基于“词—词性”匹配模式获取的古汉语树库快速构建方法
2017-10-11宋天宝彭炜明朱淑琴宋继华
何 静,宋天宝,彭炜明,朱淑琴,2,宋继华
(1. 北京师范大学 信息科学与技术学院 北京 100875; 2. 北京联合大学 师范学院 北京100101)
基于“词—词性”匹配模式获取的古汉语树库快速构建方法
何 静1,宋天宝1,彭炜明1,朱淑琴1,2,宋继华1
(1. 北京师范大学 信息科学与技术学院 北京 100875; 2. 北京联合大学 师范学院 北京100101)
该文针对古汉语文本小、句简短、模式性强的结构特点,提出了一种基于“词-词性”匹配模式获取的快速树库构建方法,将句法标注过程规约为获取候选匹配模式、制定句法转换规则、自动生成句法树和最终人工校对四个步骤。该方法可大大缩减人工标注工作量,节省树库构建的工程成本,且所获取的匹配规则在古汉语教学研究中具有一定的实用价值。
古代汉语;树库构建;模式获取
Abstract: An efficient approach for ancient Chinese treebank construction is proposed, which is based on "word or POS" match strategy. To deal with the ancient Chinese characterized by short-clauses and typical-patterns, it divides the Chinese treebank construction into four steps: 1) candidate match pattern generation; 2) syntactic transformation rule composition; 3) syntactic parsing; 4) manual verification. In addition to minimize the manual annotation cost in treebank construction, the match patterns obtained during this process can provide data support for the ancient Chinese teaching and research.
Key words: ancient Chinese; treebank construction; pattern acquisition
收稿日期: 2016-07-09 定稿日期: 2017-03-29
基金项目: 北京师范大学青年教师基金(2014NT39)
1 引言
树库是带句法结构信息的深加工语料库,由于标注成本相对较高,汉语树库通常都带有很强的现代应用目的,主要为NLP自动句法分析以及以语料库语言学为背景的语法教学和研究。汉语树库构建的大部分生语料均取材于新闻文本,主要为现代汉语语料。但在汉语的语言教学和研究中,古代汉语(文言)也是不可忽视的一个方面,对深入理解中国文化和探究汉语发展源流具有重要意义。由于古汉语在词汇和句法层面都与现代汉语有着特定的系统差异,现代汉语树库的现有成果和构建方法不能直接移植到古汉语中。因此,古汉语的语言资源建设要远远滞后于现代汉语,具体而言,目前古汉语语料库加工多停留在分词和词性标注阶段,未见有成规模树库构建的研究。
当前构建古汉语树库,明确以下两点至关重要。
(1) 古汉语的核心文本,即传统典籍中的文言,是一个静态、有穷的封闭集合。在树库的应用方面,并不以实现通用的古汉语自动句法分析器作为主要目标;在构建策略上,也应着眼于最小化特定范围内语料标注的工程成本,采用“自动句法分析+人工校对”方法未必如基于规则的针对性策略有效。
(2) 古汉语不同于现代汉语的显著特点之一是: 小句简短且具有较强模式性。通过对35本上古汉语典籍统计发现,小句的平均长度为4.05个词长,可推断小句的句法结构相对简单、种类较少。因此,这种“强模式”特征可以考虑被用于古汉语树库构建。
2 相关工作
构建汉语树库依赖于经分词、词性标注的词法语料库,由于古汉语信息处理研究开展得并不广泛,目前从事这方面研究并构建了大规模语料库的主要有四处: (1)台湾《中央研究院》语言所自1990年起构建了古汉语语料库(the academia sinica ancient Chinese corpus, ASACC),包括上古汉语和中古汉语两个子库[1]; (2)英国谢菲尔德大学为研究汉语历时变迁而构建了谢菲尔德中文语料库(the Sheffield corpus of Chinese, SCC)[2],同样划分为上古汉语和中古汉语两部分; (3)南京师范大学陈小荷教授主持构建了以25种先秦传世文献为主的古汉语语料库,该库服务于先秦词汇统计和知识检索,在构建过程中采用了基于CRF的分词标注一体化方法[3]; (4)北京师范大学语言与文字资源研究中心以古今汉语平行语料库项目为背景,构建了以《十三经》为主的分词标注语料库[4]。其中,前两者的词类标记粒度较细,许多词类已细化到语义层面,标记集都在50个以上;后两者采用学界普遍认可的词性,标记集大小分别为21和15。以上语料库在生语料层面有很大重叠,但分词和词性标注却存在不少差异,这反映出在古汉语语法上的语言学争议同样存在。
不同于现代汉语的树库构建[5-9]和句法分析[10-14]等研究的广泛开展,目前古汉语的句法标注资源极少,基本都是小样本集上的尝试,如香港城市大学John Lee等构建的唐诗依存树库[15]、北京大学计算语言所彭炜明等选取《论语》《唐宋八大家文钞》语料构建的图解树库[16]。在此前提下构建古汉语树库显然是处在资源的原始积累阶段,大量的人工标注和校对不可避免。目前有益的工作是探索一种基于规则的句法标校辅助方法,以最大限度地减少人工机械重复的工作量。为了减少词性标注先验知识对本文方法的干扰,我们选取词性标记最为通用的北师大语料作为实验语料。
3 基于匹配模式的树库构建流程
针对古汉语小句简短、模式性强的结构特点,我们将句法标注过程规约为对“小句”的成分分析。句法树库的分析单位通常是以句号(。)、问号(?)、叹号(!)等切分所得的“整句”,而“小句”是用逗号(,)对整句做进一步切分所得的标点句。需要说明的是,此处的小句与语言学意义上的小句并不一定吻合,比如,逗号出现在句首状语之后,这样切分得到的“小句”只是一个状语成分。这种情况下该“小句”除了作内部成分分析之外,还需整体标记为状语,在最后阶段再统一并入小句。
本文的快速构建方法主要是解决小句的成分分析问题。由于小句长度不大,句法树结构通常也不复杂,在同一批语料中具有较高的整体复现率。因此,在实际标注中找出特定的能代表一批小句的若干“词/词性”序列,从而将去重后的待分析小句全集划分为若干子集通过为“词/词性”序列制定转换规则的方式,将它们进行批量的标注。我们将这种特定序列称为“匹配模式”(matching pattern),相关形式化定义如下:
• CS(小句,clause): W1/P1W2/P2… Wi/Pi… Wn/Pn,其中Wi表示小句中第i个词,Pi为相应的词性;
• CMP(候选模式,candidate matching pattern): U1U2… Ui… Un,其中Ui为某一具体词形或词性;
• Match: 对长度均为n的CMP{Ui}和CS{Wi/Pi},如果Ui=Wi或 Ui=Pi,i∈[1, …,n],则称CMP Match CS;
• CS_Set(CMP的匹配集): {CS | CMP Matches CS};
• CMP_Set(CMP的等价集合): {CMP | 对应相同CS_Set的CMP},因此CMP_Set与CS_Set是一一对应的关系;
• MP(匹配模式,matching pattern)和SS(句法骨架,syntactic skeleton): 若某个CS_Set共享相同的句法骨架,则称与其对应的CMP_Set中所有CMP都是MP,相应句法骨架为SS(图1)。在具体实现时,SS的结构类型不限,短语结构或依存结构均可。如果一个待分析的CS能够与一个MP匹配,那么将SS中占位符“*”逐个替换为对应的词,即可得到该CS的句法结构。
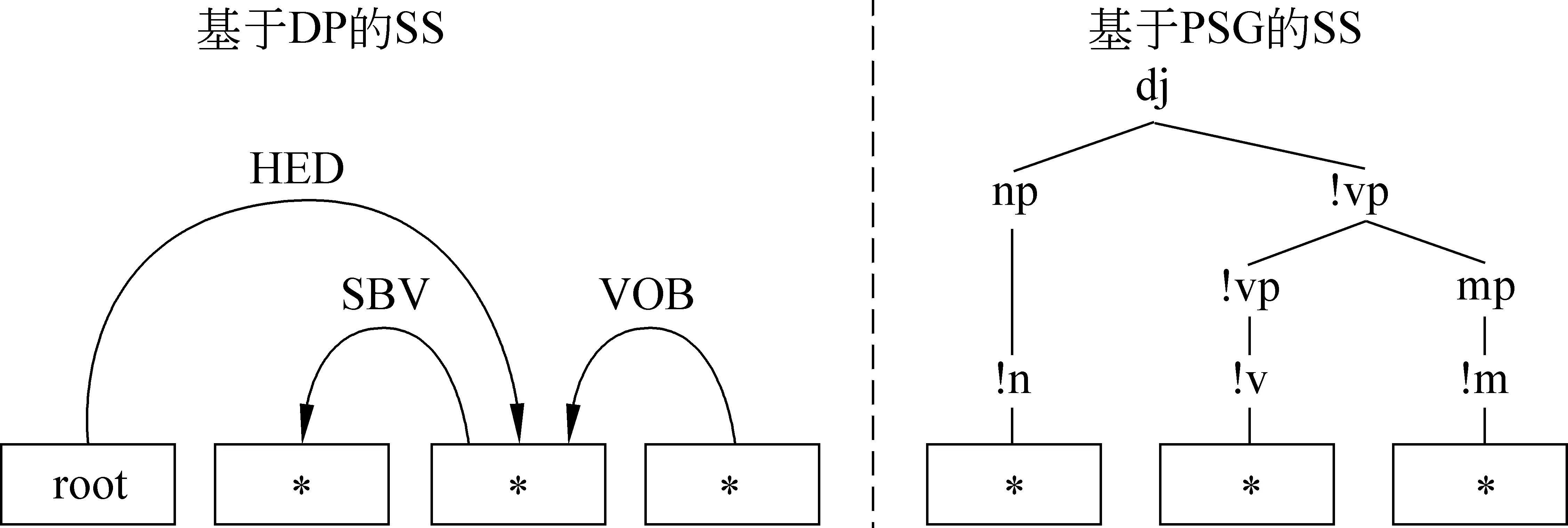
图1 基于DP和PSG的SS样例
CMP由语料库中CS采样生成,每个位置或取词形,或取词性。CMP取词形越多,匹配的CS就越少,成为MP的可能性就越大;反之,取词性越多,匹配的CS就越多,成为MP的可能性就越小。对于树库构建而言,CMP_Set的优劣与两个因素有关: (1)对应的CS_Set中各CS的树结构越趋同越好(理想情况下树结构全同,此时CMP_Set中各CMP均为MP); (2)在(1)的前提下对应的CS_Set越多越好。本文古汉语树库构建的流程如图2所示。

图2 树库构建总体流程
其中步骤(1)、(3)由程序自动完成,步骤(2)、(4)由人工完成。(1)是本算法的核心,将在第四节详述。由(1)生成CMP队列的大小将决定(2)的具体工作量。通过(1)的筛选,CMP对应的CS_Set在树结构上具有较高的趋同性。手工制定SS时,可从CS_Set随机选取不超过十个的CS,快速判断多数CS共享的树结构,并制定从CMP到SS的转换规则。
4 CMP优先队列获取算法
4.1 建立CS_Set和CMP_Set对应组 • CSCMP: 所有CS都用来生成CMP。在长度为n的经过分词、词性标注的CS中,每个位置或取词,或取词性,理论上可以生成2n个CMP(如图3中步骤①),考虑到计算复杂度,生成CMP时限制如下: 若某一词形Wi在语料库中的总频次小于3,则CMP中该词所在位置均设为词性,即Ui=Pi;
图3 CS_Set和CMP_Set对应组构建示意图
以下步骤用于选出那些CS_Set享有相同句法结构的对应组的CMP_Set。以图3为例,因为(a)、(f)和(g)三个CS具有相同的句法结构,(c)和(e)具有相同的句法结构,(b)是另一种句法结构(句法结构见图4),所以排除A、D(包含不同的句法结构)和E、F、G、H(不是最大的组),因此B、C、I和J这四个对应组的CMP_Set在以下步骤中应该被选出。
4.2 赋权CMP组
对每一个CMP_Set(或者对应的CS_Set),定义如式(1)(W值大的CMP组在树库构建时应优先考虑应用)所示。
(1)
第三节中给出评判CMP_Set优劣的标准: (a)所匹配的CS_Set的SS种类越少越好; (b)在(a)的前提下匹配的CS越多越好。对于(a),用|CMP_Set|(CMP_Set的集合大 小)的 值 来 表 征,因为|CMP_Set|与CS_Set的SS种数呈反比(图3),|CMP_Set|越大表明其中CMP的模式性越强;对于(b),由|CS_Set|(CS_Set的集合大小)的值来表征,|CS_Set|越大表明覆盖CS越多。又因为|CMP_Set|是一个指数级的增长过程,在相比较的两个CMP_Set之间,它们的|CMP_Set|的差异常常远大于|CS_Set|的差异,因此公式中对前者采用对数函数来抑制其变化趋势,并用α来微调。为了避免W=0的情况,又采取加1操作。α是待定的参数,在第六节,通过与金标准树库Treebank-Gold对比,来得到一个最佳范围。

图4 相似CS的不同依存树结构
4.3 删减CMP组
CS_Set之间存在大小不等的交集。在图5中,每个圆形表示一个CS_Set,它们中有些具有包含关系,如A-B, A-I, D-I。
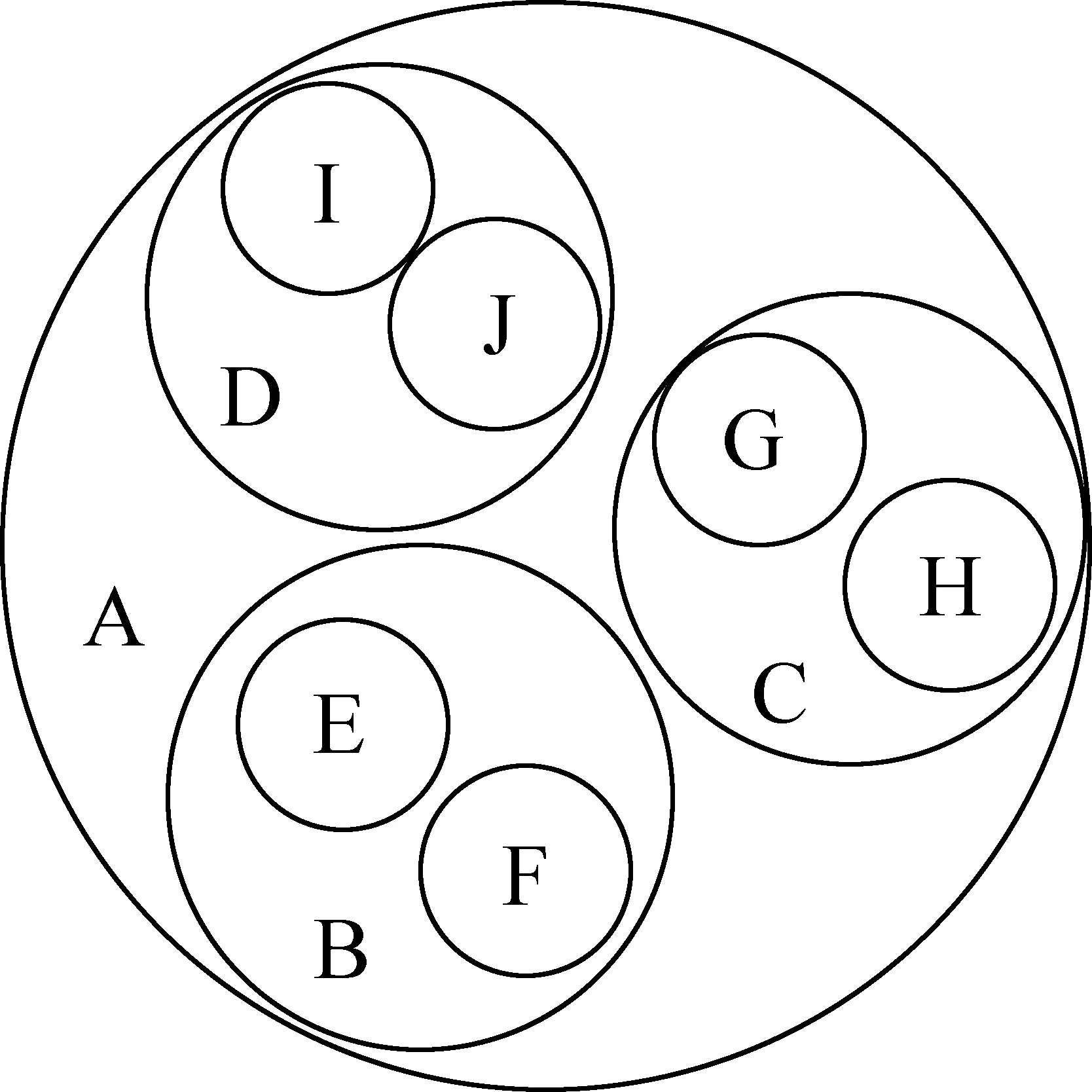
图5 CS_Set重叠关系示例
为了减少一个CS_Set被另一个CS_Set覆盖的情况,需对其中一些CS_Set进行消减,主要是消除其中的包含关系。首先定义两个集合:
• SC: CS_Set的保留集,初始时为按大小降序排列的CS_Set全集。
• GC: CS_Set的删除集,初始时为空集。
按以下顺序执行删减和恢复:
(1) 从SC中选出两个具有包含关系的CS_Set(按SC顺序选取),比较其W权值,权值小的CS_Set标记为“待删”。
(2) 将所有标记为“待删”的CS_Set从SC移至GC。此时SC中剩余CS_Set的CS覆盖率将大大降低。假设存在一种情况: 若W(B)>W(A),删A;若W(A)>W(C),删C,但是C与B没有交集,因此不应该被删除。以下步骤(3)将解决此问题。
(3) 将GC中的CS_Set按W值降序排列,依次考察其是否与SC中某一CS_Set存在交集,如果不存在,则将该CS_Set重新移回SC中。
SC中剩下的CS_Set所对应的CMP_Set即为这一步骤的最终结果。
4.3 产生CMP优先队列
将SC中的CMP_Set按W权值降序排列,并从每个CMP_Set中选出含词形数最多的一个作为该组的代表(根据以上CMP_Set定义,其中的CMP因为匹配的CS_Set都相同,故对该语料库来说都是等同的),加入优先队列。此外,对上述步骤中造成的少数未被CMP覆盖的CS,生成单独的全词CMP,加在优先队列的末尾。
5 评价标准
若优先队列中CMP均为MP,则通过SS批量标注的结果完全正确,不需要额外工作量。这意味着相对于逐句标注,本方法手工成本可以从小句总量降至优先队列的大小。若CS_Set存在结构歧义,则需对其中CS逐一检查,并修改错误的树结构,改正的成本稍大于从零标注。综合起来,针对某一CMP采用SS批量标注并检查、校正的成本与其CS_Set内不同结构树分布的混乱度(熵值)相关,可用如下公式来衡量。
其中,Tree(CS_Set)表示CS_Set内CS的不同SS的概率分布(需要人工构建的金标准树库Treebank-Gold)。
所有语料的树库构建成本,如式(4)所示。
(4)
6 实验结果
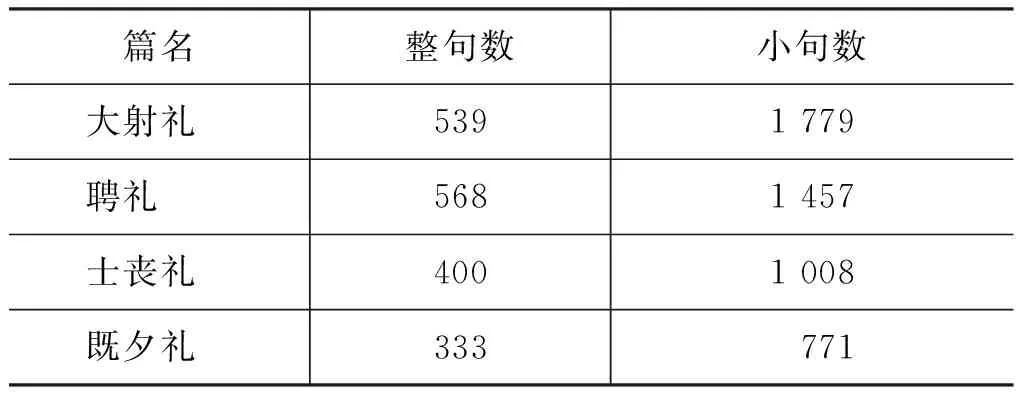
6.1 实验一: 《仪礼》 实验一采用从北京师范大学《十三经》分词标注语料中节选的八篇《仪礼》文本,各篇语料规模分布如表 1所示。如此选择是出于这样的考虑: 所选语料在内容方面尽量存在相关性,这样有利于找到更多的匹配模式。例如,《士昏礼》和《聘礼》都是关于婚嫁的,《士丧礼》和《既夕礼》是关于丧葬的,《乡射礼》和《大射》都是关于射箭的。语料中所有句子经过“逗号”切分后得小句数为8 251。
为了获得效果最好的α参数值,我们让α依次取从1到100的整数,并分别计算各自Cost值,如图6所示。
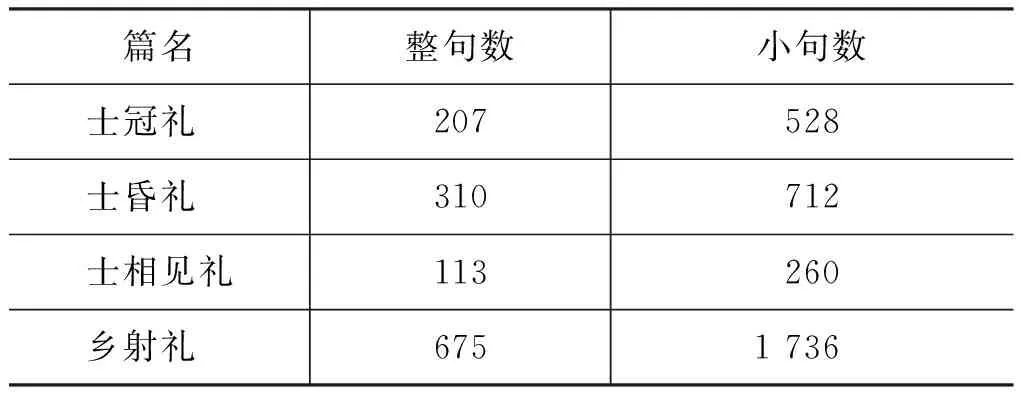
表1 语料规模分布(实验一)
续表
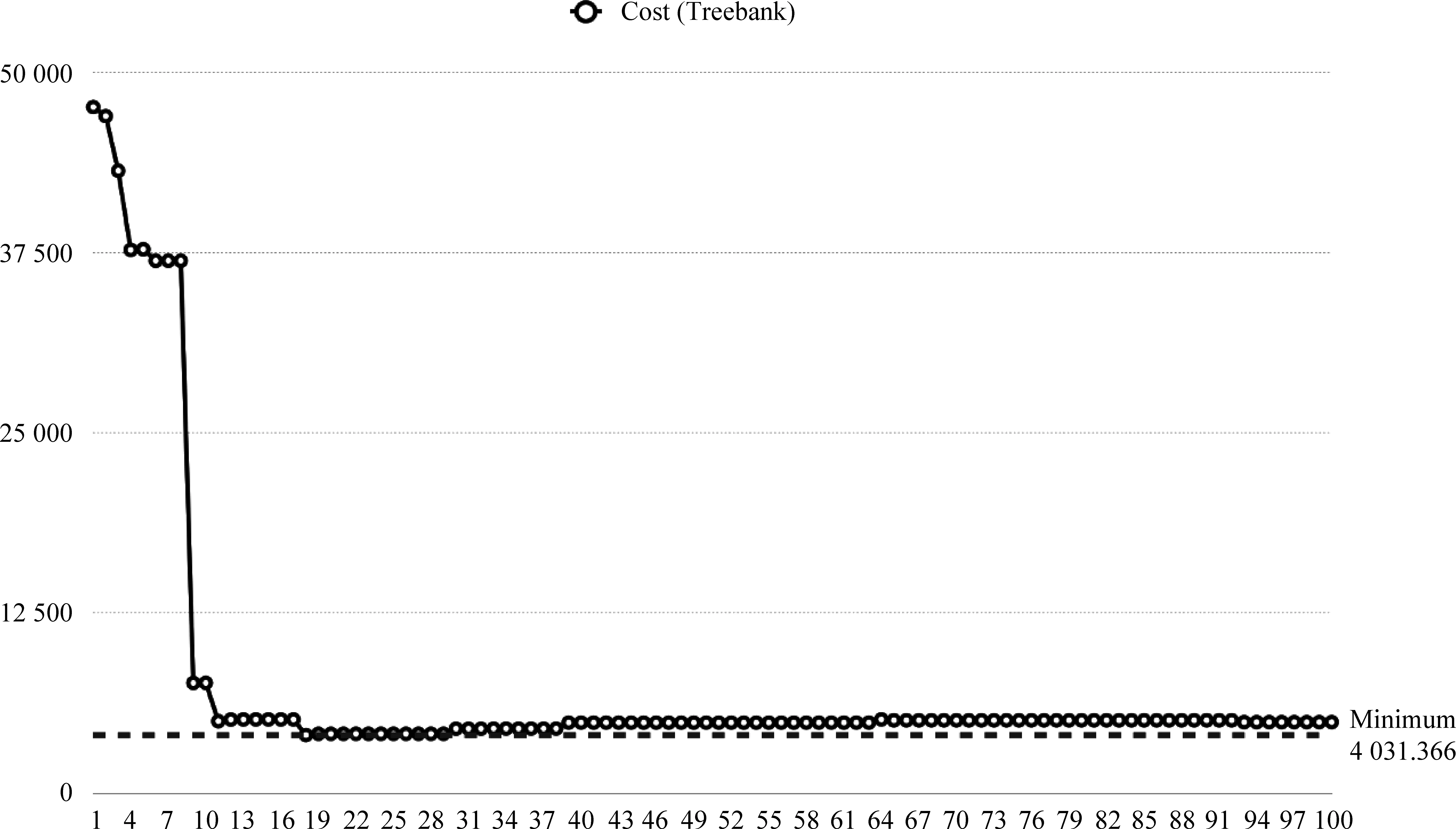
图6 α参数与Cost变化图(实验一)
最好的α参数值为18,此时Cost(Treebank)=4039.43。此时,与Treebank-Gold比较可知Treebank-α18构建过程中的如下参数:
• 所有CMP数: 3 081,共覆盖8 198条CS。如果用所有CMP来分析句子,意味着需要手工编制3 081条SS,所得句法分析结果为: 准确率96.89%,覆盖率99.36%;
• 覆盖CS数大于1的CMP数: 780,共覆盖5 898条CS。如果用覆盖CS大于1的CMP来分析句子,意味着需要手工编制780条SS,所得句法分析结果为: 准确率95.68%,覆盖率71.48%;
• 有效MP(CMP无结构歧义且覆盖CS数大于1)数: 734,共覆盖CS数为2 985。
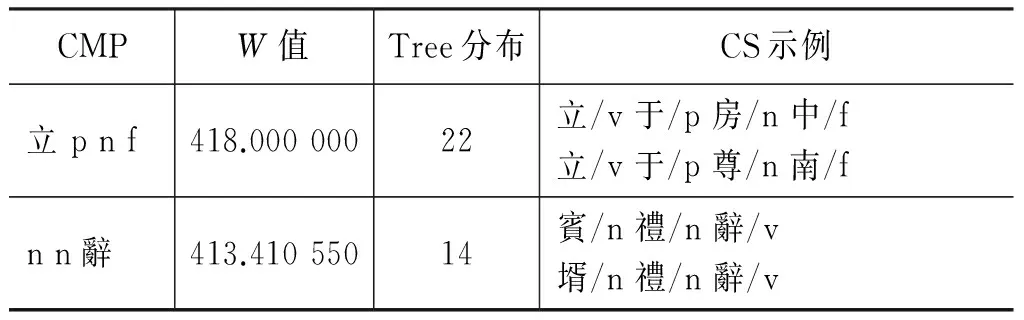
前十条CMP及其Tree(CS_Set)的分布如表 2所示。
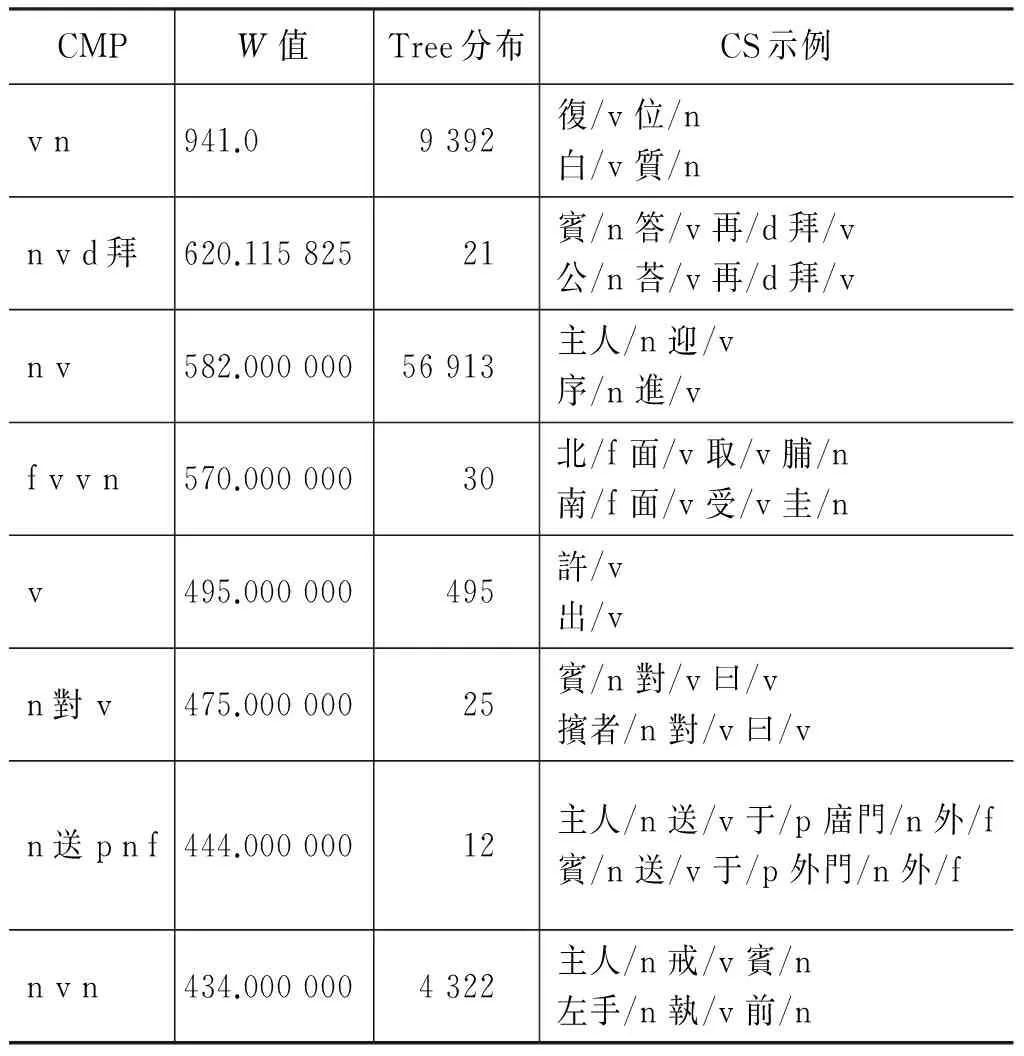
表2 α=18时前十CMP示例(实验一)
续表
第一条CMP中,939句的SS为主谓结构,仅有两句“白/v 質/n”、“赤/v 質/n”与其他句子的SS是不一样的,这是因为“白”、“赤”词性标注有误,应该标为形容词,因此,若词性标注正确,这一条CMP对应的CS的SS都是一致的。
第三条CMP中,569句的SS均为动宾结构,仅有13句为状中结构(古汉语中的名作状现象)。第8条CMP中,432句的SS均为主谓宾结构,仅两句“左手/n 執/v 前/n”、“右手/n 執/v 項/n”为状谓宾结构。这两个CMP对应的SS虽然不是唯一,但是也相对收敛。该方法基本上可以保证大部分句子被分析正确,且是高效的。
由图6可知,当α∈[18, 29]时,Cost在最小值附近小幅波动。为了验证α的上述范围在更多语料中的适应性,我们在《左传》部分语料上进行了重复实验。
6.2 实验二: 《左传》
实验二采用从北师大《十三经》分词标注语料中节选的两篇《左传》文本,语料规模分布如表3所示。语料中所有句子经过“逗号”切分后得小句数为6 791。
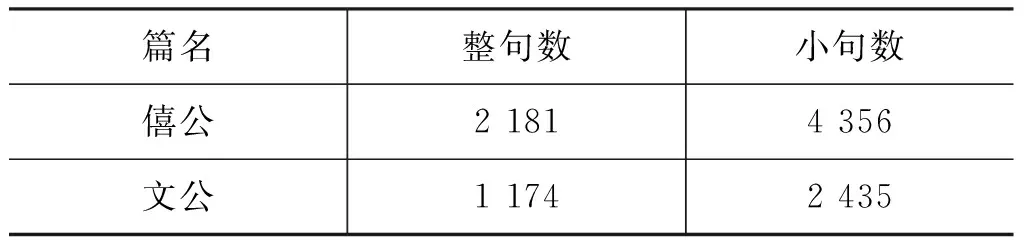
表3 语料规模分布(实验二)
同上,让α依次取从1到100的整数,并分别计算各自Cost值,结果如图7所示。
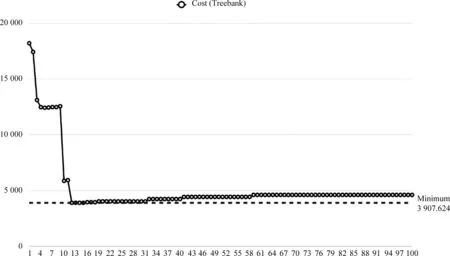
图7 α参数与Cost变化图(实验二)
图7中,当α∈[12, 31]时,Cost在最小值附近小幅波动。这个范围与实验一基本吻合,说明了α∈[18, 29]在不同语料上具有一定的适应性。
7 结语
本文提出的匹配模式获取方法在古汉语信息处理中具有较强的针对性和实用价值。在古汉语树库构建的原始积累阶段,可以大大缩减人工标注工作量,节省工程成本。构建过程中所得的大量MP可为古汉语句式教学和研究提供数据支持。小句简短、模式性强是本方法可适用语料的特征条件,而这正是古汉语文本的典型特征。
限于词法语料库的获取权限,本文仅以北师大语料《仪礼》《左传》部分语篇为例进行实验。若词性标注粒度细化至如Sinica语料库,则匹配模式获取效果将更值得期待,这也是本文进一步工作的规划。
[1] 魏培泉, 谭朴森, 刘承慧,等. 建构一个以共时与历时语言研究为导向的历史语料库[J]. 中文计算语言学期刊, 1997, 2(1): 131-145.
[2] Hu X, Williamson N, Mclaughlin J. Sheffield corpus of Chinese for diachronic linguistic study[J]. Literary and Linguistic Computing, 2005, 20(3): 281-293.
[3] 石民, 李斌, 陈小荷. 基于 CRF 的先秦汉语分词标注一体化研究[J]. 中文信息学报, 2010, 24(2): 39-45.
[4] 宋继华, 胡佳佳, 孟蓬生,等. 古今汉语平行语料库的语料构建[J]. 现代教育技术, 2008, 18(1): 92-99.
[5] 陈凤仪, 蔡碧芳, 陈克健,等. 中文句结构树资料库(Sinica Treebank)的构建[J]. Computational Linguistics and Chinese Language Processing, 1999, 4(2): 87-104.
[6] 周强. 汉语句法树库标注体系[J]. 中文信息学报, 2004, 18(4): 2-9.
[7] Xue N, Xia F, Chiou F-D, et al. The penn Chinese treebank: phrase structure annotation of a large corpus[J]. Natural language engineering, 2005, 11(02): 207-238.
[8] 李正华, 车万翔, 刘挺. 短语结构树库向依存结构树库转化研究[J]. 中文信息学报, 2008, 22(6): 14-19.
[9] 邱立坤, 金澎, 王厚峰. 基于依存语法构建多视图汉语树库[J]. 中文信息学报, 2015, 29(3): 9-15.
[10] Levy R, Manning C. Is it harder to parse Chinese, or the Chinese treebank?[C]//Proceedings of the 41st Annual Meeting on Association for Computational Linguistics-Volume 1, 2003: 439-446.
[11] 曹海龙. 基于词汇化统计模型的汉语句法分析研究[D].哈尔滨工业大学博士学位论文, 2006.
[12] 马金山. 基于统计方法的汉语依存句法分析研究[D]. 哈尔滨工业大学博士学位论文, 2007.
[13] Zhang Y, Clark S. Transition-based parsing of the Chinese treebank using a global discriminative model[C]//Proceedings of the 11th International Conference on Parsing Technologies, 2009: 162-171.
[14] Che W, Spitkovsky V I, Liu T. A comparison of Chinese parsers for Stanford dependencies[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2, 2012: 11-16.
[15] Lee J, Kong Y H. A dependency treebank of classical Chinese poems[C]//Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2012: 191-199.
[16] 彭炜明, 何静, 宋继华. 句本位语法图解析句系统的设计与实现[C].第四届数字典藏与数字人文国际研讨会, 2012.

何静(1986—),博士研究生,主要研究领域为自然语言处理。
Email: hejing8@mail.bnu.edu.cn

宋天宝(1988—),博士研究生,主要研究领域为自然语言处理。
Email: songtianbao@mail.bnu.edu.cn

宋继华(1963—),通信作者,博士,教授,博士生导师,主要研究领域为语言信息处理、计算机教育应用。
Email: songjh@bnu.edu.cn
An Efficient Approach to Ancient Chinese Treebank Construction Based on “Word or POS” Match
HE Jing1, SONG Tianbao1, PENG Weiming1, ZHU Shuqin1,2, SONG Jihua1
(1. College of Information Science and Technology, Beijing Normal University, Beijing 100875,China; 2. Teacher’s College, Beijing Union University, Beijing 100101,China)
1003-0077(2017)04-0114-08
TP391
A
