基于模式的远监督关系抽取算法
2017-10-11王加楠
王加楠,鲁 强
(中国石油大学(北京) 计算机科学与技术系,北京 102249)
基于模式的远监督关系抽取算法
王加楠,鲁 强
(中国石油大学(北京) 计算机科学与技术系,北京 102249)
远监督关系抽取算法能够自动将关系库中的关系与无标注的文本对齐,以进行文本中的关系抽取。目前提出的远监督关系抽取算法中,大多数是基于特征的。然而,此类算法在将实例转换为特征时,经常会出现关键信息不突出、数据集线性不可分等问题,影响关系抽取的效果。该文提出了一种基于模式的远监督关系抽取算法,其中引入了基于模式的向量,并使用了基于核的机器学习算法来克服上述问题。实验结果表明,该文提出的基于模式的远监督关系抽取算法,能够有效地提升远监督关系抽取的准确率。
远监督;关系抽取;模式;核方法
Abstract: Distant supervision for relation extraction is an approach that can extract relations from texts automatically by aligning a database of facts with texts. Most of existing solutions are feature-based algorithms with certain defects. In this paper, we propose a pattern-based algorithm for distant supervised relation extraction with pattern-based vector. A kernel-based method is used in the algorithm to overcome the problems in feature-based algorithm. The experimental result shows that our algorithm can successfully improve the precision of distant supervision for relation extraction.
Key words: distant supervision; relation extraction; pattern; kernel method
1 引言
文本信息提取是指自动从文本中提取出人们感兴趣的信息,并以结构化的形式存储,以便进一步利用。关系抽取作为文本信息抽取中一项重要任务,其主要目标是识别并获取实体间的关系信息。基于机器学习的关系抽取算法主要包括: 有监督的关系抽取算法[1-3],无监督的关系抽取算法[4-5],以及远监督的关系抽取算法[6-8]。
有监督的关系抽取算法发展得相对成熟,具有较高的性能。然而,由于所需的人工标注代价太大,导致训练数据缺乏,使其无法胜任海 量 数 据背景下的关系抽取任务。无监督的关系抽取算法无需人工标注,通常用于开放领域及未知领域的关系抽取。然而,其准确率相对较低,且得到的关系没有名称,因此在抽取后需要进一步筛选和命名才可以使用。远监督的关系抽取算法,主要解决了有监督关系抽取算法中对标注数据的依赖问题。其利用已有的关系库,将关系库中的关系与文本数据中的实例建立映射,这一过程也被称为“对齐”。由于远监督的关系抽取算法很好地解决了有监督和无监督关系抽取算法中的问题,既不依赖于标注数据,又具有标准的关系名称,因此在提出后获得了很多学者的研究。
在实现远监督关系抽取的众多算法中,有一类使用特征对文本实例进行表示的算法,称为基于特征的远监督关系抽取算法。基于特征的表示方法广泛应用于自然语言处理任务中,然而在关系抽取任务中,该方法具有以下局限性。 首先,没有突出关键的特征信息。基于特征的实例表示方法,通过获取文本语句中所含的词法、句法、语法等特征信息,构造特征向量,并应用于分类器中。在关系抽取任务中,应尽量选取有利于关系识别的特征信息,特别要突出具有决定作用的特征信息。例如,要确定图1中句1中两个实体间的关系,关键的特征信息是两个实体的类型“PER”和“ORG”,以及连接两个实体的动词“创办”。而对于图1中的句2,最重要的特征信息则是词项“CEO”。基于特征的方法选取了大量的特征信息,但每个特征都是独立平等的,没有针对关系抽取任务做出优化。其次,实例在特征空间中往往是线性不可分的。一些特征,如实体之间的距离特征,具有普遍性。这类特征出现在大量甚至所有的实例中,使得所构造的特征向量在向量空间中通常是线性不可分的。而基于特征的模型大多使用了具有线性性质的分类器,如逻辑回归分类器等,导致算法的准确率在一定程度上打了折扣。

图1 “实例—关系”示例
在有监督的关系抽取中,为了解决以上问题,提出了基于核的实例表示方法。基于核的方法并不显式地抽取特征信息,而是直接使用核函数对实例进行计算。由于不同方法中核函数的设计不同,因此其对不同特征的侧重也不同。例如,最短依赖路径核函数以实体间的最短依赖路径作为计算的主要依据。此外,当对线性不可分的数据进行线性分类的时候,基于核的算法能够在一定程度提升分类的准确率[9]。基于核的实例表示方法在有监督关系抽取中得到了广泛的应用,并取得了良好的效果。
核函数本质上是特征空间中的内积函数,因此要求相关的算法模型在执行过程中仅依赖于内积。然而此类算法多为有监督的学习算法,如支持向量机等。远监督关系抽取算法中无法直接利用监督信息,因此不能直接应用核函数。为了解决这一问题,本文对基于特征的远监督关系抽取算法做了扩展,提出了基于模式的远监督关系抽取算法。本文的主要工作如下:
(1) 提出了基于模式的远监督关系抽取算法(第3.2节)。该算法对已有的基于特征的远监督关系抽取算法做了扩展,在其中使用了基于模式的向量。该算法提供了通用的扩展接口,因此可应用于任何基于特征的远监督关系抽取算法。
(2) 借鉴无监督关系抽取中模式的概念,设计了基于模式的向量(第4.1节)。在传统的特征向量中,每一个维度对应一个特征。但在本文设计的模式向量中,每一个维度对应一个模式。为了与传统的特征向量相区分,本文中所使用的向量称为模式向量。模式向量能够有效地区分不同关系的实例,从而提升关系抽取的准确率。
(3) 提出了模式向量的构造方法(第4.2节)。以分层聚类为基础,在其中应用了基于核的实例表示方法,从而克服了基于特征的实例表示方法带来的局限性。
(4) 通过实验,验证了基于模式的远监督关系抽取算法能够有效地提升关系抽取的准确率(第5节)。
2 背景
2.1 远监督关系抽取 远监督关系抽取的基本思想是将关系库中的关系与文本实例进行对齐[10-11],对齐的主要依据是关系与文本实例所共有的实体对。因此,可以将实例与关系按照实体对进行分组。图2即是一个简单的分组,可以看到,关系库中的两个关系与文本库中的四个实例通过其共有的实体“比尔盖茨”、“微软”建立了简单的联系,每一个实例都可能表达了其中的某个关系。远监督关系抽取的目标就是自动地将实例与其真正表达的关系对应起来。

图2 远监督关系抽取中的实例与关系分组示例
2.2 基于核的实例表示方法
基于特征的方法将实例转化为一系列的特征,然后生成特征向量。在自然语言处理中,实例大多具有内在的句法、语法结构,转换为特征后会损失一定的结构信息。例如,解析树被转化为特征后,丢失了其树形的结构,形式上与其他特征并无二致。
基于核的实例表示方法[12]保持了实例原有的表达形式,使用一个精心设计的核函数直接对实例进行计算。核函数是符合特定条件的相似度函数,一个核函数必须是对称且半正定的。核函数本质上是在高维空间中计算实例间的内积,从而将一对实体(x,y)映射为它们的相似度得分K(x,y)∈[0,∞]。
核函数无需显式地对实例进行转换,而是直接对实例中的特征进行计算。例如,在解析树核[13]中,直接对实例的解析树进行计算。其核函数计算了两个实例的解析树中公共子树的数量。
基于核的方法的关键问题在于核函数的构建。针对不同的任务,核函数应尽量利用对该任务的效果具有关键意义的特征信息。
许多算法中直接利用了实例间的内积,这类算法被称为dual学习算法。将其中的内积替换为特定的核函数,即可用在基于核的学习算法中。支持向量机是应用最为广泛的dual学习算法。
3 基于模式的远监督关系抽取算法
3.1 问题 基于特征的实例表示方法,从文本中获取词法、句法、语法等特征信息,并构造特征向量。特征向量的每一个维度均对应一个特征,维数等于语料库中所有不重复的特征的数量。每一个维度上的分量取值为0或1,代表实例是否具有该维度所对应的特征。表1给出了两个实例、对应的关系,以及从实例获取的部分特征。
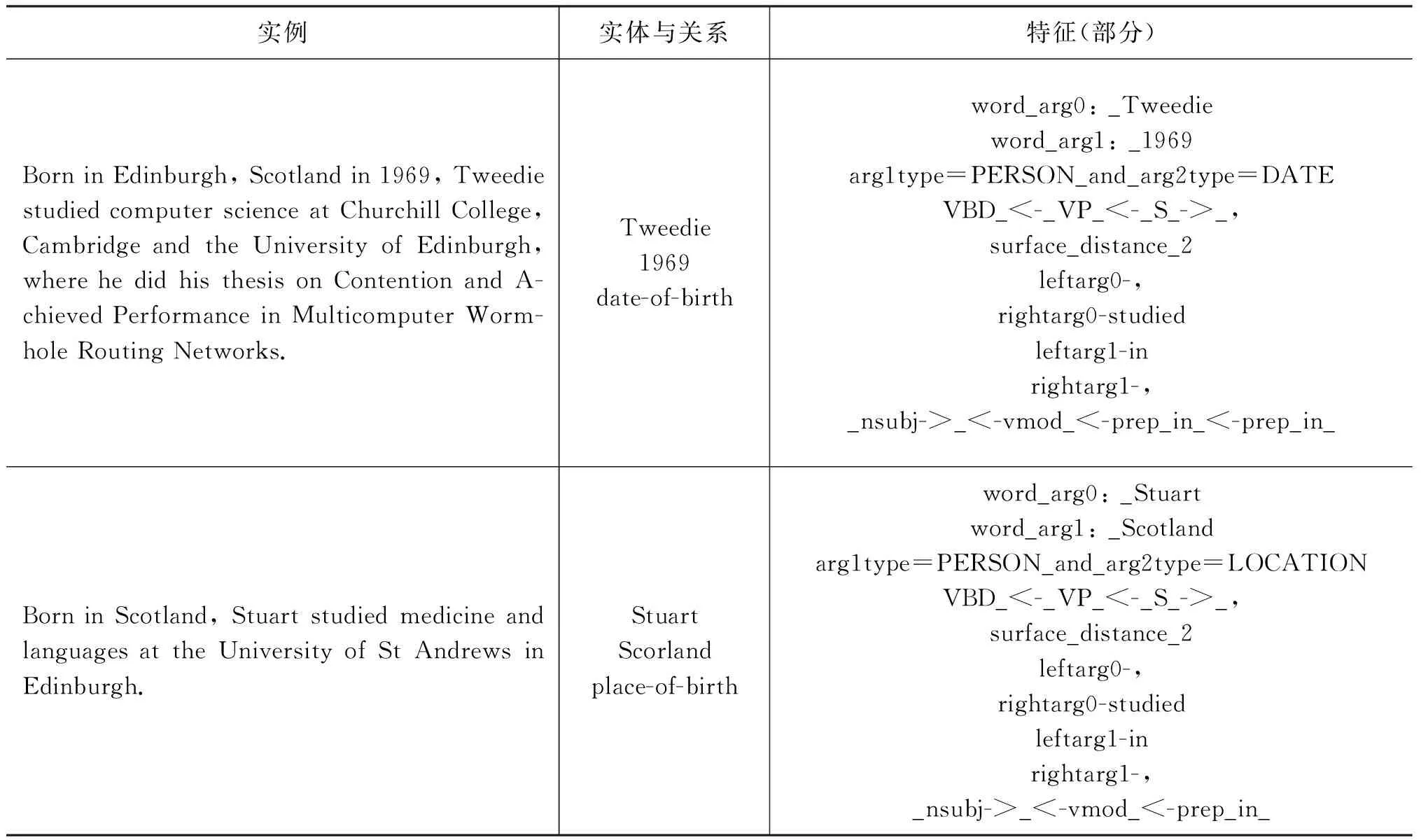
表1 基于特征的实例表示示例
从表1可以看出,虽然两个实例所表达的关系并不相同,但它们的特征中却有相当一部分是重复的,如surface_distance。这些重复的特征几乎在所有关系的实例中均会出现,对识别、区分关系的意义并不大。而表1中真正关键的特征,如argtype,仅占特征中的一小部分。此外,依赖树包含了句子的主干结构,对于关系抽取具有重要意义。而表1中的依赖树特征仅仅是一个简单的字符串,已经丢失了结构信息。由此可见,基于特征的方法并没有突出关系抽取任务中所需的关键特征。
此外,由于特征的重复出现,导致实例在该特征空间中往往是线性不可分的。基于特征的远监督关系抽取模型,通常使用具有线性性质的分类器,如逻辑回归分类器等,从而导致关系抽取的准确率在一定程度上打了折扣。
3.2 算法设计
本文的目标是使用基于核的方法,替代基于特征的方法,从而改善后者的局限性。为了实现这一目标,本文对基于特征的远监督关系抽取算法进行了扩展,提出了基于模式的远监督关系抽取算法。算法中训练部分的描述见图3。

图3 基于模式的远监督关系抽取训练算法
由图3可见,基于模式的远监督关系抽取算法,使用模式向量替换了已有算法模型中的特征向量。而训练算法中所用到的模型,仍然为原有算法中的模型。模式向量在形式上与特征向量一致,因此具有通用性,任何基于特征的远监督关系抽取算法均可使用本文提出的算法进行扩展。基于模式的远监督关系抽取算法是一种简单易行的解决方案。
4 模式向量
4.1 基本定义
4.1.1 模式的定义 在人工制定的关系抽取规则中,模式是特定的词法、句法、语法结构的组合,这符合人们书写文本的规律。例如,要表达“雇员(A,B)”这一关系,可以使用“A在B工作”这样的模式,而该模式则唯一表达了上述关系。一个定义完善的模式,其所表达的语义是唯一且确定的,从而能够准确地对实体间的关系进行判别。
由于语言的多样性,对同一种关系的表述可能有多种模式。如图4所示,可以建立“关系—模式—
实例”三级关联,其中每种关系对应的模式的数量是有限的。因此,表达某种关系的所有实例,可以依据其模式分为多个组。

图4 关系—模式—实例三级关系示例
本文中采用Bunescu与Mooney[14]对模式的定义,即: 模式是由两个实体的类型以及实体间的最短依赖路径组成的。实体间的最短依赖路径通常包含了一句话的骨干结构,与人工制定的规则中的模式类似。
4.1.2 模式向量的定义
本节提出了模式向量的定义。模式向量中每一个维度均对应于一个模式,因此模式向量的维数等于模式的数量。在理想情况下,每个实例唯一对应一个模式,则该实例的特征向量中,除了相应模式对应维度的分量为1,其他维度的分量均为0。模式向量建立了“模式—实例”这两级间的关联,而训练后所得到的模型,则建立了“关系—模式”两级间的关联。
然而,在实际的学习过程中,很难准确地建立实例与模式间的联系。因此,本文采用以下方法定义模式向量,作为对理想的模式向量的近似。对每个实例x,定义其模式向量为式(1)。
f(x)=[K(x,p1),K(x,p2),…,K(x,pN)]
(1)
其中,pi(i=1,2,…,N)为所有的模式,N为模式的数量,K(x,pi)∈[0,1]表示实例x对应于模式pi的可能程度,f(x)即为所构造的模式向量。同时,该模式向量为归一化的向量,即所有维度的分量之和为1。
4.2 模式向量的构造算法
根据上一节中的定义,模式向量的构造算法如图5所示。

图5 模式向量构造算法
4.2.1 相似度函数
模式向量中的分量K(x,pi)表示实例x与模式pi对应的可能性,本文以实例x与模式pi之间的相似度作为可能性的近似值。具体的计算方法如下: 首先提取实例x的模式px,然后计算两个模式的相似度K′(px,pi),最后对各个分量进行归一化。
对于两个模式a和b,按照4.1.1节对模式的定义,a1a2…am和b1b2…bn为对应的两条最短依赖路径。Bunescu和Mooney[14]通过式(2)计算相似度。
(2)
其中,c(ai,bi)=|ai∪bi|是ai与bi共有特征的数量。例如,在图6中,S为原始语句所对应的依赖图,P为实体Protesters与实体stations对应的模式,包括最短依赖路径及该路径上元素的特征(方括号中)。

图6 最短依赖路径核示例
本文对该最短依赖路径核函数做了部分改动,去除了实体词特征,如图6方括号中的protesters与stations。因为对于模式的相似度而言,无需考虑实体词。
4.2.2 模式提取
构造模式向量之前,首先要提取出所有模式,即pi(i=1,2,…,N)。本文根据模式的相似度,将实例进行聚簇,并认为每个簇中的实例具有相同的模式。之后,选择位于簇中心的实例,提取其模式作为该簇对应的模式。
本文所使用的聚簇方法基于分层聚类。分层聚类可以分为凝聚的分层聚类(HAC)和分裂的分层聚类,前者采用自底向上的策略,后者采用自顶向下的策略。本文采用改进的HAC方法。
如图7所示,基本的HAC算法首先将每个实例视为一个簇,然后迭代地合并最相似的两个簇,直到所有簇之间的相似度都小于某个特定的阈值为止。描述簇与簇之间的相似度通常有三种方法: 单连接、全连接和平均连接。算法从两簇中各选取一个实例组成一对,计算其相似度。上述三种方法分别取所有实例对中的最大相似度、最小相似度和平均相似度作为簇与簇之间的相似度。
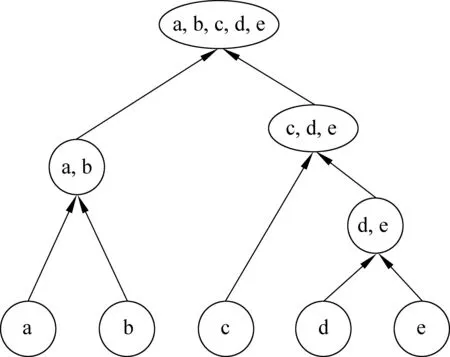
图7 HAC算法示例
HAC算法中,最终得到的聚簇的数量,取决于上文提到的相似度阈值。本文采用Rosenfeld和Feldman[4]提出的方法进行计算,该方法无需设定相似度阈值,因此无需指定聚簇的数目。在聚簇中使用单连接来刻画簇间相似度,并将聚簇的停止条件设置为: “两个簇的元素之间的平均相似度小于最大相似度的α倍”,其中,α为一常数且0<α<1。
聚簇完成之后,对每一个簇,要选择该簇的中心元素,并提取其模式作为该簇的模式。根据K-medoids算法中对聚簇中心的定义,本文通过以下方法选择聚簇中心实例: 对簇中每一个实例,分别计算其与簇中其他实例的相似度并求和,相似度总和最大的元素则为该簇的聚簇中心。
整个模式提取算法的描述见图8。
图8 模式提取算法
5 实验与评估
5.1 实验数据 本文实验使用了Google Research提供的数据集。该数据集包含了维基百科中的文本片段,以及从该片段中提取出的关系三元组。每个关系三元组均对应有人工的评估结果,可用于判断关系的正确性。本文以该数据集为基础,将其中的语料与Freebase进行对齐,并选取其中的出生日期、出生地、教育程度及机构四种关系进行实验。
实验前,对Google Research提供的数据集进行了以下处理,以便实验使用。
首先,将数据集中的三元组与文本片段建立关联。由于三元组中的两个实体均以Freebase中MID的形式表示,而文本片段中含有多个实体,需要确定关系三元组对应于文本中的哪一对实体。处理过程中,少量文本未能与关系三元组进行对应,这一部分数据未在实验中使用。
其次,数据集中包含了五位评估者对关系正确性的判断。实验中,当有四位或超过四位评估者给出“yes”的判断时,则认为该实例表达了相应关系,否则认为该实例并未表达关系。
最终在实验中使用的数据集构成见表2。其中,训练集与测试集按照4∶1的比例随机采样生成。

表2 实验数据集的构成
5.2 实验结果与评估
5.2.1 模式向量评估 与传统的特征向量相比,模式向量能够有效地区分不同关系的实例。即表达不同关系的两个实例,其相似度应尽量小。本文使用以下方法进行验证。
对任意两个关系r1、r2、X1、X2分别为对应于这两个关系的实例集合。对每个实例对(a,b)∈{(x1,x2)|x1∈X1,x2∈X2},分别使用特征向量和模式向量计算实例间的余弦相似度,称为特征相似度和模式相似度。最后,对相似度为0的实例对进行统计,结果见表3。
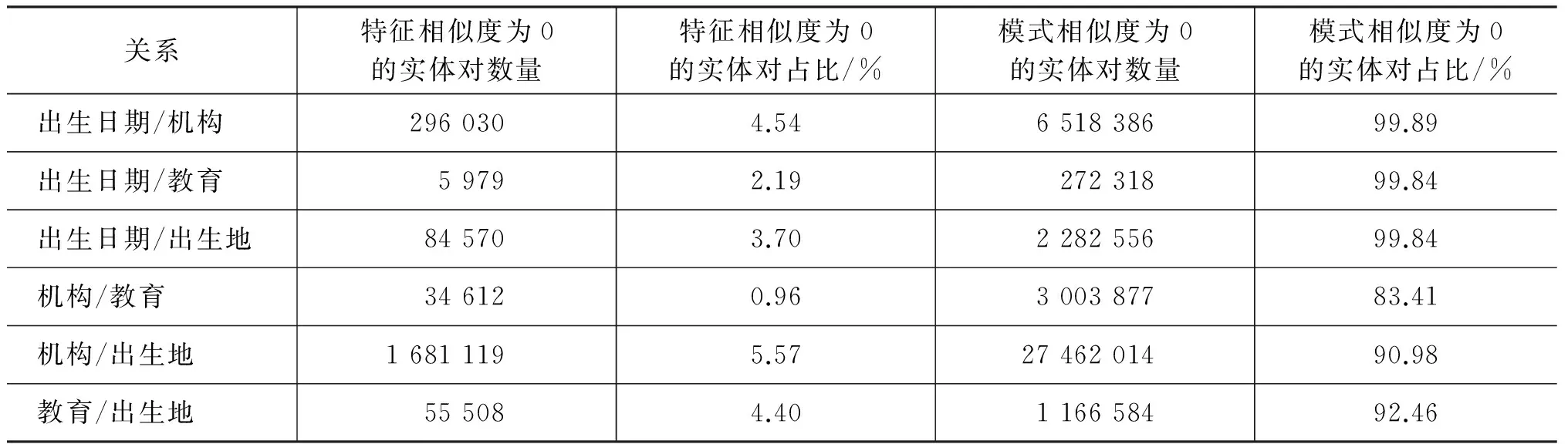
表3 相似度为0的实例对的数量及占比
从表3中可见,使用传统特征向量的情况下,仅有不到10%的实例对的相似度为0。这意味着不同关系的实例或多或少共享了一部分特征,正是造成数据集线性不可分的主要原因。而模式向量则大幅提升了这一结果,90%以上的实体对的相似度为0,因此能够对不同关系的实例进行更好的区分,从而提高关系抽取的准确率。
5.2.2 基于模式的关系抽取算法评估
本文提出的关系抽取算法,能够对使用特征向量作为输入的算法模型进行扩展。通过对基准模型进行扩展,并比较扩展后与扩展前模型的性能,对本文提出的算法进行评估。本文选择了以下三种基准模型进行实验。
(1) Mintz++。该模型基于Mintz等[6]提出的模型,主要做了如下改进: (1)对应于同一实体对的实例不再合并,(2)允许同一实体对具有多种关系。
(2) Hoffmann。即Hoffmann[15]提出的MultiR模型。该模型将关系抽取视为多实例、多标签问题,并基于“at-least-one”假设。在学习过程中并未使用分类器,而是使用感知器算法。
(3) MIML-RE。该模型由Surdeanu[16]提出,将关系抽取视为多实例、多标签问题,并在学习过程中使用逻辑回归分类器。其中,关系级的分类器在“at-least-one”假设的基础上,还对关系间的依赖进行了建模。
具体的实验结果见表4。可以看出,与三种基准模型相比,基于模式的关系抽取算法在准确率上均有一定的提升,但在召回率上则有小幅的下降。
实验结果对应的准确率/召回率曲线见图9。从Mintz模型可以看出,当召回率达到0.7左右时,基于模式的算法保持了一定的准确率,没有出现大幅度的下滑。在Hoffmann模型中,在召回率达到0.7左右时,基于模式的算法在准确率方面 表 现 得 较
为稳定。在MIML-RE模型中,基于模式的算法均维持了较高的准确率。在上述三个模型中,基于模式的算法对应的曲线的最右端横坐标均小于原始算法的最右端横坐标。

表4 三种基准模型及其改进模型的实验结果
综上所述,基于模式的算法对基准模型的提升主要体现在召回率达到一定高度时,在召回率略微下降的前提下,明显地提升了关系抽取的准确率。对于使用线性分类器的多实例、多标签模型,如MIML-RE模型,本算法带来的准确率提升更加显著。
6 相关工作
有监督的关系抽取通常被视为分类问题,按照实例表示方法的不同可以分为基于特征的分类模型和基于核的分类模型。多位研究者提出了不同的特征提取策略,用来将序列、解析树、依赖树等结构中可能有用的信息转换为特征向量[2]。基于特征的方法难点在于如何选择合适的特征。Jiang和Zhai[17]对此做了详细的研究。基于核的方法使用更加自然的方法,允许使用大量特征但并不显式地提取它们。在之前的研究中,多种核函数被提出,如卷积树核[18],子序列核[19],依赖树核[14]等。

图9 三种基准模型及其改进模型的PR曲线图
远监督关系抽取方法的提出,主要是为了解决有监督关系抽取中缺乏标注数据的问题。远监督方法最早由Craven和Kumlien[10]引入信息抽取领域,主要用于抽取蛋白质与基因间的关系,使用Yeast Protein Database作为关系库。之后,Mintz等[6]将其引入关系抽取中,并作出如下假设: (1)每个实体对仅具有一种关系,(2)所有包含该实体对的实例均表达了此关系。Riedel等[7]放松了假设(2),提出了重要的“at-least-one”假设,即“至少有一个包含该实体对的实例表达了该关系”。Hoffmann等[15]则进一步放松了假设(1),允许两个实体间具有多种关系。之后,Surdeanu等[16]引入了多实例、多标签学习框架,建立了更为形式化的模型。除了上述基于特征的模型之外,部分学者从其他角度提出了多种模型。Alfonseca等[20]提出了分层主题模型,使用三个主题模型分别来捕捉背景模式、对应于实体对的模式和对应于关系的模式。Takamatsu等[8]则通过对常见模式的预测,判断其是否真正表达了目标关系,从而移除错误的关系标签。
无监督关系抽取算法主要利用无监督的聚簇技术来发现文本中的关系。Rosenfeld和Feldman[4]使用实体词之间的文本作为模式,并利用k-means和HAC算法来进行聚类。Bollegala等[21]不仅使用了词法特征,还使用了浅层的句法特征作为模式,并同时对实体对和模式进行聚类。Wang等[22]在聚类时,利用过滤技术去除了不太可能表达关系的实例。
7 结论和展望
本文提出了一种基于模式的远监督关系抽取算法,利用模式向量,对现有的基于特征的远监督关系抽取算法进行了扩展。在模式向量的构造过程中,应用了基于核的实例表示方法。因此,扩展后的算法克服了基于特征的算法中的局限性。实验结果表明,模式向量能够有效地区分不同关系的实例,基于模式的远监督关系抽取算法对关系抽取的准确率有明显的提升。
下一步的工作,是设计出更为合理的核函数及聚类算法,使基于模式的特征向量能够更加准确地对实例进行表示,从而进一步提升算法的性能。
此外,现阶段的研究尚未能做到直接将基于核的方法应用到远监督关系抽取中,在今后的工作中可以更深入地探讨基于核的远监督关系抽取算法的设计与实现。
[1] Zelenko D, Aone C, Richardella A. Kernel methods for relation extraction[J]. The Journal of Machine Learning Research, 2003(3): 1083-1106.
[2] Kambhatla N. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations[C]//Proceedings of the ACL 2004 on interactive poster and demonstration sessions. Association for Computational Linguistics, 2004: 22.
[3] GuoDong Z, Jian S, Jie Z, et al. Exploring various knowledge in relation extraction[C]//Proceedings of the 43rd annual meeting on association for computational linguistics. Association for Computational Linguistics, 2005: 427-434.
[4] Rosenfeld B, Feldman R. Clustering for unsupervised relation identification[C]//Proceedings of the sixteenth ACM conference on Conference on Information and Knowledge Management. ACM, 2007: 411-418.
[5] Yan Y, Okazaki N, Matsuo Y, et al. Unsupervised relation extraction by mining Wikipedia texts using information from the web[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2. Association for Computational Linguistics, 2009: 1021-1029.
[6] Mintz M, Bills S, Snow R, et al. Distant supervision for relation extraction without labeled data[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2. Association for Computational Linguistics, 2009: 1003-1011.
[7] Riedel S, Yao L, McCallum A. Modeling relations and their mentions without labeled text[M].Machine learning and knowledge discovery in databases. Springer Berlin Heidelberg, 2010: 148-163.
[8] Takamatsu S, Sato I, Nakagawa H. Reducing wrong labels in distant supervision for relation extraction[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. Association for Computational Linguistics, 2012: 721-729.
[9] Pham A T, Raich R. Kernel-based instance annotation in multi-instance multi-label learning[C]//Proceedings of Machine Learning for Signal Processing (MLSP), 2014 IEEE International Workshop on. IEEE, 2014: 1-6.
[10] Craven M, Kumlien J. Constructing biological knowledge bases by extracting information from text sources[C]//Proceedings of the ISMB, 1999: 77-86.
[11] Bunescu R, Mooney R. Learning to extract relations from the Web using minimal supervision[C]//Proceedings of the Annual meeting-Association for Computational Linguistics. 2007, 45(1): 576.
[12] Cristianini N, Shawe-Taylor J. An introduction to support vector machines and other kernel-based learning methods[M]. Cambridge university press, 2000.
[13] Collins M, Duffy N. Convolution kernels for natural language[C]//Proceedings of the Advances in Neural Information Processing Systems. 2001: 625-632.
[14] Bunescu R C, Mooney R J. A shortest path dependency kernel for relation extraction[C]//Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2005: 724-731.
[15] Hoffmann R, Zhang C, Ling X, et al. Knowledge-based weak supervision for information extraction of overlapping relations[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, 2011: 541-550.
[16] Surdeanu M, Tibshirani J, Nallapati R, et al. Multi-instance multi-label learning for relation extraction[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Association for Computational Linguistics, 2012: 455-465.
[17] Jiang J, Zhai C X. A Systematic exploration of the feature space for relation extraction[C]//Proceedings of the HLT-NAACL. 2007: 113-120.
[18] Qian L, Zhou G, Kong F, et al. Exploiting constituent dependencies for tree kernel-based semantic relation extraction[C]//Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2008: 697-704.
[19] Mooney R J, Bunescu R C. Subsequence kernels for relation extraction[C]//Proceedings of the Advances in neural information processing systems. 2005: 171-178.
[20] Alfonseca E, Filippova K, Delort J Y, et al. Pattern learning for relation extraction with a hierarchical topic model[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2. Association for Computational Linguistics, 2012: 54-59.
[21] Bollegala D T, Matsuo Y, Ishizuka M. Relational duality: Unsupervised extraction of semantic relations between entities on the web[C]//Proceedings of the 19th international conference on World wide Web. ACM, 2010: 151-160.
[22] Wang W, Besançon R, Ferret O, et al. Filtering and clustering relations for unsupervised information extraction in open domain[C]//Proceedings of the 20th ACM international conference on Information and knowledge management. ACM, 2011: 1405-1414.

王加楠(1990—),硕士,主要研究领域为自然语言处理、信息抽取。
E-mail: piovano@outlook.com

鲁强(1977—),通信作者,博士,副教授,硕士生导师,主要研究领域为知识工程、演化计算。
E-mail: luqiang@cup.edu.cn
Pattern-Based Distant Supervision for Relation Extraction Algorithm
WANG Jianan, LU Qiang
(Department of Computer Science and Technology, China University of Petroleum, Beijing 102249, China)
1003-0077(2017)04-0122-10
TP391
A
2015-12-17 定稿日期: 2016-03-23
国家自然科学基金(61402532)
