数,Nsv是支持向量数,l是样本数。可见SVM的训练时间由维数、训练样本数及支持向量数共同决定。而本文算法把训练集划分为多个不相交的子集,因此每个子分类器的训练样本数量及支持向量数量都会明显减少,由于a3+b3+c3<(a+b+c)3、l(a2+b2+c2)<l(a+b+c)2,从而每次迭代的训练时间会大大减少,划分的子集越多速度提高得越多,但是若划分子集过多会导致每个分类器由于训练数据集不足导致分类器性能不佳(本文采用的实验数据集,如果划分为11个子集,则训练时间有明显增多,因为分类准确度下降,导致迭代次数增加),子集的数量可以根据训练数据集的规模大小来确定,规模较小子集数少,这里采用了折衷的方法,划分为3个子集。另外,委员会投票可以提高样本标注的准确度,可以减少样本重置次数,进而减少迭代次数,可以提高训练速度。
表3给出了总体分类、正常行为分类、攻击行为分类、已有攻击分类、未知攻击的实验结果,表4给出了查准率的实验结果。SVM算法结果是依据类密度计算两类的错分代价,然后对300个样本继续训练,得到分类器对1 000个测试样本进行测试的结果,由于未能学到新攻击类型数据的空间信息,导致对未知攻击的分类准确率较低(平均27.15%)。PTSVM算法是用成对标注的直推式支持向量机算法,该算法的前提是两类样本数量相当,而实际的测试集中两类样本不均衡,因此分类准确率仍不理想,但学习了测试样本及未知攻击类型的空间分布信息,因此分类准确率有了明显的提升。DC-TSVM算法是利用密度计算类的错分惩罚因子,减少分类超平面的偏移,提高标注准确率,同时学习了测试集中空间分布信息,因此对分类准确率及未知攻击的分类准确率都有了明显的提高。
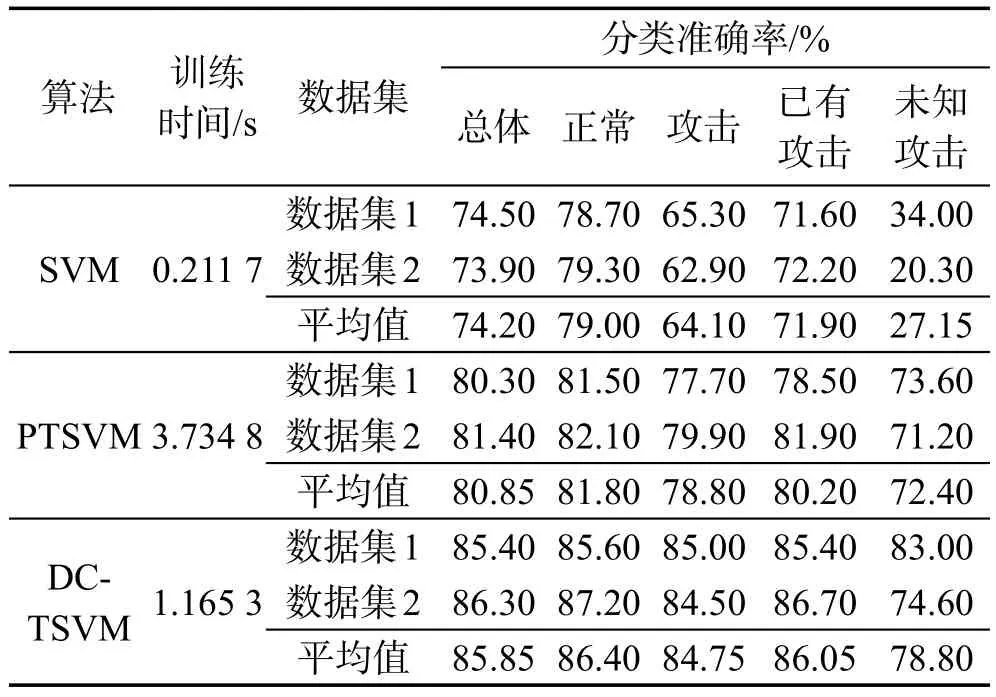
Table 3 Accuracy comparison表3准确率对比
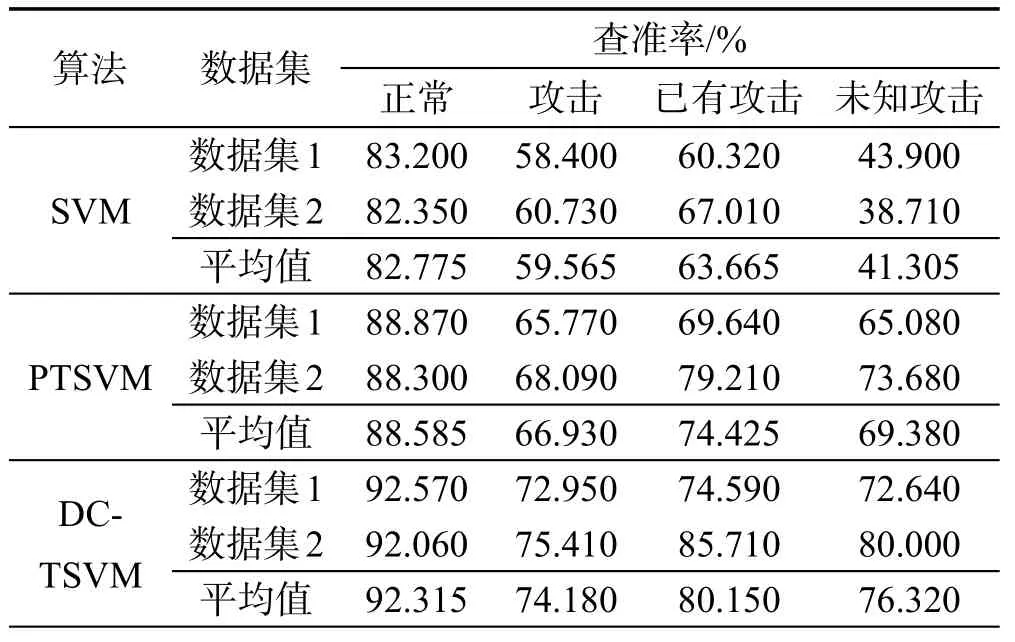
Table 4 Precision comparison表4 查准率对比
图2、图3、图4和表5分别给出了查全率、查准率以及Fv和Gm的实验结果,可以看到本文算法性能有所提高,这是因为本文算法中采用动态代价减少错误的传递和累积,提高每个子分类器的分类性能,利用协同标注提高每次迭代中样本标注的准确度,提高最终分类器的分类性能。
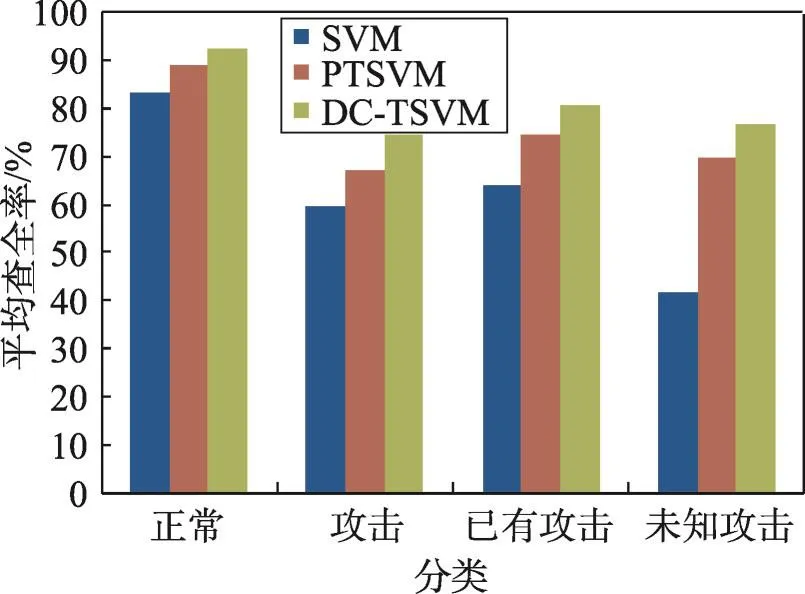
Fig.2 Average recall comparison图2 平均查全率对比
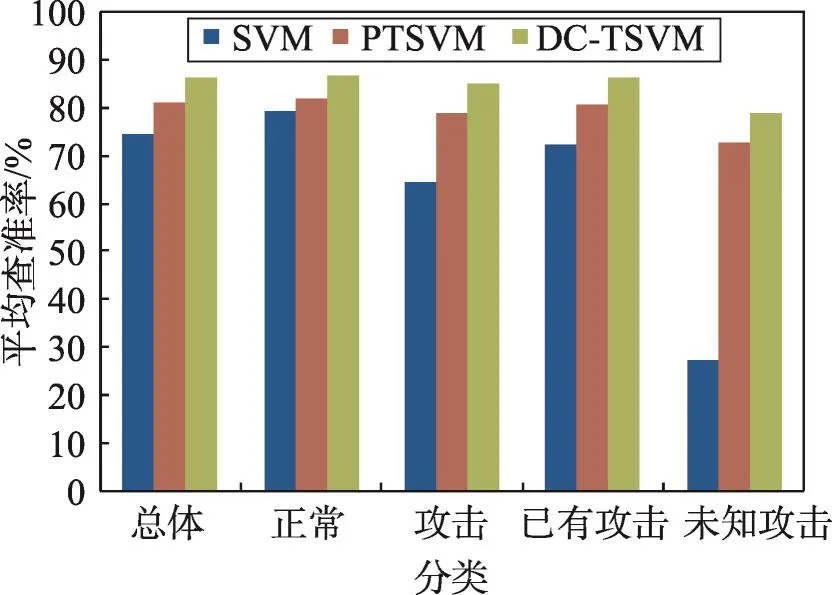
Fig.3 Average precision comparison图3 平均查准率对比
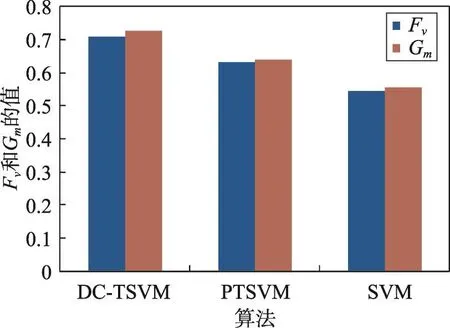
Fig.4 Average Fvand Gmcomparison图4 平均Fv和Gm值对比
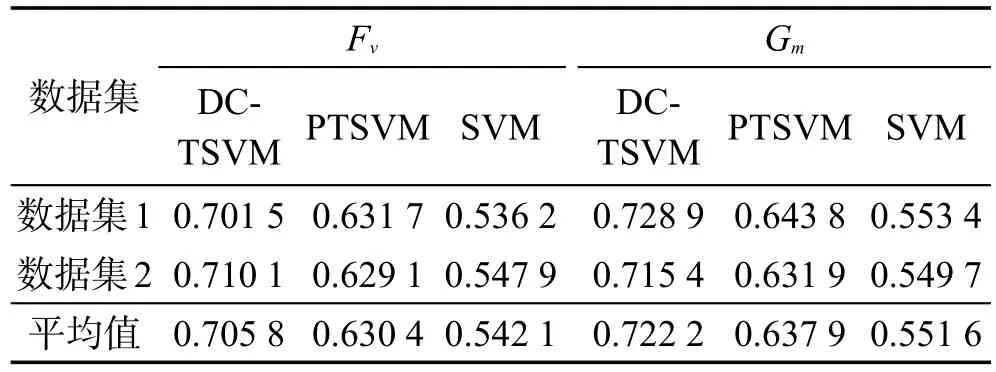
Table 5 Fvand Gmcomparison表5 Fv和Gm对比
5 结束语
针对数据不均衡进行标注的困难,结合投票委员会思想和动态代价思想提出了DC-TSVM算法,最后在KDDCUP99数据集下进行实验,实验结果表明算法的有效性,能够提高未知攻击类型的检测准确率。但是算法在大规模数据集下的收敛速度仍然较慢,如何提高速度将是下阶段的主要工作。
[1]Li Yuchong,Luo Xingguo,Qian Yekui,et al.RMPCM:network-wide anomaly detection method based on robust multivariate probabilistic calibration model[J].Journal on Communications,2015,36(11):201-212.
[2]Li Yinhui,Xia Jingbo,Zhang Silan,et al.An efficient intrusion detection system based on support vector machines and gradually feature removal method[J].Expert Systems withApplications,2012,39(1):424-430.
[3]Wu Xiaonian,Peng Xiaojin,Yang Yuyang,et al.Two-level feature selection method based on SVM for intrusion detection[J].Journal on Communications,2015,36(4):19-26.
[4]Zhuang Fuzhen,Luo Ping,He Qing,et al.Survey on transfer learning research[J].Journal of Software,2015,26(1):26-39.
[5]Chen Yisong,Wang Guoping,Dong Shihai.Progressive transductive inference algorithm based on support vector machine[J].Journal of Software,2003,14(3):451-460.
[6]Zhang Xin,He Ben,Luo Tiejian,et al.Performance analysis of clustering-based transductive learning[J].Journal of Software,2014,25(12):2865-2876.
[7]Yang Liu,Jing Liping,Yu Jian.Heterogeneous transductive transfer learning algorithm[J].Journal of Software,2015,26(11):2762-2780.
[8]Wu Qingyao,Ng M K,Ye Yunming.Cotransfer learning using coupled Markov chains with restart[J].IEEE Intelligent Systems,2014,29(4):26-33.
[9]Yang Liu,Jing Liping,Yu Jian.Heterogeneous co-transfer spectral clustering[C]//LNCS 8818:Proceedings of the 9th International Conference on Rough Sets and Knowledge Technology,Shanghai,Oct 24-26,2014.Berlin,Heidelberg:Springer,2014:352-363.
[10]Li Wen,Duan Lixin,Xu Dong,et al.Learning with augmented features for supervised and semi-supervised heterogeneous domain adaptation[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2014,36(6):1134-1148.
[11]Wei Fengmei,Zhang Jianpei,Chu Yan,et al.CFSFP:transfer learning from long texts to the short[J].Applied Mathematics&Information Sciences,2014,8(4):2033-2044.
[12]Du Hongle.Algorithm for imbalanced dataset based onK-nearest neighbor in kernel space[J].Journal of Frontiers of Computer Science and Technology,2015,9(7):869-876.
[13]Du Hongle,Zhang Yan.A classification algorithm for imbalanced dataset of sample density[J].Journal of Xihua University:Natural Science,2015,34(5):16-23.
[14]Du Hongle,Teng Shaohua,Zhang Lin.Support vector machine based on dynamic density equalization[C]//LNCS 9567:Proceedings of the 2nd International Conference on Human Centered Computing,Colombo,Sri Lanka,Jan 7-9,2016.Berlin,Heidelberg:Springer,2016:58-69.
[15]Zhang Yishi,YangAnrong,Xiong Chan,et al.Feature selection using data envelopment analysis[J].Knowledge-Based Systems,2014,64:70-80.
[16]Chang C C,Lin C J.LIBSVM:a library for support vector machines[EB/OL].(2014)[2016-07-30].http://www.csie.ntu.tw/~cjlin/libsvm.
附中文参考文献:
[1]李宇翀,罗兴国,钱叶魁,等.RMPCM:一种基于健壮多元概率校准模型的全网络异常检测方法[J].通信学报,2015,36(11):201-212.
[3]武小年,彭小金,杨宇洋,等.入侵检测中基于SVM的两极特征选择方法[J].通信学报,2015,36(4):19-26.
[4]庄福振,罗平,何清,等.迁移学习研究进展[J].软件学报,2015,26(1):26-39.
[5]陈毅松,汪国平,董士海.基于支持向量机的渐进直推式分类学习算法[J].软件学报,2003,14(3):451-460.
[6]张新,何苯,罗铁坚,等.基于聚类的直推式学习的性能分析[J].软件学报,2014,25(12):2865-2876.
[7]杨柳,景丽萍,于剑.一种异构直推式迁移学习算法[J].软件学报,2015,26(11):2762-2780.
[12]杜红乐.基于核空间中K-近邻的不均衡数据算法[J].计算机科学与探索,2015,9(7):869-876.
[13]杜红乐,张燕.密度不均衡数据分类算法[J].西华大学学报:自然科学版,2015,34(5):16-23.
2016-09,Accepted 2016-12.
NetworkAnomaly Detection Based on Dynamic Cost and Cooperative Labeling*
ZHANG Yan,DU Hongle+
School of Mathematics and ComputerApplications,Shangluo University,Shangluo,Shaanxi 726000,China
+Corresponding author:E-mail:dhl5597@126.com
This paper focuses on the imbalanced data classification and the labeling cost,proposes a classification method DC-TSVM(dynamic cost and cooperative labeling transductive support vector machine)based on voting committee algorithm and dynamic cost.This method constructs each sub-classifier according to the misclassification cost of each sub-class that is calculated based on the relationship of density.It can reduce the offset of the classified hyperplane.Then this method labels the sample according to the voting entropy.It can reduce the accumulation and transmission of errors,improve the accuracy of labeling and get the high generalization performance.Finally,the experimental results with KDDCUP99 dataset show that this method has higher detection accuracy for unknown attacks.
support vector machine;network anomaly detection;voting committee;cooperative labeling
10.3778/j.issn.1673-9418.1609048
*The Natural Science Foundation Research Project of Shaanxi Province under Grant No.2015JM6347(陕西省自然科学基础研究计划项目);the Scientific Research Program of Shaanxi Provincial Education Department under Grant No.15JK1218(陕西省教育厅科技计划项目);the Science and Technology Research Project of Shangluo University under Grant No.15sky010(商洛学院科学与技术项目).
CNKI网络优先出版:2016-12-23,http://www.cnki.net/kcms/detail/11.5602.TP.20161223.1702.004.html
ZHANG Yan,DU Hongle.Network anomaly detection based on dynamic cost and cooperative labeling.Journal of Frontiers of Computer Science and Technology,2017,11(11):1775-1782.
A
TP301.6

ZHANG Yan was born in 1977.She received the M.S.degree from Northwest A&F University in 2011.Now she is a lecturer at Shangluo University.Her research interests include pattern recognition and machine learning,etc.
张燕(1977—),女,陕西丹凤人,2011年于西北农林科技大学获得计算机应用硕士学位,现为商洛学院讲师,主要研究领域为模式识别,机器学习等。发表学术论文10余篇,主持或承担过校级以上项目8项。

DU Hongle was born in 1979.He received the M.S.degree from Guangdong University of Technology in 2010.Now he is a lecturer at Shangluo University.His research interests include machine learning and data mining,etc.
杜红乐(1979—),男,河南宜阳人,2010年于广东工业大学获得硕士学位,目前是商洛学院讲师,主要研究领域为数据挖掘、机器学习等。发表学术论文近30多篇,主持或承担校级以上项目12项。
