一种基于词素媒介的汉蒙统计机器翻译方法
2017-10-11杨振新卫林钰
杨振新,李 淼,陈 雷,卫林钰,陈 晟,孙 凯
(1. 中国科学技术大学 自动化系,安徽 合肥 230027;2. 中国科学院 合肥智能机械研究所,安徽 合肥 230031)
一种基于词素媒介的汉蒙统计机器翻译方法
杨振新1,2,李 淼2,陈 雷2,卫林钰1,2,陈 晟1,孙 凯1
(1. 中国科学技术大学 自动化系,安徽 合肥 230027;2. 中国科学院 合肥智能机械研究所,安徽 合肥 230031)
汉蒙语形态差异性及平行语料库规模小制约了汉蒙统计机器翻译性能的提升。该文将蒙古语形态信息引入汉蒙统计机器翻译中,通过将蒙古语切分成词素的形式,构造汉语词和蒙古语词素,以及蒙古语词素和蒙古语的映射关系,弥补汉蒙形态结构上的非对称性,并将词素作为中间语言,通过训练汉语—蒙古语词素以及蒙古语词素-蒙古语统计机器翻译系统,构建出新的短语翻译表和调序模型,并采用多路径解码及多特征的方式融入汉蒙统计机器翻译。实验结果表明,将基于词素媒介构建出的短语翻译表和调序模型引入现有统计机器翻译方法,使得译文在BLEU值上比基线系统有了明显提高,一定程度上消解了数据稀疏和形态差异对汉蒙统计机器翻译的影响。该方法是一种通用的方法,通过词素和短语两个层面信息的结合,实现了两种语言在形态结构上的对称,不仅适用于汉蒙统计机器翻译,还适用于形态非对称且低资源的语言对。
中间语言;词素;统计机器翻译;短语翻译表;调序模型
Abstract: To deal with the morphological difference between Chinese and Mongolian, this paper proposes a method of adopting morpheme of Mongolian as the pivot to Chinese-Mongolian statistical machine translation (SMT). First, we segment Mongolian word into morphemes, achieving a balance in the morphology of the language pair. Then, we treat Mongolian morpheme as pivot language and construct two new SMT systems: Chinese-Morpheme SMT and Morpheme-Mongolian SMT. New translation knowledge including phrase translation table and reordering model is introduced for these two SMT systems. Finally, we use multiple decoding paths and multiple features to incorporate the new translation knowledge. Experimental results demonstrate our method can improve the translation quality significantly.
Key words: pivot language; morpheme; statistical machine translation; phrase translation table; reordering model
收稿日期: 2015-9-18 定稿日期: 2016-2-24
基金项目: 国家自然科学基金(61502445,61572462);中国科学院信息化专项(XXH12504-1-10)
1 引言
我国作为一个历史悠久的多民族国家,民族语言之间的相互翻译对促进民族间的文化交流、经济发展具有重要意义。汉语和少数民族语言之间的形态差异性以及平行语料库规模小使得汉蒙统计机器翻译面临挑战。
对于汉蒙统计机器翻译来说,汉语和蒙古语在形态方面差异极大。汉语属于没有形态变化的孤立语,蒙古语是形态丰富的黏着语,蒙古语的词由词干和词缀组成。根据所表达的不同意思,蒙古语的词干后面可以层层缀接不同的词缀。因此,在汉蒙统计机器翻译中,需要大规模语料才能覆盖复杂多变的蒙古语。
目前,汉蒙双语语料库需要依靠语言学专家人工构造,费时费力,在短时间里无法得以大量扩充。汉蒙双语语料资源稀缺,使得以统计为基础的机器翻译面临严重的数据稀疏问题,加之汉蒙语言在形态方面差异较大,进一步制约了汉蒙统计机器翻译性能的提升[1]。
两种语言在形态方面的差异使得统计机器翻译面临严峻挑战[2]。相关研究证实融入形态信息对于提高统计机器翻译译文质量有很大帮助。Al-Haj和Lavie[3]在阿拉伯语到英语的翻译中对阿拉伯语进行形态切分,有效提高了阿拉伯语-英语机器翻译质量;Kholy和Habash[4]比较了三种不同的方法将形态信息融入英语-阿拉伯语统计机器翻译中;Luong等[5]在翻译模型训练和解码过程中采用混合的词素级、词级策略,提高了英语-芬兰语的翻译质量;Goldwater和McClosky[6]在捷克语-英语的翻译中对捷克语进行形态分析;Singh和Habash[7]在希伯来语-英语翻译中使用形态信息改善未登录词的翻译;Salameh等[8]针对形态丰富的目标语言翻译,将形态信息融入词格解码过程,显著提高了译文质量。
在汉蒙机器翻译方面,引入蒙古语形态信息可以显著提高译文质量[1,9,10,19,20]。杨攀等[1]将蒙古语形态信息引入统计机器翻译因子化模型中,在一定程度上消除了汉蒙形态差异及译文选词混乱等问题;骆凯等[9]将汉语依存句法信息及蒙古语形态信息融入因子化模型,并采用LOP对模型参数进行调整;但因子化模型翻译解码时间较长,且受生成模型影响。Li等[10]分两步完成汉蒙机器翻译,首先将汉语翻译成蒙古语词素,再将蒙古语词素翻译成蒙古语,但两次机器翻译也会产生相关误差。
与上述工作不同的是,本文将蒙古语形态信息引入统计机器翻译,将蒙古语词素视为中间语言,训练汉语-蒙古语词素和蒙古语词素-蒙古语统计机器翻译系统,通过基于蒙古语词素为媒介的统计机器翻译方法构建出有用的翻译知识,并将其融入汉语-蒙古语统计机器翻译系统中,以此消解汉蒙语形态差异及数据稀疏对统计机器翻译的影响。
2 汉蒙语形态差异
汉语属于孤立语,词语几乎没有形态变化,同时也没有表示语法意义的附加成分。然而,蒙古语属于黏着语,有着丰富的形态,在构词和构形上与汉语不同。蒙古语的构词、构形都是通过在词干后缀接不同的词尾实现的,并且根据需求还可以层层缀接,这使得蒙古语形态丰富且复杂。在英语或汉语中必须用词表达的意义,在蒙古语中用构形词缀表示就可以。表1是蒙古语形态变化丰富的例子。
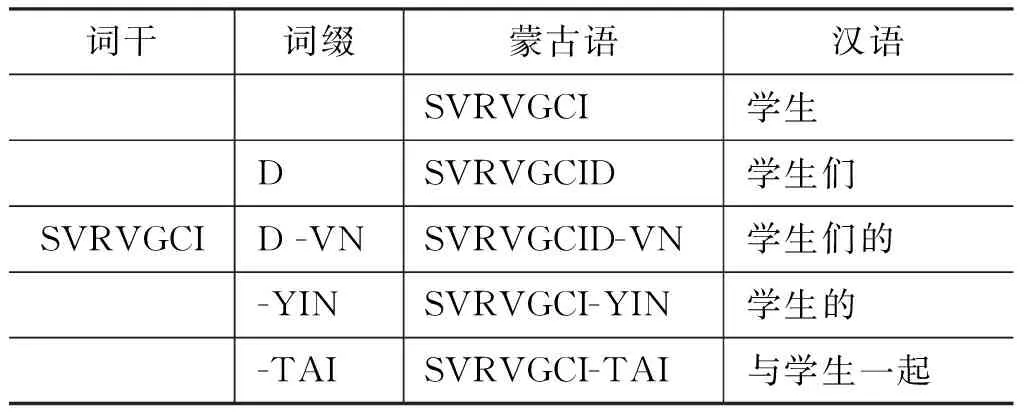
表1 蒙古语形态学示例
根据《蒙古语语法信息词典》中的统计,蒙古语中有超过3万多个词干、297个构形词缀,由此派生出来的蒙古语词理论上是呈指数级增长的,这需要大规模语料才能覆盖蒙古语可能的表面词形[1]。相对于汉语而言,蒙古语属于低资源语言,汉蒙双语平行语料稀缺,加之蒙古语形态变化丰富,语法、句法表达能力强,在形态非对称的汉蒙机器翻译系统中,语料稀疏问题更加严重,统计翻译模型的建模能力受到了很大的挑战。蒙古语形态信息中蕴含了丰富的知识,从直观上看,充分利用蒙古语形态信息,对于消解统计机器翻译中面临的数据稀疏问题有很大帮助。
需要说明的是,形态学中的词素包含“词根”、“词干”、“构词词缀”和“构形词缀”等多个概念。但由于蒙古语自动词法分析技术目前只能做到词干、构形词缀的自动识别和标注,因此本文中的词素包括词干和构形词缀。
3 基于词素的短语翻译表
3.1 短语翻译表 短语翻译表作为基于短语的统计机器翻译中的重要组成部分[11],由以下4部分组成: 正向短语翻译概率、正向词汇化加权、反向短语翻译概率、反向词汇化加权。
反向短语翻译概率的计算方式如式(1)。
(1)
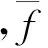
词汇化加权作为一种有效的平滑方式,可以反映短语对的可靠性,通过将短语分解为词,可获得更多的统计数据,反向词汇化加权计算方式如式(2)。
(2)


3.2 中间语言策略的短语翻译表构建
汉蒙语料资源稀缺,加之汉蒙语形态差异大,因此汉蒙统计机器翻译建模困难极大。本文对蒙古语进行形态切分[19],将蒙古语词表示成词素形式,即蒙古语词表示为“词干+词缀”。通过将蒙古语词素作为中间语言,训练汉语—蒙古语词素翻译系统和蒙古语词素—蒙古语翻译系统,并构建出新的短语翻译表,以此丰富翻译模型。
本文将构建出的短语翻译表添加到原始基线系统中,通过多路径解码策略和基线短语翻译表相结合,提升翻译效果。具体而言,我们设置两条翻译路径独立解码,每条翻译路径包含一个短语表,择优选择最佳译文。
4 基于词素的调序模型
4.1 调序模型 词汇化调序模型[12]可以显著提高机器翻译质量,在统计机器翻译中广泛使用。在基于词的词汇化调序模型中,当前短语对与目标语言前方词的位置关系称为前向关系,与后方词的位置关系称为后向关系。根据当前短语对与前后上下文的位置关系,使用三种调序方向: 单调(monotone)、交换(swap)、非连续(discontinuous)。因此,考虑前后向关系,基于词的调序模型一共有六种特征。
调序方向的识别如图1所示。
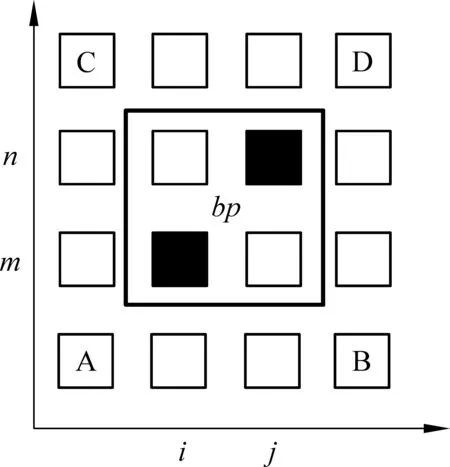
图1 调序方向识别示意图
在词对齐矩阵中,对于每一个抽取出的短语对,识别其与前后词之前的位置关系。(i,j)是源语言短语位置,(m,n)是目标语言短语位置。对于抽取出的短语对bp,前向关系的调序方向识别如下:
• 单调调序: 如果(i-1,m-1)存在词对齐,且(j+1,m-1)没有对齐点;
• 交换调序: 如果(i-1,m-1)没有词对齐,且(j+1,m-1)存在对齐点;
• 非连续调序: 单调调序和交换调序以外的情况。
后向关系的调序方向识别如下:
• 单调调序: 如果(j+1,n+1)存在词对齐,且(i-1,n+1)没有对齐点;
• 交换调序: 如果(j+1,n+1)没有词对齐,且(i-1,n+1)存在对齐点;
• 非连续调序: 单调调序和交换调序以外情况。
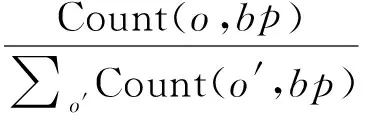
(7)
为了避免零概率出现对机器翻译解码造成的干扰,本文将Count(o,bp)加0.5平滑。考虑前、后向调序关系,对于每个给定短语对,本文根据式(7)计算六个不同概率。
4.2 中间语言策略的调序模型构建
(8)
本文将构建出的调序模型作为特征融入统计机器翻译对数线性框架。需要注意的是,由于采用多个短语翻译表,在机器翻译解码过程中,翻译候选可能在调序模型中找不到相应调序概率。针对这种情况,本文采用默认概率的方法,即分别对两个调序模型求出相应的调序概率平均值。解码过程中如果某
个翻译候选无法在调序模型中找到调序概率,则将调序概率平均值作为翻译选项的调序概率。
5 实验
在汉蒙统计机器翻译中,翻译的任务是给定汉语句子f=f1…fn,搜索使得条件概率p(e|f)最大的蒙古语句子e=e1…em作为译文的输出。在对数线性模型框架下,最优的蒙古语翻译可以定义为:
(9)
其中,h(f,e)统计机器翻译所采用特征,λ是特征参数。对数线性模型允许添加任意多的特征,每个特征对应一个参数,参数的调节采用最小错误率算法。
基于词素媒介的汉蒙统计机器翻译框图如图2所示。
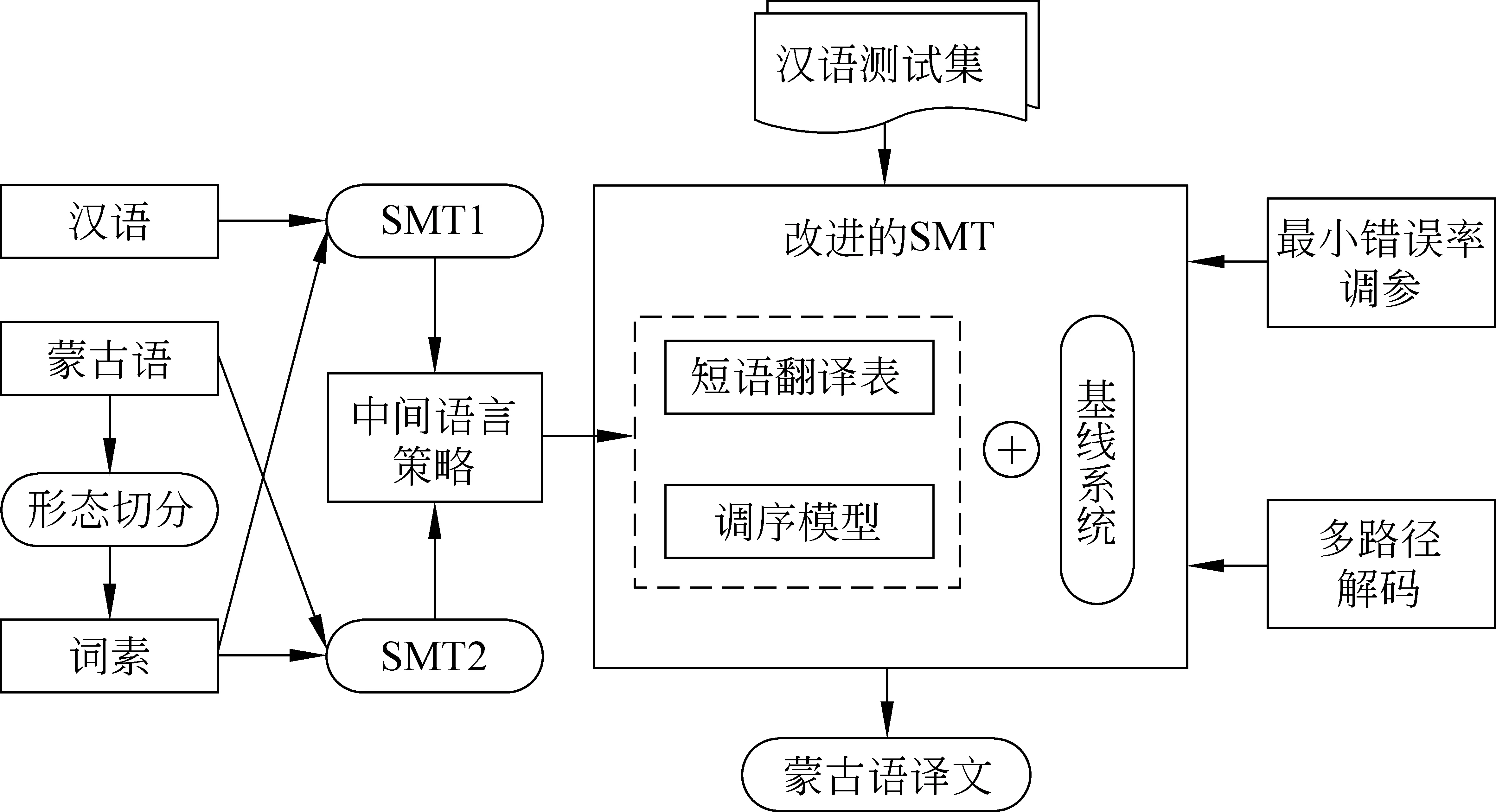
图2 基于词素的汉蒙统计机器翻译框图
5.1 实验数据
实验采用的训练集是第五届全国机器翻译研讨会提供的汉蒙日常用语训练语料,开发集为500句,测试集也为500句。开发集和测试集中每句汉语都有四句由语言学专家独立翻译的蒙古语译文。蒙古语语料均进行了传统蒙文到拉丁蒙文的转换。实验数据信息如表2所示,其中500×4指的是500句源语言句子,每一句源语言对应四句目标语言参考译文。
5.2 实验设置
本文首先采用HMM方法[19]将蒙古语词切分成词素形式,不考虑词干还原现象。构造出词素中间语言所需的三种不同形式语料: 汉语、蒙古语词素、蒙古语。
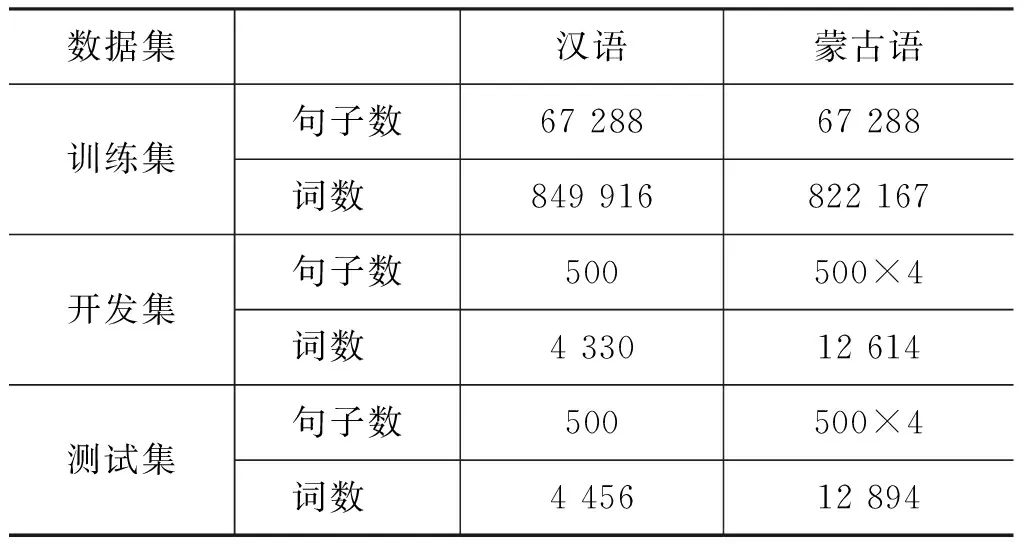
表2 实验数据
本文使用开源工具GIZA++[13]并采用grow-diag-final-and[11]启发式策略进行双语词对齐。但是在蒙古语词素—蒙古语机器翻译系统中,本文根据蒙古语词干、词缀的规律生成了双语词对齐结果,并没有使用GIZA++。使用SRILM[14]训练3元语言模型,并采用改进的KN平滑算法[15]。汉语使用ICTCLAS[16]进行中文分词。采用最小错误率算法[17]对参数进行调整。短语抽取时最大短语长度设为7。
5.3 基于词素媒介的短语表分析
基于词素媒介的汉蒙统计翻译方法本质上是利用蒙古语形态信息,构建出新的短语对,以此丰富翻译模型。基线系统的短语表有1 872 336个短语对,基于词素媒介的短语表有1 305 651个短语对,其中有35%的短语对没有出现在基线短语表中。
直观上,基于中间语言构造出来的短语表规模会很大,而本文词素短语表比基线短语表规模小。这是因为在蒙古语词素—蒙古语机器翻译系统中,我们使用规则方法生成词对齐,不存在空对齐,抽取出来的蒙古语词素-蒙古语短语表规模较小。
5.4 实验结果与分析
为了验证本文提出方法的有效性,本文设计了4组系统。
(1) 系统A: 基线系统,使用的是汉蒙机器翻译领域研究最广泛的基于短语的统计机器翻译系统;
(2) 系统B: 将词素中间语言构建出的短语翻译表以多路径解码策略融入基线系统中;
(3) 系统C: 针对系统B中构建出的短语翻译表可能无法在基线调序模型中找到相关调序概率的情况,设置默认概率;
(4) 系统D: 在系统C的基础上,将词素中间语言的调序模型以特征的方式融入统计机器翻译对数线性模型,对于在调序模型中找不到概率信息的翻译选项,采用默认概率。
本文采用BLEU[18]对译文进行打分,所有实验均重复三次取平均值,以此消解调参过程对实验结果的影响。实验结果如表3所示。
通过表3可以看出,本文所提出的基于词素中间语言策略的统计机器翻译方法可以有效地提高机器翻译译文质量。系统B、C、D都比基线系统有提升,系统C通过采用默认调序概率的方法比系统B又有所提高,加入基于词素中间语言的调序模型虽然取得了最好的效果,但是和系统C相比并没有太多提高,我们分析原因可能是双调序模型产生了特征冗余现象,在开发集上调得的参数不能有效地发挥双调序模型的优势。
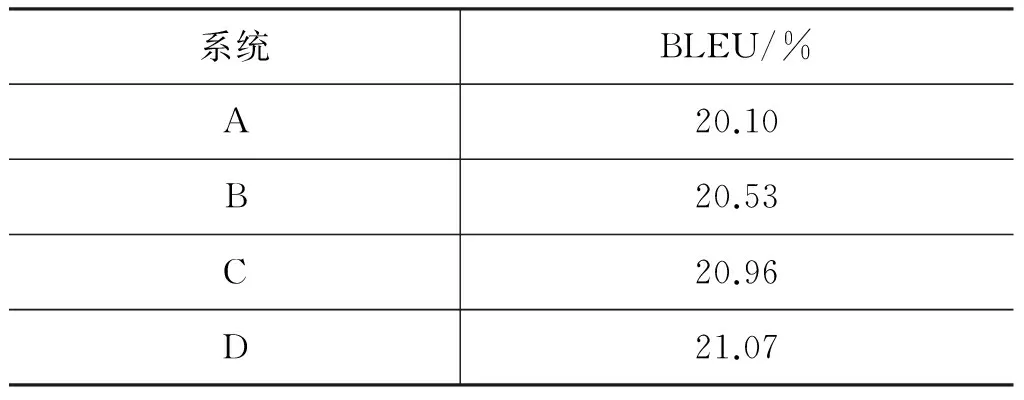
表3 实验结果
为了从直观上理解本文方法的有效性,本文将表现最好的系统D和基线系统翻译出的译文进行比较,分析两个系统译文的差异性。翻译结果如表4所示。
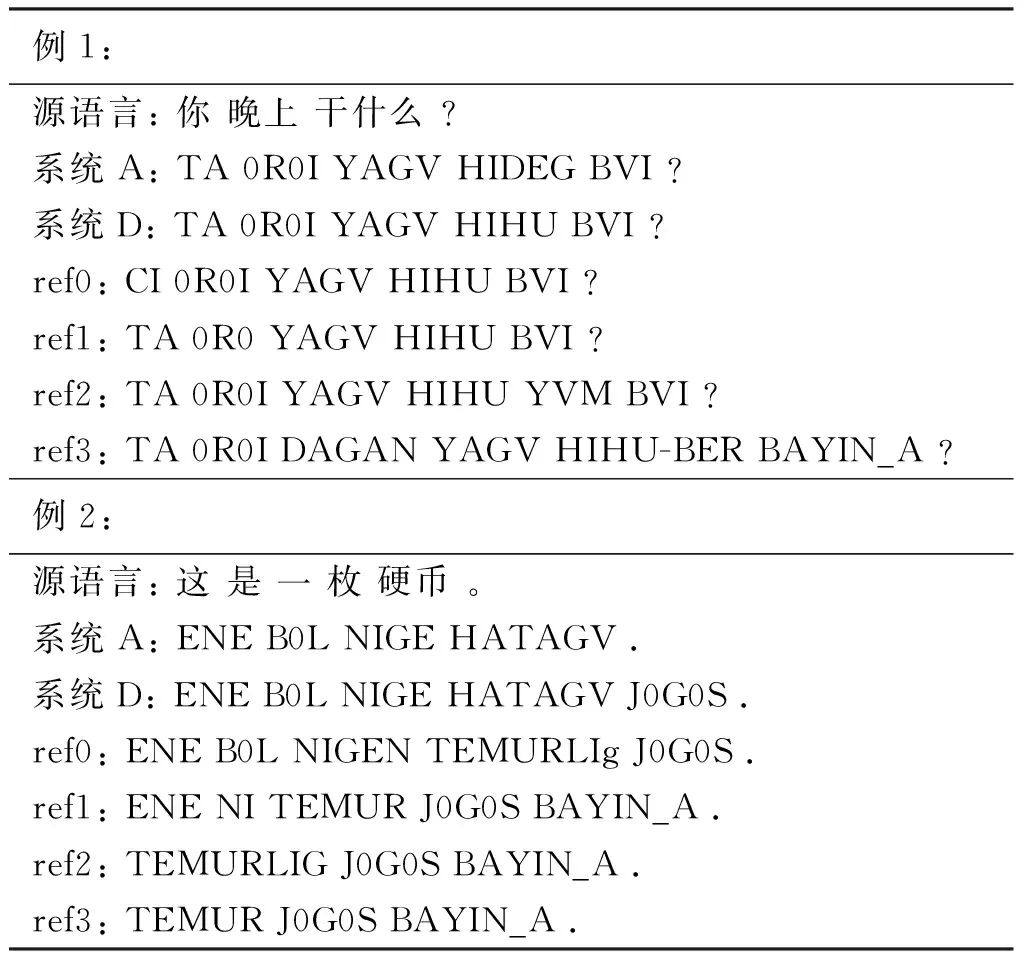
表4 翻译结果
表4是不同系统的机器翻译结果,源语言是汉语,系统A和系统D输出结果是机器翻译出来的蒙古语,ref0、ref1、ref2、ref3是语言学家对源语言进行翻译的结果。对于表4的两个例子,系统D的结果明显优于系统A。
例1是译文时态选择的例子,系统A和系统D中不同的地方在于HIDEG和HIHU。HI是动词的词干,表示“干什么”,其后面缀加不同的词缀表示不同的时态,DEG是表示经常体的形动词词缀,它充当述语时表示动作的经常性或习惯性,多用在现在时;而HU是表示将来的词缀,它充当述语时表示绝对的或相对的将来时。因此,系统D对于译文时态的选择有帮助。
例2是词汇精确翻译的例子,系统A翻译结果不完整,系统A译文结果没有“币”,而J0G0S在蒙古语中表示“币”的意思。因此,系统D可以使译文的词汇翻译更加准确。
6 结论
本文针对汉蒙统计机器翻译面临的数据稀疏和形态差异大的问题,将蒙古语进行形态切分,一定程度上消解了汉蒙形态结构不一致问题,同时将蒙古语词素看作中间语言,训练汉语-蒙古语词素、蒙古语词素-蒙古语翻译系统,并以此构建出两类新的翻译知识: 短语翻译表和调序模型,改善了数据稀疏对汉蒙机器翻译系统的影响。另外,本文采用了多路径解码和多特征方法将以词素为媒介构建出来的翻译知识集成到现有机器翻译系统中,集成方式简单有效。实验结果表明,本文方法是有效的,而且具有通用性,不仅适用于汉蒙统计机器翻译,同时也适用于其他形态非对称且平行语料规模较小的语言对。然而,本文采用的双调序模型会产生特征冗余。因此,下一步工作将考虑如何对特征冗余进行消解,如何将本文方法用在其他形态非对称语言对的统计机器翻译中。
[1] 杨攀, 张建, 李淼,等.汉蒙统计机器翻译中的形态学方法研究[J]. 中文信息学报, 2009, 23(1): 50-57.
[2] Ke Tran, Arianna Bisazza, Christof Monz. Word translation prediction for morphologically rich languages with bilingual neural networks[C]//Proceedings of EMNLP, 2014: 1676-1688.
[3] Hassan Al-Haj, Alon Lavie. The impact of Arabic morphological segmentation on broad-coverage English-to-Arabic statistical machine translation[J]. Machine translation, 2012, 26(1-2): 3-24.
[4] Ahmed El Kholy, Nizar Habash. Translate, predict or generate: modeling rich morphology in statistical machine translation[C]//Proceedings of EAMT, 2012: 27-34.
[5] Minh-Thang Luong, Preslav Nakov, Min-Yen Kan. A hybrid morpheme-word representation for machine translation of morphologically rich languages[C]//Proceedings of EMNLP, 2010: 148-157.
[6] Sharon Goldwater, David McClosky. Improving statistical MT through morphological analysis[C]//Proceedings of HLT-EMNLP, 2005: 676-683.
[7] Nimesh Singh, Nizar Habash. Hebrew morphological preprocessing for statistical machine translation[C]//Proceedings of EAMT, 2012: 43-50.
[8] Mohammad Salameh, Colin Cherry, Greg Kondrak. Lattice desegmentation for statistical machine translation[C]//Proceedings of ACL, 2014: 100-110.
[9] 骆凯, 李淼, 乌达巴拉,等.汉蒙翻译模型中的依存语法与形态信息应用研究[J]. 中文信息学报, 2009, 23(6): 98-104.
[10] Wen Li, Lei Chen, Miao Li, et al. Chained machine translation using morphemes as pivot language[C]//Proceedings of COLING, 2010: 169-177.
[11] Philipp Koehn, Franz Josef Och, Daniel Marcu. Statistical phrase-based translation[C]//Proceedings of NAACL-HLT, 2003: 48-54.
[12] Philipp Koehn, Hieu Hoang, Alexandra Birch, et al. Moses: open source toolkit for statistical machine translation[C]//Proceedings of ACL, 2007: 177-180.
[13] Franz Josef Och, Hermann Ney. Improved statistical alignment models[C]//Proceedings of ACL, 2000: 440-447.
[14] Andreas Stolcke. SRILM-an extensible language modeling toolkit.[C]//Proceedings of International Conference on Spoken Language Processing, 2002: 901-904.
[15] Stanley F Chen, Joshua Goodman. An empirical study of smoothing techniques for language modeling[C]//Proceedings of ACL, 1996: 310-318.
[16] 刘群, 张华平, 俞鸿魁,等.基于层叠隐马模型的汉语词法分析[J]. 计算机研究与发展, 2004, 41(8): 1421-1429.
[17] Franz Josef Och. Minimum error rate training in statistical machine translation[C]//Proceedings of ACL, 2003: 160-167.
[18] Kishore Papineni, Salim Roukos, Todd Ward,et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of ACL, 2002: 311-318.
[19] Miantao He, Miao Li, Lei Chen. Mongolian morphological segmentation with hidden Markov model[C]//Proceedings of IALP, 2012: 117-120.
[20] Hui Liu, Miao Li, Jian Zhang, et al. Morpheme Segmentation Using Bilingual Features[C]//Proceedings of IALP, 2012: 209- 212.

杨振新(1990—),博士研究生,主要研究领域为统计机器翻译。
E-mail: xinzyang@mail.ustc.edu.cn

李淼(1955—),通信作者,研究员,博士生导师,主要研究领域为自然语言语言处理。
E-mail: mli@iim.ac.cn

陈雷(1981—),副研究员,硕士生导师,主要研究领域为机器学习与自然语言处理。
E-mail: chenlei@iim.ac.cn
A Morpheme-Based Approach for Chinese-Mongolian SMT
YANG Zhenxin1,2, LI Miao2, CHEN Lei2, WEI Linyu1,2, CHEN Sheng1, SUN Kai1
(1. Department of Automation, University of Science and Technology of China, Hefei, Anhui 230027, China;2. Institute of Intelligent Machines, Chinese Academy of Sciences, Hefei, Anhui 230031, China)
1003-0077(2017)04-0057-06
TP301
A
