一种基于多特征因子改进的中文文本分类算法
2017-10-11汤世平牛振东
叶 敏,汤世平,牛振东
(北京理工大学 计算机学院,北京 100081)
一种基于多特征因子改进的中文文本分类算法
叶 敏,汤世平,牛振东
(北京理工大学 计算机学院,北京 100081)
采用向量空间模型(vector space model,VSM)表示网页文本,通过在CHI(Chi-Square)特征选择算法中引入频度、集中度、分散度、位置信息这四个特征因子,并考虑词长和位置特征因子改进TF-IDF权重计算公式,提出了PCHI-PTFIDF(promoted CHI-promoted TF-IDF)算法用于中文文本分类。改进算法能降维得到分类能力更强的特征项集、更精确地反映特征项的权重分布情况。结果显示,与使用传统CHI和传统TF-IDF的文本分类算法相比,PCHI-PTFIDF算法的宏F1值平均提高了10%。
Abstract: In the framework of the vector space model(VSM), a new PCHI-PTFIDF(promoted CHI-promoted TFIDF)method based on feature selection and weight calculation is proposed. First, the factors of frequency, concentration, dispersion and location are introduced to CHi-Square based feature selection. Then, the TF-IDF weight is proposed to be optimized by the length and location factors of text terms. The proposed method can reduce the dimensions of the features with better classification ability, and produce better estimation of the weight distribution. The experimental results show that, compared with the algorithm using the traditional CHI and traditional TFIDF, the PCHI-PTFIDF method achieves 10% improvement in Macro-F1 on average.
收稿日期: 2016-06-15 定稿日期: 2016-09-18
1 引言
文本自动分类[1]是指在给定的分类体系下,将未知类别的文本采用某种算法自动分配到所属类别的过程。中文文本分类实验流程分为文档分词、特征选择和提取、特征权重计算、构造分类器、分类测试几个步骤。文本文档通常采用G Salton 提出的向量空间模型(VSM)来表示,而数据的高维性、冗余性会对文本分类形成强烈的干扰,权重分布情况也直接影响着文本分类的准确度。为了降低特征项集维数、优化特征项权重表示,本文针对文本分类流程里特征选择和权重计算两个环节,分析了常用CHI特征选择算法和TF-IDF权重计算方法的不足,提出了基于多特征因子改进的中文本文分类算法。
2 相关工作
代六玲[4]等人通过分析中、英文文本分类处理的差异,得出“中文特征空间维数比英文高,且含有更多的低频词”的结论。而CHI算法对低频词的倚重使中文文本分类处于劣势。肖雪[5]等在CHI算法中引入了特征项在某类文档中的频度信息,减少了低频词的干扰,提高了文本分类的效果,不足之处是没有考虑特征项在类内、类间的分布差异。刘振岩[6]等人从类间集中度的角度提出了适用于偏斜数据集的特征选择算法。文献[7-9]就特征项在类内、类间分布情况设计了权重因子,从而改进分类效果,研究的不足之处在于没有考虑特征项在文档中不同位置的权重分布及特征降维和特征加权相结合的问题。
本文通过分析特征项的频度、类间集中度、类内分散度和文本中的位置信息四个特征因子,优化了CHI特征选择算法,并对文本向量表示中TF-IDF权重计算方法进行了改进,使改进后的权重体现出位置因素和词长对文本信息分布的影响。结合两步改进形成PCHI-PTFIDF算法,该算法将位置特征因子用于TF子式,同时应用于特征选择和特征项权重计算,分类效果与优化前相比有显著提升。
3 PCHI-PTFIDF文本分类算法模型

针对传统CHI算法存在的问题。拟通过改进频度、集中度、分散度、位置信息四个特征因子使评估函数包含更多分类信息的特性,降低原有算法对低频词敏感的特性,同时体现特征项在类内、类间分布情况。故而,从下面四个参考因子入手进行改进:
(1) 特征项频度
通常某个特征项ti在某类文本ck中出现的次数越多,则ti就越能代表类ck,我们用tf(ti,ck)表示ti在类ck内出现的次数。
(2) 类间集中度
一般特征项ti出现的文本类别数越少,说明该特征项区别不同类别文本的能力越强,我们把特征项和类别间的这种关系定义为类间集中度,用F(ti)表示。
如果ti只在一个类中出现,那么只要在某个文档中发现该特征项,就可以确定这个文档的类别。ti在两个或多个类中出现,说明包含该特征项的文档可能属于某些类,不可能属于另外一些类。如果ti在所有类中都出现,那么认为这样的特征项对分类几乎没有帮助,可以直接过滤掉。
由上述分析,特征项的类间集中度可以表示为式(1)。
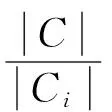
(1)
其中|C|为训练文本中总的类别数,|Ci|为包含特征项ti的类别数。
(3) 类内分散度
一个特征项仅在某类的少数几篇文档中出现,而在该类的其他文档中不出现,这个特征项对该类的作用就小;相反,一个特征项越在该类中均匀出现,对该类的作用越大。特征项在类中的这种分布关系用类内分散度来衡量,我们用dfk(ti)/Nk表示,其中dfk(ti)表示特征ti在类ck内出现的文档数,Nk表示类ck内文档的总数。
(4) 特征项在文本中的位置重要性度量
特征项的位置信息在一定程度上反映了它的重要性。标题区域比正文区域的权重要大,段首段尾区域的特征项比文本中间特征项权重要大。为简便起见,我们把预处理之后的语料文本中第一行信息作为文本的标题,其余部分为正文。特征项ti在类ck的标题位置出现频数为tftitle(ti,ck),在正文位置出现的频数为tfbody(ti,ck),特征项在标题区域的权重为α,特征项在正文区域的权重为β。从α=β=1开始,随着α的增大和β的减小,特征项在标题位置的重要性越来越强,在正文区的重要性越来越弱,改变α和β的值,可衡量不同位置权重对分类效果的影响。
通过上述的分析,我们可以得到一个新的特征选择函数,将其表示为式(2)。
(2)
其中tfi表示特征项ti在整个训练集中的频数,α≥1≥β>0。
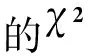
(3)
3.2 基于词长和位置的特征项权重计算
TF-IDF(词频率—逆文档频率)的主要思想是: 特征项在文档中的权重为特征项在文档中出现的频数反比于包含该特征项的文档数目,用来评估特征项的重要程度。传统的TF-IDF公式如式(4)所示。
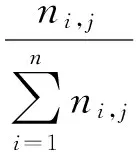
(4)
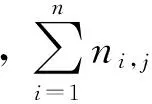
传统的TF-IDF计算特征项权重时,只考虑了特征项频率和包含特征项的文档数量,没有考虑特征项在文本中的位置和特征项的长度这两个重要信息。和特征选择改进算法中特征位置的表示类似,特征项ti在文档dj的标题位置出现频数为tftitle(ti,dj),在dj正文位置出现的频数为tfbody(ti,dj)。通常较长的特征项比较短的特征项包含了更多的信息,更适合表征文本的分类,因此需要增大较长词的权重。据此改进TF-IDF算法如式(5)所示。
(5)
式(5)中,L为特征项的长度,α、β取值的确立与改进与特征选择算法中所述相同。
3.3 PCHI-PTFIDF文本分类算法
PCHI-PTFIDF文本分类算法思想描述如下:
(1) 遍历训练集,得到训练文本所有不重复词项,然后将这些词项加入到HashMap中,得到原始词集itemMap,用PCHI算法对其进行降维即得特征项集fMap。
(2) 根据得到的特征项集,用PTFIDF算法进行训练文本的向量表示,训练分类器模型。
训练过程的伪码如下所示:
输入: 训练集D
输出: 降维后的特征项集fMap,向量表示的训练文本集VSMmap,训练得到分类器svmmodel
file: 训练集中一篇文本
C: 训练集文档类别
item: 文本中的词项
itemMap: 训练集中出现的所有词项的集合
fit: fMap中的特征项
1. for each file in D do
2. itemMap=WordCut.getItemMap(file)
3. C=WordCut. getClassLabel(file)
4. end for
5. for each item in itemMap
6. itemValue(item)=PCHI(item, C)
7. order(item.itemValue())
8. choose the top-N items to form the fMap
9. end for
9. for each item in D
10. for each item in file
11. if item matches a feature item fit in fMap
11. fitValue(fit)=PTFIDF(item)
12. VSMmap(file).add(fit, fitValue(fit))
13. end for
14. end for
15. libfile=convertToSvmFormat(VSMmap(file))
16. svmmodel=libSVM(libfile)
17. end
(3) 遍历测试集,采用PTFIDF算法进行测试文本的向量表示,用训练得到的分类器对测试集分类,最后评估分类效果。
测试集分类过程的伪码如下所示:
输入: 测试集T,训练过程得到的特征项集fMap,训练得到的分类器svmmodel
输出: 向量表示的测试文本集testVSMmap,测试文本的类别predictC
testfile: 测试集中的一篇文本
testitem: 测试文本中的词项
testitemMap: 测试集中出现的所有词项的集合
fit: fMap中的特征项
1. for each test file in T do
2. testitemMap=WordCut.getItemMap(testfile)
3. end for
4. for each testfile inT
5. for each testitem in testfile
6. if testitem matches a feature item fit in fMap
7. fitValue(fit)=PTFIDF(testitem)
8. testVSMmap(testfile).add(fit, fitValue(fit))
9. end for
10. end for
11. libtestfile=convertToSvmFormat(testVSMmap(testfile))
12. predictC=svmmodel(libtestfile)
13. end
4 实验结果与分析
本文使用的分词系统是中国科学院计算技术研究所汉语词法分析系统ICTCLAS[11],分词处理后去除常用停用词。实验采用由台湾大学林智仁教授开发的LIBSVM[12]进行SVM分类,我们选用线性SVM分类器。实验中线性SVM分类器采用libsvm默认参数。
4.1 数据集与评价方法
数据集采用复旦大学的文本分类语料,从中选取宇航、计算机、经济、农业、艺术、历史、政治、医学、军事九个类别,删掉文档中除标题与正文外的无关信息,并从中随机选取3 225篇文档,使训练集和测试集的文本数量之比为2∶1进行实验。数据集文本分布情况如表1所示。

表1 语料集
本实验采用查准率P(precision)和查全率R(recall)来作为文本分类的测评标准,此外还选取F1值作为标准测度,它是综合考虑查准率和查全率的一个指标。计算公式如下:

(8)
其中,P为类的查准率,R为类的查全率,TP为正确分类到ck类的测试文档数,FP为错误分类到ck类的测试文档数,FN为属于但未被分类到ck类的测试文档数。
上面提出的查准率、查全率及F1值都是针对单个类的分类情况而言的,当需要评价某个分类算法时,需要将所有的类上的结果综合起来得到平均的结果,实验采用宏平均F1方法。
上式中,m是类别数。
4.2 实验比较和结果分析
就特征选择和特征项权重计算中位置因子系数的确定进行实验,从α=β=1开始,随着α的增大和β的减小,特征项在标题区的重要性越来越强,在正文区的重要性越来越弱,因此用(α,β)表示变化的位置权重向量,以0.1为变化间隔,可衡量不同位置权重对分类效果的影响。
为了获得合适的特征项位置权重(α,β)值,通过控制变量,在不缩减特征项集维数情况下,采用PCHI-PTFIDF算法进行文本分类实验,实验得到文本分类宏F1值如图1所示。
由图1可知,特征项位置权重(α,β)值取(1.2,0.8)时,文本分类宏F1值最高,即特征项在标题区域的权重α取1.2,特征项在正文区域的权重β取0.8时可以获得较好的分类效果。与未考虑特征项在文本中位置重要性(α=β=1)时对比,文本分类的宏F1值提升了0.9%。
为了考察PCHI算法和PTFIDF方法的优化效果,特征项位置权重(α,β)值取(1.2,0.8)时,将PCHI-PTFIDF分类算法、PCHI算法、PTFIDF算法与传统分类算法做比较。图2为不同算法随特征集维数变化时的分类效果图。
从图2可以看出,特征项集维数较小时,文本中不相关或冗余特征所占比重大,因而传统CHI算法和PTFIDF算法分类效果较差。而维数较低时PCHI方法和PCHI-PTFIDF就有较高的宏F1值,且随着维数增加,这两种算法变化稳定,鲁棒性较强。当维数达一定程度时,传统算法和改进TF-IDF算法的分类效果随维数增加首先开始下降,说明PCHI-PTFIDF算法有效地剔除了特征集中的冗余特征,保留了分类能力更强的特征项,达到确保分类精度的目的。从图2可以还可以看出,1 500维时,PCHI-PTFIDF算法的宏F1值达0.88,可从较大程度上确保分类的准确性,同时实现特征维数有效压缩。因此我们以维数1 500为例,分析不同文本类别的分类效果。表2是特征维数为1 500时不同文本类别的宏F1值,图3为对应的折线图。
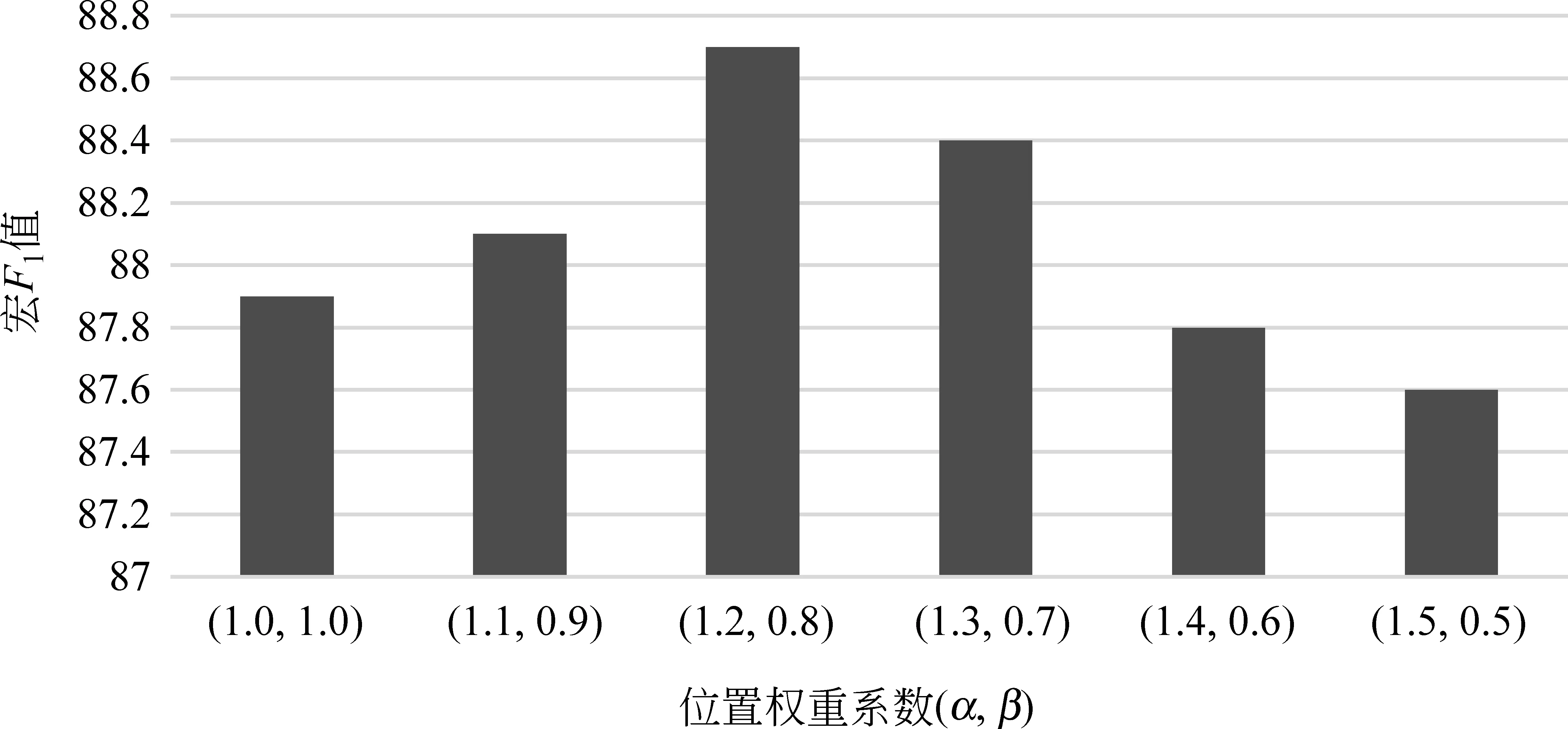
图1 文本分类宏F1值随特征项位置权重的变化
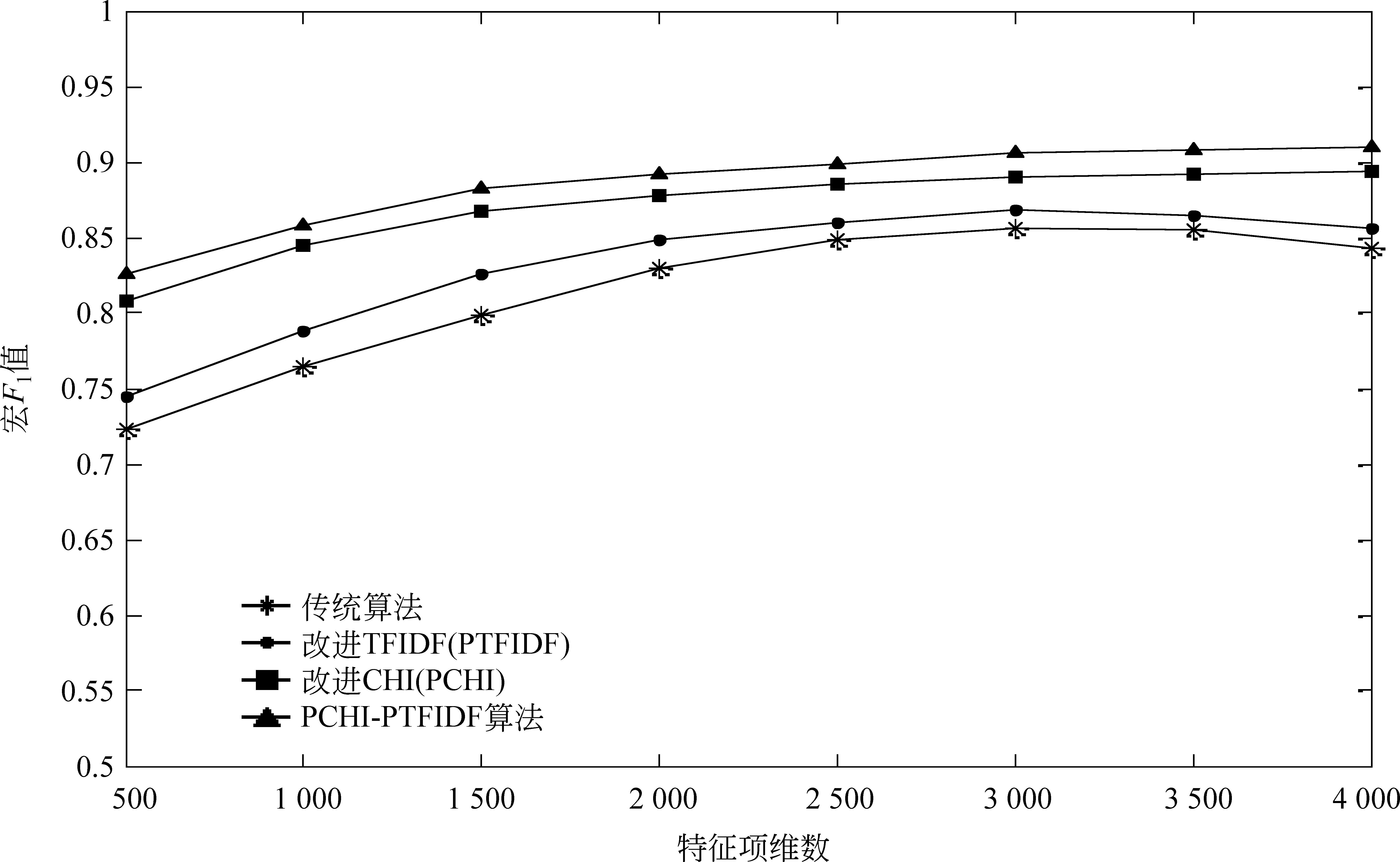
图2 不同特征维数下文本分类宏F1值比较

续表

图3 维数1 500时不同分类算法宏F1值对比图
统计不同算法的宏F1值得出: PTFIDF算法、PCHI算法、PCHI-PTFIDF算法的宏F1值分别提高了3.73%、8.95%、10.91%。从图3可以看出,相较于其他三种算法,本文提出的PCHI-PTFIDF算法分类效果最佳,其中宏F1值最高的类别是历史类。医学和军事类别分类效果最差,原因是这两种类别文本篇幅普遍较短,文档向量含有较多空值,文档向量的稀疏性导致分类能力下降。从图3还可以看出,PCHI算法也使分类效果得到显著提升,说明通过对低频、分类能力弱的词项的过滤,很好地改善了传统CHI的缺陷。PTFIDF通过引入词长、位置信息改善了文本向量权重分布,使分类效果进一步得到优化。
5 结论
本文通过分析特征选择低频词敏感、冗余特征比重较大的问题,和文本向量权重分布不精确的问题,提出了PCHI-PTFIDF的文本分类方法,利用最大程度减少信息损失的条件下使特征维数有效压缩的原理,有效地选出了分类能力较强的特征项集,并进一步优化了特征项的权重计算,调节位置系数得到分类能力更强的位置权重因子,使文本分类的精度提高了0.9%。通过实验可知,新型的文本分类方法相对于传统的方法,宏F1值提升了约10%。
[1] Sebastiani F. Machine learning in automated text categorization[J]. Acm Computing Surveys, 2002, 34(2): 1-47.
[2] DeySarakar S, Goswami S. Empirical Study on Filter based Feature Selection Methods for Text Classification[J]. International Journal of Computer Applications, 2013, 81(6): 38-43.
[3] 胡龙茂. 中文文本分类技术比较研究[J]. 安庆师范学院学报(自然科学版), 2015(2): 49-53.
[4] 代六玲, 黄河燕, 陈肇雄. 中文文本分类中特征抽取方法的比较研究[J]. 中文信息学报, 2004, 18(1): 26-32.
[5] 肖雪, 卢建云, 余磊,等. 基于最低词频CHI的特征选择算法研究[J]. 西南大学学报(自然科学版), 2015(6): 138-143.
[6] 刘振岩, 孟丹, 王伟平,等. 基于偏斜数据集的文本分类特征选择方法研究[J]. 中文信息学报, 2014, 28(2): 116-121.
[7] 刘海峰, 苏展, 刘守生. 一种基于词频信息的改进CHI文本特征选择[J]. 计算机工程与应用, 2013, 49(22): 110-114.
[8] 李国和, 岳翔, 吴卫江,等. 面向文本分类的特征词选取方法研究与改进[J]. 中文信息学报, 2015, 29(4): 120-125.
[9] 申剑博. 改进的 TF-IDF中文本特征项加权算法研究[J]. 软件导刊, 2015(4): 67-69.
[10] Yang Y. A re-examination of text categorization methods[C]//Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 1999: 42-49.
[11] Zhang H P, Yu H K. Xiong D Y, et al. HHMM-based Chinese lexical analyzer ICTCLAS[C]//Proceeds of the Sighan Workshop on Chinese Language Processing. Association for Computational Linguistics, 2003:758-759.
[12] Chang C C, Lin C J. LIBSVM: A library for support vector machines[J]. Acm Transactions on Intelligent Systems & Technology, 2011, 2(3): 389-396.

叶敏(1989—),硕士,主要研究领域为自然语言处理、数字图书馆。
E-mail: yanmin_ye@126.com

汤世平(1975—),博士,讲师,主要研究领域为自然语言理解。
E-mail: simontangbit@bit.edu.cn

牛振东(1968—),博士,教授,主要研究领域为智能教育软件系统、数字图书馆。
E-mail: zniu@bit.edu.cn
An Improved Chinese Text Classification Algorithm Based On Multiple Feature Factors
YE Min, TANG Shiping, NIU Zhendong
(Department of Computer Science, Beijing Institute of Technology, Beijing 100081, China)
1003-0077(2017)04-0132-06
TP391
A
