文献中的词语分布、词型等级和风格计算
2017-10-11马创新陈小荷
马创新,陈小荷
(1. 江苏师范大学 语言科学与艺术学院,江苏 徐州 221009; 2. 南京师范大学 文学院,江苏 南京 210097)
文献中的词语分布、词型等级和风格计算
马创新1,陈小荷2
(1. 江苏师范大学 语言科学与艺术学院,江苏 徐州 221009; 2. 南京师范大学 文学院,江苏 南京 210097)
文献的语言风格是作者在语言运用方面的思维定势的体现,对于文献之间语言风格的差异,以前的研究大多采用定性分析的方式加以比较和概括,而在文献检索和文本分类领域需要得到量化的语言风格相似度。该文首先分析文献中词语分布的普遍规律,以先秦八部经典文献为观察语料,发现这些文献中的词语既呈离散分布,又呈集中分布;然后通过计算文献之间词型等级的相关系数,来获取量化的语言风格相似度,构建了八部文献之间的相似度矩阵,验证了语言风格的差异不仅体现在使用的常用词上,还更细微地体现在常用词的使用频率等级上。
词语分布; 离散; 集中; 检索; 风格
Abstract: The language style of literature is the embodiment of the author’s mindset using language. For a quantitative analysis of the language style, this paper analyzes the word distribution in the pre-Qin literatures, collecting eight classic literatures as the corpus. The power-law distribution is again testified. Then the correlation coefficient of the word type grades between the literatures are calculated. We show that the language style differs not only in the use of common words, but also in the word types grade.
Key words: words distribution; dispersion; concentration; retrieval; style
收稿日期: 2016-07-11 定稿日期: 2017-02-23
基金项目: 江苏省社科基金(15YYC001);国家社科基金(15BYY096)
1 引言
人类行为由于受到思维定势的影响,会表现出相对固定的模式。思维定势是个体受到生活环境、知识背景和过往经验的影响而逐渐形成的相对稳定的思维方式,在一定的时期内,成为指导个体行为方式的固有模式。文献的语言风格就是作者在语言运用方面的思维定势的体现,是作者在遣词造句方面的个性特征。当作者在表达一个事物或者现象时,会有一系列的同类词语可供选择,有的词语会被经常选用,有的不常被选用。这种频度不均的选择本身使得被选词语的特征信息更加突出,又会反过来作为再次被选择的依据。如果把个体在表达一个事物或者现象时选用某个词语看作是这个词语的一次成功,那么这种成功的累积必然容易产生新的成功,这就逐渐形成个体在语言运用方面的思维定势[1]。
对于作品之间语言风格的差异,以前的研究大多采用定性分析的方式,加以比较、归纳和概括。那么,如何才能得到文献之间量化的语言风格相似度呢?这成为文献检索和文本分类领域亟需解决的关键问题。本文在分析文献中词语分布普遍规律的基础上,首次提出通过计算文献之间在词频等级方面的相关系数来尝试获取量化的语言风格相似度的方法。
2 相关研究
在词频等级的研究方面,布拉德福提出了一种在社会科学领域中应用广泛的重要研究方法,即频次-等级排序法。按某一具体事项在其主体来源中的出现频次按递减顺序排列起来,就会导出布拉德福分布。比如,如果把某篇文章中的词语按照其出现频次递减排列,就会呈现出布拉德福分布。布拉德福分布的特点显示出我们考察的具体对象的大多数集中于少数主体来源。比如,人们写文章时总是倾向于选择自己常用的词语。齐普夫定律[2]描述了词语的频率与等级序号之间的关系,发现任何一篇文章中词的频次和频次等级的乘积总是一个常数。孙清兰[3]研究高频、低频词界分公式,分析词频与同频词数量的内在规律。
在计算语言风格的研究方面,徐秉铮等[4]从词的相关性和上下文的相关性、字符数的统计、字符串的统计等三方面判断《红楼梦》前八十回与后四十回的语言风格有明显的不同。日本学者金明哲[5]采用基于词性组合的统计分析方法,使用以字符为单位的unigram 和以词性为单位的n-gram 作为特征,分析文本的语言风格。武晓春等[6]依据文体学理论,利用HowNet知识库,提出一种基于词汇语义分析的相似度评估方法,有效利用了功能词以外的其他词汇,达到了较好的作者身份识别性能。王少康等[7]基于对句长的统计构建段长的序列组合,分析写作风格,利用不同作者写作时在文章语句节奏控制方面的特点,对十位作家进行识别分类。陈芯莹等[8]对两个语料样本进行统计分析,从中总结出句长、型例比、名词比例、代词比例、标点符号比例、感叹句比例、单现词比例等七个具有显著分布差异的语言结构特征,并以这些特征作为文本的表示特征对两个未知作家文本进行了相关系数统计和分析,准确地判定了这两个文本的作者。
3 文献中词语分布的普遍规律
为了考察文献中的词语分布规律,我们选取了八部先秦经典文献作为观察语料。这八部文献中包含三部儒家著作: 《论语》、《孟子》、《荀子》;两部道家著作: 《老子》、《庄子》;两部法家著作: 《韩非子》、《管子》;一部墨家著作: 《墨子》。我们首先对这八部文献作了人工分词处理,然后再考察它们的词语分布状况[9-10]。通过对文献中出现的词语进行排序、统计和比较,我们发现文献中的词语分布普遍存在两个相互对立而又统一的规律,即离散分布和集中分布。
3.1 离散分布
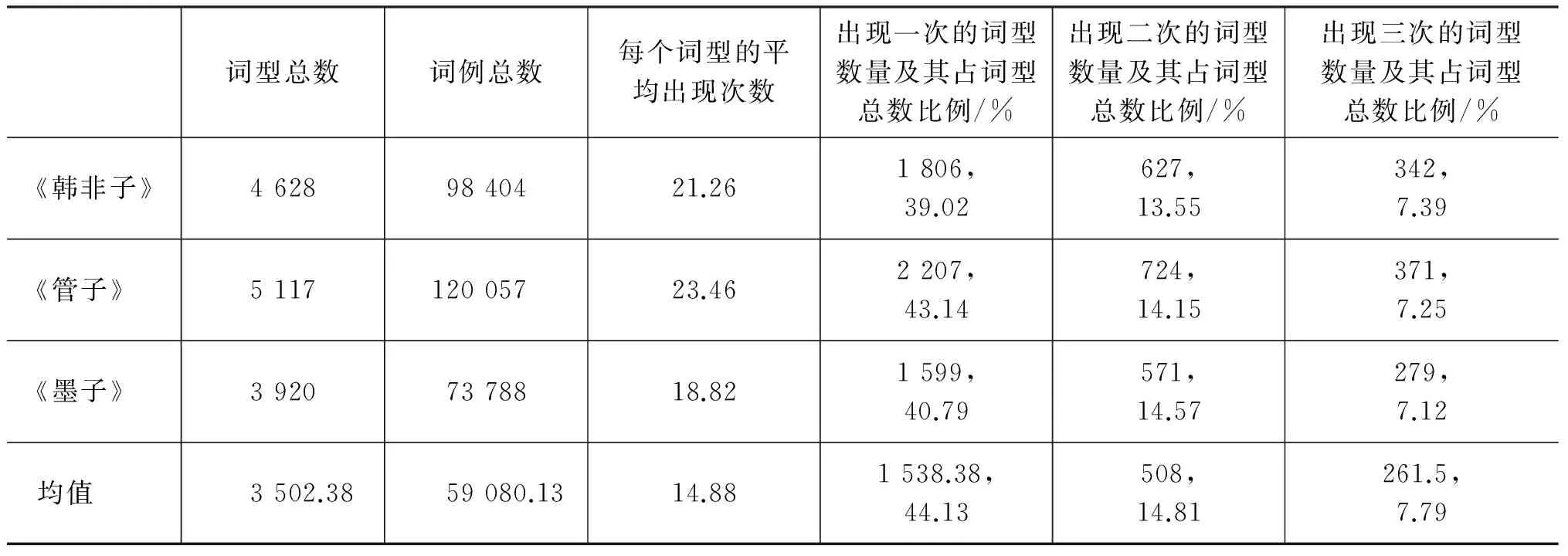
词型(word types)是指词表中所包含的一个个词语条目,词例(word tokens)是指某个词型在特定语料中的使用实例,如果某个词型被多次使用,这个词型就会有多个词例。我们首先统计了文献中出现的词型总数和词例总数(词例总数等于所有词型的出现次数之和),再把各个词型按照其出现次数(即各个词型的词例数)从高到低排序[11-12],我们发现各个文献中出现一次的词型数占总词型数的比例是基本相同的,全都呈现出极具规律性的离散分布。如表1所示。
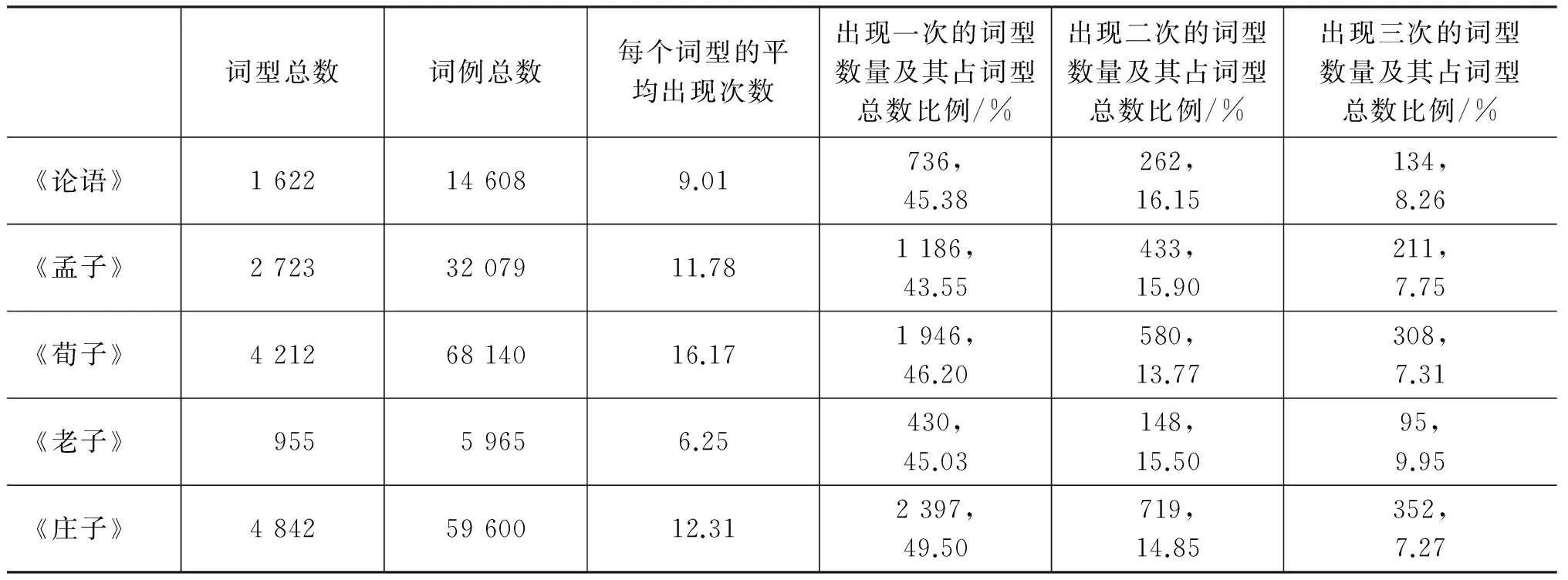
表1 文献中词语的离散分布情况
续表
分析表1,发现如下特点。
(1) 在各部文献中,词型的平均出现次数差异很大,在6.25次~23.46次之间,均值为14.88。在《老子》中每个词型平均出现次数最少,为6.25次,《管子》中每个词型平均出现次数最多,为23.46次,这两个文献中的每个词型平均出现次数相差17.21次。
(2) 在各个文献中,“仅出现一次的词型数量”与“词型总数”之比是相近的,在39.02%~49.50%之间,均值为44.13%,全距为10.48%。“仅出现两次的词型数量”与“词型总数”之比也是相近的,在13.55%~16.15%之间,均值为14.81%,全距为2.6%。“仅出现三次的词型数量”与“词型总数”之比也是相近的,在7.12%~9.95%之间,均值为7.79%,全距为2.83%。
(3) 文献中出现的大量词型是呈离散分布的。在这八部文献中,平均44.13%的词型仅出现一次,14.81%的词型只出现两次,7.79%的词型仅出现三次。也就是说,仅出现一次、两次和三次的词型就占了词型总数的66.73%。
(4) “词型的出现频次”与“出现该频次的词型数量”之间基本上呈负相关趋势。为了能够得到准确的分析结果,我们统计了《孟子》中出现频次在1~20次之间的词型数量,统计结果如表2所示。其中,出现一次的词型数量为1 186,出现二次的词型数量为433,出现三次的词型数量为211, ……词型的出现次数越多,出现相同频次的词型数量就会越少,例外情况极少,两者之间基本上呈负相关关系。
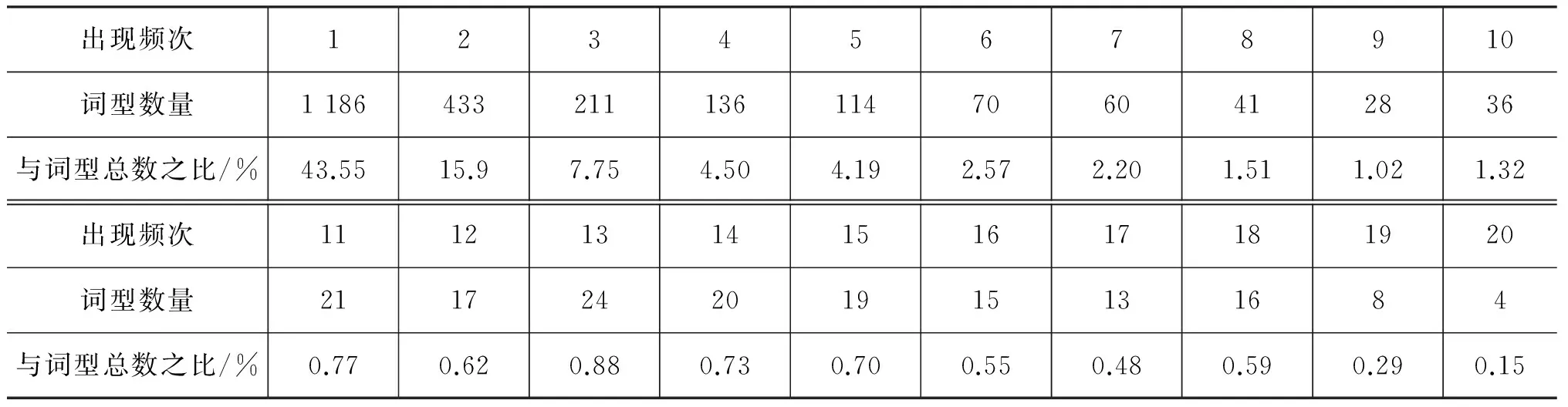
表2 “词型的出现频次”与“出现该频次的词型数量”之间关系
3.2 集中分布
我们分别统计文献中出现频次排前5%、10%、15%、20%的词型的出现频次之和,计算它们占词例总数的比例,把数据汇总起来,形成表3。
通过对表3的分析,发现如下特点:
(1) 在各个文献中,虽然出现的词型总数和词例总数相差很大,但在各个文献中“出现频次排前5%的词型的出现频次之和”与“词例总数”之比是相近的,在51.92%~72.21%之间,均值为66.75%,全距为20.29%。“出现频次排前20%的词型的出现频次之和”与“词例总数”之比更加相近,在77.23%~92.12%之间,均值为87.13%,全距为14.89%。

表3 文献中词语的集中分布情况
(2) 在各部文献中,词语均呈现出集中分布的状况,“出现频次排前5%的词型的出现频次之和”就占“词例总数”的66.75%左右,“出现频次排前20%的词型的出现频次之和”占到“词例总数”的87.13%左右,呈现出高度集中的状况。
我们还分别统计了文献中出现频次排在前400位、500位、600位、700位、800位、900位的词型出现频次之和,并且计算频次之和与词例总数的比率,把数据汇总起来,形成表4。通过分析,我们发现虽然各部文献中出现的词型总数和词例总数相差很大,比如《管子》中出现的词型总数是《老子》的5.36倍,出现的词例总数更是相差20多倍。但是在各部文献中,“出现频次排在前400位的词型的出现频次之和” 与“词例总数”的比率却是非常相近,在78.84%~88.70%之间,均值为82.03%,全距为9.86%。
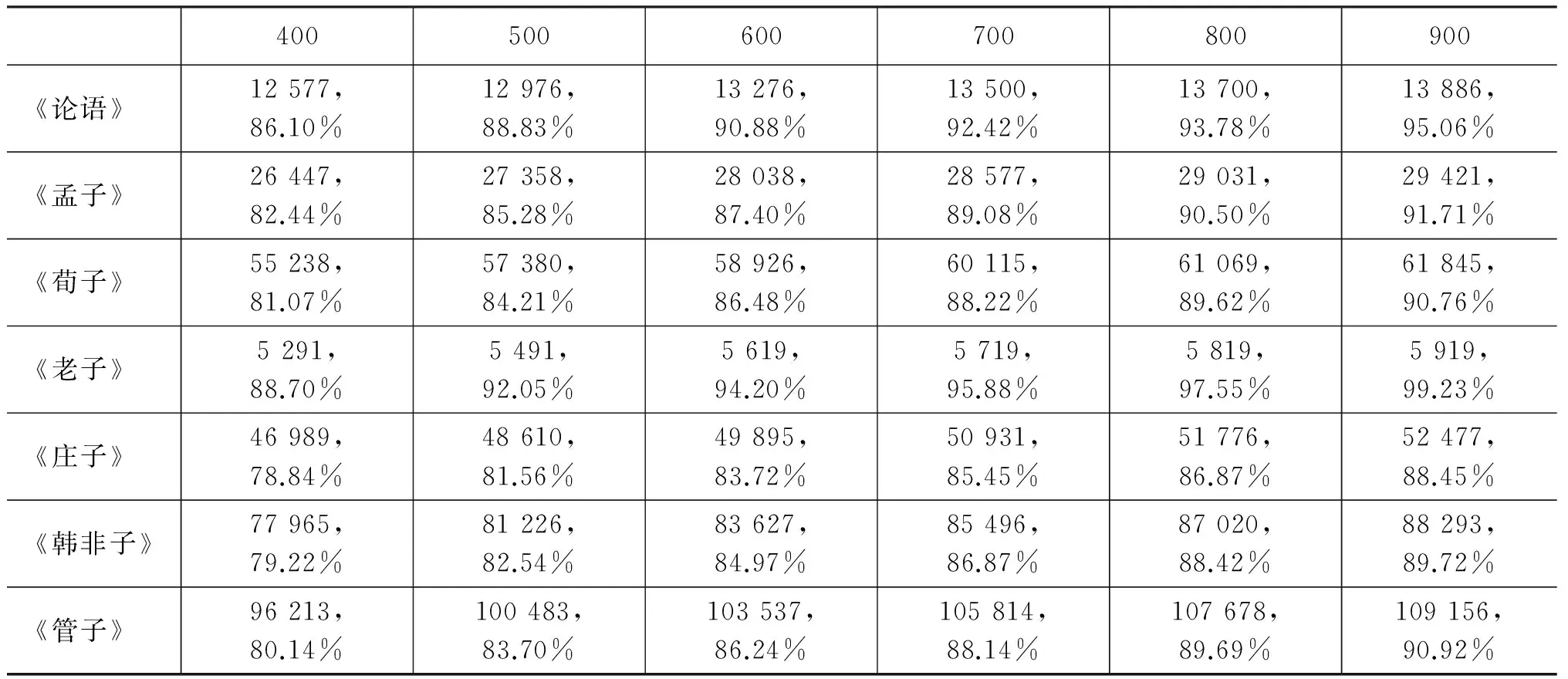
表4 出现频次排在前列的词型出现频次之和及其与词例总数之比

续表
另外,文献中的词语分布呈现高度集中的状况,“出现频次排在前400位的词型的出现频次之和” 就占到“词例总数”的82.03%左右,“前500位的词型的出现频次之和”占到“词例总数”的85.27%左右,“前600位的词型的出现频次之和”占到“词例总数”的87.54%左右,“前700位的词型的出现频次之和” 占到“词例总数”的89.30%左右,“前800位的词型的出现频次之和”占到“词例总数”的90.79%左右,“前900位的词型的出现频次之和”占到“词例总数”的92.11%左右。
3.3 小结
文献中的词语既呈现离散分布,又呈现集中分布,并且离散分布是绝对的,集中分布是相对的。从低频词的词型方面看,词语在文献中呈现离散分布,在本文考察的八部文献中,平均44.13%的词型仅出现一次,14.81%的词型只出现两次,7.79%的词型仅只出现三次;从高频词的词例方面看,词语在文献中呈现出高度集中的分布状况,“出现频次排前20%的词型的出现频次之和”占到“词例总数”的87.13%左右,“出现频次排在前400位的词型的出现频次之和”就占到“词例总数”的82.03%左右。“前900位的词型的出现频次之和”占到“词例总数”的92.11%左右。
我们认为齐普夫所提出的“最小努力原则”可以解释这种词语分布状况。齐普夫发现自然语言的词汇使用服从“最小努力原则”这个定律,就是当人们用语言表达思想时,同时受到“单一化的力”和“多样化的力”的共同作用,说话者希望尽量简短,只用一个词表达要领最为省力,而听话者希望尽量详尽,每个概念都用一个词表达,理解起来最为省力。这两者的相互作用,取得平衡,使自然语言的词汇出现频次双曲线。
4 语言风格的相似度计算
4.1 词型等级的确定方法 如何确定词型的等级是一个非常重要的问题。一般情况下,“词型等级”是按照词型在文献中的出现频次(即词型的词例数)以递减顺序排列,把出现频次最高的词型等级定为1,次高的词型等级定为2,依次类推。然而,还有大量的同频词型存在,如何确定同频词型的等级,国内外学者提出过四种方法[13-14]。
(1) 并列法。把同一频次的词型都当作一个词型对待,以其在文献中词频序值为等级。
(2) 最大值法。对同一频次的词型排序,排法任意,取它们在文献中序值的最大值作为这些词型的等级。国内外语言研究者一般认为齐普夫定律采用的是这种确定等级的方法。
(3) 最小值法。对同一频次的词型任意排序,取它们在文献中序值的最小值作为这些词型的等级。
(4) 平均值法。对同一频次的词型任意排列,取这些同频词在文献中序值的算术平均数作为它们的等级。
表5以《孟子》中出现频次排前30位的词型为例,对比了这四种词型等级的确定方法。

表5 词型等级的确定实例(以《孟子》中出现频次排前30位的词型为例)

续表
4.2 相似度的计算方法
本文通过计算文献之间词型等级的相关系数,来估量文献之间语言风格的相似度。相关系数是统计学中广泛使用的一种量数,它表示两组变量之间联系的强度。根据研究目的和研究数据的不同,选择不同的相关系数计算方法[15-16]。当研究数据是具有等级性质的顺序变量,数据的总体分布不是正态分布时,可以计算数据的“斯皮尔曼等级相关”,它是英国统计学家、心理学家斯皮尔曼根据积差相关的概念推导出来的。斯皮尔曼等级相关的计算如式(1)。

(1)
其中Di表示每一对数据相应的两个等级之差,n表示样本数。
斯皮尔曼等级相关适用于研究数据是具有等级性质的成对数据,并且变量之间呈线性关系。但是,文献之间出现的词型数据并不是成对的,从表1可见,各部文献中出现的词型数量差异很大,比如,《论语》中出现1 622个词型,《孟子》中出现2 723个词型,不仅词型数量不同,而且《论语》中出现的1 622个词型在《孟子》中也不一定都会出现。所以,我们不能照搬斯皮尔曼等级相关来计算词型等级的相似度,需要对原公式作一些改进和限定。
我们用ARs来表示“以文献A中词型为样本”与文献B比较所得到的相关系数,对于在文献A中出现而文献B中没有出现的词型,不放在计算范围内。同样,以BRs来表示“以文献B中词型为样本”与文献A比较所得到的相关系数,对于在文献B中出现而文献A中没有出现的词型,也不在计算范围内。
由于语言风格体现在常用的词语和句式中,并且从3.2节我们得知文献中“出现频次排在前400位的词型的出现频次之和”就占到“词例总数”的82.03%左右。所以,本文选取在文献中出现频次排在前400、500、600、700、800、900位的词型作为样本。当然,采用这种计算方法所得到的相关系数是一个近似值。
例如,以《论语》中出现频次排在前400位的词型作为样本,计算它们与《孟子》中对应词型的等级相关性,首先要计算这400个词型在《论语》和《孟子》中的词型等级差,对于没有在《孟子》中出现的词型不作统计,然后再使用斯皮尔曼等级相关公式计算它们相关系数。
我们假定为词型等级的相关系数就是语言风格的相似度,文献A与B的语言风格相似度用ABRs来表示,ABRs等于ARs与BRs的均值,即: ABRs=(ARs+BRs)/2。也就是说,文献A与B的语言风格相似度就等于“以文献A中词型为样本”与文献B比较所得到的相关系数,加上“以文献B中词型为样本”与文献A比较所得到的相关系数,两个系数之和再除以2所得到的商。
4.3 实验和分析
为了验证本文所提出理论和方法的有效性,我们选取《论语》作为参照文献,采用“并列法”确定词型等级,计算《论语》的折半相似度(所谓折半相似度,即把《论语》均分成两部文献,再计算这两部文献的相似度),以及《论语》分别与另外七部文献之间的风格相似度。实验数据如表6所示,表6中第一行的“400”表示选取文献中出现频次排在前400位的词型作为样本,依此类推,500、600、700、800和900也表示同类含义。
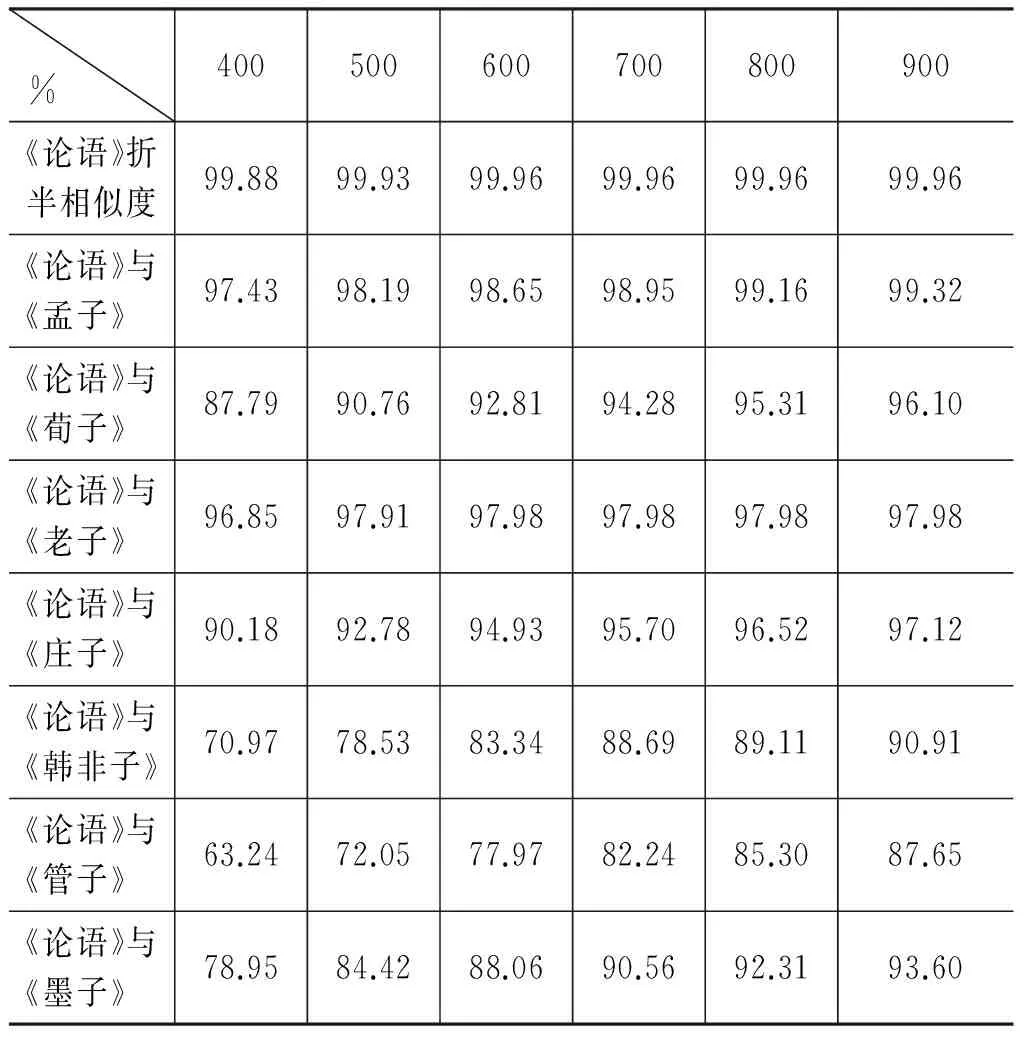
表6 以《论语》为参照的相似度数据
观察表6中的数据,可以发现如下特点。
(1) 《论语》的折半相似度高于《论语》与其他任一文献之间的相似度。
(2) 《论语》作为儒家文献,与其他两部儒家文献之间的相似度较高,与道家文献的相似度也比较高,与法家、墨家文献的相似度比较低。
(3) 选取的词型样本数越多,相似度越大。比如,在选取频次排在前400位的词型作为样本时,《论语》《管子》的相似度是63.24%,选取前500位的词型作为样本时,相似度是72.05%,选取前600位的词型作为样本时,相似度是77.97%,随着选取样本数的增加,相似度也在增加。
(4) 无论选取多少个词型样本,不管是400个、500个,还是900个,相似度的高低顺序是相同的。按照相似度由高到低排列,依次是: 《论语》折半相似度、《论语》与《孟子》、《论语》与《老子》、《论语》与《庄子》、《论语》与《荀子》、《论语》与《墨子》、《论语》与《韩非子》、《论语》与《管子》。
(5) 随着样本数的增加,相似度之间的差距在缩小。比如,在选取频次排在前400位的词型作为样本时,《论语》折半相似度是99.88%,《论语》与《墨子》相似度是78.95%,两个相似度之间的差距是20.93%;而在选取频次排在前500位的词型作为样本时,两个相似度之间的差距是15.51%;选取前600位的词型作为样本时,两个相似度之间的差距是11.09%,差距都是越来越小。
以上的观察,证明了本文所提出的方法是能够有效测量文献之间语言风格相似度的。
为了能够更全面地分析八部先秦经典文献之间的风格相似度,我们采用并列法确定词型等级,全部选取频次排在前500位的词型作为样本,分别测量八部文献两两之间的相似度,以及它们各自的折半相似度,形成如表7所示的相似度矩阵[17]。
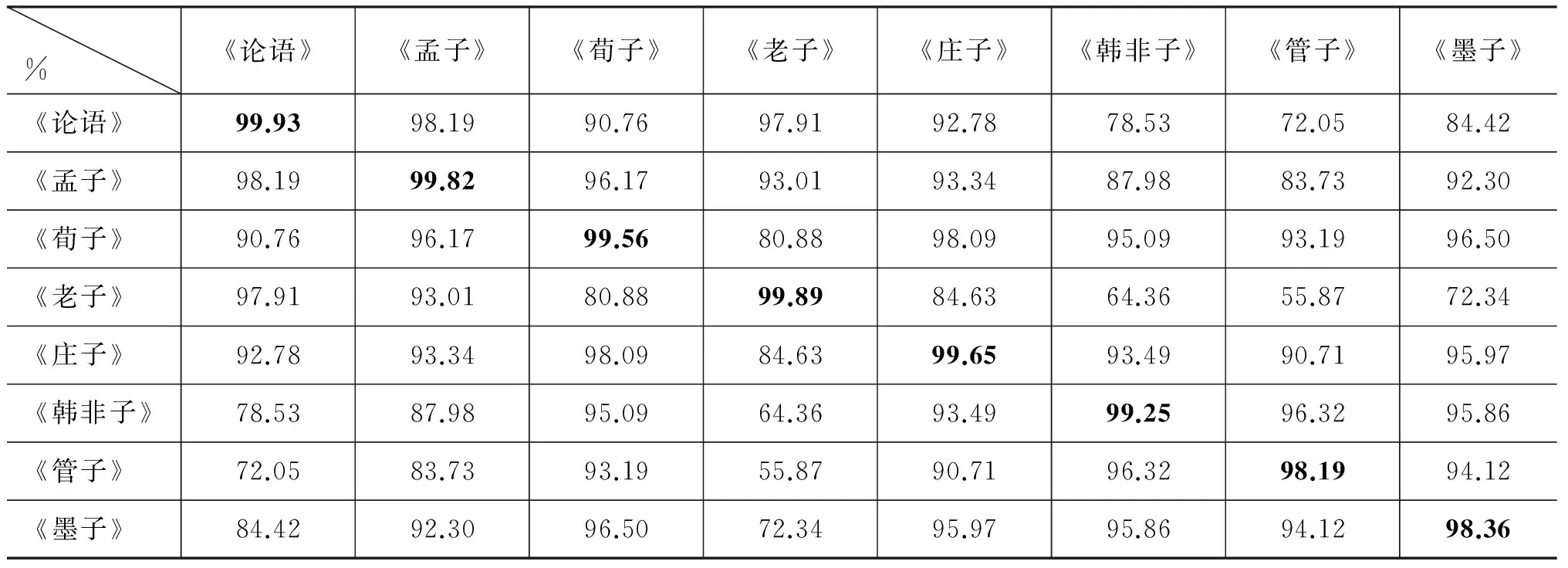
表7 八部文献之间的相似度矩阵
表7中黑体加粗的数字表示的是文献自身的折半相似度,比如第二行第二列的99.93%就是《论语》的折半相似度,第三行第三列的99.82%是《孟子》的折半相似度,依此类推。观察表7,我们能够得到如下规律:
(1) 文献的折半相似度总是高于该文献与其他文献之间的相似度。例如,《墨子》的折半信度为98.36%,高于《墨子》与其他任一文献之间的相似度;
(2) 同一学术流派内文献之间的相似度一般高于流派之间文献的相似度。例如,《论语》与《孟子》的相似度为98.19%,《韩非子》与《管子》的相似度为96.32%。
5 结语
本文分析了文献中词语分布的普遍规律,提出通过计算文献之间词型等级的相关系数,来获取量化的语言风格相似度。实验证明,我们提出的方法是切实可行的,并且还验证了文献语言风格的差异不仅体现在使用的常用词上,还更加细微地体现在常用词的使用频率等级上。
本文提出的方法,除了用于测量语言风格的相似度,还具有一些其他用途[18],比如本方法对于文献的自动分类具有辅助作用,同一流派、同一体裁,或者同一时代的文献之间语言风格相似度会高于其他文献之间的相似度。此外,本方法还可作为鉴定文献作者的辅助方法,古代的一些文献的作者难以认定,当今学者有着不同的看法,那么可把“存疑文献”分别与多位作者的“确认文献”进行对比,估量文献之间在词型等级方面的相似度,这能够为辨别“存疑文献”的作者提供参考信息。
[1] 靖继鹏,马费成,张向先. 情报科学理论[M].北京: 科学出版社,2009: 33-50.
[2] G.K.Zipf, Human behavior and the principle of least effort[M], 1949: 5-12.
[3] 孙清兰. 高频、低频词的界分及词频估计方法[J]. 情报科学,1992,13(2): 28-32.
[4] 徐秉铮,蔡伟鸿. 从信息论角度探讨《红楼梦》的作者[J].中文信息学报,1990,4(2): 1-5.
[5] 金明哲.中文文章的作者识别[R].第二届中国社会语言学国际学术研讨会暨中国社会语言学会成立大会,2003.
[6] 武晓春,黄萱菁,吴立德.基于语义分析的作者身份识别方法研究[J].中文信息学报,2006,20(6): 61-68.
[7] 王少康,董科军,阎保平.基于语句节奏特征的作者身份识别研究[J]. 计算机工程, 2011,37(9): 4-5.
[8] 陈芯莹,李雯雯,王燕. 计量特征在语言风格比较及作家判定中的应用: 以韩寒《三重门》与郭敬明《梦里花落知多少》为例[J]. 计算机工程与应用, 2012,48(3): 137-139, 208.
[9] 石民,李斌,陈小荷. 基于CRF的先秦汉语分词标注一体化研究[J]. 中文信息学报,2010, 24(2): 39-45.
[10] 段磊,韩芳,宋继华. 古汉语双字词自动获取方法的比较与分析[J]. 中文信息学报,2012,26(4): 34-42.
[11] 史存直.汉语词汇史纲要[M].上海: 华东师范大学出版社,1989: 79-96.
[12] 潘允中.汉语词汇史概要[M].上海: 上海古籍出版社,1989: 1-15.
[13] 刘伟成,孙吉红. 跨语言信息检索进展研究[J]. 中国图书馆学报,2008(1): 88-92.
[14] Booth, A.D. A law of occurrences for words of low frequency[J],Information and control, 1967,10(4): 386-393.
[15] Michel J B, Yuan K S, Aiden A P, et al. Quantitative analysis of culture using millions of digitized books[J].Science, 2011,331(6014): 176-182.
[16] 罗德里克·弗拉德.计量史学方法导论[M]. 王小宽,译. 上海: 上海译文出版社,1997: 50-60.
[17] 陆宇杰,许鑫,郭金龙. 文本挖掘在人文社会科学研究中的典型应用述评[J]. 图书情报工作,2012(8): 18-25.
[18] 马创新,陈小荷. 基于引文分析的古籍文献影响力评估[J]. 大学图书馆学报,2016(1): 16-24.

马创新(1980—),博士,讲师,主要研究领域为计算语言学、知识组织。
E-mail: machxin@126.com

陈小荷(1952—),博士,教授,博士生导师,主要研究领域为计算语言学、汉语语法学。
E-mail: chenxiaohe5209@126.com
Word Distribution, Word Type Grades and Style Computing in Literatures
MA Chuangxin1, CHEN Xiaohe2
(1. Linguistic Sciences and Arts School, Jiangsu Normal University, Xuzhou, Jiangsu 221009, China; 2. College of Liberal Arts, Nanjing Normal University, Nanjing, Jiangsu 210097, China)
1003-0077(2017)04-0020-08
TP391
A
