长度分布约束下的摘要文本无监督分割算法
2017-10-11骆俊帆于中华丁革建
骆俊帆,陈 黎,于中华,丁革建,罗 谦
(1. 四川大学 计算机学院,四川 成都 610065; 2. 浙江师范大学 数理与信息工程学院,浙江 金华 321004;3. 中国民用航空总局第二研究所 信息技术分公司,四川 成都610041)
长度分布约束下的摘要文本无监督分割算法
骆俊帆1,陈 黎1,于中华1,丁革建2,罗 谦3
(1. 四川大学 计算机学院,四川 成都 610065; 2. 浙江师范大学 数理与信息工程学院,浙江 金华 321004;3. 中国民用航空总局第二研究所 信息技术分公司,四川 成都610041)
作为文章内容的浓缩表达,摘要蕴含着文章关键的发现和结论。自动分析挖掘摘要内容,对于充分利用快速增长的科技文献具有重要意义。该文以Medline生物医学文章的摘要为对象,对摘要的文本分割问题进行了研究。针对摘要各论述侧面(内容块)之间在长度分布上倾向于均匀的特点,提出了一种考虑长度分布约束的摘要文本无监督分割算法,该算法以信息熵作为长度分布均匀性的度量指标,将信息熵与块内语义相似度及块间语义相似度相结合作为优化的目标函数,采用动态规划方法搜索最佳分割点。在8 603篇Medline摘要上对算法进行了实验验证,并与文献中最新的无监督分割算法进行了实验对比。结果表明,该文提出的增加了长度分布约束的分割算法更加适用于摘要文本分割,分割的准确率有3%的提高。
文本分割;无监督;动态规划;生物医学;摘要文本
Abstract: To deal with the text segmentation for academic paper abstracts, an unsupervised text segmentation algorithm is proposed, which incorporates constraint of the length distribution derived from the preference of length uniformity in different discussion aspects (i.e. content blocks) of an abstract. A metric based on information entropy is introduced to the algorithm to measure the length distribution uniformity, and the object function is designed with further combination of semantic similarities of inter-and intra-content blocks. A standard dynamic programming scheme is employed to determine the best segmentation sequence. Experimented on 8603 abstracts from Medline, the results show an improvement of 3% in accuracy compared with baselines.
Key words: text segmentation; unsupervised; dynamic programming; biomedical; abstract-text
收稿日期: 2016-03-14 定稿日期: 2016-11-20
基金项目: 四川省科技支撑项目(2014GZ0063)
1 引言
海量的科技文献作为大数据的重要组成部分,蕴含着人类科研活动取得的各种发明、发现和创造方面的关键信息。以这些信息为处理对象,进行分析和挖掘,对于促进科技进步和科研成果转化,具有重要意义。
当前,多数科技文献文本挖掘的研究工作以Medline生物医学文献摘要为处理对象,具体的研究内容包括句子边界识别、命名实体识别和分类、关系抽取、缩略语识别和理解等,根本目的是从摘要中抽取出研究结果或结论信息,例如特定蛋白质对之间的作用关系。选择生物医学文献摘要作为对象的原因一方面是生物医学的快速发展使得借助计算机进行文献分析处理更为迫切,另一方面是Medline*http://www.pubmed.gov.摘要数据量大,覆盖面广,作为文献全文的浓缩表达,包含了全文关键的结果和结论,满足抽取文献关键信息的需要,且具有简洁、冗余少等特点。
任何文本都具有篇章结构,各种信息按照逻辑被组织成不同的文本块(逻辑单元)。通过文本分割,自动识别文本块,再利用篇章结构来提高文本理解(包括信息抽取)的效果,十分重要[1-4]。摘要作为一篇文章的浓缩表达,同样具有篇章结构,例如很多Medline摘要都包括目的、方法、结果、结论四个逻辑单元。对摘要进行文本分割,识别构成摘要的逻辑单元,对于科技文献的文本挖掘和信息抽取,具有重要意义。
针对现有摘要分割算法存在的不足,本文以Medline生物医学文献摘要为对象,研究无监督的摘要自动分割问题,在总结摘要篇章结构特点的基础上,提出基于长度分布约束的无监督分割算法,并对该算法进行实验验证。
本文的后续内容组织如下: 第一节介绍相关工作,分析现有分割算法存在的不足;第二节提出基于长度分布约束的无监督摘要分割算法,对算法进行分析和描述;第三节对算法进行实验验证,介绍实验所用的数据集和实验结果,并对结果进行分析;最后第四节对全文工作进行总结,展望下一步工作的改进方向。
2 相关工作
文本分割属于篇章层面的自然语言处理任务,已经有几十年的研究历史。但是传统的相关研究主要面向具有段落结构的全文文本,而摘要简短、无段落结构的特点使得全文文本分割算法无法直接应用于摘要[5-7]。专门面向摘要的文本分割研究还比较少见,据我们所知,仅有文献[5-7]等有监督方法,这些方法基于大量人工标注的语料来训练分割模型,可移植性差。
面向一般文本提出的无监督分割算法[8-14],通常是先对文档结构进行分析,自动识别主题边界,再将原始文档分割成连续的主题块。词汇分布(如词项重复、词汇链)是这些无监督分割算法经常利用的信息,因为在同一主题块内, 相似或有关联的词汇经常大量重复出现[8]。文献[9-11]从主题块的词汇内聚性出发,内聚性越大的文本块越倾向于被分割为一个主题块,而文献[12-13]则根据文本块间词汇分布的耦合性来划分主题块,两文本块间词汇分布越不相似,则存在分割边界的可能性越大。虽然词汇内聚性比耦合性能带来更好的分割效果,但是也会产生过度分割的问题。文献[11]通过构建一个概率模型,利用动态规划自动选择最优的分割结果,文献[14]基于文献[11]的模型框架,提出一种综合考虑文本块内聚性和块间耦合性的算法,使分割效果明显提高。
尽管上述算法并未利用段落信息,同时属于无监督方法,不需要人工标注训练数据,但是摘要简短的特点使得这些算法在用于摘要文本分割时面临着数据稀疏带来的内聚性和耦合性难以准确度量的困难。摘要不同于一般文本,它平均长度短,概括性强,浓缩了文章的主要内容。根据我们对Medline数万篇摘要的统计,一般的生物医学文献摘要平均仅包含11个句子,320个词次(token),这些句子被组织成不同的语义块,例如,背景、方法、结果、结论等。因此,有必要对摘要文本的无监督分割进行专门的研究。
本文旨在根据摘要文本的特点,设计面向摘要的无监督文本分割算法。摘要文本简短、无段落结构的特点,一方面带来了块内聚性和块间耦合性难以准确评价的困难,但另一方面也使得构成摘要的各语义块(论述侧面)之间在长度的分布上倾向于均匀,这种长度分布的均匀性倾向可以与块内聚性及块间耦合性一起作为评价分割质量优劣的准则,弥补单纯依赖块内聚性和块间耦合性带来的准确率降低的问题。基于上述思想,本文提出一种长度分布约束下的摘要文本无监督分割算法,并对该算法进行实验验证和分析。
3 分割模型及算法描述
3.1 分割模型 沿用文献[11,14]的思想,本文将摘要文本分割归结为搜索最佳分割块序列的优化问题,并采用动态规划方法来求解该问题。然而与文献[11]和[14]不同,本文不但采用文献[14]的方法度量文本块内聚性和块间耦合性,还根据摘要文本的特点,在优化的目标函数中增加对块长度分布均匀性的度量,从而弥补单纯依赖块内容带来的数据稀疏使分割准确率下降的问题。
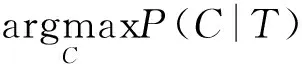
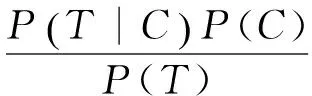
(1)
而P(T)与C无关,因此,给定T,最可能的C应该为
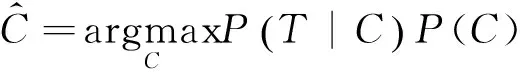
(2)
采用马尔可夫有限历史的假设,将P(T|C)分解为
(3)
其中P(Tci|ci,ci-1)和P(Tci|ci)分别定义为
(4)
和
(5)
其中,λ为可以调整的权值。式(4)的分子部分和式(5)用于从概率的角度度量文本块的内聚性,而式(4)中的Δ(Tci,Tci-1)为耦合项,采用向量夹角余弦值度量文本块间主题(论述侧重点)的差异性,即块间耦合性。式(6)为Δ(Tci,Tci-1)的计算方法。
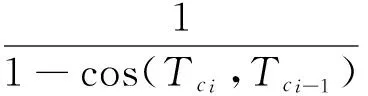
(6)
其中,cos(Tci,Tci-1)是文本块Tci和Tci-1之间的余弦相似度。
式(5)中的V是词表,P(wj|ci)为单词wj在文本Tci中出现的概率,采用最大似然估计确定该概率,并用“加一”法进行平滑,如式(7)所示。
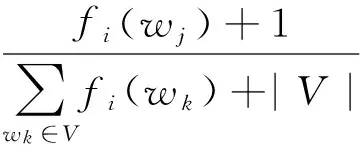
(7)
其中,fi(wj)为单词wj在Tci中出现的次数,|V|表示词表的大小。
对于P(C),文献[11]和[14]从信息编码的角度来惩罚块数多的分割(式(8))。
P(C)=n-m
(8)
考虑到摘要各个文本块(论述侧重点)的长度分布倾向于均匀的特点,本文在式(8)的基础上施加长度分布约束,惩罚长度分布倾斜的分割方案。为此,采用信息熵来度量文本块长度分布的均匀性大小,将信息熵引入到P(C)中,使得分割算法综合利用文本块内聚性、块间耦合性和长度分布均匀性来决策最优分割点的位置。改进的P(C)定义为式(9)。
(9)
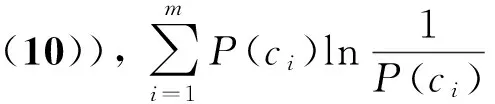
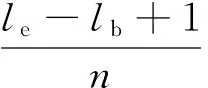
(10)
这样,本文算法将摘要文本分割归结为寻找满足下列条件的Cout:
(11)
其中,α是权重,用于调整长度分布均匀性约束相对于块内聚性和块间耦合性的重要程度。定义Δ(Tc1,Tc0)=0,则式(11)变成:
(12)
从式(12)很容易看出,T=S1S2…Sn任何分割方案C=c1c2…cm的得分值(即P(C|T))可以归结为每个块ci给定前一块ci-1情况下得分值的累加(见式(13)),因此可以采用动态规划方法来求解最优分割方案。
(13)
3.2 算法描述与分析
为了采用动态规划算法求解最佳分割,定义变量
(14)
该变量表示对于摘要T前j个句子的分割,最后一个文本块由第i个句子到第j个句子组成的分割中最佳分割的分值。此外,定义变量ψi,j来保存式(14)中的ik-1+1,即最佳分割中块ck-1的起始位置。
利用变量σi,j和ψi,j,基于动态规划求解式(12)中Cout的过程可以归结为下列递推计算。
(1) 初始化
计算由第1个句子到第j个句子组成的文本块的得分,1≤j≤n
σ1,j←Score([1,j]|c0))
ψi,j←-1 //-1表示之前没有别的块
(2) 递推
for(i=2;i≤n;i++){
for(j=i;j≤n;j++){
[k,i-1])]
[k,i-1])]
}
}
(3) 回溯读出最佳分割点
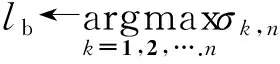
le←n//最后一块的起始句子编号
lnewb←ψlb,le//倒数第二块起始句子的编号
while(lnewb!=-1){
le←lb-1 //新当前块的结尾句子编号
lb←lnewb//新当前块的起始句子编号
lnewb←ψlb,le//前一块起始句子的编号
}
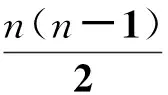
4 实验
4.1 数据集 为了对所提出算法的效果进行实验验证,本文从美国国家生物技术信息中心(National Center of Biotechnology Information)*http://www.ncbi.nlm.nih.gov/.收集了8 603篇分割好的摘要作为标准测试集。这些摘要被原始作者分割成四部分,分别用标签Background、Methods、Results、Conclusions表示,图1给出了其中的一篇。每篇摘要去除其中的分割标签后作为算法的输入,算法输出的分割位置与被去除的分割标签位置进行比对,从而判断算法分割是否正确。
4.2 评价指标
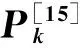
4.3 实验结果及分析
考虑到绝大多数科技文章的摘要都由四个文本块(背景、方法、结果、结论)组成,因此首先进行固定分割块个数m=4的实验,算法中的参数λ和α设为1,这种情况的实验结果见表1。
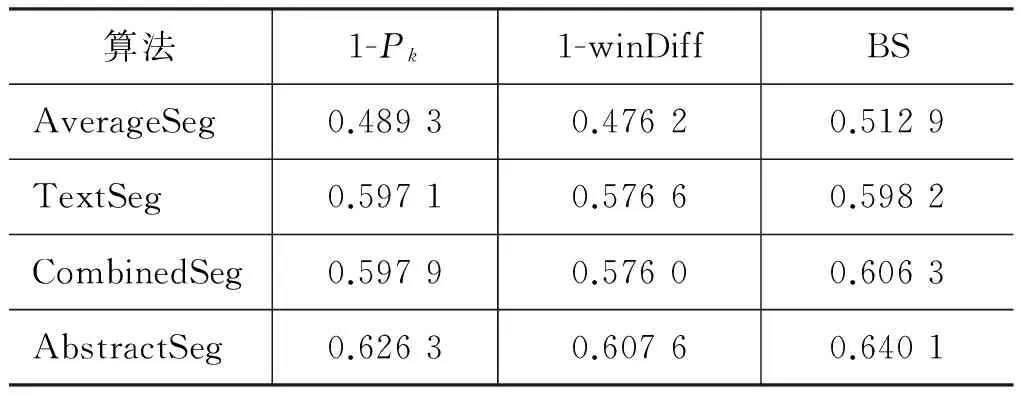
表1 固定分割块数目情况下的实验结果
从表1可以看出,对于摘要文本分割,在固定分割块个数的情况下,单纯基于长度分布均匀性约束的AverageSeg明显低于TextSeg、CombinedSeg和AbstractSeg,单纯依赖文本块内聚性的TextSeg不及兼顾内聚性和块间耦合性的CombinedSeg,本文提出的附加长度分布约束,综合考虑文本块内聚性和块间耦合性的AbstractSeg,在三种评价指标下都明显优于另外三个算法,说明本文提出的摘要文本块长度分布约束及基于熵的长度分布度量是有效的。与基于词分布的块内聚性和块间耦合性分析相结合,可以显著提高摘要文本分割的效果。
为了观察长度分布均匀性约束对分割效果的影响,我们实验了不同的α(α∈[0,16],λ=1),得到的结果如图2~4所示。由于固定文本块个数,P(C)对于TextSeg、CombinedSeg和AverageSeg不起作用,分割结果不受α影响,因此这三个图中TextSeg和CombinedSeg与AverageSeg都是直线。从这三个图可以看出,随着α值的增大,AbstractSeg的分割效果先逐渐上升,大约在α=5时达到峰值,然后逐渐下降,α=0时与CombinedSeg重合,此时AbstractSeg退化为CombinedSeg。
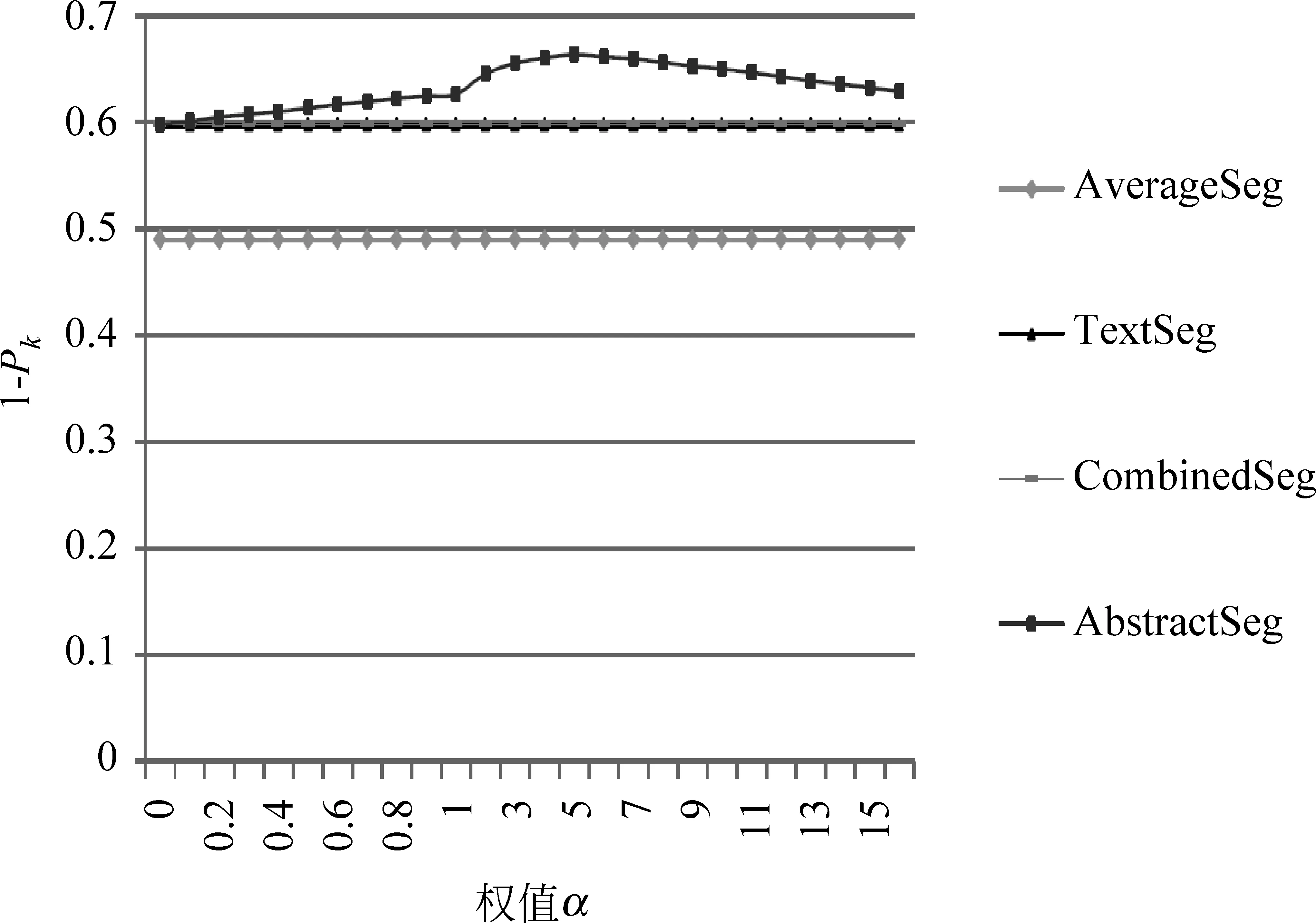
图2 随着α的增加,1-Pk的变化情况
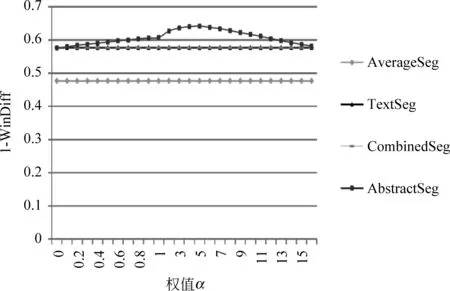
图3 随着α的增加,1-winDiff的变化情况
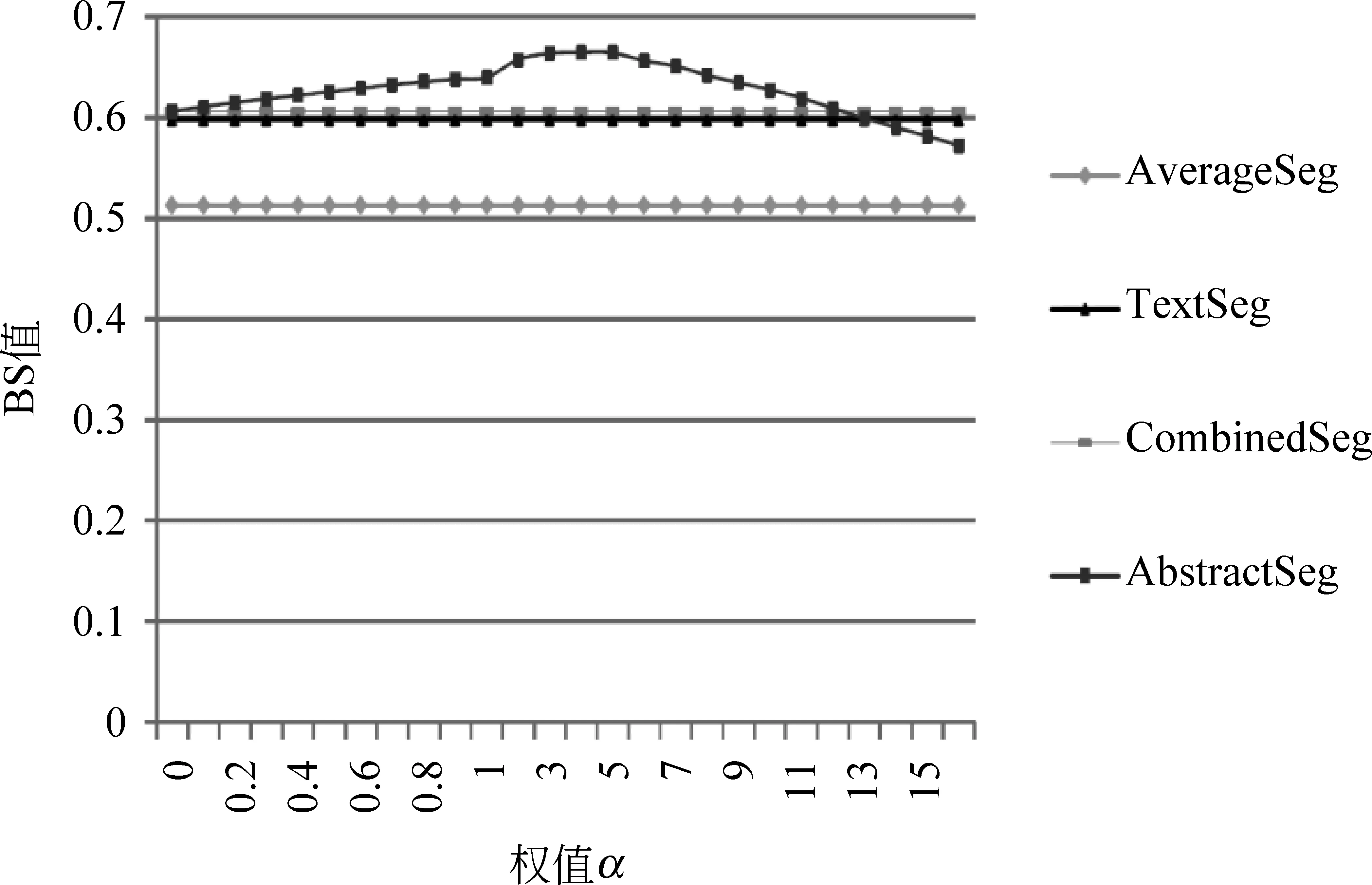
图4 随着α的增加,BS的变化情况
表2为不固定文本块数目情况下的实验结果,算法的参数λ和α的值仍然都设为1。如果不指定文本块个数,单纯基于长度分布均匀性约束的AverageSeg总是把每个句子单独分成一块,这使得AverageSeg无法使用。因此,表2相对于表1少了AverageSeg。从表2的实验数据很容易看出,即使不固定文本块个数,本文提出的算法AbstractSeg仍然明显优于TextSeg和CombinedSeg。
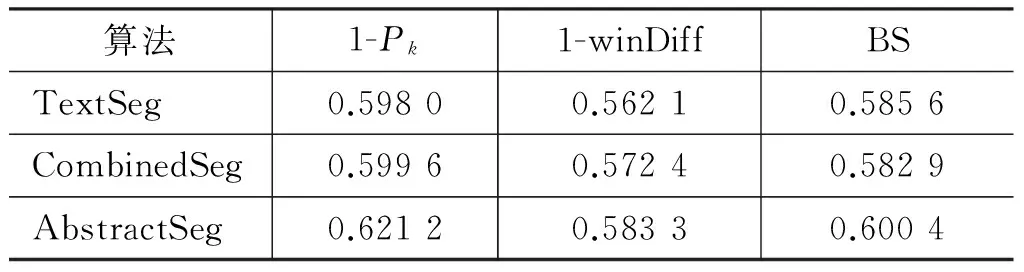
表2 不固定分割块数目情况下的实验结果
对比表1和表2可以发现,固定文本块个数情况下的分割效果优于不固定文本块个数的效果。在固定文本块个数的情况下,摘要应该分割成多少个文本块,即m,是已知的算法参数,例如本文实验用的Medline摘要均由四部分组成,因此固定文本块个数时设定m=4,此时算法只需要搜索固定个数的最优分割点序列。而不固定文本块个数时,m未知,算法需要同时优化分割点个数和分割点序列,面临的搜索空间更大,导致分割效果变差。
5 结论
本文针对现有无监督文本分割算法在用于摘要分割时面临的困难,基于摘要文本块长度的分布具有均匀性倾向这一特点,提出了基于长度分布约束的无监督摘要文本分割算法,该算法以信息熵作为块长度分布均匀性的度量指标,并综合度量文本块内聚性和块间耦合性,从而使摘要文本分割的效果显著提高。实验数据验证了本文算法的效果。作为下一步的工作,考虑利用一些时态特征及关键词在不同文本块出现的情况,提高算法的分割效果。
尽管实验验证是在英文Medline摘要文本上进行的,但是由于所用的文本特征与语言无关,因此,本文算法也应该适用于中文摘要文本分割。搜集中文摘要文本并进行人工分割形成测试数据集,在此基础上进一步测试本文算法对于中文摘要文本自动分割的效果,是下一步的工作内容之一。
[1] 刘娜, 唐焕玲, 鲁明羽. 文本线性分割方法的研究[J]. 计算机工程与应用, 2008, 44(21): 212-216.
[2] Liu Na, Tang Huanling, Lu Mingyu. Study on linear text segmentation method[J]. Computer Engineering and Applications, 2008, 44(21): 212-216.
[3] 童毅见, 唐慧丰. 面向自动文摘的主题划分方法[J]. 北京大学学报(自然科学版), 2013, 49(1): 39-44.
[4] Tong Yijian, Tang Huifeng. Topic partition for automatic summarization[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2013, 49(1): 39-44.
[5] Li X, Han A. An improved method of statistical model for text segmentation[C]//Proceedings of the IEEE Electronics Information and Emergency Communication(ICEIEC), 2013: 282-285.
[6] Wu J W, Tseng J C R, Tsai W N. A hybrid linear text segmentation algorithm using hierarchical agglomerative clustering and discrete particle swarm optimization[J]. Integrated Computer-Aided Engineering, 2014, 21(1): 35-46.
[7] McKnight L, Srinivasan P. Categorization of sentence types in medical abstracts[C]//Proceedings of the AMIA Annual Symposium Proceedings, 2003: 440.
[8] Lin R T K, Dai H J, Bow Y Y. Result identification for biomedical abstracts using conditional random fields[C]//Proceedings of Information Reuse and Integration Conference on IEEE, 2008: 122-126.
[9] 陈源, 陈蓉, 胡俊锋,等. 面向概括性小文本的文本分割算法[J]. 计算机工程, 2008, 34(22): 43-45.
[10] Chen Yuan, Chen Rong, HU Junfeng.Text segmentation algorithm oriented to small general-text[J]. Computer Engineering, 2008, 34(22): 43-45.
[11] Halliday M A K, Hasan R. Cohesion in English[M].London. Routledge, 1976.
[12] Jeffrey C, Reynar. An automatic method of finding topic boundaries[C]//Proceedings of the 32nd Annual Meeting on Association for Computational Linguistics, 1994: 331-333.
[13] Marie Francine Moens, Rik De Busser. Generic topic segmentation of document texts[C]//Proceedings of the 24th International Conference on Research and Developement in Information Retrieval, 2001: 418-419.
[14] Masao Utiyama, Hitoshi Isahara. A statistical model for domain-independent text segmentation[C]//Proceedings of the 39th Annual Meeting on the Association for Computational Linguistics, 2001: 499-506.
[15] Marti A Hearst. TextTiling: Segmenting text into multi-paragraph subtopic passages[J]. Computational Linguistics, 1997, 23(1): 33-64.
[16] Choi F Y Y. Advances in domain independent linear text segmentation[C]//Proceedings of the 1st North American chapter of the Association for Computational Linguistics Conference, 2000: 26-33.
[17] Simon A R, Gravier G, Sébillot P. Leveraging lexical cohesion and disruption for topic segmentation[C]//Proceedings of International Conference on Empirical Methods in Natural Language Processing, 2013.
[18] Beeferman D, Berger A, Lafferty J. Statistical models for text segmentation[J]. Machine Learning, 1999, 34(1-3): 177-210.
[19] Pevzner L, Hearst M A. A critique and improvement of an evaluation metric for text segmentation[J]. Computational Linguistics, 2002, 28(1): 19-36.
[20] Fournier, Chris. Evaluatingtext segmentation using boundary edit distance[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, 2013: 1702-1712.

骆俊帆(1990—),硕士,工程师,主要研究领域为自然语言处理。
E-mail: 244459939@qq.com

陈黎(1977—),博士,讲师,主要研究领域为数据挖掘、自然语言处理。
E-mail: cl@scu.edu.cn

于中华(1967—),通信作者,博士,副教授,主要研究领域为数据挖掘、自然语言处理。
E-mail: yuzhonghua@scu.edu.cn
A Length Distribution Constrained Text Segmentation for Paper Abstracts
LUO Junfan1, CHEN Li1, YU Zhonghua1, DING Gejian2, LUO Qian3
(1. Department of Computer Science, Sichuan University, Chengdu, Sichuan 610065, China;2. College of Mathematics, Physics and Information Engineering, Zhejiang Normal University, Jinhua, Zhejiang 321004,China;3. Information Technology Branch, The Second Research Institute, General Administration of Civil Aviation of China, Chengdu, Sichuan 610041,China)
1003-0077(2017)04-0138-07
TP393
A
