基于半监督CRF的跨领域中文分词
2017-10-11邓丽萍罗智勇
邓丽萍,罗智勇
(1. 北京语言大学 信息科学学院,北京 100083; 2. 北京语言大学 语言信息处理研究所,北京 100083)
基于半监督CRF的跨领域中文分词
邓丽萍1,罗智勇2
(1. 北京语言大学 信息科学学院,北京 100083; 2. 北京语言大学 语言信息处理研究所,北京 100083)
中文分词是中文信息处理领域的一项关键基础技术。随着中文信息处理应用的发展,专业领域中文分词需求日益增大。然而,现有可用于训练的标注语料多为通用领域(或新闻领域)语料,跨领域移植成为基于统计的中文分词系统的难点。在跨领域分词任务中,由于待分词文本与训练文本构词规则和特征分布差异较大,使得全监督统计学习方法难以获得较好的效果。该文在全监督CRF中引入最小熵正则化框架,提出半监督CRF分词模型,将基于通用领域标注文本的有指导训练和基于目标领域无标记文本的无指导训练相结合。同时,为了综合利用各分词方法的优点,该文将加词典的方法、加标注语料的方法和半监督CRF模型结合起来,提高分词系统的领域适应性。实验表明,半监督CRF较全监督CRF OOV召回率提高了3.2个百分点,F-值提高了1.1个百分点;将多种方法混合使用的分词系统相对于单独在CRF模型中添加标注语料的方法OOV召回率提高了2.9个百分点,F-值提高了2.5个百分点。
跨领域;中文分词;半监督CRF
Abstract: Applying the minimum entropy regularization framework to the supervised CRF model, this paper proposes a semi-supervised CRF model that combing the supervised learning on the labeled text in common domain with the unsupervised learning on the unlabeled text in the target professional domain. The domain adaptation is further improved by introducing a domain dictionary and a tagged corpus. Experiments on a cross domain segmentation task show that proposed method out-performs supervised CRF in terms of OOV recall and F-value.
Key words: cross domain; Chinese word segmentation; semi-supervised conditional random field
收稿日期: 2016-03-01 定稿日期: 2016-05-16
基金项目: 北京市哲学社会科学规划研究基地项目(13JDZHB005);中央高校基本科研业务费专项资金(09YB09)
1 引言
中文分词(chinese word segmentation,CWS)是指将组成句子的汉字序列用分隔符切分成单独的词语序列的过程。中文分词是其他中文信息处理应用(如机器翻译、信息检索、信息抽取等)的基础,其结果直接影响以此为基础的中文信息处理应用的性能。
近十年来,中文分词技术发展迅速,特别是将文本中局部上下文信息引入统计机器学习模型中,歧义切分和未登录词(out-of-vocabulary,OOV)识别相对于传统基于词典和规则的方法有了较大的提升[1]。
目前,基于统计的中文分词方法中最具代表性的是基于字标注的全监督分词方法(character-based tagging approach)[2]。该方法需要大量标注训练语料,一般在处理和训练语料相似的文本时,分词效果较好。历次SIGHAN CWS BACKOFF的评测结果显示,使用同一领域的语料进行测试时,全监督分词方法已经能够取得很好的结果,F-值高达95%*http://www.sighan.org/bakeoff2005/data/results.php.htm。但是,当测试语料和训练语料领域不一致时,分词准确率会大幅降低。中文信息处理应用可能涉及诸多领域,为每个领域都标注大量的训练语料,需要耗费极大的人力物力。然而,大量通用领域标注语料和专业领域无标记文本却极易获得。因此,中文分词方法的领域适应性问题,成为一个值得关注的研究课题。
在跨领域分词任务中,由于文本领域内容的变化,许多在测试语料中出现的特征信息不在训练语料中出现(据统计,本文使用的Chemistry语料约有55%的特征不在SIGHAN CWS BACKOFF 2005提供的PKU训练语料中出现),导致未登录词识别困难;同时,由于文本的上下文变化,也使得测试语料和训练语料中共同出现的特征在分布上也存在较大的差异,从而导致已登录词(in-vocabulary,IV)的识别性能下降。为了解决专业领域文本特征缺失和已有特征分布不一致的问题,本文提出: 在训练过程中,将特征模板同时作用于通用领域训练文本和专业领域测试文本,以弥补专业领域文本特征缺失的问题;同时,通过最小化专业领域无标记文本上的条件熵将专业领域文本的分布信息和通用领域的标注信息纳入到统一的学习框架中,以提高跨领域分词性能。
本文第二节介绍中文分词领域适应性相关研究;第三节介绍条件随机场模型;第四节介绍基于序列标注的中文分词建模;第五节介绍半监督CRF分词模型;第六节通过实验说明半监督CRF在跨领域中文分词中的有效性;第七节总结并提出下一步工作。
2 相关研究
随着中文信息处理应用的发展,分词方法的领域适应性逐渐引起了学者们的关注和重视。近年来,研究者提出了许多方法,其中,常见的方法主要有数据加权算法和半监督学习方法。张梅山[3]等人提出统计与词典相结合的领域自适应中文分词方法,训练阶段将通用领域词典的词长信息以特征的方式融入CRF模型,而在对不同领域的文本进行分词时,需要通过加载相应领域的词典提取词长特征以辅助分词系统进行分词。许华婷[4]等人提出Active Learning算法与n-gram统计特征相结合的领域自适应方法,从专业领域无标记文本中选择比较有代表性的句子进行人工标注并加入训练语料,以提高分词系统的领域适应性。该方法能够显著提高分词系统的领域适应性,但每当领域变化时,均需要抽取和人工标注对应领域的语料。Fan Yang[5]等人提出将部分标记学习引入CRF模型,通过半监督学习方法学习维基百科词条的边界信息,从而提高分词系统的领域适应性。该方法只能提高在维基百科词条中出现的词汇的识别率,对于维基百科中未出现的词语帮助有限。
针对以上工作中领域知识(专业词典、标注语料等)依赖问题,本文在不引入任何人工干预的情况下,直接将专业领域待切分文本的特征信息加入到训练模型中,从而解决专业领域文本特征缺失的问题;同时,为了学习专业领域无标记文本的特征分布信息,本文将最小熵正则化框架[6]引入CRF模型,将基于通用领域标注文本的有指导训练和基于目标领域无标记文本的无指导训练相结合,生成半监督CRF模型,并将其应用于跨领域分词任务中,实验结果表明该方法能显著提高分词系统的领域适应性。但是,单独使用半监督CRF模型的分词系统仅能在一定程度上提高未登录词的召回率,无法降低未登录词比例。同时,已有研究工作中的“加词典”的方法和基于Active Learning算法的语料选择方法均能够有效降低测试语料中未登录词所占的比例,对分词系统性能提升有较大的帮助。因此,本文将半监督CRF模型和“加词典”的方法及加标注语料的方法结合起来,达到既能够降低未登录词比例,又能够提高未登录词召回率的目的,进一步提高分词系统的领域适应性。实验表明,单独使用本文所提半监督CRF模型便能够在全监督CRF模型的基础上使 OOV召回率提高3.2个百分点,F-值提高1.1个百分点,并达到和人工加入“领域词典”的方法相当的性能。同时,将半监督CRF模型和“加词典”以及加标注语料的方法结合的分词系统,相对于单独在CRF模型中添加标注语料的方法性能有较大的提升,OOV召回率提高了2.9个百分点,F-值提高了2.5个百分点。
3 条件随机场(CRF)
条件随机场(conditional random filed, CRF)[7-8]在建模时考虑了数据的内容信息和数据标签之间的变化信息,其相关模型在许多自然语言处理任务中取得了较好的结果。CRF已成功应用于中文分词、词性标注、命名实体识别等任务中。在序列标记任务中,CRF要学习一个从观察序列x=(x1,x2,…,xT)到标记序列y=(y1,y2,…,yT)的概率函数映射关系,本文采用简单的线性链式CRF模型,该模型的条件概率公式[8]为:
(1)
其中,fk(yi-1,yi,x,i)为状态特征函数或转移特征函数,θk为待估计的模型参数,Z(x)为标准化因子,是所有可能的标记序列情况之和,如式(2)所示。
(2)
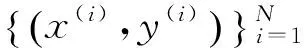
(3)
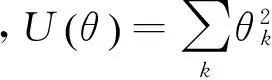
4 中文分词建模
4.1 序列标注问题建模 由于中文词语具有上下文的序列特征,因此本文将中文分词问题转化为序列标注问题[2]。其序列标注模型定义为: 给定一个长度为T的中文句子x=(x1,x2,…,xT),从所有可能的标记序列中,挑出最有可能的标记序列y=(y1,y2,…,yT),从解得的标记序列y中还原分词结果。
一个字符在词语中的位置通常有四种: 词首(B,Begin),词中(M,Middle),词尾(E,End)和单字词(S,Single)。一个词语应是以B开头、以E结尾、中间可能有M的标记,或是以单字词S标记。一个简单的中文分词标记序列示例如图1所示。

图1 中文分词标记序列示例
4.2 中文分词特征定义
综合考虑训练时间和分词效果两方面的因素,本文采用大小为3的文本窗口定义特征。特征定义方式以某字符相对于当前字符在文本中的偏移位置标记。本文使用六种字符特征模板,包括一元字符特征模板C0(当前字符)、C-1(当前字符的前一个字符)、C1(当前字符的后一个字符)和二元字符特征模板C-1C0、C0C1和C-1C1。同时,加入了二元标记转移特征模板y-1y0(前一个字符的标记到当前字符标记的转移特征)。
由于数据稀疏问题,以及训练文本和目标领域文本之间的差异,仅在训练语料中使用上述基本特征模板难以获取目标领域文本的构词信息。因此,在抽取特征实例时,本文将上述基本特征模板应用于训练语料的同时,将除y-1y0外其他六种字符特征模板应用于目标领域未标记文本,并引入半监督CRF模型,将从标记语料和未标记文本中获取的特征联合进行训练,以提高跨领域分词效果。
5 半监督CRF
5.1 半监督CRF介绍 在面向分类的半监督学习方法[9]中经常采用低密度划分原则,从大量未标注实例中获取分类信息。由于未标注实例缺少类别标注信息,该原则要求选取的分割面尽量穿过样本点较为稀疏的区域,即让样本点尽可能远离分割面。

给定标记样本Dl={(x(1),y(1)),(x(2),y(2)),…,(xN,yN)}和未标记样本Du={x(N+1),x(N+2),…,x(M)},训练的目标函数为:
(4)
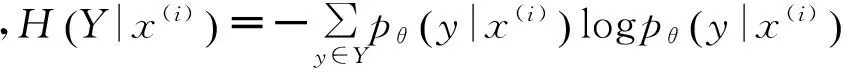
最后,半监督CRF的参数估计为:

(5)
参数θ的初始值为对应超参数取值的全监督CRF的最优解。
最大化RL(θ)即最大化对数似然并最小化条件熵H(Y|x(i)),在尽量拟合标注数据的同时保证了未标注数据的标记序列概率区分度最大。
测试阶段,对于给定的观测序列x,最佳标记序列y*由式(6)给出:

(6)
5.2 半监督CRF训练过程优化
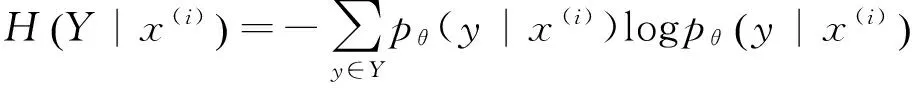
(7)
其中,Y-(i..j)=〈Y1..(i-1)Y(j+1)..T〉。
未标记数据的条件熵可展开为:
(8)
由于线性CRF遵循马尔科夫性质,yi+2独立于yi,因此可以得到式(9)。
(9)
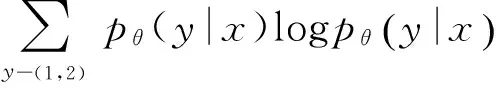
根据熵的分解运算规则:
可将Hα和Hβ分别递推成前向和后向运算的形式,递推公式如式(12)、式(13)所示。
初始取值为:Hα(φ|y1,x)=0,Hβ(φ|yT,x)=0。优化后,目标函数及梯度的计算复杂度均为O(TS2)(S为标记种类数,本文为四种;T为观察序列长度),与全监督CRF的时间复杂度相同。
6 实验结果与分析
6.1 实验数据 本文使用的标记训练语料为SIGHAN CWS BACKOFF 2005 提供的PKU训练语料(包括19 056条句子,1 109 947个词语),该语料为《人民日报》新闻语料;专业领域语料包括《中国大百科全书》生物卷鸟类(Bird)语料和化学卷有机化学类(Chemistry)语料。鸟类语料主要是对鸟的分类、形态、习性等的描述说明,有机化学类语料主要包括对某一化学物质的组成、作用、反应等的说明。
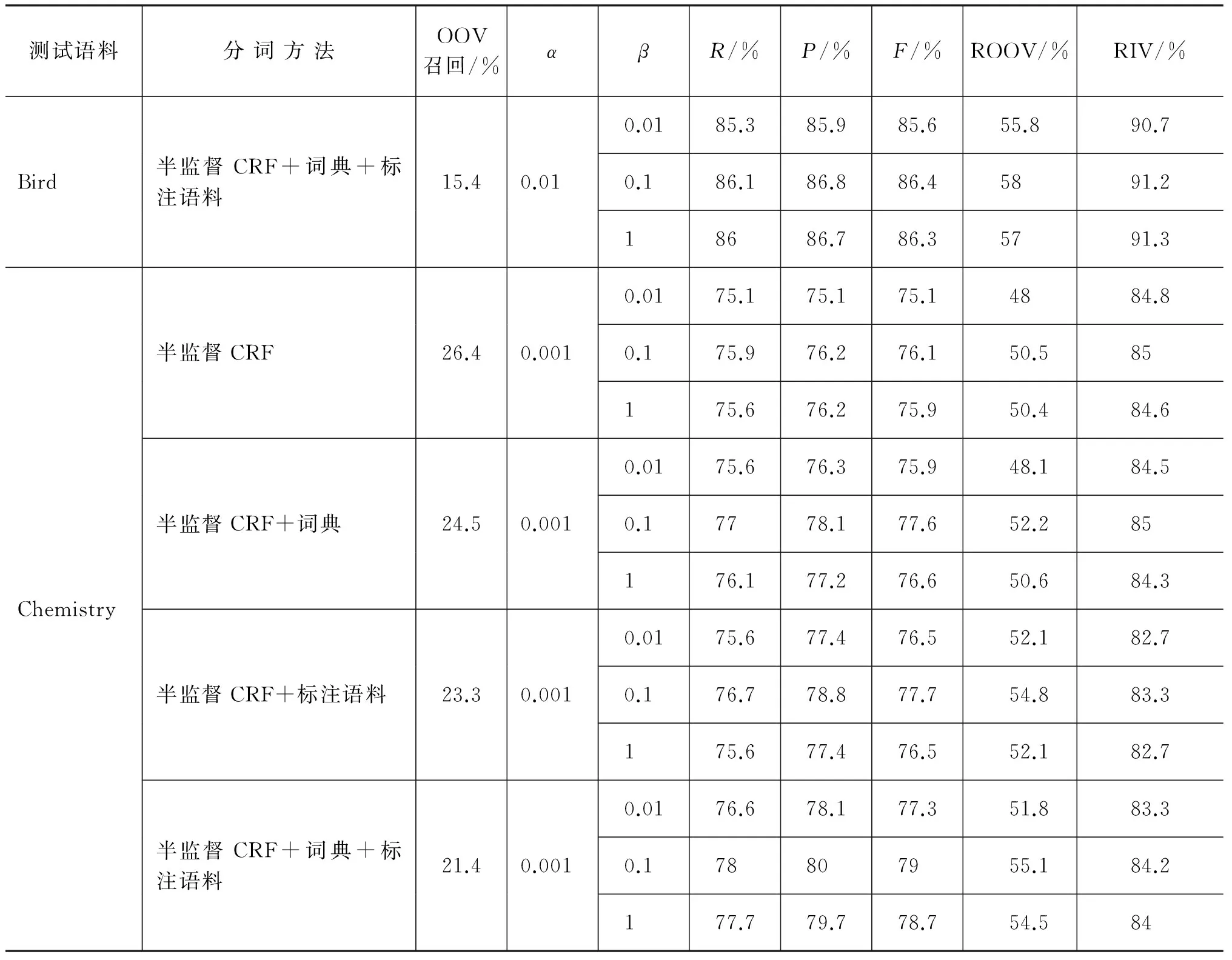
为了进行对比实验,本文根据文献[4]中语料打分方法(其中,w1、w2、w3、w4分别取值为0.1、0.2、0.3和0.4)从未标注的Bird和Chemistry语料中各选取得分排名前50的句子进行人工标注作为少数的专业领域标注语料,Bird语料和Chemistry语料去掉得分排名前50的句子后,剩下的句子人工标注作为测试集,标注规范为北大分词标注规范[12]。表1给出了各个测试语料的统计信息。从表1中能够看出,Bird和Chemistry语料相对于PKU训练语料差异较大,OOV召回率最高可达26.4%。
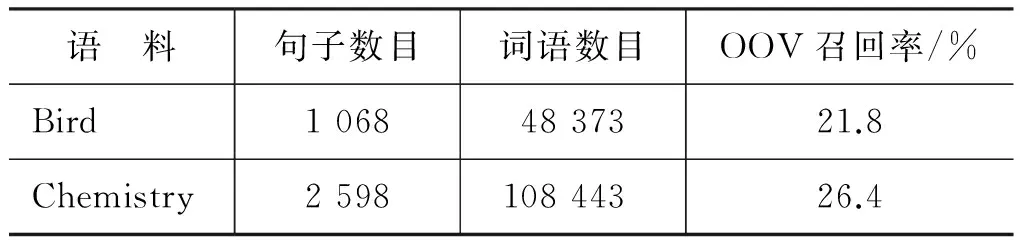
表1 测试语料统计信息
由于语料中英文、数字和标点符号种类有限,为了避免数据稀疏并减少特征数量,训练和测试之前,用“A”替换所有的大写英文字母,“a”替换所有的小写英文字母,“0”替换所有的阿拉伯数字,“。”替换掉常用的标点符号。
6.2 实验设置
表2列出了各种分词方法的评测对比结果,表中数据为选择最优超参数的结果,超参数的选择见6.4节。
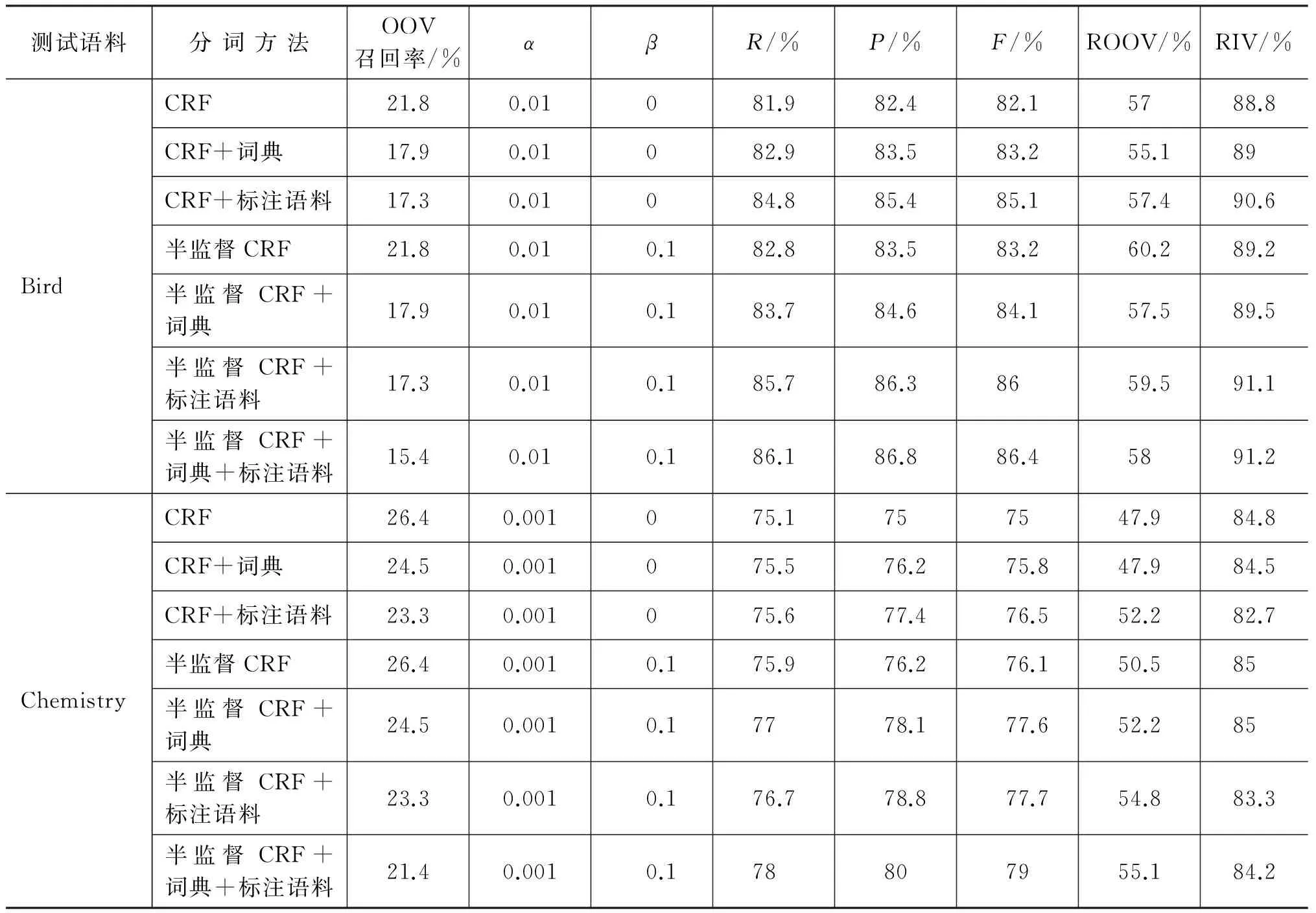
表2 不同分词方法的评测结果
为了验证本文所提半监督CRF模型的有效性,我们将半监督CRF和全监督CRF的实验结果进行了对比。
为了考察半监督CRF在领域自适应方面的性能,我们复现了“加词典”的方法和添加标注语料的方法。其中,“加词典”的方法所用专业领域词典通过文献[13]的新词发现算法在测试语料中挖掘新词,取得分排名前300的词语进行人工筛选、并去掉训练语料中已有的词语。为了解决文献[3]中的领域词汇在训练语料中不出现导致特征缺失的问题,本文所做实验直接将领域词表加入训练语料进行训练。添加标注语料的方法通过文献[4]的语料选择方法分别从Bird语料和Chemistry语料中选取得分排名前50的句子进行人工标注后加入训练语料进行训练。
为了进一步考察半监督CRF的可扩展性能,我们在加入专业词典和标注语料后,仍然使用半监督CRF进行训练,结果表明分词性能仍有显著提升。
由于“加词典”的方法和添加标注语料的方法能够有效降低测试语料中未登录词的比例,为了综合利用本文所提半监督CRF模型和“加词典”及添加标注语料的方法的优点,本文在加入“领域词典”和专业领域标注语料的基础上,采用半监督CRF模型进行训练,进一步提高分词系统的领域适应性。
6.3 实验结果
通过对比表2中的评测结果,可以得出以下结论。
(1) 加入词典、加入标注语料和本文所提半监督CRF方法均能对分词系统的性能进行改善;
(2) 加入词典和加入标注语料的方法均使得部分未登录词成为已登录词,从而降低了测试语料的未登录词比率,提高了分词系统的性能。从结果来看, 在Bird语料上,加入词典和加入标注语料对未登录词的召回率提升并不明显,加入词典的方法甚至有下降的趋势,它的主要作用是提升了已登录词的召回率;在Chemistry语料上加入句子的方法对未登录词召回率的提升有较大的帮助,但却明显降低了已登录词的召回率;
(3) 本文提出的半监督CRF模型通过简单的添加特征和条件熵最小化,便能达到和加入词典的方法相当的效果,从表2可以看出,半监督CRF在全监督CRF的基础上保证了已登录词召回率不下降的情况下,还能显著提高未登录词的召回率,在Bird语料上,未登录词召回率提升幅度高达3.2个百分点,F-值提升幅度达1.1个百分点;
(4) 在加入词典和标注语料的情况下,半监督CRF仍能在全监督CRF的基础上进一步提升性能,由此证明了半监督CRF模型在领域自适应中的有效性;
(5) 将加词典、加标注语料和半监督CRF模型结合起来的分词系统,既降低了测试语料中未登录词的比例,又提高了未登录词的识别率,在Chemistry语料上相对于在全监督CRF模型中添加标注语料的方法,OOV召回率提高了2.9个百分点,F-值提高了2.5个百分点。
6.4 超参数选择
本文使用分步策略确定超参数α和β的取值。
第一步: 将β固定为0,在全监督CRF模型上调整α的值。表3给出了α取值对应的全监督CRF识别结果。从表中数据看出,α取值较小时,对全监督CRF的性能影响较小。α取值在0.001到0.1之间时,在Bird语料上的F-值呈现先增大后减小的趋势,并在α=0.01处分词效果最好;α取值在0.0001到0.01之间变化时,在Chemistry语料上的F-值也同样呈现先增大后减小的趋势,并在α=0.001处分词效果最好。
第二步: 将α取值固定为上一步中F-值最高时的取值,在半监督CRF模型上调整β的值,待估计参数θ初始值为对应α取值的全监督CRF的最优解。表4给出了β取值对半监督CRF分词性能的影响。从表中数据看出,β取值对分词性能有较大的影响。当β取值在0.01到1之间变化时,半监督CRF的分词效果呈现先增大后减小的趋势,并且分词效果均高于或者等于全监督CRF的分词效果。当β=0.1时,分词效果最好。
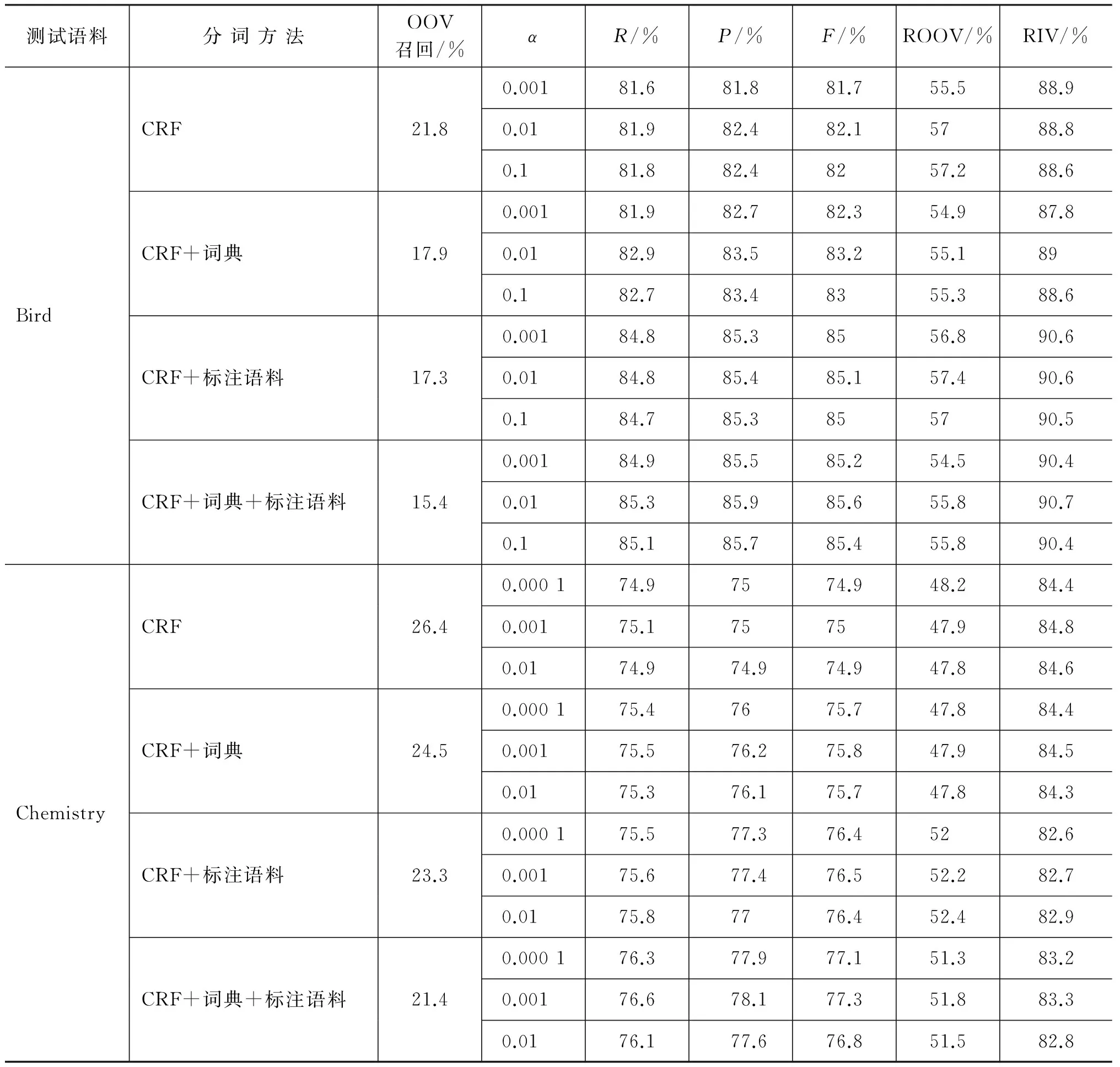
表3 α取值对应全监督CRF的分词结果对比

表4 β取值对应半监督CRF的分词结果对比
续表
6.5 特征分析
为了进一步了解在半监督CRF模型中,特征权重变化对分词结果的影响,本文以Bird语料为例对特征权重在模型迭代过程中的变化情况进行分析。如图2所示,对于汉字序列“具棕色横斑”,全监督CRF将其误切分为“具棕色/横斑”,半监督CRF则将其正确切分为“具/棕色/横斑”。从图2中标注结果看出,半监督CRF相对于全监督CRF,字符“具”和“棕”的标记发生了变化。

图2 全监督CRF和半监督CRF切分结果对比
图3和图4给出了当前字符为“具”时,特征C0和C-1C0在“具”字取不同标记时权重随迭代次数变化的趋势图(横轴为半监督CRF迭代次数,取0时即为全监督CRF;纵轴为特征权重取值)。其中,图4中标记为E和标记为M的特征权重变化曲线在0附近重合。从图中来看,对于特征C0和C-1C0来说,“具”的标记为S的特征权重增大的同时,标记为B的特征权重在逐渐减小。虽然还有其他特征权重的变化影响,但图2的切分结果表明,随着迭代次数增加,字符“具”的所有特征总体上使“具”的标记最终偏向正确答案S。
同样,图5和图6给出了当前字符为“棕”时,特征C-1和C1对应不同标记的权重变化图。从图5、图6的特征权重变化和图2的切分结果看出,“棕”的所有特征总体上使得“棕”的标记偏向正确答案B。
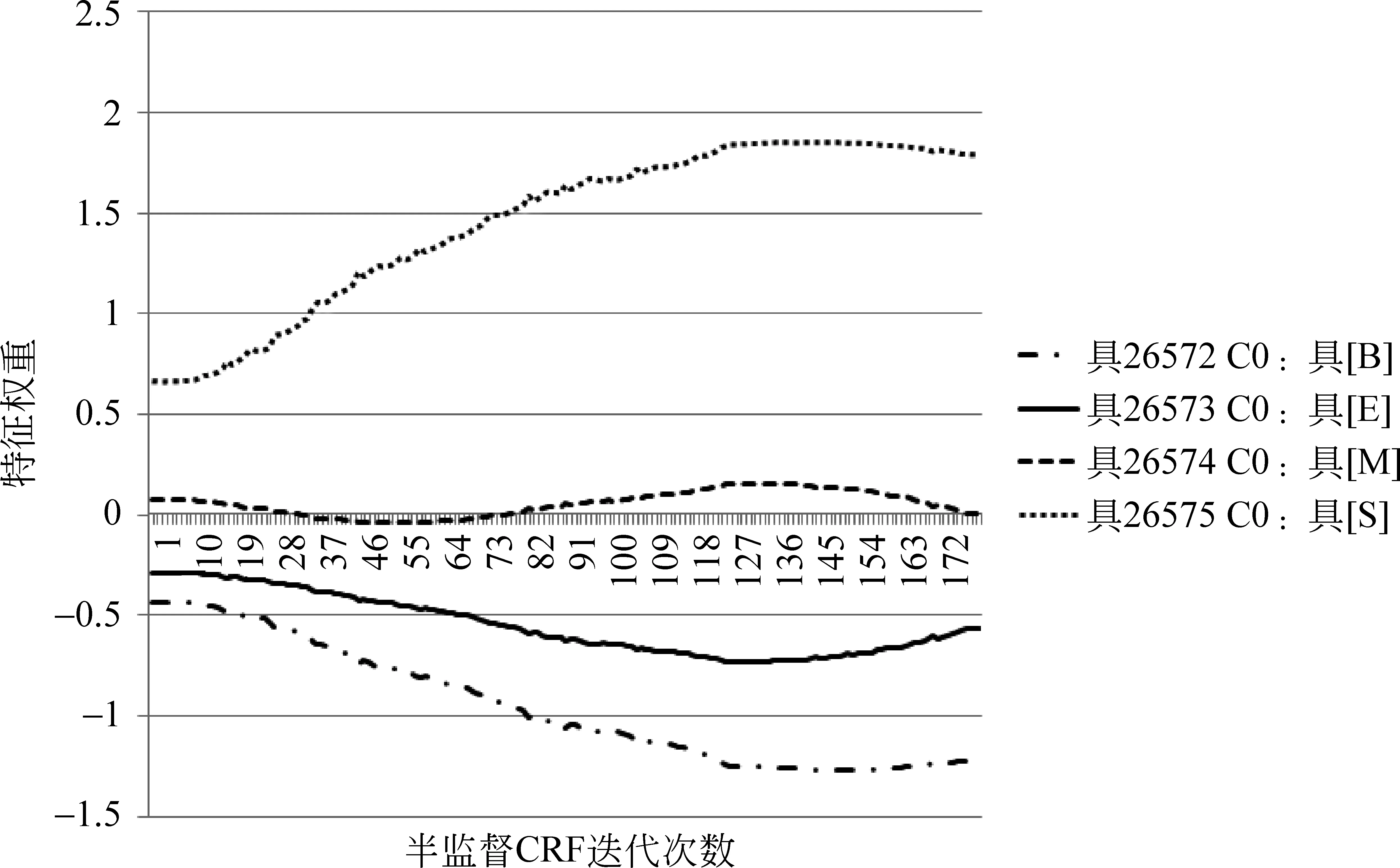
图3 “具”的特征权重变化趋势图(1)
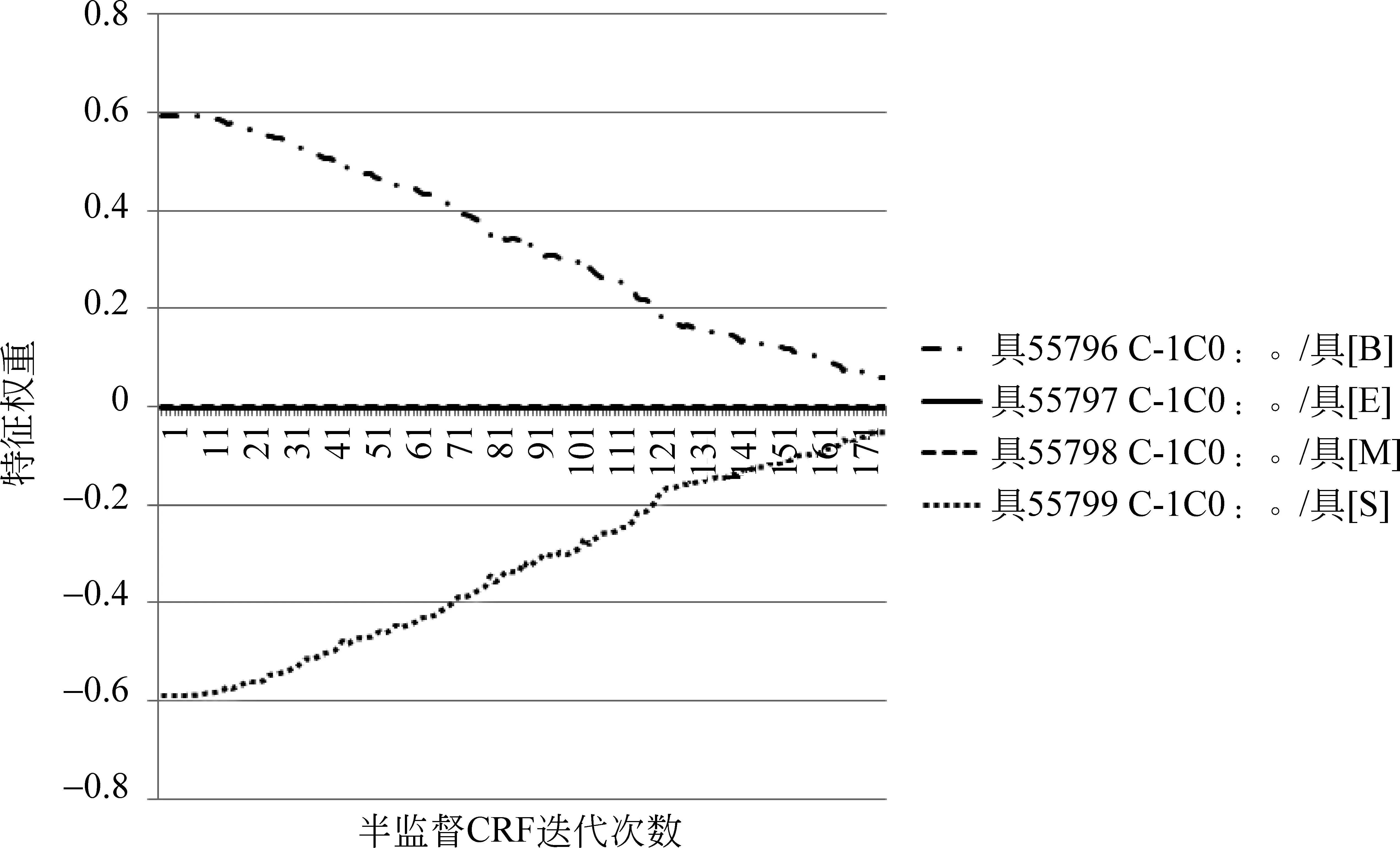
图4 “具”的特征权重变化趋势图(2)
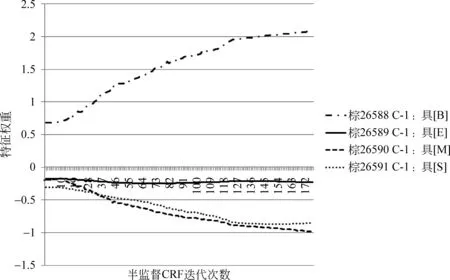
图5 “棕”的特征权重变化趋势图(1)
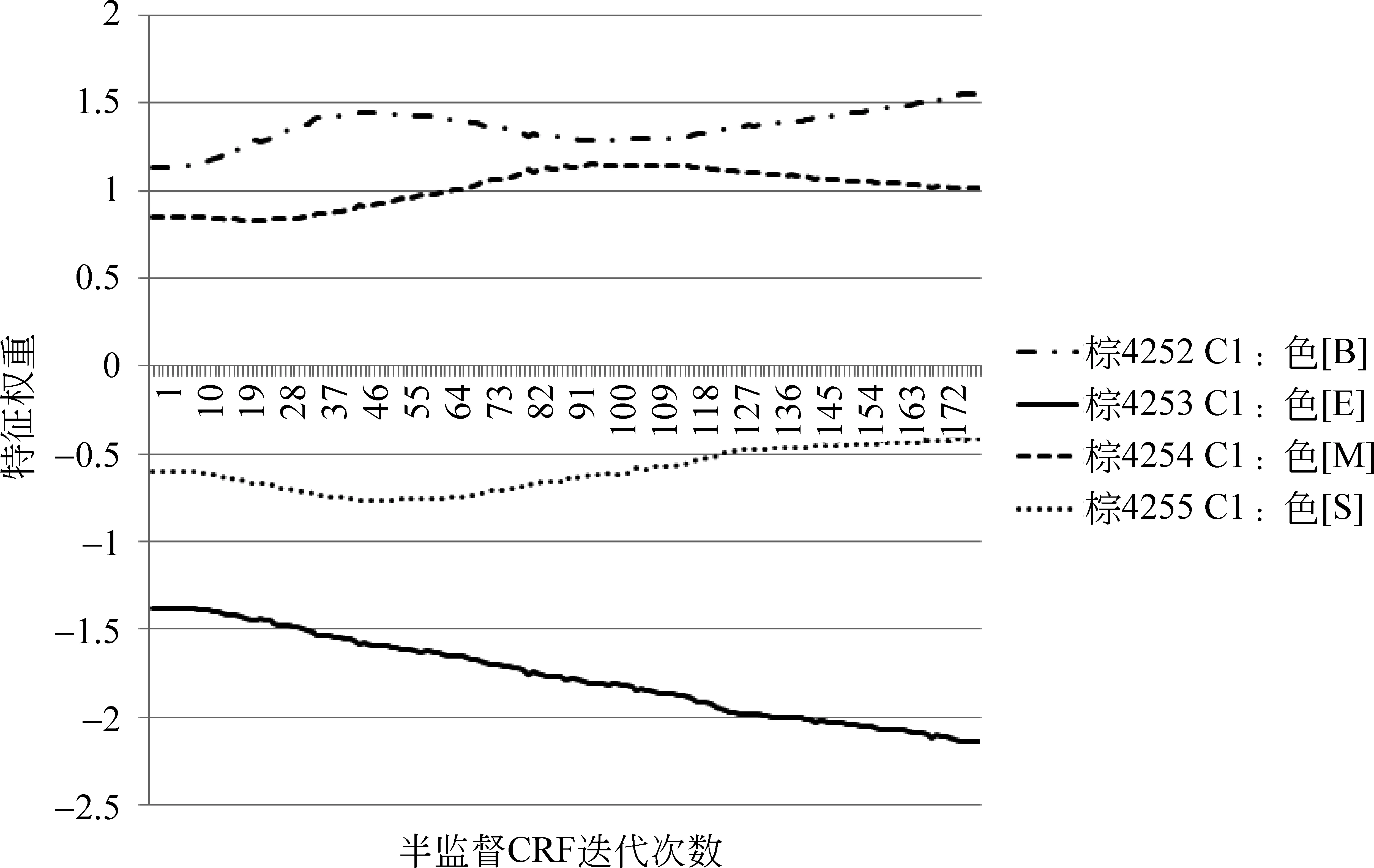
图6 “棕”的特征权重变化趋势图(2)
7 结论及下一步工作
本文通过引入最小熵正则化框架,提出半监督CRF分词模型,将标注数据的标注信息和未标注数据的分布信息结合起来,对跨领域分词效果进行了改进。同时,为了综合利用各个分词方法的优点,本文将加词典的方法、添加标注语料的方法和半监督CRF模型三种方法结合起来,进一步提高了分词系统的领域适应性。实验结果表明,本文所提方法能够有效改善跨领域分词系统的性能。
本文提出的方法虽然能够对跨领域分词结果进行有效改善,但还有进一步改进的空间。同时,研究测试发现: (1)基于简单文本窗口的特征提取方法并不能较好地挖掘专业领域文本特征,后续工作中,将在模型中加入专业领域文本重复字串及边界特征; (2)现有研究中,带标记训练语料和未标记语料仍使用同一套特征和权重,以后的研究中将引入更灵活的学习框架。
[1] 黄昌宁,赵海. 中文分词十年回顾[J]. 中文信息学报,2007,21(3): 8-20.
[2] Xue Nianwen. Chinese word segmentation as character tagging[J]. Computational Linguistics and Chinese Language Processing, 2003, 8(1): 29-48.
[3] 张梅山,邓知龙,车万翔,等.统计与词典相结合的领域自适应中文分词[J].中文信息学报, 2012, 26(2): 8-12.
[4] 许华婷,张玉洁,杨晓晖,等.基于Active Learning的中文分词领域自适应[J].中文信息学报, 2015, 29(5): 55-62.
[5] Fan Yang, Paul Vozila. Semi-supervised chinese word segmentation using partial-label learning with conditional random fields[C]//Proceedings of the 2014 conference on empirical methods in natural language processing(EMNLP), 2014: 90-98.
[6] Y Grandvalet, Y Bengio. Semi-supervised learning by entropy minimization[C]//Proceedings of the Advances in neural information processing systems 17, Cambridge, MA: MIT Press, 2005: 529-536.
[7] Lafferty, A. McCallum, F. Pereira. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]// Proceedings of the 18th International Conference on Machine Learning, 2001: 282-289.
[8] 李航. 统计学习方法[M]. 北京: 清华大学出版社,2012: 191-209.
[9] O. Chapelle, B. Schölkopf, A. Zien. Semi-supervised learning[M]. Cambridge, MA: The MIT Press, London, 2006.
[10] 宗成庆. 统计自然语言处理[M]. 北京: 清华大学出版社,2008: 19-20.
[11] Mann G S, McCallum A. Efficient computation of entropy gradient for semi-supervised conditional random fields[C]//Proceedings of the 2007 Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg, USA: Association for Computational Linguistics, 2007.
[12] 俞士汶,段慧明,朱学锋,等. 北大语料加工规范: 切分·词性标注·注音[J]. 汉语语言与计算学报,2004,13(2): 121-158.
[13] 罗智勇,宋柔.基于多特征的自适应新词识别[J].北京工业大学学报, 2007, 33(7): 718-725.
[14] Jiao Feng, Wang Shaojun, Lee Chi-Hoon, et al. Semi supervised conditional random fields for improved sequence segmentation and Labeling[C]//Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics. Sydney, Australia: Association for Computational Linguistics, 2006.
[15] Stephen P. Boyd, Lieven Vandenberghe.Convex optimization [M]. Cambridge University Press, 2004.

邓丽萍(1990—),硕士,主要研究领域为自然语言处理。
E-mail: dengliping_blcu@126.com

罗智勇(1975—),通信作者,博士,副教授,硕士生导师,主要研究领域为自然语言处理、机器学习。
Email: luo_zy@blcu.edu.cn
Domain Adaptation of Chinese Word Segmentation on Semi-Supervised Conditional Random Fields
DENG Liping1,LUO Zhiyong2
(1. College of Information Science,Beijing Language and Culture University,Beijing 100083,China; 2. Institute of Linguistic Information Processing,Beijing Language and Culture University,Beijing 100083,China)
1003-0077(2017)04-0009-11
