基于非线性核的SVM模型可视化策略
2022-02-19郭明朱焱
郭 明 朱 焱
(西南交通大学信息科学与技术学院 四川 成都 611756)
0 引 言
支持向量机(SVM)是一种基于黑盒模型的分类器。由于在数据挖掘建模的过程中隐藏了具体的分析细节,导致许多使用支持向量机模型解决问题的用户,不太清楚其内部的分类机制。
大数据可视化技术是当前的研究热点。基于模型可视化的研究有助于理解模型的内在分析原理,并增强结果的可信度。目前基于模型可视化的研究多针对决策树或神经网络[1]。SVM可视化的研究主要分为以下两个方面:
(1) 基于模型转换的可视化方法。Jakulin等[2]根据线性核中特征的可加性,首次将线性SVM模型的核函数转换成概率模型,并利用Nomogram进行可视化。随后在此基础上,Cho等[3]提出利用局部径向基核函数解决非线性核中特征不可加性的难题。Belle等[4]则在Nomogram可视化中融合颜色表达。文献[2-4]提出的可视化方法能够反映出每个特征对预测结果的影响程度,但是Nomogram是一个概率模型,无法在可视化上刻画超平面,导致可视化后的SVM模型仍然难以被直观理解。
(2) 基于数据与超平面关系的可视化方法。Caragea等[5]借助tours工具对多维数据进行低维线性投影,并通过网格采样点来夹逼不同类之间的边界。Hamel[6]采用自组织映射将多维数据投射到二维空间,并在支持向量之间适当模拟一个判别超平面。Ma等[7]将模型分为线性核和非线性核,对于线性核,通过包围盒采样线性超平面上的点,然后平行投影到二维空间,利用这些点的密集分布刻画超平面;而对于非线性核,采用多个局部线性模型替代全局模型的方法。其中文献[5-6]侧重分类结果的表达,它刻画的超平面是在二维空间根据正负类边界模拟出的,因此,这种超平面无法定义数据与真实超平面之间的距离关系。文献[7]在可视化线性核模型时,具有良好的直观性;然而,在可视化非线性核模型时,非线性全局模型和局部线性模型的替代是参照两者之间的分类精度,其说服力不强。在基于数据与超平面关系的可视化方法中,克服维度约束至关重要。文献[5-7]都是将数据通过二维投影进行可视化展示,但是在刻画超平面上,却存在明显缺陷,尤其是非线性核超平面。因此,目前关于超过二维空间的非线性SVM模型的可视化,仍然是一个重要挑战。
针对方法(1)在模型的直观理解上存在明显缺陷和方法(2)在刻画超过二维空间非线性超平面上存在的困难,本文对非线性核SVM模型超平面可视化技术展开了深入研究,并将模型分为三维特征模型与多维特征模型两类,分别引入了曲面拟合和信息重构的思想,提出了基于移动最小二乘法拟合的三维特征模型超平面可视化策略与基于t-SNE点重构的多维特征模型超平面可视化策略,最后通过实验数据对相关可视化策略进行验证。实验结果表明,本文提出基于非线性核的SVM模型可视化策略具有良好的直观性,并在一定程度上解决了三维、多维空间非线性核超平面难以刻画的问题。
1 相关工作
1.1 支持向量机(SVM)
设一组训练样本T={(x1,y1),(x2,y2),…,(xn,yn)},x∈Rm,y∈{-1,1},其中:x表示特征;y表示类标;n为样本的个数;m为特征的个数。假设样本数据是线性可分的,支持向量机通过训练,寻找一个超平面将数据划分为{-1,1}两类。线性支持向量如图1所示。

图1 线性支持向量示意图[7]
定义1(超平面) 在支持向量机模型中,划分正负类样本的决策目标函数称为超平面。线性支持向量机的判别式为:
WTX+b=0
(1)
式中:X是m维特征向量;W是超平面的法向量;b是截距。
定义2(支持向量) 在支持向量机模型中,距离超平面最近且满足一定条件的几个训练样本点被称为支持向量[8]。正类和负类支持向量所在的边界可表示为:
WTX+b=1
(2)
WTX+b=-1
(3)
优化式(2)和式(3)满足最大间隔。最后经推导,可得出支持向量机的决策目标函数:
(4)
式中:k表示支持向量的个数;αi为第i个支持向量的拉格朗日系数;yi为第i个支持向量的原始类标;xi为支持向量对应的特征;x为待预测样本的特征;K(xi,x)表示核函数。
定义3(核函数) 对于所有x,x′∈χ,满足K(x,x′)=(Φ(x),Φ(x′))[8],其中Φ表示非线性函数。常见的非线性核函数有:
(2) 多项式核:K(x,x′)=(xTx′)n。
1.2 移动最小二乘法
移动最小二乘法[9]是在最小二乘法基础上引入了基函数和紧支撑权函数。
定义4(拟合函数) 在拟合区的局部子域上,拟合函数可表示为[10]:
(5)
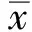
定义5(紧支撑权函数) 紧支撑权函数是带约束的权函数。常用的紧支撑权函数是样条函数:
设影响域的半径为d,假设对于二维问题,待拟合的点为(x,y),影响域中的点有(xI,yI),则:
加入紧支撑权函数,计算所有待拟合数据点的误差加权平方和有:
(6)
式中:m表示影响域中的点个数;w(sI)为(xI,yI)处的影响权重;f(x)是拟合函数;yI是x=xI处的节点值。
然后取式(6)的极小值,可求出a(x),最后将a(x)代入式(5)中,便可求出x处的拟合值。
1.3 t-SNE降维
t-SNE是由Maaten等[11-12]提出的对高维数据的可视化方法。t-SNE降维核心思想为:将数据点的欧氏距离转换为邻近概率分布。设高维空间中的数据集X=(x1,x2,…,xn),其在低维空间中的映射数据表示为Y=(y1,y2,…,yn)。其中n表示数据点的个数。高维空间中的数据的概率分布可由式(7)定义,低维空间中的数据的概率分布可由式(8)定义。
(7)
(8)
式中:pij表示以xi为中心,xj到xi的邻近概率;qij表示以yi为中心,yj到yi的邻近概率。
使用KL散度计算qij对pij的忠实度有:
(9)
式中:C是总代价;P是高维空间的联合概率分布;Q是低维空间的联合概率分布。

(10)
式中:Y表示低维空间的坐标;t表示不同迭代阶段;η表示学习率;α(t)表示t阶段时的动量。
t-SNE能够在低维空间保留数据在高维空间的全局结构和局部结构,并有效地解决了SNE在降维处理时参数难以寻优和低维空间数据拥挤的问题。因此,它已成为高维数据可视化的重要方法之一。
2 可视化设计策略
当特征空间的维度从二维上升到三维时,由于维度的增加,造成了非线性核超平面目标函数在三维特征空间难以有效转换。因此,大部分研究学者选择投影至二维空间后去模拟超平面或利用线性超平面替代非线性超平面的方法。
本文在研究三维特征空间非线性核SVM模型可视化时,未沿用上述可视化方法。主要出于三个方面考虑:(1) 二维投影后模拟出的超平面无法反映真实数据点与真实超平面之间的距离关系;(2) 线性超平面替代非线性超平面的不确定性太强且说服力不足;(3) 三维空间本身就处于人类可识别的维度范围内。
因此,如果将三维特征空间非线性核SVM模型在三维空间进行可视化,那么就可以有效避免(1)和(2)存在的问题。然而,非线性核超平面却难以直接通过超平面方程进行平面/曲面采样。为此,本文引入网格采样+曲面拟合的思想,提出了基于移动最小二乘法拟合的三维特征模型超平面可视化策略MLS-SVMVis。该策略通过网格采样超平面上的点;由于直接通过采样点绘制超平面,超平面在光滑性和直观性上都存在极大的视觉缺陷,故MLS-SVMVis策略以超平面采样点为基础,采用移动最小二乘法对超平面进行拟合,从而改善了非线性SVM模型的直观性。具体算法步骤如算法1所示。
算法1MLS-SVMVis(D)
输入:三维特征数据集D。
输出:SVM可视化模型。
Begin:
1. 对数据集进行训练,构建超平面方程;
2. 设定超平面预采样点个数阈值nums;
3. 设定网格采样参数,进行网格采样;
4. 计算采样点到超平面的距离d,统计d等于0的点的个数;
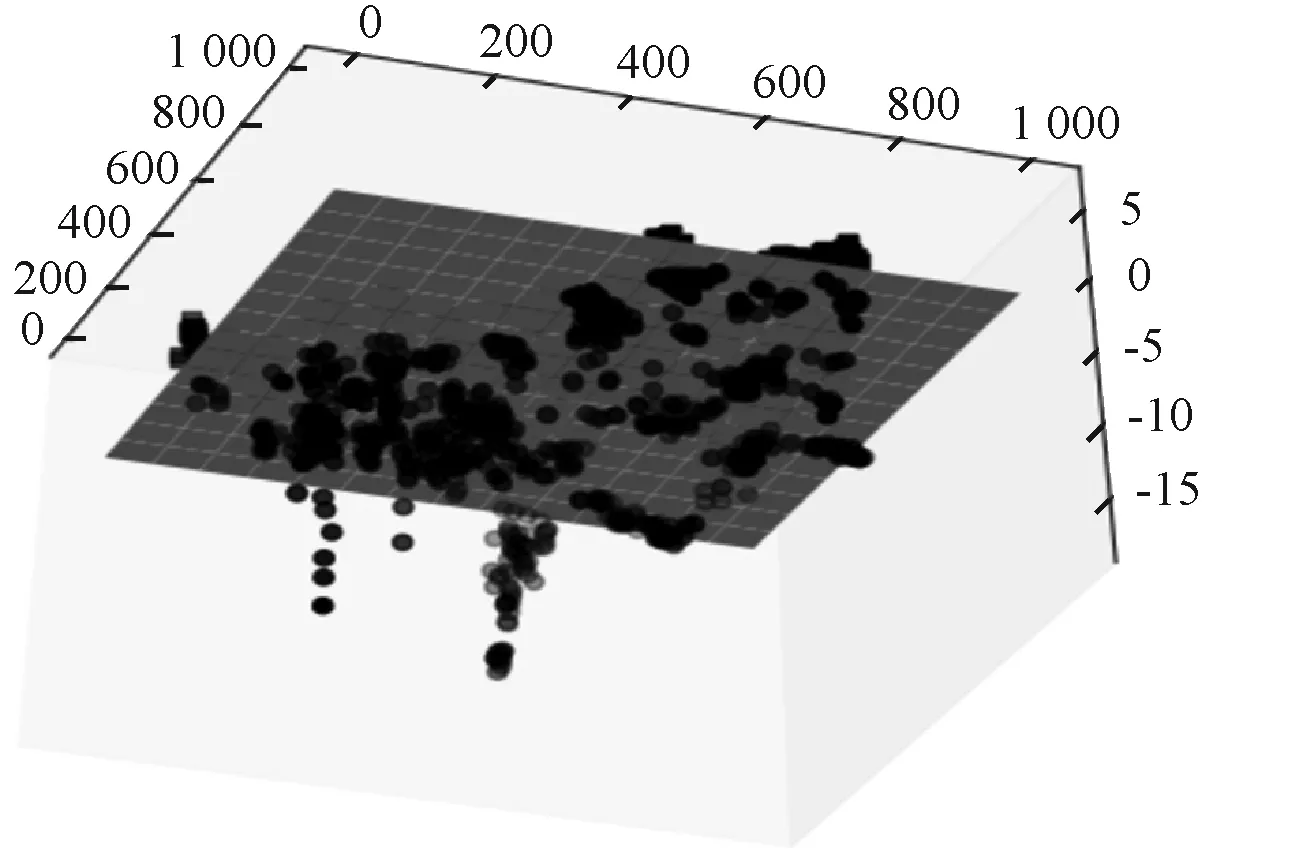
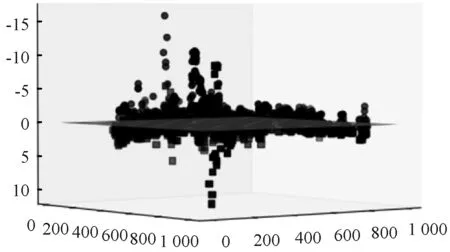
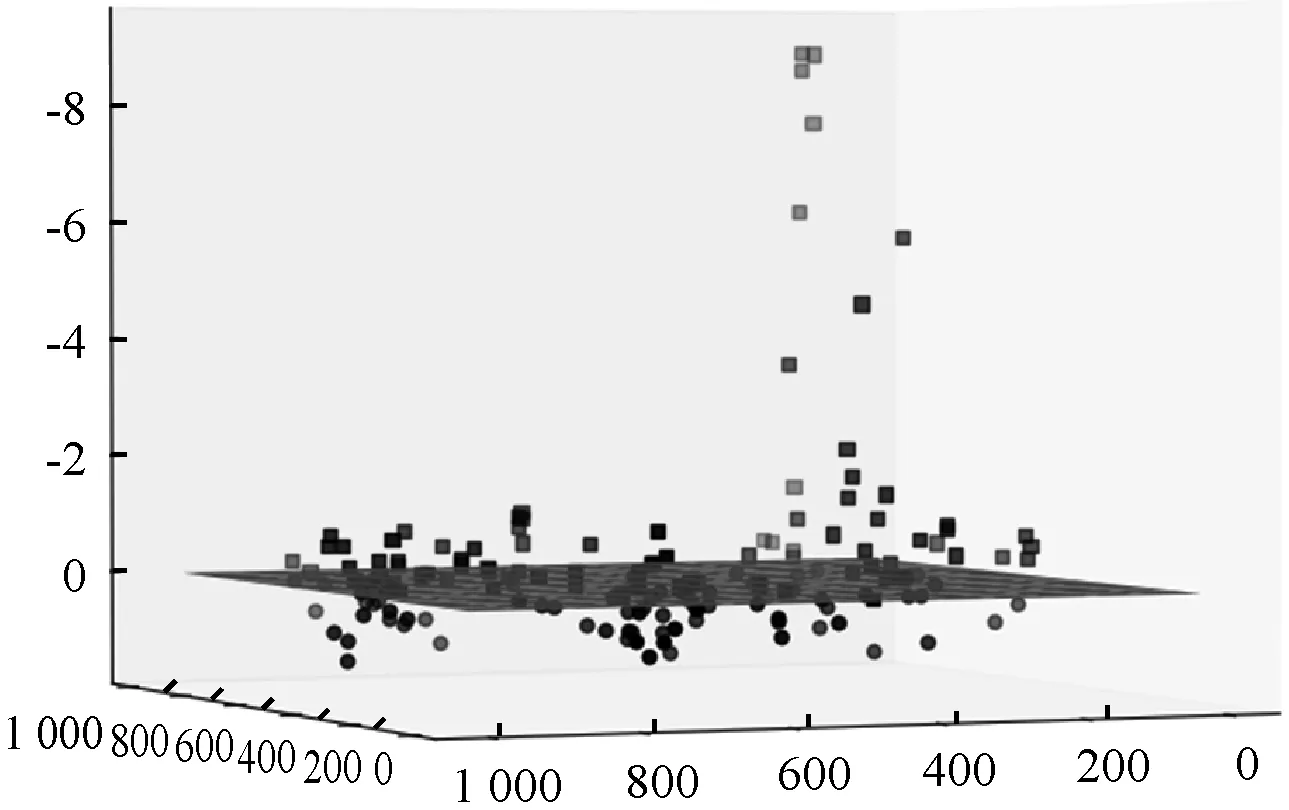
5. ifcount(d==0) 返回到步骤3,更新采样参数; 6. 设定点的拟合偏差值阈值error; 7. 网格化拟合区域,设置基函数P和影响域半径R; 8. 根据超平面采样点,利用移动最小二乘法进行拟合,并计算拟合点的拟合偏差值; 9. for拟合超平面上每一个点的拟合偏差值miss ifmiss>error 返回步骤7,更新基函数P和影响域半径R; 10. 绘制超平面拟合曲面; 11. 输出带有数据点的三维SVM可视化模型; End 对于一个n维特征的支持向量机模型,其超平面为(n-1)维。当特征空间高于三维时,非线性核模型的超平面将呈现出不规则的多维几何体样貌。因此,通过投影技术来展示超平面,可能无法在低维空间反映出数据与超平面之间的关系。 为了能够反映高维数据分布情况以及数据与超平面之间的关系,本文根据t-SNE基于邻近概率分布降维原理,引入信息重构的思想,提出了基于t-SNE点重构的多维特征模型超平面可视化策略PR-SVMVis。该策略以高维数据在二维空间上的分布和点到超平面之间的距离作为重构信息。对于一个多维特征空间非线性SVM模型,如果将点到超平面的距离d看作一个维度,那么这个维度能够反映出点与超平面之间的关系,且刻度为0的地方即为超平面。然而,信息重构时,在高维数据的二维空间表示中增加了一个维度,会破坏数据原来的空间分布。为了使重构后数据依然保持原来的空间分布,本文利用t-SNE基于邻近概率分布降维原理,通过扩大高维数据在转换至二维空间展示时的坐标尺度,然后再与d进行信息重构,这样就能达到弱化d的效果,从而降低了增加维度对数据的邻近概率分布产生的影响。因此,重构后的数据,既能反映数据在高维空间的分布结构,还能刻画出数据与超平面之间的关系。具体算法步骤如算法2所示。 算法2PR-SVMVis(D) 输入:多维特征数据集D。 输出:SVM可视化模型。 Begin: 1. 对数据集进行训练,构建超平面方程; 2. 计算数据集到超平面的距离,记为集合D; 3. 通过的t-SNE将数据集降维到扩增尺度的二维空间,记为集合L; 4. 将L和D重构成三维坐标点,记为集合M; 5. 对于集合M,根据D的取值为0绘制超平面; 6. 输出带有数据点的SVM可视化模型; End 为了验证本文提出的策略能够有效地可视化非线性二分类SVM模型,本文选取了四个经典的UCI真实数据集(Iris、Seeds、Vertebral和Robot-Navigation)进行实验。其中:Iris、Seeds和Vertebral用于验证基于MLS-SVMVis可视化策略;Robot-Navigation用于验证基于PR-SVMVis可视化策略。 Iris数据集选取类标为“Iris-setosa”(正类)和“Iris-versicolor”(负类)共100条样本,实验使用3个特征(sepal length、sepal width、petal length)。 Seeds数据集选取类标为“2”(正类)和“3”(负类)共140条样本,实验使用Seeds数据集PCA降维后的三维特征。 Vertebral数据集选取类标为“SL”(正类)和“NO”(负类)共250条样本,实验使用3个特征(sacral slope、pelvic radius、grade of spondylolisthesis)。 3个数据集分别选取80%作为训练集和20%作为测试集。 Robot-Navigation也是Ma等[7]实验中的数据集,共24个特征,本文保持与该实验样本的一致性,选取类标为“Sharp-Right-Turn”和“Move-Forward”共4 302条样本,以“Sharp-Right-Turn”为正类,“Move-Forward”为负类,分别在正负类中各取50%作为训练集和测试集。 3.2.1基于MLS-SVMVis三维特征模型可视化 Iris、Seeds和Vertebral都是小样本数据集,本文在进行实验时,将超平面预采样点个数阈值nums设为200;然后,进行网格化,在每个特征取值范围内采集了90个值,构建了90×90×90采样点;由于在严格意义上不容易采集到距离超平面恰好为0的点,实验设定点到超平面距离|d|≤0.000 85的点为超平面上的点。对于拟合函数,实验选用了基函数PT=[1,x,y],error=0.1。分别设定3个数据集拟合函数的影响域半径,RIris=0.7,RSeeds=0.6,RVertebral=0.7。 在可视化模型中,“■”代表正类,“●”代表负类;深灰色的平面表示超平面,浅色的平面表示正、负类支持向量边界。 图2、图3、图4分别展示了基于Iris数据集、Seeds数据集、Vertebral数据集的分类情况,其中ACC表示算法的准确率。其中图2(a)、图3(a)和图4(a)是根据采样点直接绘制的超平面,图2(b)-图2(d)、图3(b)-图3(d)和图4(b)-图4(d)是采用MLS-SVMVis策略拟合的超平面。对比两者的可视化效果,可以看出采用MLS-SVMVis策略拟合的超平面是十分光滑的曲面或近似的平面,直观性较好。分别计算3个数据集拟合超平面上各个点在超平面方程中的偏差值(即拟合点到超平面的距离)。missIris∈[-0.06,0.07],missSeeds∈[-0.08,0.01],missVertebral∈[-0.002,0.009]。 (a) 根据网格采样点直接绘制的超平面 (b) 基于移动最小二乘法拟合的超平面(c) 加入正负、类支持向量边界的可视化模型(d) 测试集在模型中的表现图2 Iris非线性SVM模型展示(高斯核,σ=0.5,ACCtrain=1,ACCtest=1) (a) 根据网格采样点直接绘制的超平面 (b) 基于移动最小二乘法拟合的超平面 (c) 加入正负、类支持向量边界的可视化模型 (d) 测试集在模型中的表现图3 Seeds非线性SVM模型展示(高斯核,σ=5,ACCtrain=1,ACCtest=1) (a) 根据网格采样点直接绘制的超平面 (b) 基于移动最小二乘法拟合的超平面 (c) 加入正负、类支持向量边界的可视化模型 (d) 测试集在模型中的表现图4 Vertebral非线性SVM模型展示(多项式核,n=2,C=1.5,ACCtrain=0.944,ACCtest=0.975) MLS-SVMVis策略在保持拟合效果同时,改善了通过采样点直接绘制SVM模型超平面的粗糙性,它能够避免当数据点与超平面采样点接近时,通过点密集程度刻画超平面[5,7]所产生的视觉混乱。 3.2.2基于PR-SVMVis多维特征模型可视化 (11) 式中:xmin、ymin、xmax和ymax分别表示未经缩放前x和y的最小值和最大值。 经t-SNE二维降维的点(xi,yi)通过式(11)可缩放表示为(xI,yI)。 在可视化模型中,“■”代表正类,“●”代表负类,深灰色平面表示超平面。 Robot-Navigation数据集有24个特征,故将t-SNE二维降维后的两个维度缩放至[0,2 400]。图5和图6展示了基于Robot-Navigation训练数据的分类情况,ACCtrain=1。图7和图8展示了测试数据的表现,ACCtest=0.921,图中可以清晰地看到,有一些数据点被SVM分类器误分了。计算t-SNE降维后的数据与点重构转换后的数据之间的KL散度,KLtrain(2→3)=3.45×10-6,KLtest(2→3)=3.15×10-6,可认为点重构没有破坏t-SNE降维后的数据分布,即重构的数据依然保持了数据在高维空间相似的分布结构。由于PR-SVMVis策略增加的维度是点到超平面距离d,因此,在可视化模型中,数据点在超平面哪一侧、距超平面大小与超平面方程计算的结果是完全一致的。 图5 Robot-Navigation SVM模型展示(高斯核,σ=0.5) 图6 Robot-Navigation SVM模型展示(高斯核,σ=0.5,经旋转) 图7 测试集表现(高斯核,σ=0.5) 图8 测试集分类器误分情况(高斯核,σ=0.5) PR-SVMVis策略能够在直观上反映多维数据点在高维空间中的分布结构以及数据点与超平面之间的距离关系,有利于增强用户对多维SVM模型分类结果的理解,提升分类结果的可信力度。 本文提出基于非线性核的SVM模型可视化策略在一定程度上解决了三维、多维空间非线性核超平面难以直观刻画的问题。然而,网格采样点、基函数、影响域半径对曲面拟合效果有较大的影响,故使用基于MLS-SVMVis可视化策略需要根据数据集的不同设定合适的参数值。下一步工作准备将基于MLS-SVMVis可视化策略与交互设计相结合,通过交互操作来选择合适的参数和可视化方案。3 实 验
3.1 数据集与预处理
3.2 验证实验与结果分析



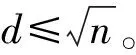

4 结 语
