基于网络结构的多种用户影响力分析算法对比研究
2017-10-11陈毅恒李雪婷
陈毅恒,李雪婷,王 彪,刘 挺
(1. 哈尔滨工业大学 计算机科学与技术学院信息检索研究中心,黑龙江 哈尔滨 150001;2. 哈尔滨工业大学 图书馆信息咨询部,黑龙江 哈尔滨 150001)
基于网络结构的多种用户影响力分析算法对比研究
陈毅恒1,李雪婷2,王 彪1,刘 挺1
(1. 哈尔滨工业大学 计算机科学与技术学院信息检索研究中心,黑龙江 哈尔滨 150001;2. 哈尔滨工业大学 图书馆信息咨询部,黑龙江 哈尔滨 150001)
随着社交网络的发展,人们可以非常平等、快捷地发布和接受信息,这导致线上生活对线下生活的影响越来越大。社会化营销应运而生,其非常重要的一个需求是要最大化营销活动在社交网络中的影响力。因此,社交网络中用户影响力分析成为一个至关重要的研究点。该文重点考察了基于网络结构的影响力分析方法,主要包括最大度算法、距离中心点算法、类似PageRank算法的PeopleRank算法等,并给出了具体的分析结论。
用户影响力分析; 网络结构; 社交网络; 微博
Abstract: The analysis of the user influence in the social network is a key research issue in social marketing. This paper is focused on several network structure based algorithms for user influence analysis, and conducts a contrastive study on their performances.
Key words: user influence analysis; network structure; social network; chinese microblog
1 引言
在当前的社交网络大潮中,通过社交网络来销售自己的产品成为传统行业所做的积极尝试。人们发现,对于一些新的产品或者思想,总是由少数几个人首先接受,然后将其传播到整个社交网络中去。于是,常用的一种营销手段就是,在某个潜在客户群体中找一些人,给予他们一定的优惠或者试用机会,争取得到他们的推荐,进而将新产品或者思想传播到整个潜在客户群体中去。对于这种营销手段来说,产品的质量和创新或者价格的优惠是影响最终效果的一个方面,另一个非常重要的方面就在于,应该选择社交网络中的哪些人,才能最大 化 地 影 响 潜
在客户群体。本文主要着眼于社会化营销这一新兴市场需求,通过研究社交网络中用户的影响力,着力解决如何选出合适的用户以达到市场营销的目的。挖掘社交网络中有影响力的用户,或者对用户的影响力进行量化和排序,对于信息检索、信息推荐和社区挖掘等各方面的研究都是十分有利的。
在信息检索领域,我们需要对网页进行排序,所用的排序算法利用了节点与节点之间的链接关系。事实上,网页之间的相互链接关系与微博这种社交网络中用户与用户之间关注或者粉丝的关系是非常相似的。研究者们很早便将这种用于网页排序的算法应用到社交网络中来。基于此,将这些算法引入到微博网络中并分析各种算法的结果表现,非常值得尝试。
本文将着眼于影响力的排序算法,基于微博的网络结构,在不考虑任何文本特征的情况下,对比使用最大度算法[1]、距离中心点算法[2]、平均转发率和改进的PageRank算法——PeopleRank算法的排序结果。并对几种算法的结果进行分析,说明不同场合下算法的表现。
2 相关研究
2.1 面向信息检索领域的网络节点重要度计算方法 与用户影响力比较近似的是面向信息检索领域的节点重要度的计算方法。信息检索领域在对检索结果进行排序的过程中,产生了对于网页权威度或者说重要度进行评价的需求。实际上,这就是一个有向图中计算节点重要度的需求。
Kleinberg等人提出了一种网页重要性的分析的算法[3],算法对每个页面计算两种值,一个是枢纽值(hub scores),另一个是权威值(authority scores)。这两个值是相互依存、相互影响的。这个算法就是著名的HITS算法。Page等人在1999年提出一种基于网页间相互链接关系的网页重要度计算方法,称为PageRank[4]。PageRank 并不计算直接链接的数量,而是将从网页 A 指向网页B的链接解释为由网页A对网页B所投的一票。这样,PageRank会根据网页B所收到的投票数量来评估该页的重要性。Haveliwala等人又对通用性的PageRank算法做了进一步的变形[5],使得网页排序算法不仅要考虑网页之间的链接,还加进了对正文上下文和主题的考虑。
HITS和PageRank及其衍生算法出现之后,人们发现其不仅可以用来评价网页的重要度,也可以用于评价社交网络中的成员的重要性。Zhang等人在一个Java主题的社区网站中,尝试使用HITS等多种方法来评价用户权威度[6]。Qin等人[7]和Xu等人[8]基于PageRank算法的核心思想,在犯罪网络中做了评价网络成员重要性的尝试。
2.2 针对社交网络中用户影响力的研究
Cha等人[9]提出了三个影响力评价指标,并对三者进行了对比研究: indegree(入度,即粉丝数),retweets(转发)和 mentions(提及)。作者用三个指标分别对5 400万用户排序,分析各个指标之间的情况得出结论: 被提及多的人,被转发也多。但是粉丝数却和其他两个指标没有什么关系。由此可以看出,粉丝数多的人不一定影响力大。作者同时研究了影响力随话题的变化规律。结论是最有影响力的人可以在各种话题中发挥影响力。Romero等人[10]的着眼点还是影响力的指标,其他人的工作大多考虑的是影响者的influence,而没能考虑被影响者的passivity (忠诚度)。作者提出综合influence和passivity来判断一个用户的影响力。Weng等人[11]首先对Twitter用户分析: 72.4%的用户关注了其80%以上的粉丝,80.5%的用户获得了其关注者80%的回粉率。基于这个发现,作者提出一个算法TwitterRank——基于PageRank,考虑话题相似性及网络拓扑结构。Huang等人[12]研究了口碑推荐与用户后续的评价之间的关系,并发现了反直觉的现象,这二者之间是有着关联关系的。作者建立了一个框架来衡量个人的社会影响力,即衡量这个人的粉丝数及对新鲜事物的敏感度,且研究出一套方法来识别个人能够影响的好友数。Singer等人[13]试图在社交网络中识别出一个个人的小集合,这些集合中的人可以作为新产品或新技术最早的接受者,并且在社交网络中能够触发出一个爆发式的传播。Bhagat等人[14]在社交网络中度量产品能被最大程度接受的量,提出了新颖的方法研究产品最大接受率,接近病毒式传销的应用,并且在电影社交网站和音乐社交网站上都取得了不错的效果。还有研究者将用户行为融入模型中,来分析用户影响力,如Wang等人[15]将用户行为融入随机游走算法中,Huang等人[16]将用户行为融入PageRank算法中,Bi等人[17]不仅只考虑用户之间的链接关系,还考虑用户发布的具体内容,来分析微博中的用户影响力。
3 基于用户本身特性的用户影响力分析
3.1 用户节点特性的选择 在评价用户影响力的算法中[9],最直接的便是通过统计节点本身的某些特性来推断其影响力。从社交网络中用户影响力分析的需求来看,我们最需要选择的是那些可以引起其他人反应的用户,比如转发和评论。这就决定了那些越是可以把自己的消息送到最多的人面前的用户,影响力越大。我们可以使用社会学研究者们经常使用的影响力评价算法: 最大度算法[1]和距离中心点算法[2]。
最大度算法的一个最基本的假设是,越是拥有更多跟其他节点链接的节点,越是可能让更多人看到自己所发布的信息。因此,一个朴素的想法是,社交网络中度数越大的节点,其影响力也越大。即:
inf(v)=d(v),v∈N
(1)
距离中心点算法的一个基础假设为: 社交网络中的节点,如果可以以更短的路径到达其他节点,那它应该有更高的机会来影响其他节点。考察网络中某个节点到达其他节点所需的路径长度,也可以是衡量其影响力的一个方法。即:
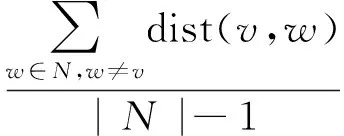
(2)
其中dist(v,w)是指网络中两个节点之间的最短距离。
除了以上两种方法之外,我们还可以根据微博用户中微博被转发的历史记录计算其每条微博的平均被转发率,以每条微博引起的转发行为作为其影响力的一种体现。即:
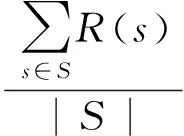
(3)
其中S为v的所有微博的集合。
3.2 基于节点特性的用户影响力算法
对于最大度算法,我们采用最简单的方式。统计某位用户有多少领域内的粉丝(入度)。具体算法如算法1所示。

算法1 最大度影响力算法
对于距离中心点算法,要计算每个节点的影响力,需要计算到达某个节点的平均路径长度。也即每个节点通过关注到此节点的评价路径长度,如算法2所示。

算法2 距离中心点算法
对于用户平均转发率的计算,如算法3所示。

算法3 计算用户平均转发率的算法
续表

3.3 基于PeopleRank算法的用户影响力分析
前文已经探讨了距离中心点算法,主要考虑影响其他节点的距离。事实上,在信息检索领域的网页权威度算法PageRank算法能够更好地描述一个节点在整个网络中的重要程度。本节将借鉴PageRank算法的主要思想,计算微博网络中用户的影响力。基于以上想法,我们设计了PeopleRank的公式,如式(4)所示。
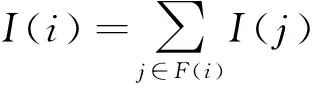
(4)
但是仔细分析就会发现,式(4)中有一个缺陷: 无论j关注了多少用户,只要j关注了i,i都将得到与j一样的影响力。当j关注了多个用户时,这个思想就会造成不合理的情况。例如,一个新加入的用户x获得了两个人的关注,一个是行业里早已存在的意见领袖f,另一个是很不知名的用户u。根据上面的公式,就会得到这个新加入的用户x比意见领袖f影响力更大的结论。这个结论显然不符合人们的常识。
弥补这个缺陷的一个简单方法是当j关注了多个用户时(假设个数为N),其每个关注用户得到其影响力R(j)/N(j)。如式(5)所示。
(5)
F(i)为i的粉丝用户集,N(j)为用户j的关注数目。
为了得到更加贴近现实情况的结果,我们在上面公式的基础上增加一个常数c,得到最终的公式,如式(6)所示。
(6)
其中的c为阻尼系数,代表一条消息从用户A到用户B(即B转发A)的概率。
PeopleRank算法如算法4所示。

算法4 PeopleRank算法
4 实验与分析
4.1 数据 本文中所进行的实验全部基于新浪微博数据。考虑到获取包含三亿用户的微博网络的难度过大,而且在如此巨大的网络中进行实验的计算速度必然十分缓慢。于是我们只选取了“IT互联网”领域进行本文的所有实验。对于“IT互联网领域”的人员名单,我们使用了新浪微博“名人堂”中的“IT互联网”领域人员名单。最终获取了2 381名用户的信息,6 589 451条微博。考虑到本文所研究的算法为通用的影响力分析算法,限制在某些领域内只是为了方便方法的验证,所以,我们对已经获得的数据进行了进一步的加工和整理。整理之后的数据增加了用户在本领域内followesIds、friendsIds的信息,也即用户在本领域内的关注和粉丝列表。
4.2 实验结果与分析
使用前三种方法,即最大度算法、距离中心算法和用户平均转发率得到的实验结果如表1所示。
为了对比各个方法得出的结果,我们将三个排序结果做了比较。
第一种比较方法是,将三个结果作为三个向量,对比三个向量的差别。
首先,我们对三个算法的结果进行数值标准化,如式(7) 所示。
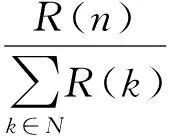
(7)
计算余弦相似度如式(8)。
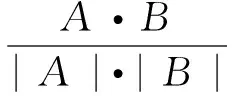
Sim(A,B)=cosθ= (8)
其中A,B为两个向量,每个用户即为一个维度,每个用户的标准化数值即为该维度的值。
对数值化之后的向量计算两两之间的余弦相似度,结果如表2所示。

表2 三种算法得出的IT互联网领域结果的相似度对比
通过对比,我们发现,距离中心点算法与平均转发率算法的结果最为接近,而两者与最大度算法的结果都相差较大。
另一种方法是看某个用户在三个结果中的排名相差多少,即计算两个排序结果相关度,具体公式如式(9)。
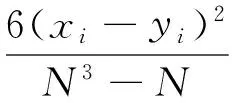
(9)
其中xi,yi为第i个用户在两个排序中不同的名次。对数值化之后的向量两两计算相关度,结果如表3所示。

表3 三种算法得出的IT互联网领域排名的相关度对比
与余弦相似度的计算类似,当考虑所有节点时,不同方法的排序结果之间差异大体相同。如果考虑影响力比较大的用户,距离中心点和转发率算法的结果比较接近,而两者与最大度算法的差异都比较大。综上所述,距离中心点算法的结果与平均转发率算法的结果是比较接近的,而最大度算法的结果与以上两种算法结果不是太接近。
基于此,我们要探究一种可代表某个用户将某个消息扩散出去的能力的方法。所以,从概念上考虑,将某个节点的度数作为其扩散能力的代表,可能是不适合的,从实际效果来看,其与其他算法的差别也是非常大的。但是,探索某个用户可以通过几个用户就可以到达另一个用户,通过统计该用户之前的扩散能力以推测其实际的扩散能力,或许是一种符合我们目的的算法。从实际结果来看,这两种算法的结果也是比较接近的。
为了对PeopleRank的算法结果与前文的三个算法进行对比,先将PeopleRank的结果进行标准化,然后计算它们的余弦相似度,结果如表4所示。

表4 PeopleRank算法与三种统计算法的余弦相似度
计算PeopleRank算法结果与三种统计方法的排名相关度,结果如表5所示。

表5 PeopleRank算法与三种统计算法的排名相关度
从前面两个结果可以看出,PeopleRank算法与转发率算法比较接近,而与最大度算法差别最大。
4.2 基于用户本身特性的算法与PeopleRank算法的对比和分析 从前面几种算法的结果可以发现,使用PeopleRank算法的排序结果与用户的平均转发率排序差别最小。如前文所述,平均转发率可以比较真实地表示某个用户发布一条微博之后所获得的传播效果,所以,大体上可以说,PeopleRank的算法要比最大度算法和距离中心点算法效果要好。
事实上,从理论上讲,最大度算法、距离中心点算法和PeopleRank算法都是利用了网络本身的特性。其中,对于节点A,最大度算法只考察了其粉丝数目,意图使用粉丝的数目来推断其影响力大小,实际试验证明,这一方法的表现是最差的。而距离中心点算法,考察节点A距离网络中其他节点的平均距离,事实上,是对最大度算法的一个扩展,直观上讲,如果A的粉丝越多,则其距离所有节点平均距离也可能越小。但是距离中心点算法考察的网络属性要比最大度算法更多。
对于PeopleRank算法,其不仅考察了整个网络的关系属性,而且尝试着模拟消息的传递过程。算法公式中的阻尼系数c事实上就是代表某个消息被下一个节点转播的概率。多次的迭代过程,也是在模拟整个网络中一遍又一遍进行的消息传播的过程。所以,PeopleRank算法不仅考察了网络的整体属性,而且考虑进了信息传播的过程,实际试验表明其比其他两个算法更加接近实际的转发效果。
但是,我们应该看到,PeopleRank算法中对于信息传播过程的描述是非常粗略的,其传播概率值c的取值也是非常不精确的。不考虑当前节点与下一个节点的关系,粗糙而简单地将传播概率设为一个统一的常量,并不是最好的做法。
5 结论与未来工作
用户影响力分析是社会计算领域一个重要的研究方向。本文首先从用户特性的统计算法着手,分析了最大度算法、距离中心点算法和平均转发率算法之间的区别,发现最大度算法与后两者的区别较大,得出的结论为粉丝数越大,不一定影响力越大。继而,本文又将经典的PageRank算法迁移到微博网络中,即PeopleRank算法。通过对比PeopleRank算法与之前三个算法,得出的结论是PeopleRank算法的结果与真实转发率更加接近。
本文的PeopleRank算法中我们简单地采用一个统一的常数c来表示下一个节点被影响的概率,是不精确的。事实上,这个概率应该是根据用户与用户之间的关系不同、交互历史不同而变化的。因此,在未来工作中,我们将建立一个更合理的模型,对影响力传播过程做进一步的细化。
[1] Reka Albert, Hawoong Jeong, Albert-Laszlo Barabasi. Error and attack tolerance of complex networks[J]. Nature, 2000, 406 (6794): 378-382.
[2] S Wasserman, K Faust, D Iacobucci, et al. Social Network Analysis: Methods and Applications[M]. Cambridge University Press, 1994.
[3] Jon M Kleinberg. Authoritative sources in a hyperlinked environment[J]. Journal of the ACM, 1999, 46(5): 604-632.
[4] Lawrence Page, Sergey Brin, Rajeev Motwani, et al. The PageRank citation ranking: Bringing order to the web[J]. World Wide Web Internet and Web Information Systems, 1998, 54(2): 1-17.
[5] T H Haveliwala. Topic-sensitive PageRank: a context-sensitive ranking algorithm for Web search[J]. IEEE Transactions on Knowledge and Data Engineering, 2003, 15(4): 784-796.
[6] Jun Zhang, Mark S Ackerman, Lada Adamic. Community Net Simulator: Using Simulations to Study Online Community Networks[J]. Forum American Bar Association, 2007, 2005(3): 221-230.
[7] Jialun Qin, Jennifer J Xu, Daning Hu, et al. Analyzing Terrorist Networks: A Case Study of the Global Salafi Jihad Network[J]. Network, 2005, 3495(196): 287-304.
[8] Jennifer J Xu, Hsinchun Chen. Fighting organized crimes: using shortest-path algorithms to identify associations in criminal networks[J]. Decision Support Systems, 2004, 38(3): 473-487.
[9] Meeyoung Cha, Krishna P Gummadi. Measuring User Influence in Twitter: The Million Follower Fallacy[J]. Artificial Intelligence, 2010, 146(1): 10-17.
[10] Daniel M Romero, Wojciech Galuba, Sitaram Asur, et al. Influence and Passivity in Social Media[J]. Information Systems Journal, 2010, 1(4): 1-9.
[11] Jianshu Weng, Ee-Peng Lim, Jing Jiang, et al. TwitterRank: Finding Topic-Sensitive Influential Twitters[C]// Proceedings of WSDM, 2010: 261-270.
[12] Junming Huang, Xue-qi Cheng, Hua-wei Shen, et al. Exploring Social Influence via Posterior Effect of Word-of-Mouth Recommendations[C]//Proceedings of the 5th ACM international conference on Web search and data mining,2012: 573-582.
[13] Yaron Singer. How to Win Friends and Influence People, Truthfully: Influence Maximization Mechanisms for Social Networks[C]// Proceedings of WSDM, 2012: 733-742.
[14] Smriti Bhagat, Amit Goyal, Laks V S Lakshmanan. Maximizing Product Adoption in Social Networks[C]// Proceedings of the 15th ACM international conference on Web search and data mining WSDM, 2012: 603-612.
[15] Meng Wang, Gang Zhou, Jun Yu Chen. Analysis of User Influence Using User Behavior and Random Walk[J]. Applied Mechanics and Materials, 2014, 571: 1163-1167.
[16] Yulan Huang. Analysis of user influence in social network based on behavior and relationship[J]. Measurement, Information and Control, 2013: 682-686.
[17] Bin Bi, Yuanyuan Tian et al. Scalable Topic-Specific Influence Analysis on Microblogs[C]//Proceedings of WSDM, 2014: 513-522.

陈毅恒(1979—), 博士,主要研究领域为自然语言处理。
E-mail: yhchen@ir.hit.edu.cn

李雪婷(1982—),硕士,主要研究领域为情报学。
E-mail: lixueting@hit.edu.cn

王彪(1987—),硕士,主要研究领域为自然语言处理。
E-mail: bwang@ir.hit.edu.cn
Comparison of User Influence Analysis Algorithms Based on Network Structure
CHEN Yiheng1, LI Xueting2, WANG Biao1, LIU Ting1
(1. Research Center for Social Computing and Information Retrieval of Computer Science and Technology School, Harbin Institute of Technology, Harbin, Heilongjiang 150001, China;2. Information Counseling of Library, Harbin Institute of Technology, Harbin, Heilongjiang 150001, China)
1003-0077(2017)04-0216-07
TP391
A
2015-10-20 定稿日期: 2016-04-16
国家自然科学基金(61202277, 61133012)
