融合用户观点的社会影响力分析
2017-10-11魏晶晶廖祥文林柏钢陈国龙
陈 畅,魏晶晶,廖祥文,林柏钢,陈国龙
(福州大学 数学与计算机科学学院,福建 福州 350116)
融合用户观点的社会影响力分析
陈 畅,魏晶晶,廖祥文,林柏钢,陈国龙
(福州大学 数学与计算机科学学院,福建 福州 350116)
社交媒介已经成为了一种分享交换信息的重要平台,识别出其中影响力高的用户已经广泛地应用于推荐系统、专家识别、广告投放等应用。该文提出了一种受限张量分解方法,其能识别出给定主题下影响力高的用户,同时保持其影响力的极性分布(例如正面、中性、负面)。该方法通过拉普拉斯矩阵引入用户主题相似性约束,控制张量分解过程,使用分解结果计算用户影响力得分。实验结果表明,该方法在社会影响力分析中的性能优于OOLAM、TwitterRank等基准算法,并具有良好的可扩展性。
张量分解;观点;拉普拉斯矩阵;社会影响力分析
Abstract: Social media has become an popular platform for sharing and exchanging information. The identification of users of social influence has already been applied into many applications including recommendation systems, experts finding, social advertising et al. This paper proposes a constrained tensor factorization method to identify users with high social influence. In the factorization result, the polairy allocation of influence is preserved (i.e. positive, neutral and negative influence). This method fuses topical similarity of users by Laplacian matrix, which would control tensor factorization to approximate the user influence. Experimental results demonstrate that the method outperformes the OOLAM, TwitterRank etc. in terms of ranking accuracy.
Key words: tensor factorization; opinion; Laplacian matrix; social influence analysis
收稿日期: 2015-09-18 定稿日期: 2016-03-20
基金项目: 国家自然科学基金青年项目(61300105);教育部博士点基金联合资助项目(2012351410010);福建省科技重大专项项目(2013H6012);福州市科技计划项目(2012-G-113, 2013-PT-45)
1 引言
随着社交网络的飞速发展(例如微博、Facebook、Twitter等),包括文本、评论、关注、转发等由用户生成的数据正在飞速增长。这些数据给我们提供了机会去分析和度量社交网络中用户的影响力。根据Wikipedia的解释,社会影响力(social influence)是指一个人的思想、情感或行为被他人所影响的现象。因此,社会影响力分析具有很高的应用价值,其应用包括专家识别[1]、广告投放[2]、推荐系统[3]等。
然而,社会影响力是一种控制人与人之间关系的复杂因素,其分析和度量是一件困难的任务。近几年,该问题吸引了许多数据挖掘相关的学者、团体。Domingos等人[4]对用户影响力在营销网络中的传播规律展开了探索,他们发现具有广泛影响力的用户在营销传播中起到重要作用。Liu等人[5]提出了挖掘话题级社会影响力这一问题,并设计了一种产生式模型,结合连接关系和内容信息挖掘混合网络中的社会影响力。Iwata等人[6]提出了一种概率模型用于发现社区中用户间潜在的影响力,该模型能够找到社区中影响力高的用户、用户间关系及预测事件热门程度。Mehmood等人[7]提出了一种用于分析社区级影响力大小的模型。借助于层次策略,给定社区间信息传播模式,该模型能够识别出社区及它们相互之间的影响力大小。张玥等人[8]针对PageRank算法按照度分布进行数据结构优化,提出了一种基于集合划分的快速排序算法SD-Rank。在天涯论坛上的用户排序实验中,算法时空复杂性大大降低。郭岩等人[9]利用层次分析法结合专家打分,构建了一种网络信息源影响力的评估模型,通过信息源表现力、网民关注度和媒体关注度等指标对影响力进行评估。除此之外,基于图的挖掘算法也被应用于社会影响力分析中,这些算法将用户看成图中的一个节点,从不同的角度定义边的含义[10-11]。一些更细粒度的社会影响力分析方法也被提出,它们基于受限非负矩阵分解[12],通过分解(用户—帖子)矩阵来预测用户将会收到的点击量。但是,在社交媒介的环境下,用户间的关系往往存在描述性的信息,这使得这些由用户产生的信息变成多维数据。比起矩阵或图的表示方法,张量提供了一种更加自然、简洁的数据框架,用于这类多维数据的表示。本文提出一种受限非负张量分解方法用于社会影响力分析,使用三阶张量表示用户间评论关系,关于主题的辅助信息则以限制项的形式加入到张量分解中,控制张量分解过程。使用该方法,话题相关的用户将比话题无关的用户更具影响力。通过实验比较,在用户影响力排序精度上,本文提出的方法要比TwitterRank[10]、OOLAM[11]等基准方法有更优的性能。
近些年来,张量分解被大量地应用于数据挖掘任务中,例如,链接预测[13]、标签推荐[14]等。但是这些张量分解方法无法引入辅助信息控制张量分解过程。因此,许多受限张量分解方法被提出以利用额外的知识,控制张量分解。两种应用广泛的张量分解模型是CANDECOMP/PARAFAC(CP)和Tucker分解[15]。基于这两种分解方法衍生出一系列受限张量分解方法。在文献[16]中,一种使用拉普拉斯矩阵限制张量分解的方法被应用于图像表示,在图像聚类中取得了优于基准方法的性能。在文献[17]中,通过控制张量分解中潜在因子的性质,在事件预测中取得了更好的效果。本文提出的张量分解方法主要有两方面不同于以往的工作,一方面是受限张量分解的目标函数,另一方面是求解该目标函数的迭代算法。
接下来文章的结构安排如下: 第二节将介绍本文提出的受限张量分解方法,第三节说明如何将本文的张量分解方法应用于社会影响力分析,第四节为实验与结果分析。
2 基于拉普拉斯限制项的非负张量分解
CANDECOMP/PARAFAC(CP)是一种被广泛使用的张量分解方法,CP分解是将张量分解为一系列秩为1的张量[15]。为了检索出给定主题下社会影响力高的用户,本文提出一种基于CP模型的受限张量分解方法,其更新迭代规则是矩阵运算,形式更加简洁高效。
2.1 加入拉普拉斯限制项的目标函数
通过分析本文的实验数据我们发现,相关度前100名用户所接收到的评论总量平均高出后100名用户133.7%,这意味着主题相关的用户将比无关用户更有可能得到更多的评论。为了利用这一数据特性,我们引入拉普拉斯限制项,目标函数如式(1)所示。
其中,Xk∈I×J表示张量X∈I×J×K的第k片正面切片。k∈I×J表示Xk的估计。k是Ak∈I×R与VT∈R×J的乘积。H∈{0,1}I×I表示用户相似性矩阵,若Hij=1表示用户i与用户j相似,否则不相似。接下来α设为1,即拟合原始张量和限制项同等重要。
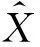
其中,C是一个对角矩阵,Cii=Lii。这里Ak和V的元素都是需要求解的变量。
2.2 求解目标函数
我们使用交替最小二乘法,交替更新变量矩阵,当更新其中一个变量矩阵时固定其他变量矩阵。使用KKT条件找到一个局部最优解。拉格朗日函数如式(3)所示。
其中,λ、σ和θ表示对应三个限制条件的拉格朗日乘子。将矩阵V看成变量,将Ak看成常量。可以得到J(V)的梯度。
根据V的补充条件,对于任意a、b,有σabVab=0。使用该条件,我们有:
先给出V的更新规则,详细的求解步骤在2.3节给出。同样的方法,我们可以得到Ak的更新规则。形式如式(6)。
定理 1 拉格朗日函数J在更新规则(6)下是非增的。证明将在2.3节中给出。
矩阵运算能够方便地用MapReduce编程框架实现,从而适应大规模数据。不难发现,式(6)可以写成紧凑的矩阵运算形式:
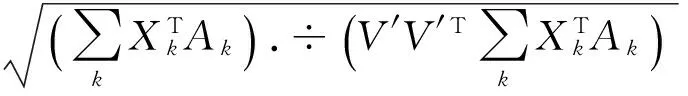


图1 拉普拉斯受限张量分解算法伪代码
2.3 收敛性证明
先给出证明所需条件,证明方法类似文献[18]。
定义2.1 对于任意M,M′,若函数Z(M,M′)满足:
那么我们称Z(M,M′)是一个J(M)的辅助函数。
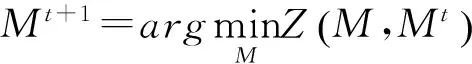
将矩阵V视为函数J的变量,那么拉格朗日函数J可以写成:
定理 2 函数Z(V,V′)是拉格朗日函数J(V)的辅助函数。Z(V,V′)形式如下:
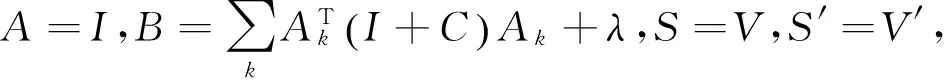
式(11)关于Vab是凸的,这里令辅助函数Z(V,V′)关于Vab的梯度为0,求其极小值点,可以得到式(12)。
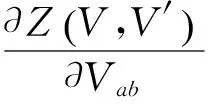
计算式(12)可以得到:
根据式(5)可得Vab的更新规则公式。同理,可以得到Akab的更新规则。这样就可以得到式(6)。综上,拉格朗日函数J在更新规则(6)下是非增的。定理1证毕。
3 社会影响力分析
为分析用户的社会影响力,本文首先使用张量表示用户间的交互关系,即用户间的评论关系。描述性信息是评论内容的极性。所有的交互关系使用一个三阶张量X∈{0,1}N×M×E表示。评论的极性分为三类: 正面、中性、负面。若用户i对用户j进行了一次极性倾向为k的评价,那么Xijk=1,否则为0。这里判定一条评论的极性是根据正负面情感词的数量。若评论中正面词多于负面词,则记为正面评论。若正面词少于负面词,则记为负面评论。否则为中性评论。
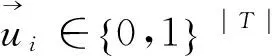
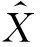
4 实验及分析
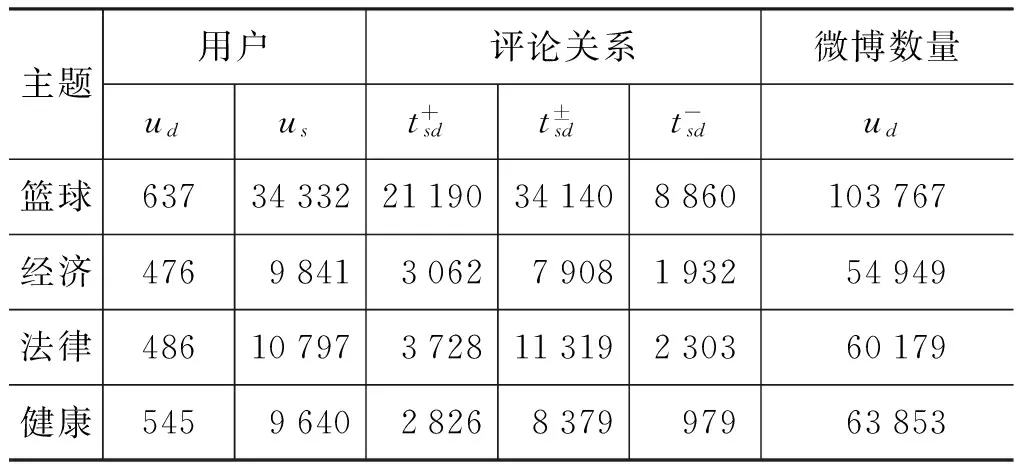
表1 实验数据集构成细节
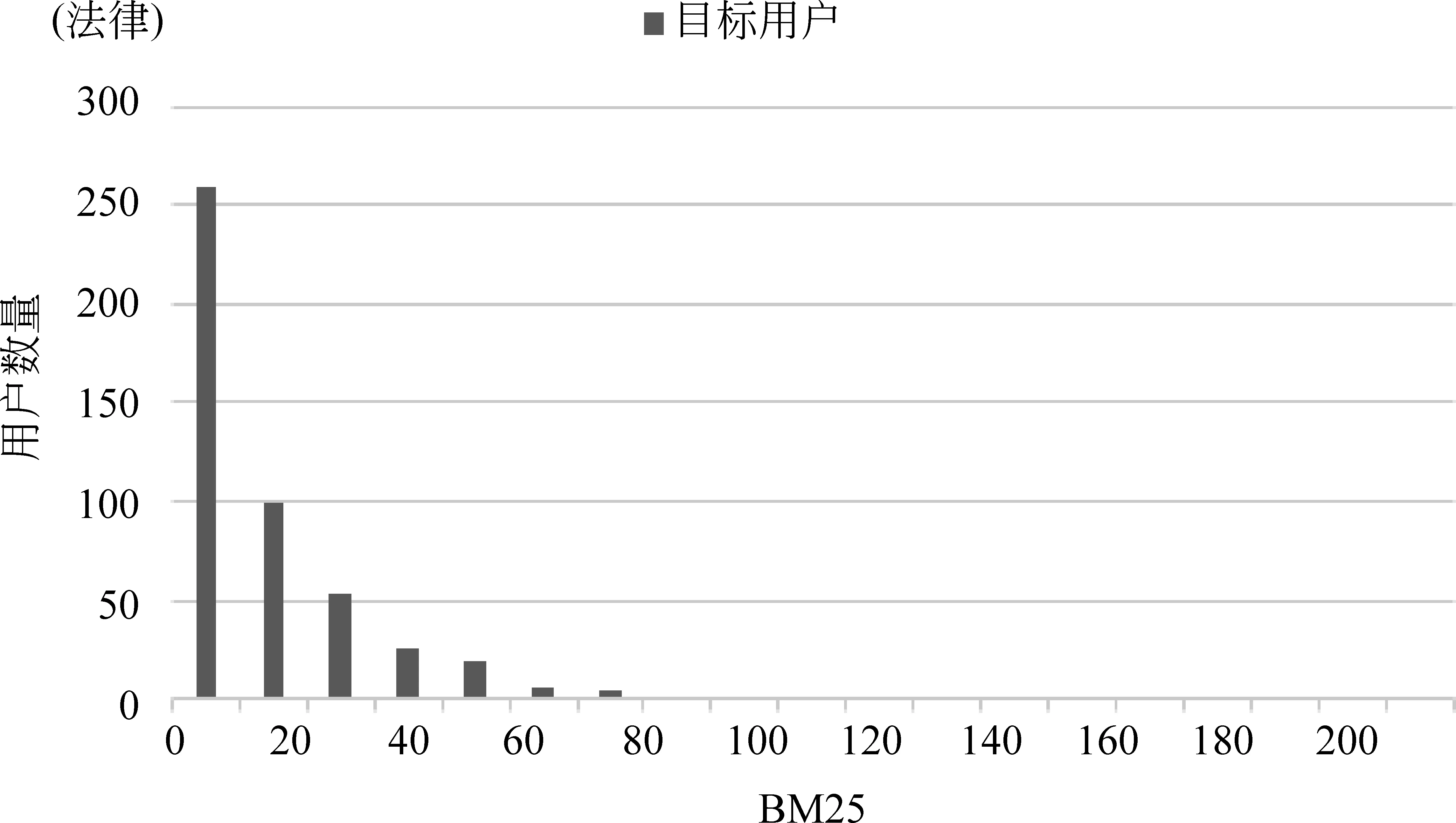
数据集中目标用户粉丝数量分布如图2所示,所选取的目标用户,其粉丝数量分布近似服从幂律分布,具有一定的代表性。不同主题下,固定BM25值范围内目标用户数量的分布如图3所示,BM25是一种衡量用户主题相关度的度量(BM25越大则与主题越相关),虽然我们使用关键词搜索出目标用户,但是主题弱相关的用户还是占到大部分,这也是为什么我们使用主题词搜索目标用户,而不是随机选取目标用户。
实验中另一个关键问题是在给定主题下如何确定真实的用户社会影响力排序列表。例如,给定主题篮球,我们通过人工排序确定真实的用户影响力排序列表。五位分别来自数学和计算机系的学生,根据投票原则,分别选出影响力排名1~5、5~10、11~20的列表作为真实的用户影响力排序列表。特别需要说明的是,这五位学生均参加过COAE2012,COAE2013和SIGHAN2015的语料标注工作。
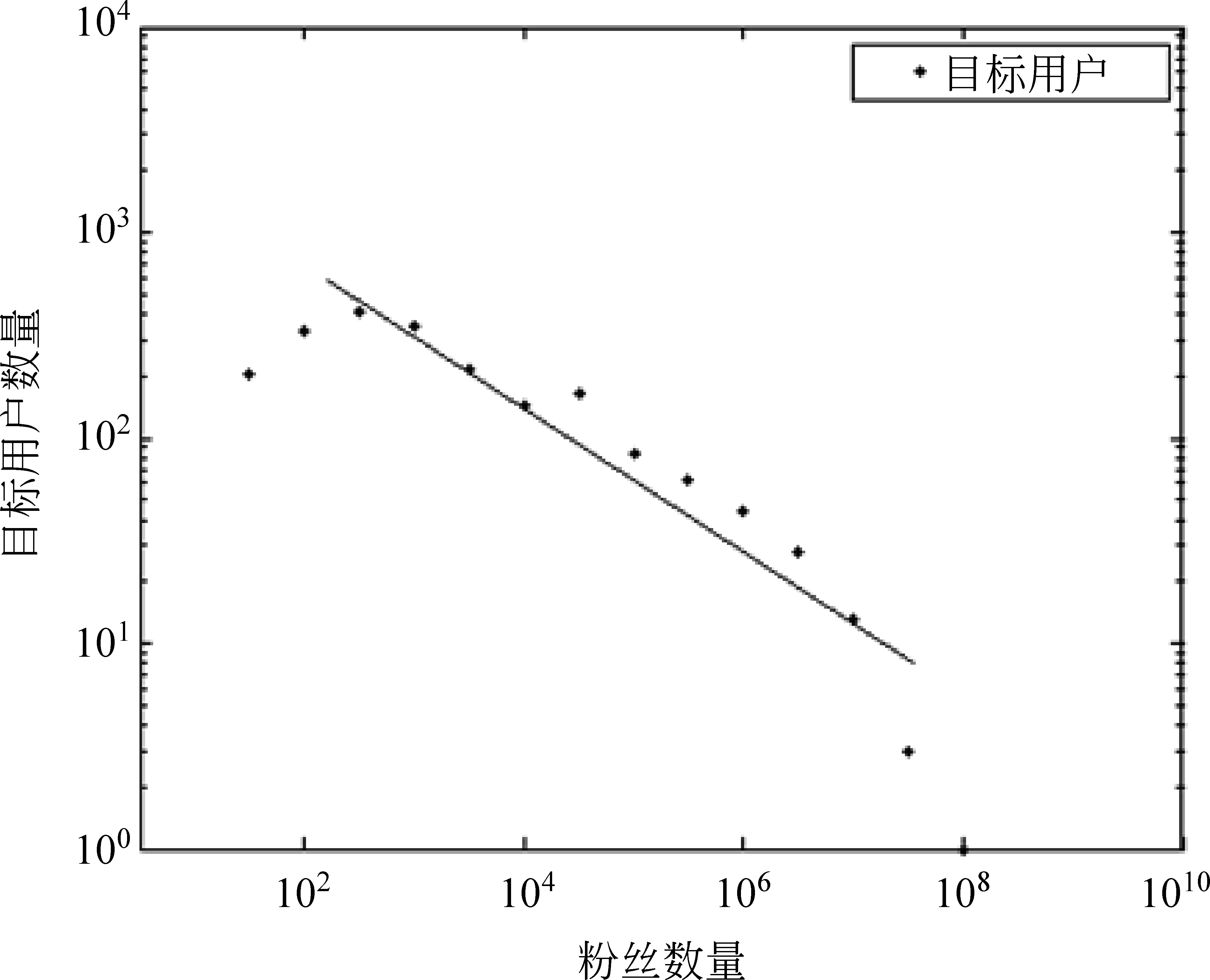
图2 拥有不同规模粉丝数的目标用户分布图
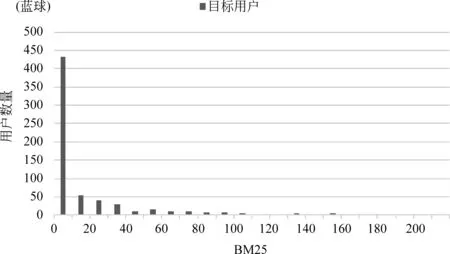
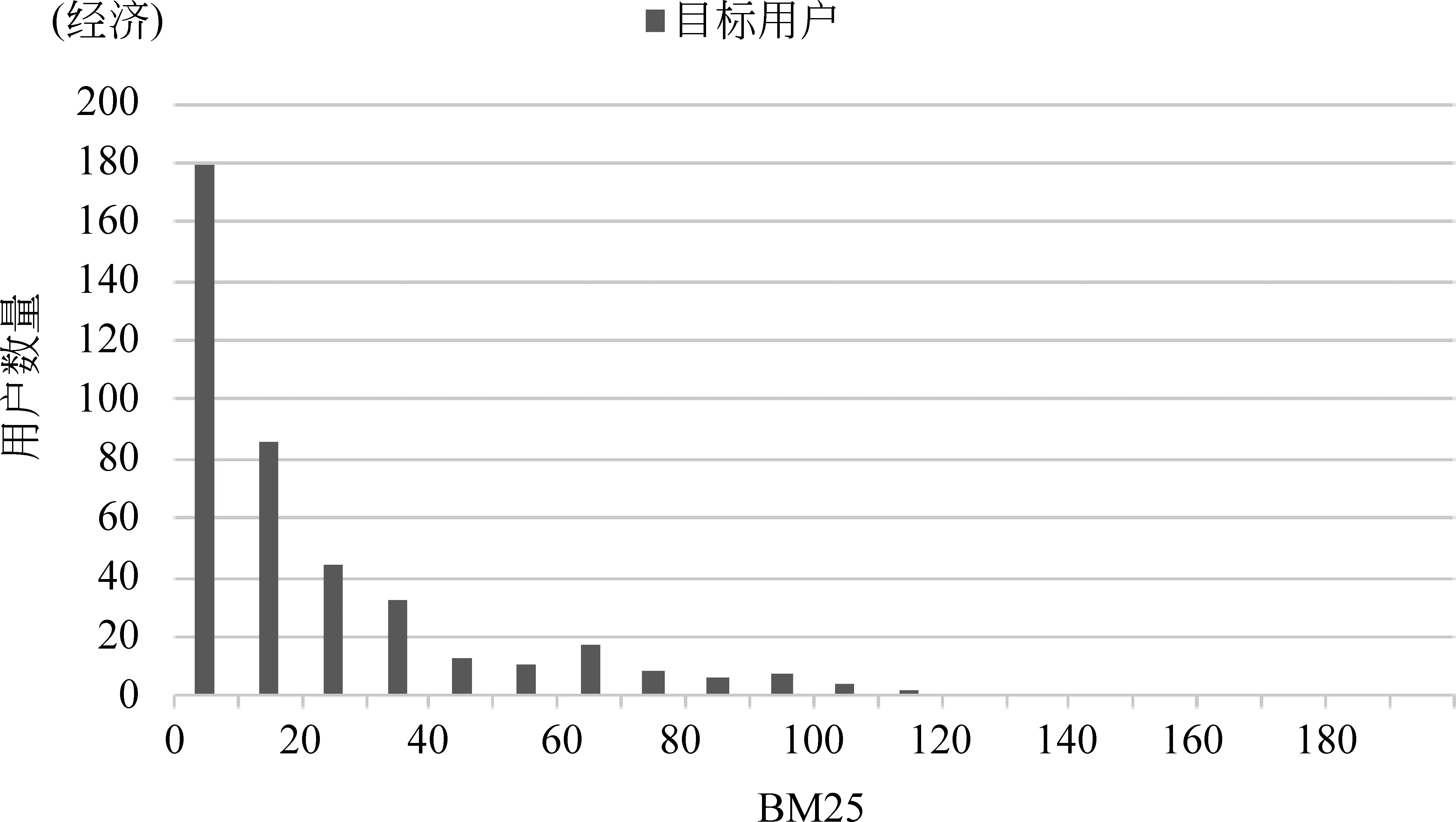
4.2 实验性能分析
参数包括调节因子α和潜在特征维度R。这里将拟合原始张量和限制项视为同等重要,令α=1。确定R的方法则以篮球主题为例,如图4所示,RMSE为均方根误差,当R>5后RMSE下降幅度极小,故实验中R=5。图4也印证了本文方法的收敛性。
为了更好地体现本文方法在社会影响力分析上的有效性,本文设置了如下基准方法:
(1) 为了验证本文加入的拉普拉斯限制项能够起到作用,我们设置了两个基准实验CP及融合BM25的CP。第一个是为了说明本文加入的拉普拉斯限制项是有效的。第二个是为了说明本文的方法能够更好地融合主题因素到社会影响力分析中。
(2) OOLAM的结果是正面、负面两种社会影响力大小。我们将其均值看作用户社会影响力得分。同样,OOLAM并没有加入主题信息,我们还设置了一个加入BM25值的OOLAM基准实验。
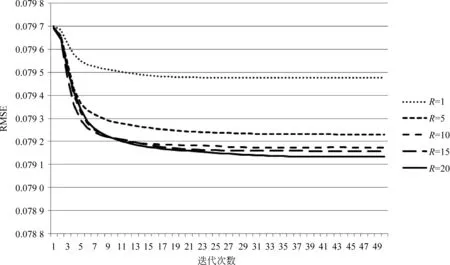
图4 随迭代次数变化的RMSE
(3) TwitterRank能够计算出用户在给定主题下的影响力,但是没有加入交互关系因素。因此我们还设置了一个添加评论关系的TwitterRank基准实验,记为TR+RA。
(4) 粉丝数和评论量也被设置为对比实验,分别记为FA和RA。
实验中使用p@k评价指标评判各个方法的排序精度,实验结果如表2所示,从中可以得到如下结论: (1)比起CP和CP+BM25,本文的方法在排序精度上有明显的提升。这说明加入拉普拉斯限制项在该数据集上是有效的,能够更好地融合主题信息到社会影响力分析中。(2)本文的方法在该应用场景下优于OOLAM和TwitterRank。同时,本文方法的平均准确率要高出第二好性能10%。(3)根据排序结果,本文方法在部分指标下并未取得最好性能。主要有两方面原因: 一方面是那些主题相关并且影响力大的用户,他们的影响力会被拉普拉斯限制项降低;另一方面是优化算法的优化程度,例如部分主题无关且影响力大的用户,他们的影响力并未减小。
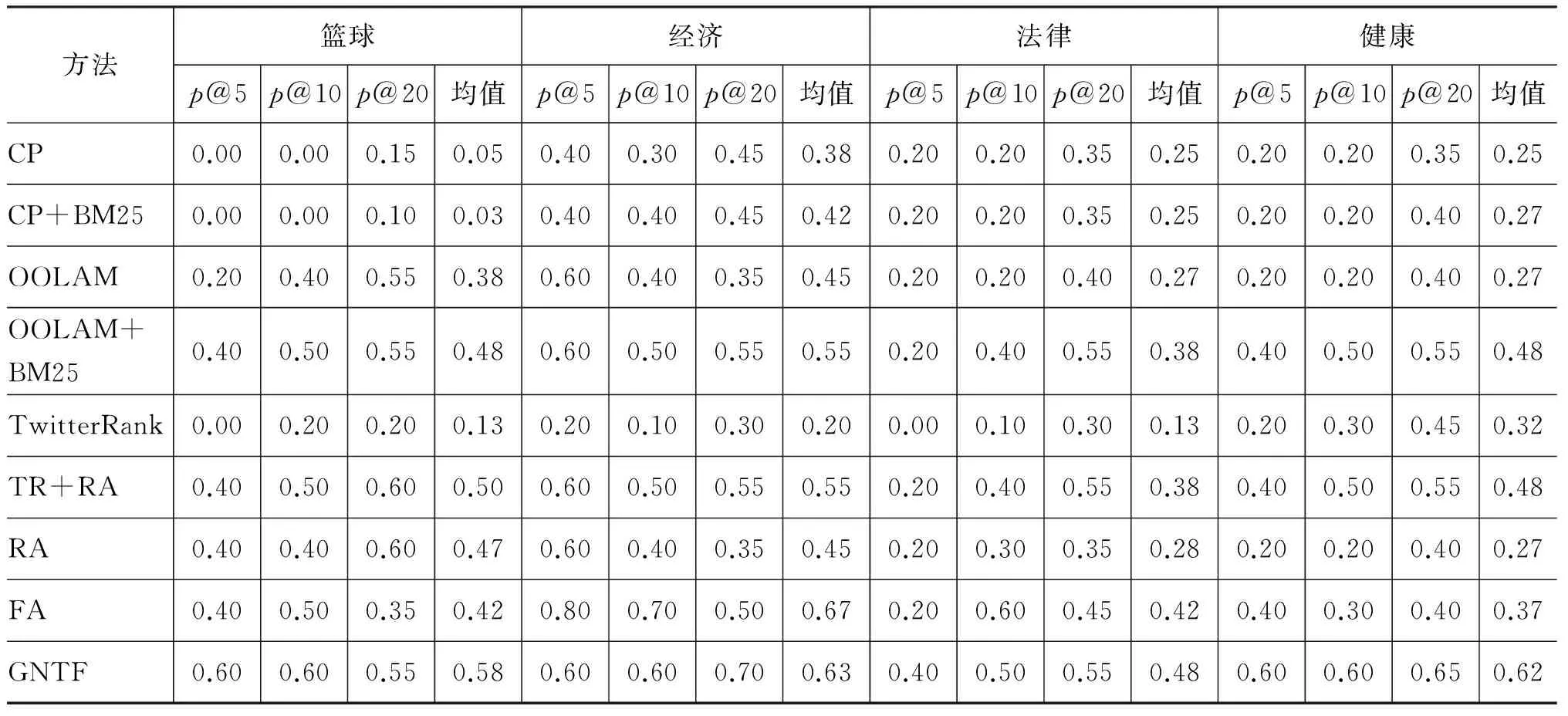
表2 本文方法与基准方法在p@k下的性能对比
这里使用Pearson相关系数,来衡量本文方法能否在张量分解之后仍然保留用户影响力极性分布的特征。从表3中可以看出,分解后预测的结果与真实结果有较强的相关性,能够反映用户社会影响力的极性分布特性。从一定程度上可以说明本文的限制项对用户影响力极性信息的影响较小。
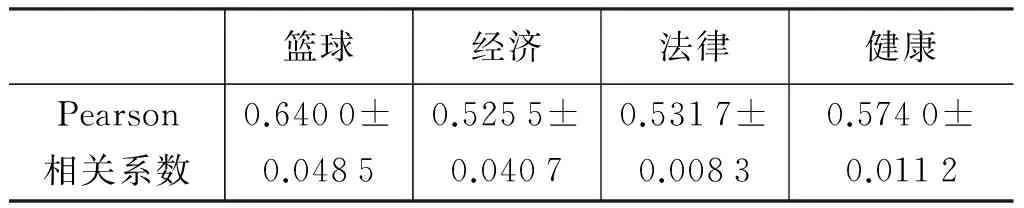
表3 预测用户影响力极性分布与真实值的相关性
为了验证本文算法的可扩展性,我们使用MapReduce编程模型实现该算法,实验平台为Hadoop。Hadoop集群由六台相同配置的节点构成,共24个Intel 处理器(2.83GHz)、96GB内存。按不同节点数和不同大小潜在特征维度R,测试加速比,实验结果如图5所示。可以看出,本文的方法具有良好的可扩展性。
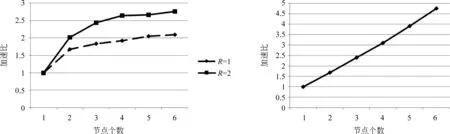
图5 在不同节点数与潜在因子维数下的加速比
5 结论
本文针对给定主题下用户影响力的问题,提出一种新的受限张量分解方法,并应用到影响力用户识别中,保持了用户影响力的极性分布。首先,利用张量对用户间交互关系建模。其次,提出一种受限张量分解,利用张量补全计算用户影响力得分。最后,根据分解结果计算用户影响力极性分布。实验表明,与OOLAM、TwitterRank等方法比较,本文方法在挖掘主题相关用户社会影响力上更加有效,能够保持用户影响力极性且扩展性良好。
[1] Tang J, Sun J, Wang C, et al. Social influence analysis in large-scale networks[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Paris, France, 2009: 807-816.
[2] Bakshy E, Eckles D, Yan R, et al. Social influence in social advertising: evidence from field experiments[C]//Proceedings of the 13th ACM Conference on Electronic Commerce. Valencia, Spain, 2012: 146-161.
[3] Rashid A M, Karypis G, Riedl J. Influence in ratings-based recommender systems: An algorithm-independent approach[C]//Proceedings of the 15th SIAM International Conference on Data Mining. California, USA, 2005: 556-560.
[4] Domingos P, Richardson M. Mining the network value of customers[C]//Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA, 2001: 57-66.
[5] Liu L, Tang J, Han J, et al. Learning influence from heterogeneous social networks[J]. Data Mining and Knowledge Discovery, 2012, 25(3): 511-544.
[6] Iwata T, Shah A, Ghahramani Z. Discovering latent influence in online social activities via shared cascade poisson processes[C]//Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Chicago, USA, 2013: 266-274.
[7] Mehmood Y, Barbieri N, Bonchi F, et al. Csi: Community-level social influence analysis[M].Machine learning and knowledge discovery in databases. Springer Berlin Heidelberg, 2013: 48-63.
[8] 张玥,张宏莉,张伟哲. 基于幂律分布的网络用户快速排序算法[J]. 中文信息学报, 2012,26(4): 122-128.
[9] 郭岩,刘春阳,余智华,等. 网络舆情信息源影响力的评估研究[J]. 中文信息学报. 2011,25(3): 64-71.
[10] Weng J, Lim E P, Jiang J, et al. Twitterrank: finding topic-sensitive influential twitterers[C]//Proceedings of the 3rd ACM International Conference on Web Search and Data Mining. New York City, USA, 2010: 261-270.
[11] Cai K, Bao S, Yang Z, et al. OOLAM: an opinion oriented link analysis model for influence persona discovery[C]//Proceedings of the 4th ACM International Conference on Web Search and Data Mining. Hong Kong, China, 2011: 645-654.
[12] Cui P, Wang F, Liu S, et al. Who should share what?: item-level social influence prediction for users and posts ranking[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. Beijing, China, 2011: 185-194.
[13] Dunlavy D M, Kolda T G, Acar E. Temporal link prediction using matrix and tensor factorizations[J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2011, 5(2): 10.
[14] Rendle S, Schmidt-Thieme L. Pairwise interaction tensor factorization for personalized tag recommendation[C]//Proceedings of the 3rd ACM International Conference on Web Search and Data Mining. New York City, USA, 2010: 81-90.
[15] Kolda T G, Bader B W. Tensor decompositions and applications[J]. SIAM Review,2009, 51(3): 455-500.
[16] Wang C, He X, Bu J, et al. Image representation using Laplacian regularized nonnegative tensor factorization[J]. Pattern Recognition, 2011, 44(10): 2516-2526.
[17] Davidson I, Gilpin S, Walker P B. Behavioral event data and their analysis[J]. Data Mining and Knowledge Discovery, 2012, 25(3): 635-653.
[18] Zhang Z Y, Li T, Ding C. Non-negative tri-factor tensor decomposition with applications[J]. Knowledge and Information Systems, 2013, 34(2): 243-265.

陈畅(1991—),硕士研究生,主要研究领域为面向社会媒介的观点挖掘。
E-mail: 175695762@qq.com

魏晶晶(1984—),博士研究生,主要研究领域为网络文本倾向性分析。
E-mail: weijj_0517@163.com

廖祥文(1980—),通信作者,副教授,主要研究领域为网络文本倾向性分析。
E-mail: liaoxw@fzu.edu.cn
Social Influence Analysis Considering User Opinion
CHEN Chang, WEI Jingjing, LIAO Xiangwen, LIN Bogang, CHEN Guolong
(College of Mathematics and Computer Science, Fuzhou University, Fuzhou, Fujian 350116, China)
1003-0077(2017)04-0191-08
TP391
A
