基于语义串抽取及主题相似度度量的维吾尔文文本分类
2017-10-11吐尔地托合提维尼拉木沙江艾斯卡尔艾木都拉
吐尔地·托合提,维尼拉·木沙江,艾斯卡尔·艾木都拉
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
基于语义串抽取及主题相似度度量的维吾尔文文本分类
吐尔地·托合提,维尼拉·木沙江,艾斯卡尔·艾木都拉
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
该文研究一种改进的n元递增算法来抽取维吾尔文本中表达关键信息的语义串,并用带权语义串集来刻画文本主题,提出了一种类似于Jaccard相似度的文本和类主题相似度度量方法,并实现了相应的维吾尔文分类算法。实验结果表明,该文提出的文本模型简单有效,分类算法计算量不高,而且还能达到或超过经典分类器的分类综合性能。
维吾尔文;n元递增算法;语义串抽取;主题相似度;文本分类
Abstract: This paper proposes an improved frequent pattern-growth approach to discover and extract the semantic strings which express key information in Uyghur texts. Then the topics are described by these weighted semantic strings. Based on these features, the Uyghur text classification is conducted by a new-designed Jaccard-like similarity measure. Experimental results show that the proposed method achieves comparable performance with a reasonable computation cost with regard to two traditional classifiers.
Key words: Uyghur language; frequent pattern-growth algorithm; semantic string extraction; topic similarity; text classification
1 引言
提取什么样的特征,如何评价和选取最佳特征子集,从而很好地训练分类器,是文本分类中的一个重要研究课题[1]。关于特征提取,常用的方法是对文本进行分词,并以词为特征表示文本。但是,词的语义表达能力有限,而且还有多义、歧义等现象的存在,用词特征往往不能很好地表征文本[2-3]。除此之外,用词特征表示文本时的特征空间的高维性和类间交叉特征的出现,是制约学习算法性能的主要因素[4]。因此,越来越多的研究者在探索从文本抽取表达信息比单词更具体而完整的语言单元作为文本特征的方法[5-7]。
维吾尔文属于阿尔泰语系突厥语族,是一种拼音文字。从文字表面上看,维吾尔文是以空格隔开的词序列,在这一特点上与英文类似。因此,常以空格作为自然分隔符简单获取文本中的词。由于这种简单分词方法的局限性和不足,以词特征表示文本时的维吾尔文分类结果总是不能被接受[8]。其实,维吾尔文中能表达一个完整语义的最小语言单元常常不是一个单词,而是突破词语概念界限的语义串[9],其特点是: 文本中上下文任意多个连续字符(字或词)的稳定组合,其结构稳定不可分割,是语义完整的语言单元,如固定搭配、习语、对偶词等具有词汇意义和语法意义的模式串[10],词组或短语[11],复合词或领域术语[12],还有命名实体等。
在文本中,句子可以表达一个完整、连贯、易于理解的语义,而语义串能蕴含句子中的关键信息。因此,以语义串作为特征表示文本,就可以有效地刻画文本主题,这就有利于文本相似性的正确判断[13]。因此,我们研究一种改进的n元递增算法和语言规则结合的方法,抽取文本集中表达关键信息的语义串集,并从结构完整性和所蕴含的信息量等方面评价语义串,然后用带权语义串集来表示文本主题和类主题。相似度度量和分类准则方面,我们提出了一种类似于Jaccard相似度的文本主题和类主题相似度度量方法,并实现了相应的基于主题相似度的分类算法。最终,我们将本文分类算法与NB和KNN的分类性能进行对比,实验结果表明,本文算法分类准确率非常接近KNN,但超过NB,时间效率优于KNN。
2 语义串抽取
本文提出的语义串抽取方法是在单词(词干)的基础上,按文本书写方向进行向下扩展,从而识别文本中的语义串。这就需要每一个单词或词串的频次、长度、文本中出现的位置、词性、上下文等统计信息。因此,我们设计一种多层动态索引结构来存储以上信息[14],并在此基础上发现文本中的频繁模式,最终对于频繁模式进行完整性评价,从而获取语义及结构完整的语义串。频繁模式的发现是对n元递增算法做了改进[15],语义串的抽取主要分为以下几个步骤。
2.1 建索引
对于经过预处理的文本集,首先按单词在文本中出现的顺序建立词典,然后对于生成的单词ID序列建词索引。例如,对于只有六个单词的文本“ABCF#EFCEABCFD#EFCADFECDABCFACD#”(#是标点符号),建词索引示例如图1所示。
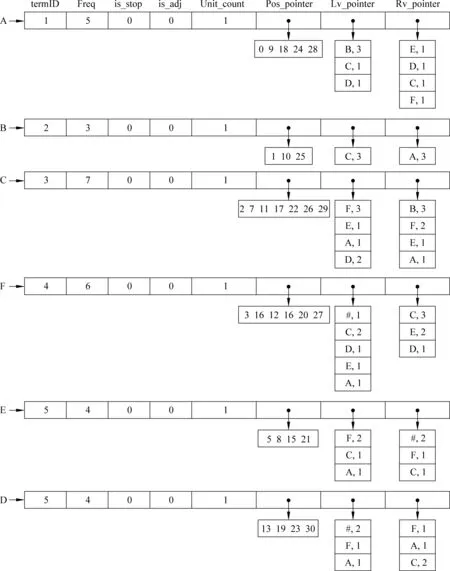
图1 索引示例
一级索引中,termID是一个单词或串在索引空间唯一的ID,Freq是该索引项在语料中的频次;is_stop是停用词标志;is_adj是形容词标志;Unit_count是该索引项的单词长度(串中包含的单词个数); Pos_pointer,Lv_pointer和Rv_pointer分别是对应二级索引入口的地址偏移量。二级索引也是一个索引项列表,其入口由一级索引获取。二级索引表中的每一项是该索引项在文本集中的概要描述。其中,第一个索引表是Position,是该索引项的位置倒排;第二个是左邻接列表,是该索引项所有的左邻接及其频次;第三个是右邻接列表,是该索引项所有的右邻接及其频次。
通过这种索引结构,可以描述每一个单词或串尽可能多的属性,其动态性、效率和扩展性等也符合海量文本处理需求。
2.2 串扩展及频繁模式发现
开始时,让所有单词(ID)进入一个队列中,然后根据每个单词的索引信息从每个单词扩展得到其二词串或三词串,让该单词出队并将新产生的扩展串入队,继续从n词串扩展到n+1词串或n+2词串,反复迭代,直到队列为空。串扩展候选单词索引及队列初始状态如图2所示。
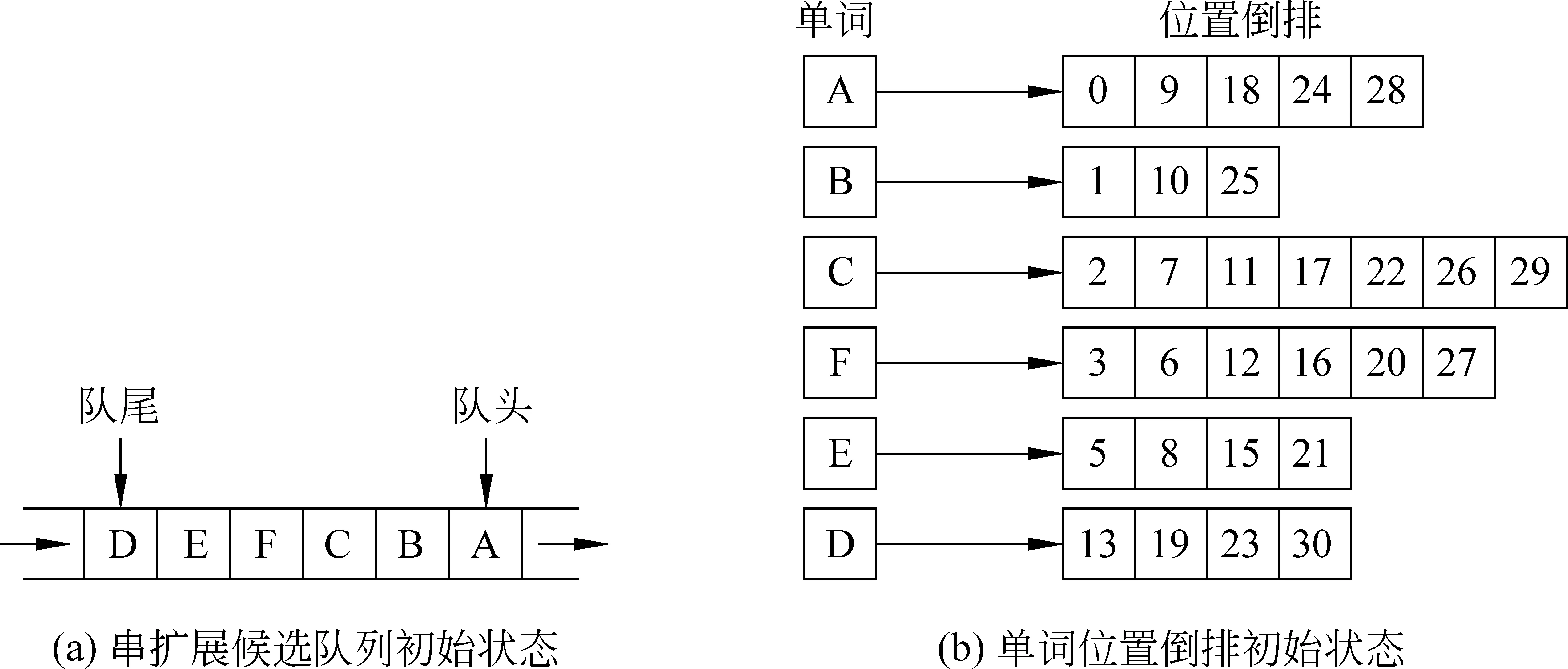
图2 串扩展初始状态示例
判断一个单词或串能否与其下文单词或串结合成为一个关联模式,我们用语言规则、置信度和逆置信度等评价指标[16]。置信度(Confidence)是指单词关联wi-1→wi的上文(前件)wi-1出现的情况下,其下文是wi的条件概率。而逆置信度(R-Confidence)是指单词关联wi-1→wi的下文(后件)wi出现的情况下,其上文是wi-1的条件概率,计算公式如下:
可见,置信度评价的是单词关联的上文在此关联中的比重,而逆置信度用来衡量单词关联的下文对此关联强度的贡献。因此,当Confidence(wi-1,wi)>minconf或R-Confidence(wi-1,wi)>minconf时,则可确定词串wi-1wi为可信频繁模式(trusted frequent pattern,TFP)。
本文研究中,我们还发现以下语言特性对于文本中关联模式的识别非常有用。
特性1 维吾尔文助词、连词、副词、量词、代词以及感叹词等功能词,在文本中始终不跟其他单词结合成语义串。本文将这些词称为“独立词”(independent word, IW)。
特性2 维吾尔文单词间的结合主要是在名词(N),形容词(ADJ)和动词(V)之间发生。其中,当形容词与名词或与动词结合时,形容词总是作为前驱,而不会出现在后继位置。因此,N+ADJ或V+ADJ关系的相邻单词绝不可能结合构成一个语义串。
根据以上语言特性1和特性2,归纳出用于词间关联识别的单词结合规则(word association rule, WAR)并定义如下。
定义1(单词结合规则WAR) 对于文本中的相邻词对“X Y”,如成立条件: X{IW} or Y {IW} or Y {ADJ} ,则判断X与Y不能结合成为关联模式。
有了以上规则和评价指标,假定X、Y是文本中相邻的两个单词(或串),X是Y的右邻接词(上文),Y是X的左邻接词(下文),要进行X→X Y的扩展,则要满足以下条件 :
① X不是停用词,即is_stop(X)=0;
② X是频繁模式,即Freq(X)≥2;
③ Y不是停用词或形容词,即is_adj(Y)=0且is_stop (Y) =0;
④ Y是频繁模式,即Freq(Y)≥2;
⑤ XY是可信频繁模式,即Confidence(X→Y)>minconf且R-Confidence(X→Y) >minconf。
以上例子中,当队头单词A出队后,因为A具备条件①和②,因此从二级索引中读取A的左邻接列表,然后根据条件③、④、⑤依次判断A与其每一个左邻接(下文)词构成新串的可能性。本例中,A的第一个左邻接B具备条件③和④,同时A与B构成的扩展串AB也具备条件⑤,因此将新产生的串AB入队,同时将该信息追加到索引中,然后判断A与其下一个左邻接词C的关联强度,依次判断并进行从单词到二词串扩展,直到A的所有左邻接词都被访问完为止。此时,扩展候选队列及索引变化情况如图3所示。
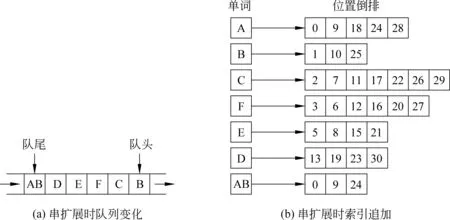
图3 串扩展(示例1)
之后,让当前队头单词B出队,因为B已跟A结合,就不再进行扩展,然后是C出队。就这样,依次对每一个单词进行二词串或三词串扩展,同时将新产生的二词串或三词串作为可信频繁模式入队,等待继续被扩展。所有单词都被访问完之后,队列及索引变化情况如图4所示。

图4 串扩展(示例2)
等所有单词的二词串或三词串扩展进行完毕,就接着进入从候选串扩展成更长串的过程,直到串扩展候选队列为空,此时,频繁模式发现过程就结束。
2.3 模式串完整性评价及语义串抽取
如果一个串能成为语义串,那么它在结构、语用、语义及统计上应该满足一定的特点。一般情况下,通过频繁模式发现得到的结果只能满足可统计性要求,称为语义串候选,还需要采用上下文邻接分析或语言模型分析等方法进行进一步甄别和过滤[17]。本文研究中,甄别和过滤维吾尔文语义串候选,我们用的方法与中文有所不同。主要原因如下:
(1) 中文常用功能字会跟其他汉字构成实词,如“的士”等。因此,对于串首(串尾)出现功能字的情况,就需要判断串首(串尾)字对双字耦合度和首字词首(词尾)成词概率。另外,不是所有的汉字都能作为词首或词尾,因此可以根据单字位置成词概率来判断串首和串尾,这种方法可以有效过滤垃圾串。但维吾尔文与中文不同,首先维吾尔文功能词不会跟其他词结合构成新词。另外,维吾尔文中的词本来就是一个独立运用的语言单位,词在串首、串尾位置的用法没有特定规律(形容词除外)。
(2) 维吾尔文语义串抽取中,我们也可以用与中文类似的方法去判断串首和串尾“双词”耦合度,这对于垃圾串的过滤肯定会有一定的帮助。但是,这就需要大量学习语料、人工标注并构建双词耦合度词典,而本文研究目的是无监督学习的语义串抽取方法。
(3) 关于语言模型的分析方法,本算法引入单词结合规则,并将它嵌入频繁模式发现过程中,因而有效避免串尾出现形容词的垃圾串产生的情况,减轻了垃圾串过滤任务。
因此,本文主要是根据上下文邻接特征来判断每一个语义串候选的结构完整性。中文相关研究结果表明,采用邻接熵的结果比其他三种邻接特征量(邻接种类,邻接对种类,邻接对熵)的结果好[18]。因此,我们用式(3)为每一个候选语义串赋权重。
AEweight(S)=min(LAE(S),RAE(S))
(3)
其中,AEweight(S)是串S的邻接熵(adjacency entropy: AE)权重,LAE(S)是串S的左邻接熵,RAE(S)是其右邻接熵。左(右)邻接熵计算公式为式(4)。
(4)
其中,m是串S的左邻接种类数,ni是串S的第i个左邻接的频次,所有左邻接频次总和为N,计算邻接特征量所需要的全部信息在它们被发现时就已记录好并存入索引中。最后,依次输出邻接特征量达到阈值的频繁模式,那就是最终要得到的语义串。语义串抽取流程如图5所示。
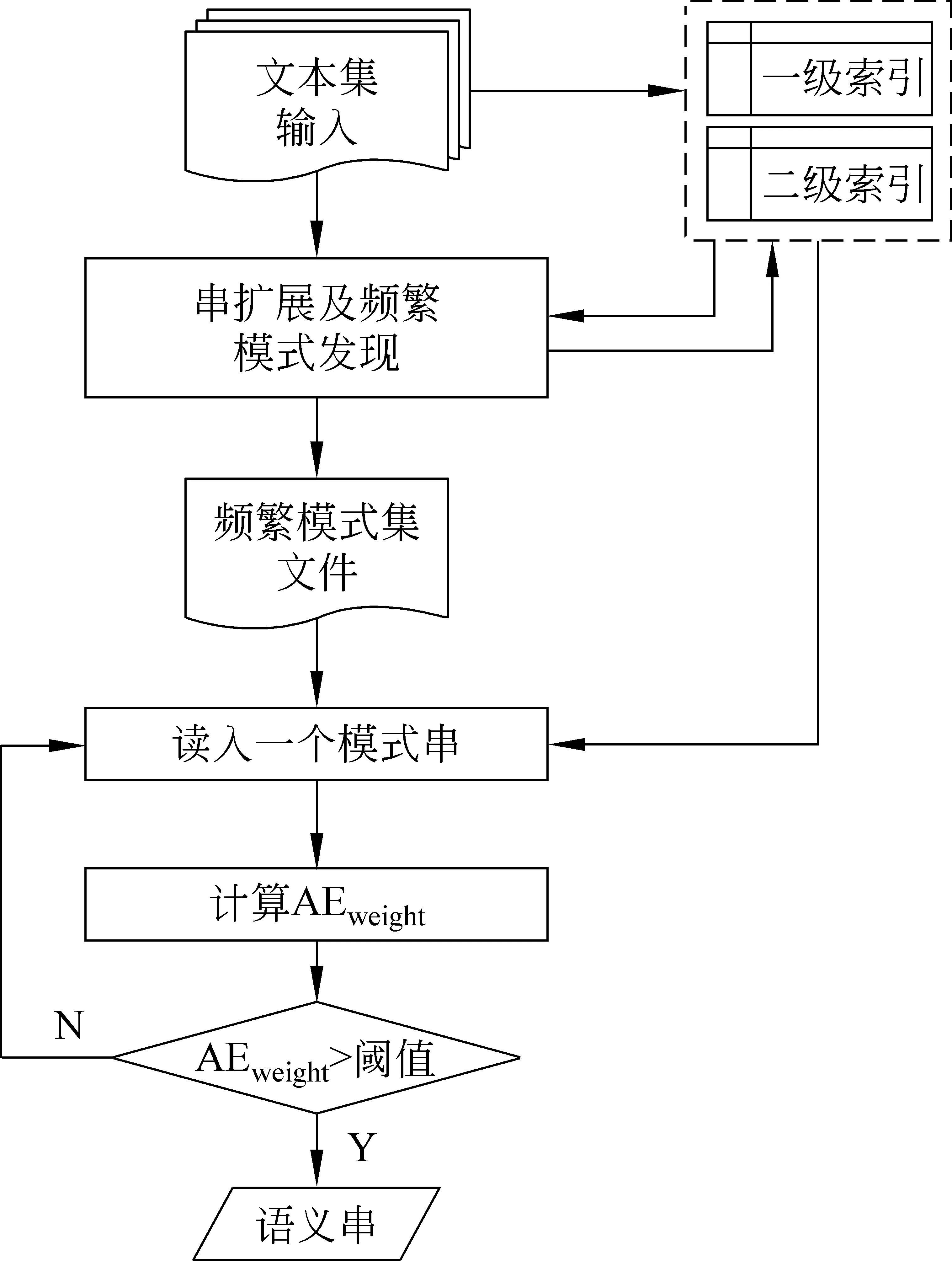
图5 语义串抽取流程
3 文本表示
一个文档就是一个长字符串,而将一个文档表示成主题项集合的最有效的方法是构建文档中表示关键信息的短字符串集合。如果文档采用这样的集合表示,那么有相同的句子甚至短语的文档之间将会拥有很多公共的集合元素,即使两篇文档中的句子顺序不相同也是如此。这种文本表示方法简单,特别是在大语料库中寻找相似的文档时可以取得较好的效果[19]。因此,我们通过图5的处理流程抽取每一个训练文本和测试文本中的语义串,然后用语义串集表示每一个文档。
假设,文档di的主题项集合中有n个语义串{S1,S2,...,Sj,...,Sn-1,Sn},若用Wj来表示语义串Sj的权重,则我们可以用一个二元组(Sj,Wj)来表示一个主题项,那么文本di就可以表示成n个带权主题项的集合,即{(S1,W1),(S2,W2),…,(Sj,Wj)…,(Sn-1,Wn-1),(Sn,Wn)}。
计算语义串(主题项)权重时,我们主要考虑语义串对于表示文本主题的贡献度。首先,邻接特征量表示语义串在语用环境中的结构完整性,而结构完整的词串总是能表达与文本主题相关的关键信息。除此之外,语义串的长度与其表达的信息量呈正比的关系。因此,长度越长,语义串表达的信息量也越大,其语义更具体且完整。例如,语义串“高速公路收费系统”的信息量比“高速”,“高速公路”和“高速公路收费”都大,这样的语义串能更大程度地表示文本主题。因此,给出了如下权重计算公式,即
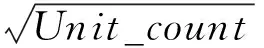
(5)
其中,Wj是文档di中语义串Sj的权重,AEweight是其邻接熵(用式(3)计算得到),Unit_count是其长度(单词个数)。
最终,根据以上定义和计算公式,分别构建文档主题项集合和类主题项集合。对于测试文本,一个文档是一个集合,要构建n个文档主题项集合(n为测试文档个数),而对于训练文本,要构建m个类主题项集合(m为从训练文本集获取的类别个数)。
4 相似度度量和分类规则
根据本文提出的文本表示方法,我们采取了一种类似于Jaccard相似度的文档与类主题相似度度量方法[20]。相关术语定义如下:
(1)Dtrain={Dc1,Dc2,...,Dci,...,Dcm}:Dtrain为训练文档集,Dci是Dtrain中第i个类文档集。
(2)Dtest={di}:Dtest为测试文档集,di是Dtest中第i个文档。
(3) 文档主题项集Tdi: 是Dtest中文档di的带权语义串集合。
(4) 类主题项集TCi: 是第i个类Ci的带权语义串集合,由从Dci中不重复的选入语义串构建而成。
(5) 文档(类)权重: 是文档主题项集Tdi(类主题项集合TCi)中全部n个语义串权重之和,如式(6)所示。

(6)
(6) 相交项集Tdi∩TCi: 是Tdi和TCi公共的那些语义串集。
(7) 相交权重Weight(Tdi∩TCi): 是相交项集全部语义串权重之和。
文档与类间的相似度是由文档主题项集Tdi和类主题项集TCi的共性来体现,更确切地说,文档与类间的相似度可以通过它们相交特征集对于文档主题或类主题的贡献度来衡量。因此,对于文档主题项集Tdi和类主题项集TCi,根据以下情况可以判断它们之间的相似程度。
(1) 如相交项集Tdi∩TCi=Φ,则表明文档di和类Ci在主题上没有共性,相似度为零。
(2) 如相交项集Tdi∩TCi≠Φ,则表明它们在主题上有相似性,然后用式(7)计算它们之间的相似程度。
Sim(Tdi,TCi)=
(7)
计算公式说明,如果文档与类在主题上存在共性,那么它们之间将会拥有若干个对于它们主题贡献较大的公共集合元素。也就是说,Weight(Tdi∩TCi)越大,文档di和类Ci的相似程度也越大。
我们提出的方法和Jaccard相似度都是基于集合的相似度度量方法,但二者有所不同。对于集合Tdi和TCi,Jaccard相似度为|Tdi∩TCi|/|Tdi∪TCi|,也就是集合Tdi和TCi的交集和集合并集大小之间的比率。可以看出,Jaccard相似度只看两个集合公共元素个数,而不考虑公共元素对于集合的重要度,但本文提出的方法主要考虑的不是数量,而是质量。
根据以上文本表示和相似度度量方法,本文分类方法就按照式(7)计算文档与给定主题类别之间的相似度,并根据相似度大小把文档归类到与它最相似的那个类中。语义串抽取及分类流程如图6所示。
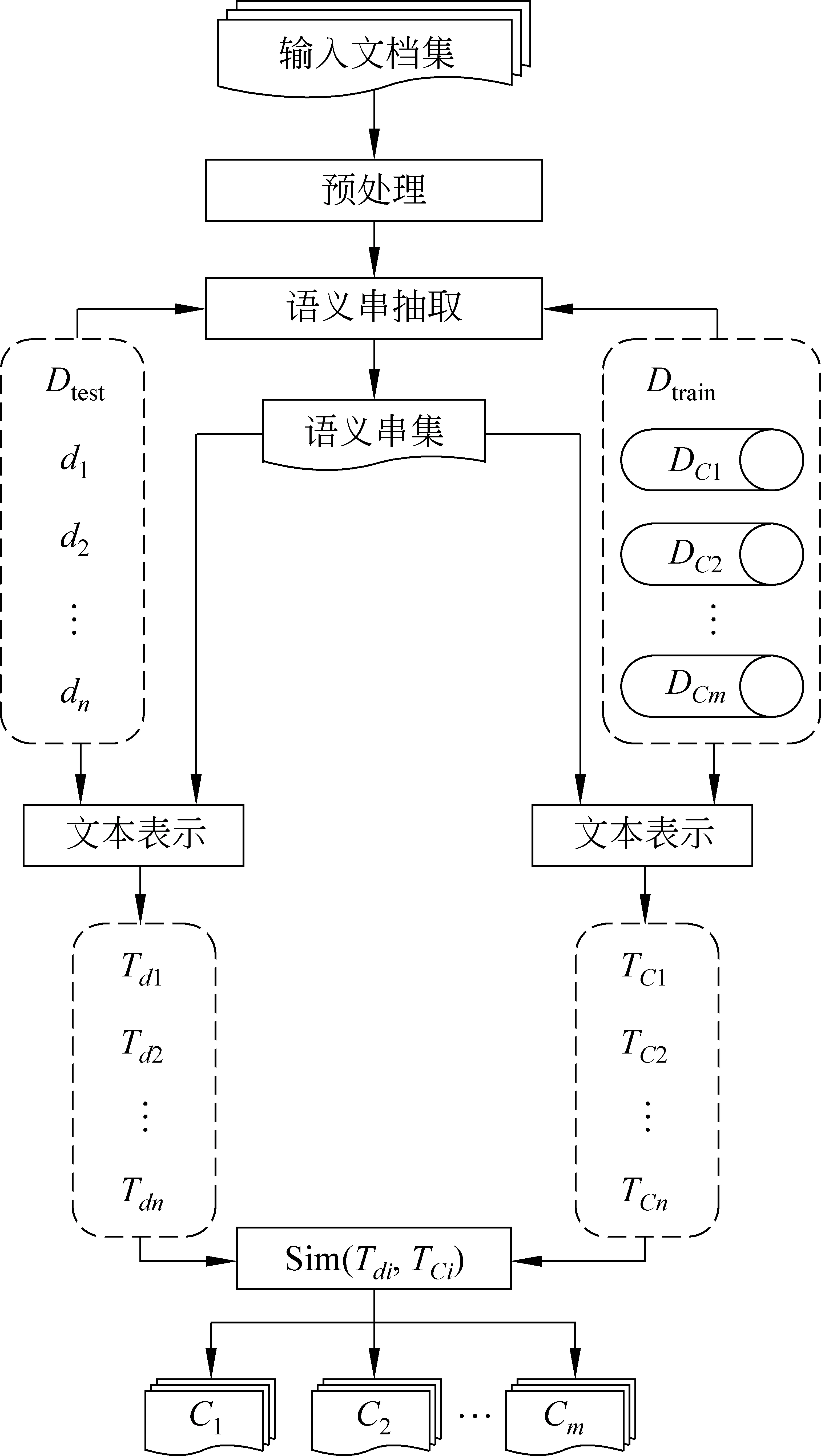
图6 语义串抽取及分类流程
5 实验与分析
5.1 数据集 本文用新疆大学智能信息处理重点实验室提供的维吾尔文分类文本集进行分类实验和分析,共含六类(01健康,02交通,03教育,04经济,05体育,06宗教)1 800篇文本(每类300篇)。
5.2 实验方案和评价指标
为了验证本文提出的方法的有效性,我们设计了两个实验。
实验1 用传统方法对文本集进行分词,以词为特征构建文本VSM,选用特征选择方法为CHI,分别进行NB和KNN分类,观察分类效果。
实验2 用本文提出的方法抽取语义串,并用语义串作为主题项表示文本,然后用本文提出的主题相似度度量方法进行分类,与实验1对比分类效果。
本实验仍然用准确率(precision)、召回率(recall)和F-measure等常用指标来评价分类效果,同时我们还对比本文分类方法与NB和KNN的时间性能。
5.3 分类实验
为了验证本文提出的文本模型和分类方法的有效性,我们在实验数据集上分别进行NB和KNN分类,并与本文分类效果进行对比。实验方案和语料划分如表1所示。

表1 实验方案和语料划分
在评价分类效果时,我们将五次5-fold交叉验证运行结果的分类评价指标平均值作为最终的分类效果。经过实验确定KNN的K值为11,三种分类模型分类效果和时间效率对比如图7和图8所示。
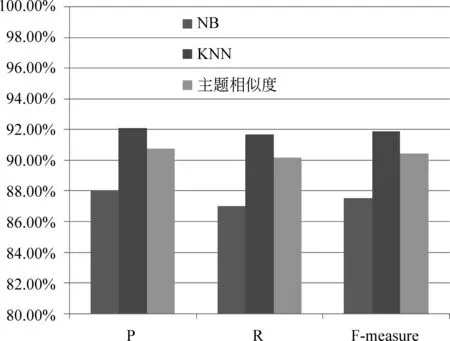
图7 三种分类模型分类效果对比
从图7展示的三种分类结果评价指标对比中可以看出,本文分类方法各个指标非常接近KNN分类效果,但比NB的分类效果好得多。然后从图8给出的三种分类时间效率对比中可以看出,本文分类方法时间性能优于KNN。因此,从分类效果和时间效率综合评价来看,本文提出的分类方法是有效的。
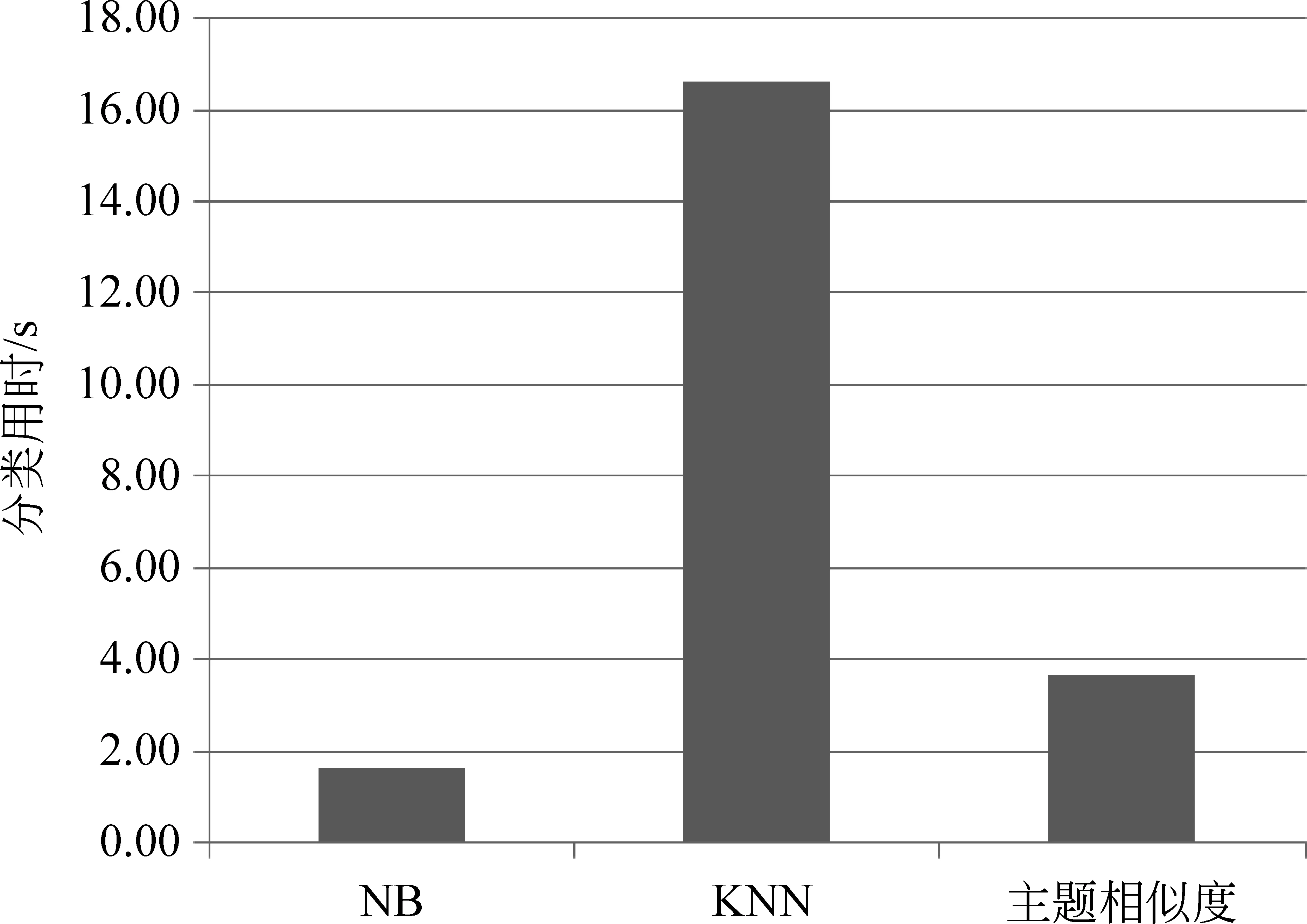
图8 三种分类模型时间效率对比
6 结语
大数据时代的到来,对文本挖掘的任务及相关技术提出了更高的要求,特别是海量文本的快速积累及实时变化,要求文本挖掘算法也具有极高的时间效率及实时处理能力。因此,如何简化学习策略及学习过程,从而提高算法实时处理能力,已成为大数据文本挖掘中的一个重要研究课题。从另一方面讲,大数据文本更突出的统计特性使各类基于统计的文本挖掘算法取得了更好的效果。
因此,本文结合统计和语言性的方法抽取文本集中的语义串,然后用这些带权语义串构建文档和类主题项集,在此基础上进行主题相似度度量和文本分类。因为,本文用表达信息比单词更具体、更完整的语言单元来刻画文本主题,采取较简单的文本模型和分类模型,因此在分类和时间效率方面得到了相对于经典分类模型更好的综合性能。
[1] 苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,17(9): 1848-1859.
[2] C Niu, W Li, R K Srihari, et al. Word independent context pair classification model for word sense disambiguation [C]//Proceedings of the Ninth Conference on Computational Natural Language Learning,2005: 33-39.
[3] Y Liu, P Scheuermann, X Li, et al. Using WordNet to disambiguate word senses for text classification[J]. Lecture Notes in Computer Science, 2007: 781-789.
[4] 徐燕,李锦涛,王斌,等.基于区分类别能力的高性能特征选择方法[J].软件学报,2008,19(1): 82-89.
[5] W Zhang,T Yoshida,X J Tang. Text classification using multi-word features[C]//Proceedings the 12 th IEEE International Conference on Systems, Man and Cybernetics, 2007: 3519-3524.
[6] F Figueiredo,L Rocha,T Couto,et al. Word co-occurrence features for text classification[J]. Information Systems,2011,36(5): 843-858.
[7] D Sreya, M M Narasimha. Using discriminative phrases for text categorization [C]//Proceedings of the 20th International Conference on Neural Information Processing, 2013: 273-280.
[8] 阿力木江·艾沙,吐尔根·依布拉音,艾山·吾买尔, 等.基于机器学习的维吾尔文文本分类研究[J].计算机工程与应用, 2012, 48(5): 110-112.
[9] Turdi Tohti, Winira Musajan, Askar Hamdulla.Unsupervised learning and linguistic rule based algorithm for Uyghur word Segmentation [J]. Journal of Multimedia, 2014, 9(5): 627-634.
[10] M Candito,M Constant. Strategies for contiguous multiword expression analysis and dependency parsing[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, ACL 2014-Proceedings of the Conference,2014: 743-753.
[11] Rais N H, Abdullah M T, Kadir R A. Multiword phrases indexing for malay-english cross-language information retrieval [J]. Information Technology Journal, 2011,10(8): 1554-1562.
[12] Murata Masaki, U Masao. Compound word segmentation using dictionary definitions- extracting and examining of word constituent information [J]. ICIC Express Letters, Part B: Applications, 2012, 3(3): 667-672.
[13] A E Eldesoky, M Saleh, N A Sakr. Novel similarity measure for document clustering based on topic phrases [C]//Proceedings of the 2009 International Conference on Networking and Media Convergence, 2009: 92-96.
[14] Y Ma, L Wang. Dynamic indexing for large-scale collections [J]. Journal of Beijing Normal University(Natural Science),2009,45(2): 134-137.
[15] R Uday Kiran,P Krishna Reddy. An improved frequent pattern-growth approach to discover rare association rules[C]//Proceedings of the 1st International Conference on Knowledge Discovery and Information Retrieval,2009: 43-52.
[16] J K Jain, N Tiwari M Ramaiya. Mining positive and negative association rules from frequent and infrequent pattern using improved genetic algorithm[C]//Proceedings of the 5th International Conference on Computational Intelligence and Communication Networks, 2013: 516-521.
[17] A Tiwari,R K Gupta, D P Agrawal. A survey on frequent pattern mining: current status and challenging issues [J]. Information Technology Journal, 2010, 9(7): 1278-1293.
[18] 张华平,高凯 ,黄河燕,等.大数据搜索与挖掘[M].北京: 科学出版社,2014.
[19] R Anand,U D Jeffrey,互联网大规模数据挖掘与分布式处理[M].王斌,译.北京: 人民邮电出版社,2012.
[20] J Q Ji, J M Li, S C Yan, et al. Min-max hash for jaccard similarity[C]//Proceedings of the IEEE 13th International Conference on Data Mining, 2013: 301-309.

吐尔地·托合提(1975—),通信作者,副教授,博士,硕士生导师,主要研究领域为自然语言处理及文本挖掘。
E-mail: turdy@xju.edu.cn

维尼拉·木沙江(1960—),教授,硕士生导师,主要研究领域为自然语言处理及信息检索。
E-mail: winira@xju.edu.cn

艾斯卡尔·艾木都拉(1972—),教授,博士,博士生导师,主要研究领域为智能信息处理。
E-mail: askar@xju.edu.cn
Semantic String-Based Topic Similarity Measuring Approach for Uyghur Text Classification
Turdi Tohti, Winira Musajan, Askar Hamdulla
(School of Information Science and Engineering, Xinjiang University, Urumqi, Xinjing 830046, China)
1003-0077(2017)04-0100-08
TP391
A
2015-10-23 定稿日期: 2016-02-05
国家自然科学基金(61562083,61262062,61262063);新疆维吾尔自治区高校科研计划重点项目(XJEDU2012I11)
