社会网中时间最优的利润最大化算法研究*
2017-11-16谢胜男朱敬华
刘 勇,谢胜男,张 巍,朱敬华,王 楠
黑龙江大学 计算机科学技术学院,哈尔滨 150080
社会网中时间最优的利润最大化算法研究*
刘 勇+,谢胜男,张 巍,朱敬华,王 楠
黑龙江大学 计算机科学技术学院,哈尔滨 150080
影响最大化问题是在社会网上寻找最具影响力的种集。目前的研究工作忽略了影响传播最大化和利润最大化的区别,以及影响范围会随着时间的推移趋于平稳。考虑用户动作日志,提出了基于时间长度的影响力分配模型IVA-T(influence value allocation-T),在此基础上首次提出了时间最优的利润最大化问题(time optimal profit maximization,OTPM),并证明了该问题为NP-hard问题。为求解OTPM问题,提出了一个有效的近似算法Profit-Max,并证明了Profit-Max算法的近似比。多个真实数据集上的实验结果表明,该算法可以有效并高效地解决OTPM问题。
社会网;利润最大化;动作日志;时间长度
1 引言
最近几年,一些规模较大的社会网流行起来,如微信、Instagram、微博等。这些网络将人们以各种方式联系起来,进行信息交互和资源共享。进一步,使得社会网的研究具有较大意义,可以通过对社会网中用户之间的联系,估计影响传播概率,进行一些新思想或是新商品的传播。
基于上述思想,Domingos等人[1]在2001年首次提出了病毒性市场营销这一概念。在社会网中选取k个有影响力的用户,免费给他们使用待推广产品,通过社会网中的口碑效应,使最多的用户接受并购买该产品。2003年,Kempe等人[2]将上述问题形式化为影响最大化问题:给定有向图G(V,E),正整数k,选择一组节点数为k的集合,即为种集,在给定的影响传播模型下,最终达到最大的影响范围。文献[3-7]针对影响最大化问题进行了进一步的研究,对不同应用背景下的影响最大化提出了相应的解决方案。然而,上述文献的解决方法并没有考虑以下两个问题:(1)在求种集的影响范围时,没有考虑成本问题;(2)忽略了营销时间对影响范围的影响。
在现实应用中,促销成本一定会随着时间推移而增加,而种集的影响范围会变得平稳,以下的实验证实了这一观点。在真实数据集Digg上做了如下实验:利用文献[8]中的算法选择具有最大影响力的10个节点组成种集,选择了长度递增的7个时间段,用以观察种集的影响范围随时间的变化,实验结果如表1所示。其中,T表示不同的时间长度,Spread为影响范围,表示被影响的节点数量。

Table 1 Spread vs different timespan T in Digg dataset表1 在Digg数据集上影响范围vs不同的时间长度
从表1可以得出结论,影响范围会随着时间的推移而逐渐趋于平稳。从中可以得出另一重要结论,对于不同的时间长度,最终选择的种集也是不一样,具体实验结果见5.4节。因此,在市场营销应用中,选择最佳的促销时长及对应的种集可以帮助商家以最小的成本获得最大的利润。
现有如下场景:京东商城的一家商店要推广一个新的商品,现要在整个社会网中进行促销。这个商家每天都有一定的促销成本,每件商品都有一定的利润。由于受影响而购买该商品的用户总量会随着时间的推移而不再呈上升趋势,所以这家商店期望可以选择具有较大影响力的用户和最佳的促销时间段来获得更大的利润。上文的场景可以形式化地表示为时间最优的利润最大化问题:给定每个时间单位的促销成本cost,每件商品利润price,用户的历史动作记录L,要选择时间长度T和种集S,使得S在时间T内的影响可以使商家获取最大的利润。显然,选择最佳的促销时间长度有重要的应用价值。本文主要贡献如下:
(1)利用用户的历史动作记录,设计了基于时间长度的影响力分配模型IVA-T(influence value allocation-T),在该模型基础上第一次提出了时间最优的利润最大化问题(time optimal profitmaximization,OTPM),并证明了该问题是NP-hard问题。
(2)提出了一个近似算法Profit-Max来解决OTPM问题,同时证明了Profit-Max算法的近似比为1-1/e-β/e,其中β表示最优解的成本与最优解的纯利润的比值,是一个极小的数。
(3)通过在多个真实数据集上的实验结果,得出以下结论:Profit-Max算法可以有效并高效地求解OTPM问题。另外,发现给定不同的时间长度,最终得到的种集是不一样的。
本文组织结构如下:第2章介绍了相关工作;第3章给出了影响力分配模型及OTPM问题定义;第4章提出了基于动作日志的时间最优利润最大化算法Profit-Max;第5章给出了实验结果及分析;第6章对本文工作进行了总结。
2 相关工作
2003年,Kempe等人[2]第一次提出了社会网中的影响最大化问题,并利用贪心算法来解决该问题。每次迭代过程中选择一个影响范围增益最大的节点加入到种集,迭代循环到种集中节点数目为k。算法在选择种子节点时,每次迭代都需要进行大量次数的蒙特卡罗模拟使得求解的影响范围更为精确,然而效率会变低。2007年,Leskovec等人[7]提出了CELF(cost-effective lazy forward)优化算法改进贪心算法的效率,比原始贪心算法快700倍。Zhou等人[9]为影响范围函数设计了一个上界,该上界可以减少在贪心算法中调用蒙特卡罗模拟的次数,尤其是在初始化的第一次迭代中,基于该上界,并结合CELF优化,设计了UBLF(upper bound based lazy forward)算法。Liu等人[10]也提出了一个线性的上界方法来计算影响力及影响最大化,设计了一个定量指标Group-Page-Rank,以便快速地在线性方法上估计影响力的上界,进一步提高影响最大化算法的效率。很多研究也将竞争因素结合到影响最大化研究中。Chen等人[11]扩展了IC传播模型,提出了带有时间限制的影响最大化问题。2012年,Lu等人[12]提出了LT-V模型,并在该模型上定义了利润最大化问题。此后,Bhagat等人[13]提出LT-C传播模型,并在该模型上研究并解决了最大化产品购买问题。Lin等人[14]考虑了现在社会网中很多相似商品之间的竞争关系,提出了基于学习的框架去解决多轮的竞争影响最大化,每个竞争者在选择种集的时候不仅考虑了网络信息,也考虑了对手的选择,分别提出了已知对手策略和未知对手策略的解决办法。
然而,上述模型都有如下弊端:边上的概率值为预先设定,不能准确地模拟真实传播。为解决该问题,Goyal等人[8]提出了基于动作日志来求解影响最大化问题。他们定义了基于数据传播的CD模型,利用用户的历史行动日志来学习用户之间的影响概率。在真实数据的传播过程中有一个新的发现:给定不同的传播时间,最终计算出的种集是不同的。而且,在现实营销环境中,成本会随着时间的推移而增加。因此,在利用动作日志精确选择种集的基础上,考虑不同的时间长度可以使最终选择的种集具有更大的影响范围。
3 传播模型及问题定义
本章提出了一个考虑时间长度的影响力分配模型IVA-T,并给出了时间最优的利润最大化问题(OTPM)的定义。
3.1 IVA-T传播模型
给定有向图G=(V,E),时间长度T,动作日志L。动作日志L中记录格式为(user,action,time),表示用户user在时间time执行了动作action。令V表示user的全集,A表示action的全集。对于任意u∈V,a∈A,令t(u,a)代表用户u执行动作a的时间。现假设每一个用户最多只执行某个动作一次。t(u,a)<t(v,a)代表用户u在用户v之前执行过动作a;t(u,a)=+∞代表用户u未执行过动作a。如果对于节点v,满足0≤t(v,a)-t(u,a)≤T并且(u,v)∈E,则表示在时间T内,动作a从节点u传播到节点v。
对于动作a,定义在T时间内,直接影响v的节点集合为Nin(v,a,T)={u|{u,v)∈E,0≤t(v,a)-t(u,a)≤T}。节点v在执行动作a时,v要对∀u∈Nin(v,a,T)分配直接影响力,记作αv,u(a,T),且满足。对于直接影响力αv,u(a,T),有多种分配方式。为便于理解,先定义αv,u(a,T)=1/Nin(v,a,T)。节点v迭代地为节点u的父节点w分配影响力,进一步判断v与w的执行时间间隔是否满足0≤t(v,a)-t(w,a)≤T,若满足该条件,则需要给w分配影响力,否则不需要。给定动作a,节点v在时间T内给它的父节点w分配的影响力形式化地表示为,并 且Γu,u(a,T)=1。给定集合S⊆V,对于动作a,可以类似定义节点v在时间T内对S分配的影响力,如果u∈S,那么Γu,S(a,T)=1。最后,对动作日志中的每个动作聚集,得出最终影响力。节点v在时间T内给它的父节点w分配的影响力定义为,其中|Pv|表示节点v执行的动作个数。在时间T内,对于任意集合S⊆V,节点v对S分配的影响力表示为。以上描述的具有时间限制的传播模型定义为IVA-T。在时间T内,给定IVA-T模型,种集S的影响范围。
举例来解释提出的模型。给定一个有向图G=(V,E),其中V={1,2,3,4,5,6,7},E={(1,2),(2,3),(2,4),(5,6),(5,7)}。动作日志L={(1,a,0),(5,a,0),(2,a,1),(6,a,1),(7,a,1),(3,a,3),(4,a,3)}。首先,对动作日志(u,a,t)做预处理:先按action排序,再按照time排序。利用IVA-T模型,先计算T=1时,图G中节点的影响力分配,找到影响力最大的节点。当T=1时,对于动作日志记录(1,a,0),节点1先于其他节点执行动作a,因此节点1不给其他节点分配影响力;对于日志记录(2,a,1),扫描指向节点2的邻接链表,因为0≤t(2,a)-t(1,a)≤1,(1,2)∈E,所以节点2给节点1分配的影响力为1/Nin(2,a,1)=1;同理,对于动作日志记录(6,a,1)和(7,a,1),得出节点6给节点5分配的影响力为1/Nin(6,a,1)=1,节点7给节点5分配的影响力也为1/Nin(7,a,1)=1;对于动作日志记录(3,a,3),扫描指向节点3的邻接链表,因为t(3,a)-t(2,a)>1,所以节点3不对节点2分配影响力。同理节点4也不对节点2分配影响力。当T=2时,采用上述方法进行影响力分配。当T=1,T=2时影响力分配的结果如表2所示。
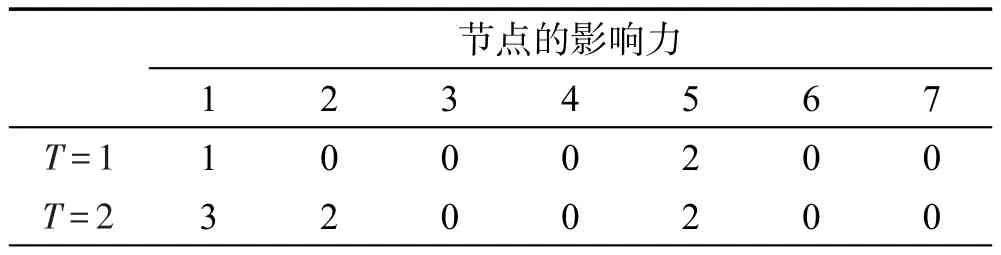
Table 2 Influence value of different timespan表2 在不同时间长度条件下分配的影响力
通过上述例子,发现在不同时间长度条件下,影响力最大的节点是不同的。例如,T=1时,节点5影响力最大;T=2时,节点1影响力最大。因此,在不同的时间长度条件下,应当选择不同的种集。
3.2 问题定义
时间最优的利润最大化问题(OTPM):给定有向图G=(V,E),动作日志L(user,action,time),每件商品的利润price,单位时间的成本cost,正整数k,最佳促销时间长度T,种集S,其中|S|=k,使得在IVA-T模型下,商品的纯利润price×δIVA-T(S,T)-cost×T达到最大,其中price×δIVA-T(S,T)表示在时间T内促销商品获得的利润,cost×T表示在时间T内促销的成本。
定理1最优的利润最大化问题OTPM是NP-hard问题。
证明 如果把时间长度T设置为社会网中用户执行动作的最大时间T=max{t(u,a)|u∈V},那么IVA-T传播模型等价于CD传播模型[8],使price=1,cost=0,则时间最优的利润最大化问题OTPM可以转化为影响最大化问题。Goyal已经证明影响最大化问题在CD传播模型下是NP-hard问题。由于时间最优的利润最大化问题的特殊情况是NP-hard,那么该问题也是NP-hard。 □
4 基于动作日志的利润最大化算法
首先将时间均匀分为M个单位长度,对于每个递增的时间长度,首先利用算法Initialization影响力分配链表inf_link进行初始化,再利用算法Greedy-CELF选择种集S_temp,并计算当前时间长度所选择的种集得到的利润。如果当前利润大于最大利润,则依次替换当前最大利润、种集S和最佳时间长度T。Profit-Max算法的伪代码如算法1所示。
算法1 Profit-Max算法

4.1 扫描动作日志,初始化影响力分配链表
算法Initialization按序扫描动作日志,针对动作a∈A,对每个节点u∈V的影响力分配链表inf_link[a][u]进行初始化。inf_link[a][u]中存储节点u在动作a上为其他节点分配的影响力值。
首先,对动作日志L(user,action,time)进行预处理:先按动作action进行排序,然后按时间time排序。令active为存储被目前动作激活的节点集合,P[u]代表节点u执行动作的个数,father[u]为节点u在目前动作上可激活的父节点集合,time[u]为节点u执行目前动作的时间。由给定有向图G=(V,E)可构造指向每个节点u∈V的邻接表in_edge[u]。顺序扫描动作日志(u,a,t),邻接表in_edge[u]中的每个节点w,若w在active集合中,并且u执行目前动作的时间与w执行目前动作的时间间隔小于等于时间长度T,则把w加入节点u的影响力分配链表中,再对w进行影响力分配。然后迭代地对节点w的父节点进行影响力分配。算法2为Initialization算法的伪代码。
算法2 Initialization算法

4.2 利用CELF优化选取节点
在选择种集时使用了CELF算法。CELF算法利用函数的子模性。如果对∀S⊆T,有φ(S∪{u})-φ(S)≥φ(T⋃{u})-φ(T),则称函数φ(∙)具有子模性。易证,本文提出的影响传播函数δIVA-T(S,T)在时间T固定时具有子模性,因此本文采用CELF算法进行种集选择。
首先,Greedy-CELF算法利用Margin-compute计算节点u∈V的影响增益u.margin,更新当前迭代次数,再将u存储到优先队列queue。优先队列queue将所有节点按margin的值从大到小排序。Greedy-CELF算法的伪代码如算法3所示。
算法3 Greedy-CELF算法

4.3 对所有动作聚集,计算节点影响范围增益
Margin-compute计算节点x加入种集S后影响范围增益margin。gain[a]中存储节点x每个动作上的影响力聚集值。SA[a][x]表示节点x针对动作a对当前种集S的影响力。那么针对动作a将x加入种集S,增益为gain[a]×(1-SA[a][x])。则基于所有动作,margin为增益gain[a]×(1-SA[a][x])的累加和。Margin-compute的伪代码如算法4所示。
算法4 Margin-compute算法


4.4 更新影响力分配链表
将节点x加入到种集S后,算法Value-update更新了inf_link以及其他节点给当前种集S分配的影响力SA。算法Value-update的伪代码如算法5所示。
算法5 Value-update算法

4.5 算法的时间复杂性分析
Profit-Max算法的时间复杂度为O(kηM|V||L|)。其中k为S的大小;η是所有节点的父节点数的最大值,即η=max{|inf_link[a][u]|,a∈A,u∈V};|inf_link[a][u]|表示链表inf_link[a][u]的长度;M是时间段数;|V|是图中节点数目;|L|为动作日志记录数。
定理2 Profit-Max算法的近似比为1-1/e-β/e,其中β表示最优解的成本比上最优解的纯利润,即β=(cost×T0)/(price×δIVA-T(S0,T0)-cost×T0)。其中(S0,T0)是问题OTPM的最优解。
证明 本文提出在选择最终种集S时,固定了时间长度T。当T为常数时,利用文献[8]的定理2易证δIVA-T(S,T)具有子模性、单调性。因此当T为常数时,利用贪心算法可以找到一个与最优解的比值至少为1-1/e的近似解。为了便于阅读,令α=1-1/e。设T=T0,S=S0是OTPM问题的最优解,Profit-Max算法在T=T0时找到的种集为S′,Profit-Max算法在求解OTPM问题时返回的解为T=T1,S=S1。那么有α×δIVA-T(S0,T0)≤δIVA-T(S′,T0)。因此price×δIVA-T(S0,T0)-cost×T0≤1/α×price×δIVA-T(S′,T0)-cost×T0=1/α×(price×δIVA-T(S′,T0)-cost×T0)+(1/α-1)× cost×T0≤ 1/α×(price×δIVA-T(S1,T1)-cost×T1)+(1/α-1)×cost×T0,从 而 1≤1/α×(price×δIVA-T(S1,T1)-cost×T1)/(price×δIVA-T(S0,T0)-cost×T0)+(1/α-1)×β。整理后,(price×δIVA-T(S1,T1)-cost×T1)/(price×δIVA-T(S0,T0)-cost×T0)≥(1-(1/α-1)×β)×α=α-(1-α)×β=1-1/e-β/e。 □
5 实验与结果分析
在两个真实数据集上测试和评估了本文提出的算法,并从多个角度验证本文算法的有效性和高效性。
5.1 实验环境描述
本文使用的两个数据集都包含一个社会网G=(V,E)和一组动作日志L(user,action,time)。数据集分别是Last.fm[15]和Digg[15]。其中,Last.fm是社交音乐平台,用户可以评论音乐。动作日志中的信息代表用户u在时间t评论音乐a。从中提取了2 100个节点,25 435条边及相应的动作日志。该动作日志包含1 000个动作,21 646条记录。Digg是社交新闻网站,用户可以评论网站上的文章。动作日志中的信息代表用户u在时间t评论文章a。从中提取了5 000个节点,395 513条边及相应的动作日志。该动作日志包含500个动作,77 461条记录。
实验中所有算法均用C++编写,在Microsoft Visual Studio 2010环境下编译。所有实验都在Intel®Core™2 Duo CPU,2 GB主存的台式机上运行。
5.2 种集大小和时间长度对利润的影响
本组实验考察种集大小k和时间长度T对影响范围Spread和利润Profit的影响。从图1和图2可以看出,当时间长度T固定时,随着种集大小k的增加,影响范围Spread也在不断增加。当k固定时,随着时间长度T的增加,影响范围Spread也在增加。
从图3和图4可以看出,固定k时,随着时间长度T的增加,利润不断增加,但当时间达到某个点时,利润不再增加。在Last数据集上T=6时,利润Profit达到最大。而在Digg数据集上,利润Profit在T=3时达到最大。由此可见选择最佳促销时间在营销过程中的重要性。
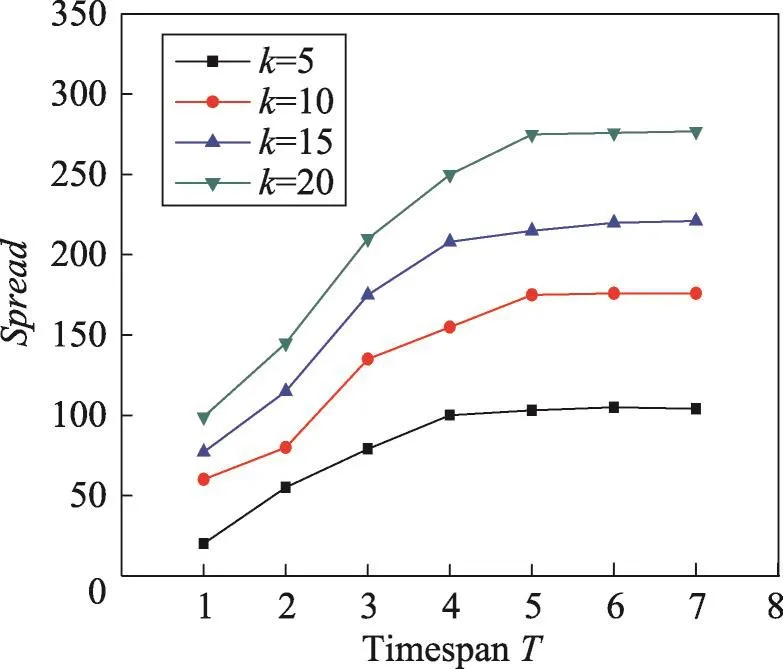
Fig.1 Spread vs timespan T in Last dataset图1 在Last数据集上影响范围vs时间长度T

Fig.3 Profit vs timespan T in Last dataset(price=20,cost=100)图3 在Last数据集上price=20,cost=100时产品利润vs时间长度T
5.3 产品价格和成本对利润的影响
本组实验考察产品价格price和成本cost对利润和最佳促销时间的影响。由图5可以看出,最佳促销时间随着price的增加也在不断增加。当price=10时,T=3为最佳促销时间。而当price=40时,T=6为最佳。由图6可以看出,最佳促销时间不断减小。当cost=100时,T=6为最佳促销时间。而当cost=400时,T=4为最佳。由此可见,在不同的产品价格price和成本cost条件下,选择不同的促销时间长度是重要的。
在Digg数据集上也做了相同的实验,实验结果得出的规律与在Last上的结果相似。
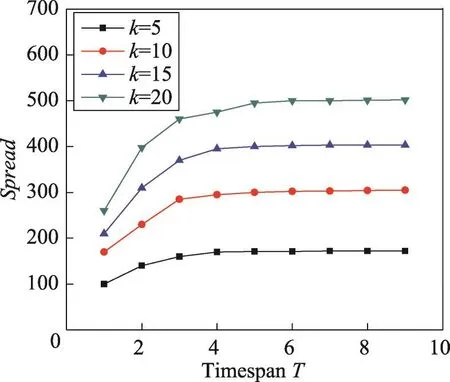
Fig.2 Spread vs timespan T in Digg dataset图2 在Digg数据集上影响范围vs时间长度T
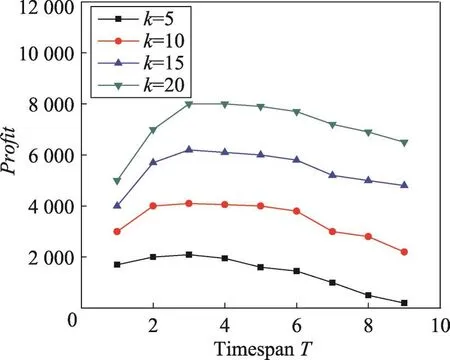
Fig.4 Profit vs timespan T in Digg dataset(price=20,cost=400)图4 在Digg数据集上price=20,cost=400时产品利润vs时间长度T
5.4 比较不同算法选择的种集
本组实验考察本文算法与其他算法在选择的种集的真实影响范围以及运行时间上的差异。主要与下面方法进行比较。(1)Degree-Max:选择节点度数最大的k个节点作为种集;(2)Greedy-Max:使用贪心算法选取种集;(3)CD-Max:在CD模型上使用贪心算法选取种集;(4)LAIC-Max:在LAIC模型上根据时间长度选取种集;(5)IC-M-Max:在IC-M模型上根据时间长度选取种集。
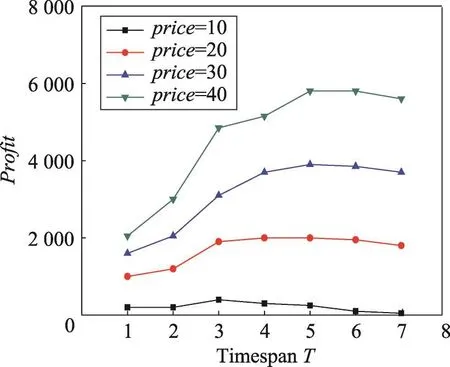
Fig.5 Profit vs timespan T in Last dataset(cost=300,k=10)图5 在Last数据集上cost=300,k=10时产品利润vs时间长度T
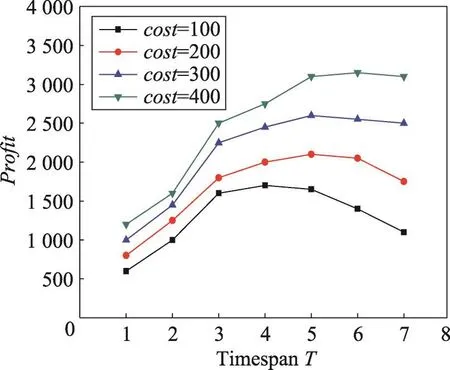
Fig.6 Profit vs timespan T in Last dataset(price=20,k=10)图6 在Last数据集上price=20,k=10时产品利润vs时间长度T
在这组实验中,分别利用上述6种算法选择k=10的种集,并计算选定种集在不同时间长度下影响范围Spread。从图7和图8中可以看出,Degree-Max的结果最差,因为Degree-Max只是选择全局具有最大度数的节点。Greedy-Max在计算影响范围时采用了蒙特卡罗模拟估计,使得该算法结果略优于Degree-Max。LAIC-Max与IC-M-Max既考虑了图的拓扑结构,也考虑了时间因素,但是在求解影响范围时没有利用真实数据,因此计算出的影响范围不准确。CD-Max虽然利用了真实数据,但该算法在每个时间长度所选择的种集S都是相同的。Profit-Max则在真实数据上计算影响范围,根据不同的时间长度T,选择最优种集S,因此得到的影响范围优于其他算法。
从图9中可以看出以上6种算法的运行时间。Degree-Max运行时间较快的原因是该算法只是简单地选择全局度数最大的k个节点作为种集。LAICMax与IC-M-Max的运行时间随着时间长度的增加呈线性增加的趋势。Profit-Max运行时间最快,是因为Profit-Max直接利用真实数据计算影响范围。由于Greedy-Max方法需要大量次数蒙特卡罗模拟,使得运行时间太长,图中没有显示。
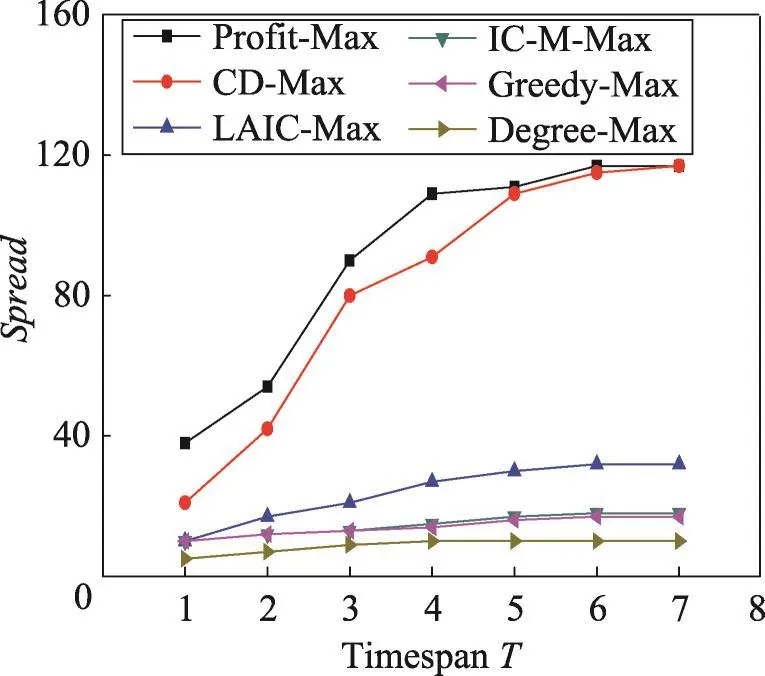
Fig.7 Spread vs timespan T in Last dataset(k=10)图7 在Last数据集上k=10时影响范围vs时间长度T
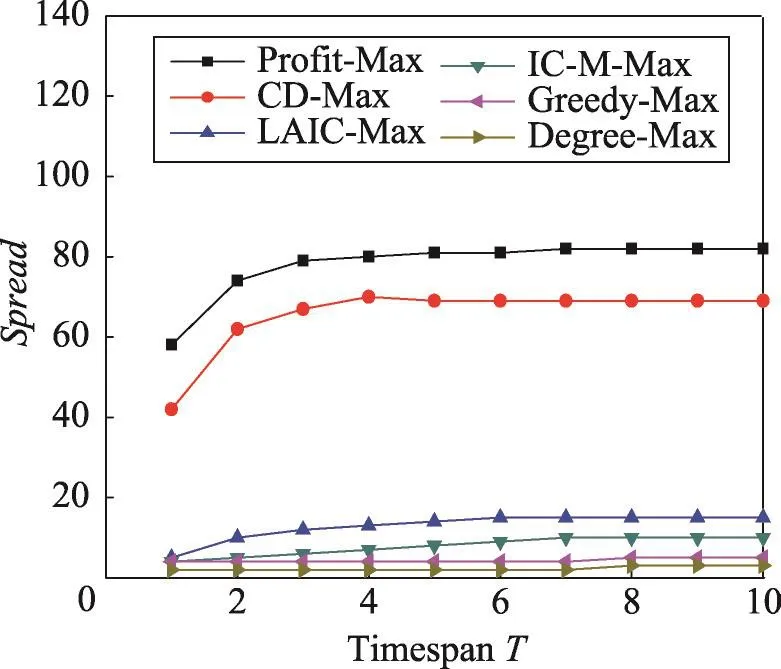
Fig.8 Spread vs timespan T in Digg1000 dataset(k=10)图8 在Digg1000数据集上k=10时影响范围vs时间长度T
选择了7个不同的时间长度,分别计算出在这些不同时间长度下的种集。从表3中可以得出结论,在不同的促销时间长度下,应选择不同的种集。
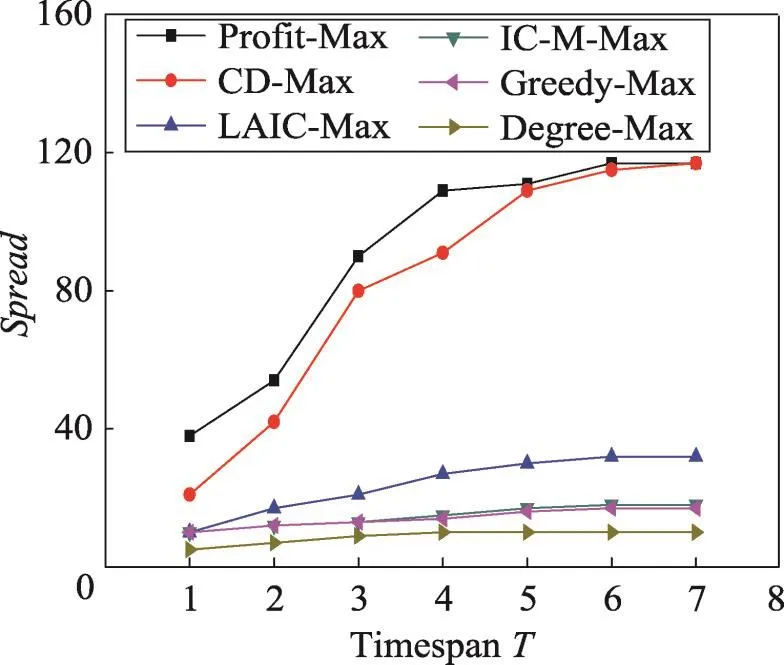
Fig.9 Running time vs timespan T in Digg1000 dataset(k=10)图9 在Digg1000数据集上k=10时运行时间vs时间长度T
6 结束语
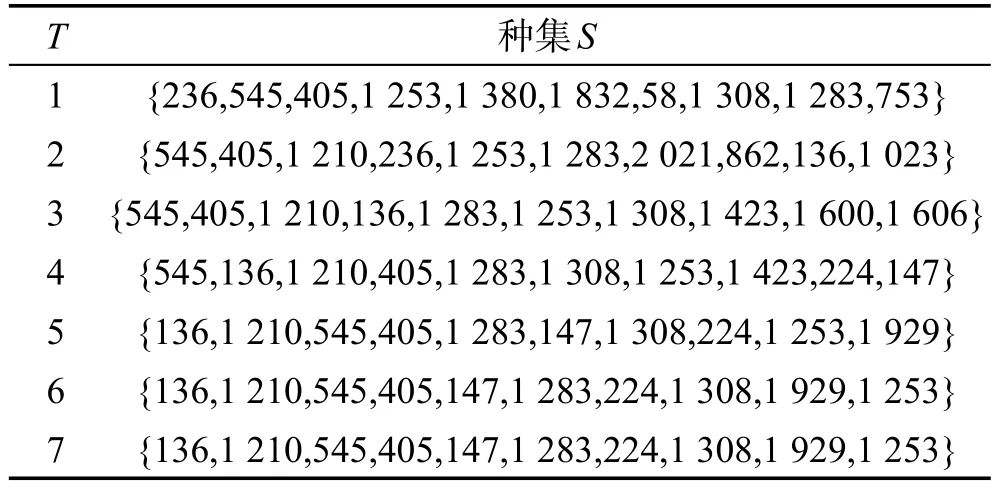
Table 3 Different time vs seed set length in Last dataset with k=10表3 在Last数据集上k=10时时间长度vs种集
本文提出了基于时间长度的影响力分配模型IVA-T,在其基础上提出了时间最优的利润最大化问题(OTPM),并证明了该问题是NP-hard问题。为解决该问题,提出了一个高效的近似算法Profit-Max,并证明了Profit-Max的近似比。多个数据集上的实验结果证明了Profit-Max算法的有效性和高效率。
[1]Domingos P,Richardson M.Mining the network value of customers[C]//Proceedings of the 7th ACM SIGKDD Conference on Knowledge Discovery and Data Mining,San Francisco,USA,Aug 26-29,2001.NewYork:ACM,2001:57-66.
[2]Kempe D,Kleinberg J M,Tardos É.Maximizing the spread of influence through a social network[C]//Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington,Aug 24-27,2003.New York:ACM,2003:137-146.
[3]Chen Wei,Wang Yajun,Yang Siyu.Efficient influence maximization in social networks[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Paris,Jun 28-Jul 1,2009.New York:ACM,2009:199-208.
[4]Chen Wei,Wang Chi,Wang Yajun.Scalable influence maximization for prevalent viral marketing in large-scale social networks[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington,Jul 25-28,2010.New York:ACM,2010:1029-1038.
[5]Li Yuchen,Zhang Dongxiang,Tan K L.Real time targeted influence maximization for online advertisements[J].Proceedings of the VLDB Endowment,2015,8(10):1070-1081.
[6]Horel T,Singer Y.Scalable methods for adaptively seeding a social network[C]//Proceedings of the 24th International Conference on World Wide Web Companion,Florence,Italy,May 18-22,2015.New York:ACM,2015:623-624.
[7]Leskovec J,Krause A,Guestrin C,et al.Cost-effective outbreak detection in networks[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Jose,USA,Aug 12-15,2007.New York:ACM,2007:420-429.
[8]Goyal A,Bonchi F,Lakshmanan L V S.A data-based approach to social influence maximization[J].Proceedings of the VLDB Endowment,2011,5(1):73-84.
[9]Zhou Chuan,Zhang Peng,Guo Jing,et al.An upper bound based greedy algorithm for mining top-kinfluential nodes in social networks[C]//Proceedings of the 23rd International World Wide Web Conference,Seoul,Apr 7-11,2014.New York:ACM,2014:421-422.
[10]Liu Qi,Xiang Biao,Chen Enhong,et al.Influence maximization over large-scale social networks:a bounded linear approach[C]//Proceedings of the 23rd International Conference on Information and Knowledge Management,Shanghai,Nov 3-7,2014.New York:ACM,2014:171-180.
[11]Chen Wei,Lu Wei,Zhang Ning.Time-critical influence maximization in social networks with time-delayed diffusion process[C]//Proceedings of the 26th Conference on Artificial Intelligence,Toronto,Canada,Jul 22-26,2012.Menlo Park,USA:AAAI,2012:592-598.
[12]Lu Wei,Lakshmanan L V S.Profit maximization over social networks[C]//Proceedings of the 12th International Conference on Data Mining,Brussels,Dec 10-13,2012.Washington:IEEE Computer Society,2012:479-488.
[13]Bhagat S,Goyal A,Lakshmanan L V S.Maximizing product adoption in social networks[C]//Proceedings of the 5th International Conference on Web Search and Data Mining,Seattle,USA,Feb 8-12,2012.NewYork:ACM,2012:603-612.
[14]Lin Suchen,Lin Shoude,Chen M S.A learning-based framework to handle multi-round multi-party influence maximization on social networks[C]//Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Sydney,Australia,Aug 10-13,2015.New York:ACM,2015:695-704.
[15]Goyal A,Bonchi F,Lakshmanan L V S.Learning influence probabilities in social networks[C]//Proceedings of the 3rd International Conference on Web Search and Data Mining,New York,Feb 4-6,2010.New York:ACM,2010:241-250.
2016-08,Accepted 2017-02.
Research on Time Optimal Profit Maximization in Social Network*
LIU Yong+,XIE Shengnan,ZHANG Wei,ZHU Jinghua,WANG Nan
School of Computer Science and Technology,Heilongjiang University,Harbin 150080,China
+Corresponding author:E-mail:acliuyong@sina.com
Influence maximization is the problem of finding a small set of seed nodes in a social network.Existing works ignore the differences between influence spread maximization and profit maximization,and influence spread becomes stable when time passes by.This paper uses real action log and proposes a new propagation model with timespan which is called IVA-T(influence value allocation-T)propagation model,and firstly proposes time optimal profit maximization(OTPM)problem and proves that the problem is NP-hard.In order to solve the problem,this paper designs an effective approximation algorithm Profit-Max and analyzes the approximation ratio.The experimental results on several real datasets show that Profit-Max algorithm can solve OTPM problem effectively and efficiently.
social network;profit maximization;action log;timespan
10.3778/j.issn.1673-9418.1608044
*The Natural Science Foundation of Heilongjiang Province under Grant No.F201430(黑龙江省自然科学基金);the Innovation Talents Project of Science and Technology Bureau of Harbin under Grant No.2017RAQXJ094(哈尔滨科技创新人才研究专项资金项目);the Fundamental Research Funds of Universities in Heilongjiang Province,Special Fund of Heilongjiang University under Grant No.HDJCCX-201608(黑龙江省高校基本科研业务费黑龙江大学专项资金项目).
CNKI网络优先出版:2017-03-01,http://kns.cnki.net/kcms/detail/11.5602.TP.20170301.1040.002.html
LIU Yong,XIE Shengnan,ZHANG Wei,et al.Research on time optimal profit maximization in social network.Journal of Frontiers of Computer Science and Technology,2017,11(11):1723-1732.
A
TP311

LIU Yong was born in 1975.He received the Ph.D.degree in computer science from Harbin Institute of Technology in 2010.Now he is an associate professor and M.S.supervisor at School of Computer Science and Technology,Heilongjiang University.His research interests include data mining and database,etc.
刘勇(1975—),男,河北昌黎人,2010年于哈尔滨工业大学计算机科学专业获得博士学位,现为黑龙江大学计算机科学技术学院副教授、硕士生导师,主要研究领域为数据挖掘,数据库等。

XIE Shengnan was born in 1991.She received the M.S.degree from School of Computer Science and Technology,Heilongjiang University in 2015.Her research interest is data mining.
谢胜男(1991—),女,黑龙江黑河人,黑龙江大学计算机科学技术学院硕士研究生,主要研究领域为数据挖掘。

ZHANG Wei was born in 1989.She received the M.S.degree from School of Computer Science and Technology,Heilongjiang University in 2015.Her research interest is data mining.
张巍(1989—),女,黑龙江人,2015年于黑龙江大学计算机科学技术学院获得硕士学位,主要研究领域为数据挖掘。

ZHU Jinghua was born in 1976.She received the Ph.D.degree in computer science from Harbin Institute of Technology in 2009.Now she is an associate professor and M.S.supervisor at Heilongjiang University.Her research interests include data mining and database,etc.
朱敬华(1976—),女,黑龙江齐齐哈尔人,2009年于哈尔滨工业大学计算机科学专业获得博士学位,现为黑龙江大学计算机科学技术学院副教授、硕士生导师,主要研究领域为数据挖掘,数据库等。

WANG Nan was born in 1980.She is a Ph.D.candidate at School of Electronic Engineering,Heilongjiang University.Her research interests include sensor network and social network,etc.
王楠(1980—),女,黑龙江哈尔滨人,黑龙江大学电子工程学院博士研究生,主要研究领域为传感器网络,社会网络等。
