基于Hadoop的大数据处理平台研究
2017-11-02朱颢东冯嘉美张志锋
朱颢东, 冯嘉美, 张志锋
(1.郑州轻工业学院 计算机与通信工程学院, 郑州 450002; 2.郑州轻工业学院 软件学院, 郑州 450002)
基于Hadoop的大数据处理平台研究
朱颢东1*, 冯嘉美1, 张志锋2
(1.郑州轻工业学院 计算机与通信工程学院, 郑州 450002; 2.郑州轻工业学院 软件学院, 郑州 450002)
大数据时代的到来伴随着海量数据,进而使得筛选出具有价值的信息成为大数据被广泛应用的核心步骤.在此情况下Apache Hadoop顺势而生,其通过简化数据密集、高度并行的分布式应用来应对大数据带来的挑战.由于目前基于Hadoop的大数据平台在多领域普遍使用,从而平台搭建成为进行大数据探索的第一步.而很多文章介绍的平台搭建是在虚拟机中完成,与真实情况存在相应差异.本文讨论以真实集群为基础搭建Hadoop平台的原因,Hadoop集群的强大功能,搭建平台所需设备、环境、安装、设置及测试过程.
Hadoop; 大数据; 分布式应用
大数据的特征不仅在于数量级巨大而且同时包含结构化和非结构化的多种数据源.因此真正的问题在于如何从中提取有意义的信息,于是就离不开大数据的分析和工具.Hadoop就是对大数据处理的一种具有海量存储,支持快速数据访问的分布式处理并且具有可靠性、失效转移、可扩展的工具.大数据科研价值与商业价值的凸显,使更多的人需要搭建Hadoop平台.随着把计算机聚合成服务器集群的简单化,Hadoop平台的使用越来越广泛,进而平台搭建成为后续学习、研究、商业化的基础.
1 直面大数据挑战—Hadoop
不断增长的Hadoop系统具有相应的核心组件.能够实现在完全分布式的集群上对海量数据的快速分布式存储的Hadoop分布式文件系统(HDFS),构建在HDFS之上的NoSQL数据库HBase,用于大规模数据分布式并行的mapper、reducer处理的执行框架MapReduce,对Hadoop中存储的数据进行查询的高级语言Hive,用于关系型数据库和数据仓库与Hadoop之间移动数据的连通性工具Sqoop等组成.
1.1 Hadoop的发展
Hadoop是Apache基金会提出的可支持TB 级别大文件数据处理的开源云计算平台,具有投入成本低、可扩展性高、易部署且开源等优势[1].Hadoop做到了平台即服务(Platform as a Service,PaaS),已经由Hadoop 1.x版本,如图1所示,升级为Hadoop 2.x版本,如图2所示.

图1 Hadoop 1.x框架示意图Fig.1 Schematic diagram of Hadoop 1.x frame

图2 Hadoop2.x框架示意图Fig.2 Schematic diagram of Hadoop 2.x frame
对于Hadoop1.x及以下的运行架构存在可伸缩性的问题,即当集群从节点数超过4 000时再增加从节点也不能获得对应性能上的近似线性提高[2].因此在Hadoop2.x版本对之前版本存在一定问题进行改进,增加YARN.可以看出,全局资源管理器YARN的出现是为了解决MapReduce 中存在的一些缺陷.从节点运行于每个节点之上,它们管理特定节点上的容器,监控一个节点的执行,汇报资源可用性给主节点,主节点负责在系统中所有应用程序之间的仲裁[3].
1.2 Hadoop的强大功能
面对大数据GB、TB的数据量,传统关系型数据库会出现溢出、无法运行等情况,HDFS应时而生来满足大数据存储、读取、写入[4].使用HDFS和HBase的组合用于高效数据存储,HDFS可以做到保存顺序访问的海量数据,HBase可以达到快速随机访问数据,两者结合可以实现快速访问大的数据条目.Hadoop能够将数据存储和处理完美的结合,MapReduce框架能够解决大规模数据计算问题.Oozie可以实现Hadoop作业的自动化和管理.Hadoop强大的功能使其应用变得广泛,尤其是从Hadoop 1.0 升级到Hadoop 2.0后相应的搭建也有所改变,本文以真实集群为基础进行平台的搭建,为后续的学习研究提供基础保障.
2 基于Hadoop 2.0以上版本的大数据处理平台搭建实践
平台搭建是解决相关问题的基础,随着Hadoop版本的逐步发展,本文选择以完全稳定的Hadoop2.6.0进行安装.Hadoop有3种安装模式: 单机模式、伪分布模式和全分布模式,前两种方式并不能体现大数据计算的优势与意义,本文采用多台机器搭建全分布模式集群.
2.1 计算机聚合服务器集群
市场上内存价格与服务器价格的直线下降使计算机聚合成服务器越来越简单[5].在学习中使用若干台计算机搭建一个小的平台进行探究,相较于使用虚拟机会出现服务器宕机、软件驱动底层排错困难以及性能大大降低等问题,搭建过程有助于理解Hadoop平台的机制.在企业中以更低的成本获得需求的计算能力并且在内存中处理比以往更多的数据,达到效益利益最高化.
根据实际需求选择集群的硬件环境,本文以达到后续研究为目的,选择5台HP ProLinant ML350 G6服务器,cpu Xeon E5506 2.4GHz,内存8G,硬盘1T.一台Auto USB KVM Switch,达到配置集群环境,减少每台主机配置独立键盘,显示器,鼠标的费用,节省多余部件需要占据的空间,节省能源消耗,避免来回奔波于各电脑间的不便与时间浪费.形成完全分布式网络拓扑图,如图3所示.
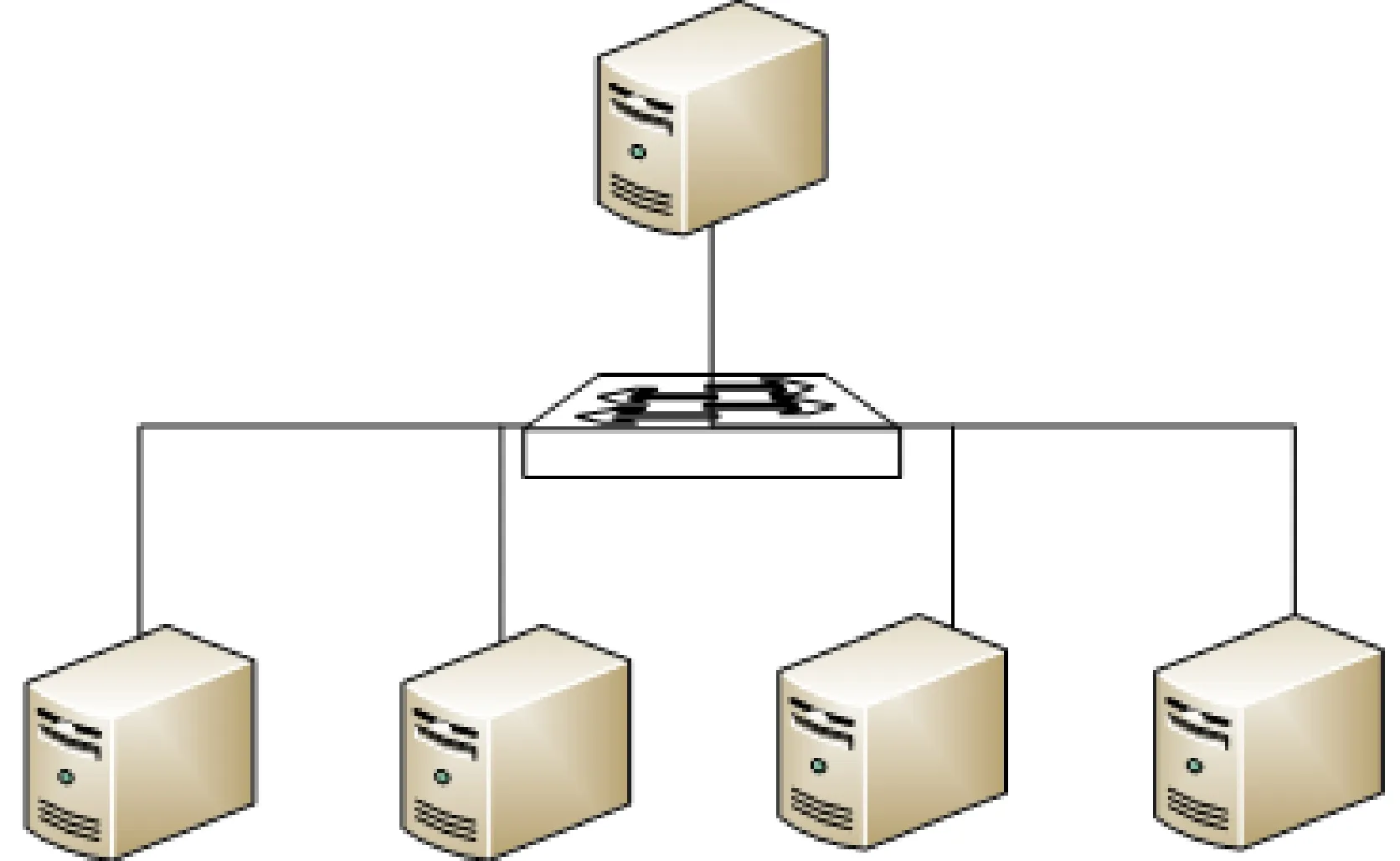
图3 完全分布式网络拓扑图Fig.3 Fully distributed network topology
2.2 主机上Linux系统的安装与设置
Hadoop在Windows操作系统和Linux操作系统下均可使用,但是在Window 系统下安装之前要先安装 Cygwin软件,来模拟Unix操作系统环境方可使用.Linux操作系统也具有很多版本,而CentOS是一个基于Red Hat的无付费的、稳定的、可自由使用源代码的、企业级的Linux系统.使用CentOS能够获得7年的技术支持,满足开发的需求,并且新版本的系统还在以每2 a一次的速度持续更新发布中,保证了CentOS的持久生命力.能够做到完全免费,不需要序列号,独具yum命令支持在线升级,可以即时更新系统,建立一个安全、低维护、稳定、高预测性的 Linux 环境,所以选择稳定的CentOS-6.7-x86_64-bin-DVD1.iso做成光盘镜像进行安装.
5台服务器做实验,1 台做 Name Node,Job-Tracker,服务器名为master.另外 4 台做Data Node,Task-Tracker,服务器名分别为 slave1,slave2,slave3,slave4.安装系统时可以使用创建的统一用户,也可使用root用户,再此我们用root 用户将需要的软件全部安装在 root 根用户下.
修改文件vim/ etc / sysconfig / network修改5台服务器主机名:HOSTNAME
网关统一为:GATEWAY=192.168.1.1
修改文件vim/etc /hosts 添加集群中所有机器的IP与主机名,使master和所有slave能够通信,添加如下:
192. 168. 1. 101 master
192. 168. 1. 102 slave1
192. 168. 1. 103 slave2
192. 168. 1. 104 slave3
192. 168. 1. 105 slave4
关闭集群中所有机器的防火墙不然会出现datanode开后又自动关闭、集群不能连通等问题,设置如下:chkconfig iptables off
2.3 配置双向SSH免密码登录
在master节点上生成密码对:ssh-keygen-t rsa-P ''
把id_rsa.pub加到授权key中:cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
修改authorized_keys权限,SSH机制非常严谨,不设置权限会触发不安全设置,导致不能使用RSA功能,设置如下:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
在root用户下,修改SSH配置文件:vim/etc/ssh/sshd_config 启用RSA认证、公钥私钥配对认证方式,设置公钥文件路径.
将公钥复制到所有的slave服务器上:scp~/.ssh/id_rsa.pub 远程用户名称@远程服务器IP:~/.
上述步骤即可实现master到slave的SSH无密码登录.以相同方式在4台slave节点上进行相同过程,实现slave到master的SSH无密码登录,进而完成了master和slave之间双向SSH无密码登录.
2.4 安装JAVA-JDK
检查系统中是否具有openjdk若存在需要删除.下载jdk-7u67-linux-i586.tar.gz,进入保存jdk的文件夹,用命令tar-zxvf jdk在linux系统下所需版本的.tar的压缩包,执行jdk的安装.
vim /etc/profile使用命令shift+I修改profile文件设置java环境,在文件末尾添加JAVA_HOME、PATH和CLASSPATH的需求路径.
2.5 安装Hadoop 2.6.0
下载Hadoop 2.0以上完善版本的hadoop-2.6.0.tar.gz到安装目录下,使用命令:tar-zxvf hadoop-2.6.0.tar.gz解压安装包.
1) 配置名字节点上的 / etc / profile 为了方便直接使用 Hadoop 命令,在名字节点上的 /etc / profile 配置如下:
export HADOOP_HOME=/安装目录/ hadoop_2.6.0
export HADOOP_CONF_DIR=$ HADOOP_HOME / conf
export PATH=$ HADOOP_HOME / bin: $ PATH
2) 在本地文件系统创建以下文件夹:~/hadoop/tmp、~/dfs/data、~/dfs/name.进入Hadoop目录,使用命令:ls查看文件夹是否创建成功.
3) 配置 hadoop-env.sh文件,该文件是hadoop运行基本环境的配置,修改JAVA_HOME为安装的jdk保存路径,export JAVA_HOME=/jdk的安装目录/安装jdk的版本名称.
4) 在Hadoop2.x版本中要重新设置 yarn-env.sh 文件,使用vim 命令打开后将JAVA_HOME更改为新安装的jdk路径来配置yarn框架运行环境,不能使用open jdk的路径.
export JAVA_HOME=/JDK安装目录/jdk1.7.0_79
5) 配置slaves文件,增加所有slave节点信息.
slave1 slave2 slave3 slave4
6) 配置 core-site.xml文件,进行全局配置,配置HDFS端口号、地址以及Hadoop缓冲区,具体如图4所示.

图4 配置core-site.xml文件Fig.4 Configured core-site.xml file
7) 站在HDFS角度上配置hdfs-site.xml 文件.设置namenode、datanode端口和目录位置;配置的备份方式默认为3;将dfs.webhdfs.enabled属性设置为true,否则就不能使用webhdfs的LISTSTATUS、LISTFILESTATUS等需要列出文件、文件夹状态的命令,因为这些信息都是由namenode来保存的,配置如图5所示.
8) 在使用YARN的集群下,大数据核心运算中以MapReduce角度设置、更改并以source命令保存 mapred-site.xml 文件.使用yarn框架、jobhistory使用地址以及web地址,如图6所示.

图5 配置 hdfs-site.xml文件Fig.5 Configured hdfs-site.xml file

图6 配置 mapred-site.xml文件Fig.6 Configured mapred-site.xml file
9) 在Hadoop2.0以上版本中,YARN作为增加的一项重要功能,需要修改yarn-site.xml文件,在集群运行中能够实现yarn功能,设置yarn.nodemanager.aux-services 否则NodeManager会启动失败;设置ResourceManager对客户端显示的地址;设置ResourceManager 对ApplicationMaster显示的访问地址;设置ResourceManager对NodeManager显示的地址;设置ResourceManager 对管理员显示的访问地址;设置ResourceManager对外WebUI地址,用户可通过该地址在浏览器中查看集群各类信息,具体配置如图7所示.

图7 配置 yarn-site.xml 文件Fig.7 Configured yarn-site.xml file
10) 在root用户下,将配置好的hadoop文件copy到其余4台slave机器上,使用命令:
scp-r hadoop-2.6.0/ root@服务器IP:/ 完成Hadoop从master的Hadoop的安装.
2.6 所建平台技术优势分析
目前,国内外专家学者也构建了一些较好的分布式集群框架,例如,Jongseong Yoona等[6]提出了一个用于文件存储的NoSQL DBMS分布式集群框架,刘艳俊等[7]提出了一个基于Mongo DB云计算的GML分布式集群框架,这些集群框架主要针对GML文档具有海量空间数据量的特性,通过Mongodbshards分片技术,来实现 GML 数据共享及在Mongo DB中建立索引以实现集群分片存储.同时,也存在一些群框架采用Oracle Grid Engine(OGE)、Load Sharing Facility(LSF)等软件来实现分布式集群的资源管理和任务调度.上述这些分布式集群一般是通过配置服务器、设置参数并构建shard分片来实现,或通过在集群上部署OGE、LSF等进行作业信息统计来实现.但是,这些分布式集群相对于Hadoop的基础组件HDFS来说,它们在大数据存储性能上较差,所使用的分布式资源管理软件也缺少灵活性,从而导致它们不能根据某些特定需求来自定义某些相关功能,从而与平台的兼容性更好.本文所搭建的完全分布式Hadoop集群以YARN为基础,可以灵活运行多种计算框架,MapReduce只是其中一个选项,这不但克服了静态slot 资源分配的不足,避免了资源浪费,而且还能够使Map和Reduce这两种操作根据需求来灵活使用,并且还可以在Map之后与Reduce之前增加过滤器和组合器来提高集群的整体性能.本文所建Hadoop云平台的实现可以随时实地对平台进行连接,十分便捷,并且运行效果和稳定性更好.
3 平台搭建与验证
最终通过5台服务器,1台交换机,1台显示器,搭建形成完全分布式Hadoop集群,如图8所示.

图8 所搭建的完全分布式Hadoop集群Fig.8 Proposed fully distributed hadoop cluster
Hadoop系统安装好后,形成一个新的HDFS系统,需要进行格式化,每个新的HDFS格式化只需一次,命令为: hadoop namenode-format,然后再分别启HDFS和yarn服务: ./sbin/start-dfs.sh./sbin/start-yarn.sh
Hadoop的验证有很多种方法,在此选择简单明晰的一种进行验证.开启Hadoop集群后出现主节点和从节点logging.在主节点master上执行jsp命令,会出现进程号、SecondaryNameNode、ResourceManager、DataNode、Jps、NameNode、NodeManager.在从节点slaver1、slaver2、slaver3、slaver4上均执行jps命令,会输出:进程号、DataNode、Jps、NodeManager ,即可验证Hadoop安装成功,如图9所示.在安装成功的基础上就可以进行更深入的学习与研究.
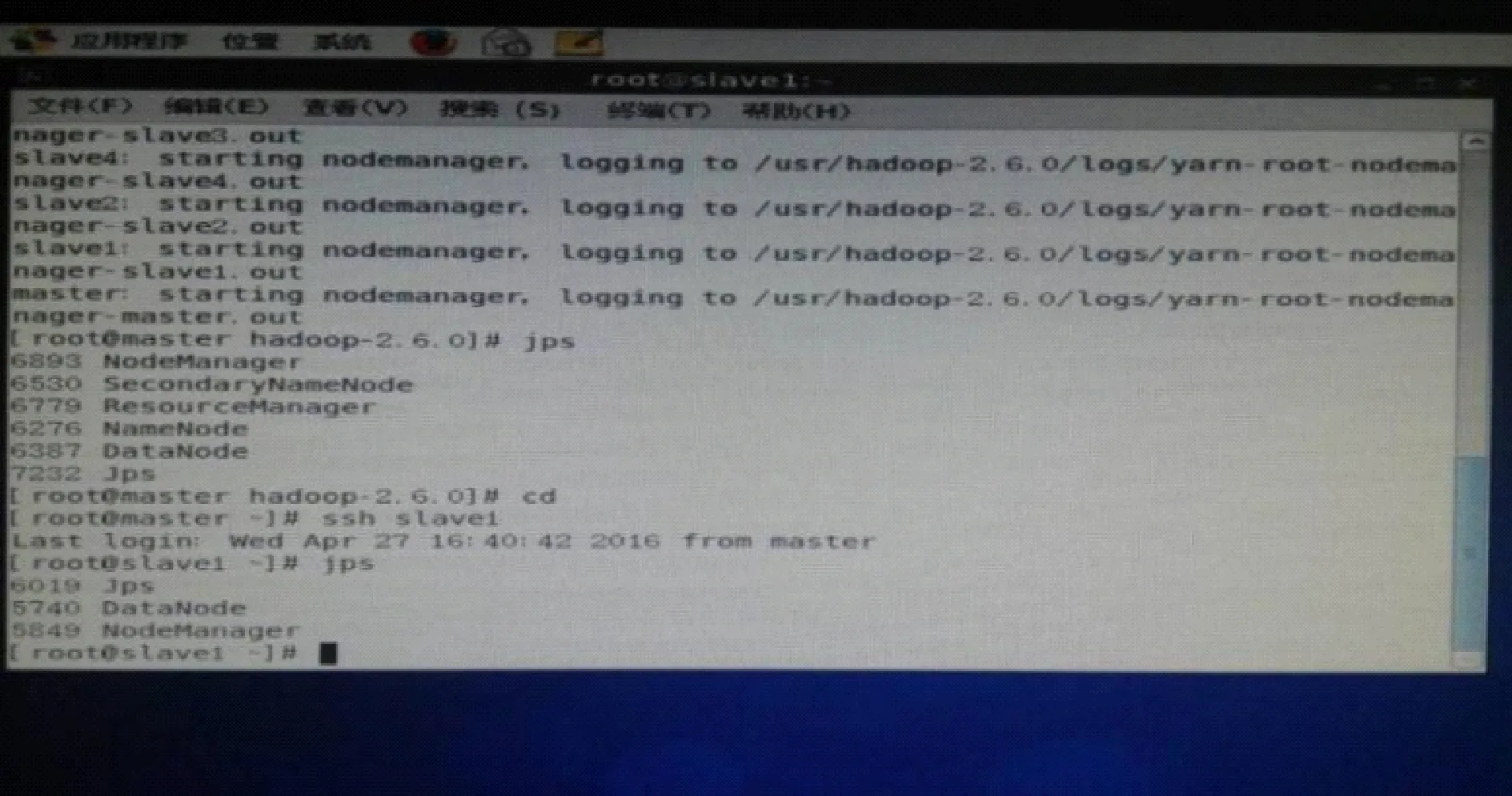
图9 平台验证Fig.9 Platform validation
4 总结
Hadoop 分布式架构云计算平台是一个非常重要的开源架构平台,与其他并行化架构平台相比有着巨大的优势[8].本文对其现状、功能以及搭建过程做了介绍,真实搭建了完全分布式Hadoop平台,经过jps和自带单词计数测试验证平台搭建成功,能够成为后续Hadoop平台上的检索系统、推荐系统等等功能系统开发的基础[9].读万卷书不如行万里路,在学习大数据过程中,动手搭建过程能够深入了解Hadoop的原理,并且锻炼分析问题解决问题的能力,为后续工作打下坚实基础.我们下一步工作是在大数据平台下进行有关算法的研究,将其中的一些算法实现并行化运行.
在搭建过程中发现以下几点问题,应该在以后的搭建平台过程中引起注意在 本次平台搭建过程中遇到以下几点具有代表性的问题,真实集群搭建与虚拟集群存在差异,避免问题再次出现.
1) 位数一致问题.操作系统、jdk、Hadoop要求位数一致,否则会产生不兼容,即使集群配置也会报错无法使用.
2) 在多个配置文件中正确配置安装路径.如果路径配置错误,那么在Hadoop运行时则不能启动Java、Maven等等,从而导致平台不能正常工作[10].
3) 关闭每台服务器的防火墙.因为在使用HDFS和MapReduce时,Hadoop会打开许多监听端口.
4) 注意细微区别.一定要设置yarn.nodemanager.aux-services的value值为mapreduce_shuffle而不是原来设置的mapreduce.shuffle,否则会导致nodemanage无法启动.
[1] 周 江, 王伟平, 孟 丹. 面向大数据分析的分布式文件系统关键技术[J]. 计算机研究与发展, 2014,51(2): 382-394.
[2] 陈 浩. 基于Hadoop的农业电子商务数据平台构建关键技术研究[D]. 武汉: 华中师范大学, 2015, 17-19.
[3] 卢博林斯凯. Hadoop高级编程-构建与实现大数据解决方案[M]. 穆玉伟, 靳晓辉, 译. 北京: 清华大学出版社, 2014.
[4] 蒋云霞, 符 琦. 基于Hadoop的云教学资源平台的研究[J]. 当代教育理论与实践, 2016,4(8): 111-113.
[5] 李 军. 大数据从海量到精准[M]. 北京: 清华大学出版社, 2014.
[6] YOON J, JEONG D, KANG C, et al. Forensic investigation framework for the document store NoSQL DBMS: MongoDB as a case study[J]. Digital Investigation, 2016,17(3): 53-65.
[7] 刘艳俊,敖杰刚,徐齐行.基于Mongo DB云计算下GML分布式集群环境搭建研究[J]. 测绘标准化, 2012,28(1): 3-5.
[8] 崔文斌, 牟少敏. Hadoop大数据平台的搭建与测试[J]. 山东农业大学学报(自然科学版), 2013,44(4) : 550-555.
[9] 谭洁清, 毛锡军. Hadoop云计算基础架构的搭建和hbase 和 hive 的整合应用[J]. 贵州科学, 2013,31(5) : 32-35.
[10] 张 岩, 郭 松, 赵国海.基于Hadoop的云计算试验平台搭建研究[J]. 沈阳师范大学学报(自然科学版), 2013,31(1) : 85-89.
StudyonbigdataprocessingplatformbasedonHadoop
ZHU Haodong1, FENG Jiamei1, ZHANG Zhifeng2
(1.School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou 450002;2.School of Software, Zhengzhou University of Light Industry, Zhengzhou 450002)
The age of big data is companied by massive data, making the selection of valuable information become a core step for wide usage of big data. Apache Hadoop is invented in this case and addressing the challenges from big data via simplifying data intensive and highly parallel distributed applications. The current big data based on Hadoop platform is widely used, so constructing a platform becomes the first step of exploration in big data. This paper describes the reason of Hadoop platform construct based on real cluster and the powerful function of Hadoop cluster as well as equipment, environment, installation, setting and testing process in the construction process.
Hadoop; dig data; distributed application
TP393.0
A
2016-11-27.
河南省科技计划项目(152102210357,152102210149); 河南省高等学校青年骨干教师资助计划项目(2014GGJS-084); 河南省高等学校重点科研项目(16A520030); 郑州轻工业学院校级青年骨干教师培养对象资助计划项目(XGGJS02); 郑州轻工业学院博士科研基金资助项目(2010BSJJ038); 郑州轻工业学院研究生科技创新基金资助项目.
*E-mail: zhuhaodong80@163.com.
10.19603/j.cnki.1000-1190.2017.05.005
1000-1190(2017)05-0585-06
